10 ก.ค. 2568·2 นาที
รูปแบบคิวงานพื้นหลังง่าย ๆ สำหรับอีเมลและเว็บฮุก
เรียนรู้รูปแบบคิวงานแบ็กกราวด์ง่าย ๆ สำหรับส่งอีเมล รันรายงาน และส่ง webhook พร้อม retry, backoff และ dead-letter โดยไม่ต้องใช้เครื่องมือหนัก
เรียนรู้รูปแบบคิวงานแบ็กกราวด์ง่าย ๆ สำหรับส่งอีเมล รันรายงาน และส่ง webhook พร้อม retry, backoff และ dead-letter โดยไม่ต้องใช้เครื่องมือหนัก
งานที่ใช้เวลามากกว่าหนึ่งหรือสองวินาทีไม่ควรทำภายในคำขอของผู้ใช้ การส่งอีเมล การสร้างรายงาน และการส่ง webhook ขึ้นกับเครือข่าย บริการภายนอก หรือคิวรีช้า บางครั้งบริการเหล่านั้นล่าช้า ล้มเหลว หรือใช้เวลานานกว่าที่คาดไว้
ถ้าคุณทำงานพวกนี้ในขณะที่ผู้ใช้รอ ผู้ใช้จะสังเกตทันที หน้าเพจค้าง ปุ่ม "บันทึก" หมุน และคำขอหมดเวลา การ retry ก็อาจเกิดในจุดที่ไม่เหมาะ—ผู้ใช้รีเฟรช, load balancer รีสไตร, หรือ frontend ส่งข้อมูลซ้ำ แล้วคุณจะได้อีเมลซ้ำ, webhook ซ้ำ, หรือการรันรายงานสองงานแข่งกัน
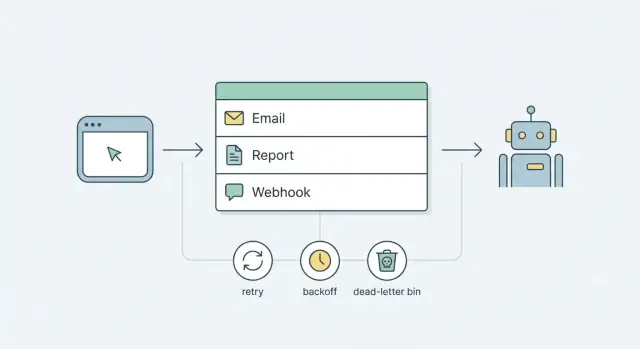
งานแบ็กกราวด์แก้ปัญหานี้โดยทำให้คำขอเล็กและคาดเดาได้: รับการกระทำ ลงบันทึกเป็น job เพื่อทำทีหลัง แล้วตอบกลับอย่างรวดเร็ว งานจะรันนอกคำขอ ภายใต้นโยบายที่คุณควบคุมได้
ส่วนที่ยากคือความน่าเชื่อถือ เมื่อย้ายงานออกจากเส้นทางคำขอ คุณยังต้องตอบคำถามเช่น:
หลายทีมตอบด้วยการเพิ่ม "โครงสร้างพื้นฐานหนัก": message broker, fleet worker แยกต่างหาก, แดชบอร์ด, การแจ้งเตือน และ playbook เครื่องมือเหล่านี้มีประโยชน์เมื่อคุณต้องการจริง ๆ แต่ก็เพิ่มชิ้นส่วนที่ต้องดูแลและโหมดล้มเหลวใหม่
เป้าหมายเริ่มต้นที่ดีกว่าคือความเรียบง่าย: งานที่เชื่อถือได้โดยใช้ส่วนที่คุณมีอยู่แล้ว สำหรับผลิตภัณฑ์ส่วนใหญ่ นั่นหมายถึงคิวที่อิงกับฐานข้อมูลบวกกับ process worker เล็ก ๆ เพิ่มนโยบาย retry และ backoff ที่ชัดเจน และแพตเทิร์น dead-letter สำหรับงานที่ล้มเหลวบ่อย ๆ คุณจะได้พฤติกรรมที่คาดเดาได้โดยไม่ต้องผูกมัดกับแพลตฟอร์มซับซ้อนตั้งแต่วันแรก
แม้ว่าคุณจะสร้างอย่างรวดเร็วด้วยเครื่องมือแชทอย่าง Koder.ai การแยกนี้ก็ยังสำคัญ ผู้ใช้ควรได้รับการตอบสนองที่เร็วในทันที และระบบของคุณควรทำงานช้าหรือเสี่ยงล้มเหลวให้เสร็จอย่างปลอดภัยในแบ็กกราวด์
คิวคือแถวรอสำหรับงาน แทนที่จะทำงานช้าในคำขอของผู้ใช้ (ส่งอีเมล สร้างรายงาน เรียก webhook) ให้ใส่เรคอร์ดเล็ก ๆ ลงในคิวแล้วตอบกลับเร็ว ๆ ต่อมาจะมี process แยกมาดึงเรคอร์ดนั้นไปทำงาน
คำศัพท์ที่คุณจะเจอบ่อย ๆ:
โฟลว์ที่ง่ายที่สุดเป็นดังนี้:
Enqueue: แอปของคุณบันทึกเรคอร์ดงาน (ประเภท, payload, เวลารัน)
Claim: worker หา job ถัดไปที่ว่างและ "ล็อก" มันเพื่อให้มี worker เดียวรันมัน
Run: worker ทำงาน (ส่ง สร้าง ส่งต่อ)
Finish: ทำเครื่องหมายว่าเสร็จ หรือบันทึกความล้มเหลวและตั้งเวลารันครั้งถัดไป
ถ้าปริมาณงานไม่มากและคุณมีฐานข้อมูลแล้ว คิวที่อิงฐานข้อมูลมักเพียงพอ เข้าใจง่าย ดีต่อการดีบัก และครอบคลุมความต้องการทั่วไปเช่นการประมวลผลงานอีเมลและความน่าเชื่อถือในการส่ง webhook
แพลตฟอร์มสตรีมมิ่งเริ่มมีเหตุผลเมื่อคุณต้องการ throughput สูงมาก ผู้บริโภคหลายรายแบบแยกอิสระ หรือความสามารถในการ replay ประวัติอีเวนต์ขนาดใหญ่ข้ามหลายระบบ ถ้าคุณรันบริการหลายสิบตัวพร้อมเหตุการณ์ล้านต่อชั่วโมง เช่น Kafka จะช่วยได้ แต่จนกว่าจะถึงจุดนั้น ตารางฐานข้อมูลบวกวงจร worker ครอบคลุมคิวโลกความเป็นจริงได้มากแล้ว
คิวที่อิงฐานข้อมูลจะคุมค่าได้แค่ถ้าแต่ละเรคอร์ดตอบ 3 คำถามได้เร็ว: จะทำอะไร, จะลองครั้งถัดไปเมื่อไหร่, และครั้งก่อนเกิดอะไรขึ้น ทำถูกแล้วการปฏิบัติการจะน่าเบื่อ (ซึ่งเป็นเป้าหมาย)
เก็บอินพุตที่เล็กที่สุดที่จำเป็นสำหรับทำงาน อย่าเก็บเอาต์พุตที่เรนเดอร์แล้ว payload ที่ดีเป็น ID และพารามิเตอร์ไม่กี่ตัว เช่น { "user_id": 42, "template": "welcome" }
หลีกเลี่ยงการเก็บบล็อบขนาดใหญ่ (HTML อีเมลเต็ม รายงานขนาดใหญ่ ตัวเนื้อหา webhook ใหญ่ ๆ) เพราะจะทำให้ฐานข้อมูลโตเร็วและทำให้การดีบักยากขึ้น ถ้างานต้องการเอกสารขนาดใหญ่ ให้เก็บเป็นการอ้างอิงแทน: report_id, export_id, หรือ file key แล้วให้ worker ดึงข้อมูลจริงเมื่อรัน
อย่างน้อย ควรมีพื้นที่สำหรับ:
job_type เลือก handler (send_email, generate_report, deliver_webhook). payload เก็บอินพุตเล็ก ๆ เช่น ID และตัวเลือกqueued, running, succeeded, failed, dead)attempt_count และ max_attempts เพื่อหยุด retry เมื่อชัดเจนว่าไม่ควรลองอีกcreated_at และ next_run_at (เมื่อถึงเวลาที่ทำได้) เพิ่ม started_at และ finished_at ถ้าต้องการมองเห็นงานช้าชัดขึ้นidempotency_key เพื่อป้องกันผลข้างเคียงซ้ำ และ last_error เพื่อดูสาเหตุล้มเหลวโดยไม่ต้องไล่ logsIdempotency ฟังดูซับซ้อน แต่ความคิดง่าย: ถ้างานเดียวกันรันสองครั้ง ครั้งที่สองควรตรวจเจอแล้วไม่ทำสิ่งที่อันตราย เช่น งานส่ง webhook อาจใช้ idempotency key เช่น webhook:order:123:event:paid เพื่อไม่ส่งอีเวนต์ซ้ำถ้า retry ทับกับ timeout
เก็บตัวเลขพื้นฐานไม่กี่ตัวตั้งแต่ต้น คุณไม่ต้องมีแดชบอร์ดใหญ่เริ่มต้น แค่คิวรีที่บอกว่า: มีกี่งานรอ, มีกี่งานล้มเหลว, อายุของงานที่เก่าแก่ที่สุด
ถ้าคุณมีฐานข้อมูลแล้ว คุณสามารถเริ่มคิวแบ็กกราวด์โดยไม่ต้องเพิ่มโครงสร้างพื้นฐานใหม่ งานเป็นแถว และ worker เป็น process ที่คอยเลือกแถวที่ถึงเวลาแล้วทำงาน
เก็บตารางให้ง่ายและเรียบ ๆ คุณต้องการฟิลด์พอให้รัน retry และดีบักในภายหลัง
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
ถ้าคุณสร้างบน Postgres (พบบ่อยกับ backend ที่เขียนด้วย Go) jsonb เป็นวิธีที่ใช้ได้จริงในการเก็บข้อมูลงานเช่น { "user_id":123,"template":"welcome" }
(บล็อกโค้ด SQL ข้างต้นต้องไม่ถูกแปลหรือแก้ไข)
เมื่อการกระทำของผู้ใช้จะกระตุ้นงาน (ส่งอีเมล เรียก webhook) ให้เขียนแถว job ใน transaction เดียวกับการเปลี่ยนแปลงหลักเมื่อเป็นไปได้ นั่นป้องกันกรณี "ผู้ใช้ถูกสร้างแต่ job หาย" ถ้าแอปล่มหลังจากเขียนข้อมูลหลัก
ตัวอย่าง: เมื่อลงทะเบียนผู้ใช้ ให้ insert แถว user และ job send_welcome_email ใน transaction เดียวกัน
Worker ทำซ้ำวงจรเดียวกัน: หา job ที่ถึงเวลา อ้างสิทธิ์มันเพื่อไม่ให้คนอื่นเอาไป ทำงาน แล้วทำเครื่องหมายว่าเสร็จหรือกำหนด retry
ในการปฏิบัติ:
status='queued' และ next_run_at <= now()SELECT ... FOR UPDATE SKIP LOCKED)status='running', locked_at=now(), locked_by='worker-1'done/succeeded) หรือบันทึก last_error และตั้งเวลา retry ครั้งต่อไปหลาย worker สามารถรันพร้อมกันได้ ขั้นตอนอ้างสิทธิ์คือสิ่งที่ป้องกันการเลือกซ้ำ
เมื่อปิดโปรเซส หยุดรับงานใหม่ ให้ทำงานปัจจุบันให้เสร็จ แล้วออก ถ้าโปรเซสตายกลางคัน ใช้กฎง่าย ๆ: งานที่ค้างในสถานะ running เกิน timeout ให้ถือว่าสามารถ re-queue ได้โดยงาน periodic "reaper"
ถ้าคุณสร้างใน Koder.ai แบบแนะนำ คิวฐานข้อมูลนี้เป็นค่าเริ่มต้นที่มั่นคงสำหรับอีเมล รายงาน และ webhook ก่อนจะเพิ่มบริการคิวเฉพาะทาง
Retry คือวิธีที่คิวสงบเมื่อโลกภายนอกไม่แน่นอน ไม่มีนโยบายที่ชัดเจน การ retry จะกลายเป็นลูปเสียงดังที่สแปมผู้ใช้ ตี API ซ้ำ และปกปิดบั๊กจริง
เริ่มจากตัดสินใจว่าอะไรควร retry และอะไรควรล้มเร็ว
Retry ปัญหาชั่วคราว: timeout เครือข่าย, 502/503, rate limit, หรือการเชื่อมต่อฐานข้อมูลสะดุด
Fail fast เมื่องานจะไม่สำเร็จเลย: ที่อยู่อีเมลหายไป, 400 จาก webhook เพราะ payload ไม่ถูกต้อง, หรือขอรายงานสำหรับบัญชีที่ถูกลบ
Backoff คือช่วงเวลาหยุดระหว่างการลอง Linear backoff (5s, 10s, 15s) เรียบง่าย แต่ยังสร้างคลื่นของทราฟฟิกได้ Exponential backoff (5s, 10s, 20s, 40s) กระจายโหลดได้ดีกว่าและปลอดภัยสำหรับเว็บฮุกและผู้ให้บริการภายนอก เพิ่ม jitter (ดีเลย์สุ่มเล็กน้อย) เพื่อไม่ให้พันงาน retry ในวินาทีเดียวกันหลังจากการล่ม
กฎที่มักทำงานดีใน production:
Max attempts คือการจำกัดความเสียหาย สำหรับหลายทีม 5–8 attempts เพียงพอ หลังจากนั้น ให้หยุด retry และย้ายงานไปสู่ลำดับ dead-letter แทนที่จะวนไม่รู้จบ
Timeout ป้องกันงาน "ซอมบี้" อีเมลอาจตั้ง timeout ประมาณ 10–20 วินาทีต่อการลอง Webhook มักต้องการ limit สั้นกว่า เช่น 5–10 วินาที เพราะผู้รับอาจล่มและคุณอยากไปงานถัดไป รายงานอาจอนุญาตให้รันเป็นนาทีได้ แต่ก็ควรมี cutoff แน่นอน
ถ้าสร้างใน Koder.ai ให้ปฏิบัติกับ should_retry, next_run_at และ idempotency key เป็นฟิลด์สำคัญ รายละเอียดเล็ก ๆ เหล่านี้ทำให้ระบบเงียบเมื่อเกิดปัญหา
สถานะ dead-letter คือที่ที่งานไปเมื่อการ retry ไม่ปลอดภัยหรือไม่มีประโยชน์ มันเปลี่ยนความล้มเหลวที่เงียบให้กลายเป็นสิ่งที่คุณเห็น ค้นหาได้ และจะจัดการได้
เก็บข้อมูลพอให้เข้าใจว่าเกิดอะไรขึ้นและสามารถ replay งานได้โดยไม่ต้องเดา แต่ระวังความลับ
เก็บไว้:
ถ้า payload มีโทเคนหรือข้อมูลส่วนบุคคล ให้ redacted หรือเข้ารหัสก่อนเก็บ
เมื่อ job ตกสู่ dead-letter ให้ตัดสินใจเร็ว ๆ: retry, แก้ไข, หรือเพิกเฉย
Retry สำหรับการล่มจากภายนอกและ timeout แก้ไขสำหรับข้อมูลไม่ถูกต้อง (อีเมลหาย, URL webhook ผิด) หรือบั๊กในโค้ด เพิกเฉยควรน้อย แต่ถูกต้องเมื่องานไม่เกี่ยวข้องแล้ว (เช่น ลูกค้าลบบัญชี) หากเพิกเฉย ให้บันทึกเหตุผลเพื่อไม่ให้ดูเหมือนงานหายไป
การ requeue แบบแมนนวลปลอดภัยที่สุดเมื่อมันสร้างงานใหม่และเก็บงานเก่าให้อยู่ไม่เปลี่ยนแปลง ทำเครื่องหมายงาน dead-letter ว่าใคร requeued เมื่อไหร่ และทำไม แล้ว enqueue สำเนาใหม่ที่มี ID ใหม่
สำหรับการแจ้งเตือน ให้เฝ้าสัญญาณที่มักหมายถึงปัญหาใหญ่: จำนวน dead-letter เพิ่มขึ้นเร็ว ข้อผิดพลาดเดียวกันเกิดซ้ำในหลายงาน และงานที่คิวไว้เก่าไม่ถูกคนเอาไปทำ
ถ้าคุณใช้ Koder.ai ภาพ snapshot และ rollback ช่วยเมื่อ release แย่ ๆ ทำให้ความล้มเหลวพุ่ง เพราะคุณจะย้อนกลับได้เร็วขณะสืบสวน
สุดท้าย เพิ่มวาล์วความปลอดภัยสำหรับการล่มของ vendor จำกัดการส่งต่อให้แต่ละผู้ให้บริการ และใช้ circuit breaker: ถ้าจุดรับ webhook ล้มหนัก ให้หยุดการพยายามใหม่สักช่วงสั้น ๆ เพื่อไม่ให้คุณและพวกเขาถูกน้ำท่วม
คิวทำงานได้ดีที่สุดเมื่อแต่ละประเภทงานมีกฎชัดเจน: อะไรถือเป็นความสำเร็จ, อะไรควร retry, และอะไรห้ามเกิดซ้ำ
อีเมล. ความล้มเหลวของอีเมลมักเป็นชั่วคราว: timeout ผู้ให้บริการ, rate limit, หรือการล่มสั้น ๆ ให้ retry ด้วย backoff ความเสี่ยงใหญ่คือการส่งซ้ำ ทำให้งานอีเมลเป็น idempotent เก็บ dedupe key คงที่ เช่น user_id + template + event_id และปฏิเสธการส่งซ้ำหากคีย์นั้นถูกมาร์กเป็นส่งแล้ว
ควรเก็บชื่อเทมเพลตและเวอร์ชัน (หรือ hash ของ subject/body ที่เรนเดอร์) ถ้าต้อง re-run งาน คุณจะเลือกได้ว่าจะ resend เนื้อหาเดิมหรือเรนเดอร์ใหม่ ถ้าผู้ให้บริการคืน message ID ให้บันทึกไว้เพื่อการติดตาม
รายงาน. การล้มเหลวของรายงานต่างออกไป มันอาจรันเป็นนาที ติดขีดจำกัด pagination หรือล้มเพราะหน่วยความจำไม่พอเมื่อทำทั้งหมดในครั้งเดียว แบ่งงานเป็นชิ้นเล็ก ๆ แพตเทิร์นที่พบบ่อยคือ: งาน "report request" หนึ่งงานสร้างหลายงาน "page" หรือ "chunk" แต่ละงานประมวลผลชิ้นของข้อมูล
เก็บผลลัพธ์ไว้เพื่อดาวน์โหลดภายหลังแทนที่จะให้ผู้ใช้รอ อาจเป็นตารางฐานข้อมูลที่ใช้ report_run_id เป็นคีย์ หรือ reference ไฟล์พร้อมเมตาดาต้า (status, row count, created_at) เพิ่มฟิลด์ความคืบหน้าเพื่อให้ UI แสดง "กำลังประมวลผล" กับ "พร้อมแล้ว" โดยไม่เดา
Webhooks. เว็บฮุกเน้นความน่าเชื่อถือของการส่ง ไม่ใช่ความเร็ว ลงลายเซ็นทุกคำขอ (เช่น HMAC กับ secret ร่วม) และใส่ timestamp เพื่อป้องกัน replay Retry เฉพาะเมื่อผู้รับอาจสำเร็จในภายหลัง
ชุดกฎง่าย ๆ:
การจัดลำดับและความสำคัญ. งานส่วนใหญ่ไม่ต้องการ ordering เข้มงวด เมื่อ ordering จำเป็น มักเป็น per-key (ต่อผู้ใช้ ต่อใบแจ้งหนี้ ต่อ endpoint) เพิ่ม group_key และให้มีงานเดียวที่กำลังรันต่อ key
สำหรับความสำคัญ แยกงานด่วนจากงานช้า backlog รายงานขนาดใหญ่ไม่ควรดีเลย์อีเมลรีเซ็ตรหัสผ่าน
ตัวอย่าง: หลังการซื้อ คุณ enqueue (1) อีเมลยืนยันคำสั่งซื้อ, (2) webhook ให้พาร์ทเนอร์, และ (3) งานอัพเดตรายงาน งานอีเมล retry ไว เว็บฮุก retry นานขึ้นด้วย backoff รายงานรันทีหลังด้วยความสำคัญต่ำ
ถ้างานใช้เวลามากกว่า 1–2 วินาที หรือขึ้นกับการเรียกเครือข่าย (ผู้ให้บริการอีเมล, จุดรับ webhook, คิวรีช้า) ให้ย้ายไปเป็นงานแบ็กกราวด์。
เก็บคำขอของผู้ใช้ให้ง่าย: ตรวจสอบข้อมูล, เขียนการเปลี่ยนแปลงหลัก, ใส่ job ลงคิว แล้วตอบกลับเร็ว ๆ
เริ่มด้วยคิวที่เก็บในฐานข้อมูลเมื่อ:
เพิ่ม message broker หรือแพลตฟอร์ม streaming เมื่อคุณต้องการ throughput สูงมาก, ผู้บริโภคหลายฝ่ายที่เป็นอิสระ, หรือความสามารถในการ replay เหตุการณ์ข้ามบริการหลายตัว
เก็บค่าพื้นฐานที่ตอบคำถาม: จะทำอะไร, จะลองครั้งถัดไปเมื่อไหร่, และครั้งก่อนเกิดอะไรขึ้น。
ขั้นต่ำที่ใช้งานได้จริง:
เก็บ อินพุต ไม่ใช่เอาต์พุตขนาดใหญ่。
Payload ที่ดี:
user_id, template, report_id)หลีกเลี่ยง:
กุญแจคือนาทีการอ้างสิทธิ์ (claim) แบบอะตอมิก เพื่อไม่ให้สอง worker เอางานเดียวกันไปทำ。
วิธีที่พบบ่อยบน Postgres:
FOR UPDATE SKIP LOCKED)running และบันทึก locked_at/locked_by ทันทีวิธีนี้ทำให้ worker ขยายแบบขนานได้โดยไม่ประมวลผลซ้ำ
ถือว่าบางครั้งงานจะรันซ้ำได้ (crash, timeout, retry) ให้ผลข้างเคียงปลอดภัย:
รูปแบบง่าย ๆ:
idempotency_key เช่น welcome_email:user:123สิ่งนี้สำคัญมากสำหรับอีเมลและ webhook เพื่อป้องกันการส่งซ้ำ
ใช้ policy เริ่มต้นที่ชัดเจนและเรียบง่าย:
Fail fast กับข้อผิดพลาดถาวร (ที่อยู่อีเมลหายไป, payload ไม่ถูกต้อง, 4xx ส่วนใหญ่จาก webhook)
Dead-letter คือสถานะที่หยุด retry และทำให้ปัญหามองเห็นได้ ใช้เมื่อ:
max_attemptsเก็บบริบทพอให้ทำงานได้ เช่น job type, payload (redact ถ้าจำเป็น), attempt count, timestamps, last_error และรหัสสถานะล่าสุด (เว็บฮุก)
เมื่อ replay ให้สร้างงานใหม่และเก็บงาน dead-letter ไว้เป็น immutable
จัดการงานที่ติดสถานะ running หลัง crash ด้วยสองกฎ:
running ที่เกินเวลาที่กำหนด แล้วทำการ re-queue หรือทำเครื่องหมายว่า failedวิธีนี้ให้ระบบฟื้นตัวจาก worker crash ได้โดยไม่ต้องแก้ด้วยมือมาก
แยกงานช้ากับงานด่วน:
ถ้าต้องการลำดับ ให้ใช้ group_key และอนุญาตให้มีงานเดียวต่อ key ที่กำลังรันเพื่อรักษาลำดับในระดับท้องถิ่นโดยไม่ต้องบังคับลำดับทั่วทั้งระบบ
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at, และ created_atlocked_at, locked_bylast_erroridempotency_key (หรือกลไก dedupe อื่น ๆ)ถ้างานต้องการข้อมูลใหญ่ ให้เก็บเป็น reference (เช่น report_run_id หรือ file key) แล้วให้ worker ดึงข้อมูลจริงเมื่อทำงาน