ทำไม REST ของ Roy Fielding ยังคงสำคัญ
Roy Fielding ไม่ใช่แค่ชื่อที่ผูกกับคำฮิตของ API เท่านั้น เขาเป็นหนึ่งในผู้เขียนหลักของสเปก HTTP และ URI และในวิทยานิพนธ์ปริญญาเอกของเขาได้อธิบายสไตล์สถาปัตยกรรมที่เรียกว่า REST (Representational State Transfer) เพื่ออธิบายว่าทำไมเว็บจึงทำงานได้ดีอย่างที่เป็นอยู่
ต้นกำเนิดนี้มีความหมายเพราะ REST ไม่ได้ถูกคิดขึ้นมาเพื่อทำให้ "endpoints ดูสวย" มันเป็นวิธีอธิบายข้อจำกัดที่ทำให้เครือข่ายขนาดโลกที่ยุ่งเหยิงยังสามารถสเกลได้: ลูกค้าจำนวนมาก เซิร์ฟเวอร์จำนวนมาก ตัวกลาง การแคช ความล้มเหลวบางส่วน และการเปลี่ยนแปลงอย่างต่อเนื่อง
สิ่งที่คุณจะได้จากบทความนี้
ถ้าคุณเคยสงสัยว่าทำไมสอง "REST APIs" ถึงให้ความรู้สึกต่างกันอย่างสิ้นเชิง—หรือทำไมการเลือกออกแบบเล็กๆ ในตอนแรกจึงกลายเป็นปัญหาการแบ่งหน้า ความสับสนเรื่องแคช หรือการเปลี่ยนแปลงที่ทำให้พังในภายหลัง—คู่มือนี้มีไว้เพื่อลดความเซอร์ไพรส์เหล่านั้น
คุณจะได้:
- การตัดสินใจที่ชัดเจนขึ้นเมื่อออกแบบหรือประเมิน API
- คำศัพท์ที่ดีขึ้นสำหรับการถกเถียงเรื่องการแลกเปรียบกับทีม
- ความรู้เชิงปฏิบัติว่าแนวคิด REST ใดสำคัญที่สุดในโปรเจกต์จริง
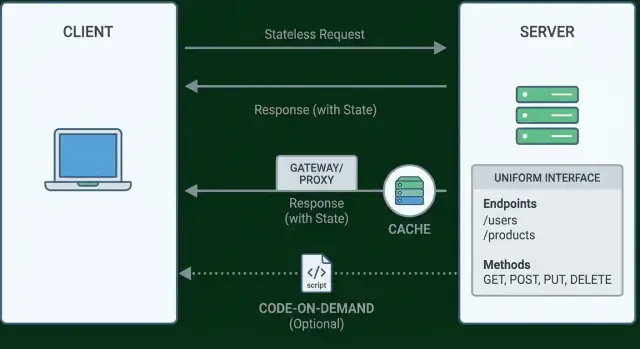
REST ในหนึ่งหน้า: สไตล์ ไม่ใช่มาตรฐาน
REST ไม่ใช่เช็คลิสต์ ไม่ใช่โปรโตคอล และไม่ใช่การรับรอง Fielding อธิบายมันว่าเป็น สไตล์สถาปัตยกรรม: ชุดของข้อจำกัดที่เมื่อประยุกต์ร่วมกันจะสร้างระบบที่สเกลได้เหมือนเว็บ—ใช้งานง่าย พัฒนาได้เมื่อเวลาผ่านไป และเป็นมิตรกับตัวกลาง (พร็อกซี แคช เกตเวย์) โดยไม่ต้องประสานงานตลอดเวลา
ปัญหาที่ REST แก้
เว็บยุคแรกต้องทำงานข้ามองค์กร เซิร์ฟเวอร์ เครือข่าย และประเภทไคลเอ็นต์ต่างๆ มันต้องเติบโตโดยไม่มีการควบคุมส่วนกลาง อยู่รอดจากความล้มเหลวบางส่วน และอนุญาตให้ฟีเจอร์ใหม่ๆ ปรากฏโดยไม่ทำให้ของเก่าพัง REST ตอบโจทย์นี้โดยเน้นแนวคิดที่แชร์กันกว้าง (เช่น ตัวระบุ ตัวแทน และการดำเนินการมาตรฐาน) แทนการผูกมัดแบบเฉพาะทางและแน่นหนา
“ข้อจำกัดเชิงสถาปัตยกรรม” แบบเข้าใจง่าย
ข้อจำกัดคือกฎที่จำกัดอิสระในการออกแบบเพื่อแลกกับผลประโยชน์ ตัวอย่างเช่น คุณอาจ สละ สถานะเซิร์ฟเวอร์ฝั่งเซิร์ฟเวอร์เพื่อให้คำขอใดก็ได้ถูกจัดการโดยโหนดเซิร์ฟเวอร์ใดก็ได้ ซึ่งช่วยปรับปรุงความน่าเชื่อถือและการสเกล ข้อจำกัดแต่ละข้อของ REST ทำการแลกแบบเดียวกัน: ความยืดหยุ่นแบบสุ่มน้อยลง ความสามารถทำนายและพัฒนาได้มากขึ้น
REST กับ API ที่ “เหมือน REST”
หลาย API บน HTTP นำแนวคิดของ REST มาใช้ (JSON ผ่าน HTTP, URL แบบ endpoint, บางทีก็ใช้รหัสสถานะ) แต่ไม่ได้ใช้ชุดข้อจำกัดทั้งหมด นั่นไม่ใช่ "ผิด"—มักสะท้อนกำหนดเวลาโปรดักต์หรือความต้องการภายในเท่านั้น เพียงแต่มีประโยชน์ที่จะเรียกความแตกต่างนี้: API สามารถเป็น มุ่งทรัพยากร โดยไม่จำเป็นต้องเป็น REST เต็มรูปแบบ
แบบจำลองทางใจก้อนเดียว
คิดถึงระบบ REST ว่าเป็น ทรัพยากร (สิ่งที่คุณตั้งชื่อด้วย URL) ที่ไคลเอ็นต์โต้ตอบผ่าน representation (มุมมองปัจจุบันของทรัพยากร เช่น JSON หรือ HTML) โดยมี ลิงก์ นำทาง (การกระทำต่อไปและทรัพยากรที่เกี่ยวข้อง) ไคลเอ็นต์ไม่ต้องมีกฎความลับนอกแบนด์; มันตามเซแมนติกมาตรฐานและนำทางด้วยลิงก์ เหมือนที่เบราว์เซอร์เคลื่อนผ่านเว็บ
ทรัพยากรและ representation: คลังคำศัพท์หลัก
ก่อนจะหลงในข้อจำกัดและรายละเอียด HTTP REST เริ่มจากการเปลี่ยนกรอบความคิดง่ายๆ: คิดในแง่ ทรัพยากร ไม่ใช่ การกระทำ
ทรัพยากร = คำนามที่ระบุได้
ทรัพยากร คือสิ่งที่สามารถระบุในระบบของคุณ: ผู้ใช้ ใบแจ้งหนี้ หมวดหมู่สินค้า ตะกร้าสินค้า ส่วนสำคัญคือมันเป็น คำนาม ที่มีเอกลักษณ์
นั่นเป็นเหตุผลที่ /users/123 อ่านได้อย่างเป็นธรรมชาติ: มันระบุ ผู้ใช้ที่มี ID 123 เทียบกับ URL แบบคำสั่งเช่น /getUser หรือ /updateUserPassword ซึ่งอธิบาย คำกริยา—การดำเนินการ—ไม่ใช่สิ่งที่ดำเนินการบนมัน
REST ไม่ได้บอกว่าคุณไม่สามารถดำเนินการได้ มันบอกว่าการกระทำควรถูกแสดงผ่าน uniform interface (สำหรับ API บน HTTP มักหมายถึงเมธอดอย่าง GET/POST/PUT/PATCH/DELETE) ที่กระทำบนตัวระบุทรัพยากร
Representation = มุมมองของทรัพยากร
Representation คือสิ่งที่คุณส่งผ่านเครือข่ายเป็น snapshot หรือมุมมองของทรัพยากรในช่วงเวลาเดียวกัน ทรัพยากรเดียวกันสามารถมี representation หลายแบบได้
ตัวอย่างเช่น ทรัพยากร /users/123 อาจถูกนำเสนอเป็น JSON สำหรับแอป หรือเป็น HTML สำหรับเบราว์เซอร์
GET /users/123
Accept: application/json
อาจคืนค่า:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
ในขณะที่:
GET /users/123
Accept: text/html
อาจคืนหน้า HTML ที่เรนเดอร์ข้อมูลผู้ใช้เช่นเดียวกัน
แนวคิดสำคัญ: ทรัพยากรไม่ใช่ JSON และมันไม่ใช่ HTML นั่นเป็นเพียงฟอร์แมตที่ใช้เพื่อแทนมันเท่านั้น
ทำไมกรอบความคิดนี้เปลี่ยนการออกแบบ API
เมื่อคุณมอง API ของคุณรอบทรัพยากรและ representation การตัดสินใจเชิงปฏิบัติหลายอย่างจะง่ายขึ้น:
- การตั้งชื่อคงที่ขึ้น.
/users/123 ยังคงใช้งานได้แม้ UI, เวิร์กโฟลว์ หรือโมเดลข้อมูลของคุณจะพัฒนา
- Endpoints ง่ายขึ้น. แทนที่จะสร้าง URL ใหม่สำหรับทุกการดำเนินการ คุณนำ URL ทรัพยากรกลับมาใช้และเปลี่ยนเมธอดหรือ representation
- โค้ดไคลเอ็นต์หลวมขึ้น. ไคลเอ็นต์มุ่งที่ "ดึงผู้ใช้" หรือ "อัปเดตฟิลด์บนผู้ใช้" แทนการจำรายการ endpoint การกระทำ
แนวคิดมุ่งทรัพยากรนี้เป็นฐานที่ข้อจำกัดของ REST สร้างขึ้น หากไม่มีมัน "REST" มักกลายเป็นแค่ "JSON บน HTTP ที่มีรูปแบบ URL ดีๆ"
ข้อจำกัด 1: การแยก Client–Server
การแยก client–server คือวิธีของ REST ในการบังคับการแบ่งความรับผิดชอบที่ชัดเจน ไคลเอ็นต์มุ่งที่ประสบการณ์ผู้ใช้ (สิ่งที่คนเห็นและทำ) ขณะที่เซิร์ฟเวอร์มุ่งที่ข้อมูล กฎ และการเก็บถาวร (สิ่งที่เป็นจริงและสิ่งที่อนุญาต) เมื่อคุณแยกความกังวลเหล่านี้แต่ละฝ่ายสามารถเปลี่ยนได้โดยไม่ต้องเขียนใหม่ทั้งคู่
อะไรอยู่บน client เทียบกับ server?
ในเชิงปฏิบัติ client คือ "เลเยอร์นำเสนอ": หน้าจอ การนำทาง การตรวจสอบแบบฟอร์มเพื่อฟีดแบ็กเร็ว และพฤติกรรม UI แบบ optimistic (เช่น แสดงคอมเมนต์ใหม่ทันที) เซิร์ฟเวอร์คือ "แหล่งความจริง": การพิสูจน์ตัวตน การให้สิทธิ์ กฎธุรกิจ การเก็บข้อมูล การตรวจสอบ และสิ่งที่ต้องคงความสอดคล้องข้ามอุปกรณ์
กฎการปฏิบัติ: ถ้าการตัดสินใจมีผลต่อความปลอดภัย เงิน สิทธิ์ หรือความสอดคล้องของข้อมูลร่วม ให้วางไว้บนเซิร์ฟเวอร์ ถ้าการตัดสินใจมีผลต่อความรู้สึกของประสบการณ์ (เลย์เอาต์ เคล็ดลับอินพุตท้องถิ่น สถานะการโหลด) ให้วางไว้บน client
ทำไมมันเข้ากับรูปแบบแอปสมัยใหม่
ข้อจำกัดนี้สอดคล้องตรงกับเซ็ตอัพทั่วไป:
- SPA + API: เว็บแอป (React/Vue/ฯลฯ) ปรับปรุง UI ในขณะที่ API ยังคงให้บริการทรัพยากร
- แอปมือถือ: ไคลเอ็นต์ iOS และ Android แบ่งปันกฎและ endpoints เดียวกัน
- การรวมของบุคคลที่สาม: พาร์ทเนอร์ใช้ความสามารถของเซิร์ฟเวอร์โดยไม่ต้องใช้ UI ของคุณ
การแยก client–server คือสิ่งที่ทำให้ "หนึ่ง backend หลาย frontend" เป็นเรื่องจริง
กับดักทั่วไป: รั่วไหลของสถานะ UI ลงเซสชันบนเซิร์ฟเวอร์
ความผิดพลาดที่พบบ่อยคือการเก็บสถานะเวิร์กโฟลว์ของ UI บนเซิร์ฟเวอร์ (เช่น: "ผู้ใช้กำลังอยู่ในขั้นตอนที่เท่าไรของการเช็คเอาต์") ในเซสชันฝั่งเซิร์ฟเวอร์ นั่นผูก backend กับโฟลว์หน้าจอเฉพาะและทำให้การสเกลยากขึ้น
แนะนำให้ส่งบริบทที่จำเป็นกับแต่ละคำขอ (หรืออนุมานจากทรัพยากรที่เก็บไว้) เพื่อให้เซิร์ฟเวอร์ยังคงมุ่งที่ทรัพยากรและกฎ—ไม่ใช่การจำว่า UI เฉพาะกำลังอยู่ที่ขั้นตอนไหน
ข้อจำกัด 2: การโต้ตอบแบบไร้สถานะ (Stateless)
Statelessness หมายถึงเซิร์ฟเวอร์ไม่จำเป็นต้องจำอะไรเกี่ยวกับไคลเอ็นต์ระหว่างคำขอ แต่ละคำขอต้องมีข้อมูลทั้งหมดที่จำเป็นเพื่อให้เข้าใจและตอบกลับอย่างถูกต้อง—ใครเป็นผู้เรียก ผู้เรียกร้องอะไร และบริบทใดที่ต้องใช้ในการประมวลผล
ทำไมเรื่องนี้จึงสำคัญ
เมื่อคำขอเป็นอิสระ คุณสามารถเพิ่มหรือลบเซิร์ฟเวอร์หลัง load balancer โดยไม่ต้องกังวลว่า "เซิร์ฟเวอร์ไหนรู้จัก session ของฉัน" ซึ่งช่วยปรับปรุงการสเกลและความทนทาน: อินสแตนซ์ใดก็ได้สามารถจัดการคำขอใดก็ได้
มันยังทำให้งานปฏิบัติการง่ายขึ้น การดีบักมักง่ายขึ้นเพราะบริบทเต็มอยู่ในคำขอ (และล็อก) แทนที่จะซ่อนในหน่วยความจำเซสชันของเซิร์ฟเวอร์
การแลกเปลี่ยนที่คุณจะรู้สึกใน API จริง
API แบบ stateless มักส่งข้อมูลมากขึ้นต่อการเรียก แทนที่จะพึ่งพาเซสชันเซิร์ฟเวอร์ ไคลเอ็นต์รวมข้อมูลรับรองและบริบททุกครั้ง
คุณยังต้องชัดเจนเรื่องฟลōวที่ต้องมีสถานะ (เช่น การแบ่งหน้า หรือการเช็คเอาต์หลายขั้นตอน) REST ไม่ห้ามประสบการณ์หลายขั้นตอน—แต่มันผลักสถานะไปยังไคลเอ็นต์หรือทรัพยากรบนเซิร์ฟเวอร์ที่มีตัวระบุและดึงคืนได้
รูปแบบปฏิบัติ (และปัญหาที่แก้ได้)
- โทเค็นพิสูจน์ตัวตน (เช่น Bearer JWT): แต่ละคำขอมีเฮดเดอร์
Authorization: Bearer … เพื่อให้เซิร์ฟเวอร์ใดก็ได้สามารถตรวจสอบได้
- Idempotency keys: สำหรับการดำเนินการเช่น "สร้างการชำระเงิน" ไคลเอ็นต์ส่ง
Idempotency-Key เพื่อให้การลองใหม่ไม่สร้างงานซ้ำโดยไม่ตั้งใจ
- Correlation IDs: เฮดเดอร์อย่าง
X-Correlation-Id ช่วยให้ติดตามการกระทำของผู้ใช้ข้ามบริการและล็อกได้ แม้ในระบบกระจาย
สำหรับการแบ่งหน้า หลีกเลี่ยงการให้เซิร์ฟเวอร์ "จำหน้าที่ 3" ให้ใช้พารามิเตอร์ชัดเจนเช่น ?cursor=abc หรือ next link ที่ไคลเอ็นต์ตามได้ เก็บสถานะการนำทางในคำตอบแทนที่จะเก็บในหน่วยความจำเซิร์ฟเวอร์
ข้อจำกัด 3: การตอบกลับที่แคชได้
การแคชคือการนำคำตอบก่อนหน้ากลับมาใช้ใหม่อย่างปลอดภัยเพื่อให้ไคลเอ็นต์ (หรือบางสิ่งระหว่างทาง) ไม่ต้องถามเซิร์ฟเวอร์คุณซ้ำอีก หากทำดีจะลดเวลาแฝงให้ผู้ใช้และลดโหลดให้ระบบ—โดยไม่เปลี่ยนความหมายของ API
“แคชได้” หมายถึงอะไรในทางปฏิบัติ
การตอบกลับแคชได้เมื่อปลอดภัยที่คำขออื่นจะได้รับ payload เดิมภายในช่วงเวลาหนึ่ง บน HTTP คุณสื่อสารเจตนานั้นด้วยเฮดเดอร์การแคช:
Cache-Control: สวิตช์หลัก (เก็บนานแค่ไหน เก็บโดยแคชแบบแชร์ได้หรือไม่ ฯลฯ)ETag และ Last-Modified: ตัวตรวจสอบที่ให้ไคลเอ็นต์ถามว่า "มันเปลี่ยนไหม" และได้คำตอบราคาถูกว่า "ไม่เปลี่ยน"Expires: วิธีเก่าที่ใช้แสดงความสด ยังพบเห็นได้บ้าง
นี่มากกว่าการ "แคชของเบราว์เซอร์" ตัวกลางอย่างพร็อกซี CDN API gateway และแม้แต่แอปมือถือก็สามารถใช้คำตอบซ้ำได้เมื่อกฎชัดเจน
อะไรที่มักแคชได้ (และอะไรไม่ควร)
ผู้สมัครที่ดี:
- ข้อมูลสาธารณะที่เหมือนกันสำหรับทุกคน (แคตาล็อกสินค้า เอกสาร หมุดฟีเจอร์ที่ไม่ผูกผู้ใช้)
- ทรัพยากรแบบอ่านอย่างเดียวที่เปลี่ยนไม่บ่อย (การตั้งค่าคงที่ ข้อมูลอ้างอิง)
- การตอบกลับ GET ที่ไม่พึ่งพาคุกกี้หรือการพิสูจน์ตัวตน
ผู้สมัครที่ไม่ดี:
- ข้อมูลส่วนบุคคลผูกกับบัญชี (โปรไฟล์ คำสั่งซื้อ ข้อความ)
- การตอบกลับที่เกี่ยวกับการพิสูจน์ตัวตน (แลกโทเค็น สถานะเซสชัน)
- ทุกอย่างที่เปลี่ยนตามผู้ใช้ เว้นแต่จัดการอย่างชัดเจน (เช่น กฎ
private)
ผลลัพธ์เชิงปฏิบัติที่คุณจะสังเกต
- หน้าเร็วขึ้นและแอปตอบสนองดีขึ้น (รอน้อยลง)
- ค่าใช้จ่ายเซิร์ฟเวอร์และฐานข้อมูลต่ำลง (คำนวณซ้ำลดลง)
- เหตุการณ์ "เกินขีดจำกัดคำขอ" ลดลง (การอ่านแบบแคชช่วยลดปริมาณคำขอ)
แนวคิดสำคัญ: การแคชไม่ใช่สิ่งที่มาทีหลัง มันเป็นข้อจำกัดของ REST ที่ให้รางวัลกับ API ที่สื่อสารความสดและการตรวจสอบอย่างชัดเจน
Uniform interface มักถูกเข้าใจผิดว่าเป็นแค่ "ใช้ GET เพื่ออ่าน และ POST เพื่อสร้าง" นั่นเป็นเพียงส่วนเล็กๆ ความคิดของ Fielding ใหญ่กว่านั้น: API ควรรู้สึกสม่ำเสมอพอที่ไคลเอ็นต์ไม่ต้องมีความรู้พิเศษเป็นราย endpoint เพื่อใช้งาน
-
การระบุทรัพยากร: ตั้งชื่อ สิ่งต่างๆ (ทรัพยากร) ด้วยตัวระบุที่คงที่ (มักเป็น URLs) ไม่ใช่การกระทำ คิด /orders/123 แทน /createOrder
-
การจัดการผ่าน representation: ไคลเอ็นต์เปลี่ยนทรัพยากรโดยส่ง representation (JSON, HTML ฯลฯ) เซิร์ฟเวอร์ควบคุมทรัพยากร ไคลเอ็นต์แลกเปลี่ยน representation ของมัน
-
ข้อความที่บรรยายตัวเองได้: แต่ละคำขอ/คำตอบควรมีข้อมูลพอที่จะเข้าใจวิธีประมวลผล—เมธอด รหัสสถานะ เฮดเดอร์ media type และ body ที่ชัดเจน หากความหมายซ่อนอยู่ในเอกสารนอกแบนด์ ไคลเอ็นต์จะผูกกับเซิร์ฟเวอร์มากขึ้น
-
Hypermedia (HATEOAS): การตอบกลับควรรวมลิงก์และการกระทำที่อนุญาตเพื่อให้ไคลเอ็นต์สามารถทำตามเวิร์กโฟลว์โดยไม่ต้องเข้ารหัส URL ทุกตัว
ทำไมมันลดการผูกกัน
อินเทอร์เฟซที่สม่ำเสมอทำให้ไคลเอ็นต์พึ่งพารายละเอียดภายในเซิร์ฟเวอร์น้อยลง เมื่อเวลาผ่านไป นั่นหมายถึงการเปลี่ยนแปลงพังน้อยลง กรณีพิเศษน้อยลง และงานซ่อมน้อยลงเมื่อทีมพัฒนา endpoint
เฮียวริสติกส์ที่ใช้ได้จริง
- ใช้รหัสสถานะสม่ำเสมอ: เช่น
200 สำหรับการอ่านสำเร็จ, 201 สำหรับทรัพยากรถูกสร้าง (พร้อม Location), 400 สำหรับปัญหาการตรวจสอบ, 401/403 สำหรับ auth, 404 เมื่อทรัพยากรไม่มี
- มาตรฐานรูปแบบข้อผิดพลาดของคุณ ทั่ว API เช่นฟิลด์
code, message, details, requestId
- ให้ media types และ headers มีความหมาย (
Content-Type, เฮดเดอร์การแคช) เพื่อให้ข้อความอธิบายตัวเอง
Uniform interface เกี่ยวกับ ความสามารถทำนายได้และการพัฒนาได้ ไม่ใช่แค่ "ใช้เมธอดให้ถูก"
ข้อความที่บรรยายตัวเองได้: การออกแบบเพื่อให้เข้าใจ
ข้อความที่ "บรรยายตัวเองได้" คือข้อความที่บอกผู้รับว่าควรตีความอย่างไร—โดยไม่ต้องใช้ความรู้ tribal นอกแบนด์ ถ้าไคลเอ็นต์ (หรือ ตัวกลาง) ไม่สามารถเข้าใจการตอบสนองว่าหมายถึงอะไรเพียงดู HTTP เฮดเดอร์และบอดี คุณได้สร้างโปรโตคอลส่วนตัวบน HTTP แล้ว
ชัยชนะง่ายๆ คือการระบุ Content-Type (สิ่งที่คุณส่ง) และบ่อยครั้ง Accept (สิ่งที่คุณต้องการกลับ) การตอบกลับที่มี Content-Type: application/json บอกไคลเอ็นต์กฎการพาร์สพื้นฐาน แต่คุณสามารถไปไกลกว่านั้นด้วย media types แบบ vendor หรือ profile เมื่อความหมายสำคัญ
ตัวอย่างแนวทาง:
- media type ทั่วไป + ฟิลด์คงที่:
application/json พร้อมสคีมาที่รักษาไว้ เป็นวิธีที่ง่ายสุดสำหรับทีมส่วนใหญ่
- vendor media types:
application/vnd.acme.invoice+json เพื่อสื่อถึง representation เฉพาะ
- profiles: รักษา
application/json แต่เพิ่มพารามิเตอร์ profile หรือ link ไปที่โปรไฟล์ที่นิยามความหมาย
เวอร์ชันและความเข้ากันได้ (โดยไม่ทำให้ไคลเอ็นต์พัง)
การเวอร์ชันควรปกป้องไคลเอ็นต์เก่า ตัวเลือกยอดนิยมรวมถึง:
- เวอร์ชันใน URL (
/v1/orders): ชัดเจนแต่สามารถกระตุ้นให้แยกสคีมามากกว่าพัฒนา
- เวอร์ชันผ่านเฮดเดอร์หรือ media type (ผ่าน
Accept): ทำให้ URLs คงที่และความหมายเป็นส่วนหนึ่งของข้อความ
- การพัฒนาแบบเติมเพิ่ม: ชอบการเพิ่มฟิลด์ใหม่และรักษาของเก่าให้ทำงาน; ค่อยๆ ประกาศเลิกใช้
ไม่ว่าคุณจะเลือกแบบใด ตั้งเป้าหมายความเข้ากันได้ย้อนหลังเป็นค่าเริ่มต้น: อย่าเปลี่ยนชื่อฟิลด์โดยไม่คิด เปลี่ยนความหมายอย่างลับๆ หรือเอาออกโดยไม่ถือเป็นการเปลี่ยนแปลงที่ทำให้พัง
ข้อผิดพลาดที่สอดคล้องและการตั้งชื่อที่ชัดเจน
ไคลเอ็นต์เรียนรู้เร็วเมื่อข้อผิดพลาดมีรูปแบบเดียวกันทุกที่ เลือกรูปแบบข้อผิดพลาดหนึ่งแบบ (เช่น code, message, details, traceId) และใช้มันทั่ว endpoints ใช้ชื่อฟิลด์ที่ชัดเจนและสม่ำเสมอ (createdAt vs created_at) และยึดถือคอนเวนชันเดียว
เอกสารช่วยได้—แต่มุมมองต้องอยู่ในข้อความ
เอกสารดีช่วยให้การนำไปใช้เร็วขึ้น แต่ไม่ควรเป็นที่เดียวที่มีความหมาย ถ้าไคลเอ็นต์ต้องอ่านวิกิเพื่อรู้ว่า status: 2 หมายถึง "จ่ายแล้ว" หรือ "รอดำเนินการ" ข้อความนั้นไม่บรรยายตัวเองได้ เฮดเดอร์ที่ออกแบบดี media types และ payload ที่อ่านได้จะลดการพึ่งพาเอกสารและทำให้ระบบง่ายต่อการพัฒนา
Hypermedia (สรุปเป็น HATEOAS: Hypermedia As The Engine Of Application State) หมายความว่าไคลเอ็นต์ไม่จำเป็นต้อง "รู้" URL ถัดไปล่วงหน้า แต่ละการตอบสนองรวม ขั้นตอนถัดไปที่ค้นพบได้ เป็นลิงก์: จะไปที่ไหนต่อ การกระทำใดเป็นไปได้ และบางครั้งเมธอด HTTP ที่ต้องใช้
มันเป็นอย่างไรในทางปฏิบัติ
แทนที่จะเข้ารหัสเส้นทางเช่น /orders/{id}/cancel ไคลเอ็นต์ตามลิงก์ที่เซิร์ฟเวอร์ให้ เซิร์ฟเวอร์กำลังบอกว่า: "ตามสถานะปัจจุบันของทรัพยากร นี่คือการเคลื่อนไหวที่ถูกต้อง"
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
ถ้าคำสั่งกลายเป็น paid ในภายหลัง เซิร์ฟเวอร์อาจหยุดแนบ cancel แล้วเพิ่ม refund—โดยไม่ทำให้ไคลเอ็นต์ที่ปฏิบัติตามเบรก
เมื่อไฮเปอร์มีเดียช่วยได้มากที่สุด
Hypermedia เด่นเมื่อ ฟลōวเปลี่ยน: การนำผู้ใช้เข้าระบบ การชำระเงิน การอนุมัติ การสมัคร หรือกระบวนการที่ "สิ่งที่อนุญาตต่อไป" เปลี่ยนตามสถานะ สิทธิ์ หรือกฎทางธุรกิจ
มันยังลดการเข้ารหัส URL แบบฝังและการตั้งสมมติฐานที่เปราะบางของไคลเอ็นต์ คุณสามารถจัดระเบียบเส้นทางใหม่ เพิ่มการกระทำใหม่ หรือล้มเลิกอันเก่าได้โดยไม่ทำให้ไคลเอ็นต์เสียหาย ตราบใดที่คุณรักษาความหมายของความสัมพันธ์ลิงก์ไว้
ทำไมทีมถึงข้ามมัน (และสูญเสียอะไร)
ทีมมักข้าม HATEOAS เพราะมันดูเหมือนงานเพิ่ม: กำหนดรูปแบบลิงก์ ตกลงชื่อความสัมพันธ์ และสอนนักพัฒนาไคลเอ็นต์ให้ตามลิงก์แทนการประกอบ URL
สิ่งที่คุณสูญเสียคือประโยชน์สำคัญของ REST: การผูกแบบหลวม โดยไม่มี hypermedia หลาย API กลายเป็น "RPC บน HTTP"—อาจใช้ HTTP แต่ไคลเอ็นต์ยังพึ่งเอกสารนอกแบนด์และเทมเพลต URL ที่ตายตัว
ข้อจำกัด 5: ระบบแบบหลายชั้น
ระบบแบบหลายชั้นหมายความว่าไคลเอ็นต์ไม่จำเป็นต้องรู้ (และมักจะไม่สามารถบอกได้) ว่ากำลังคุยกับ origin server จริงๆ หรือกับตัวกลางตามทาง เลเยอร์เหล่านั้นอาจรวม API gateways reverse proxies CDNs บริการ auth WAFs service meshes และแม้แต่การ routing ภายในระหว่าง microservices
ทำไมเลเยอร์มีประโยชน์
เลเยอร์สร้างขอบเขตที่ชัดเจน ทีมความปลอดภัยสามารถบังคับใช้ TLS อัตราจำกัด การพิสูจน์ตัวตน และการตรวจสอบคำขอที่ edge โดยไม่ต้องแก้ไขทุก backend ทีมปฏิบัติการสามารถสเกลแบบแนวนอนหลังเกตเวย์ เพิ่มแคชใน CDN หรือเปลี่ยนทราฟฟิกระหว่างเหตุการณ์ฉุกเฉิน สำหรับไคลเอ็นต์ มันทำให้ง่ายขึ้น: endpoint หนึ่งคงที่ เฮดเดอร์ที่สอดคล้องและรูปแบบข้อผิดพลาดที่คาดเดาได้
การแลกเปลี่ยนที่คุณจะรู้สึกในทางปฏิบัติ
ตัวกลางอาจเพิ่มความหน่วงที่ซ่อนอยู่ (hop เพิ่มขึ้น handshake เพิ่มขึ้น) และทำให้การดีบักยากขึ้น: บั๊กอาจอยู่ในกฎของเกตเวย์ ในแคช CDN หรือในโค้ดต้นทาง การแคชก็สับสนเมื่อแต่ละเลเยอร์แคชต่างกัน หรือเมื่อเกตเวย์เขียนเฮดเดอร์ใหม่ที่มีผลต่อคีย์แคช
เคล็ดลับเชิงปฏิบัติที่จะทำให้เลเยอร์ไม่ทำร้ายคุณ
- ใช้ tracing IDs ทั้งระบบ: ยอมรับ request ID (หรือสร้างหนึ่งอัน) และส่งต่อมันผ่านทุก hop; รวมไว้ในคำตอบและล็อก
- ทำให้การเผยแพร่ข้อผิดพลาดชัดเจน: มาตรฐานรูปแบบข้อผิดพลาดและแมปความล้มเหลว upstream อย่างชัดเจน (อย่าเปลี่ยนทุกปัญหาเป็น 500 ทั่วไป)
- ตั้งค่า timeouts ต่อ hop: timeout ของเกตเวย์ upstream และ client ควรสอดคล้องกันเพื่อลดการตัดการเชื่อมต่อที่ลึกลับ
- เอกสารพฤติกรรมการแคช: ชัดเจนว่าการตอบสนองใดแคชได้และเฮดเดอร์ใดที่ตัวกลางต้องรักษา
เลเยอร์มีพลัง—เมื่อระบบยังคงสังเกตได้และคาดการณ์ได้
ข้อจำกัด 6 (ตัวเลือก): Code-on-Demand
Code-on-demand คือข้อจำกัดเดียวของ REST ที่เป็น ทางเลือกได้ มันหมายความว่าเซิร์ฟเวอร์สามารถขยายไคลเอ็นต์โดยส่ง โค้ดที่รันได้ ไปยังฝั่งไคลเอ็นต์ แทนที่จะส่งพฤติกรรมทุกอย่างมาก่อน ไคลเอ็นต์สามารถดาวน์โหลดตรรกะใหม่ตามต้องการ
ตัวอย่างที่คุ้นเคยของเว็บ: JavaScript
ถ้าคุณเคยโหลดหน้าเว็บที่กลายเป็น interactive—ตรวจฟอร์ม เรนเดอร์ชาร์ต กรองตาราง—คุณได้ใช้ code-on-demand มาแล้ว เซิร์ฟเวอร์ส่ง HTML และข้อมูล พร้อมกับ JavaScript ที่รันในเบราว์เซอร์เพื่อมอบพฤติกรรม
นี่เป็นเหตุผลใหญ่ที่เว็บพัฒนาได้เร็ว: เบราว์เซอร์ยังคงเป็นไคลเอ็นต์ทั่วไป ในขณะที่ไซต์ส่งฟีเจอร์ใหม่โดยไม่ต้องให้ผู้ใช้ติดตั้งแอปใหม่ทั้งหมด
ทำไมมันเป็นทางเลือก (และทำไมหลาย API ข้ามมัน)
REST ยังคง "ใช้งานได้" โดยไม่มี code-on-demand เพราะข้อจำกัดอื่นๆ ก็เพียงพอแล้วเพื่อให้สเกล เรียบง่าย และทำงานร่วมกัน แอป API สามารถเป็นเชิงทรัพยากรบริสุทธิ์—เสิร์ฟ representation เช่น JSON—ในขณะที่ไคลเอ็นต์นิยามพฤติกรรมเอง
หลาย Web API สมัยใหม่ตั้งใจหลีกเลี่ยงการส่งโค้ดที่รันได้เพราะมันซับซ้อน:
- ความปลอดภัย: โค้ดที่รันได้เป็นพื้นผิวการโจมตีที่ใหญ่ขึ้น (injection, ปัญหา supply-chain, สคริปต์ประสงค์ร้าย)
- นโยบายเนื้อหา: เบราว์เซอร์บังคับ Content Security Policy (CSP) และองค์กรอาจบล็อกสคริปต์ฝังหรือแหล่งที่ไม่รู้จัก
- การตรวจสอบและการปฏิบัติตาม: ยากที่จะพิสูจน์ว่าโค้ดใดรันบนไคลเอ็นต์ในช่วงเวลาหนึ่ง โดยเฉพาะเมื่อดึงแบบไดนามิก
เมื่อ code-on-demand ยังมีเหตุผลอยู่
มันอาจมีประโยชน์เมื่อคุณควบคุมสภาพแวดล้อมไคลเอ็นต์และต้องการม้วนออกพฤติกรรม UI อย่างรวดเร็ว หรือเมื่อคุณต้องการไคลเอ็นต์บางที่ดาวน์โหลด "ปลั๊กอิน" หรือกฎจากเซิร์ฟเวอร์ แต่ควรถือเป็นเครื่องมือเสริม ไม่ใช่ข้อบังคับ
ข้อสรุปสำคัญ: คุณสามารถทำตาม REST ได้เต็มโดยไม่ต้องใช้ code-on-demand—และหลาย API ในการผลิตทำเช่นนั้น—เพราะข้อจำกัดนี้เป็นเรื่องของการขยายตัวทางเลือก ไม่ใช่พื้นฐานของการโต้ตอบเชิงทรัพยากร
นำ REST ไปใช้วันนี้: การเลือกเชิงปฏิบัติและความผิดพลาดที่พบบ่อย
ทีมส่วนใหญ่ไม่ได้ ปฏิเสธ REST—พวกเขาใช้สไตล์ที่ "เหมือน REST" ที่เก็บ HTTP ไว้เป็นพาหนะขณะที่ค่อยๆ ทิ้งข้อจำกัดสำคัญ นั่นไม่เป็นไร ตราบใดที่เป็นการแลกเปลี่ยนโดยตั้งใจ ไม่ใช่อุบัติเหตุที่จะกลายเป็นไคลเอ็นต์เปราะบางและการเขียนโค้ดใหม่ที่แพงในภายหลัง
ทางลัด REST-ish ที่พบบ่อย (และทำไมมันเกิด)
พฤติกรรมบางอย่างวนเวียนซ้ำแล้วซ้ำเล่า:
- RPC endpoints:
/doThing, /runReport, /users/activate—ตั้งชื่อง่าย ต่อเชื่อมง่าย
- URL ที่เต็มไปด้วยคำกริยา:
/createOrder, /updateProfile, /deleteItem—เมธอด HTTP กลายเป็นเรื่องรอง
- เซสชันที่ซ่อนอยู่: API ที่ดู "ไร้สถานะ" แต่ยังพึ่ง sticky sessions หรือความจำบนเซิร์ฟเวอร์ หรือสถานะเวิร์กโฟลว์แบบนิ่ง
การเลือกเหล่านี้มักดูให้ผลเร็วในช่วงแรกเพราะสะท้อนชื่อฟังก์ชันภายในและกระบวนการธุรกิจ
ผลที่คุณจะสังเกตในภายหลัง
- ไคลเอ็นต์เปราะบาง: ถ้าไคลเอ็นต์พึ่งรูปแบบ endpoint เฉพาะและพฤติกรรมเฉพาะ การ refactor เซิร์ฟเวอร์เล็กน้อยอาจทำให้พัง
- การเวอร์ชันยาก: เมื่อ URL เข้ารหัสการกระทำ แทนที่จะเป็นทรัพยากร สุดท้ายคุณต้องเวอร์ชันพฤติกรรมแทนที่จะพัฒนา representation
- การพลาดแคช (และความหน่วงสูงขึ้น): การไม่ใช้เฮดเดอร์แคชหรือใช้ POST ทุกอย่าง ป้องกันไม่ให้ตัวกลางช่วยคุณ
- ปัญหาการสเกล: สถานะเซิร์ฟเวอร์ที่ซ่อนอยู่ทำให้การสเกลแนวนอนและการกู้คืนจากความล้มเหลวยากขึ้น
เช็คลิสต์การปรับให้อยู่ในแนวทางปฏิบัติ
ใช้สิ่งนี้เป็นการทบทวนว่า "เราจริงๆ แล้วเป็น REST แค่ไหน":
- ตั้งชื่อทรัพยากร ไม่ใช่การกระทำ: ชอบ
/orders/{id} แทน /createOrder
- ใช้ HTTP methods อย่างมีเหตุผล: GET สำหรับดึง, POST สำหรับสร้าง, PUT/PATCH สำหรับอัปเดต, DELETE สำหรับลบ
- ทำให้คำขอเป็นอิสระ: ไม่มีหน่วยความจำเซิร์ฟเวอร์ที่จำเป็นเพื่อเข้าใจ "ไคลเอ็นต์อยู่ขั้นตอนไหน"
- ใช้แคชเมื่อปลอดภัย: กำหนด
Cache-Control, ETag, และ Vary สำหรับการตอบกลับ GET
- มาตรฐานข้อผิดพลาดและ media types: รหัสสถานะและรูปแบบการตอบกลับที่สอดคล้องจะลดกรณีพิเศษ
สิ่งนี้ปรากฏเมื่อคุณกำลังสร้างจริง
ข้อจำกัดของ REST ไม่ใช่แค่ทฤษฎี—มันคือราวกันชนที่คุณรู้สึกได้ขณะส่งมอบ เมื่อคุณกำลังสร้าง API อย่างรวดเร็ว (เช่น สร้าง frontend React ด้วย backend Go + PostgreSQL แบบสคริปต์) ข้อผิดพลาดที่ง่ายที่สุดคือปล่อยให้ "สิ่งที่เร็วที่สุดในการเชื่อม" กำหนดอินเทอร์เฟซของคุณ
ถ้าคุณใช้แพลตฟอร์มที่โค้ดจากแชทได้อย่าง Koder.ai การนำข้อจำกัด REST เหล่านี้เข้ามาตั้งแต่ต้นช่วยได้—ตั้งชื่อทรัพยากรก่อน รักษา stateless กำหนดรูปแบบข้อผิดพลาดสอดคล้อง และตัดสินใจว่าควรแคชที่ไหนอย่างปลอดภัย ด้วยวิธีนี้ แม้การวนรอบอย่างรวดเร็วก็ยังผลิต API ที่คาดเดาได้สำหรับไคลเอ็นต์และง่ายต่อการพัฒนา (และเพราะ Koder.ai รองรับการส่งออกซอร์สโค้ด คุณสามารถปรับสัญญา API และการใช้งานได้ตามความต้องการที่เปลี่ยนไป)