03 ต.ค. 2568·2 นาที
เวิร์กโฟลว์แบบ snapshot-first เพื่อเปลี่ยนใหญ่ที่ปลอดภัยกว่า
เรียนรู้เวิร์กโฟลว์แบบ snapshot-first เพื่อสร้างจุดบันทึกปลอดภัยก่อนเปลี่ยน schema, auth และ UI และย้อนกลับโดยไม่เสียความคืบหน้า
เรียนรู้เวิร์กโฟลว์แบบ snapshot-first เพื่อสร้างจุดบันทึกปลอดภัยก่อนเปลี่ยน schema, auth และ UI และย้อนกลับโดยไม่เสียความคืบหน้า
เวิร์กโฟลว์แบบ snapshot-first หมายความว่าคุณสร้างจุดบันทึกก่อนจะทำการเปลี่ยนที่อาจทำให้แอปพัง Snapshot คือสำเนาคงที่ของโปรเจค ณ ช่วงเวลาใดช่วงเวลาหนึ่ง ถ้าก้าวต่อไปเกิดปัญหา คุณสามารถกลับไปยังสถานะเดิมได้แทนที่จะมานั่งไล่แก้ทีละอย่างด้วยมือ
การเปลี่ยนใหญ่ๆ มักไม่ล้มเหลวในทางที่ชัดเจนเสมอไป การอัพเดต schema อาจทำให้รายงานที่อยู่ไกลออกไปพัง การปรับ auth อาจล็อกคุณออก การเขียน UI ใหม่อาจดูดีด้วยข้อมูลตัวอย่าง แต่พังเมื่อใช้กับบัญชีจริงและเคสขอบเขต ถ้าไม่มีจุดบันทึกชัดเจน คุณจะต้องเดาว่าแปลงไหนเป็นต้นเหตุ หรือคอยปะพื้นไปเรื่อยๆ จนลืมไปว่า "สถานะที่ทำงาน" เป็นอย่างไร
Snapshot มีประโยชน์เพราะให้ baseline ที่รู้ว่าดี มันทำให้ลองไอเดียกล้าหาญได้ถูกลง และทำให้การทดสอบง่ายขึ้น เมื่อมีอะไรพัง คุณจะตอบได้ว่า: "ตอนหลังจาก Snapshot X มันยังโอเคอยู่ไหม?"
ควรชัดเจนว่า snapshot ปกป้องอะไรได้และไม่ได้ Snapshot เก็บโค้ดและการตั้งค่า ณ ตอนนั้น (และบนแพลตฟอร์มอย่าง Koder.ai มันอาจเก็บสถานะแอปทั้งหมดที่คุณกำลังทำงานด้วย) แต่จะไม่แก้สมมติฐานที่ผิด หากฟีเจอร์ใหม่คาดหวังคอลัมน์ฐานข้อมูลที่ไม่มีใน production การย้อนกลับโค้ดจะไม่ย้อนการมายเกรชันที่รันแล้ว คุณยังต้องมีแผนเรื่องการเปลี่ยนข้อมูล ความเข้ากันได้ และลำดับการดีพลอย
การเปลี่ยนความคิดคือมองการทำ snapshot เป็นนิสัย ไม่ใช่ปุ่มช่วยชีวิต ถ่าย snapshot ก่อนการเคลื่อนไหวที่เสี่ยง ไม่ใช่หลังจากมีอะไรพัง คุณจะเคลื่อนไหวได้เร็วขึ้นและใจเย็นขึ้นเพราะมี "สถานะสุดท้ายที่รู้ว่าดี" ไว้กลับเสมอ
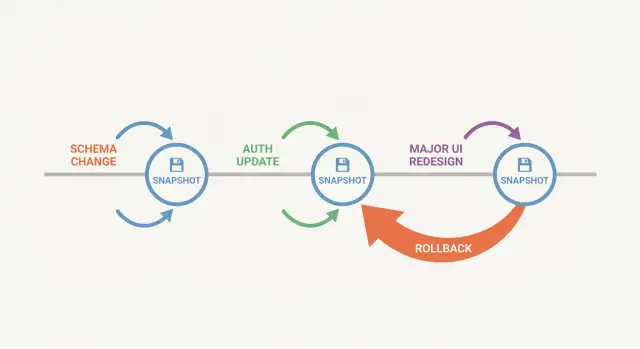
Snapshot คุ้มค่ามากเมื่อการเปลี่ยนสามารถทำให้หลายส่วนพังพร้อมกัน
งานกับ schema เป็นตัวอย่างชัดเจน: ตั้งชื่อคอลัมน์ใหม่แล้วคุณอาจทำ API, background job, export, และรายงานที่ยังคาดหวังชื่อเก่าให้พังได้ง่ายๆ งานเกี่ยวกับการยืนยันตัวตนก็เช่นกัน: กฎเล็กน้อยอาจล็อกเอาท์แอดมินหรือให้สิทธิ์ที่ไม่ตั้งใจ การเขียน UI ใหม่มักผสมการเปลี่ยนทั้งด้านภาพและพฤติกรรม และ regression มักซ่อนในสเตตัสขอบเขต
ถ้าต้องการกฎง่ายๆ: สแนปชอตก่อนทุกอย่างที่เปลี่ยนรูปทรงของข้อมูล, ระบุตัวตนและการเข้าถึง, หรือหลายหน้าพร้อมกัน
การแก้ไขความเสี่ยงต่ำมักไม่จำเป็นต้องหยุดแล้ว snapshot บ่อยๆ การเปลี่ยนข้อความ, ปรับช่องว่างเล็กๆ, กฎการตรวจสอบเล็กๆ หรือล้างฟังก์ชันช่วยเล็กๆ มักมี blast radius เล็ก คุณยังสามารถ snapshot ถ้ามันช่วยให้คุณโฟกัส แต่ไม่จำเป็นต้องขัดจังหวะทุกการแก้ไขเล็กน้อย
การเปลี่ยนความเสี่ยงสูงต่างออกไป พวกนี้มักทำงานผ่านการทดสอบ "เส้นทางสมบูรณ์" แต่ล้มเหลวกับค่า null ในแถวเก่า, ผู้ใช้ที่มีการรวมบทบาทไม่ปกติ, หรือสถานะ UI ที่คุณไม่ได้เจอด้วยมือ
สแนปชอตช่วยได้เมื่อคุณจำมันได้อย่างรวดเร็วภายใต้ความกดดัน ชื่อและบันทึกคือสิ่งที่เปลี่ยนการย้อนกลับให้เป็นการตัดสินใจที่สงบและไว
ป้ายที่ดีตอบสามคำถาม:\n\n- เปลี่ยนอะไร?\n- ทำไมถึงเปลี่ยน?\n- ก้าวถัดไปคืออะไร?\n\nให้สั้นแต่เฉพาะเจาะจง หลีกเลี่ยงชื่อกว้างๆ อย่าง “before update” หรือ “try again”
เลือกรูปแบบหนึ่งแล้วยึดตามตัวอย่าง:\n\n- [WIP] Auth: add magic link (prep for OAuth)\n- [GOLD] DB: users table v2 (passes smoke tests)\n- [WIP] UI: dashboard layout refactor (next: charts)\n- [GOLD] Release: billing fixes (deployed)\n- Hotfix: login redirect loop (root cause noted)\n\nสถานะก่อน, แล้วจึงพื้นที่, การกระทำ, แล้วสั้นๆ ว่า "ถัดไป" ส่วนสุดท้ายนั้นช่วยได้มากเมื่อผ่านมาแล้วสัปดาห์หนึ่ง
ชื่ออย่างเดียวไม่พอ ใช้บันทึกเพื่อจับสิ่งที่ตัวเองในอนาคตจะลืม: สมมติฐานที่คุณทำ, สิ่งที่คุณทดสอบ, อะไรยังพังอยู่, และสิ่งที่คุณตั้งใจละไว้
บันทึกที่ดีมักมีสมมติฐาน, 2–3 ขั้นตอนการทดสอบสั้นๆ, ปัญหาที่รู้ และรายละเอียดเสี่ยง (การปรับ schema, การเปลี่ยนสิทธิ์, การเปลี่ยน routing)
มาร์ก snapshot เป็น GOLD ก็ต่อเมื่อปลอดภัยที่จะกลับไปโดยไม่มีเซอร์ไพรส์: ฟลูว์พื้นฐานทำงาน, ข้อผิดพลาดเข้าใจได้, และคุณสามารถทำงานต่อจากจุดนั้นได้ ทุกอย่างที่เหลือคือ WIP นิสัยเล็กๆ นี้ป้องกันการย้อนกลับไปยังจุดที่ดูนิ่งแต่คุณลืมบั๊กใหญ่ไว้
วงจรที่ดีเป็นเรื่องเรียบง่าย: เคลื่อนไปข้างหน้าจากจุดที่รู้ว่าดีเท่านั้น
ก่อนจะ snapshot ให้แน่ใจว่าแอปยังรันและฟลูว์สำคัญทำงาน เก็บให้เล็ก: เปิดหน้าหลักได้ไหม, ล็อกอินได้ไหม (ถ้ามี), และทำหนึ่งการกระทำหลักจนเสร็จโดยไม่มีข้อผิดพลาดหรือไม่? ถ้ามีบางอย่างไม่เสถียร ให้แก้ก่อน มิฉะนั้น snapshot จะเก็บปัญหาไว้
สร้าง snapshot แล้วเพิ่มโน้ตสั้นๆ ว่าทำเพื่ออะไร อธิบายความเสี่ยงที่จะเกิดขึ้น ไม่ใช่สภาพปัจจุบัน
ตัวอย่าง: “Before changing users table + adding organization_id” หรือ “Before auth middleware refactor to support SSO”.
หลีกเลี่ยงการกองการเปลี่ยนใหญ่หลายอย่างในรอบเดียว (schema พร้อม auth พร้อม UI) เลือกสไลซ์เดียว จบมัน แล้วหยุด
“การเปลี่ยนหนึ่งอย่าง” ที่ดีคือ “เพิ่มคอลัมน์ใหม่และทำให้โค้ดเก่ายังคงทำงาน” มากกว่าการ “แทนที่โมเดลข้อมูลทั้งหมดและอัพเดตทุกหน้าจอ”
หลังแต่ละขั้นตอน ให้รันการเช็คเดิมเพื่อให้ผลเทียบกันได้ ทำให้มันสั้นเพื่อคุณจะได้ทำจริง
เมื่อการเปลี่ยนใช้งานได้และคุณมี baseline สะอาด ให้ถ่าย snapshot อีกครั้ง นั่นจะเป็นจุดปลอดภัยใหม่สำหรับก้าวถัดไป
การเปลี่ยนฐานข้อมูลมักดู "เล็ก" จนกว่าจะทำให้ signup, รายงาน หรือ background job ที่คุณลืมมีปัญหา ปฏิบัติงาน schema เป็นลำดับของ checkpoint ปลอดภัย ไม่ใช่กระโดดครั้งเดียว
เริ่มด้วย snapshot ก่อนแตะอะไร แล้วเขียน baseline เป็นภาษาง่ายๆ: ตารางใดเกี่ยวข้อง, หน้าจอหรือ API ใดอ่านข้อมูล, และ "ถูกต้อง" คืออะไร (ฟิลด์ที่ต้องมี, กฎ unique, จำนวนแถวที่คาดหวัง) การทำสิ่งนี้ใช้เวลาไม่กี่นาทีแต่ช่วยประหยัดชั่วโมงเมื่อคุณต้องเทียบพฤติกรรม
ชุดจุดบันทึกที่ปฏิบัติได้สำหรับงาน schema ส่วนใหญ่มีลักษณะดังนี้:
หลีกเลี่ยงการมายเกรชันครั้งใหญ่ที่เปลี่ยนชื่อทุกอย่างพร้อมกัน แบ่งเป็นก้าวเล็กๆ ที่คุณสามารถทดสอบและย้อนกลับได้
หลังแต่ละ checkpoint ให้ยืนยันมากกว่าทางเดินปกติ CRUD ที่ขึ้นกับตารางที่เปลี่ยนแปลงสำคัญ แต่ export (ดาวน์โหลด CSV, ใบแจ้งหนี้, รายงานแอดมิน) ก็สำคัญเพราะมักใช้ query เก่า
วางแผนเส้นทางการย้อนกลับก่อนเริ่ม ถ้าคุณเพิ่มคอลัมน์ใหม่แล้วเริ่มเขียนข้อมูลลงไป ให้ตัดสินใจว่าจะทำอย่างไรหากย้อนกลับ: โค้ดเก่าจะละเลยคอลัมน์ใหม่อย่างปลอดภัยหรือคุณต้องมี reverse migration? หากอาจได้ข้อมูลที่ย้ายไม่เสร็จ ให้ตัดสินใจว่าจะตรวจจับและทำให้เสร็จหรือยกเลิกอย่างสะอาดอย่างไร
การเปลี่ยน auth เป็นหนึ่งในวิธีที่เร็วที่สุดที่จะล็อกตัวเอง (และผู้ใช้) ออก จุดบันทึกช่วยเพราะคุณสามารถลองการเปลี่ยนเสี่ยง ทดสอบ และย้อนกลับได้อย่างรวดเร็วถ้าจำเป็น
ถ่าย snapshot ทันที ก่อนแตะ auth แล้วเขียนลงว่าระบบตอนนี้เป็นอย่างไร แม้มันจะดูชัดเจนก็ตาม นี่ป้องกันความประหลาดใจแบบ “ฉันคิดว่าแอดมินยังล็อกอินได้”
จับข้อมูลพื้นฐาน:\n\n- วิธีล็อกอินปัจจุบัน (email/password, magic link, SSO/OAuth ฯลฯ)\n- บทบาทและสิทธิ์ (ผู้ใช้ vs แอดมิน ทำอะไรได้บ้าง)\n- กฎพิเศษ (invite-only, 2FA จำเป็น, allowlist IP)\n- บัญชีทดสอบ (ผู้ใช้ปกติ 1 บัญชี, แอดมิน 1 บัญชี)\n- ความลับและการตั้งค่าสภาพแวดล้อมที่ผูกกับ auth (คีย์, callback URLs, อายุ token)
เมื่อเริ่มเปลี่ยน ให้เปลี่ยนทีละกฎ หากเปลี่ยนการตรวจบทบาท, โลจิก token, และหน้าจอการล็อกอินพร้อมกัน คุณจะไม่รู้ว่าอะไรเป็นสาเหตุของความล้มเหลว
จังหวะที่ดีคือ: เปลี่ยนชิ้นเดียว, รันเช็คสั้นเดิม, แล้ว snapshot อีกครั้งถ้ามันสะอาด ตัวอย่าง: เมื่อต้องเพิ่มบทบาท "editor" ให้ทำการสร้างและการกำหนดบทบาทก่อนและยืนยันว่าการล็อกอินยังทำงาน จากนั้นเพิ่มประตูสิทธิ์ทีละอย่างและทดสอบ
หลังการเปลี่ยน ยืนยันการควบคุมการเข้าถึงจากสามมุมมอง ผู้ใช้ปกติไม่ควรเห็นการกระทำเฉพาะแอดมิน แอดมินต้องยังเข้าถึงการตั้งค่าและการจัดการผู้ใช้ได้ จากนั้นทดสอบขอบเคส: เซสชันหมดอายุ, รีเซ็ตรหัสผ่าน, บัญชีถูกปิด, และผู้ใช้ที่ลงชื่อเข้าด้วยวิธีที่คุณไม่ได้ใช้ในระหว่างการทดสอบ
รายละเอียดที่คนมักพลาด: ความลับมักอยู่นอกโค้ด ถ้าคุณย้อนกลับโค้ดแต่เก็บคีย์ใหม่และการตั้งค่า callback ไว้ auth อาจพังในแบบที่สับสน จงจดบันทึกชัดเจนเกี่ยวกับการเปลี่ยนสภาพแวดล้อมที่คุณทำหรือที่ต้องย้อนกลับ
การเขียน UI ใหม่เสี่ยงเพราะผสมงานภาพกับการเปลี่ยนพฤติกรรม สร้างจุดบันทึกเมื่อ UI เสถียรและคาดเดาได้ แม้มันจะไม่สวยนั่นคือ baseline การทำงานของคุณ: เวอร์ชันสุดท้ายที่คุณพร้อมจะส่งถ้าจำเป็น
การเขียน UI ใหม่พังเมื่อมองเป็นสวิตช์ใหญ่ แบ่งงานเป็นสไลซ์ที่ยืนได้เอง: หนึ่งหน้าจอ หนึ่ง route หรือหนึ่งคอมโพเนนต์
ถ้าคุณเขียน checkout ใหม่ ให้แบ่งเป็น Cart, Address, Payment, และ Confirmation หลังแต่ละสไลซ์ ทำให้พฤติกรรมเก่าตรงก่อน แล้วจึงปรับเลย์เอาต์ ข้อความ และปฏิสัมพันธ์เล็กๆ เมื่อสไลซ์นั้น "เสร็จพอ" ให้สแนปชอตมัน
หลังแต่ละสไลซ์ ทำการทดสอบสั้นๆ ที่มักพังในงาน rewrite:\n\n- Navigation: เข้าถึงหน้าจอได้จากทางหลักไหม?\n- ฟอร์ม: การตรวจสอบ ฟิลด์ที่จำเป็น การส่ง\n- สถานะการโหลดและสถานะว่าง\n- สถานะข้อผิดพลาด (คำขอล้มเหลว, สิทธิ์, การลองใหม่)\n- พฤติกรรมมือถือ (หน้าจอเล็ก, การเลื่อน, ขนาดเป้ากด)
ความล้มเหลวที่พบบ่อยคือ: หน้าจอ Profile ใหม่ดูดี แต่หนึ่งฟิลด์บันทึกไม่ได้เพราะคอมโพเนนต์เปลี่ยนรูปแบบ payload ด้วยจุดบันทึกดีๆ คุณสามารถย้อนกลับ เปรียบเทียบ แล้วนำการปรับปรุงด้านภาพกลับมาใหม่โดยไม่เสียงานเป็นวันๆ
การย้อนกลับควรรู้สึกควบคุมได้ ไม่ใช่การตื่นตระหนก ตัดสินใจก่อนว่าคุณต้องย้อนกลับทั้งหมดไปจุดที่รู้ว่าดี หรือแค่ undo บางส่วน
การย้อนกลับเต็มเหมาะเมื่อแอปพังหลายจุด (เทสล้ม, server เริ่มไม่ได้, ล็อกอินล็อกเอาท์ไม่ได้) การ undo บางส่วนเหมาะเมื่อชิ้นเดียวพัง เช่น มายเกรชันหนึ่งตัว guard route หนึ่งตัว หรือคอมโพเนนต์ที่ทำให้แครช
มอง snapshot เสถียรล่าสุดเป็นฐานบ้าน:\n\n1. ย้อนกลับไปยัง snapshot เสถียรล่าสุด\n2. ยืนยันการไหลงานหลักทำงานอีกครั้ง (เริ่มแอป, ล็อกอิน, เข้าถึงหน้าหลัก, ทำการกระทำสำคัญหนึ่งอย่าง)\n3. สร้าง snapshot ใหม่ทันที ตั้งชื่อเช่น “stable-after-rollback”\n4. นำการแก้ที่ดีกลับมาทีละก้าวเล็ก (หนึ่งมายเกรชัน, หนึ่งกฎ auth, หนึ่งชิ้น UI)\n5. Snapshot หลังแต่ละก้าวที่สะอาดเพื่อคุณจะหยุดได้ก่อนก้าวที่เสี่ยงถัดไป
จากนั้นใช้ห้านาทีตรวจพื้นฐาน ง่ายที่จะย้อนกลับแล้วพลาดการแตกเงียบๆ เช่น background job ที่ไม่ทำงานอีกต่อไป
การเช็คด่วนที่จับปัญหาได้มากที่สุด:\n\n- ผู้ใช้ใหม่สมัครและล็อกอินได้ไหม?\n- หน้าหลักโหลดโดยไม่มีข้อผิดพลาดไหม?\n- การสร้างและการบันทึกทำงานไหม (เส้นทาง "เงิน")?\n- ข้อมูลยังอยู่และอ่านได้ไหม?
ตัวอย่าง: คุณลอง refactor auth ใหญ่แล้วบล็อกบัญชีแอดมิน ย้อนกลับไปยัง snapshot ก่อนการเปลี่ยน ยืนยันล็อกอินได้ จากนั้นนำการแก้กลับมาในก้าวเล็กๆ: บทบาทก่อน, แล้ว middleware, แล้วการปิดกั้น UI ถ้ามันพังอีกครั้ง คุณจะรู้ว่าขั้นตอนไหนเป็นต้นเหตุ
สุดท้าย จดบันทึกสั้นๆ: อะไรพัง คุณสังเกตยังไง อะไรแก้ได้ และจะทำต่างไปยังไงครั้งหน้า นี่เปลี่ยน rollback ให้เป็นบทเรียนไม่ใช่เวลาที่เสียไป
ความเจ็บปวดจาก rollback มักมาจากจุดบันทึกไม่ชัด การผสมการเปลี่ยน และการข้ามการเช็ค
การบันทึกน้อยเกินไปเป็นความผิดพลาดคลาสสิก ผู้คนฝ่าฝืนการ tweak schema แบบ "เร็วๆ" เปลี่ยนกฎ auth เล็กน้อย และปรับ UI พร้อมกัน แล้วพบว่าแอปพังโดยไม่มีจุดง่ายๆ ให้กลับไป
ปัญหาตรงข้ามคือบันทึกบ่อยเกินไปแต่ไม่มีโน้ต สิบสแนปชอตชื่อ “test” หรือ “wip” โดยพื้นฐานคือสแนปชอตเดียวเพราะคุณบอกไม่ได้อันไหนปลอด
การผสมการเปลี่ยนความเสี่ยงหลายอย่างในรอบเดียวก็เป็นกับดักอีกอย่าง ถ้า schema, สิทธิ์, และ UI มาพร้อมกัน การย้อนกลับกลายเป็นการเดา คุณยังเสียโอกาสเก็บส่วนที่ดีไว้ (เช่น ปรับ UI ให้ดี) ขณะย้อนกลับส่วนเสี่ยง (เช่น มายเกรชัน)
อีกปัญหาคือย้อนกลับโดยไม่ตรวจสอบสมมติฐานข้อมูลและสิทธิ์ หลัง rollback ฐานข้อมูลอาจยังมีคอลัมน์ใหม่ ค่า null ที่ไม่คาดคิด หรือแถวที่ย้ายไม่เสร็จ หรือคุณอาจคืนค่า logic สิทธิ์เก่าในขณะที่บทบาทผู้ใช้ถูกสร้างภายใต้กฎใหม่ ความไม่ตรงกันนั้นอาจดูเหมือน “rollback ไม่ได้ผล” ทั้งที่จริงมันได้ผลแล้ว
ถ้าต้องการวิธีง่ายๆ ที่หลีกเลี่ยงส่วนใหญ่ของปัญหาเหล่านี้:
สแนปชอตทำงานได้ดีที่สุดเมื่อจับคู่กับการเช็คสั้นๆ เหล่านี้ การเช็คไม่ใช่แผนทดสอบเต็ม มันคือชุดการกระทำเล็กๆ ที่บอกคุณอย่างรวดเร็วว่าควรเดินหน้าต่อหรือย้อนกลับ
รันเหล่านี้ก่อนคุณถ่าย snapshot คุณกำลังพิสูจน์ว่าเวอร์ชันปัจจุบันคุ้มค่าที่จะบันทึก\n\n- แอปเริ่มและโหลดโดยไม่มีข้อผิดพลาด\n- ล็อกอินทำงานด้วยผู้ใช้จริงอย่างน้อยหนึ่งบัญชี (หรือผู้ใช้ทดสอบ)\n- หนึ่งฟลูว์หลักทำงานจากต้นจนจบ (สร้างบางอย่าง, บันทึก, เห็นมันอีกครั้ง)\n- ฐานข้อมูลเข้าถึงได้และการอ่านพื้นฐานทำงาน\n- คุณสามารถบอกว่าคุณจะเปลี่ยนอะไรต่อด้วยประโยคเดียว
ถ้าบางอย่างพังอยู่แล้ว ให้แก้ก่อน อย่า snapshot ปัญหา เว้นแต่คุณตั้งใจจะเก็บไว้เพื่อตรวจดีบัก
เป้าหมายคือเส้นทางที่สมหวังหนึ่งเส้น, เส้นทางข้อผิดพลาดหนึ่งเส้น, และการเช็คสิทธิ์หนึ่งอย่าง\n\n- เส้นทางสมหวัง: ทำการกระทำหลักที่คุณแตะให้เสร็จ\n- เส้นทางข้อผิดพลาด: กระตุ้นความล้มเหลวที่รู้จักแล้วยืนยันข้อความแสดงผลเหมาะสม\n- สิทธิ์: ยืนยันว่าผู้ใช้ที่ควรเข้าถึงทำได้ และผู้ที่ไม่ควรเข้าถึงไม่สามารถ\n- รีเฟรชและกลับมาดู: โหลดใหม่และยืนยันว่าสถานะไม่หาย\n- ถ้ามีการมายเกรชัน: ตรวจหนึ่งเรคอร์ดเก่าและหนึ่งเรคอร์ดใหม่
สมมติว่าคุณกำลังเพิ่มบทบาทใหม่ชื่อ “Manager” และออกแบบหน้าการตั้งค่าใหม่\n\n1) เริ่มจาก build ที่เสถียร รันการเช็คก่อนเปลี่ยน แล้วสแนปชอตด้วยชื่อชัดเจน เช่น: “pre-manager-role + pre-settings-redesign”.\n\n2) ทำงานด้าน backend ของบทบาทก่อน (ตาราง, สิทธิ์, API). เมื่อบทบาทและกฎเข้าถึงทำงานถูกต้อง สแนปชอตอีกครั้ง: “roles-working”.\n\n3) จากนั้นเริ่มเขียน UI หน้า Settings ใหม่ ก่อนการรีไรท์เลย์เอาต์ใหญ่ ให้สแนปชอต: “pre-settings-ui-rewrite”. ถ้า UI เละ ให้ย้อนกลับไปจุดนั้นแล้วลองแนวทางที่สะอาดกว่าโดยไม่เสียงานบทบาทที่ดีแล้ว\n\n4) เมื่อ Settings UI ใหม่ใช้งานได้ ให้สแนปชอต: “settings-ui-clean”. แล้วค่อยขัดเกลา
ลองทำกับฟีเจอร์เล็กๆ สัปดาห์นี้ เลือกการเปลี่ยนเสี่ยงหนึ่งอย่าง วางสองสแนปชอตรอบมัน (ก่อนและหลัง) แล้วฝึกย้อนกลับโดยตั้งใจ
ถ้าคุณกำลังสร้างบน Koder.ai (koder.ai) ฟีเจอร์สแนปชอตและการย้อนกลับในตัวช่วยให้เวิร์กโฟลว์นี้รักษาได้ง่ายขณะคุณวนปรับปรุง เป้าหมายง่ายๆ: ทำให้การเปลี่ยนใหญ่รู้สึกย้อนกลับได้ เพื่อคุณจะเคลื่อนไหวเร็วโดยไม่เสี่ยงเวอร์ชันที่ทำงานดีที่สุดของคุณ
A snapshot คือจุดบันทึกคงที่ของโปรเจค ณ ช่วงเวลาใดช่วงเวลาหนึ่ง นิสัยมาตรฐานคือ: สร้าง snapshot ทันที ก่อนการเปลี่ยนที่มีความเสี่ยง เพื่อให้คุณกลับไปยังสถานะที่รู้ว่าทำงานได้หากมีอะไรพัง\n\nมันมีประโยชน์มากเมื่อความล้มเหลวไม่ได้ชัดเจนทันที (เช่น การเปลี่ยน schema ทำให้รายงานพัง การปรับ auth ทำให้ล็อกเอาท์ไม่ได้ หรือการเขียน UI ใหม่ที่พังกับข้อมูลจริง)
สร้าง snapshot ก่อนการเปลี่ยนที่มีพื้นที่กระทบสูง เช่น:\n\n- การเปลี่ยนฐานข้อมูล/โครงสร้าง (คอลัมน์ใหม่ การเปลี่ยนชื่อ ข้อจำกัด มายเกรชัน)\n- การเปลี่ยนการยืนยันตัวตนและสิทธิ์ (บทบาท middleware กฎ token, การตั้งค่า SSO)\n- การเขียน UI ใหม่หลายหน้าพร้อมกัน (routing, ฟอร์ม, คอมโพเนนต์ที่แชร์กัน)\n\nสำหรับแก้ไขเล็กๆ (ปรับข้อความ ช่องว่างเล็กน้อย รีแฟกเตอร์เล็กๆ) โดยทั่วไปไม่จำเป็นต้องหยุดแล้ว snapshot ทุกครั้ง
ใช้รูปแบบชื่อที่ตอบ:\n\n- อะไรเปลี่ยน\n- ทำไม\n- ทำอะไรต่อ\n\nรูปแบบที่ใช้งานได้คือ: STATUS + Area + Action (+ next step)\n\nตัวอย่าง:\n\n- [WIP] Auth: add magic link (next: OAuth)\n- [GOLD] DB: users v2 (passes smoke tests)\n\nหลีกเลี่ยงชื่ออย่าง “test” หรือ “before update” — มันยากจะเชื่อเมื่ออยู่ภายใต้ความกดดัน
มาร์ก snapshot เป็น GOLD เฉพาะเมื่อคุณยินดีจะกลับมาและทำงานต่อได้โดยไม่มีเซอร์ไพรส์:\n\nGOLD มักจะหมายถึง:\n\n- แอปเริ่มและทำงานได้สะอาด\n- หนึ่งการไหลงานหลักทำงานจากต้นจนจบ\n- ปัญหาที่รู้จักถูกเข้าใจและจดบันทึกไว้\n\nทุกอย่างที่เหลือคือ WIP — ข้อปฏิบัตินี้ช่วยป้องกันการย้อนกลับไปยังจุดที่ดูนิ่งแต่ยังมีบั๊กใหญ่ซ่อนอยู่
เก็บการเช็คสั้นๆ ที่ทำซ้ำได้เพื่อจะได้ทำจริง:\n\n- แอปเริ่มโดยไม่มีข้อผิดพลาด\n- การล็อกอินทำงาน (ถ้ามี)\n- หนึ่งการไหลงานหลักทำงานจากต้นจนจบ (สร้าง/บันทึก/ดู)\n- ไม่มี error ใน console/server ระหว่างการไหลงานนั้น\n- ขอบเคสที่เกี่ยวข้องหนึ่งอย่างทำงาน (สถานะว่าง, ข้อผิดพลาดการตรวจสอบ)\n\nเป้าหมายไม่ใช่การทดสอบครบชุด แต่เพื่อพิสูจน์ว่ายังมี baseline ปลอดภัยอยู่
ลำดับของจุดบันทึกที่เป็นประโยชน์สำหรับงาน schema คือ:\n\n- Baseline snapshot: ก่อนการมายเกรชันครั้งแรก\n- Additive snapshot: หลังเพิ่มคอลัมน์/ตารางใหม่ (ยังไม่ลบอะไร)\n- Backfill snapshot: หลังคัดลอก/คำนวณข้อมูลลงคอลัมน์ใหม่ พร้อมตรวจสอบจุดเล็กๆ\n- Code switch snapshot: หลังแอปรับ/เขียนข้อมูลจากโครงสร้างใหม่\n- Cleanup snapshot: หลังตรวจสอบการใช้งานจริงก่อนลบคอลัมน์เก่าหรือเข้มงวดข้อจำกัด\n\nกฎมาตรฐาน: หลีกเลี่ยงการมายเกรชันครั้งใหญ่ที่เปลี่ยนชื่อทุกอย่างพร้อมกัน ให้แบ่งเป็นก้าวเล็กๆ เพื่อทดสอบและย้อนกลับได้ปลอดภัย
สร้าง snapshot ก่อน คุณแตะส่วน auth แล้วจดไว้ว่า ณ ตอนนี้ระบบเป็นอย่างไร:\n\n- วิธีล็อกอินปัจจุบัน\n- บทบาทและสิทธิ์\n- บัญชีทดสอบ (อย่างน้อยหนึ่งผู้ใช้ปกติและหนึ่งแอดมิน)\n- การตั้งค่าที่เกี่ยวข้องกับความลับ/สภาพแวดล้อม (คีย์, callback URL, อายุ token)\n\nเปลี่ยนทีละกฎ ทดสอบ แล้ว snapshot อีกครั้งถ้ามันสะอาด อย่าลืมว่าการย้อนกลับโค้ดไม่คืนค่าความลับภายนอก—ให้จดบันทึกการเปลี่ยนแปลงสภาพแวดล้อมด้วย
แบ่งการเขียน UI ใหม่เป็นชิ้นที่ยืนได้ด้วยตัวเอง:\n\n- หนึ่งหน้าหรือคอมโพเนนต์ต่อชิ้น\n- ทำให้พฤติกรรมเดิมตรงก่อน (ฟอร์ม, payloads, navigation)\n- แล้วค่อยปรับเลย์เอาต์และปฏิสัมพันธ์\n\nหลังแต่ละชิ้น ให้ทดสอบสิ่งที่มักพัง: เส้นทางการนำทาง, การส่งฟอร์ม/การตรวจสอบ, สถานะการโหลด/ว่าง/ข้อผิดพลาด และพฤติกรรมมือถือ แล้ว snapshot เมื่อชิ้นนั้น "เพียงพอที่จะเก็บไว้"
ขั้นตอนการย้อนกลับอย่างปลอดภัย:\n\n1. ย้อนกลับไปยัง snapshot ล่าสุดที่เสถียร\n2. ยืนยันการไหลงานหลักทำงานอีกครั้ง (เริ่มแอป, ล็อกอิน, การกระทำหลัก)\n3. สร้าง snapshot ใหม่ทันที ชื่อเช่น stable-after-rollback\n4. นำการเปลี่ยนที่ดีกลับมาอีกครั้งทีละก้าวเล็ก (หนึ่งมายเกรชัน, หนึ่งกฎ auth, หนึ่งชิ้น UI)\n5. Snapshot หลังแต่ละก้าวที่สะอาดเพื่อคุณจะหยุดได้ก่อนก้าวถัดไปที่มีความเสี่ยง\n\nการทำเช่นนี้เปลี่ยน rollback ให้เป็นการกลับสู่ "ฐานบ้าน" แทนการยกเลิกแบบตื่นตระหนก
ความผิดพลาดที่พบบ่อย:\n\n- บันทึกน้อยเกินไป: หาจุดสะอาดกลับไปไม่ได้\n- บันทึกบ่อยเกินไปแต่ไร้โน้ต: หลาย snapshot ชื่อเหมือนกันทำให้เชื่อถือไม่ได้\n- ผสมการเปลี่ยนความเสี่ยงหลายอย่าง: schema + auth + UI พร้อมกันทำให้แยกสาเหตุยาก\n- ไม่ตรวจสอบข้อมูล/สภาพแวดล้อม: ย้อนกลับโค้ดไม่ได้ย้อนการมายเกรชันหรือการเปลี่ยนความลับภายนอก\n\nการปฏิบัติง่ายๆ ที่ช่วยหลีกเลี่ยงส่วนใหญ่:\n\n- Snapshot ที่จุดตัดสินใจ (ก่อนและหลังการเปลี่ยนเสี่ยงหนึ่งอย่าง)\n- เขียนประโยคเดียวบอกว่ามีอะไรเปลี่ยน ทดสอบอะไร และ "ดี" คืออะไร\n- แบ่งงานใหญ่เป็นชิ้นแยก: schema, แล้ว auth, แล้ว UI\n- หลัง rollback ให้ยืนยันสถานะฐานข้อมูลและเส้นทางสิทธิ์จริง\n- ทำซ้ำความผิดพลาดเดิมที่กระตุ้น rollback แล้วยืนยันว่ามันหายไป