05 ต.ค. 2568·4 นาที
RabbitMQ สำหรับแอปของคุณ: รูปแบบ การตั้งค่า และการปฏิบัติการ
เรียนรู้การใช้ RabbitMQ ในแอปของคุณ: แนวคิดหลัก รูปแบบที่ใช้บ่อย เคล็ดลับความน่าเชื่อถือ การสเกล ความปลอดภัย และการมอนิเตอร์สำหรับการใช้งานจริง
ทำไม RabbitMQ ถึงสำคัญสำหรับทีมแอปพลิเคชัน
RabbitMQ คือ message broker: มันอยู่ตรงกลางระหว่างส่วนต่างๆ ของระบบและเคลื่อนย้าย “งาน” (ข้อความ) จากผู้ผลิตไปยังผู้บริโภคอย่างน่าเชื่อถือ ทีมแอปมักเลือกใช้เมื่อการเรียกตรงแบบซิงโครนัส (service-to-service HTTP, ฐานข้อมูลร่วมกัน, cron job) เริ่มสร้างการพึ่งพาที่เปราะบาง ภาระการทำงานที่ไม่สม่ำเสมอ และห่วงโซ่ความล้มเหลวที่ยากจะดีบัก
ปัญหาที่ RabbitMQ ช่วยแก้
การกระแทกของทราฟฟิกและภาระงานที่ไม่สม่ำเสมอ. หากแอปคุณมีการลงทะเบียนหรือคำสั่งซื้อเพิ่มขึ้น 10× ในช่วงสั้น การประมวลผลทั้งหมดทันทีอาจทำให้บริการด้านล่างล้นได้ ด้วย RabbitMQ ผู้ผลิตจะ enqueue งานได้เร็วและผู้บริโภคจะไล่ทำงานทีละรายการในจังหวะที่ควบคุมได้
การจับคู่แน่นระหว่างบริการ. เมื่อ Service A ต้องเรียก Service B แล้วรอ ผลลัพธ์จากความล้มเหลวและความหน่วงจะกระจายไป Messaging ช่วยให้แยกการพึ่งพา: A เผยแพร่ข้อความแล้วทำงานต่อ; B จะประมวลผลเมื่อพร้อม
การจัดการความล้มเหลวที่ปลอดภัยขึ้น. ไม่ใช่ทุกความล้มเหลวที่ควรกลายเป็นข้อผิดพลาดแสดงต่อผู้ใช้ RabbitMQ ช่วยให้ลองประมวลผลซ้ำในพื้นหลัง กักกันข้อความ “พิษ” และหลีกเลี่ยงการสูญหายของงานในช่วงการขาดช่วงชั่วคราว
ผลลัพธ์ที่ทีมมักเห็น
ทีมมักได้ ภาระงานที่ราบรื่นขึ้น (บัฟเฟอร์ช่วงพีค), บริการที่แยกกันมากขึ้น (พึ่งพาตอนรันไทม์น้อยลง), และ การลองใหม่ที่ควบคุมได้ (ลดงานแก้ไขด้วยมือ) สำคัญไม่แพ้กันคือการอธิบายได้ง่ายขึ้นว่า งานไปติดที่ไหน—ที่ผู้ผลิต ในคิว หรือที่ผู้บริโภค
คู่มือนี้ครอบคลุมอะไร (และไม่ครอบคลุมอะไร)
คู่มือนี้เน้น RabbitMQ เชิงปฏิบัติสำหรับทีมแอป: แนวคิดหลัก รูปแบบทั่วไป (pub/sub, work queues, การลองใหม่และ DLQ) และประเด็นการปฏิบัติการ (ความปลอดภัย การสเกล การมอนิเตอร์ การแก้ปัญหา)
มันไม่ได้ตั้งใจจะเป็นคู่มือ AMQP ครบถ้วนหรือเจาะลึกปลั๊กอินทุกตัว เป้าหมายคือช่วยคุณออกแบบการไหลของข้อความที่ยังดูแลรักษาได้ในระบบจริง
คำศัพท์ด่วน
- Producer: ส่วนของแอปที่ส่งข้อความ
- Consumer: ส่วนของแอปที่รับและประมวลผลข้อความ
- Queue: บัฟเฟอร์ที่เก็บข้อความจนกว่าผู้บริโภคจะจัดการ
- Exchange: จุดเข้าเพื่อ routing ข้อความไปยังคิวหนึ่งหรือหลายคิว
- Routing key: ป้ายกำกับที่ exchange ใช้ตัดสินใจว่าข้อความควรไปที่ใด
พื้นฐาน RabbitMQ: มันคืออะไรและเมื่อใดควรใช้
RabbitMQ คือ message broker ที่ route ข้อความระหว่างส่วนต่างๆ ของระบบของคุณ เพื่อให้ผู้ผลิตสามารถส่งมอบงานแล้วผู้บริโภคประมวลผลเมื่อพร้อม
การส่งข้อความแบบ AMQP vs การเรียก HTTP ตรงๆ
ด้วยการเรียก HTTP ตรง Service A ส่งคำขอไปยัง Service B และมักจะ รอ คำตอบ หาก Service B ช้าหรือหยุดทำงาน Service A จะล้มเหลวหรือค้าง และคุณต้องจัดการ timeout, retry, และ backpressure ในทุกตัวเรียก
ด้วย RabbitMQ (มักผ่าน AMQP) Service A เผยแพร่ข้อความไปยัง broker RabbitMQ เก็บและ route มันไปยังคิวที่เหมาะสม และ Service B จะบริโภคแบบอะซิงโครนัส การเปลี่ยนสำคัญคือคุณสื่อสารผ่าน ชั้นกลางที่ทนทาน ซึ่งบัฟเฟอร์การกระแทกและทำให้ภาระงานราบรื่นขึ้น
เมื่อใดที่ messaging เหมาะ (และเมื่อไม่เหมาะ)
Messaging เหมาะเมื่อคุณ:
- ต้องการ แยก ทีม/บริการเพื่อให้ deploy และสเกลแยกกันได้
- ต้องการงานแบบ อะซิงโครนัส (ส่งอีเมล สร้าง PDF ตรวจสอบการฉ้อโกง) โดยไม่บล็อกคำขอผู้ใช้
- คาดว่ามี ทราฟฟิกเป็นช่วงๆ และต้องการใช้คิวดูดซับพีก
- ต้องการ การส่งที่เชื่อถือได้ พร้อม ack, retry, และ dead-letter queues
Messaging ไม่เหมาะเมื่อคุณ:
- ต้องการ คำตอบทันที เพื่อให้บริการคำขอนั้น (เช่น “รหัสผ่านนี้ถูกต้องไหม?”)
- ทำการอ่านแบบซิงโครนัสที่เรียบง่ายซึ่งเรียกตรงจะชัดเจนและดีบักง่ายกว่า
- ไม่มีแผนสำหรับการเวอร์ชันข้อความ, retry และมอนิเตอร์ (คุณจะย้ายความซับซ้อนจากที่หนึ่งไปอีกที่แทนที่จะลดมัน)
ตัวอย่าง request/response vs workflow แบบอะซิงค์
ซิงโครนัส (HTTP):
บริการ checkout เรียกบริการออกใบแจ้งหนี้ผ่าน HTTP: “สร้างใบแจ้งหนี้” ผู้ใช้รอระหว่างที่ออกใบแจ้งหนี้ หากช้าหรือหยุด checkout จะช้า/ล้มเหลว
อะซิงโครนัส (RabbitMQ):
Checkout เผยแพร่ invoice.requested พร้อม order id ผู้ใช้ได้รับการยืนยันทันทีว่ารับคำสั่งแล้ว Invoicing บริโภคข้อความ สร้างใบแจ้งหนี้ แล้วเผยแพร่ invoice.created เพื่อให้ระบบอีเมล/การแจ้งเตือนทำงานต่อ แต่ละขั้นตอน retry แยกกันได้ และการขาดช่วงชั่วคราวจะไม่ทำให้ทั้ง flow พัง
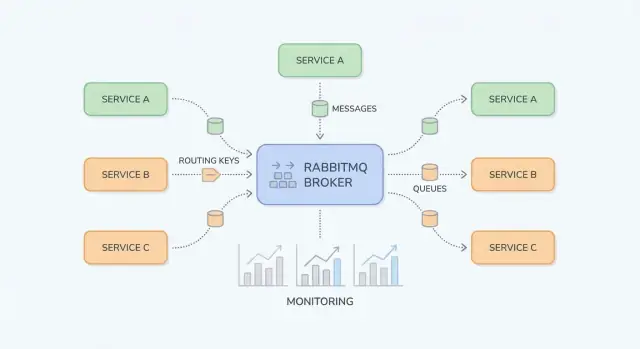
โครงสร้างพื้นฐาน: Exchanges, Queues, และ Routing
RabbitMQ เข้าใจง่ายเมื่อคุณแยกระหว่าง “ที่ที่เผยแพร่ข้อความ” กับ “ที่ที่เก็บข้อความ” ผู้ผลิตเผยแพร่ไปยัง exchanges; exchanges route ไปยัง queues; ผู้บริโภคอ่านจากคิว
Exchanges: RabbitMQ ตัดสินใจส่งข้อความอย่างไร
Exchange ไม่เก็บข้อความ มันประเมินกฎและส่งต่อข้อความไปยังคิวหนึ่งหรือหลายคิว
- Direct exchange: route ตามการจับคู่ตรงของ routing key ใช้เมื่อคุณต้องการปลายทางชัดเจน (เช่น
billingหรือemail) - Topic exchange: route โดยใช้แพตเทิร์นใน routing key เหมาะสำหรับ pub/sub และการสมัครรับหมวดหมู่
- Fanout exchange: กระจายไปยังทุกคิวที่ผูกกับมัน โดยไม่สน routing key เหมาะเมื่อผู้บริโภคทุกตัวควรได้รับทุกเหตุการณ์ (เช่น invalidate cache)
- Headers exchange: route โดยพิจารณาจาก header ของข้อความแทน routing key ใช้ในกรณีพิเศษที่การ route ขึ้นกับหลายแอตทริบิวต์ (เช่น
region=euANDtier=premium) แต่เก็บไว้สำหรับกรณีพิเศษเพราะเข้าใจยากกว่า
Queues และ bindings: ข้อความไปถึงที่ถูกต้องอย่างไร
Queue คือที่ที่ข้อความนั่งรอจนกว่าผู้บริโภคจะจัดการ มันอาจมีผู้บริโภคหนึ่งตัวหรือหลายตัว (competing consumers) และโดยทั่วไปข้อความจะถูกส่งให้ผู้บริโภคทีละรายการ
Binding เชื่อม exchange กับ queue และกำหนดกฎการ route คิดว่าเหมือน: “เมื่อข้อความชน exchange X พร้อม routing key Y ให้ส่งไปยัง queue Q” คุณสามารถผูกหลายคิวกับ exchange เดียวกัน (pub/sub) หรือผูกคิวเดียวกับหลาย routing key
Routing keys และแพตเทิร์น (topic exchanges)
สำหรับ direct exchange การ route ต้องแม่นยำ สำหรับ topic exchange routing key เป็นคำที่คั่นด้วยจุด เช่น:
orders.createdorders.eu.refunded
Bindings สามารถมี wildcards:
*จับคู่คำเดียวพอดี (เช่นorders.*จับorders.created)#จับคู่ศูนย์คำหรือมากกว่า (เช่นorders.#จับorders.createdและorders.eu.refunded)
นี่เป็นวิธีที่ดีในการเพิ่มผู้บริโภคใหม่โดยไม่ต้องเปลี่ยนผู้ผลิต—สร้างคิวใหม่แล้ว bind ด้วยแพตเทิร์นที่ต้องการ
การยืนยันข้อความ: ack, nack, requeue
หลังจาก RabbitMQ ส่งข้อความ ผู้บริโภคต้องรายงานผล:
- ack: “ประมวลผลเรียบร้อย.” RabbitMQ เอาข้อความออกจากคิว
- nack (หรือ reject): “ล้มเหลว.” คุณสามารถเลือกทิ้งหรือ requeue มัน
- requeue: นำข้อความกลับเข้าไปในคิวเพื่อพยายามใหม่ (มักจะทันที)
ระวังการ requeue: ข้อความที่ล้มเหลวตลอดเวลาสามารถวนลูปไม่รู้จบและกีดขวางคิวได้ ทีมส่วนใหญ่จึงจับคู่การ nack กับกลยุทธ์ retry และ dead-letter queue เพื่อจัดการความล้มเหลวอย่างคาดการณ์ได้
กรณีใช้งานทั่วไปในแอปจริง
RabbitMQ โดดเด่นเมื่อต้องย้ายงานหรือการแจ้งเตือนระหว่างส่วนของระบบโดยไม่ทำให้ทุกอย่างรอขั้นตอนช้า ต่อไปนี้เป็นรูปแบบปฏิบัติที่พบในผลิตภัณฑ์ประจำวัน
การเผยแพร่/สมัครรับ (pub/sub) (fanout/topic)
เมื่อต้องการให้ผู้บริโภคหลายรายตอบสนองต่อเหตุการณ์เดียวกันโดยที่ผู้เผยแพร่ไม่รู้ว่าพวกเขาคือใคร pub/sub เหมาะ
ตัวอย่าง: เมื่อลูกค้าอัพเดตโปรไฟล์ คุณอาจต้องแจ้ง indexing สำหรับการค้นหา, analytics, และการซิงก์ CRM พร้อมกัน ด้วย fanout exchange คุณกระจายไปยังทุกคิวที่ผูกไว้; ด้วย topic exchange คุณ route แบบเลือกได้ (เช่น user.updated, user.deleted) วิธีนี้หลีกเลี่ยงการผูกกันแน่นและให้ทีมเพิ่มผู้สมัครรับใหม่ได้โดยไม่ต้องเปลี่ยนผู้ผลิต
Work queues สำหรับงานแบ็คกราวด์
ถ้างานหนึ่งต้องใช้เวลา ให้ push มันไปยังคิวและให้ worker ประมวลผลแบบอะซิงโครนัส:
- การประมวลผลรูป/วิดีโอ
- การส่งอีเมลธุรกรรม
- การสร้าง PDF หรือรายงาน
- การนำเข้าหรือส่งออกข้อมูล
สิ่งนี้ทำให้เว็บรีเควสเร็วขึ้นในขณะที่สเกล worker แยกจากกันได้ และเป็นวิธีธรรมชาติเพื่อควบคุมความขนาน: คิวเป็นรายการ "ต้องทำ" และจำนวน worker คือปุ่มปรับ throughput
การรวมบริการแบบขับเคลื่อนด้วยเหตุการณ์
หลาย workflow ข้ามขอบเขตบริการ: order → billing → shipping แทนที่ให้บริการหนึ่งเรียกอีกบริการและบล็อก แต่ละบริการสามารถเผยแพร่เหตุการณ์เมื่อเสร็จขั้นตอน ลำดับถัดไปจะบริโภคเหตุการณ์และทำงานต่อ
สิ่งนี้เพิ่มความยืดหยุ่น (การขาดช่วงของ shipping ชั่วคราวจะไม่ทำให้ checkout พัง) และทำให้ความรับผิดชอบชัดเจน: แต่ละบริการตอบสนองต่อเหตุการณ์ที่มันสนใจ
เป็นบัฟเฟอร์สำหรับการพึ่งพาช้า/ไม่เสถียร
RabbitMQ ยังเป็นบัฟเฟอร์ระหว่างแอปของคุณกับการพึ่งพาที่ช้าหรือไม่น่าเชื่อถือ (API ภายนอก ระบบเก่า ฐานข้อมูลแบตช์) คุณ enqueue คำขออย่างรวดเร็ว แล้วประมวลผลด้วยการลองใหม่ที่ควบคุมได้ หากการพึ่งพาหยุดทำงาน งานจะสะสมอย่างปลอดภัยและระบายออกทีหลัง แทนที่จะทำให้เกิด timeout ทั่วทั้งแอป
ถ้าคุณวางแผนจะแนะนำคิวแบบค่อยเป็นค่อยไป ขั้นตอนแรกที่ดีคือ "async outbox" เล็กๆ หรือคิวงานแบ็คกราวด์เดียว เพื่อทดลองและขยายต่อ (ดูบทความแนะนำแผนการเปิดตัว)
ออกแบบการไหลของข้อความให้ยังดูแลง่าย
Standardize retries and DLQs
สร้างการตั้งค่าลองใหม่และ dead-letter ที่พร้อมแก้ไขได้ พร้อมคอนเวนชันการตั้งชื่อที่สอดคล้อง
การตั้งค่า RabbitMQ จะยังทำงานสบายๆ เมื่อเส้นทางชัดเจน ชื่อสอดคล้อง และ payload พัฒนาได้โดยไม่ทำให้ผู้บริโภคเก่าเสียหาย ก่อนเพิ่มคิวใหม่ ให้แน่ใจว่า "เรื่องราว" ของข้อความชัดเจน: มาจากไหน ถูก route อย่างไร และเพื่อนร่วมงานจะแก้ปัญหาตั้งแต่ต้นจนจบได้อย่างไร
เลือกประเภท exchange ให้ตรงกับความต้องการ routing
การเลือก exchange ที่ถูกต้องตั้งแต่ต้นจะลดการ binding เฉพาะกิจและการ fan-out ที่ไม่คาดคิด:
- Direct exchange: ดีเมื่อ routing key แมปไปยังคิวเฉพาะ (เช่น
billing.invoice.created) - Topic exchange: ดีสำหรับ pub/sub ยืดหยุ่นกับแพตเทิร์น (เช่น
billing.*.created,*.invoice.*) เป็นตัวเลือกที่พบบ่อยสำหรับการ route แบบเหตุการณ์ที่ดูแลรักษาได้ - Fanout exchange: ดีเมื่อผู้บริโภคทุกตัวควรได้รับทุกข้อความ (พบไม่บ่อยสำหรับเหตุการณ์ธุรกิจ; ใช้กับสัญญาณแบบ broadcast มากกว่า)
กฎทั่วไป: ถ้าคุณกำลังเขียน logic routing ซับซ้อนในโค้ด อาจเหมาะกับ topic exchange แทน
พื้นฐานสคีมาของข้อความ: การเวอร์ชันและความเข้ากันได้ย้อนหลัง
ปฏิบัติต่อ body ของข้อความเหมือน API สาธารณะ ใช้ การเวอร์ชัน ชัดเจน (เช่น ฟิลด์บนสุด schema_version: 2) และตั้งเป้าความเข้ากันได้ย้อนหลัง:
- เพิ่มฟิลด์; อย่าเปลี่ยนชื่อ/ลบ
- ชอบฟิลด์ที่เป็น option พร้อมค่า default ปลอดภัย
- หากต้องเปลี่ยนแบบ breaking ให้เผยแพร่ประเภทข้อความ/ routing key ใหม่ แทนการเปลี่ยนแปลงเงียบๆ ของแบบเก่า
วิธีนี้ช่วยให้ผู้บริโภคเก่ายังทำงานได้ในขณะที่ผู้บริโภคใหม่ย้ายไปใช้สคีมใหม่ตามเวลาของตัวเอง
Correlation IDs และ trace IDs สำหรับการดีบักข้ามบริการ
ทำให้การแก้ปัญหาถูกและเร็วขึ้นด้วยการมาตรฐานเมตาดาตา:
correlation_id: ผูกคำสั่ง/เหตุการณ์ที่อยู่ในธุรกรรมเดียวกันtrace_id(หรือ W3Ctraceparent): เชื่อมข้อความกับ distributed tracing ระหว่าง HTTP และงานอะซิงค์
เมื่อผู้เผยแพร่ตั้งค่านี้อย่างสม่ำเสมอ คุณจะตามธุรกรรมเดียวผ่านหลายบริการได้โดยไม่ต้องเดา
คอนเวนชันการตั้งชื่อที่สเกลได้
ใช้ชื่อที่ทำนายได้และค้นหาได้ หนึ่งรูปแบบที่ใช้กันบ่อย:
- Exchanges:
<domain>.<type>(เช่นbilling.events) - Routing keys:
<domain>.<entity>.<verb>(เช่นbilling.invoice.created) - Queues:
<service>.<purpose>(เช่นreporting.invoice_created.worker)
ความสอดคล้องชนะความฉลาด: คุณในอนาคต (และทีม on-call) จะขอบคุณ
รูปแบบความน่าเชื่อถือ: Retries, DLQs และ Idempotency
การส่งข้อความที่เชื่อถือได้คือการวางแผนสำหรับความล้มเหลว: consumer ล้ม downstream API timeout และบางเหตุการณ์มีสคีมไม่ถูกต้อง RabbitMQ ให้เครื่องมือ แต่โค้ดของแอปต้องร่วมมือด้วย
การส่งอย่างน้อยหนึ่งครั้ง (at-least-once) และความหมายสำหรับโค้ดของคุณ
การตั้งค่าที่พบบ่อยคือ at-least-once delivery: ข้อความอาจถูกส่งมากกว่าหนึ่งครั้ง แต่ไม่ควรหายไปเงียบๆ นั่นมักเกิดเมื่อ consumer รับข้อความ เริ่มทำงาน แล้วล้มก่อน ack—RabbitMQ จะ requeue และส่งใหม่
ผลปฏิบัติ: การซ้ำเป็นเรื่องปกติ ดังนั้น handler ของคุณต้องปลอดภัยที่จะรันซ้ำได้
กลยุทธ์ idempotency สำหรับผู้บริโภค
Idempotency หมายถึง "การประมวลผลข้อความเดิมสองครั้งให้ผลเท่ากับการประมวลผลครั้งเดียว" แนวทางที่ใช้ได้:
- Dedupe keys: ใส่
message_idคงที่ (หรือ business key เช่นorder_id + event_type + version) แล้วเก็บในตาราง/แคชว่าได้ประมวลผลแล้ว พร้อม TTL - การอัพเดตอย่างปลอดภัย: ใช้การเขียนแบบมีเงื่อนไข (เช่น อัพเดตก็ต่อเมื่อสถานะยังเป็น
PENDING) หรือข้อจำกัดความเป็นเอกลักษณ์ใน DB เพื่อป้องกันการสร้างซ้ำ - Outbox/inbox patterns: บันทึกรับเหตุการณ์ก่อนแล้วจึงประมวลผล เพื่อให้ retries ไม่ทำให้ side effects ซ้ำ
Retries ด้วย TTL + DLX/DLQ
การลองใหม่ควรจัดเป็นกระแสแยก ไม่ใช่ลูปแน่นใน consumer
รูปแบบที่พบบ่อยคือ:
- เมื่อเกิดความล้มเหลวชั่วคราว ให้ reject และ route ไปยัง retry queue ที่มี TTL ต่อคิวหรือข้อความ
- เมื่อตัว TTL หมดอายุ ข้อความจะ dead-letter กลับไปยังคิวเดิมผ่าน dead-letter exchange (DLX)
- ติดตามจำนวนครั้งที่พยายามผ่าน header (หรือเข้ารหัสใน routing key) และหยุดหลัง N ครั้ง
วิธีนี้สร้าง backoff โดยไม่ทำให้ข้อความถูก "ค้าง" ในสถานะ unacked
ข้อความพิษ: กักและ replay
บางข้อความจะไม่สำเร็จ (สคีมผิด ข้อมูลอ้างอิงหาย bug ในโค้ด) ตรวจจับโดย:
- ถึงจำนวน retry สูงสุด
- ความล้มเหลวซ้ำที่มีลายเซ็นเดียวกัน
ส่งไปยัง DLQ เพื่อกักกัน ถือ DLQ เป็น inbox เชิงปฏิบัติการ: ตรวจ payload แก้ปัญหา แล้ว replay ด้วยมือ เฉพาะข้อความที่เลือก (ดีที่สุดผ่านเครื่องมือ/สคริปต์ควบคุม) แทนการเททุกอย่างกลับเข้าไปในคิวหลัก
ประสิทธิภาพและการสเกล: เคล็ดลับการปรับจูนเชิงปฏิบัติ
ประสิทธิภาพ RabbitMQ มักถูกจำกัดด้วยปัจจัยปฏิบัติหลายอย่าง: การจัดการการเชื่อมต่อ ความเร็วการประมวลผลของ consumer และการใช้คิวเป็น "ที่เก็บ" เป้าหมายคือ throughput ที่เสถียรโดยไม่ให้ backlog โตขึ้นเรื่อยๆ
Connections vs channels (การนำกลับมาใช้และข้อจำกัด)
ข้อผิดพลาดทั่วไปคือเปิดการเชื่อมต่อ TCP ใหม่สำหรับผู้เผยแพร่หรือผู้บริโภคแต่ละตัว Connections หนักกว่าที่คิด (handshakes, heartbeats, TLS) ดังนั้นเก็บให้ยาวนานและนำกลับมาใช้
ใช้ channels เพื่อ multiplex งานบนจำนวนการเชื่อมต่อน้อยลง กฎง่ายๆ: few connections, many channels แต่ก็อย่าสร้างช่องเป็นพันๆ — แต่ละ channel มี overhead ไลบรารีไคลเอนต์ของคุณอาจมีข้อจำกัดเอง ให้ใช้ pool ช่องขนาดเล็กต่อบริการและนำกลับมาใช้เมื่อเผยแพร่
Prefetch และ concurrency (throughput โดยไม่ overload)
ถ้าผู้บริโภคดึงข้อความมากเกินไปพร้อมกัน จะเห็น memory spike, เวลาในการประมวลผลยาว, และ latency ไม่สม่ำเสมอ ตั้งค่า prefetch เพื่อให้แต่ละ consumer ถือจำนวน unacked ที่ควบคุมได้
คำแนะนำเชิงปฏิบัติ:
- สำหรับงานช้า (เรียก API ไฟล์) เริ่มที่ prefetch 1–10 ต่อ consumer
- สำหรับ handler ที่เร็วและเบาทาง CPU เพิ่ม prefetch ทีละน้อยพร้อมเฝ้าดูอัตราการ ack และทรัพยากรโฮสต์
- สเกลโดยเพิ่ม instance ของ consumer ก่อนจะเพิ่ม prefetch มากๆ
ขนาดข้อความ: เก็บ payload ให้กระทัดรัด
ข้อความใหญ่ทำให้ throughput ลดและเพิ่มแรงกดในหน่วยความจำ (ทั้งผู้เผยแพร่ broker และ consumer) ถ้า payload ใหญ่ (เอกสาร รูปภาพ JSON ขนาดใหญ่) พิจารณาเก็บที่อื่น (object storage หรือ DB) แล้วส่งแค่ ID + metadata ผ่าน RabbitMQ
เฮียวริสติกที่ดี: เก็บข้อความในช่วง KB ไม่ใช่ MB
Backpressure: ป้องกันการเติบโตไม่รู้จบของคิว
การเติบโตของคิวคืออาการ ไม่ใช่กลยุทธ์ เพิ่ม backpressure ให้ผู้ผลิตชะลอตัวเมื่อผู้บริโภคตามไม่ทัน:
- จำกัดงานของ consumer: กำหนด concurrency และ tune prefetch ให้งานที่กำลังทำอยู่คาดเดาได้
- ตรวจจับและตอบสนองต่อการเติบโต: แจ้งเตือนเมื่อ queue depth เพิ่ม และเปรียบเทียบอัตราการเผยแพร่กับอัตราการ ack
- ปล่อยทิ้งภาระ: สำหรับเหตุการณ์ไม่สำคัญ ให้ลดหรือสุ่มตัวอย่างก่อนเผยแพร่ในช่วงพีก
เมื่อสงสัย ให้เปลี่ยนทีละตัวแล้ววัด: publish rate, ack rate, queue length และ end-to-end latency
เช็คลิสต์ความปลอดภัยสำหรับการปรับใช้ RabbitMQ
Validate under real pressure
รันการฝึกจำลองการจราจรสูงและปรับการสเกลของ consumer ก่อนขึ้นโปรดักชัน
ความปลอดภัยของ RabbitMQ ส่วนใหญ่เกี่ยวกับการทำให้ "ขอบ" แน่น: วิธีที่ไคลเอนต์เชื่อมต่อ ใครทำอะไรได้ และการเก็บข้อมูลรับรองให้ห่างจากที่ผิด ใช้เช็คลิสต์นี้เป็นฐานแล้วปรับให้เข้ากับข้อกำหนดของคุณ
เข้ารหัสการเชื่อมต่อด้วย TLS
- เปิด TLS สำหรับการเชื่อมต่อของไคลเอนต์ (AMQP over TLS บน 5671 หรือพอร์ตที่เลือก) และใช้เวอร์ชัน/cipher ที่ทันสมัย
- ใช้ใบรับรองที่ตรงกับ hostname ของ broker ที่ไคลเอนต์เชื่อมต่อ
- วางแผนการหมุนใบรับรอง: ติดตามวันหมดอายุ อัตโนมัติการต่ออายุเมื่อทำได้ และซ้อมขั้นตอน reload เพื่อไม่ให้การหมุนเป็นสาเหตุของการขาดช่วง
- หากทำได้ ให้ยืนยันไคลเอนต์ด้วย mTLS สำหรับบริการภายในที่จัดการข้อมูลละเอียดอ่อน
การยืนยันตัวตนและการอนุญาต
สิทธิ์ของ RabbitMQ มีประสิทธิภาพเมื่อใช้สม่ำเสมอ:
- สร้างผู้ใช้แยกสำหรับแต่ละแอป (หลีกเลี่ยงบัญชีร่วม)
- ใช้ vhost เพื่อแยกระบบหรือทีม (เช่น หนึ่ง vhost ต่อผลิตภัณฑ์/ทีม)
- ใช้สิทธิ์แบบ least privilege ต่อ vhost:
- Configure (สร้าง/แก้ไข resource)
- Write (เผยแพร่)
- Read (บริโภค)
แยก dev/staging/prod ให้ปลอดภัย
- รันคลัสเตอร์แยกตามสภาพแวดล้อมเมื่อเป็นไปได้ ถ้าต้องแชร์โครงสร้างพื้นฐาน ให้แยกด้วย vhost ที่เข้มงวดและข้อมูลรับรองที่ต่างกัน
- ห้ามให้แอป dev ชี้ไปยัง broker prod เพื่อทดสอบ ทำให้เป็นไปไม่ได้ผ่านนโยบายเครือข่ายและการตั้งชื่อ DNS
จัดการความลับในแอปอย่างถูกต้อง
- อย่าใส่ credentials ในโค้ด คอนฟิกที่คอมมิตใน git หรือภาพคอนเทนเนอร์
- ฉีดความลับตอนรันไทม์ผ่านแพลตฟอร์มของคุณ (Kubernetes secrets, secrets manager, หรือตัวแปร CI ที่เข้ารหัส)
- หมุน credentials เป็นประจำและลบผู้ใช้ที่ไม่ใช้แล้ว
สำหรับการทำให้แข็งแกร่งในเชิงปฏิบัติการ (พอร์ต, firewall, auditing) ให้เก็บ runbook สั้นๆ ภายในและเชื่อมโยงจากเอกสารความปลอดภัยภายใน เพื่อให้ทีมปฏิบัติตามมาตรฐานเดียวกัน
การมอนิเตอร์และการสังเกตการณ์: ควรวัดอะไร
เมื่อ RabbitMQ ผิดพลาด อาการจะปรากฏในแอปของคุณก่อน: endpoint ช้าลง timeout หายไป หรืองานที่ "ไม่เคยจบ" การสังเกตการณ์ที่ดีช่วยให้ยืนยันได้ว่า broker เป็นสาเหตุ ใส่ใจคอขวด (ผู้เผยแพร่ broker หรือผู้บริโภค) และลงมือก่อนที่ผู้ใช้จะสังเกตเห็น
เมตริกของ broker ที่ควรติดตาม
เริ่มจากสัญญาณไม่กี่ตัวที่บอกว่าสาระยังไหล:
- Queue depth (messages ready + unacked): depth เพิ่มขึ้นบอกว่าผู้บริโภคตามไม่ทันหรือค้าง
- Publish rate และ ack rate: publish เพิ่มแต่ ack แบน = backlog; ack ลดลงอย่างฉับพลัน = consumer ล้มเหลวหรือ timeout
- การใช้งานของ consumer: ผู้บริโภคว่าง เวียนเต็ม หรือรีสตาร์ทบ่อย? จับคู่กับ prefetch และ concurrency
- Redeliveries / requeues: ตัวชี้บ่งการผิดพลาดในการประมวลผล หรือนโยบาย retry ที่ไม่ดี
สัญญาณแจ้งเตือนที่จับเหตุการณ์ได้เร็ว
ตั้งการแจ้งเตือนตามแนวโน้ม ไม่ใช่แค่เกณฑ์คงที่:
- Backlog เพิ่มขึ้นต่อเนื่องเป็น N นาที: depth เพิ่มต่อเนื่องมีประโยชน์กว่าการแจ้งเตือนว่า "depth > X" ทันที
- Redeliveries/requeues ซ้ำๆ: ชี้ไปที่ loop ของความล้มเหลวที่ใช้ CPU และบล็อกคิว
- การเชื่อมต่อและ channel churn: ตัดการเชื่อมต่อบ่อยบอกปัญหาแอป, เครือข่าย หรือ heartbeat config ผิด
- Unacked ค้างสูงเป็นเวลานาน: บ่งชี้ว่า consumer หยุดหรือต่อข้อความนานเกินไป
โลก์และการติดตามข้อความในเหตุการณ์
ล็อกของ broker ช่วยแยกระหว่าง "RabbitMQ ล่ม" กับ "ไคลเอนต์ใช้ไม่ถูกต้อง" มองหา authentication failures, blocked connections (resource alarms), และ channel errors บ่อยๆ ในฝั่งแอป ให้แน่ใจว่าทุกความพยายามประมวลผลล็อก correlation_id, ชื่อคิว, และผลลัพธ์ (acked, rejected, retried)
ถ้าคุณใช้ distributed tracing ให้ส่งต่อ trace headers ผ่าน properties ของข้อความเพื่อเชื่อม "คำขอ API → ข้อความที่เผยแพร่ → งานของ consumer"
แดชบอร์ดและ runbook ภายใน
สร้างแดชบอร์ดต่อ flow สำคัญ: publish rate, ack rate, depth, unacked, requeues, และจำนวน consumer ใส่ลิงก์ไปยัง runbook ภายใน และเช็คลิสต์ "ตรวจอะไรเป็นอันดับแรก" สำหรับผู้รักษาระบบ
แก้ไขปัญหาที่พบบ่อยของ RabbitMQ
Make changes with confidence
ทดลองเปลี่ยนการตั้งค่า routing และย้อนกลับเร็วเมื่อ binding หรือ handler ผิดพลาด
เมื่อบางอย่าง "หยุดเคลื่อน" ใน RabbitMQ อย่ารีบรีสตาร์ทเป็นอย่างแรก ปัญหาส่วนใหญ่ชัดเมื่อคุณดู (1) binding และ routing (2) สุขภาพของ consumer และ (3) resource alarms
ข้อความไม่ถูกบริโภค
หากผู้เผยแพร่บอกว่า "ส่งสำเร็จ" แต่คิวว่างหรือคิวผิดเต็ม ให้ตรวจ routing ก่อนโค้ด
เริ่มจาก UI การจัดการ:
- ยืนยัน ประเภท exchange และว่า queue มี binding ที่คาดหวัง
- ยืนยันว่า routing key ที่ผู้ผลิตส่งตรงกับแพตเทิร์นของ binding (โดยเฉพาะกับ
topic) - ยืนยันว่าคุณเผยแพร่ใน vhost ที่ถูกต้อง
ถ้าคิวมีข้อความแต่ไม่มีการบริโภค ให้ยืนยัน:
- มี consumer เชื่อมต่อและ subscribe ที่คิวถูกต้องหรือไม่
- consumer ไม่ติดเพราะ prefetch ต่ำ/สูงเกินไป หรือถูกบล็อกด้วยงานด้านล่างช้า
- ack เกิดขึ้นหรือไม่ (unacked เพิ่มมักหมายความว่า consumer ไม่ ack หรือล้น)
การส่งซ้ำและการประมวลผลนอกลำดับ
การส่งซ้ำมักเกิดจาก retries (consumer ล้มหลังประมวลผลแต่ก่อน ack), การตัดการเชื่อมต่อเครือข่าย หรือการ requeue ด้วยมือ ป้องกันโดยทำให้ handler idempotent (เช่น dedupe ด้วย message ID ในฐานข้อมูล)
การส่งนอกลำดับเป็นเรื่องปกติเมื่อมีหลาย consumer หรือ requeues ถ้าลำดับสำคัญ ให้ใช้ consumer เดียวสำหรับคิวเดียว หรือแบ่งตามคีย์เข้าเป็นหลายคิว
alarms ของหน่วยความจำ/ดิสก์
alarms คือ RabbitMQ ป้องกันตัวเอง:
- Disk alarm: เพิ่มพื้นที่ว่างในดิสก์ ย้ายล็อก หรือขยายโวลุ่ม แล้วตรวจว่า alarm หายไป
- Memory alarm: ลดจำนวนข้อความในหน่วยความจำ (lower prefetch, ชะลอผู้เผยแพร่, เทียบ payload ขนาดใหญ่)
การ replay ที่ปลอดภัยจาก DLQ
ก่อน replay ให้แก้สาเหตุรากและป้องกันลูปของ "ข้อความพิษ" รีคิวเป็นชุดเล็กๆ ติด stamp metadata ของความล้มเหลว (attempt count, last error) พิจารณาส่งข้อความที่ replay ไปยังคิวแยกก่อน เพื่อหยุดเร็วถ้าเกิดข้อผิดพลาดเดิมอีกครั้ง
RabbitMQ เทียบกับทางเลือก: เลือกเครื่องมือที่เหมาะสม
การเลือกเครื่องมือ messaging ไม่ใช่เรื่องของ "ดีที่สุด" แต่เป็นการจับคู่กับรูปแบบทราฟฟิก ความทนต่อความผิดพลาด และความสะดวกในการปฏิบัติการ
เมื่อ RabbitMQ เหมาะ
RabbitMQ ดีเมื่อคุณต้องการ การส่งข้อความเชื่อถือได้และ routing ยืดหยุ่น ระหว่างส่วนของแอป มันเหมาะสำหรับ workflow แบบ async—คำสั่ง งานแบ็คกราวด์ การกระจายข้อความ และรูปแบบ request/response โดยเฉพาะเมื่อคุณต้องการ:
- การยืนยันต่อข้อความและ backpressure (ผู้บริโภคช้าไม่ทำให้งานหาย)
- routing ที่ยืดหยุ่น (topic, headers, direct) โดยไม่ต้องสร้างเอง
- การสเกลเชิงปฏิบัติการที่ง่าย สำหรับหลายทีม (เพิ่ม consumer ปรับ prefetch จัดการคิว)
ถ้าแอปของคุณขับเคลื่อนด้วยเหตุการณ์แต่เป้าหมายหลักคือ เคลื่อนย้ายงาน มากกว่าการเก็บประวัติยาว RabbitMQ มักเป็นค่าเริ่มต้นที่สบาย
RabbitMQ vs ระบบสตรีมแบบ Kafka
Kafka และแพลตฟอร์มคล้ายกันสร้างมาเพื่อ สตรีมความเร็วสูงและล็อกเหตุการณ์ยาวนาน เลือกระบบแบบ Kafka เมื่อคุณต้องการ:
- ความสามารถในการ replay (ผู้บริโภคสามารถประมวลผลประวัติได้)
- Throughput สูงมาก ด้วยการสเกลแบบพาร์ติชัน
- สตรีมเดียวเป็น “source of truth” สำหรับ analytics + services
ข้อแลกเปลี่ยน: ระบบแบบ Kafka อาจมีภาระการปฏิบัติการสูงกว่าและผลักออกแบบสู่ throughput-oriented design (batching, partition strategy) RabbitMQ มักง่ายกว่าใน throughput ต่ำถึงปานกลางพร้อม latency ต่ำและ routing ซับซ้อนได้ดี
เมื่อตารางงานแบบง่ายอาจพอเพียง
ถ้าคุณมีแอปเดียวผลิตงานและ worker pool เดียวบริโภค และยอมรับ semantics ที่เรียบง่าย คิวบน Redis (หรือบริการจัดการงาน) อาจพอเพียง ทีมมักจะเติบโตออกจากมันเมื่อพวกเขาต้องการการันตีการส่งที่แข็งแรงขึ้น, dead-lettering, หรือ routing ที่ชัดเจน
พิจารณาการย้ายเมื่อความต้องการเปลี่ยน
ออกแบบสัญญาข้อความราวกับว่าคุณอาจย้ายในอนาคต:
- เก็บ สคีมข้อความมีเวอร์ชัน และเข้ากันได้ย้อนหลัง
- หลีกเลี่ยงฟีเจอร์เฉพาะ broker ใน payload (วาง routing ใน header/metadata ไม่ใช่ใน body)
- สร้างผู้ผลิต/ผู้บริโภคให้รันขนานกันได้ในระหว่างการย้าย
ถ้าคุณต้องการสตรีมที่ replay ได้ คุณมักจะสามารถเชื่อมต่อเหตุการณ์จาก RabbitMQ ไปยังระบบล็อกแบบ log-based ในขณะที่รักษา RabbitMQ สำหรับ workflow เชิงปฏิบัติการ สำหรับแผนการเปิดตัวเชิงปฏิบัติ ดูบทความแผนการใช้งาน
คำถามที่พบบ่อย
เมื่อไหร่ทีมแอปควรใช้ RabbitMQ แทนการเรียก HTTP ตรงๆ?
ใช้ RabbitMQ เมื่อคุณต้องการแยกการทำงานระหว่างบริการ ช่วยดูดซับการกระแทกของทราฟฟิก หรือนำงานช้าออกจากเส้นทางคำขอ
การใช้งานที่เหมาะสมได้แก่ งานแบ็คกราวด์ (ส่งอีเมล สร้าง PDF), การแจ้งเตือนไปยังผู้บริโภคหลายราย, และ workflow ที่ต้องการทำงานต่อแม้บริการข้างล่างจะล้มชั่วคราว
หลีกเลี่ยงเมื่อคุณต้องการคำตอบทันที (การอ่าน/ตรวจสอบแบบซิงโครนัส) หรือตอนที่คุณยังไม่มีแผนสำหรับการเวอร์ชันข้อความ, การลองใหม่, และการมอนิเตอร์ — สิ่งเหล่านี้จำเป็นสำหรับการใช้งานจริงในโปรดักชัน
ฉันควรเลือกระหว่าง direct, topic, fanout และ headers exchanges อย่างไร?
เผยแพร่ไปยัง exchange แล้ว route เข้าสู่ queue:
- ใช้ direct exchange เมื่อ routing key ควรชี้ไปยังปลายทางเฉพาะ
- ใช้ topic exchange เมื่อคุณต้องการแพตเทิร์นยืดหยุ่น เช่น
orders.*หรือorders.# - ใช้ fanout exchange เมื่อผู้บริโภคทุกตัวควรได้รับข้อความทุกข้อความ
- ใช้ headers exchange เฉพาะกรณีพิเศษเมื่อการตัดสินใจ routing ขึ้นกับหลายแอตทริบิวต์
ทีมส่วนใหญ่มักเริ่มต้นด้วย topic exchanges สำหรับการ route แบบเหตุการณ์ที่ดูแลรักษาง่าย
ความแตกต่างระหว่าง queue และ binding คืออะไร และการ routing ผิดพลาดเกิดจากอะไร?
คิวเก็บข้อความจนกว่าผู้บริโภคจะประมวลผล; binding คือกฎที่เชื่อม exchange กับ queue
เพื่อ debug ปัญหา routing:
- ยืนยันประเภท exchange และแพตเทิร์น binding ของ queue
- ตรวจสอบว่าระบบผู้ผลิตส่ง routing key ตรงกับ binding (โดยเฉพาะกับ wildcards ของ topic)
- ตรวจสอบว่าเผยแพร่/บริโภคใน vhost ที่ถูกต้อง
สามขั้นตอนนี้แก้ปัญหาส่วนใหญ่เมื่อ "เผยแพร่แล้วแต่ไม่ถูกบริโภค"
รูปแบบ "work queue" ที่เรียบง่ายที่สุดสำหรับงานแบ็คกราวด์คืออะไร?
ใช้ work queue เมื่อคุณต้องการให้หนึ่งงานถูกประมวลผลโดยหนึ่งในผู้ทำงานหลายตัว
ข้อแนะนำการตั้งค่า:
- ให้แต่ละข้อความเป็นหน่วยงานทำงานหนึ่งหน่วย (เล็กและ retry ได้)
- ตั้งค่า prefetch ของ consumer เพื่อไม่ให้หยิบข้อความไม่กี่รายการจนเกินไป
- สเกลโดยเพิ่มจำนวน consumer ก่อนจะเพิ่ม prefetch มากๆ
- เก็บ payload ให้เล็ก (ส่ง ID + metadata; เก็บ blob ขนาดใหญ่ที่อื่น)
At-least-once delivery คืออะไร และฉันจัดการกับการส่งซ้ำอย่างไร?
At-least-once delivery หมายความว่าข้อความอาจถูกส่งซ้ำได้ (เช่น consumer หยุดทำงานหลังทำงานแต่ก่อน ack)
ทำให้ consumer ปลอดภัยโดย:
- ใช้
message_idคงที่ (หรือ business key) และบันทึก ID ที่ประมวลผลแล้วพร้อม TTL - ออกแบบการอัพเดตแบบปลอดภัย (เช่น เขียนแบบมีเงื่อนไข หรือตั้งข้อจำกัดความเป็นเอกลักษณ์ในฐานข้อมูล)
- แยก side effects เพื่อให้ retries ไม่ทำให้ถูกเรียกเก็บเงินหรือส่งอีเมลซ้ำ
ถือว่าเกิด duplicate เป็นเรื่องปกติและออกแบบระบบให้รับมือได้
ฉันควรนำรูปแบบการลองใหม่และ dead-letter queue (DLQ) มาใช้ใน RabbitMQ อย่างไร?
หลีกเลี่ยงลูป requeue แบบแน่นเกินไป รูปแบบที่ใช้บ่อยคือ “retry queues” + DLQ:
- เมื่อเกิดข้อผิดพลาดชั่วคราว ให้ reject ไปยัง retry queue ที่มี TTL (เพื่อ backoff)
- เมื่อตัว TTL หมดอายุ ข้อความจะ dead-letter กลับไปยังคิวหลักผ่าน DLX
- ติดตามจำนวนความพยายาม (header หรือ metadata) และหยุดหลังจาก N ครั้ง
- ส่งความผิดพลาดถาวรไปยัง DLQ เพื่อกักกัน
การ replay จาก DLQ ควรทำหลังแก้สาเหตุแล้วและทำเป็นชุดเล็กๆ
ฉันจะรักษา message contracts ให้ดูแลรักษาได้เมื่อบริการวิวัฒนาการอย่างไร?
เริ่มจากชื่อที่คาดเดาได้และปฏิบัติต่อข้อความเหมือน API สาธารณะ:
- เพิ่ม
schema_versionใน payload - เน้นการเปลี่ยนแบบเพิ่มฟิลด์ (อย่าเปลี่ยนชื่อหรือลบฟิลด์)
- หากต้องทำ breaking change ให้เผยแพร่ประเภทข้อความ/ routing key ใหม่
มาตรฐานเมตาดาตาดังต่อไปนี้จะช่วยการดีบัก:
เมตริกและการแจ้งเตือนอะไรสำคัญที่สุดสำหรับ RabbitMQ ในโปรดักชัน?
เน้นสัญญาณไม่กี่ตัวที่บอกว่างานยังไหลอยู่:
- ความลึกของคิว (ready + unacked)
- อัตราการเผยแพร่เทียบกับอัตราการ ack
- การ redeliveries/requeues (มักบอกปัญหา loop ของการประมวลผล)
- จำนวนผู้บริโภค/การใช้งานและการรีสตาร์ทซ้ำ
ตั้งการแจ้งเตือนบนแนวโน้ม (เช่น backlog เพิ่มขึ้นเป็นเวลาหลายนาที) และใช้ล็อกที่มี queue name, correlation_id และผลลัพธ์การประมวลผล (acked/retried/rejected)
เช็คลิสต์ความปลอดภัยขั้นต่ำสำหรับการปรับใช้ RabbitMQ มีอะไรบ้าง?
ทำสิ่งพื้นฐานต่อไปนี้อย่างสม่ำเสมอ:
- ใช้ TLS สำหรับการเชื่อมต่อของไคลเอนต์; พิจารณา mTLS สำหรับการสื่อสารภายในที่ละเอียดอ่อน
- สร้างผู้ใช้แยกตามแอป (หลีกเลี่ยงบัญชีร่วม)
- ใช้ vhost เพื่อแยกสภาพแวดล้อม/tenant และกำหนดสิทธิ์แบบ least-privilege (configure/write/read)
- อย่าเก็บความลับในโค้ด ให้ฉีดความลับตอนรันไทม์และหมุนรหัสเป็นประจำ
เก็บ runbook สั้นๆ ภายในเพื่อให้ทีมปฏิบัติตามมาตรฐานเดียวกัน
ฉันจะแก้ปัญหา "ข้อความไม่ถูกบริโภค" หรือ "ทุกอย่างติด" ได้อย่างไร?
เริ่มจากหาว่ากระแสถูกหยุดที่ไหน:
- ถ้าคิวว่าง ให้ตรวจสอบ exchange/binding/routing key และ vhost
- ถ้าข้อความอยู่ในคิวแต่ไม่เคลื่อนไหว ให้ตรวจสอบการเชื่อมต่อของ consumer, prefetch, และว่า unacked เพิ่มขึ้นหรือไม่
- ถ้าเห็น duplicate หรือการประมวลผลนอกลำดับ ให้คาดว่าเกิดจาก retries และ competing consumers; บรรเทาด้วย idempotency และการแบ่งพาร์ติชันถ้าจำเป็น
- ถ้าเกิด disk/memory alarms ให้ลดงานในหน่วยความจำ (prefetch/concurrency), ชะลอผู้เผยแพร่ และแก้ข้อจำกัดทรัพยากรก่อนรีสตาร์ท
การรีสตาร์ทไม่ควรเป็นก้าวแรกเสมอไป