21 พ.ค. 2568·1 นาที
สร้างเว็บแอปสำหรับรายงาน SLA แบบรวมศูนย์สำหรับลูกค้าหลายราย
เรียนรู้วิธีวางแผน สร้าง และเปิดตัวเว็บแอปสำหรับลูกค้าหลายรายที่เก็บข้อมูล SLA ทำให้เมตริกเป็นมาตรฐาน และส่งมอบแดชบอร์ด การแจ้งเตือน และรายงานที่ส่งออกได้
เรียนรู้วิธีวางแผน สร้าง และเปิดตัวเว็บแอปสำหรับลูกค้าหลายรายที่เก็บข้อมูล SLA ทำให้เมตริกเป็นมาตรฐาน และส่งมอบแดชบอร์ด การแจ้งเตือน และรายงานที่ส่งออกได้
การรายงาน SLA แบบรวมศูนย์เกิดขึ้นเพราะหลักฐาน SLA มักไม่อยู่ที่เดียวกัน ความพร้อมใช้งานอาจอยู่ในเครื่องมือตรวจสอบ เหตุการณ์ในเพจสถานะ ตั๋วใน helpdesk และบันทึกการส่งเรื่องในอีเมลหรือแชท เมื่อแต่ละลูกค้ามีสแต็กที่ต่างกันเล็กน้อย (หรือการตั้งชื่อนามธรรมต่างกัน) การทำรายงานรายเดือนจะกลายเป็นงานสเปรดชีตด้วยมือ—และความขัดแย้งว่า “สิ่งที่เกิดขึ้นจริงคืออะไร” จะเกิดบ่อย
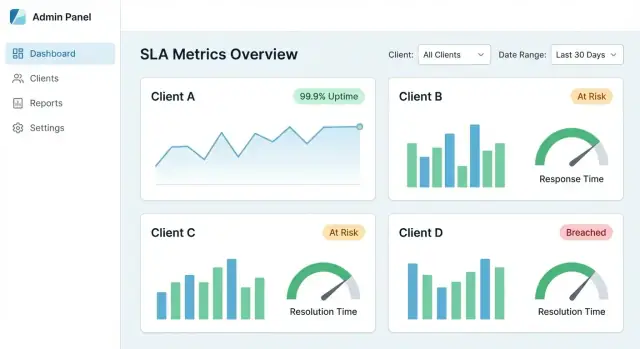
แอปรายงาน SLA ที่ดีให้บริการผู้ชมหลายกลุ่มที่มีเป้าหมายต่างกัน:
แอปควรนำเสนอความจริงพื้นฐานเดียวกันที่ระดับรายละเอียดต่างกัน ขึ้นกับบทบาทของผู้ใช้
แดชบอร์ด SLA แบบรวมศูนย์ควรมอบ:
ในทางปฏิบัติ ตัวเลข SLA ทุกตัวควรตรวจสอบย้อนกลับได้ถึงเหตุการณ์ดิบ (alerts, tickets, ไทม์ไลน์ของ incident) พร้อม timestamps และผู้รับผิดชอบ
ก่อนสร้างใดๆ ให้กำหนดว่าอะไร อยู่ในขอบเขต และอะไร อยู่นอกขอบเขต ตัวอย่าง:
ขอบเขตที่ชัดเจนช่วยป้องกันการถกเถียงในภายหลังและทำให้การรายงานสอดคล้องข้ามลูกค้า
อย่างน้อยที่สุด ควรรองรับห้าวิธีการทำงาน:
ออกแบบรอบๆ เวิร์กโฟลว์เหล่านี้ตั้งแต่วันแรก แล้วส่วนอื่นของระบบ (โมเดลข้อมูล การผสานระบบ และ UX) จะสอดคล้องกับความต้องการรายงานจริง
ก่อนสร้างหน้าจอหรือพายป์ไลน์ ตัดสินใจก่อนว่าแอปจะวัดอะไรและตัวเลขเหล่านั้นตีความอย่างไร เป้าหมายคือความสม่ำเสมอ: สองคนอ่านรายงานเดียวกันควรได้ข้อสรุปเดียวกัน
เริ่มจากชุดเล็กที่ลูกค้าส่วนใหญ่รู้จัก:
ระบุชัดเจนว่าแต่ละเมตริกวัดอะไรและอะไรที่ ไม่รวม แผงคำนิยามสั้นๆ ใน UI (และลิงก์ไปยัง /help/sla-definitions) ช่วยป้องกันความเข้าใจผิดในภายหลัง
กฎคือจุดที่การรายงาน SLA มักพัง เอกสารเป็นประโยคที่ลูกค้าสามารถตรวจสอบได้ จากนั้นแปลงเป็นตรรกะในระบบ
ครอบคลุมสิ่งจำเป็น:
เลือกช่วงปกติ (รายเดือนและรายไตรมาสเป็นเรื่องปกติ) และว่าจะรองรับ ช่วงกำหนดเอง หรือไม่ ระบุเขตเวลาที่ใช้สำหรับการตัดคะแนนให้ชัดเจน
สำหรับการละเมิด ให้กำหนด:
สำหรับแต่ละเมตริก ให้ระบุอินพุตที่ต้องการ (เหตุการณ์จากการมอนิเตอร์, บันทึก incident, ไทม์สแตมป์ของตั๋ว, หน้าต่างการบำรุงรักษา) นี่คือพิมพ์เขียวสำหรับการผสานระบบและการตรวจสอบคุณภาพข้อมูล
ก่อนออกแบบแดชบอร์ดหรือ KPI ให้ชัดว่าเหตุผลที่เป็นหลักฐาน SLA อยู่ที่ไหน ทีมมักค้นพบว่า “ข้อมูล SLA” ถูกแยกอยู่ในเครื่องมือต่างๆ เป็นเจ้าของโดยกลุ่มต่างๆ และบันทึกด้วยความหมายที่ต่างกันเล็กน้อย
เริ่มด้วยรายการง่ายๆ ต่อแต่ละลูกค้า (และต่อบริการ):
สำหรับแต่ละระบบ ให้จดผู้รับผิดชอบ ระยะเวลาการเก็บข้อมูล ขีดจำกัด API ความละเอียดเวลา (วินาที vs นาที) และข้อมูลนั้นเป็นสเกลลูกค้าหรือแชร์ร่วมกันหรือไม่
แอปรายงาน SLA ส่วนใหญ่ใช้การผสม:
กฎปฏิบัติ: ใช้ webhooks เมื่อความสดใหม่สำคัญ และ API pulls เมื่อความครบถ้วนสำคัญ
เครื่องมือต่างกันอธิบายเหตุการณ์เดียวกันแตกต่างกัน Normalize เป็นชุดเหตุการณ์เล็กๆ ที่แอปพึ่งพาได้ เช่น:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedใส่ฟิลด์ที่สอดคล้องกัน: client_id, service_id, source_system, external_id, severity, และ timestamps
เก็บ timestamps ทั้งหมดเป็น UTC แล้วแปลงเมื่อแสดงตามโซนเวลาที่ลูกค้าเลือก (โดยเฉพาะสำหรับการตัดช่วงรายเดือน)
วางแผนสำหรับช่องว่างด้วย: บางลูกค้าอาจไม่มี status pages บางบริการอาจไม่ได้มอนิเตอร์ 24/7 และบางเครื่องมืออาจสูญเสียเหตุการณ์ ให้แสดง “การครอบคลุมบางส่วน” ในรายงาน (เช่น “ไม่มีข้อมูลมอนิเตอร์เป็นเวลา 3 ชั่วโมง”) เพื่อไม่ให้ผล SLA ทำให้เข้าใจผิด
ถ้าแอปรายงาน SLA ให้ลูกค้าหลายราย การตัดสินใจด้านสถาปัตยกรรมจะกำหนดว่าคุณสามารถปรับขนาดได้อย่างปลอดภัยโดยไม่รั่วไหลข้อมูลข้ามลูกค้าหรือไม่
เริ่มโดยการตั้งชื่อชั้นต่างๆ ที่ต้องรองรับ “ลูกค้า” อาจหมายถึง:
จดสิ่งเหล่านี้ตั้งแต่ต้น เพราะมันมีผลกับ permissions, filters, และวิธีเก็บการตั้งค่า
แอปรายงาน SLA ส่วนใหญ่เลือกหนึ่งในสองแบบ:
tenant_id. ประหยัดและง่ายต่อการปฏิบัติ แต่ต้องมีวินัยในการเขียน queryแนวกลางที่พบบ่อยคือ DB ร่วมสำหรับ tenant ส่วนใหญ่ และ DB เฉพาะสำหรับลูกค้าองค์กรระดับ enterprise
การแยกต้องครอบคลุม:
tenant_id เพื่อไม่ให้เขียนผลไปยัง tenant ผิดใช้ guardrails เช่น row-level security, mandatory query scopes, และ automated tests สำหรับขอบเขต tenant
ลูกค้าต่างกันจะมีเป้าหมายและคำนิยามต่างกัน วางแผนสำหรับการตั้งค่าต่อ tenant เช่น:
ผู้ใช้ภายในมักต้อง “แอบเป็นลูกค้า” ให้มีการสลับที่ตั้งใจ (ไม่ใช่ฟิลเตอร์เสรี) แสดง tenant ที่ใช้งานเด่นชัด บันทึกการสลับเพื่อการตรวจสอบ และป้องกันลิงก์ที่ข้ามการตรวจสอบ tenant
Centralized SLA reporting ควรสร้าง แหล่งข้อมูลเดียวที่เชื่อถือได้ โดยดึงข้อมูล uptime, incidents และไทม์ไลน์ของตั๋วมารวมกันในมุมมองเดียวที่ตรวจสอบได้
ในทางปฏิบัติ ควร:\n\n- ลดเวลาการทำรายงานประจำจากวันเหลือเป็นนาที\n- ทำให้ทุกตัวเลขสามารถตรวจสอบย้อนกลับไปยังเหตุการณ์ดิบได้\n- ป้องกันข้อพิพาทโดยแสดงกฎการคำนวณและเหตุการณ์ที่รวม/ยกเว้น
เริ่มจากชุดเมตริกเล็กๆ ที่ลูกค้าส่วนใหญ่คุ้นเคย แล้วขยายเมื่อคุณสามารถอธิบายและตรวจสอบได้
เมตริกเริ่มต้นที่พบได้บ่อย:\n\n- Availability/uptime (ต่อบริการ ต่อช่วงเวลา)\n- Time to first response (การตอบกลับจากคนจริงหรืออัพเดตที่มีความหมายครั้งแรก)\n- Time to resolution (ยืนยันว่าแก้ไขแล้ว)\n\nสำหรับแต่ละเมตริก ให้ระบุชัดว่าอะไรที่วัด และอะไรที่ถูกยกเว้น รวมถึงแหล่งข้อมูลที่ต้องใช้
เขียนกฎเป็นภาษาธรรมดาก่อน แล้วแปลงเป็นตรรกะในระบบ
โดยทั่วไปต้องกำหนด:\n\n- ปฏิทินเวลาทำการ vs 24/7 (แยกตาม client/service)\n- ปฏิทินวันหยุดและผู้รับผิดชอบ\n- การยกเว้น (maintenance, waiting-on-customer, third-party)\n- เวลาที่เริ่ม/หยุด (เหตุการณ์ใดเริ่มนาฬิกา เหตุการณ์ใดหยุดมัน)
ถ้าสองคนไม่เห็นด้วยกับเวอร์ชันภาษาที่เข้าใจได้ โค้ดก็จะถูกตั้งคำถามทีหลัง
เก็บ timestamps ทั้งหมดเป็น UTC แล้วแปลงเมื่อแสดงตามเขตเวลาที่ลูกค้าต้องการสำหรับการตัดช่วงรายงาน
นอกจากนี้ ให้ตัดสินใจก่อนว่า:\n\n- เขตเวลาใดเป็นตัวกำหนดการตัด (เช่น สิ้นเดือน)\n- จะจัดการกับการเปลี่ยน DST ยังไง\n- จะใช้เขตเวลาในสัญญาหรือเขตเวลาของผู้มีส่วนได้ส่วนเสียหรือไม่
แสดงให้ชัดใน UI (เช่น “การตัดช่วงรายงานอยู่ใน America/New_York”)
ใช้การผสมวิธีการเชื่อมต่อขึ้นกับความต้องการเรื่องความสดใหม่และความสมบูรณ์ของข้อมูล:\n\n- Webhooks / event streams สำหรับการอัพเดตแบบเกือบเรียลไทม์และการตรวจจับ breach เร็วขึ้น\n- API pulls สำหรับการเติมข้อมูลย้อนหลังและการประสานข้อมูล\n- CSV imports สำหรับลูกค้ารายเล็กหรือเครื่องมือเก่า
กฎปฏิบัติ: ใช้ webhooks เมื่อความสดสำคัญ, ใช้ API pulls เมื่อความครบถ้วนสำคัญ
กำหนดชุดเหตุการณ์ canonical เล็กๆ เพื่อให้เครื่องมือต่างๆ แมปไปยังแนวคิดเดียวกันได้
ตัวอย่าง:\n\n- / \n- / \n- / / \n\nรวมฟิลด์สำคัญอย่าง , , , , และ timestamps เป็น UTC
เลือกโมเดล multi-tenancy แล้วบังคับการแยกข้อมูลให้เป็นจริง ไม่ใช่แค่ UI
การป้องกันสำคัญๆ:\n\n- กำหนดขอบเขตทุกคำสั่งค้นหา, export, และงานตามเวลาด้วย tenant_id\n- ใช้ guardrails อย่าง row-level security หรือ mandatory query scopes\n- บันทึกและตรวจสอบการสลับ tenant ของผู้ใช้งานภายใน
คาดหวังว่าการส่งออกและงานแบ็กกราวด์เป็นจุดที่ข้อมูลรั่วไหลได้ง่ายที่สุดถ้าไม่ออกแบบให้มีบริบท tenant
เก็บทั้ง raw events และ derived results เพื่อให้เร็วและตรวจสอบได้
การแบ่งเชิงปฏิบัติ:\n\n- เหตุการณ์ดิบแบบ immutable (พร้อม IDs ต้นทางและ snapshot payload)\n- ข้อเท็จจริงที่ถูกปรับเป็นมาตรฐานที่แอปใช้\n- ผลลัพธ์ SLA ที่คำนวณได้ (ต่อ incident/วัน/เดือน)\n- rollups ที่พรี-แอ็กรีเกตไว้สำหรับแดชบอร์ดและการส่งออก
เพิ่ม calculation_version เพื่อให้สามารถสร้างรายงานเก่าได้แบบเป๊ะหลังจากกฎเปลี่ยน
ทำให้ pipeline มีขั้นตอนชัดเจนและ idempotent:\n\n- ดึงเหตุการณ์ดิบเข้ามาโดยไม่เปลี่ยนแปลง\n- ทำ normalization ไปสู่รูปแบบ canonical\n- roll up เป็นผลรายวัน/รายเดือนที่แคชไว้
เพื่อความน่าเชื่อถือ:\n\n- ลดความซ้ำด้วย source event IDs หรือ hashed keys\n- สามารถ rebuild rollups สำหรับช่วงเวลาหนึ่งได้ (เช่น “recompute last 14 days”)\n- กักข้อมูลที่น่าสงสัย (timestamps หาย ระยะเวลาเป็นลบ) แทนการทิ้งเงียบ
เริ่มด้วยการแจ้งเตือนสามประเภทเพื่อให้ระบบเป็นส่วนปฏิบัติได้ ไม่ใช่แค่แดชบอร์ด:\n\n- Impending breach (คำเตือนจาก burn-rate หรือเหลือ budget ต่ำ)\n- Confirmed breach (ช่วงเวลาถูกยืนยันแล้วว่าไม่ผ่าน)\n- Data pipeline failure (ข้อมูลล้าหรือขาดหาย)
ลดเสียงรบกวนด้วยการ deduplication, quiet hours และ escalation และทำให้แต่ละการแจ้งเตือนปฏิบัติได้ด้วยการยืนยันรับและบันทึกหมายเหตุการแก้ไข
incident_openedincident_closeddowntime_starteddowntime_endedticket_createdfirst_responseresolvedtenant_idservice_idsource_systemexternal_idseverity