13 มิ.ย. 2568·1 นาที
Palantir กับซอฟต์แวร์องค์กร: การรวมข้อมูล การวิเคราะห์ และการปรับใช้
ดูว่าแนวทางของ Palantir ในการรวมข้อมูล การวิเคราะห์เชิงปฏิบัติการ และการปรับใช้ต่างจากซอฟต์แวร์องค์กรแบบดั้งเดิมอย่างไร — และหมายความว่าอย่างไรสำหรับผู้ซื้อ
ดูว่าแนวทางของ Palantir ในการรวมข้อมูล การวิเคราะห์เชิงปฏิบัติการ และการปรับใช้ต่างจากซอฟต์แวร์องค์กรแบบดั้งเดิมอย่างไร — และหมายความว่าอย่างไรสำหรับผู้ซื้อ
ผู้คนมักใช้คำว่า “Palantir” เป็นคำย่อของผลิตภัณฑ์ที่เกี่ยวข้องและแนวทางในการสร้างการปฏิบัติการที่ขับเคลื่อนด้วยข้อมูล เพื่อให้การเปรียบเทียบชัดเจน ควรกำหนดว่ากำลังพูดถึงอะไรบ้าง
เมื่อกล่าวถึง “Palantir” ในบริบทองค์กร มักหมายถึงหนึ่งในสิ่งเหล่านี้หรือทั้งหลาย:
บทความนี้ใช้คำว่า “คล้าย Palantir” เพื่ออธิบายชุดของ (1) การรวมข้อมูลที่แข็งแกร่ง (2) เลเยอร์ความหมาย/ontology ที่ทำให้ทีมมีความเข้าใจร่วมกัน และ (3) รูปแบบการปรับใช้ที่ครอบคลุม cloud, on‑prem และสภาพแวดล้อมที่ตัดการเชื่อมต่อได้
“ซอฟต์แวร์องค์กรแบบดั้งเดิม” ไม่ได้หมายถึงผลิตภัณฑ์ตัวเดียว แต่คือสแต็กทั่วไปที่หลายองค์กรประกอบขึ้นตามเวลา เช่น:
แนวทางนี้มักทำให้การรวมข้อมูล การวิเคราะห์ และการปฏิบัติการถูกจัดการโดยเครื่องมือและทีมแยกกัน แล้วเชื่อมกันผ่านโครงการและกระบวนการกำกับดูแล
นี่คือการเปรียบเทียบ “แนวทาง” ไม่ใช่การรับรองผู้ขาย หลายองค์กรประสบความสำเร็จด้วยสแต็กแบบดั้งเดิม ขณะที่บางองค์กรได้ประโยชน์จากโมเดลแพลตฟอร์มที่รวมศูนย์กว่า
คำถามเชิงปฏิบัติคือ: คุณแลกเปลี่ยนอะไรบ้างในด้านความเร็ว การควบคุม และความใกล้ชิดระหว่างการวิเคราะห์กับงานประจำวัน?
เพื่อความชัดเจน เราจะเน้นสามด้านหลัก:
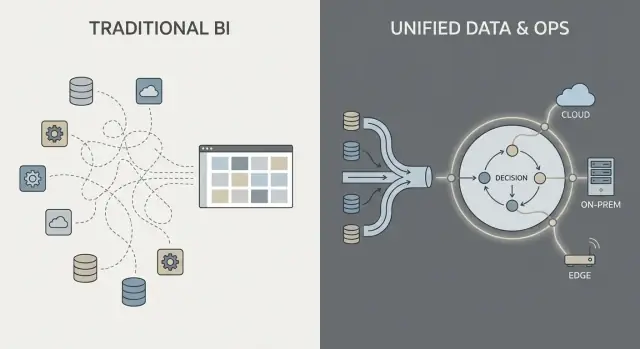
งานข้อมูลในสแต็กแบบดั้งเดิมมักเป็นสายตรรกะที่คุ้นเคย: ดึงข้อมูลจากระบบ (ERP, CRM, logs), แปลงข้อมูล, โหลดเข้า warehouse หรือลาก แล้วสร้างแดชบอร์ด BI พร้อมแอปปลายทางบางตัว
รูปแบบนี้ใช้ได้ดีในบางกรณี แต่บ่อยครั้งการรวมข้อมูลกลายเป็นชุดของการส่งต่อที่เปราะบาง: ทีมหนึ่งเป็นเจ้าของสคริปต์ดึงข้อมูล ทีมอีกทีมเป็นเจ้าของโมเดลใน warehouse ทีมที่สามเป็นเจ้าของนิยามแดชบอร์ด และทีมธุรกิจเก็บสเปรดชีตที่นิยามตัวเลขจริงขึ้นมาเงียบๆ
กับ ETL/ELT การเปลี่ยนแปลงมักส่งผลเป็นลูกโซ่ ฟิลด์ใหม่ในระบบต้นทางอาจทำให้ท่อพัง แก้ไขชั่วคราวอาจสร้างท่อที่สอง ในไม่ช้าคุณจะมีเมตริกซ้ำซ้อน (“revenue” ในสามที่) และไม่ชัดเจนว่าใครรับผิดชอบเมื่อจำนวนไม่ตรงกัน
การประมวลผลแบบเป็นชุดเป็นเรื่องปกติ: ข้อมูลมาถึงตอนกลางคืน และแดชบอร์ดอัพเดตตอนเช้า การทำ near‑real‑time เป็นไปได้ แต่มักกลายเป็นสแตกสตรีมมิ่งแยกต่างหากพร้อมเครื่องมือและเจ้าของของตัวเอง
แนวทางแบบ Palantir มุ่งรวมแหล่งข้อมูลและใช้ความหมายที่สอดคล้องกัน (นิยาม ความสัมพันธ์ และกฎ) ให้เร็วก่อน แล้วเปิดเผยข้อมูลที่คัดสรรเดียวกันสู่การวิเคราะห์และเวิร์กโฟลว์เชิงปฏิบัติการ
พูดง่ายๆ: แทนที่จะให้แต่ละแดชบอร์ดหรือแอปต้อง “ค้นหาเอง” ว่า ลูกค้า ทรัพย์สิน เคส หรือการจัดส่งหมายถึงอะไร ความหมายนั้นถูกนิยามครั้งเดียวและใช้ซ้ำได้ ซึ่งช่วยลดตรรกะซ้ำและทำให้ความรับผิดชอบชัดเจนขึ้น—เพราะเมื่อมีการเปลี่ยนแปลงนิยาม คุณรู้ว่ามันอยู่ที่ไหนและใครเป็นผู้อนุมัติ
การรวมข้อมูลมักล้มเหลวที่ความรับผิดชอบ ไม่ใช่แค่ตัวเชื่อม:
คำถามสำคัญไม่ใช่แค่ “เชื่อมกับระบบ X ได้ไหม?” แต่คือ “ใครเป็นเจ้าของท่อ เมตริก และความหมายทางธุรกิจในระยะยาว?”
ซอฟต์แวร์องค์กรแบบดั้งเดิมมักมอง “ความหมาย” เป็นเรื่องรอง: ข้อมูลเก็บในสคีมาของแอปหลายตัว นิยามเมตริกอยู่ในแดชบอร์ดแต่ละชิ้น และทีมต่างๆ ดูแลเวอร์ชันของตัวเองของ “คำว่า order คืออะไร” หรือ “เมื่อใดที่เคสถือว่าแก้ปัญหาแล้ว” ผลลัพธ์คือค่าต่างกันในที่ต่างกัน การประชุมปรับตัวช้า และความรับผิดชอบไม่ชัดเมื่อผลลัพธ์ผิดปกติ
ในแนวทางคล้าย Palantir เลเยอร์เชิงความหมายไม่ได้เป็นแค่ความสะดวกในการรายงาน ontology ทำหน้าที่เป็นโมเดลธุรกิจร่วมที่กำหนด:
นี่กลายเป็น “จุดศูนย์ถ่วง” สำหรับการวิเคราะห์และการปฏิบัติการ: แหล่งข้อมูลหลายตัวอาจยังคงมีอยู่ แต่จะแม็ปเข้ากับชุดอ็อบเจ็กต์ธุรกิจร่วมที่มีนิยามสอดคล้องกัน
โมเดลร่วมช่วยลดตัวเลขที่ไม่ตรงกันเพราะทีมไม่ต้องประดิษฐ์นิยามใหม่ในทุกรายงานหรือแอป มันยังเพิ่มความรับผิดชอบ: ถ้า “การส่งมอบตรงเวลา” ถูกนิยามจากเหตุการณ์ Shipment ใน ontology จะเห็นได้ชัดขึ้นว่าใครเป็นเจ้าของข้อมูลพื้นฐานและตรรกะธุรกิจ
เมื่อทำได้ดี ontology ไม่เพียงทำให้แดชบอร์ดสะอาดขึ้น แต่ทำให้การตัดสินใจประจำวันเร็วขึ้นและมีข้อโต้แย้งน้อยลง
แดชบอร์ด BI และการรายงานแบบดั้งเดิมมุ่งที่ อดีตและการมอนิเตอร์ ตอบคำถามเช่น “เกิดอะไรเมื่อสัปดาห์ที่แล้ว?” หรือ “เราเดินตาม KPI หรือไม่?” แดชบอร์ดฝ่ายขาย รายงานปิดงบการเงิน หรือสกอร์การ์ดผู้บริหารมีคุณค่า—แต่บ่อยครั้งหยุดที่การมองเห็น
การวิเคราะห์เชิงปฏิบัติการต่างออกไป: เป็นการวิเคราะห์ที่ฝังในกระบวนการตัดสินใจและการปฏิบัติงานประจำวัน แทนที่จะมี “ปลายทางการวิเคราะห์” แยกต่างหาก การวิเคราะห์ปรากฏในเวิร์กโฟลว์ที่ทำงาน และขับเคลื่อนขั้นตอนถัดไปที่ชัดเจน
BI/การรายงานมักมุ่งที่:
สิ่งเหล่านี้ดีสำหรับการกำกับดูแล การจัดการผลการปฏิบัติงาน และความรับผิดชอบ
การวิเคราะห์เชิงปฏิบัติการมุ่งที่:
ตัวอย่างที่จับต้องได้มักไม่ใช่ “กราฟ” แต่เหมือน คิวงานพร้อมบริบท:
การเปลี่ยนที่สำคัญคือการผูกการวิเคราะห์เข้ากับ ขั้นตอนเวิร์กโฟลว์เฉพาะ แดชบอร์ด BI อาจบอกว่า “การส่งมอบล่าช้าเพิ่มขึ้น” แต่การวิเคราะห์เชิงปฏิบัติการจะเปลี่ยนเป็น “นี่คือ 37 การจัดส่งที่เสี่ยงวันนี้ สาเหตุที่เป็นไปได้ และการแทรกแซงที่แนะนำ” พร้อมความสามารถในการดำเนินการหรือมอบหมายทันที
การวิเคราะห์องค์กรแบบดั้งเดิมมักจบที่มุมมองแดชบอร์ด: คนเห็นปัญหา ส่งออก CSV ส่งอีเมล แล้วทีมแยกต่างหาก “ทำอะไรสักอย่าง” ต่อมา แนวทางคล้าย Palantir ถูกออกแบบมาเพื่อลดช่องว่างนั้นโดยฝังการวิเคราะห์เข้าไปในเวิร์กโฟลว์ที่ตัดสินใจเกิดขึ้น
ระบบที่เน้นเวิร์กโฟลว์มักสร้างคำแนะนำ (เช่น “จัดลำดับ 12 การจัดส่งนี้ก่อน,” “ติดธงซัพพลายเออร์ 3 รายนี้,” “กำหนดการบำรุงรักษาภายใน 72 ชั่วโมง”) แต่ยังต้องมีการอนุมัติที่ชัดเจน ขั้นตอนการอนุมัติสำคัญเพราะสร้าง:
สิ่งนี้มีประโยชน์โดยเฉพาะในงานที่มีการกำกับหรือความเสี่ยงสูง ซึ่งการบอกว่า “ระบบบอกแบบนั้น” อย่างเดียวไม่เพียงพอ
แทนที่จะมองการวิเคราะห์เป็นปลายทางแยกต่างหาก อินเทอร์เฟซสามารถส่งข้อมูลเชิงลึกเข้าไปในงาน: มอบหมายให้คิว ขอนุมัติ ทริกเกอร์การแจ้งเตือน เปิดเคส หรือสร้างคำสั่งงาน จุดสำคัญคือผลลัพธ์ถูกติดตามภายในระบบเดียวกัน—ดังนั้นคุณจึงวัดได้ว่าการกระทำลดความเสี่ยง ต้นทุน หรือความล่าช้าได้จริงหรือไม่
การออกแบบโดยรอบเวิร์กโฟลว์มักแยกประสบการณ์ตามบทบาท:
ปัจจัยความสำเร็จทั่วไปคือการจัดผลิตภัณฑ์ให้สอดคล้องกับ สิทธิการตัดสินใจและขั้นตอนปฏิบัติการ: ใครทำได้ อะไรต้องอนุมัติ และคำว่า “เสร็จ” หมายถึงอะไรเชิงปฏิบัติการ
การกำกับดูแลคือที่ที่โครงการวิเคราะห์หลายโครงการประสบความสำเร็จหรือสะดุด มันไม่ใช่แค่ “การตั้งค่าความปลอดภัย” แต่คือชุดกฎปฏิบัติและหลักฐานที่ทำให้ผู้คนเชื่อถือตัวเลข แบ่งปันอย่างปลอดภัย และใช้มันตัดสินใจจริง
องค์กรส่วนใหญ่ต้องการการควบคุมหลักเหมือนกัน ไม่ว่าจะเป็นผู้ขายใด:
สิ่งเหล่านี้ไม่ใช่การสร้างงานราชการโดยไม่จำเป็น แต่เป็นวิธีป้องกันปัญหา “สองเวอร์ชันของความจริง” และลดความเสี่ยงเมื่อการวิเคราะห์เข้าใกล้การปฏิบัติการมากขึ้น
การใช้งาน BI แบบดั้งเดิมมักวางการควบคุมที่ เลเยอร์รายงาน เป็นหลัก: ผู้ใช้ดูแดชบอร์ดบางอันได้ และผู้ดูแลจัดการสิทธิ์ที่นั่น เมื่อการวิเคราะห์เป็นการบรรยายเป็นหลัก วิธีนี้อาจใช้งานได้
แนวทางแบบ Palantir ดันการกำกับดูแลและความปลอดภัยให้แทรกซึม ตลอดห่วงโซ่: ตั้งแต่การดึงข้อมูลดิบ ไปยังเลเยอร์ความหมาย (อ็อบเจ็กต์ ความสัมพันธ์ นิยาม) ไปจนถึงโมเดล และแม้แต่การกระทำที่ถูกทริกเกอร์จากข้อมูลเชิงลึก เป้าหมายคือตัดสินใจเชิงปฏิบัติการ (เช่นการส่งทีม การปล่อยสต็อก หรือลำดับคดี) ต้องสืบทอดการควบคุมเดียวกับข้อมูลเบื้องหลัง
สองหลักการสำคัญเพื่อความปลอดภัยและความรับผิดชอบ:
ตัวอย่างเช่น นักวิเคราะห์อาจเสนอการนิยามเมตริก ผู้ดูแลข้อมูลอนุมัติ และฝ่ายปฏิบัติการใช้มัน—พร้อมเส้นทางการตรวจสอบชัดเจน
การกำกับดูแลที่ดีไม่ได้เป็นเรื่องของทีมความเป็นไปตามอย่างเดียว เมื่อผู้ใช้ธุรกิจคลิกดูเส้นทางที่มา เห็นนิยาม และเชื่อถือสิทธิ์ที่สอดคล้อง พวกเขาจะเลิกถกเถียงเรื่องสเปรดชีตและเริ่มลงมือทำ ความมั่นใจนี้แหละที่เปลี่ยนการวิเคราะห์จาก “รายงานที่น่าสนใจ” ให้กลายเป็นพฤติกรรมเชิงปฏิบัติการ
ในบทความนี้ “Palantir” เป็นคำย่อสำหรับแนวทางแบบแพลตฟอร์มที่มักเกี่ยวข้องกับ Foundry (แพลตฟอร์มเชิงพาณิชย์ด้านข้อมูล/ปฏิบัติการ), Gotham (มีรากในภาครัฐ/กลาโหม), และ Apollo (ระบบการปรับใช้/จัดส่งข้ามสภาพแวดล้อม)
“ซอฟต์แวร์องค์กรแบบดั้งเดิม” หมายถึงสแต็กที่องค์กรส่วนใหญ่ประกอบกันเอง: ERP/CRM + data warehouse/ lake + BI + ETL/ELT/iPaaS และ middleware สำหรับการเชื่อมต่อ ซึ่งมักถูกดูแลโดยทีมแยกต่างหากและเชื่อมผ่านโครงการกับกระบวนการกำกับดูแล
เลเยอร์เชิงความหมายคือที่ที่คุณนิยาม ความหมายทางธุรกิจครั้งเดียว (เช่น “Order”, “Customer”, หรือ “On-time delivery”) แล้วใช้ซ้ำในงานวิเคราะห์และเวิร์กโฟลว์
Ontology จะไปไกลกว่านั้นโดยการจำลอง:
ประโยชน์เชิงปฏิบัติคือมีนิยามที่ขัดแย้งกันน้อยลงระหว่างแดชบอร์ด แอป และทีม และมีความรับผิดชอบชัดเจนเมื่อมีการเปลี่ยนแปลงนิยาม
ETL/ELT แบบดั้งเดิมมักกลายเป็นการส่งต่อตามลำดับ: ดึงจากแหล่ง → แปลง → โมเดลใน warehouse → แดชบอร์ด โดยแต่ละขั้นตอนมีเจ้าของต่างกัน
โหมดล้มเหลวทั่วไปได้แก่:
รูปแบบคล้าย Palantir พยายามนิยามความหมายให้เร็วกว่าการใช้งาน แล้วนำอ็อบเจ็กต์ที่คัดสรรแล้วไปใช้ซ้ำทุกที่ เพื่อลดตรรกะซ้ำและทำให้การควบคุมการเปลี่ยนแปลงชัดเจนขึ้น
แดชบอร์ด BI เป็น primarily การ สังเกตและอธิบาย: ตรวจสอบ KPI การรีเฟรชแบบตารางเวลา และการวิเคราะห์ย้อนหลัง
Operational analytics คือการ ตัดสินใจและลงมือทำ:
ถ้าผลลัพธ์คือ “กราฟ” มักเป็น BI แต่ถ้าผลลัพธ์คือ “นี่คือสิ่งที่ต้องทำต่อไป และทำได้ที่นี่” นั่นคือ operational analytics
ระบบที่มุ่งออกแบบโดยรอบเวิร์กโฟลว์ย่อมย่นระยะระหว่างข้อมูลเชิงลึกกับการปฏิบัติจริงโดยฝังการวิเคราะห์ไว้ที่ที่งานเกิดขึ้น
ในทางปฏิบัติจะมาแทนที่การ “ส่งออก CSV แล้วอีเมล” ด้วย:
เป้าหมายไม่ใช่แค่รายงานสวยงาม แต่คือการตัดสินใจที่เร็วขึ้นและตรวจสอบได้
“Human-in-the-loop” หมายถึงระบบสามารถแนะนำการดำเนินการได้ แต่ ผู้คนต้องอนุมัติหรือกลับคำสั่งได้อย่างชัดเจน
สิ่งนี้สำคัญเพราะมันสร้าง:
สำคัญโดยเฉพาะในงานที่มีการกำกับหรือความเสี่ยงสูง ซึ่งไม่สามารถอ้างว่า “โมเดลบอกมา” ได้อย่างเดียว
การกำกับดูแลไม่ใช่แค่การตั้งค่าเข้าสู่ระบบ แต่มันคือกฎปฏิบัติและหลักฐานที่ทำให้ผู้คนเชื่อถือเมตริก แบ่งปันอย่างปลอดภัย และใช้เพื่อการตัดสินใจจริง
ขั้นต่ำที่องค์กรมักต้องการได้แก่:
การกำกับดูแลที่ดีทำให้ทีมเสียเวลาในการปรับตัวตัวเลขน้อยลง และใช้ข้อมูลในการลงมือทำได้มากขึ้น
ตัวเลือกการปรับใช้จำกัดสิ่งที่เป็นไปได้ในเรื่องความเร็ว การควบคุม และค่าใช้จ่ายในการดำเนินงาน:
การส่งมอบแบบคล้าย Apollo คือการทำ continuous delivery สำหรับสภาพแวดล้อมที่มีความเสี่ยงสูง: ส่งปรับปรุงบ่อย ๆ โดยไม่ทำให้การปฏิบัติงานเสียหาย
เมื่อเทียบกับวงจรการอัพเกรดแบบดั้งเดิม มันเน้น:
สำคัญเพราะ operational analytics พึ่งพาท่อข้อมูลและตรรกะธุรกิจที่เชื่อถือได้ ไม่ใช่แค่รายงาน
พัฒนาการใช้งานที่ได้ผลคือแคบและมุ่งประเด็นเชิงปฏิบัติการ
โครงสร้างที่ได้ผลเช่น:
การกำหนดราคาควรเชื่อมกับผลลัพธ์ที่ต้องการ (การรวมข้อมูล + การสร้างโมเดล + การกำกับดูแล + แอปเชิงปฏิบัติการ) ไม่ใช่แค่รายการซอฟต์แวร์
ตัวขับต้นทุนปกติสำหรับแพลตฟอร์มแบบ Palantir ได้แก่:
สแต็กแบบจุด (point solutions) อาจดูถูกกว่าในตอนแรก แต่ค่าใช้จ่ายรวมมักกระจายไปที่ไลเซนส์หลายตัว การบูรณาการ และการบำรุงรักษาต่อเนื่อง
แพลตฟอร์มแบบ Palantir มักเหมาะเมื่อปัญหาเป็นเชิงปฏิบัติการ: คนต้องตัดสินใจและลงมือข้ามระบบ ไม่ใช่แค่ต้องการรายงาน
เหมาะอย่างยิ่งเมื่อ:
ไม่เหมาะหากเป้าหมายเป็นการรายงานช่วงปกติ (KPIs รายสัปดาห์, การปิดบัญชีง่าย ๆ) หรือข้อมูลขนาดเล็ก/schema คงที่ที่ทีมเดียวควบคุมแหล่งที่มาและนิยาม
ถามตัวเองสามคำถาม: ความเร่งด่วน, ความซับซ้อนของข้อมูล, และความสามารถในการเปลี่ยนแปลงขององค์กร เพื่อประเมินความเหมาะสม
รายการตรวจสอบสำหรับผู้ซื้อช่วยสร้างความชัดเจนก่อนผูกมัดกับการใช้งานระยะยาวหรือเครื่องมือเฉพาะจุด
ถามผู้ขายให้ชัดเจนในเรื่อง ใครทำอะไร, ทำให้คงที่อย่างไร, และ ใช้ในปฏิบัติการอย่างไร:
เลือกตามกฎการจัดเก็บข้อมูล สภาพเครือข่าย และความสามารถในการดูแลแพลตฟอร์ม
หลีกเลี่ยงการใช้แดชบอร์ดทั่วไปเป็นเป้าหมายของพายล็อตหากเป้าหมายจริงคือผลกระทบเชิงปฏิบัติการ
สำหรับการสาธิต อย่ายอมรับสไลด์—ขอการสาธิตเชิงปฏิบัติการจริง เช่น การไล่เส้นทางเมตริก หนึ่ง KPI จากแหล่งสู่ค่า และการทำงานเวิร์กโฟลว์จากข้อมูลดิบถึงการกระทำและบันทึกการตรวจสอบ
สุดท้ายรวมผู้มีส่วนได้ส่วนเสีย: IT, ความปลอดภัย, data stewards, ผู้นำปฏิบัติการ และผู้ใช้งานแนวหน้า แล้วทำ proof‑of‑value แบบมีระยะเวลา เกี่ยวกับเวิร์กโฟลว์เดียวที่วัดผลได้