วิธีเลือกผลิตภัณฑ์ที่เหมาะกับการเขียนโค้ดโดยมี AI ช่วย
เครื่องมือเขียนโค้ดด้วย AI สามารถเขียนฟังก์ชัน สร้างบอยเลอร์เพลต แปลงไอเดียเป็นโค้ดเริ่มต้น และแนะนำการแก้เมื่อเกิดข้อผิดพลาดได้ดี โดยเฉพาะงานที่เป็นรูปแบบคุ้นเคย: ฟอร์ม หน้าจอ CRUD API ขั้นพื้นฐาน การแปลงข้อมูล และคอมโพเนนต์ UI
เครื่องมือเหล่านี้น่าเชื่อถือน้อยลงเมื่อข้อกำหนดไม่ชัดเจน กฎโดเมนซับซ้อน หรือเมื่อตัวผลลัพธ์ที่ “ถูกต้อง” ตรวจสอบได้ยาก พวกมันอาจประดิษฐ์ไลบรารี สมมติค่าคอนฟิก หรือผลิตโค้ดที่ทำงานได้ในกรณีทั่วไปแต่ล้มเหลวในกรณีขอบ
ถ้าคุณกำลังประเมินแพลตฟอร์ม (ไม่ใช่แค่ผู้ช่วยเขียนโค้ด) ให้โฟกัสที่ว่ามันช่วยคุณ เปลี่ยนสเปคเป็นแอปที่ทดสอบได้ และวนปรับอย่างปลอดภัยได้หรือไม่ ตัวอย่างเช่น แพลตฟอร์มไลก์ไวบ์โค้ดดิ้งอย่าง Koder.ai ออกแบบมาเพื่อผลิตเว็บ/เซิร์ฟเวอร์/แอปมือถือที่ใช้งานได้จากแชท—มีประโยชน์เมื่อคุณสามารถตรวจสอบผลลัพธ์ได้เร็วและต้องการวนปรับอย่างไวด้วยฟีเจอร์อย่างสแนปช็อต/ย้อนกลับและการส่งออกซอร์สโค้ด
ทำไมประเภทผลิตภัณฑ์จึงสำคัญกว่าภาษา
การเลือกผลิตภัณฑ์ที่เหมาะสมส่วนใหญ่เกี่ยวกับ ความง่ายในการตรวจสอบผลลัพธ์ ไม่ใช่ว่าคุณใช้ JavaScript, Python หรือภาษาอื่น ถ้าคุณสามารถทดสอบผลิตภัณฑ์ด้วย:
- อินพุตและเอาต์พุตที่ชัดเจน,\n- วงจรตอบกลับที่เร็ว (เป็นนาที ไม่ใช่เป็นสัปดาห์), และ\n- ผลกระทบต่ำเมื่อเกิดความผิดพลาด,\n
แสดงว่า AI ช่วยเขียนโค้ดได้ดี
ถ้าผลิตภัณฑ์ของคุณต้องใช้ความเชี่ยวชาญลึกเพื่อพิจารณาความถูกต้อง (การตีความกฎหมาย การตัดสินใจทางการแพทย์ การปฏิบัติตามกฎการเงิน) หรือความผิดพลาดมีค่าใช้จ่ายสูง คุณมักจะต้องใช้เวลาตรวจสอบและแก้ไขโค้ดที่ AI สร้างมากกว่าที่จะประหยัดได้
วิธีง่าย ๆ ในการตัดสินใจอย่างรวดเร็ว
ก่อนสร้าง ให้กำหนดว่า “เสร็จ” หมายถึงอะไรในเชิงสังเกตได้: หน้าจอที่ต้องมี การกระทำที่ผู้ใช้สามารถทำได้ และผลลัพธ์ที่วัดได้ (เช่น “นำเข้า CSV แล้วแสดงยอดรวมที่ตรงกับไฟล์ตัวอย่างนี้”) ผลิตภัณฑ์ที่มีเกณฑ์ยอมรับชัดเจนจะสร้างได้ปลอดภัยกว่าโดยใช้ AI
บทความนี้จบด้วยเช็คลิสต์ปฏิบัติที่คุณสามารถรันในไม่กี่นาทีเพื่อตัดสินว่าผลิตภัณฑ์เหมาะหรือไม่—และต้องใส่เกราะอะไรเพิ่มเติมเมื่อมันอยู่ในเกณฑ์ก้ำกึ่ง
ตั้งความคาดหวัง: AI เร่ง แต่คนรับผิดชอบคุณภาพ
แม้มีเครื่องมือดี ๆ คุณยังต้องการการตรวจทานและการทดสอบจากมนุษย์ วางแผนการตรวจโค้ด การตรวจสอบความปลอดภัยพื้นฐาน และเทสต์อัตโนมัติสำหรับส่วนที่สำคัญ คิดว่า AI เป็นผู้ร่วมงานที่ร่างและวนปรับอย่างรวดเร็ว—ไม่ใช่ตัวแทนของความรับผิดชอบ การยืนยัน และวินัยการปล่อยงาน
สิ่งที่เครื่องมือเขียนโค้ดด้วย AI ทำได้ดี (และที่มันลำบาก)
เครื่องมือ AI เด่นเมื่อคุณรู้ว่าต้องการอะไรและอธิบายได้ชัดเจน ถือมันเป็นผู้ช่วยที่รวดเร็วมาก: มันสามารถร่างโค้ด แนะนำรูปแบบ และเติมส่วนที่น่าเบื่อ แต่ไม่ได้เข้าใจข้อจำกัดจริงของผลิตภัณฑ์คุณโดยอัตโนมัติ
จุดแข็ง
พวกมันดีเป็นพิเศษในการเร่งงานที่ “รู้แล้วว่าจะทำอะไร” เช่น:
- ความเร็วและโครงคร่าว: สร้างโครงโปรเจกต์ กำหนด routes, models, คอมโพเนนต์ UI พื้นฐาน และเชื่อมไลบรารีที่ใช้ทั่วไป\n- บอยเลอร์เพลตและความซ้ำซ้อน: หน้าจอ CRUD, การตรวจสอบฟอร์มขั้นพื้นฐาน, ไคลเอนต์ API, เพจผู้ดูแล, เทสต์สตับ และร่างเอกสาร\n- รีแฟกเตอร์และทำความสะอาด: เปลี่ยนชื่อ แยกคอมโพเนนต์/ฟังก์ชัน แปลงสไตล์โค้ด และหาการซ้ำซ้อนที่ชัดเจน\n- อธิบายโค้ดที่มีอยู่: ช่วยให้เข้าใจโมดูลที่ไม่คุ้นเคยเพื่อให้คุณเปลี่ยนได้อย่างปลอดภัย
ใช้ให้เป็น นี่จะย่นเวลาเตรียมงานจากวันเป็นชั่วโมง—โดยเฉพาะสำหรับ MVP และเครื่องมือภายในองค์กร
จุดที่ลำบาก
เครื่องมือ AI มักมีปัญหาเมื่อโจทย์ไม่ได้กำหนดชัด หรือเมื่อละเอียดสำคัญกว่าความเร็ว:
- ข้อกำหนดไม่ชัด: เป้าหมายคลุมเครือ โค้ดอาจดูสมเหตุสมผลแต่แก้ปัญหาผิด\n- กรณีขอบและข้อมูลจริง: อินพุตแปลก ๆ พฤติกรรมผู้ใช้ที่รก concurrency การ retry โซนเวลา และคอขวดเรื่องประสิทธิภาพ\n- รายละเอียดเกี่ยวกับความปลอดภัย: โฟลว์การพิสูจน์ตัวตน สิทธิ์ การจัดการความลับ และค่าเริ่มต้นที่ปลอดภัย (มักละเว้นการตรวจเช็คสำคัญ)\n- ความประหลาดของการผสาน: API ภายนอกที่มีข้อจำกัดแปลก ๆ payload ไม่สอดคล้อง และ webhooks เปราะบาง
“เส้นทางสมหวัง” กับการใช้งานจริง
โค้ดที่ AI สร้างมักจะมุ่งไปที่ เส้นทางสมหวัง คือกรณีที่ทุกอย่างสำเร็จเรียบร้อยและผู้ใช้ทำตามคาด ผลิตภัณฑ์จริงอยู่ในเส้นทางที่ไม่สมหวัง—การชำระเงินล้มเหลว ภาวะชำระล่าช้า คำขอซ้ำ ผู้ใช้กดปุ่มสองครั้ง ฯลฯ
ที่ต้องตรวจสอบเพิ่ม
ปฏิบัติต่อเอาต์พุตจาก AI เป็นฉบับร่าง ยืนยันความถูกต้องด้วย:
- เกณฑ์การยอมรับและตัวอย่างที่ชัดเจน,\n- เทสต์หน่วย/อินทิเกรชันที่ครอบคลุมกรณีขอบ,\n- การตรวจรีวิวด้านความปลอดภัยและการจัดการข้อผิดพลาดด้วยคน,\n- ทดลองเล็ก ๆ ในสภาพแวดล้อมคล้ายโปรดักชันกับข้อมูลที่ใกล้เคียงจริง
ยิ่งบั๊กมีค่าตอบแทนสูงก็ยิ่งต้องพึ่งการตรวจสอบจากคนและเทสต์อัตโนมัติมากขึ้น—ไม่ใช่แค่การสร้างอย่างรวดเร็ว
เหมาะมากที่จะสร้าง: MVP และโปรโตไทป์ที่คลิกใช้งานได้
MVP และโปรโตไทป์ที่ “คลิกแล้วเป็นงานได้” คือจุดลงตัวของเครื่องมือ AI เพราะความสำเร็จวัดจากความเร็วในการเรียนรู้ ไม่ใช่ความสมบูรณ์ เป้าหมายคือขอบเขตแคบ: ปล่อยให้เร็ว รับฟังผู้ใช้จริง และตอบคำถามสำคัญหนึ่งหรือสองข้อ (มีคนใช้ไหม เขาจะจ่ายไหม เวิร์กโฟลว์นี้ช่วยประหยัดเวลาไหม)
รูปแบบ MVP ที่ใช้งานได้กับ AI
MVP ที่เป็นไปได้คือโปรเจกต์ระยะสั้น: สร้างเสร็จในไม่กี่วันหรือสองสัปดาห์ แล้วปรับตามฟีดแบ็ก เครื่องมือ AI เหมาะกับการพาถึงฐานการทำงานได้เร็ว—routing, forms, หน้าจอ CRUD เบื้องต้น, auth พื้นฐาน—เพื่อให้คุณโฟกัสที่ปัญหาและ UX
เก็บเวอร์ชันแรกให้มี 1–2 ฟลูว์หลัก ตัวอย่าง:
- เรียกดู → ขอ/ซื้อ\n- สร้าง → แชร์\n- เข้าสู่ระบบ → ทำงานหนึ่งอย่างให้เสร็จ → ดูผล
กำหนดผลลัพธ์ที่วัดได้สำหรับแต่ละฟลูว์ (เช่น “ผู้ใช้สร้างบัญชีและจองสำเร็จภายใน 2 นาที” หรือ “สมาชิกทีมส่งคำขอโดยไม่ต้องคุย Slack ซ้ำ”)
ตัวอย่างผลิตภัณฑ์ที่เหมาะกับ MVP ด้วย AI
ตัวอย่างที่เป็นตัวเลือกดีเพราะตรวจสอบง่ายและวนปรับง่าย:\n\n- ตลาดเรียบง่าย: ไดเรกทอรีที่รับการส่งข้อมูล การค้นหาพื้นฐาน/กรอง และฟลูว์ “ติดต่อผู้ขาย” หรือ “ขอใบเสนอราคา”\n- โปรโตไทป์การจอง: แอปตารางนัดเฉพาะทางสำหรับบริการหนึ่งประเภทที่มีความพร้อมใช้งาน อีเมลยืนยัน และมุมมองแอดมิน\n- ยูทิลิตี้เฉพาะกลุ่ม: เครื่องคำนวณ, เช็คลิสต์การเริ่มงาน, CRM เล็ก ๆ สำหรับจุดประสงค์เดียว, สต็อกง่าย ๆ สำหรับหมวดเล็ก ๆ
สิ่งที่ทำให้มันใช้งานได้ไม่ใช่ความกว้างของฟีเจอร์ แต่เป็นความชัดเจนของกรณีใช้งานครั้งแรก
ออกแบบเพื่อการเปลี่ยนแปลง (เพราะคุณจะเปลี่ยน)
สมมติว่า MVP ของคุณจะเปลี่ยน โครงสร้างโปรโตไทป์ให้การเปลี่ยนแปลงมีต้นทุนต่ำ:\n\n- ใช้การตั้งค่า (settings, ตารางกฎง่าย ๆ) แทนการฝังตรรกะทั่วโค้ด\n- เก็บโมเดลข้อมูลให้ขั้นต่ำ เพิ่มฟิลด์เมื่อมีเหตุผลจากการใช้งานจริง\n- สร้างเป็นชิ้นที่เปลี่ยนทดแทนได้: ผู้ให้บริการอีเมลพื้นฐานตอนนี้ แล้วอัพเกรดภายหลัง
แพทเทิร์นที่มีประโยชน์คือ: ปล่อย “happy path” ก่อน ติดเครื่องมือวัด (แม้เพียงแอนะลิติกส์เบา ๆ) แล้วขยายเฉพาะจุดที่ผู้ใช้ติด นั่นคือที่ AI ให้มูลค่าสูงสุด: วนปรับอย่างรวดเร็ว แทนการสร้างครั้งใหญ่ครั้งเดียว
เหมาะมากที่จะสร้าง: เครื่องมือภายในสำหรับทีมเล็ก
เครื่องมือภายในเป็นหนึ่งในพื้นที่ที่ปลอดภัยและให้ผลตอบแทนสูงสุดในการใช้ AI พัฒนา เพราะสร้างให้กลุ่มผู้ใช้ที่รู้จัก ใช้งานในสภาพแวดล้อมที่ควบคุมได้ และต้นทุนจากความไม่สมบูรณ์มักจัดการได้ (คุณสามารถแก้และปล่อยอัปเดตได้เร็ว)
ตัวอย่างเครื่องมือภายในที่ดี
โปรเจกต์เหล่านี้มักมีข้อกำหนดชัดและหน้าจอที่ทำซ้ำได้—เหมาะสำหรับสเกฟโฟลดิงและวนปรับด้วย AI:\n\n- แผงผู้ดูแลจัดการข้อมูล (ลูกค้า ผู้ขาย ทรัพย์สิน)\n- ติดตามสต็อก (เข้า/ออก สถานที่ หมายเหตุการสั่งซื้อซ้ำ)\n- แบบฟอร์มรับคำร้อง (IT, คำขอจัดซื้อ, อนุมัติเนื้อหา)\n- เครื่องมือจัดตารางง่าย ๆ (เวร, ห้องประชุม)
ทำไมมันเหมาะ
เครื่องมือภายในทีมเล็กมักมี:\n\n- ผู้ใช้และเวิร์กโฟลว์ที่รู้จัก: คุณสามารถสัมภาษณ์คนที่จะใช้มันจริง\n- การควบคุมสิทธิ์: กรณีขอบน้อยกว่าแอปสาธารณะ\n- วงจรตอบกลับเร็ว: ทดสอบการเปลี่ยนแปลงได้ในวันเดียวและปรับให้ดีขึ้นเร็ว
ตรงนี้คือที่ AI โชว์ศักยภาพ: สร้างหน้าจอ CRUD, การตรวจสอบฟอร์ม, UI พื้นฐาน และเชื่อมฐานข้อมูล ในขณะที่คุณโฟกัสที่รายละเอียดเวิร์กโฟลว์และการใช้งาน
ถ้าคุณต้องการเร่งตั้งแต่ต้นจนจบ แพลตฟอร์มอย่าง Koder.ai มักเข้าท่า: ปรับเพื่อสปิน React-based web apps พร้อม backend Go + PostgreSQL รวมการปรับใช้/โฮสติ้งและโดเมนเมื่อคุณพร้อมแชร์เครื่องมือกับทีม
สิ่งที่ต้องมีอย่าได้ข้าม
ภายในองค์กรไม่ได้หมายถึง “ไม่ต้องมีมาตรฐาน” ตรวจสอบให้มี:\n\n- การพิสูจน์ตัวตน (SSO ถ้ามี มิฉะนั้นอีเมล/รหัสผ่าน + MFA)\n- บทบาทและสิทธิ์ (อย่างน้อย admin vs member)\n- บันทึกการตรวจสอบ สำหรับการกระทำสำคัญ (แก้ไข อนุมัติ ลบ)\n- แบ็กอัพและการกู้คืน (สำรองฐานข้อมูล ตัวเลือกส่งออก)
เริ่มจากฟลูว์เดียว แล้วขยาย
เลือกทีมเดียวและแก้กระบวนการที่เจ็บปวดให้จบ เมื่อมีเสถียรภาพและเป็นที่เชื่อถือ ให้ขยายโครงพื้นฐานเดียวกัน—ผู้ใช้ บทบาท การบันทึก—ไปยังฟลูว์ถัดไป แทนการเริ่มใหม่ทุกครั้ง
เหมาะมากที่จะสร้าง: แดชบอร์ดและแอปรายงาน
จากการสร้างสู่การใช้งานจริง
ปรับใช้และโฮสต์แอปของคุณเมื่อพร้อมแชร์นอกเครื่อง
แดชบอร์ดและแอปรายงานเป็นจุดที่เหมาะกับ AI เพราะส่วนใหญ่เกี่ยวกับการดึงข้อมูลมานำเสนอให้ชัดเจนและช่วยคนประหยัดเวลา เมื่อพัง ผลกระทบมักเป็น “ตัดสินช้าไปหนึ่งวัน” ไม่ใช่ “ระบบล่ม” ความเสี่ยงต่ำทำให้หมวดนี้เป็นไปได้จริงสำหรับการสร้างด้วย AI
ตัวอย่างที่เหมาะ (พร้อมตัวอย่างชัดเจน)
เริ่มจากรายงานที่ทดแทนงานชีตซ้ำ ๆ:\n\n- แดชบอร์ด KPI สำหรับการขาย การตลาด หรือซัพพอร์ต (สุขภาพ pipeline อัตราแปลง backlog ตั๋ว)\n- รายงานสัปดาห์ที่สร้างสรุปอัตโนมัติ (รวมชาร์ต + เล่าเรื่องสั้น ๆ)\n- ตัวสำรวจข้อมูลสำหรับคำถามทั่วไป (“แสดง churn ตามแผน”, “กรองตามภูมิภาคและวันที่”)
เริ่มแบบอ่านอย่างเดียวเพื่อลดความเสี่ยง
กฎง่าย ๆ: ปล่อยแบบอ่านอย่างเดียวก่อน ให้แอปคิวรีแหล่งข้อมูลที่อนุมัติและแสดงผล แต่หลีกเลี่ยงการเขียนกลับ (แก้ไขเรคคอร์ด ทริกเกอร์การทำงาน) จนกว่าจะเชื่อถือข้อมูลและสิทธิ์ได้ แดชบอร์ดอ่านอย่างเดียวยืนยันง่ายกว่า ปลอดภัยกว่า และแก้ไขเร็วกว่า
สิ่งที่ต้องกำหนดล่วงหน้า
AI สร้าง UI และงานคิวรีได้ไว แต่คุณยังต้องชัดเจนเรื่อง:\n\n- คำนิยามข้อมูล: active user, qualified lead, churn คืออะไรจริง ๆ\n- ตารางการรีเฟรช: เรียลไทม์ ชั่วโมงละครั้ง รายวัน และทำอย่างไรเมื่อรีเฟรชล้มเหลว\n- การควบคุมการเข้าถึง: ใครเห็นอะไร (ทีม ภูมิภาค เซ็กเมนต์ลูกค้า) และข้อมูลต้องมาส์กไหม
แดชบอร์ดที่ “ดูถูก” แต่ตอบคำถามผิดแย่กว่าการไม่มีแดชบอร์ด
ระวัง metric drift และแหล่งข้อมูลไม่ตรงกัน
ระบบรายงานมักล้มเงียบเมื่อเมตริกเปลี่ยนแต่แดชบอร์ดไม่เปลี่ยน นั่นคือ metric drift: ชื่อ KPI เหมือนเดิมแต่ตรรกะเปลี่ยน (กฎการเรียกเก็บเงินใหม่ การติดตามเหตุการณ์ใหม่ ช่วงเวลาเปลี่ยน)
และระวังแหล่งข้อมูลที่ไม่ตรงกัน—ตัวเลขการเงินจาก data warehouse อาจไม่ตรงกับ CRM ระบุแหล่งที่มาชัดใน UI ใส่ timestamp ของการอัปเดตล่าสุดและบันทึกการเปลี่ยนแปลงสั้น ๆ ของคำนิยามเมตริก
เหมาะมากที่จะสร้าง: การบูรณาการและออโตเมชันเวิร์กโฟลว์
การบูรณาการเป็นหนึ่งในงาน “ให้ผลเยอะและปลอดภัย” สำหรับ AI เพราะงานหลักคือ glue code: ย้ายข้อมูลจาก A ไป B ทริกเกอร์การกระทำที่คาดได้ และจัดการข้อผิดพลาดให้เรียบร้อย พฤติกรรมบรรยายง่าย ทดสอบตรงไปตรงมา และสังเกตในโปรดักชันได้ง่าย
ตัวอย่างเริ่มต้นที่ดี
เลือกเวิร์กโฟลว์ที่มีอินพุตชัดเจน เอาต์พุตชัดเจน และสาขาไม่มาก เช่น:\n\n- ซิงค์ CRM → อีเมล (lead ใหม่ → เพิ่มเข้ารายชื่อ ติดแท็ก และยืนยัน)\n- การแจ้งเตือน Slack (การชำระเงินล้มเหลว ลูกค้าระดับสูงสมัครใหม่ การแจ้งเหตุการณ์)\n- ส่งออกใบแจ้งหนี้ (ระบบบัญชี → CSV/JSON ไป S3, สรุปรายสัปดาห์ทางอีเมล)\n- Webhooks (รับเหตุการณ์ → ตรวจสอบ → แปลง → ส่งต่อไปยัง API อื่น)
โปรเจกต์เหล่านี้เหมาะเพราะคุณสามารถอธิบายสัญญาได้ (“เมื่อ X เกิด ให้ทำ Y”) แล้วยืนยันด้วย fixtures และ payload ตัวอย่างจริง
ออกแบบเพื่อความเชื่อถือได้ ไม่ใช่แค่ “ทำงานครั้งเดียว”\n
บั๊กส่วนใหญ่ของออโตเมชันจะโผล่เมื่อมี retries ความล้มเหลวบางส่วน หรือเหตุการณ์ซ้ำ สร้างพื้นฐานเหล่านี้ตั้งแต่ต้น:\n\n- คิว สำหรับงานแบบ async (เพื่อป้องกัน API ช้าไปบล็อกแอป)\n- Retries พร้อม backoff สำหรับความล้มเหลวชั่วคราว (timeouts, rate limits)\n- Idempotency เพื่อให้การประมวลผลซ้ำไม่สร้างข้อมูลซ้ำ (ใช้ idempotency keys, ตาราง de-dupe, หรือ upsert)
แม้ AI จะสร้างพาร์สแรกได้ไว คุณจะได้มูลค่าเพิ่มโดยลงทุนเวลาในกรณีขอบ: ฟิลด์ว่าง ประเภทข้อมูลไม่คาดคิด pagination และ rate limits
เพิ่มการมอนิเตอร์ให้เห็นความล้มเหลวชัดเจน
ออโตเมชันมักล้มเงียบเว้นแต่คุณทำให้มันเด่น ขั้นต่ำต้องมี:\n\n- logs โครงสร้างพร้อม correlation IDs\n- alerts เมื่ออัตราข้อผิดพลาดพุ่งหรือคิวติดค้าง\n- แดชบอร์ดความล้มเหลว แสดงงานค้าง เวลาสำเร็จล่าสุด และสาเหตุข้อผิดพลาดยอดนิยม
ถ้าจะต่อยอด เพิ่มปุ่ม “replay failed job” ให้คนที่ไม่ใช่วิศวกรกู้คืนได้โดยไม่ต้องงมโค้ด
เหมาะมากที่จะสร้าง: เครื่องมือเนื้อหาและความรู้พร้อมเกราะป้องกัน
แอปเนื้อหาและความรู้เหมาะกับ AI เพราะงานชัดเจน: ช่วยคนค้น เข้าใจ และนำข้อมูลที่มีอยู่มาใช้ซ้ำ คุณค่าชัดเจนและวัดได้ด้วยสัญญาณง่าย ๆ เช่น เวลาที่ประหยัด คำถามที่ซ้ำลดลง และอัตราการแก้ปัญหาด้วยตนเองสูงขึ้น
สร้างอะไร (ตัวอย่างใช้งาน)
ผลิตภัณฑ์เหล่านี้ใช้งานดีเมื่อยึดโยงกับเอกสารและเวิร์กโฟลว์ของคุณ:\n\n- การค้นหาภายในเอกสาร ตั๋ว วิกิ และนโยบาย\n- การติดแท็กและจัดหมวดอัตโนมัติสำหรับฐานความรู้\n- ย่อสาระสำคัญของเอกสารยาว บันทึกการประชุม หรือเธรดซัพพอร์ต\n- Q&A เอกสารสำหรับ “นโยบายเกี่ยวกับ X คืออะไร?” หรือ “ทำ Y อย่างไร?”
เริ่มด้วยการเรียกค้นก่อนการสร้างคำตอบ “ฉลาด”
รูปแบบที่ปลอดภัยและมีประโยชน์ที่สุดคือ: retrieve first, generate second ค้นหาข้อมูลของคุณเพื่อหาแหล่งที่เกี่ยวข้องก่อน แล้วใช้ AI สรุปหรือให้คำตอบจากแหล่งเหล่านั้น
วิธีนี้ทำให้คำตอบมีรากฐาน ลด hallucination และแก้จุดผิดพลาดได้ง่ายขึ้น (“มันอ้างอิงเอกสารไหน?”)
เกราะที่ทำให้ไว้ใจได้
ใส่การป้องกันน้ำหนักเบาตั้งแต่ต้น แม้เป็น MVP:\n\n- การอ้างอิง/เชื่อมไปยังเอกสารที่ใช้\n- การตรวจจากคน สำหรับผลลัพธ์ที่มีผลกระทบสูง (นโยบาย กฎหมาย ลูกค้าสัมพันธ์)\n- ปุ่มฟีดแบ็ก (“มีประโยชน์ / ไม่มีประโยชน์”, “แสดงความคิดเห็นว่าไม่ถูกต้อง”) เพื่อปรับปรุงพรอมต์และเนื้อหา
วางแผนคุมค่าใช้จ่ายตั้งแต่วันแรก
เครื่องมือความรู้อาจได้รับความนิยมเร็ว หลีกเลี่ยงบิลเกินคาดด้วย:\n\n- การแคชคำตอบสำหรับคำถามซ้ำ\n- การจำกัดอัตราต่อผู้ใช้/ทีม\n- กำหนดขีดจำกัดการใช้งานและทางเลือกเมื่อเกิน: “ลองใหม่ภายหลัง” หรือ “ผลการค้นหาเท่านั้น”
ด้วยเกราะเหล่านี้ คุณจะได้เครื่องมือที่ผู้คนพึ่งพาได้—โดยไม่อ้างว่า AI ถูกต้องเสมอไป
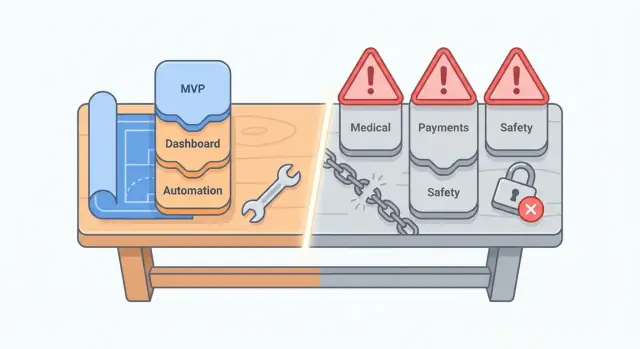
หลีกเลี่ยง: ระบบที่เกี่ยวกับความปลอดภัยหรือชีวิต
ลดต้นทุนการสร้าง
สร้างเนื้อหาเกี่ยวกับ Koder.ai หรือเชิญเพื่อนร่วมทีมแล้วรับเครดิตการใช้งาน
เครื่องมือ AI เร่งการสร้างบอยเลอร์เพลตได้ แต่ไม่เหมาะกับซอฟต์แวร์ที่ความผิดพลาดเพียงเล็กน้อยอาจทำให้เกิดอันตราย ในงานความปลอดภัย-หรือชีวิต “แทบจะถูกต้อง” ไม่พอ กรณีขอบ เวลาที่สำคัญ หรือความเข้าใจผิดในความต้องการอาจกลายเป็นการบาดเจ็บจริง
ทำไมหมวดนี้เสี่ยงเป็นพิเศษ
ระบบที่เกี่ยวกับความปลอดภัยหรือชีวิตอยู่ภายใต้มาตรฐานเข้มงวด เอกสารประกอบละเอียด และความรับผิดทางกฎหมาย แม้โค้ดที่สร้างดูสะอาด คุณยังต้องพิสูจน์ว่ามันทำงานถูกต้องในทุกสภาวะที่เกี่ยวข้อง รวมถึงเมื่อเกิดความล้มเหลว ผลผลิตจาก AI อาจซ่อนสมมติฐาน (หน่วย ค่าจำกัด การจัดการข้อผิดพลาด) ที่ง่ายต่อการพลาดเมื่อทบทวน
ตัวอย่างที่ควรหลีกเลี่ยง
ตัวอย่าง “น่าสน” ที่มีความเสี่ยงสูง:\n\n- เครื่องมือให้คำแนะนำทางการแพทย์ที่ตีความอาการ แนะนำการรักษา หรือให้แนวทางคลินิก\n- ตัวคำนวณปริมาณยาที่อาจอันตรายจากการปัดเศษหรือการแปลงหน่วย (ยา อินซูลิน ขนาดเด็ก)\n- การควบคุมความปลอดภัยอุตสาหกรรม (ลอจิกหยุดฉุกเฉิน อินเตอร์ล็อก เตือนความดัน/อุณหภูมิ)\n- ทุกอย่างที่ตัดสินจัดลำดับผู้ป่วยหรือการให้ความสำคัญโดยอัตโนมัติโดยไม่มีการควบคุมเข้มงวด
ถ้าจะลงมือจริง ๆ
หากผลิตภัณฑ์ของคุณจำเป็นต้องแตะเวิร์กโฟลว์ที่เกี่ยวกับความปลอดภัย ให้ถือว่า AI เป็นผู้ช่วย ไม่ใช่ผู้เขียนหลัก ข้อคาดหวังขั้นต่ำมักรวมถึง:\n\n- ผู้เชี่ยวชาญด้านโดเมนอยู่ในทีม (คลินิก ความปลอดภัยอุตสาหกรรม ปัจจัยมนุษย์)\n- ข้อกำหนดอย่างเป็นทางการ การติดตามการทดสอบ และการยืนยัน/ตรวจสอบอิสระ\n- การตรวจความปลอดภัย วิศวกรรมความน่าเชื่อถือ และเอกสารที่พร้อมตรวจสอบ\n- พฤติกรรม fail-safe แบบอนุรักษ์นิยม และทางเลี้ยงมนุษย์ชัดเจน
ถ้าคุณยังไม่พร้อมสำหรับความเข้มงวดระดับนั้น คุณกำลังก่อความเสี่ยงมากกว่าค่า
ทางเลือกที่ปลอดภัยกว่าแต่ยังช่วยได้
คุณยังสร้างผลิตภัณฑ์ที่มีความหมายรอบ ๆ โดเมนเหล่านี้โดยไม่ตัดสินใจชีวิตได้ เช่น:\n\n- แอปการศึกษาและการฝึกฝน (คำอธิบาย การฝึกสถานการณ์) ที่ชัดเจนว่าไม่ใช่บริการทางการแพทย์\n- ผู้ช่วยเอกสารที่สรุปขั้นตอนหรือบันทึกการบำรุงรักษาให้ผู้เชี่ยวชาญตรวจทาน\n- เครื่องมือรับข้อมูลเบื้องต้นที่ส่งต่อให้คนตรวจ—ไม่มีคำแนะนำ ไม่มีการให้คะแนนที่บอกความเร่งด่วน
ถ้าคุณไม่แน่ใจว่าขอบเขตอยู่ตรงไหน ให้ใช้เช็คลิสต์การตัดสินใจใน /blog/a-practical-decision-checklist-before-you-start-building และโน้มไปทางความช่วยเหลือที่เรียบง่าย ตรวจสอบได้ มากกว่าการออโตเมชัน
หลีกเลี่ยง: งานการเงินที่ถูกควบคุมและเวิร์กโฟลว์ที่ต้องปฏิบัติตามข้อกำหนดสูง
การสร้างในพื้นที่การเงินที่ถูกควบคุมคือที่ที่การใช้ AI อาจทำร้ายคุณอย่างเงียบ ๆ: แอปอาจ “ทำงานได้” แต่ล้มเหลวตามข้อกำหนดที่คุณไม่รู้ว่ามี ค่าเสียหายจากความผิดพลาดสูง—chargebacks ปรับ บัญชีถูกระงับ หรือความรับผิดทางกฎหมาย
งานที่ตกอยู่ในหมวดนี้
งานเหล่านี้มักดูเหมือน “ฟอร์มกับฐานข้อมูลธรรมดา” แต่มีข้อกำหนดเข้มงวดเกี่ยวกับตัวตน การตรวจสอบ และการจัดการข้อมูล:\n\n- โฟลว์การชำระเงิน (การจับบัตร คืนเงิน ข้อพิพาท)\n- การเปิดบัญชี KYC/AML และการตรวจสอบต่อเนื่อง\n- การยื่นภาษีและรายงาน\n- การคำนวณเงินเดือน รายงานสลิป และการโอนเงิน
ทำไมโค้ดจาก AI เสี่ยง
เครื่องมือ AI อาจผลิตการใช้งานที่ดูสมเหตุสมผลแต่พลาดควบคุมที่ผู้ควบคุมและผู้ตรวจสอบคาดหวัง โหมดความล้มเหลวทั่วไปได้แก่:\n\n- ความล้มเหลวด้านการปฏิบัติตามที่ละเอียด: ข้อความยินยอมไม่ครบ บันทึก audit ไม่สมบูรณ์ หรือตรรกะการรายงานผิด\n- ช่องโหว่ความปลอดภัย: การจัดการโทเค็นไม่ปลอดภัย สิทธิ์อ่อน หรือละเมิดข้อมูลใน logs\n- การเก็บลบข้อมูลผิด: เก็บเอกสารยาวเกินกว่าที่กฎหมายอนุญาต หรือลบไม่เป็นหลักฐาน\n- กฎผู้ให้บริการและเขตอำนาจ: ข้อกำหนดต่างกันตามประเทศ ผู้ให้บริการ และ merchant category
ปัญหาเหล่านี้มักไม่โผล่ในการทดสอบปกติ แต่จะเจอในการตรวจสอบ เหตุการณ์ หรือการรีวิวจากพันธมิตร
ถ้าต้องสร้างจริง ๆ
บางครั้งฟังก์ชันการเงินหลีกเลี่ยงไม่ได้ ในกรณีนั้น ลดพื้นที่ของโค้ดที่ทำเอง:\n\n- เลือก ผู้ให้บริการที่ได้รับการรับรอง สำหรับการชำระเงิน การยืนยันตัวตน ภาษี และเงินเดือน แล้วเชื่อมผ่าน API ที่สนับสนุน\n- เก็บตรรกะที่เขียนเองไว้แค่ การออร์เคสตรา (routing, UI, การจัดการสเตต) ไม่ใช่การตัดสินใจด้าน compliance หลัก\n- ปฏิบัติต่อเอาต์พุตจาก AI เป็นฉบับร่าง: ต้องมี การตรวจจากมืออาชีพ, การทำ threat modeling ชัดเจน และหลักฐานการทดสอบที่บันทึก (รวมเทสต์เชิงลบและการตรวจสอบ audit logging)
ถ้าค่าของผลิตภัณฑ์ของคุณขึ้นกับตรรกะการเงินใหม่หรือการตีความกฎ ให้พิจารณาหน่วงการใช้งาน AI จนกว่าจะมีความเชี่ยวชาญด้านโดเมนและแผนการยืนยัน
หลีกเลี่ยง: ส่วนที่สำคัญด้านความปลอดภัยและการเข้ารหัส
รักษาการเป็นเจ้าของเต็มรูปแบบ
เมื่อโปรโตไทป์โตขึ้น ส่งออกซอร์สโค้ดและพัฒนาต่อในแบบของคุณ
โค้ดที่ไวต่อความปลอดภัยเป็นพื้นที่ที่ AI อาจทำให้คุณเสียหายมากที่สุด—ไม่ใช่เพราะมันเขียนโค้ดไม่ได้ แต่เพราะมักพลาดส่วนที่ไม่งามแต่สำคัญ: การ harden กรณีขอบ การทำ threat modeling และค่าเริ่มต้นการปฏิบัติการที่ปลอดภัย
การใช้งานที่สร้างอาจดูถูกต้องในเทสต์เส้นทางสมหวังแต่พังเมื่อตกเป็นเป้าภัย (ความต่างเรื่องเวลา การโจมตี replay ความสุ่มไม่เพียงพอ การ deserialize ที่ไม่ปลอดภัย ข้อบกพร่อง confused-deputy) ปัญหาเหล่านี้มักมองไม่เห็นจนกว่าคุณจะมีผู้โจมตีจริง
อะไรที่ไม่ควรเขียนเองด้วย AI
หลีกเลี่ยงใช้ AI เป็นแหล่งข้อมูลหลักในการสร้างหรือปรับปรุง:\n\n- ปริมิทีฟและโปรโตคอลการเข้ารหัส (โหมดการเข้ารหัส, schemes ลายเซ็น, การแลกคีย์, การเซ็น/ตรวจสอบ JWT แบบ custom)\n- พื้นฐานการพิสูจน์ตัวตนและสิทธิ์ (การตรวจโทเค็น เซสชัน การจัดการ multi-tenant)\n- เอเจนต์ความปลอดภัยและการบังคับใช้เครือข่าย (ไคลเอนต์ VPN, เอเจนต์ endpoint, packet filters)\n- การจัดการคีย์ (ลอจิกการหมุนคีย์ การจัดเก็บปลอดภัย รูปแบบ KMS แบบ custom)
แม้การเปลี่ยนเล็กน้อยก็อาจทำลายสมมติฐานความปลอดภัย เช่น:\n\n- เปลี่ยนโหมดการเข้ารหัส พลาดการจัดการ nonce หรือ “ปรับให้เร็วขึ้น” แล้วทำให้ความลับรั่ว\n- แยก JWT ผิดหรือข้ามการตรวจ audience/issuer แล้วกลายเป็นการยึดบัญชีได้ทันที
เลือกผู้ให้บริการและไลบรารีที่เชื่อถือได้แทน
ถ้าฟีเจอร์ของคุณต้องการความปลอดภัย สร้างโดยการเชื่อมกับโซลูชันที่พิสูจน์แล้ว แทนการประดิษฐ์:\n\n- เลือก ผู้ให้บริการ auth (OIDC/SAML ผ่าน vendor ที่พร้อมสำหรับองค์กร) แทนระบบล็อกอินโทเค็นแบบ custom\n- ใช้ ไลบรารีเข้ารหัสที่ดูแลอย่างดี และทำตามสูตรสำเร็จของพวกมัน อย่าขอให้ AI “implement AES-GCM” หรือ “เขียน OAuth server”\n- ยึดกับ แพทเทิร์นมาตรฐาน: โทเค็นอายุสั้น การหมุน refresh token การเพิกถอนไซด์เซิร์ฟเวอร์ และการบังคับสิทธิ์แบบรวมศูนย์
AI ยังช่วยในงานพวกนี้ได้—สร้าง glue code สำหรับการเชื่อมต่อ การตั้งค่า หรือเทสต์สตับ—แต่ถือเป็นผู้ช่วยเพิ่มประสิทธิภาพ ไม่ใช่นักออกแบบความปลอดภัย
ค่าเริ่มต้นที่ปลอดภัยที่ต้องบังคับใช้ (แม้ในแอป “เรียบง่าย”)
ความล้มเหลวด้านความปลอดภัยมักเกิดจากค่าเริ่มต้น ไม่ใช่การโจมตีหรูหรา เริ่มวางไว้ตั้งแต่วันแรก:\n\n- การจัดการความลับ: อย่าฝัง API keys; ใช้ environment variables/secret managers; หมุนคีย์เป็นประจำ\n- สิทธิ์แบบน้อยที่สุด: จำกัด IAM roles, โทเค็นที่มีขอบเขตเฉพาะ, สิทธิ์ฐานข้อมูลขั้นต่ำ\n- การบันทึกและตรวจสอบ: บันทึกเหตุการณ์ auth การตรวจสอบสิทธิ์ และการกระทำของแอดมิน (โดยไม่บันทึกรหัสลับ)\n- การดูแล dependency: ตรึงเวอร์ชัน ติดตาม advisories และหลีกเลี่ยงสคริปต์ที่คัดลอกมาโดยไม่ได้ตรวจทาน
ถ้าฟีเจอร์หลักคือ “เราจัดการ X อย่างปลอดภัย” มันควรได้รับผู้เชี่ยวชาญด้านความปลอดภัย การตรวจสอบอย่างเป็นทางการ และการยืนยันอย่างละเอียด—พื้นที่ที่โค้ดจาก AI ไม่เหมาะเป็นฐาน
เช็คลิสต์การตัดสินใจก่อนเริ่มสร้าง (ปฏิบัติจริง)
ก่อนจะขอให้เครื่องมือ AI สร้างหน้าจอ routes หรือตารางฐานข้อมูล ให้ใช้เวลา 15 นาทีตัดสินว่าผลิตภัณฑ์นี้เหมาะหรือไม่—และความหมายของ “สำเร็จ” คืออะไร หยุดสั้น ๆ นี้ช่วยประหยัดวันการทำงานซ้ำได้มาก
แบบจำลองการให้คะแนนง่าย ๆ (เร็ว ตรงไปตรงมา ใช้ได้จริง)
ให้คะแนนแต่ละหัวข้อ 1 (อ่อน) ถึง 5 (แข็ง) ถ้าคะแนนรวมต่ำกว่า ~14 พิจารณาย่อไอเดียหรือเลื่อนเวลาออกไป
- ความชัดเจน: คุณอธิบายผู้ใช้ ปัญหา และเวิร์กโฟลว์ได้ใน 5–7 ประโยคไหม? คุณรู้ “happy path” ไหม?\n- ความเสี่ยง: ผลลัพธ์แย่ที่สุดที่จะเกิดคืออะไร (เงิน ความปลอดภัย ความเป็นส่วนตัว ชื่อเสียง)? โครงการที่ความเสี่ยงต่ำได้คะแนนสูงกว่า\n- การทดสอบได้: คุณตรวจผลได้ด้วยตัวอย่าง เอาต์พุตที่คาดหวัง และเทสต์อัตโนมัติได้ไหม—โดยไม่ต้อง “เดาดู”?\n- ขอบเขต: คนหนึ่งคนทำเวอร์ชันมีประโยชน์ภายใน 1–2 สัปดาห์ได้ไหม? ถ้าไม่ได้ ให้ลดขอบเขตก่อน
เช็คลิสต์ความพร้อมก่อนสร้าง
ใช้เช็คลิสต์นี้เป็นสเปคก่อนสร้าง แม้เพียงครึ่งหน้ากระดาษก็พอ
- ความต้องการ: หน้าจอ/การกระทำหลัก บทบาทผู้ใช้ และกรณีขอบ (อินพุตไม่ถูกต้อง สถานะว่าง เวลา timeout)\n- การเข้าถึงข้อมูล: ข้อมูลอยู่ที่ไหน ใครเป็นเจ้าของ และจะพิสูจน์ตัวตนอย่างไร ถ้ายังเข้าถึงไม่ได้ ให้หยุดไว้ก่อน\n- การจัดการข้อผิดพลาด: ผู้ใช้เห็นอะไรเมื่อผิดพลาด และค่าเริ่มต้นที่ปลอดภัย (เช่น “ไม่มีการบันทึกการเปลี่ยนแปลง”)\n- การสังเกตได้: logs, metrics, และ alerts พื้นฐาน ตัดสินว่าจะติดตามอะไร (ข้อผิดพลาดต่อวัน ความหน่วง งานล้มเหลว) เพื่อให้ดีบั๊กได้ภายหลัง
กำหนดคำว่า “เสร็จ” (เพื่อไม่ให้โปรโตไทป์กลายเป็นขยะ)
โปรเจกต์ “เสร็จ” เมื่อมี:\n\n- เทสต์: อย่างน้อยเทสต์ smoke สำหรับฟลูว์หลัก และหนึ่งหรือสองกรณีขอบสำคัญ\n- เอกสาร: README สั้น ๆ ว่ารันอย่างไร คอนฟิกสำคัญ และวิธีปรับใช้\n- แผนย้อนกลับ: วิธีย้อนการปล่อยหรือปิดฟีเจอร์อย่างรวดเร็ว\n- ความรับผิดชอบ: กำหนดคนหนึ่งคนรับผิดชอบการแก้ ปรับปรุง และฟังฟีดแบ็กผู้ใช้
ถ้าคุณใช้บิลเดอร์ครบวงจรอย่าง Koder.ai ให้ระบุสิ่งเหล่านี้ชัดเจน: ใช้โหมดวางแผนเพื่อเขียนเกณฑ์การยอมรับ พึ่งสแนปช็อต/ย้อนกลับเพื่อการปล่อยที่ปลอดภัย และส่งออกซอร์สโค้ดเมื่อโปรโตไทป์จะกลายเป็นผลิตภัณฑ์ระยะยาว
ใช้เทมเพลต ขอยืมมือ หรือพักไว้?
ใช้ เทมเพลต เมื่อผลิตภัณฑ์ตรงกับรูปแบบทั่วไป (CRUD, แดชบอร์ด, เว็บฮุค) จ้างช่วย เมื่อการตัดสินเรื่องความปลอดภัย โมเดลข้อมูล หรือการสเกลมีค่าใช้จ่ายสูงหากผิดพลาด พัก เมื่อคุณนิยามความต้องการไม่ชัดเจน ยังไม่มีสิทธิ์ใช้ข้อมูลตามกฎหมาย หรืออธิบายวิธีทดสอบความถูกต้องไม่ได้