02 ก.ย. 2568·4 นาที
Protobuf vs JSON สำหรับ API: ความเร็ว ขนาด และความเข้ากันได้
เปรียบเทียบ Protobuf กับ JSON สำหรับ API: ขนาดเพย์โหลด ความเร็ว การอ่าน/ดีบัก เครื่องมือ การวิวัฒนาการสคีมา และเมื่อใดควรใช้แต่ละฟอร์แมตในผลิตภัณฑ์จริง
เปรียบเทียบ Protobuf กับ JSON สำหรับ API: ขนาดเพย์โหลด ความเร็ว การอ่าน/ดีบัก เครื่องมือ การวิวัฒนาการสคีมา และเมื่อใดควรใช้แต่ละฟอร์แมตในผลิตภัณฑ์จริง
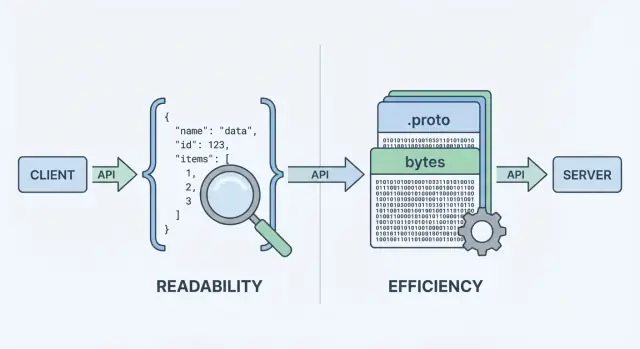
เมื่อ API ของคุณส่งหรือรับข้อมูล มันต้องมี ฟอร์แมตข้อมูล—วิธีมาตรฐานในการแทนข้อมูลในบอดี้ของคำขอและการตอบกลับ ฟอร์แมตนั้นจะถูก ซีเรียไลซ์ (แปลงเป็นไบต์) เพื่อส่งผ่านเครือข่าย และ ดีซีเรียไลซ์ กลับเป็นอ็อบเจ็กต์ที่ใช้งานได้บนไคลเอนต์และเซิร์ฟเวอร์
สองตัวเลือกที่พบบ่อยคือ JSON และ Protocol Buffers (Protobuf) ทั้งสองสามารถแทนข้อมูลธุรกิจเดียวกันได้ (ผู้ใช้ คำสั่ง เวลาที่ สายของไอเท็ม) แต่แลกเปลี่ยนกันในด้านประสิทธิภาพ ขนาดเพย์โหลด และเวิร์กโฟลว์ของนักพัฒนา
JSON (JavaScript Object Notation) เป็นฟอร์แมตข้อความที่สร้างจากโครงสร้างง่ายๆ อย่างอ็อบเจ็กต์และอาร์เรย์ มันเป็นที่นิยมสำหรับ REST APIs เพราะอ่านง่าย บันทึกได้ง่าย และตรวจด้วยเครื่องมืออย่าง curl และ DevTools ของเบราว์เซอร์ได้สะดวก
เหตุผลใหญ่ที่ JSON แพร่หลาย: ภาษาส่วนใหญ่รองรับเป็นอย่างดี และคุณสามารถมองการตอบกลับแล้วเข้าใจได้ทันที
Protobuf เป็นฟอร์แมตซีเรียไลเซชันไบนารีที่สร้างโดย Google แทนที่จะส่งข้อความ มันส่งการแทนแบบไบนารีกะทัดรัดที่กำหนดโดย สคีมา (ไฟล์ .proto) สคีมาบอกฟิลด์ ชนิดข้อมูล และแท็กตัวเลขของแต่ละฟิลด์
เพราะเป็นไบนารีและมีสคีมา Protobuf มักให้ เพย์โหลดเล็กกว่า และ แยกได้เร็วกว่าบ่อยครั้ง—ซึ่งสำคัญเมื่อมีปริมาณคำขอสูง เครือข่ายมือถือ หรือบริการที่ไวต่อความหน่วง (มักในสภาพแวดล้อม gRPC แต่ไม่จำกัดเฉพาะ gRPC)
สำคัญที่จะแยกสิ่งที่คุณส่งออกจากวิธีการเข้ารหัส "ผู้ใช้" ที่มี id, name, email สามารถจำลองได้ทั้งใน JSON และ Protobuf ความต่างคือต้นทุนที่จ่ายในด้าน:
ไม่มีคำตอบเดียวสำหรับทุกกรณี สำหรับ API สาธารณะจำนวนมาก JSON ยังคงเป็นค่าเริ่มต้นเพราะเข้าถึงง่ายและยืดหยุ่น สำหรับการสื่อสารระหว่างบริการภายใน ระบบที่ต้องการประสิทธิภาพสูง หรือสัญญาที่เข้มงวด Protobuf อาจเหมาะกว่า แนวทางของไกด์นี้คือช่วยให้คุณตัดสินใจจากข้อจำกัด ไม่ใช่อุดมคติ
เมื่อ API คืนข้อมูล มันไม่สามารถส่ง "อ็อบเจ็กต์" ตรงๆ ทางเครือข่ายได้ ต้องแปลงเป็นสตรีมของไบต์ก่อน การแปลงนี้คือ การซีเรียไลซ์—คิดว่าเป็นการ บรรจุ ข้อมูลให้อยู่ในรูปที่ส่งได้ ในฝั่งไคลเอนต์จะมีขั้นตอนกลับ (ดีซีเรียไลซ์) เพื่อ แกะ ไบต์กลับเป็นโครงสร้างข้อมูลที่ใช้งานได้
โฟลว์คำขอ/ตอบปกติมีลำดับดังนี้:
ขั้นตอน "การเข้ารหัส" นี้คือที่การเลือกรูปแบบมีผล JSON จะสร้างข้อความที่อ่านได้เช่น {\"id\":123,\"name\":\"Ava\"} ในขณะที่ Protobuf สร้างไบนารีกะทัดรัดที่คนมองไม่ออกหากไม่มีเครื่องมือ
เพราะทุกการตอบกลับต้องถูกบรรจุและแกะ ฟอร์แมตจะมีผลต่อ:
สไตล์ API ของคุณมักจะชี้นำการตัดสินใจ:
curl และง่ายต่อการบันทึก/ตรวจคุณสามารถใช้ JSON กับ gRPC (ผ่าน transcoding) หรือใช้ Protobuf ผ่าน HTTP ปกติได้ แต่ความสะดวกของสแต็ก—เฟรมเวิร์ก เกตเวย์ ไลบรารีไคลเอนต์ และนิสัยการดีบัก—มักตัดสินว่าวิธีใดง่ายที่สุดในการใช้งานประจำวัน
เมื่อคนเปรียบเทียบ protobuf vs json พวกเขามักเริ่มที่สองตัวชี้วัด: เพย์โหลดใหญ่แค่ไหนและใช้เวลานานเท่าไรในการเข้ารหัส/ถอดรหัส ข้อสรุปสั้นๆ คือ JSON เป็นข้อความที่มักอ้วนกว่า; Protobuf เป็นไบนารีที่กะทัดรัด
JSON ทำซ้ำชื่อฟิลด์และใช้การแทนตัวเลข/บูลีน/โครงสร้างเป็นข้อความ จึงมักส่งไบต์มากกว่า Protobuf แทนชื่อฟิลด์ด้วยแท็กตัวเลขและบรรจุค่ากลมกลืน ทำให้เพย์โหลดมักเล็กลง โดยเฉพาะเมื่อมีอ็อบเจ็กต์ใหญ่ ฟิลด์ซ้ำ หรือโครงสร้างซ้อนลึก
อย่างไรก็ตาม การบีบอัดสามารถลดช่องว่างได้ หากใช้ gzip หรือ brotli คีย์ที่ซ้ำของ JSON จะบีบอัดได้ดี จึงทำให้ความแตกต่างของขนาดระหว่าง JSON กับ Protobuf ในการใช้งานจริงเล็กลง Protobuf ก็สามารถบีบอัดได้เช่นกัน แต่ประโยชน์สัมพัทธ์มักน้อยกว่า
พาร์เซอร์ JSON ต้อง tokenize และ validate ข้อความ แปลงสตริงเป็นตัวเลข และจัดการ edge cases (escaping, whitespace, unicode) การดีซีเรียไลซ์ Protobuf ตรงไปตรงมามากขึ้น: อ่านแท็ก → อ่านค่าตามชนิด ในบริการหลายแห่ง Protobuf ลดเวลา CPU และการสร้าง garbage ซึ่งช่วยปรับปรุง tail latency ภายใต้โหลด
บนเครือข่ายมือถือหรือการเชื่อมต่อที่หน่วงสูง ไบต์น้อยหมายถึงการถ่ายโอนเร็วขึ้นและเวลาใช้งานวิทยุ (radio time) น้อยลง (ซึ่งช่วยเรื่องแบตเตอรี่ด้วย) แต่หากการตอบกลับของคุณเล็กอยู่แล้ว overhead ของ handshake, TLS, และการประมวลผลเซิร์ฟเวอร์อาจมีผลมากกว่า ทำให้การเลือกรูปแบบไม่โดดเด่น
วัดด้วยเพย์โหลดจริง:
นี่จะเปลี่ยนการถกเถียงเรื่อง “การซีเรียไลซ์ API” ให้กลายเป็นข้อมูลที่คุณวางใจได้สำหรับ API ของคุณ.
ด้านประสบการณ์นักพัฒนาคือจุดที่ JSON มักชนะโดยดี เรียกดูคำขอหรือการตอบ JSON ได้แทบทุกที่: DevTools, ผลลัพธ์ curl, Postman, reverse proxies, และ logs แบบข้อความ เมื่อเกิดปัญหา “เราส่งอะไรจริงๆ?” มักจะคัดลอก/วางได้ทันที
Protobuf แตกต่าง: กะทัดรัดและเข้มงวด แต่ไม่อ่านออกโดยคน หากคุณบันทึกไบนารี Protobuf ดิบ คุณจะเห็น base64 blob หรือข้อมูลอ่านไม่ออก การจะเข้าใจเพย์โหลดต้องมี .proto ที่ถูกต้องและตัวถอดรหัส (เช่น protoc, เครื่องมือเฉพาะภาษาหรือ types ที่สร้างแล้วของบริการคุณ)
กับ JSON การทำซ้ำปัญหาทำได้ง่าย: ดึงเพย์โหลดจาก logs ลบข้อมูลลับ เล่นซ้ำด้วย curl และได้กรณีทดสอบมินิมอล
กับ Protobuf คุณมักจะดีบักโดย:
ขั้นตอนเพิ่มขึ้นเล็กน้อย—แต่จัดการได้ถ้าทีมมีเวิร์กโฟลว์ที่ทำซ้ำได้
การบันทึกแบบมีโครงสร้างช่วยได้ทั้งสองฟอร์แมต บันทึก request ID, ชื่อเมธอด, ตัวระบุผู้ใช้/บัญชี และฟิลด์สำคัญแทนทั้งบอดี้
สำหรับ Protobuf โดยเฉพาะ:
.proto ใดสำหรับ JSON ให้พิจารณาบันทึก JSON canonicalized (เรียงคีย์เสถียร) เพื่อให้ง่ายต่อการ diff และไทม์ไลน์ของเหตุการณ์
API ไม่ได้แค่ย้ายข้อมูล—มันย้าย ความหมาย ความแตกต่างที่ใหญ่ที่สุดระหว่าง JSON และ Protobuf คือการกำหนดความหมายและการบังคับใช้อย่างไร
JSON โดยพื้นฐานคือ “ไม่มีสคีมา”: คุณสามารถส่งอ็อบเจ็กต์ใดก็ได้และไคลเอนต์หลายตัวจะยอมรับตราบใดที่รูปร่างดูสมเหตุสมผล
ความยืดหยุ่นนั้นสะดวกในช่วงแรก แต่ก็ซ่อนข้อผิดพลาดได้ เช่น:
userId ในการตอบหนึ่ง แต่ user_id อีกการตอบ หรือมี/ไม่มีฟิลด์ขึ้นกับเส้นทางโค้ด"42", "true", หรือ "2025-12-23"—ง่ายสร้าง แต่ก็ง่ายที่จะตีความผิดnull อาจหมายถึง "ไม่ทราบ", "ไม่ได้ตั้งค่า", หรือ "ตั้งใจว่าง" และไคลเอนต์ต่างกันอาจตีความไม่เหมือนกันคุณ สามารถ เพิ่ม JSON Schema หรือ OpenAPI แต่ JSON เองไม่ได้บังคับให้ผู้บริโภคปฏิบัติตาม
Protobuf ต้องมีสคีมากำหนดในไฟล์ .proto สคีมาคือสัญญาที่ระบุ:
สัญญานี้ช่วยป้องกันการเปลี่ยนแปลงโดยไม่ได้ตั้งใจ—เช่น เปลี่ยน integer เป็น string—เพราะโค้ดที่สร้างคาดหวังชนิดที่ชัดเจน
ด้วย Protobuf ตัวเลขยังคงเป็นตัวเลข enum ถูกจำกัดค่า และ timestamp มักโมเดลโดยใช้ well-known types แทนการใช้สตริงที่ดัดแปลงเอง “ไม่ได้ตั้งค่า” ชัดเจนขึ้น: ใน proto3 การไม่ปรากฏต่างจากค่าดีฟอลต์เมื่อคุณใช้ optional หรือ wrapper types
ถ้า API ของคุณพึ่งพาชนิดที่แน่นอนและการพาร์สที่คาดเดาได้ข้ามทีมและภาษา Protobuf ให้กราร์ดเรลที่ JSON มักต้องใช้ข้อตกลงเพื่อให้ได้
API ต้องวิวัฒน์: คุณเพิ่มฟิลด์ ปรับพฤติกรรม และยกเลิกส่วนเก่า เป้าหมายคือเปลี่ยนสัญญาโดยไม่ทำให้ผู้บริโภคประหลาดใจ
กลยุทธ์ที่ดีมักมุ่งทั้งสอง แต่ความเข้ากันได้ย้อนหลังเป็นบรรทัดฐานขั้นต่ำ
ใน Protobuf แต่ละฟิลด์มี หมายเลข (เช่น email = 3) หมายเลขนั้น—ไม่ใช่ชื่อ—คือสิ่งที่ไปบนสาย ชื่อมีไว้เพื่อคนอ่านและโค้ดที่สร้าง
เพราะแบบนั้น:
การเปลี่ยนแปลงที่ปลอดภัย (มัก):
การเปลี่ยนแปลงที่เสี่ยง (มักทำให้แตก):
แนวทางที่ดี: ใช้ reserved สำหรับหมายเลข/ชื่อเก่าและเก็บ changelog
JSON ไม่มีสคีมาบังคับ ดังนั้นความเข้ากันได้ขึ้นกับรูปแบบปฏิบัติ:
ประกาศการเลิกใช้ล่วงหน้า: ฟิลด์ไหนจะเลิกใช้ เมื่อไร และอะไรมาแทน ระบุแผนเวอร์ชันง่ายๆ (เช่น “การเปลี่ยนแปลงแบบเพิ่มเป็นไม่ทำให้แตก; การลบต้องเพิ่ม major version”) และทำตามนั้น
การเลือก JSON หรือ Protobuf มักขึ้นกับที่ API ต้องรัน—และทีมของคุณต้องการดูแลอะไร
JSON เป็นสากล: เบราว์เซอร์และ runtime แบ็กเอนด์ทุกแห่งสามารถพาร์สได้โดยไม่ต้องพึ่งพา dependency เพิ่ม ในเว็บแอป fetch() + JSON.parse() คือเส้นทางที่สะดวก และพร็อกซี เกตเวย์ และเครื่องมือสังเกตการณ์มัก "เข้าใจ" JSON โดยค่าเริ่มต้น
Protobuf ก็รันบนเบราว์เซอร์ได้เช่นกัน แต่ไม่ใช่ค่าเริ่มต้นที่ไม่มีต้นทุน คุณมักต้องเพิ่มไลบรารี Protobuf (หรือโค้ด JS/TS ที่สร้างแล้ว) จัดการขนาดบันเดิล และตัดสินใจว่าคุณจะส่ง Protobuf ผ่าน HTTP อย่างไรให้เครื่องมือเบราว์เซอร์ตรวจสอบได้
บน iOS/Android และภาษาแบ็กเอนด์ (Go, Java, Kotlin, C#, Python ฯลฯ) การสนับสนุน Protobuf เติบโตเต็มที่ ความแตกต่างใหญ่คือ Protobuf สมมติว่าคุณจะใช้ไลบรารีต่อแพลตฟอร์มและมักจะสร้างโค้ดจากไฟล์ .proto
การสร้างโค้ดให้ประโยชน์จริงๆ:
แต่มันเพิ่มต้นทุน:
.proto ร่วม, การล็อกเวอร์ชัน)Protobuf เกาะกับ gRPC อย่างใกล้ชิด ซึ่งให้เรื่องเครื่องมือครบวงจร: คำจำกัดความเซอร์วิส, สตับไคลเอนต์, สตรีมมิ่ง และ interceptors ถ้าคุณพิจารณา gRPC, Protobuf คือทางเลือกธรรมชาติ
ถ้าคุณสร้าง JSON REST แบบดั้งเดิม เครื่องมือรอบๆ JSON (DevTools เบราว์เซอร์, การดีบักด้วย curl, เกตเวย์ทั่วไป) ยังคงเรียบง่ายกว่า—โดยเฉพาะสำหรับ API สาธารณะและการรวมระบบอย่างรวดเร็ว
ถ้าคุณยังสำรวจพื้นผิว API อยู่ ช่วยให้ทำต้นแบบเร็วๆ ทั้งสองแบบก่อนจะมาตรฐาน ตัวอย่าง ทีมที่ใช้ Koder.ai มักสปิน REST API แบบ JSON เพื่อความเข้ากันได้กว้าง และบริการภายในแบบ gRPC/Protobuf เพื่อประสิทธิภาพ แล้วค่อยเบนช์มาร์กเพย์โหลดจริงก่อนเลือกเป็นค่าเริ่มต้น เพราะ Koder.ai สามารถสร้างแอปเต็มสแตก (React บนเว็บ, Go + PostgreSQL บนแบ็กเอนด์, Flutter สำหรับมือถือ) และรองรับโหมดวางแผนพร้อม snapshots/rollback จึงสะดวกในการวนลูปสัญญาโดยไม่เปลี่ยนฟอร์แมตให้เป็น refactor ครั้งใหญ่
การเลือก JSON หรือ Protobuf ไม่ได้มีแค่ขนาดเพย์โหลดหรือความเร็ว มันยังส่งผลต่อความเข้ากันได้กับเลเยอร์แคช เกตเวย์ และเครื่องมือที่ทีมใช้ระหว่างเหตุการณ์ด้วย
โครงสร้าง HTTP ส่วนใหญ่ (แคชของเบราว์เซอร์, reverse proxies, CDNs) ปรับแต่งกับ semantics ของ HTTP ไม่ใช่ฟอร์แมตบอดี้โดยเฉพาะ CDN สามารถแคชไบต์ใดก็ได้ ตราบเท่าที่การตอบกลับแคชได้
อย่างไรก็ตาม ทีมหลายทีมคาดหวัง HTTP/JSON ที่ edge เพราะตรวจสอบและแก้ไขปัญหาได้ง่าย กับ Protobuf การแคชยังทำงาน แต่คุณต้องรอบคอบเรื่อง:
Vary)Cache-Control, ETag, Last-Modified)ถ้ารองรับทั้ง JSON และ Protobuf ให้ใช้ content negotiation:
Accept: application/json หรือ Accept: application/x-protobufContent-Type ที่ตรงกันตั้ง Vary: Accept ให้ caches เข้าใจ มิฉะนั้น cache อาจเก็บ JSON แล้วส่งให้ไคลเอนต์ Protobuf (หรือกลับกัน)
API gateways, WAFs, transformers และเครื่องมือต่างๆ มักสมมติ body เป็น JSON สำหรับ:
Protobuf แบบไบนารีสามารถจำกัดฟีเจอร์เหล่านี้ถ้าเครื่องมือไม่รองรับ Protobuf หรือคุณต้องเพิ่มขั้นตอนถอดรหัส
รูปแบบที่พบบ่อยคือ JSON ที่ edge, Protobuf ข้างใน:
วิธีนี้ทำให้การรวมภายนอกเรียบง่าย ในขณะที่ยังได้ประโยชน์ด้านประสิทธิภาพของ Protobuf ในส่วนที่คุณควบคุมทั้งสองฝั่ง
การเลือก JSON หรือ Protobuf เปลี่ยนวิธีเข้ารหัสและพาร์สข้อมูล—แต่ไม่ได้แทนที่ความต้องการความปลอดภัยพื้นฐานอย่างการพิสูจน์ตัวตน การเข้ารหัส การอนุญาต และการ validate ฝั่งเซิร์ฟเวอร์ ซีเรียไลเซอร์เร็วจะไม่ช่วย API ที่รับอินพุตไม่เชื่อถือโดยไม่มีขอบเขต
อาจล่อลวงให้คิดว่า Protobuf "ปลอดภัยกว่า" เพราะเป็นไบนารีและอ่านไม่ออก อย่างไรก็ตามนั่นไม่ใช่กลยุทธ์ความปลอดภัย ผู้โจมตีไม่ต้องการให้เพย์โหลดอ่านได้ พวกเขาต้องการ endpoint ถ้า API รั่วฟิลด์ลับ หรือยอมรับสถานะที่ไม่ถูกต้อง หรือ auth อ่อนแอ การเปลี่ยนฟอร์แมตจะไม่แก้ปัญหา
ใช้การเข้ารหัสการขนส่ง (TLS), บังคับตรวจสอบสิทธิ์/การอนุญาต, validate อินพุต และบันทึกอย่างปลอดภัยไม่ว่าจะใช้ JSON REST API หรือ grpc protobuf
ทั้งสองฟอร์แมตร่วมเสี่ยงเหมือนกัน:
เพื่อให้ API เชื่อถือได้ภายใต้โหลดและการโจมตี ให้ใช้กราร์ดเรลดังนี้ทั้งสองฟอร์แมต:
สรุป: “ไบนารี vs ข้อความ” มีผลกับประสิทธิภาพและการใช้งานเชิงสภาพแวดล้อมเป็นหลัก ความปลอดภัยและความน่าเชื่อถือมาจากขอบเขตที่ชัดเจน การอัปเดตไลบรารี และการ validate ที่สม่ำเสมอ—ไม่ว่าจะใช้ serializer ใด
การเลือก JSON หรือ Protobuf ไม่ได้เกี่ยวกับอันไหน "ดีกว่า" แต่เป็นสิ่งที่ API ต้องการเพิ่มประสิทธิภาพ: ความเป็นมิตรกับมนุษย์และการเข้าถึง หรืิอ ประสิทธิภาพและสัญญาที่เข้มงวด
JSON มักเป็นค่าเริ่มต้นปลอดภัยเมื่อคุณต้องการความเข้ากันได้กว้างและการดีบักง่าย
กรณีทั่วไป:
Protobuf มักชนะเมื่อประสิทธิภาพและความสม่ำเสมอสำคัญกว่าการอ่านของมนุษย์
กรณีทั่วไป:
ใช้คำถามเหล่านี้เพื่อลดตัวเลือก:
ถ้าตัดไม่ได้ แนวทาง "JSON ที่ edge, Protobuf ข้างใน" มักเป็นการประนีประนอมที่ใช้ได้จริง
การย้ายฟอร์แมตไม่ใช่การเขียนทับทั้งหมด แต่เป็นการลดความเสี่ยงให้ผู้บริโภคใช้งานได้ระหว่างทาง การเคลื่อนไหวที่ปลอดภัยทำให้ API ใช้งานได้ตลอดการเปลี่ยนและง่ายที่จะย้อนกลับ
เลือกพื้นที่เสี่ยงต่ำ—มักเป็นการเรียกระหว่างบริการภายในหรือ endpoint อ่านอย่างเดียว นี่ช่วยให้ตรวจสคีมา Protobuf, ไคลเอนต์ที่สร้าง และการเปลี่ยนแปลงการสังเกตการณ์โดยไม่ต้องทำ big bang
ก้าวแรกปฏิบัติคือเพิ่มตัวแทนแบบ Protobuf สำหรับ resource ที่มีอยู่ ในขณะที่ยังคงรูปร่าง JSON เดิมไว้ คุณจะได้เรียนรู้เร็วว่าที่ไหนโมเดลข้อมูลคลุมเครือ (null vs missing, number vs string, รูปแบบวันที่) และแก้ไขในสคีมา
สำหรับ API ภายนอก การรองรับคู่ขนานมักเป็นเส้นทางที่ราบรื่นสุด:
Content-Type และ Accept เฮดเดอร์/v2/...) ถ้าเครื่องมือทำ negotiation ยากช่วงนี้ให้แน่ใจว่าทั้งสองฟอร์แมตผลิตมาจาก source-of-truth เดียวกันเพื่อหลีกเลี่ยงการ drift เล็กๆ น้อยๆ
วางแผนสำหรับ:
เผยแพร่ไฟล์ .proto, คอมเมนต์ของฟิลด์, และตัวอย่างคำขอ/การตอบ (ทั้ง JSON และ Protobuf) เพื่อให้ผู้บริโภคตรวจสอบว่าตีความข้อมูลถูกต้อง คู่มือย้ายสั้นๆ และ changelog ลดภาระซัพพอร์ตและเร่งการยอมรับ
การเลือก JSON หรือ Protobuf มักขึ้นกับความเป็นจริงของทราฟฟิก ไคลเอนต์ และข้อจำกัดการปฏิบัติการ เส้นทางที่เชื่อถือได้ที่สุดคือวัด เอกสารการตัดสินใจ และทำให้การเปลี่ยนแปลง API น่าเบื่อ
รันการทดลองเล็กๆ บน endpoints ตัวแทน
ติดตาม:
ทำในสเตจจิ้งด้วยข้อมูลที่คล้ายการผลิต แล้วตรวจสอบในการผลิตบนส่วนน้อยของทราฟฟิก
ไม่ว่าจะใช้ JSON Schema/OpenAPI หรือไฟล์ .proto:
แม้จะเลือก Protobuf เพื่อประสิทธิภาพ ให้เอกสารเป็นมิตร:
ถ้าคุณดูแล docs หรือ SDK ให้ชี้ชัด (เช่น /docs และ /blog). ถ้าการกำหนดราคา/ขีดจำกัดมีผลต่อการเลือกฟอร์แมต ให้แสดงให้ชัด (เช่น /pricing).
JSON เป็นฟอร์แมตข้อความที่อ่านง่าย จัดเก็บใน logs ได้สะดวก และทดสอบด้วยเครื่องมือทั่วไปได้ง่าย ส่วน Protobuf เป็นฟอร์แมตไบนารีกะทัดรัดที่กำหนดโดยสคีมา .proto มักให้เพย์โหลดเล็กกว่าและการแยกวัตถุเร็วขึ้น
เลือกตามเงื่อนไข: การเข้าถึงและการดีบัก (JSON) เทียบกับประสิทธิภาพและสัญญาที่เข้มงวด (Protobuf).
API ส่งไบต์ ไม่ใช่วัตถุในหน่วยความจำโดยตรง Serialization เข้ารหัสวัตถุของเซิร์ฟเวอร์เป็นเพย์โหลด (ข้อความ JSON หรือไบนารี Protobuf) เพื่อส่ง; Deserialization ถอดรหัสไบต์กลับเป็นวัตถุบนไคลเอนต์/เซิร์ฟเวอร์
การเลือกรูปแบบมีผลต่อแบนด์วิดท์ ความหน่วง และ CPU ที่ใช้ในการเข้ารหัส/ถอดรหัส.
มักจะใช่ โดยเฉพาะกับอ็อบเจ็กต์ขนาดใหญ่หรือลึกที่มีฟิลด์ซ้ำ เพราะ Protobuf ใช้แท็กตัวเลขและการเข้ารหัสไบนารีที่มีประสิทธิภาพ
อย่างไรก็ตาม ถ้าคุณเปิดใช้ gzip/brotli คีย์ที่ซ้ำของ JSON จะถูกบีบอัดได้ดี ทำให้ช่องว่างขนาดในโลกจริงอาจเล็กลง ควรวัดทั้งขนาด raw และ compressed.
เป็นไปได้ ในหลายกรณี JSON ต้อง tokenize ข้อความ จัดการ escape/unicode และแปลงสตริงเป็นตัวเลข ส่วนการถอดรหัส Protobuf ทำแบบตรงไปตรงมา (อ่านแท็ก → อ่านค่าตามชนิด) ซึ่งมักลดเวลา CPU และการสร้าง garbage
แต่ถ้าเพย์โหลดเล็กมาก ความหน่วงโดยรวมอาจถูกครอบงำด้วย TLS, RTT เครือข่าย หรือการประมวลผลแอปพลิเคชัน แทนที่จะเป็นการซีเรียไลซ์/ดีซีเรียไลซ์.
โดยค่าเริ่มต้นจะยากกว่า JSON. JSON อ่านได้โดยคนและตรวจดูได้ใน DevTools, logs, curl และ Postman. เพย์โหลด Protobuf เป็นไบนารี จึงมักต้องมีสคีมา .proto ที่ตรงกันและเครื่องมือถอดรหัส
แนวทางปฏิบัติที่ดีคือบันทึกมุมมอง debug ที่ถอดรหัสแล้วและลบข้อมูลลับ (มักในรูป JSON) เคียงข้างกับไบต์ดิบและ request ID.
JSON โดยปริยายไม่มีสคีมา: คุณส่งวัตถุใดก็ได้และหลายไคลเอนต์จะยอมรับตราบใดที่โครงดูสมเหตุสมผล นั่นสะดวกแต่ซ่อนข้อผิดพลาด เช่น
userId vs user_idnull คลุมเครือคุณสามารถเพิ่ม JSON Schema หรือ OpenAPI แต่ JSON เองไม่บังคับให้ปฏิบัติตามสคีมา
ใน Protobuf แต่ละฟิลด์มี หมายเลข (เช่น email = 3) หมายเลขนี้—not ชื่อฟิลด์—คือสิ่งที่ไปบนสาย ทำให้การเปลี่ยนแปลงบางอย่างปลอดภัยหรือต้องระวัง
การเปลี่ยนแปลงที่ปลอดภัยมักรวมถึงการเพิ่มฟิลด์ optional ด้วยหมายเลขใหม่ และการเก็บ reserved สำหรับหมายเลข/ชื่อตัวเก่าที่เลิกใช้ การเปลี่ยนหมายเลขหรือรีไซเคิลหมายเลขมักทำให้แตก
ได้ ใช้การต่อรองเนื้อหา (content negotiation):
Accept: application/json หรือ Accept: application/x-protobufContent-Type ที่ตรงกันVary: Accept เพื่อให้ caches ไม่ผสมฟอร์แมตถ้าเครื่องมือทำ negotiation ยาก อาจเปิด endpoint แยก (เช่น ) เป็นทางเลือกชั่วคราว
ขึ้นกับสภาพแวดล้อมของคุณ:
คำนึงถึงต้นทุนการดูแล codegen และการเวอร์ชันสคีมาร่วมด้วยเมื่อเลือก Protobuf.
อย่าถือว่าการเลือก Protobuf เป็นชั้นความปลอดภัย มันอาจทำให้ payload อ่านไม่ออกสำหรับคน แต่ไม่ได้ป้องกันการโจมตี
แนวปฏิบัติที่ควรใช้ทั้งคู่:
/v2/...