03 พ.ย. 2568·4 นาที
รูปแบบ SaaS แบบมัลติเทนานซี: การแยก การสเกล และการออกแบบด้วย AI
เรียนรู้รูปแบบ SaaS แบบมัลติเทนานซีที่พบบ่อย ข้อแลกเปลี่ยนของการแยก tenant และกลยุทธ์การสเกล รวมถึงว่าการออกแบบสถาปัตยกรรมที่สร้างโดย AI ช่วยเร่งการออกแบบและการทบทวนได้อย่างไร
ความหมายของมัลติเทนานซี (อธิบายไม่ใช้ศัพท์เทคนิค)
มัลติเทนานซีคือซอฟต์แวร์ตัวเดียวที่ให้บริการลูกค้าหลายราย (tenants) จากระบบที่กำลังรันเดียวกัน ลูกค้าแต่ละรายจะรู้สึกเหมือนมี “แอปของตัวเอง” แต่เบื้องหลังมีการแชร์ส่วนประกอบบางอย่าง—เช่น เว็บเซิร์ฟเวอร์ โค้ดเบส และบ่อยครั้งคือฐานข้อมูลเดียวกัน
ภาพเปรียบเทียบที่ได้ผลคืออาคารอพาร์ตเมนต์ ทุกคนมีห้องล็อกของตัวเอง (ข้อมูลและการตั้งค่า) แต่ใช้ลิฟต์ ระบบท่อน้ำ และทีมดูแลร่วมกัน (compute, storage, operations ของแอป)
ทำไมทีมถึงเลือกมัลติเทนานซี
ทีมส่วนใหญ่ไม่ได้เลือกมัลติเทนานซีเพราะเป็นเทรนด์ แต่เลือกเพราะมันมีประสิทธิภาพ:
- ต้นทุนต่อผู้ใช้ต่ำกว่า: โครงสร้างพื้นฐานที่แชร์มักถูกกว่าการสร้างสแตกแยกให้แต่ละลูกค้า
- การปฏิบัติการง่ายขึ้น: แพลตฟอร์มเดียวให้มอนิเตอร์ แพตช์ และปกป้อง (แทนที่จะต้องดูแลดีพลอยย่อยหลายสิบหรือหลายร้อยตัว)
- ปล่อยฟีเจอร์เร็วขึ้น: การปรับปรุงไปถึงทุกคนพร้อมกันและหลีกเลี่ยง “version drift” ข้ามลูกค้า
จุดที่อาจพังได้
สองโหมดความล้มเหลวคลาสสิกคือ ความปลอดภัย และ ประสิทธิภาพ
เรื่องความปลอดภัย: ถ้าขอบเขต tenant ไม่ถูกบังคับใช้อย่างครบถ้วน บั๊กเดียวอาจรั่วไหลข้อมูลข้ามลูกค้าได้ เหตุการณ์เหล่านี้ไม่ใช่แฮ็กครั้งใหญ่เสมอไป แต่เป็นความผิดพลาดปกติเช่นกรองข้อมูลขาด หรือตรวจสอบสิทธิ์ตั้งค่าผิดพลาด หรือ background job ที่รันโดยไม่มีบริบท tenant
เรื่องประสิทธิภาพ: การแชร์ทรัพยากรหมายความว่าลูกค้าคนเดียวที่มีงานหนักอาจทำให้คนอื่นช้าลง ปรากฏเป็นคำถามช้า งานโหลดเป็นพักๆ หรือผู้ใช้รายเดียวบริโภคแบนด์วิดท์ API มากเกินไป
ภาพรวมสั้นๆ ของรูปแบบที่จะพูดถึง
บทความนี้จะอธิบายบล็อกก่อสร้างที่ทีมใช้จัดการความเสี่ยงเหล่านั้น: การแยกข้อมูล (ฐานข้อมูล, สคีมา, หรือระดับแถว), ระบบระบุ tenant และสิทธิ์ที่ตระหนักถึง tenant, ควบคุม noisy-neighbor, และรูปแบบปฏิบัติการสำหรับการสเกลและการจัดการการเปลี่ยนแปลง
ข้อแลกเปลี่ยนหลัก: การแยก vs ประสิทธิภาพ
มัลติเทนานซีคือการตัดสินใจว่าจะแชร์มากแค่ไหนระหว่าง tenants กับจะอุทิศต่อ tenant มากแค่ไหน แต่ละรูปแบบเป็นเพียงจุดต่างๆ บนสเปกตรัมนี้
แหล่งทรัพยากรที่แชร์กับที่อุทิศ: สเปกตรัมหลัก
ปลายด้านหนึ่ง tenants แชร์แทบทุกอย่าง: ตัวแอป อินสแตนซ์ ฐานข้อมูล คิว และแคช—แยกตามตรรกะด้วย tenant ID และกฎการเข้าถึง นี่มักถูกและง่ายสุดเพราะสามารถรวมพลังการประมวลผล
อีกปลายหนึ่ง tenants ได้ “ชิ้น” ของระบบของตัวเอง: ฐานข้อมูลแยก compute แยก และบางครั้ง deployment แยก นี่เพิ่มความปลอดภัยและการควบคุม แต่เพิ่มภาระการปฏิบัติการและต้นทุน
ทำไมการแยกกับต้นทุนดึงกันคนละทาง
การแยกลดความเสี่ยงที่ tenant หนึ่งจะเข้าถึงข้อมูลของอีก tenant หนึ่งหรือใช้ทรัพยากรเกิน และช่วยให้ผ่านการตรวจสอบและการปฏิบัติตามข้อกำหนดได้ง่ายขึ้น
ประสิทธิภาพดีขึ้นเมื่อคุณกระจายความจุที่ว่างให้หลาย tenant โครงสร้างพื้นฐานที่แชร์ทำให้รันเซิร์ฟเวอร์น้อยลง สายการดีพลอยซับซ้อนน้อยลง และสเกลตามความต้องการรวมแทนที่จะสเกลตามกรณีที่แย่สุดของแต่ละ tenant
ปัจจัยการตัดสินใจแบบทั่วไป
ตำแหน่งที่ “เหมาะสม” บนสเปกตรัมขึ้นกับข้อจำกัด:
- SLA และความคาดหวังของลูกค้า: เป้าความพร้อมใช้งานหรือความหน่วงที่เข้มงวดจะดันไปทางแยกมากขึ้น
- การปฏิบัติตามกฎข้อบังคับและการเก็บข้อมูล: ข้อกำหนดอาจบังคับให้ใช้ storage หรือสภาพแวดล้อมเฉพาะ
- ระยะการเติบโต: ผลิตภัณฑ์ในช่วงแรกมักเริ่มแชร์เพื่อให้เคลื่อนไหวเร็ว; เมื่อโตขึ้นอาจเสนอทางเลือกแบบอุทิศให้ลูกค้าใหญ่
- ความชำนาญด้านปฏิบัติการ: การแยกมากขึ้นหมายถึงงานมอนิเตอร์ แพตช์ และย้ายข้อมูลมากขึ้น
แบบจำลองคิดง่ายสำหรับเลือกรูปแบบ
ถามสองคำถาม:
-
หาก tenant หนึ่งพังหรือถูกโจมตี ผลกระทบจะเป็นอย่างไร?
-
ต้นทุนทางธุรกิจของการลดผลกระทบนั้นเป็นเท่าไร?
ถ้าผลกระทบต้องเล็กมาก เลือกส่วนประกอบที่อุทิศมากขึ้น ถ้าต้นทุนและความเร็วสำคัญ ให้แชร์มากขึ้น—และลงทุนในการควบคุมการเข้าถึง การจำกัดอัตรา และมอนิเตอร์ per-tenant เพื่อให้การแชร์ปลอดภัย
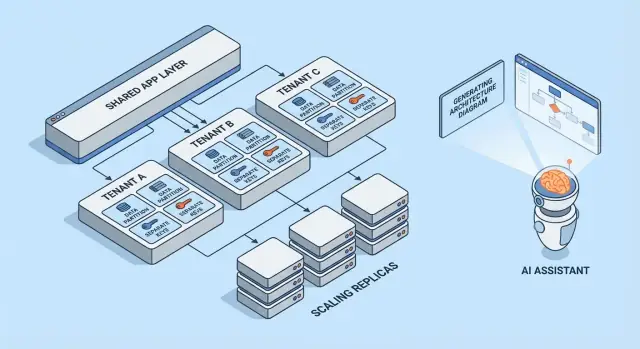
รูปแบบมัลติเทนานซีโดยสรุป
มัลติเทนานซีไม่ใช่สถาปัตยกรรมเดียว แต่มีหลายวิธีในการแชร์ (หรือไม่แชร์) โครงสร้างพื้นฐานระหว่างลูกค้า แบบที่ดีที่สุดขึ้นกับระดับการแยกที่ต้องการ จำนวน tenants ที่คาดหวัง และภาระการปฏิบัติการที่ทีมรับไหว
1) Single-tenant (อุทิศ) — จุดเริ่มต้น
ลูกค้าแต่ละรายได้สแตกแอปของตัวเอง (หรืออย่างน้อย runtime และฐานข้อมูลแยก) นี้ง่ายที่สุดในการคาดการณ์เรื่องความปลอดภัยและประสิทธิภาพ แต่โดยทั่วไปแพงที่สุดต่อแต่ละ tenant และอาจชะลอการสเกลการปฏิบัติการ
2) แอปแชร์ + DB แชร์ — ต้นทุนต่ำสุด ต้องระมัดระวังสูงสุด
ทุก tenant รันบนแอปและฐานข้อมูลเดียวกัน ต้นทุนมักต่ำสุดเพราะใช้ซ้ำสูงสุด แต่ต้องระมัดระวังบริบท tenant ทุกที่ (SQL, แคช, background job, การส่งออก analytics) ความผิดพลาดเพียงครั้งเดียวอาจเป็นการรั่วไหลข้าม tenant
3) แอปแชร์ + DB แยก — การแยกดีขึ้น ภาระงานเพิ่ม
แอปแชร์ แต่แต่ละ tenant มีฐานข้อมูลของตัวเอง การควบคุมผลกระทบจากเหตุการณ์ดีขึ้น สำรอง/กู้คืนระดับ tenant สะดวกขึ้น และช่วยเรื่อง compliance แต่ต้องดูแลฐานข้อมูลหลายตัวมากขึ้น
4) โมเดลไฮบริดสำหรับลูกค้ารายใหญ่
หลายผลิตภัณฑ์ผสมแบบ: ลูกค้าส่วนใหญ่อยู่บนโครงสร้างแชร์ ขณะที่ลูกค้ารายใหญ่หรือมีข้อกำหนดพิเศษได้ฐานข้อมูลหรือ compute อุทิศ ไฮบริดเป็นสถานะปฏิบัติจริงแต่ต้องมีกฎชัดเจนว่าใครมีสิทธิ์ ได้อะไร ค่าใช้จ่ายเท่าไร และวิธีการอัพเกรด
หากต้องการลงลึกเทคนิคการแยกภายในแต่ละโมเดล ดูบทความ data-isolation-patterns
รูปแบบการแยกข้อมูล (DB, Schema, Row)
การแยกข้อมูลตอบคำถามง่ายๆ: “ลูกค้าหนึ่งจะเห็นหรือกระทบข้อมูลของอีกคนได้หรือไม่?” มีสามรูปแบบทั่วไป แต่ละแบบมีผลต่อความปลอดภัยและการปฏิบัติการต่างกัน
การแยกระดับแถว (ตารางแชร์ + tenant_id)
ทุก tenant ใช้ตารางเดียวกัน และแต่ละแถวมีคอลัมน์ tenant_id นี่เป็นโมเดลที่มีประสิทธิภาพที่สุดสำหรับ tenant ขนาดเล็กถึงกลางเพราะลดโครงสร้างพื้นฐานและทำให้การรายงานสะดวก
ความเสี่ยงก็ชัดเจน: หากคำสั่งค้นหาใดลืมกรองด้วย tenant_id ข้อมูลอาจรั่ว แม้แต่ endpoint ของแอดมินหรือ background job เดียวก็เป็นจุดอ่อนได้ มาตรการแก้ได้แก่:
- บังคับกรอง tenant ในชั้นเข้าถึงข้อมูลร่วม (shared data-access layer) เพื่อไม่ให้ devs เขียนฟิลเตอร์เอง
- ใช้ฟีเจอร์ DB อย่าง Row-Level Security (RLS) เมื่อมี
- เพิ่ม automated tests ที่ตั้งใจพยายามเข้าถึงข้าม tenant
- ทำดัชนีสำหรับเส้นทางการเข้าถึงทั่วไป (มักเป็น
(tenant_id, created_at)หรือ(tenant_id, id)) เพื่อให้คำค้นหาแบบ tenant-scoped เร็ว
Schema ต่อ tenant (ฐานข้อมูลเดียว สคีมาแยก)
แต่ละ tenant ได้สคีมาของตัวเอง (namespace เช่น tenant_123.users, tenant_456.users) การแยกดีขึ้นเมื่อเทียบกับการแชร์ระดับแถว และทำให้การส่งออกหรือปรับจูนเฉพาะ tenant ง่ายขึ้น
แต่ภาระการปฏิบัติการเพิ่มขึ้น การมิเกรชันต้องรันข้ามสคีมจำนวนมาก และความล้มเหลวซับซ้อนกว่า: อาจมิเกรตสำเร็จ 9,900 tenant แล้วติดที่ 100 การมอนิเตอร์และเครื่องมือสำคัญ—กระบวนการมิเกรชันต้องมีการลองซ้ำและรายงานชัดเจน
ฐานข้อมูลต่อ tenant (DB แยก)
แต่ละ tenant ได้ฐานข้อมูลแยก การแยกแข็งแรง: ขอบเขตการเข้าถึงชัดเจนกว่า คำสั่งหนักจาก tenant หนึ่งไม่น่าจะกระทบอีก tenant และการกู้คืนจากสำรองระดับ tenant ทำได้สะอาดขึ้น
ต้นทุนและการสเกลเป็นข้อเสียหลัก: ฐานข้อมูลมากขึ้น ต้องจัดการ connection pool มากขึ้น และงานอัพเกรด/มิเกรชันมากขึ้น ทีมจำนวนมากสงวนแบบนี้ให้ลูกค้ามูลค่าสูงหรือต้องปฏิบัติตามกฎ
การแยกชาร์ดและยุทธศาสตร์การวางตำแหน่งเมื่อ tenants โต
ระบบจริงมักผสมรูปแบบเหล่านี้ แนวทางทั่วไปคือใช้การแยกระดับแถวตอนเติบโตช่วงต้น แล้วเมื่อ tenant ใหญ่ขึ้นย้ายไปสคีมา หรือ DB แยก
การชาร์ดเพิ่มเลเยอร์การวางตำแหน่ง: ตัดสินใจว่า tenant ไหนอยู่คลัสเตอร์ DB ไหน (ตามภูมิภาค ขนาด หรือการแฮช) ข้อสำคัญคือทำให้การวางตำแหน่ง tenant ชัดเจนและเปลี่ยนได้—เพื่อที่คุณจะย้าย tenant ได้โดยไม่ต้องเขียนแอปใหม่ และสเกลด้วยการเพิ่มชาร์ดแทนการออกแบบใหม่ทั้งหมด
ระบบยืนยันตัวตน สิทธิ์ และบริบท tenant
มัลติเทนานซีล้มเหลวด้วยวิธีที่แปลกประหลาดและธรรมดา: ฟิลเตอร์หาย, ออบเจ็กต์ในแคชถูกแชร์ข้าม tenant, หรือฟีเจอร์แอดมินที่ “ลืม” ว่าใครเป็นผู้ขอ การแก้ไม่ใช่ฟีเจอร์ความปลอดภัยเดียว แต่มาจากบริบท tenant ที่สม่ำเสมอตั้งแต่ byte แรกของคำขอจนถึงคำสั่ง DB สุดท้าย
การระบุ tenant (จะรู้ว่า "ใคร")
ผลิตภัณฑ์ SaaS ส่วนใหญ่เลือกตัวระบุหลักหนึ่งตัวและถือส่วนอื่นเป็นความสะดวก:
- ซับโดเมน:
acme.yourapp.comใช้งานง่ายและเหมาะกับประสบการณ์แบรนด์ tenant - เฮดเดอร์: มีประโยชน์สำหรับไคลเอนต์ API และบริการภายใน (แต่ต้องยืนยันตัวตน)
- ค่าในโทเค็น: JWT ที่ลงลายเซ็นรวม
tenant_idทำให้แก้ไขยาก
เลือกแหล่งข้อมูลหนึ่งที่เป็นแหล่งความจริงแล้วบันทึกไว้ทุกที่ หากรองรับหลายสัญญาณ (ซับโดเมน + โทเค็น) ให้กำหนดลำดับความสำคัญและปฏิเสธคำขอที่กำกวม
การจำกัดคำขอ (ให้ทุกคำถามอยู่ใน tenant เดียว)
กฎที่ดี: เมื่อตรวจสอบ tenant_id แล้ว ทุกอย่างต่อจากนั้นควรอ่านมันจากจุดเดียว (request context) ไม่ใช่คำนวณใหม่
การป้องกันทั่วไปได้แก่:
- มิดเดิลแวร์ที่แนบ
tenant_idกับ context ของคำขอ - ตัวช่วยเข้าถึงข้อมูลที่ต้องการ
tenant_idเป็นพารามิเตอร์ - การบังคับใช้ในฐานข้อมูล (เช่น นโยบายระดับแถว) เพื่อให้ความผิดพลาดล้มเหลวแบบปิด
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
พื้นฐานการอนุญาต (บทบาทภายใน tenant)
แยก การพิสูจน์ตัวตน (ใครคือผู้ใช้) ออกจาก การอนุญาต (ทำอะไรได้บ้าง)
บทบาททั่วไปใน SaaS คือ Owner / Admin / Member / Read-only แต่ประเด็นหลักคือตัวขอบเขต: ผู้ใช้คนหนึ่งอาจเป็น Admin ใน Tenant A และเป็น Member ใน Tenant B ต้องเก็บสิทธิ์แยกตาม tenant ไม่ใช่แบบ global
ป้องกันการรั่วข้าม tenant (เทสและการ์ดเรล)
ปฏิบัติต่อการเข้าถึงข้าม tenant เป็นเหตุการณ์ระดับบนสุดและป้องกันเชิงรุก:
- เพิ่ม automated tests ที่พยายามอ่านข้อมูล Tenant B ในขณะที่ authenticated เป็น Tenant A
- ทำให้บั๊กที่ลืมกรอง tenant ยากจะถูกปล่อย (linters, query builders, พารามิเตอร์ tenant ที่บังคับ)
- บันทึกและแจ้งเตือนพฤติกรรมที่น่าสงสัย (เช่น tenant ในโทเค็นไม่ตรงกับซับโดเมน)
หากต้องการเช็คลิสต์ปฏิบัติการเชิงลึก ให้เชื่อมกฎเหล่านี้เข้ากับ runbook วิศวกรรมของคุณในเอกสารความปลอดภัย และเก็บเวอร์ชันควบคู่กับโค้ด
การแยกนอกฐานข้อมูล
Prototype Multi-tenancy Fast
Generate a React plus Go and PostgreSQL skeleton to test tenant scoping early.
การแยกฐานข้อมูลเป็นแค่ครึ่งเรื่อง เหตุการณ์มัลติเทนานซีจริงๆ มักเกิดในท่อร่วมที่แชร์รอบแอป: แคช คิว และที่เก็บไฟล์ เลเยอร์เหล่านี้เร็วและสะดวกและง่ายที่จะทำให้เป็น global โดยไม่ตั้งใจ
แคชที่แชร์: ป้องกันการชนกันของคีย์และการรั่วของข้อมูล
ถ้าใช้ Redis หรือ Memcached ร่วมระหว่าง tenants กฎหลัก: อย่าเก็บคีย์ที่ไม่แยก tenant
รูปแบบปฏิบัติคือเพิ่มพรีฟิกคีย์ด้วยตัวระบุ tenant แบบคงที่ (ไม่ใช้โดเมนอีเมลหรือชื่อแสดง) เช่น t:{tenant_id}:user:{user_id} ซึ่งช่วยสองเรื่อง:
- ป้องกันการชนกันเมื่อสอง tenant มี ID ภายในเหมือนกัน
- ทำให้การล้างเป็นกลุ่มเป็นไปได้ (delete by prefix) ระหว่างเหตุการณ์สนับสนุนหรือการย้ายข้อมูล
นอกจากนี้ ให้ตัดสินใจว่าสิ่งใดอนุญาตให้แชร์ได้แบบ global (เช่น feature flags สาธารณะ ข้อมูลสเตติก) และบันทึกไว้—ตัวแปร global โดยไม่ตั้งใจเป็นแหล่งการรั่วข้าม tenant
อัตราจำกัดและโควตาของ tenant
แม้ว่าข้อมูลจะแยก แต่ tenants ยังส่งผลกระทบกันผ่าน compute ร่วม เพิ่มการจำกัดแบบตระหนัก tenant ที่ขอบ:
- จำกัดอัตรา API ต่อ tenant (และมักต่อผู้ใช้ภายใน tenant)
- โควตาสำหรับงานหนัก (การส่งออก, สร้างรายงาน, การเรียก AI)
ทำให้ขีดจำกัดมองเห็นได้ (เฮดเดอร์, แจ้ง UI) เพื่อให้ลูกค้ารู้ว่าการหน่วงเป็นนโยบาย ไม่ใช่ระบบล้มเหลว
งานแบ็กกราวน์: แบ่งคิวตาม tenant
คิวร่วมเดียวสามารถทำให้ tenant หนึ่งครอบงำเวลาทำงานของ worker ได้
การแก้ปกติได้แก่:
- แยกคิวตามชั้น/แผน (เช่น
free,pro,enterprise) - คิวแบ่งตามบัคเก็ต tenant (แฮช tenant_id ลงใน N คิว)
- การกำหนดเวลาที่ตระหนัก tenant เพื่อให้แต่ละ tenant ได้ส่วนที่ยุติธรรม
เสมอใส่บริบท tenant ลงใน payload ของงานและ logs เพื่อหลีกเลี่ยงผลข้างเคียงผิด tenant
ที่เก็บไฟล์/วัตถุ: แยกเส้นทาง นโยบาย และคีย์
สำหรับ S3/GCS แบบ object storage การแยกมักอาศัยเส้นทางและนโยบาย:
- bucket ต่อ tenant เพื่อการแยกเข้มงวด (ขอบเขตแข็งแรง แต่ภาระสูง)
- bucket แชร์พร้อมพรีฟิก tenant (ง่ายกว่า แต่ต้องรอบคอบกับ IAM และ signed URLs)
ไม่ว่าจะเลือกแบบใด ให้บังคับว่าอัปโหลด/ดาวน์โหลดต้องยืนยันความเป็นเจ้าของ tenant ทุกคำขอ ไม่ใช่แค่ใน UI
การจัดการ noisy neighbors และการใช้งานทรัพยากรอย่างเป็นธรรม
ระบบมัลติเทนานซีแชร์โครงสร้างพื้นฐาน จึงมีความเป็นไปได้ที่ tenant หนึ่งจะใช้ทรัพยากรมากกว่าที่ควร นี่คือปัญหา noisy neighbor: งานหนักของคนเดียวทำให้ผู้อื่นเสื่อมประสิทธิภาพ
ลักษณะของ noisy neighbor
สมมติฟีเจอร์รายงานส่งออกข้อมูลเป็น CSV ปีหนึ่ง Tenant A สั่งส่งออก 20 ครั้งเวลา 9:00 น. งานเหล่านั้นอิ่มตัว CPU และ I/O จนหน้าจอของ Tenant B เริ่ม timeout—แม้ B จะไม่ได้ทำอะไรผิดปกติ
การควบคุมทรัพยากร: ขีดจำกัด โควตา และการปรับรูปร่างงาน
การป้องกันเริ่มจากขอบเขตทรัพยากรชัดเจน:
- Rate limits ต่อ tenant และต่อ endpoint เพื่อป้องกันการสแปม API ที่แพง
- Quotas (รายวัน/รายเดือน) สำหรับสิ่งเช่น exports, อีเมล, การเรียก AI, หรืองานแบ็กกราวน์
- Workload shaping: ใส่งานหนัก (exports, imports, re-indexing) ลงคิวที่มีการจำกัด concurrency ต่อ tenant และกฎลำดับความสำคัญ
รูปแบบที่ปฏิบัติได้คือแยกทราฟฟิกแบบ interactive ออกจากงานแบบ batch: ให้คำขอที่เห็นหน้าผู้ใช้วิ่งบนเลนเร็ว และดันอื่นๆ ไปยังคิวที่ควบคุมได้
Circuit breakers และ bulkheads ต่อ tenant
เพิ่มวาล์วความปลอดภัยที่ทำงานเมื่อ tenant เกินเกณฑ์:
- Circuit breakers: ปฏิเสธหรือเลื่อนการทำงานที่มีค่าใช้จ่ายชั่วคราวเมื่อ error rate latency หรือ queue depth ของ tenant เกิน
- Bulkheads: แยกพูลที่ใช้ร่วม (DB connections, worker threads, cache) เพื่อไม่ให้ tenant หนึ่งใช้หมดความจุทั้งหมด
ถ้าทำดี Tenant A จะช้าลงเฉพาะของตัวเองโดยไม่ทำให้ Tenant B ล้ม
เมื่อใดควรย้าย tenant ไปที่ทรัพยากรอุทิศ
ย้าย tenant ไปทรัพยากรอุทิศเมื่อพฤติกรรมของเขาเกินสมมติฐานการแชร์อย่างสม่ำเสมอ: throughput สูงอย่างต่อเนื่อง, สปีดระเบิดที่ไม่คาดคิด, ความต้องการปฏิบัติตามกฎเข้มงวด, หรือเมื่อต้องการการจูนเฉพาะ หากการปกป้องลูกค้าอื่นต้องแลกด้วยการจำกัดลูกค้าที่จ่ายอยู่ประจำ ก็ถึงเวลาสำหรับความจุอุทิศหรือชั้นบริการที่สูงขึ้น แทนการแก้เป็นครั้งคราว
รูปแบบการสเกลที่ใช้ได้ใน SaaS แบบมัลติเทนานซี
Enforce Tenant Context Everywhere
Ask Koder.ai for middleware and data-access patterns that keep tenant context consistent.
การสเกลในมัลติเทนานซีไม่ใช่แค่ "เซิร์ฟเวอร์มากขึ้น" แต่คือการทำให้การเติบโตของ tenant หนึ่งไม่ทำให้คนอื่นตกใจ รูปแบบที่ดีที่สุดทำให้การสเกลคาดเดาได้ วัดได้ และย้อนกลับได้
การสเกลแนวนอนสำหรับบริการไร้สถานะ
เริ่มจากทำให้ชั้นเว็บ/API ไร้สถานะ: เก็บเซสชันในแคชที่แชร์ (หรือใช้ token-based auth), เก็บอัปโหลดใน object storage, และดันงานยาวไปยัง background jobs เมื่อคำขอไม่ขึ้นกับหน่วยความจำหรือดิสก์ท้องถิ่น คุณสามารถเพิ่มอินสแตนซ์หลัง load balancer และสเกลออกได้อย่างรวดเร็ว
เคล็ดปฏิบัติ: เก็บบริบท tenant ที่ขอบ (derived จากซับโดเมนหรือเฮดเดอร์) และส่งผ่านไปยัง handler ทุกคำขอ ไร้สถานะไม่ใช่ไร้ความรู้เรื่อง tenant—แต่รู้ tenant โดยไม่ผูกติดกับเซิร์ฟเวอร์
จุดร้อนเฉพาะ tenant: หาและไล่ให้เรียบ
ปัญหาส่วนใหญ่คือ "tenant เดียวต่างออกไป" ระวังจุดร้อนเช่น:
- tenant เดียวสร้างทราฟฟิกมากผิดปกติ
- บาง tenant มีข้อมูลขนาดใหญ่
- การใช้งานเป็นกลุ่ม (รายเดือน สิ้นเดือน รายงานคืน)
การไล่เรียบมีทั้ง จำกัดอัตรา per-tenant, ingestion แบบคิว, แคชเส้นทางอ่านเฉพาะ tenant, และชาร์ด tenant หนักลง worker pool แยก
รีพลิกาอ่าน การแบ่งพาร์ทิชัน และงานอะซิงก์
ใช้ read replicas สำหรับโหลดอ่านหนัก (แดชบอร์ด ค้นหา analytics) และเก็บเขียนไว้ที่ primary การแบ่งพาร์ทิชัน (ตาม tenant เวลา หรือทั้งสอง) ช่วยให้ดัชนีเล็กลงและคำค้นเร็วขึ้น สำหรับงานแพง—exports, การทำคะแนน ML, webhooks—ควรใช้งานอะซิงก์พร้อม idempotency เพื่อให้ retry ไม่เพิ่มโหลดแบบทวีคูณ
สัญญาณการวางแผนความจุและเกณฑ์ง่ายๆ
เก็บสัญญาณให้ง่ายและตระหนัก tenant: p95 latency, อัตรา error, queue depth, CPU DB, และอัตราคำขอต่อ tenant ตั้งเกณฑ์ง่ายๆ (เช่น “queue depth > N เป็นเวลา 10 นาที” หรือ “p95 > X ms”) ให้กระตุ้นการ autoscale หรือการจำกัด tenant ชั่วคราว—ก่อนที่คนอื่นจะรู้สึก
การสังเกตและปฏิบัติการแยกตาม tenant
ระบบมัลติเทนานซีมักล้มเหลวสำหรับ tenant เดียว ชั้นหนึ่ง หรือ workload ดังน้อย หาก logs และแดชบอร์ดของคุณตอบคำถามว่า “tenant ไหนได้รับผลกระทบ?” ไม่ได้ในไม่กี่วินาที เวลาบนหน้าตอนเกิดเหตุจะกลายเป็นการเดา
logs metrics และ traces ที่ตระหนัก tenant
เริ่มด้วยบริบท tenant ที่สม่ำเสมอทั่ว telemetry:
- Logs: ใส่
tenant_id,request_id, และactor_idที่เสถียร (user/service) ในทุกคำขอและงานแบ็กกราวน์ - Metrics: ปล่อย counters และ histograms latency แยกตาม tier ของ tenant อย่างน้อย (เช่น
tier=basic|premium) และแยกตาม endpoint ระดับสูง - Traces: ส่งต่อบริบท tenant เป็น attribute ของ trace เพื่อกรอง trace ช้าให้เจอ tenant ที่เฉพาะเจาะจงและเห็นว่าช่วงเวลาไปอยู่ที่ไหน (DB, cache, บริการภายนอก)
ควบคุม cardinality: metrics per-tenant สำหรับทุก tenant อาจแพง ทางสายกลางคือ metrics ระดับ tier โดยดีฟอลต์ พร้อม drill-down per-tenant ตามต้องการ (เช่น sampling traces สำหรับ “top 20 tenants by traffic” หรือ “tenants ที่กำลังละเมิด SLO”)
หลีกเลี่ยงการรั่วข้อมูลสำคัญใน telemetry
Telemetry เป็นช่องทางการส่งออกข้อมูล ปฏิบัติกับมันเหมือนข้อมูล production
ชอบใช้ ID แทนคอนเทนต์: log customer_id=123 แทนชื่อ อีเมล โทเค็น หรือตัว payload ของคำค้น เพิ่มการ redaction ที่ชั้น logger/SDK และบล็อกลิสต์ความลับทั่วไป (Authorization headers, API keys) สำหรับเวิร์กโฟลว์สนับสนุน เก็บ payload ดีบักในระบบที่มีการควบคุมการเข้าถึงแยกต่างหาก—ไม่ใช่ใน logs ร่วม
SLOs ตาม tier ของ tenant (โดยไม่สัญญาเกินจริง)
กำหนด SLO ที่สอดคล้องกับสิ่งที่คุณบังคับได้จริง Tenant พรีเมียมอาจได้งบประมาณ latency/error ที่เข้มงวดกว่า แต่ต้องมีการควบคุม (rate limits, workload isolation, priority queues) ประกาศ SLO ของแต่ละ tier เป็นเป้าหมาย และติดตามตาม tier และสำหรับชุด tenant มูลค่าสูงที่คัดไว้
Runbook บนหน้าตอนเกิดเหตุ: เหตุการณ์ทั่วไปใน SaaS แบบมัลติเทนานซี
Runbook ควรเริ่มด้วย “ระบุ tenant ที่ได้รับผลกระทบ” แล้วทำการกระทำแยกเร็วที่สุด:
- Noisy neighbor: throttle tenant นั้น หยุดงานหนัก หรือย้ายไปคิวความสำคัญต่ำ
- DB hotspots/runaway queries: เปิด query timeouts, ตรวจสอบ top queries ตาม tenant, ใส่ index หรือลิมิต endpoint
- บั๊กบริบท tenant (ข้อมูลปนกัน): ปิด feature flag หรือ endpoint นั้นทันทีและยืนยันการสโคป tenant ในการตรวจสอบสิทธิ์
- งานแบ็กกราวน์สะสม: ระบายคิว per-tenant, จำกัด concurrency, และ replay ด้วยมาตรการ idempotency
เป้าหมายเชิงปฏิบัติการคือ: ตรวจจับโดย tenant, บริหารโดย tenant, และกู้คืนโดยไม่กระทบทุกคน
การดีพลอย มิเกรชัน และการปล่อยตาม tenant
มัลติเทนานซีเปลี่ยนจังหวะการปล่อยฟีเจอร์ คุณไม่ได้ปล่อยแค่ “แอป” แต่ปล่อย runtime และ data path ที่แชร์ซึ่งลูกค้าหลายรายพึ่งพา เป้าหมายคือปล่อยฟีเจอร์ใหม่โดยไม่บังคับให้ทุก tenant อัพเกรดพร้อมกัน
การดีพลอยแบบหมุนและมิเกรชันไม่สะดุด
ชอบรูปแบบดีพลอยที่ทนต่อ mixed versions ชั่วคราว (blue/green, canary, rolling) นั่นใช้ได้ก็ต่อเมื่อการเปลี่ยนแปลงฐานข้อมูลถูกจัดเป็นขั้นด้วย
กฎปฏิบัติคือ ขยาย → มิเกรท → หด:
- ขยาย: เพิ่มคอลัมน์/ตาราง/ดัชนีใหม่โดยไม่ทำให้โค้ดเก่าพัง
- มิเกรท: เติมข้อมูลแบบแบทช์ (มัก per-tenant) และตรวจสอบ
- หด: เอาฟิลด์เก่าออกเมื่อ instance ทุกตัวไม่พึ่งพามันแล้ว
สำหรับตารางที่ร้อน ให้ทำ backfills แบบค่อยเป็นค่อยไป (และจำกัดความเร็ว) มิฉะนั้นคุณอาจสร้างเหตุ noisy-neighbor ในขณะมิเกรชันเอง
Feature flags ตาม tenant เพื่อการปล่อยที่ปลอดภัย
Feature flags ระดับ tenant ให้คุณปล่อยโค้ดทั่วระบบแต่เปิดพฤติกรรมแบบเลือกได้
สนับสนุน:
- โปรแกรมเข้าถึงล่วงหน้าให้ลูกค้าบางราย
- ยกเลิกเร็วโดยปิดฟีเจอร์สำหรับ tenant ที่ได้รับผล
- ทดลอง A/B โดยไม่ต้องแยก deployment
เก็บระบบ flag ให้ตรวจสอบได้: ใครเปิดอะไร ให้ tenant ไหน และเมื่อไร
เวอร์ชันและความคาดหวังความเข้ากันได้ย้อนหลัง
สมมติว่าบาง tenant อาจล้าหลังในการตั้งค่า การผสาน หรือรูปแบบการใช้งาน ออกแบบ API และเหตุการณ์ด้วยการเวอร์ชันชัดเจนเพื่อให้ producer ใหม่ไม่ทำลาย consumer เก่า
ความคาดหวังทั่วไปภายใน:
- release ใหม่ต้องอ่านรูปแบบเก่าและใหม่ระหว่างหน้าต่างมิเกรชัน
- การยกเลิกต้องมีไทม์ไลน์ประกาศ (แม้แค่บันทึกภายในและเทมเพลตอีเมลลูกค้า)
การจัดการการตั้งค่าเฉพาะ tenant
จัดการ config ของ tenant เป็นพื้นผิวผลิตภัณฑ์: ต้องมีการตรวจสอบ ค่าเริ่มต้น และประวัติการเปลี่ยนแปลง
เก็บการตั้งค่าแยกจากโค้ด (และแยกจากความลับเวลารัน) และรองรับ safe-mode fallback เมื่อ config ผิดพลาด หน้าเบาๆ ภายในเช่น settings/tenants จะช่วยได้มากระหว่างการตอบเหตุการณ์และ rollout เป็นขั้นๆ
AI ช่วยเรื่องสถาปัตยกรรมได้อย่างไร (และข้อจำกัด)
Control Noisy Neighbors
Build per-tenant rate limits and queued jobs so noisy neighbors stay contained.
AI ช่วยเร็วในการคิดสถาปัตยกรรมเบื้องต้นสำหรับ SaaS แบบมัลติเทนานซี แต่ไม่ใช่ทดแทนดุลยพินิจวิศวกรรม การทดสอบ หรือการตรวจสอบความปลอดภัย ให้ใช้ AI เป็นคู่คิดในการระดมความเห็นที่ให้ร่าง แล้วตรวจสอบสมมติฐานทุกข้อ
สิ่งที่สถาปัตยกรรมที่สร้างโดย AI ควรทำ (และไม่ควรทำ)
AI มีประโยชน์ในการสร้างทางเลือกและไฮไลต์ failure modes ทั่วไป (เช่น จุดที่บริบท tenant อาจหายไป หรือที่ทรัพยากรแชร์อาจสร้างปัญหา) แต่ไม่ควรตัดสินรูปแบบแทนคุณ ไม่รับประกันการปฏิบัติตามข้อกำหนด หรือยืนยันประสิทธิภาพ มันไม่เห็นทราฟฟิกจริง ทีม และ edge case ในการผสานของระบบเก่า
ข้อมูลนำเข้าที่สำคัญ: ข้อกำหนด ข้อจำกัด ความเสี่ยง การเติบโต
คุณภาพของผลลัพธ์ขึ้นกับข้อมูลที่ให้ ป้อนข้อมูลที่เป็นประโยชน์เช่น:
- จำนวน tenant ปัจจุบัน เทียบกับ 12–24 เดือนข้างหน้า และปริมาณข้อมูลต่อ tenant ที่คาด
- ข้อกำหนดการแยก (สัญญา กฎระเบียบ ความคาดหวังลูกค้า)
- งบประมาณและความสามารถปฏิบัติการ (on-call maturity, SRE, เครื่องมือ)
- เป้าหมาย latency รูปแบบ peak และ burstiness ตาม tenant
- ความอดทนต่อความเสี่ยง: จะเกิดอะไรขึ้นหาก tenant หนึ่งกระทบอีกคน
ใช้ AI เพื่อเสนอทางเลือกพร้อมข้อแลกเปลี่ยน
ขอให้ AI สร้าง 2–4 แบบแผน (เช่น database-per-tenant vs schema-per-tenant vs row-level isolation) และขอระบุข้อแลกเปลี่ยนอย่างชัดเจน: ต้นทุน ความซับซ้อนการปฏิบัติการ ขอบเขตผลกระทบ ความยุ่งยากในการมิเกรท และขีดจำกัดการสเกล AI ดีในการลิสต์ gotchas ที่คุณจะเปลี่ยนเป็นคำถามออกแบบให้ทีม
ถ้าต้องการไปจาก “ร่างสถาปัตยกรรม” เป็นต้นแบบที่ทำงานได้เร็วขึ้น แพลตฟอร์ม vibe-coding อย่าง Koder.ai สามารถช่วยแปลงการตัดสินใจเหล่านั้นเป็นโครงแอปจริงผ่านแชท—มักเป็น frontend React และ backend Go + PostgreSQL—เพื่อให้คุณตรวจสอบการส่งต่อบริบท tenant, rate limits, และงานมิเกรชันได้เร็วขึ้น ฟีเจอร์เช่น planning mode และ snapshots/rollback มีประโยชน์ตอนวนออกแบบโมเดลข้อมูลมัลติเทนานซี
ใช้ AI ช่วยร่าง threat models และเช็คลิสต์
AI สามารถร่าง threat model ง่ายๆ: จุดเข้าถึง ขอบเขตความเชื่อใจ การส่งผ่านบริบท tenant และความผิดพลาดทั่วไป (เช่น การขาดการตรวจสอบสิทธิ์ใน background jobs) ใช้มันสร้างเช็คลิสต์ตรวจ PR และ runbook—แต่ต้องตรวจสอบโดยผู้เชี่ยวชาญด้านความปลอดภัยจริงและประวัติเหตุการณ์ของคุณ
เช็คลิสต์ปฏิบัติที่ใช้งานได้สำหรับทีมของคุณ
การเลือกวิธีมัลติเทนานซีคือเรื่องความเหมาะสม: ความไวต่อข้อมูล การเติบโต และภาระปฏิบัติการที่ทีมรับได้
เช็คลิสต์แบบทีละขั้น (ใช้ใน workshop 30 นาที)
-
ข้อมูล: ข้อมูลใดแชร์ข้าม tenants (ถ้ามี)? ข้อใดห้ามอยู่ร่วมกัน?
-
ตัวตน: ตัวตน tenant อยู่ที่ไหน (ลิงก์เชิญ โดเมน SSO claims)? บริบท tenant ถูกตั้งค่าในทุกคำขออย่างไร?
-
การแยก: ตัดสินใจระดับการแยกดีฟอลต์ (row/schema/database) และระบุข้อยกเว้น (เช่น ลูกค้า enterprise ต้องการการแยกมากขึ้น)
-
การสเกล: ระบุแรงกดดันการสเกลแรกที่คาด (storage, read traffic, background jobs, analytics) และเลือกรูปแบบที่ง่ายที่สุดที่ตอบปัญหาได้
คำถามให้ยืนยันกับวิศวกรและผู้ตรวจสอบความปลอดภัย
- เราป้องกันการเข้าถึงข้าม tenant ได้อย่างไรถ้านักพัฒนาลืมฟิลเตอร์?
- เรื่องการตรวจสอบประวัติ (audit) per-tenant เป็นอย่างไร (ใครทำอะไร เมื่อไร)?
- เราจัดการการลบข้อมูลและการเก็บรักษาข้อมูล per-tenant อย่างไร?
- ขอบเขตผลกระทบจากมิเกรชันหรือ runaway query เป็นอย่างไร?
- เราทำ throttle, rate-limit, และจัดงบประมาณทรัพยากร per-tenant ได้หรือไม่?
สัญญาณเตือนที่ต้องออกแบบลึกขึ้น
- “เราจะเพิ่มการเช็ค tenant ทีหลัง”
- เครื่องมือแอดมินแชร์ที่เห็นทุกอย่างโดยไม่มีการควบคุมเข้มงวด
- ไม่มีแผนสำหรับสำรอง/กู้คืนเฉพาะ tenant หรือการตอบเหตุการณ์
- คิว/worker pool เดียวไม่มีความยุติธรรมต่อแต่ละ tenant
ตัวอย่าง “คำแนะนำการดำเนินการถัดไป” สรุปสั้นๆ
คำแนะนำ: เริ่มด้วยการแยกระดับแถว + บังคับบริบท tenant อย่างเข้มงวด เพิ่ม throttle per-tenant และกำหนดเส้นทางอัพเกรดไปยังสคีมา/ฐานข้อมูลแยกสำหรับ tenant ที่มีความเสี่ยงสูง
การกระทำถัดไป (2 สัปดาห์): ทำ threat-model ขอบเขต tenant, สร้างโปรโตไทป์การบังคับใช้ใน endpoint เดียว, และซ้อมมิเกรชันบนสำเนา staging สำหรับการฝึก
สำหรับคำแนะนำการโรลเอาต์ ดูบทความ tenant-release-strategies.