10 ต.ค. 2568·4 นาที
Redis สำหรับแอปของคุณ: รูปแบบ ข้อควรระวัง และคำแนะนำ
เรียนรู้วิธีใช้ Redis ในแอปของคุณอย่างเป็นรูปธรรม: แคช เซสชัน คิว pub/sub และการจำกัดอัตรา—พร้อมการสเกล ความคงทน การมอนิเตอร์ และข้อควรระวัง
เรียนรู้วิธีใช้ Redis ในแอปของคุณอย่างเป็นรูปธรรม: แคช เซสชัน คิว pub/sub และการจำกัดอัตรา—พร้อมการสเกล ความคงทน การมอนิเตอร์ และข้อควรระวัง
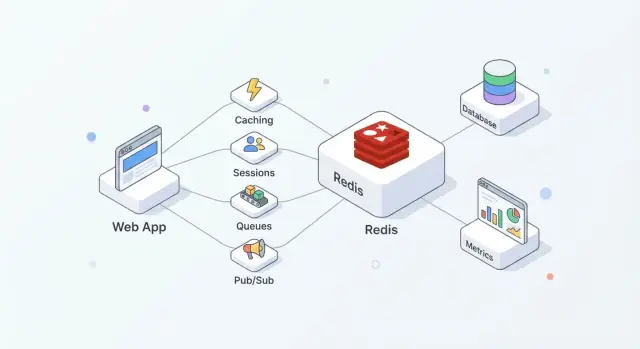
Redis คือที่เก็บข้อมูลในหน่วยความจำที่มักใช้เป็น "ชั้นความเร็ว" ร่วมสำหรับแอป ทีมชอบเพราะใช้งานง่าย ตอบสนองรวดเร็วสำหรับการดำเนินการทั่วไป และยืดหยุ่นพอที่จะรองรับหลายหน้าที่ (แคช เซสชัน เคาน์เตอร์ คิว pub/sub) โดยไม่ต้องเพิ่มระบบใหม่สำหรับแต่ละงาน
ในทางปฏิบัติ Redis ทำงานได้ดีที่สุดเมื่อคุณมองมันเป็น ความเร็ว + การประสานงาน ในขณะที่ฐานข้อมูลหลักยังคงเป็น แหล่งข้อมูลที่เชื่อถือได้
การตั้งค่าทั่วไปมีลักษณะดังนี้:
การแยกหน้าที่แบบนี้ทำให้ฐานข้อมูลของคุณมุ่งเน้นที่ความถูกต้องและความทนทาน ในขณะที่ Redis ดูดซับการอ่าน/เขียนความถี่สูงที่จะเพิ่มความหน่วงหรือภาระให้ฐานข้อมูล
เมื่อใช้ดี Redis มักให้ผลลัพธ์เชิงปฏิบัติหลายอย่าง:
Redis ไม่ใช่ตัวแทนของฐานข้อมูลหลัก หากคุณต้องการคิวรีซับซ้อน การเก็บระยะยาว หรือการรายงานวิเคราะห์ ฐานข้อมูลหลักยังคงเป็นที่เหมาะสม
นอกจากนี้ อย่าสมมติว่า Redis "ทนทานโดยปริยาย" หากการสูญเสียแม้แต่ไม่กี่วินาทีรับไม่ได้ คุณจะต้องตั้งค่าความคงทนอย่างระมัดระวัง—หรือใช้ระบบอื่น—ตามความต้องการการกู้คืนจริงของธุรกิจ
Redis มักถูกอธิบายว่าเป็น "key-value store" แต่จะมีประโยชน์กว่าเมื่อคิดว่าเป็นเซิร์ฟเวอร์ที่เร็วมากซึ่งสามารถเก็บและจัดการชิ้นข้อมูลขนาดเล็กตามชื่อ (คีย์) แบบนี้ช่วยให้รูปแบบการเข้าถึงคาดเดาได้: ปกติคุณจะรู้เลยว่าต้องการอะไร (เซสชัน หน้าถูกแคช เคาน์เตอร์) และ Redis สามารถดึงหรืออัปเดตในรอบเดียว
Redis เก็บข้อมูลใน RAM ซึ่งเป็นเหตุผลว่าทำไมจึงตอบสนองได้ในระดับไมโครวินาทีถึงมิลลิวินาที ต้นทุนคือ RAM จำกัดและมีราคาแพงกว่าดิสก์
ตัดสินใจตั้งแต่ต้นว่า Redis เป็น:
Redis สามารถคงข้อมูลลงดิสก์ได้ (RDB snapshots และ/หรือ AOF append-only logs) แต่การคงข้อมูลเพิ่มภาระการเขียนและบังคับให้คุณเลือกระดับความคงทน (เช่น "เร็วแต่สูญเสียได้เป็นวินาที" กับ "ช้ากว่าแต่ปลอดภัยกว่า") จงถือว่าการคงข้อมูลเป็นลูกบิดที่คุณปรับตามผลกระทบทางธุรกิจ ไม่ใช่ช่องทำเครื่องหมายที่ติ๊กโดยอัตโนมัติ
Redis ประมวลผลคำสั่งส่วนใหญ่ในเธรดเดียว ซึ่งฟังดูจำกัดจนกว่าคุณจะนึกถึงสองข้อ: การดำเนินการมักเล็ก และไม่มีค่าใช้จ่ายในการล็อกระหว่างเธรดหลายตัว ตราบใดที่คุณหลีกเลี่ยงคำสั่งที่หนักและ payload ขนาดใหญ่ โมเดลนี้สามารถมีประสิทธิภาพสูงภายใต้ความพร้อมใช้งานสูง
แอปของคุณสื่อสารกับ Redis ผ่าน TCP โดยใช้ไลบรารีไคลเอนต์ ใช้การพูลการเชื่อมต่อ รักษาคำขอให้เล็ก และชอบการรวม/พipelining เมื่อจำเป็นต้องทำหลายการดำเนินการ
วางแผนสำหรับ timeout และ retry: Redis เร็ว แต่เครือข่ายไม่ใช่ และแอปของคุณควรทำงานอย่างลดคุณภาพลงได้เมื่อ Redis หนักหรือไม่พร้อมชั่วคราว
หากคุณกำลังสร้างบริการใหม่และอยากมาตรฐานพื้นฐานเหล่านี้อย่างรวดเร็ว แพลตฟอร์มอย่าง Koder.ai สามารถช่วย scaffold แอป React + Go + PostgreSQL แล้วเพิ่มฟีเจอร์ที่ใช้ Redis (แคช เซสชัน การจำกัดอัตรา) ผ่าน workflow แบบแชท—พร้อมให้คุณส่งออกซอร์สโค้ดและรันที่ใดก็ได้
แคชช่วยได้เมื่อมีความเป็นเจ้าของชัดเจน: ใครเติม ใครยกเลิก และความสดใหม่ที่ "เพียงพอ" หมายถึงอะไร
Cache-aside หมายความว่าแอปของคุณ—ไม่ใช่ Redis—ควบคุมการอ่านและเขียน
กระบวนการทั่วไป:
Redis เป็นที่เก็บค่า-คีย์ที่เร็ว แอปของคุณเป็นผู้ตัดสินวิธีการซีเรียไลซ์ เวอร์ชัน และการหมดอายุของรายการ
TTL คือการตัดสินใจเชิงผลิตภัณฑ์พอๆ กับเชิงเทคนิค TTL สั้นลดความล้าสมัยแต่เพิ่มภาระฐานข้อมูล TTL ยาวประหยัดงานแต่เสี่ยงผลลัพธ์ล้าสมัย
คำแนะนำเชิงปฏิบัติ:
user:v3:123) เพื่อให้รูปแบบเก่าไม่ทำให้โค้ดใหม่เสียเมื่อคีย์ฮอตหมดอายุ หลายคำขออาจพลาดพร้อมกัน
การป้องกันที่นิยม:
ตัวที่เหมาะกับการแคชได้ดีได้แก่ ผลการตอบ API, ผลการคิวรีที่แพง, และ อ็อบเจ็กต์ที่คำนวณแล้ว (คำแนะนำ การคำนวณรวม) การแคชหน้า HTML เต็มๆ อาจใช้ได้ แต่ระวังการปรับแต่งตามผู้ใช้และสิทธิ์—ใช้การแคชแบบชิ้นส่วนเมื่อมีตรรกะเฉพาะผู้ใช้
Redis เป็นที่ใช้งานได้จริงสำหรับเก็บ สถานะการล็อกอินระยะสั้น: session IDs เมทาดาต้าของ refresh-token และแฟลก "จำอุปกรณ์นี้" เป้าหมายคือทำให้การยืนยันตัวตนเร็วขณะที่ควบคุมอายุเซสชันและการเพิกถอนอย่างเข้มงวด
รูปแบบทั่วไปคือ: แอปของคุณออก session ID แบบสุ่ม เก็บระเบียนกะทัดรัดใน Redis แล้วส่ง ID กลับไปยังเบราว์เซอร์เป็น HTTP-only cookie ในแต่ละคำขอ คุณจะมองหาคีย์เซสชันแล้วแนบตัวตนผู้ใช้และสิทธิ์เข้ากับ context ของคำขอนั้น
Redis ทำงานได้ดีที่นี่เพราะการอ่านเซสชันเกิดบ่อย และการหมดอายุของเซสชันมีในตัว
ออกแบบคีย์ให้สแกนและเพิกถอนได้ง่าย:
sess:{sessionId} → payload เซสชัน (userId, issuedAt, deviceId)user:sessions:{userId} → Set ของ session IDs ที่ใช้งานอยู่ (ตัวเลือก สำหรับ "ออกจากระบบทุกที่")ใช้ TTL บน sess:{sessionId} ที่ตรงกับอายุเซสชันของคุณ หากคุณหมุนเวียนเซสชัน (แนะนำ) ให้สร้าง session ID ใหม่และลบอันเก่าทันที
ระวังการใช้ "sliding expiration" (ยืด TTL ทุกคำขอ): มันอาจทำให้เซสชันคงอยู่ตลอดไปสำหรับผู้ใช้ที่ใช้งานหนัก ทางที่ปลอดภัยคือยืด TTL เฉพาะเมื่อใกล้จะหมดอายุ
เพื่อออกจากระบบอุปกรณ์เดียว ให้ลบ sess:{sessionId}
เพื่อออกจากระบบทุกอุปกรณ์ ให้ทำอย่างใดอย่างหนึ่ง:
user:sessions:{userId} หรือuser:revoked_after:{userId} เป็น timestamp และถือว่าเซสชันที่ออกก่อนหน้านั้นเป็นโมฆะวิธี timestamp ช่วยหลีกเลี่ยงการลบแบบ fan-out ขนาดใหญ่
เก็บข้อมูลเท่าที่จำเป็น—ชอบเก็บ ID มากกว่าข้อมูลส่วนบุคคล อย่าเก็บรหัสผ่านดิบหรือความลับที่มีอายุยาว หากต้องเก็บข้อมูลที่เกี่ยวกับโทเค็น ให้เก็บ hash และใช้ TTL ที่เข้มงวด
จำกัดผู้ที่สามารถเชื่อมต่อกับ Redis เปิดใช้งานการยืนยันตัวตน และเก็บ session IDs ให้มี entropy สูงเพื่อป้องกันการเดา
การจำกัดอัตราเป็นจุดที่ Redis โชว์ความแข็งแกร่ง: มันเร็ว แชร์ข้ามอินสแตนซ์ของแอป และมีการดำเนินการอะตอมิกที่ทำให้เคาน์เตอร์คงที่ภายใต้ทราฟิกหนาแน่น เหมาะสำหรับปกป้อง endpoints การล็อกอิน การค้นหาที่แพง การรีเซ็ตรหัสผ่าน และ API ใดๆ ที่อาจถูกขูดหรือโจมตีแบบ brute-force
Fixed window ง่ายที่สุด: "100 คำขอต่อนาที" นับคำขอในบัคเก็ตของนาทีปัจจุบัน ง่ายแต่อนุญาตให้เกิดระเบิดที่ขอบเขต (เช่น 100 คำขอที่ 12:00:59 และ 100 ที่ 12:01:00)
Sliding window ทำให้ขอบเรียบขึ้นโดยมองย้อนกลับ N วินาที/นาที แฟร์กว่า แต่มักมีต้นทุนสูงขึ้น (อาจต้องใช้ sorted sets หรือการเก็บบันทึกเพิ่มเติม)
Token bucket ดีสำหรับจัดการ burst ผู้ใช้ "หา" โทเคนเมื่อเวลาผ่านไปจนถึงขีดสุด; แต่ละคำขอใช้โทเคนหนึ่งอัน อนุญาต burst สั้นๆ พร้อมบังคับอัตราเฉลี่ย
รูปแบบ fixed-window ทั่วไปคือ:
INCR key เพื่อเพิ่มเคาน์เตอร์EXPIRE key window_seconds เพื่อตั้ง/รีเซ็ต TTLเคล็ดลับคือทำอย่างปลอดภัย หากคุณรัน INCR และ EXPIRE เป็นการเรียกสองครั้งแยกกัน การขัดข้องระหว่างคำสั่งทั้งสองอาจสร้างคีย์ที่ไม่มีวันหมดอายุ
แนวทางที่ปลอดภัยกว่าได้แก่:
INCR และตั้ง EXPIRE เมื่อคีย์ถูกสร้างครั้งแรกเท่านั้นSET key 1 EX <ttl> NX เพื่อเริ่มต้น แล้ว INCR ต่อ (มักห่อด้วยสคริปต์เพื่อหลีกเลี่ยง race)การดำเนินการแบบอะตอมิกสำคัญที่สุดเมื่อเกิดสไปก์ของทราฟิก: หากไม่มีมัน สองคำขออาจ "เห็น" โควต้าเท่ากันแล้วผ่านทั้งคู่
แอปส่วนใหญ่ต้องการหลายชั้น:
rl:user:{userId}:{route})สำหรับ endpoints ที่ระเบิดบ่อยๆ token bucket (หรือ fixed window ที่ใจกว้างพร้อมหน้าต่าง "burst" สั้นๆ) ช่วยไม่ให้ลงโทษสไปก์ที่ถูกต้องเช่นการโหลดหน้าเพจหรือการเชื่อมต่อมือถือใหม่
ตัดสินใจก่อนว่าความปลอดภัยหมายถึงอะไร:
ทางสายกลางที่พบบ่อยคือ fail-open สำหรับ routes ความเสี่ยงต่ำ และ fail-closed สำหรับจุดที่สำคัญ (ล็อกอิน รีเซ็ตรหัสผ่าน OTP) พร้อมมอนิเตอร์เพื่อสังเกตทันทีเมื่อการจำกัดอัตราหยุดทำงาน
Redis สามารถขับเคลื่อนงานพื้นหลังเมื่อต้องการคิวน้ำหนักเบาสำหรับส่งอีเมล ปรับขนาดรูป ซิงก์ข้อมูล หรือรันงานตามกำหนด หลักคือเลือกโครงสร้างข้อมูลที่เหมาะสมและตั้งกฎชัดเจนสำหรับ retry และการจัดการความล้มเหลว
Lists เป็นคิวที่ง่ายที่สุด: ผู้ผลิต LPUSH, worker BRPOP ง่ายแต่ต้องมีตรรกะเพิ่มสำหรับงาน "in-flight" retry และ visibility timeouts
Sorted sets โชว์ประสิทธิภาพเมื่อการจัดตารางเวลาเป็นเรื่องสำคัญ ใช้ score เป็น timestamp (หรือ priority) แล้ว worker ดึงงานที่ครบกำหนด เหมาะกับงานหน่วงเวลาและคิวลำดับความสำคัญ
Streams มักเป็นค่าเริ่มต้นที่ดีที่สุดสำหรับการแจกจ่ายงานอย่างทนทาน สนับสนุน consumer groups เก็บประวัติ และช่วยให้ worker หลายตัวประสานงานโดยไม่ต้องคิดระบบ "processing list" เอง
กับ Streams consumer groups worker อ่านข้อความแล้ว ACK มัน หาก worker ล้ม ข้อความจะคงเป็น pending และสามารถถูกเรียกร้องโดย worker อื่นได้
สำหรับ retry ให้ติดตามจำนวนครั้งพยายาม (ใน payload ของข้อความหรือคีย์ข้างเคียง) และใช้ exponential backoff (มักใช้ sorted set เป็น "retry schedule") หลังถึงขีดจำกัด ให้ย้ายงานไปยัง dead-letter queue (stream หรือ list อื่น) เพื่อตรวจสอบด้วยมือ
สมมติว่างานอาจรันซ้ำ ทำให้ handler idempotent โดย:
job:{id}:done) กับ SET ... NX ก่อนผลข้างเคียงเก็บ payload ให้เล็ก (เก็บข้อมูลใหญ่ที่อื่นแล้วส่ง reference) เพิ่ม backpressure โดยจำกัดความยาวคิว ชะลอผู้ผลิตเมื่อ lag โต และสเกล worker ตาม pending depth และเวลาประมวลผล
Redis Pub/Sub เป็นวิธีง่ายที่สุดในการกระจายเหตุการณ์: ผู้เผยแพร่ส่งข้อความไปยัง channel และผู้สมัครรับที่เชื่อมต่อทุกคนจะได้รับทันที ไม่มีการ polling—เป็นการ "push" เบาๆ ที่เหมาะสำหรับอัปเดตเรียลไทม์
Pub/Sub เหมาะเมื่อคุณให้ความสำคัญกับความเร็วและการแฟน-เอาท์ มากกว่าการรับประกันการส่งมอบ:
ภาพจำง่ายๆ: Pub/Sub เหมือนสถานีวิทยุ ใครที่กำลังฟังก็ได้ยิน แต่ไม่มีการบันทึกโดยอัตโนมัติ
Pub/Sub มีการแลกเปลี่ยนที่ควรพิจารณา:
เพราะเหตุนี้ Pub/Sub จึงไม่เหมาะกับเวิร์กโฟลว์ที่ทุกเหตุการณ์ต้องถูกประมวลผล (exactly once หรือแม้แต่ at least once)
ถ้าคุณต้องการ ความคงทน, retry, consumer groups, หรือ การจัดการ backpressure Redis Streams มักเป็นตัวเลือกที่ดีกว่า Streams เก็บเหตุการณ์ ให้คุณประมวลผลพร้อม acknowledgement และกู้คืนหลังสตาร์ทใหม่—ใกล้เคียงกับคิวข้อความน้ำหนักเบามากขึ้น
ในการติดตั้งจริงคุณจะมีหลายอินสแตนซ์ของแอปที่สมัครรับ นี่คือคำแนะนำเล็กน้อย:
app:{env}:{domain}:{event} (เช่น shop:prod:orders:created).notifications:global และเจาะจงผู้ใช้ด้วย notifications:user:{id}.เมื่อใช้อย่างนี้ Pub/Sub เป็นสัญญาณเหตุการณ์ที่เร็ว ขณะที่ Streams (หรือคิวอื่น) จัดการเหตุการณ์ที่คุณไม่สามารถยอมให้สูญหายได้
การเลือกโครงสร้างข้อมูลไม่ใช่แค่เรื่องว่า "อะไรทำงานได้"—มันกระทบการใช้หน่วยความจำ ความเร็วการคิวรี และความง่ายของโค้ดในระยะยาว กฎง่ายๆ คือเลือกโครงสร้างที่ตรงกับคำถามที่จะถามในอนาคต (รูปแบบการอ่าน) ไม่ใช่แค่การเก็บวันนี้
INCR/DECR.SISMEMBER เร็วและทำงานเซ็ตได้ง่ายคำสั่ง Redis เป็นอะตอมิกในระดับคำสั่ง ดังนั้นคุณจึงสามารถเพิ่มเคาน์เตอร์ได้อย่างปลอดภัยโดยไม่เกิด race การดูหน้าดูและเคาน์เตอร์การจำกัดอัตรามักใช้ strings กับ INCR และ expiry
Leaderboards เหมาะกับ sorted sets: อัปเดตคะแนน (ZINCRBY) และดึงผู้เล่นอันดับต้น (ZREVRANGE) ได้อย่างมีประสิทธิภาพโดยไม่ต้องสแกนทั้งหมด
ถ้าคุณสร้างคีย์จำนวนมากเช่น user:123:name, user:123:email, user:123:plan คุณเพิ่มค่า overhead ต่อคีย์และทำให้การจัดการคีย์ยากขึ้น
hash อย่าง user:123 ที่มีฟิลด์ (name, email, plan) รวมข้อมูลที่เกี่ยวข้องไว้ด้วยกันและมักลดจำนวนคีย์ได้ นอกจากนี้ยังทำให้การอัปเดตบางฟิลด์เป็นเรื่องง่ายขึ้น
เมื่อลังเล ให้จำลองตัวอย่างเล็กๆ และวัดการใช้หน่วยความจำก่อนตัดสินใจสำหรับข้อมูลปริมาณมาก
Redis มักถูกอธิบายว่า "in-memory" แต่คุณยังมีตัวเลือกสำหรับสิ่งที่จะเกิดขึ้นเมื่อโหนดรีสตาร์ท ดิสก์เต็ม หรือเซิร์ฟเวอร์หายไป การตั้งค่าที่เหมาะสมขึ้นกับว่าคุณยอมสูญเสียข้อมูลได้มากแค่ไหนและต้องกู้คืนเร็วแค่ไหน
RDB snapshots บันทึกจุดเวลาของ dataset เป็นภาพรวม กะทัดรัดและโหลดเร็วตอนสตาร์ท แต่คุณอาจสูญเสียการเขียนล่าสุดตั้งแต่ snapshot ล่าสุด
AOF (append-only file) บันทึกการเขียนแบบต่อเนื่อง ซึ่งมักลดการสูญเสียข้อมูล อาจทำให้ไฟล์ใหญ่ขึ้นและการเล่นซ้ำตอนสตาร์ทใช้เวลานานขึ้น แม้ Redis จะมีการ rewrite/compact ไฟล์ AOF เพื่อควบคุมขนาด
หลายทีมรัน ทั้งคู่: snapshot สำหรับรีสตาร์ทเร็ว และ AOF สำหรับความทนทานของการเขียนที่ดีกว่า
การคงอยู่ไม่ฟรี การเขียนลงดิสก์ นโยบาย fsync ของ AOF และการ rewrite พื้นหลังอาจเพิ่ม latency แบบสไปก์ถ้าสตอเรจช้า แต่การคงข้อมูลทำให้การรีสตาร์ทน่ากลัวน้อยลง: หากไม่มีการคงข้อมูล รีสตาร์ทแบบไม่คาดคิดหมายถึง Redis ว่างเปล่า
การทำสำเนาเก็บสำเนาของข้อมูลบน replica เพื่อให้ failover ได้ เป้าหมายมักเป็น availability เป็นอันดับแรก ไม่ใช่ความสอดคล้องสมบูรณ์ ภายใต้ความล้มเหลว replicas อาจช้ากว่าเล็กน้อย และการ failover อาจสูญเสียการเขียนที่เพิ่งยืนยัน
ก่อน tuning ใดๆ ให้เขียนตัวเลขสองค่าลง:
ใช้ตัวเลขเหล่านี้ในการเลือกความถี่ RDB, การตั้งค่า AOF และการตัดสินใจว่าคุณต้องการ replica (และ failover อัตโนมัติ) สำหรับบทบาท Redis แต่ละแบบ—cache, session store, queue หรือ primary data store
โหนด Redis เดียวพาคุณไปได้ไกลกว่าที่คิด: ง่ายต่อการปฏิบัติการ ตรรกะเรียบง่าย และมักเร็วพอสำหรับแคช เซสชัน หรือคิวหลายงาน
การสเกลจำเป็นเมื่อคุณถึงข้อจำกัดที่ชัดเจน—โดยปกติคือเพดานหน่วยความจำ, CPU อิ่มตัว, หรือโหนดเดี่ยวเป็น single point of failure ที่คุณยอมรับไม่ได้
พิจารณาเพิ่มโหนดเมื่อหนึ่งในสถานการณ์เหล่านี้เกิดขึ้น:
ขั้นตอนปฏิบัติที่มักเริ่มคือ แยกงาน (สองอินสแตนซ์ Redis แยกกัน) ก่อนที่จะขึ้นไปสู่คลัสเตอร์
Sharding คือการแบ่งคีย์ข้ามโหนด Redis หลายตัวเพื่อให้แต่ละโหนดเก็บเพียงส่วนหนึ่งของข้อมูล Redis Cluster คือวิธีในตัวของ Redis ที่ทำเรื่องนี้อัตโนมัติ: keyspace แบ่งเป็น slots และแต่ละโหนดเป็นเจ้าของบางสลอต
ข้อดีคือเพิ่มหน่วยความจำรวมและ throughput รวม ข้อเสียคือตัวเพิ่มความซับซ้อน: การดำเนินการหลายคีย์ถูกจำกัด (คีย์ต้องอยู่บน shard เดียวกัน) และการแก้ปัญหาต้องเจอหลายส่วนเคลื่อนไหว
แม้จะ sharding อย่างเท่าเทียม แต่ทราฟิกจริงอาจเอียงไปที่คีย์เดียว คีย์ยอดนิยม (hot key) อาจทำให้โหนดหนึ่งโอเวอร์โหลดในขณะที่โหนดอื่นว่าง
การบรรเทาปัญหารวมถึงการเพิ่ม TTL สั้นพร้อม jitter แยกค่ายค่าระหว่างหลายคีย์ (key hashing) หรือออกแบบรูปแบบการเข้าถึงใหม่เพื่อกระจายการอ่าน
Redis Cluster ต้องการไคลเอนต์ที่รู้จักคลัสเตอร์ที่สามารถค้นหา topology, routing คำขอไปยังโหนดที่ถูกต้อง และตาม redirections เมื่อ slots ย้าย
ก่อนย้าย ให้ยืนยันว่า:
การสเกลทำงานได้ดีที่สุดเมื่อเป็นการวิวัฒนาการที่วางแผน: ตรวจสอบด้วย load test ติดตั้งการมอนิเตอร์ latency ของคีย์ และค่อยๆ ย้ายทราฟิก แทนการสลับทั้งหมดในครั้งเดียว
Redis มักถูกมองว่าเป็น "งานภายใน" ซึ่งทำให้มันเป็นเป้าหมายบ่อย: พอร์ตที่เปิดเดียวอาจกลายเป็นการรั่วไหลของข้อมูลทั้งหมดหรือการควบคุม cache โดยผู้โจมตี สมมติว่า Redis เป็นโครงสร้างพื้นฐานที่ละเอียดอ่อน แม้จะเก็บข้อมูล "ชั่วคราว" ก็ตาม
เริ่มจากเปิดใช้งานการยืนยันตัวตนและใช้ ACLs (Redis 6+) ACLs ช่วยให้คุณ:
หลีกเลี่ยงการแชร์รหัสผ่านชุดเดียวระหว่างทุกองค์ประกอบ ออก credential ต่อบริการและจำกัดสิทธิ์ให้แคบ
การควบคุมที่มีประสิทธิภาพที่สุดคือ ไม่ให้เข้าถึงได้ ผูก Redis กับอินเทอร์เฟซส่วนตัว วางไว้ในซับเน็ตส่วนตัว และจำกัดการเข้าใช้งานด้วย security groups/firewalls เฉพาะบริการที่จำเป็น
ใช้ TLS เมื่อทราฟิก Redis ข้ามขอบเขตโฮสต์ที่คุณไม่ได้ควบคุมอย่างเต็มที่ (multi-AZ, เครือข่ายที่แชร์, โหนด Kubernetes หรือสภาพแวดล้อมแบบไฮบริด) TLS ป้องกันการสไนฟ์และการขโมย credential คุ้มค่ากับ overhead เล็กน้อยสำหรับเซสชัน โทเค็น หรือข้อมูลที่เกี่ยวกับผู้ใช้
ล็อกดาวน์คำสั่งที่อาจก่อความเสียหายหากถูกใช้ในทางที่ผิด ตัวอย่างทั่วไปที่ควรปิดหรือจำกัดด้วย ACLs: FLUSHALL, FLUSHDB, CONFIG, SAVE, DEBUG, และ EVAL (หรืออย่างน้อยควบคุมการใช้สคริปต์อย่างระมัดระวัง) นอกจากนี้ระวังวิธี rename-command—ACLs มักชัดเจนและง่ายต่อการตรวจสอบ
เก็บ credential ของ Redis ในตัวจัดการความลับ (ไม่ใช่ในโค้ดหรืออิมเมจคอนเทนเนอร์) และวางแผนการหมุนเวียน การหมุนเวียนง่ายขึ้นเมื่อไคลเอนต์สามารถโหลด credential ใหม่โดยไม่ต้อง redeploy หรือรองรับ credential สองตัวในช่วงเปลี่ยนผ่าน
หากต้องการเช็คลิสต์เชิงปฏิบัติ เก็บไว้ใน runbook ควบคู่กับบันทึก /blog/monitoring-troubleshooting-redis
Redis มัก "ดูดี" … จนกว่าทราฟิกจะเปลี่ยน หน่วยความจำไต่ขึ้น หรือคำสั่งช้าแขวนทุกอย่าง รูทีนการมอนิเตอร์เบาๆ และเช็คลิสต์เหตุการณ์ชัดเจนป้องกันความประหลาดใจส่วนใหญ่
เริ่มจากชุดเล็กที่อธิบายให้ทุกคนในทีมเข้าใจได้:
เมื่อบางอย่าง "ช้า" ยืนยันด้วยเครื่องมือของ Redis:
KEYS, SMEMBERS, หรือ LRANGE ขนาดใหญ่ เป็นสัญญาณเตือนถ้า latency พุ่งขณะที่ CPU ปกติ ให้พิจารณาเครือข่ายอิ่มตัว payload ใหญ่ หรือ client ถูกบล็อก
วางแผนการเติบโตโดยเก็บ headroom (มัก 20–30% หน่วยความจำว่าง) และทบทวนสมมติฐานหลังการเปิดตัวหรือฟีเจอร์ใหม่ ถือว่า "evictions ต่อเนื่อง" เป็นเหตุการณ์ฉุกเฉิน ไม่ใช่คำเตือน
ระหว่างเหตุการณ์ ให้ตรวจ (ตามลำดับ): memory/evictions, latency, client connections, slowlog, replication lag, และการ deploy ล่าสุด เขียนสาเหตุที่เกิดซ้ำสูงสุดลงแล้วแก้ไขถาวร—การตั้งเตือนอย่างเดียวไม่พอ
ถ้าทีมของคุณ iterate อย่างรวดเร็ว ควรรวมความคาดหวังการปฏิบัติการเหล่านี้เข้าใน workflow การพัฒนา เช่น ใน Koder.ai โหมดวางแผนและ snapshot/rollback คุณสามารถต้นแบบฟีเจอร์ที่ใช้ Redis (แคชหรือการจำกัดอัตรา), ทดสอบภายใต้โหลด, และย้อนกลับการเปลี่ยนแปลงอย่างปลอดภัย—ในขณะที่เก็บการใช้งานในโค้ดของคุณผ่านการส่งออกซอร์สโค้ด
Redis เหมาะเป็นชั้นความเร็วในหน่วยความจำที่ใช้ร่วมกันสำหรับ:
ใช้ฐานข้อมูลหลักสำหรับข้อมูลที่ต้องเก็บถาวรและการคิวรีซับซ้อน คิดว่า Redis เป็นตัวเร่งความเร็วและตัวประสาน ไม่ใช่ระบบบันทึกหลักของคุณ
ไม่ใช่ Redis อาจเก็บได้ แต่ไม่ใช่ "ทนทานโดยค่าเริ่มต้น" ถ้าคุณต้องการการคิวรีซับซ้อน การรับประกันความทนทานสูง หรือการวิเคราะห์/รายงาน ให้เก็บข้อมูลเหล่านั้นในฐานข้อมูลหลักของคุณ
หากการสูญเสียข้อมูลแม้แต่ไม่กี่วินาทีก็รับไม่ได้ อย่าสมมติว่าการตั้งค่าความคงทนของ Redis จะเพียงพอโดยไม่ปรับแต่งอย่างรอบคอบ (หรือพิจารณาใช้ระบบอื่นสำหรับงานนั้น)
ตัดสินใจตามระดับการสูญเสียข้อมูลที่ยอมรับได้และพฤติกรรมการกู้คืน:
จด RPO/RTO ของคุณก่อน แล้วปรับการตั้งค่าความคงทนให้สอดคล้อง
ในแนวทาง cache-aside แอปของคุณเป็นคนควบคุมลอจิก:
วิธีนี้เหมาะเมื่อแอปรับได้กับการพลาดเป็นครั้งคราวและคุณมีแผนชัดเจนเรื่องการหมดอายุ/ยกเลิก
เลือก TTL โดยพิจารณาจากผลกระทบต่อผู้ใช้และภาระที่แบ็กเอนด์:
user:v3:123) เมื่อรูปแบบข้อมูลแคชอาจเปลี่ยนถ้าไม่แน่ใจ เริ่มด้วย TTL สั้น วัดภาระฐานข้อมูล แล้วปรับ
ใช้วิธีหนึ่งหรือหลายวิธีเหล่านี้:
รูปแบบเหล่านี้ช่วยป้องกันการพลาดพร้อมกันของแคชที่สร้างภาระบนฐานข้อมูล
วิธีทั่วไปคือ:
sess:{sessionId} พร้อม TTL ที่ตรงกับอายุเซสชันuser:sessions:{userId} เป็น Set ของ session IDs ที่ใช้งานอยู่สำหรับฟีเจอร์ "ออกจากระบบทุกที่"หลีกเลี่ยงการขยาย TTL บนทุกคำขอ ("sliding expiration") เว้นแต่จะควบคุมได้เช่น ขยายเฉพาะเมื่อใกล้จะหมดอายุ
ใช้การอัพเดตแบบอะตอมิกเพื่อไม่ให้ตัวนับติดหรือเกิดการชน:
INCR และ EXPIRE เป็นสองคำสั่งแยกที่ไม่มีการป้องกันกำหนดขอบเขตคีย์ให้ชัด (per-user, per-IP, per-route) และตัดสินใจล่วงหน้าว่าจะ หรือ เมื่อ Redis ไม่พร้อม—โดยเฉพาะสำหรับจุดที่ละเอียดอ่อนเช่น การล็อกอิน
เลือกตามความต้องการด้านความทนทานและการปฏิบัติการ:
LPUSH / BRPOP): ง่าย แต่ต้องสร้างลอจิกสำหรับงานที่กำลังประมวลผล (in-flight), retry และ visibility timeouts เองใช้ Pub/Sub เมื่อคุณต้องการการแพร่สัญญาณเร็วที่ยอมให้พลาดข้อความได้ (presence, live dashboards). ข้อจำกัดคือ:
หากต้องการให้ทุกเหตุการณ์ถูกประมวลผล ให้ใช้ Redis Streams แทน—มี durability, consumer groups, retry และการจัดการ backpressure
สำหรับแนวทางการปฏิบัติ ให้ล็อก Redis ด้วย ACLs/การแยกเครือข่ายและติดตาม latency/evictions; เก็บ runbook เช่น
เก็บ payload ให้เล็ก เก็บข้อมูลขนาดใหญ่ที่อื่นแล้วส่งเฉพาะ reference
/blog/monitoring-troubleshooting-redis