07 พ.ค. 2568·3 นาที
การทำงานของ Database Sharding—และทำไมมันยากจะเข้าใจ
Sharding ช่วยขยายฐานข้อมูลโดยแบ่งข้อมูลข้ามโหนด แต่เพิ่มการกำหนดเส้นทาง การปรับสมดุล และโหมดความล้มเหลวใหม่ที่ทำให้ระบบยากจะเข้าใจ
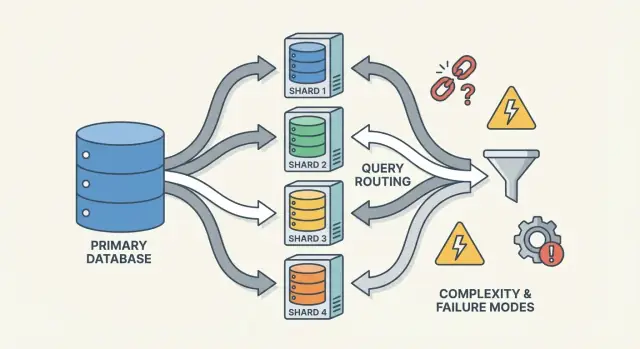
Sharding ช่วยขยายฐานข้อมูลโดยแบ่งข้อมูลข้ามโหนด แต่เพิ่มการกำหนดเส้นทาง การปรับสมดุล และโหมดความล้มเหลวใหม่ที่ทำให้ระบบยากจะเข้าใจ
Sharding (ที่เรียกอีกอย่างว่า การแบ่งแนวนอน) คือการเอาฐานข้อมูลที่ดูเหมือนเป็น หนึ่งเดียว ต่อแอปพลิเคชันและแยกข้อมูลนั้นไปไว้บน หลายเครื่อง ที่เรียกว่า ชาร์ด แต่ละชาร์ดเก็บเฉพาะส่วนของแถวเท่านั้น แต่รวมกันแล้วเป็นชุดข้อมูลทั้งหมด
โมเดลคิดที่ช่วยได้คือความต่างระหว่าง โครงสร้างตรรกะ กับ การวางทางกายภาพ
จากมุมแอป คุณอยากรันคิวรีเหมือนมันเป็นตารางเดียว แต่เบื้องหลังระบบต้องตัดสินใจว่าจะคุยกับชาร์ดไหน(หรือกี่ชาร์ด)
Sharding ต่างจาก replication ตรงที่ replication สร้าง สำเนา ของข้อมูลชุดเดียวกันบนโหนดหลายตัว เพื่อความพร้อมใช้งานและขยายอ่าน ส่วน sharding แยกข้อมูลออกไปให้แต่ละโหนดเก็บ ระเบียนต่างกัน
มันก็แตกต่างจาก การสเกลแนวตั้ง ซึ่งคุณยังคงใช้ฐานข้อมูลตัวเดียวแต่ย้ายไปเครื่องที่ใหญ่ขึ้น (CPU/RAM/ดิสก์เร็ว) การสเกลแนวตั้งอาจง่ายกว่า แต่มีขีดจำกัดทางปฏิบัติและค่าใช้จ่ายอาจพุ่งเร็ว
Sharding เพิ่มความสามารถ แต่ไม่ได้ทำให้ฐานข้อมูลของคุณ “ง่าย” โดยอัตโนมัติหรือทำให้คิวรีทุกตัวเร็วขึ้น
ดังนั้น sharding ควรถูกมองว่าเป็นวิธีขยาย พื้นที่จัดเก็บและปริมาณงาน — ไม่ใช่การอัพเกรดฟรีสำหรับทุกมิติของพฤติกรรมฐานข้อมูล
ทีมมักไม่เลือก sharding เป็นตัวเลือกแรก พวกเขามักมาถึงมันหลังจากระบบที่ประสบความสำเร็จถึงขีดจำกัดทางกายภาพ—หรือเมื่อต้องเจอความเจ็บปวดในการปฏิบัติงานบ่อยจนทนไม่ได้ แรงจูงใจมักน้อยกว่า “เราต้องการชาร์ด” และมากกว่า “เราต้องเติบโตต่อโดยไม่ให้ฐานข้อมูลตัวเดียวเป็นจุดเดี่ยวของความล้มเหลวและต้นทุน”
โหนดฐานข้อมูลตัวเดียวอาจหมดพื้นที่ในหลายทาง:
เมื่อปัญหาเหล่านี้เกิดขึ้นบ่อย ปกติสาเหตุไม่ใช่คิวรีตัวเดียว แต่เป็นว่าเครื่องเดียวแบกรับความรับผิดชอบมากเกินไป
Sharding กระจายข้อมูลและทราฟฟิกไปยังหลายโหนดเพื่อให้ความจุเพิ่มได้โดยการเพิ่มเครื่องแทนการอัปเกรดแนวตั้ง หากทำดี มันยังช่วย แยกภาระงาน (เพื่อไม่ให้สไปค์ของ tenant หนึ่งทำให้ความหน่วงของผู้อื่นแย่ลง) และ ควบคุมต้นทุน โดยหลีกเลี่ยงการต้องใช้อินสแตนซ์ระดับพรีเมียมที่ใหญ่ขึ้นเรื่อย ๆ
รูปแบบที่เกิดซ้ำรวมถึง p95/p99 ที่เพิ่มขึ้นในชั่วโมงพีก replication lag นานขึ้น แบ็กอัพ/รีสโตร์เกินหน้าต่างที่ยอมรับได้ และการเปลี่ยนสคีมาขนาดเล็กกลายเป็นเหตุการณ์ใหญ่
ก่อนตัดสินใจ ทีมมักจะลองตัวเลือกที่ง่ายกว่าก่อน: การทำดัชนีและแก้คิวรี แคชชิ่ง read replicas การแบ่งพาร์ติชันภายในฐานข้อมูลตัวเดียว การเก็บข้อมูลเก่า และอัปเกรดฮาร์ดแวร์ Sharding แก้ปัญหาขนาดได้ แต่เพิ่มการประสานงาน ความซับซ้อนการปฏิบัติการ และโหมดความล้มเหลวใหม่—ดังนั้นบรรทัดฐานควรสูง
ระบบชาร์ดไม่ใช่สิ่งเดียว—มันคือชุดชิ้นส่วนที่ทำงานร่วมกัน เหตุผลที่ sharding รู้สึก “ยากจะเข้าใจ” คือความถูกต้องและประสิทธิภาพขึ้นกับการโต้ตอบของชิ้นส่วนเหล่านี้ ไม่ใช่แค่เอนจินฐานข้อมูล
Shard คือส่วนย่อยของข้อมูล มักเก็บบนเซิร์ฟเวอร์หรือคลัสเตอร์ของตนเอง แต่ละชาร์ดมักมี:
จากมุมแอป การตั้งค่าชาร์ดมักพยายามดูเหมือนฐานข้อมูลตรรกะเดียว แต่เบื้องหลังคิวรีที่เป็น "การค้นหาดัชนีครั้งเดียว" บนฐานข้อมูลโหนดเดียวอาจกลายเป็น "หาแชาร์ดที่ถูกต้อง แล้วค่อยค้น" บนระบบชาร์ด
Router (บางครั้งเรียก coordinator, query router, หรือ proxy) คือผู้คุมทราฟฟิก มันตอบคำถามเชิงปฏิบัติ: คำขอนี้ควรให้ชาร์ดไหนจัดการ?
มีแบบแผนทั่วไปสองแบบ:
Router ลดความซับซ้อนในแอป แต่ก็อาจกลายเป็นคอขวดหรือจุดล้มเหลวใหม่ถ้าออกแบบไม่ดี
Sharding พึ่งพา เมตาดาต้า—แหล่งความจริงที่บอก:
ข้อมูลนี้มักอยู่ในบริการ config (หรือฐานข้อมูล control plane ขนาดเล็ก) หากเมตาดาต้าล้าหรือไม่สอดคล้อง router อาจส่งทราฟฟิกไปผิดที่ แม้แต่ละชาร์ดจะสุขภาพดี
สุดท้าย sharding ต้องการกระบวนการพื้นหลังที่รักษาระบบให้อยู่ได้:
งานเหล่านี้มักถูกมองข้ามแต่กลับเป็นที่มาของความประหลาดใจในการโปรดักชัน—เพราะมันเปลี่ยนรูปแบบระบบขณะยังให้บริการ
คีย์ชาร์ด คือตัวแปรที่ระบบใช้ตัดสินใจว่าแถว/เอกสารจะเก็บไว้ที่ชาร์ดไหน ตัวเลือกเดียวนี้แทบจะกำหนดประสิทธิภาพ ต้นทุน และคุณสมบัติที่รู้สึกว่า "ง่าย" ในอนาคต—เพราะมันควบคุมว่าคำขอจะถูกกำหนดเส้นทางไปชาร์ดเดียวหรือกระจายไปหลายชาร์ด
คีย์ที่ดีมักมี:
user_id แทน country)ตัวอย่างทั่วไปคือการชาร์ดตาม tenant_id ในแอป multi-tenant: การอ่าน/เขียนส่วนใหญ่สำหรับ tenant หนึ่งจะอยู่บนชาร์ดเดียว และ tenant มากพอจะกระจายโหลดได้
คีย์บางแบบรับประกันปัญหา:
แม้ฟิลด์ความหลากหลายน้อยจะสะดวกสำหรับการกรอง แต่บ่อยครั้งมันทำให้คิวรีธรรมดากลายเป็น scatter-gather เพราะแถวที่ตรงกันกระจัดกระจายอยู่ทั่ว
คีย์ชาร์ดที่ดีที่สุดเพื่อบาลานซ์โหลดไม่จำเป็นต้องเหมาะกับคีย์ที่ทำให้คิวรีผลิตภัณฑ์สะดวกเสมอ
region) แล้วคุณเสี่ยงจุดร้อนและความจุไม่เท่ากันทีมส่วนใหญ่จะออกแบบรอบการแลกเปลี่ยนนี้: ปรับคีย์ให้เหมาะกับการทำงานที่บ่อยและมีความสำคัญต่อความหน่วง แล้วจัดการที่เหลือด้วยดัชนี, denormalization, replica, หรือตารางวิเคราะห์เฉพาะทาง
ไม่มีวิธีเดียวที่ “ดีที่สุด” สำหรับการชาร์ด วิธีที่คุณเลือกกำหนดความง่ายในการกำหนดเส้นทาง การกระจายข้อมูล และรูปแบบการเข้าถึงที่เจ็บปวด
ด้วย range sharding แต่ละชาร์ดเป็นเจ้าของช่วงต่อเนื่องของ key space—ตัวอย่าง:
การกำหนดเส้นทางตรงไปตรงมา: ดูคีย์แล้วเลือกชาร์ด
ข้อเสียคือจุดร้อน: ถ้าผู้ใช้ใหม่ได้ ID เพิ่มขึ้นเรื่อย ๆ ชาร์ด “ตัวท้าย” จะเป็นคอขวดการเขียน Range sharding ยังอ่อนไหวต่อการเติบโตไม่สม่ำเสมอ แต่ข้อดีคือคิวรีช่วง (เช่น "คำสั่งทั้งหมดจาก 1–31 ต.ค.") อาจมีประสิทธิภาพเพราะข้อมูลถูกจัดกลุ่มทางกายภาพ
Hash sharding ส่งคีย์ผ่านฟังก์ชันแฮชแล้วใช้ผลลัพธ์เพื่อเลือกชาร์ด วิธีนี้มักกระจายข้อมูลได้สม่ำเสมอขึ้น ช่วยหลีกเลี่ยงปัญหาชาร์ดใหม่รับข้อมูลทั้งหมด
การแลกเปลี่ยน: คิวรีช่วงจะแย่ลง คำถามแบบ "ลูกค้าที่มี ID ระหว่าง X และ Y" อาจถูกส่งไปยังหลายชาร์ด ทีมมักใช้ consistent hashing และ virtual nodes เพื่อให้การเพิ่มชาร์ดย้ายคีย์เพียงส่วนน้อย
Directory sharding เก็บแมปชัดเจน (ตาราง/บริการ lookup) จากคีย์ → ตำแหน่งชาร์ด ความยืดหยุ่นสูง: สามารถวาง tenant เฉพาะบนชาร์ดเฉพาะ ย้ายลูกค้าเดี่ยวโดยไม่ย้ายทุกคน และรองรับขนาดชาร์ดไม่เท่ากัน
ข้อเสียคือพึ่งพาเพิ่มเติม: หากไดเรกทอรีช้า ล้าหรือไม่พร้อม การกำหนดเส้นทางจะเดี้ยง แม้ชาร์ดเองจะพร้อม
ระบบจริงมักผสมวิธี คีย์ผสม (เช่น tenant_id + user_id) แยก tenant แต่กระจายโหลดภายใน tenant การ sub-sharding คล้ายกัน: แยกก่อนตาม tenant แล้วจึงแฮชภายในกลุ่มชาร์ดของ tenant เพื่อลดความเสี่ยงที่ tenant ใหญ่จะครอบงำชาร์ดเดียว
ระบบชาร์ดมีเส้นทางคิวรีสองแบบที่ต่างกันอย่างมาก การเข้าใจว่าอยู่ในเส้นทางไหนอธิบายความประหลาดใจส่วนใหญ่ด้านประสิทธิภาพ—และทำไม sharding ถึงดูไม่แน่นอน
ผลลัพธ์ที่ต้องการคือกำหนดเส้นทางคิวรีไปยังชาร์ดเดียว หากคำขอมีคีย์ชาร์ด (หรือสิ่งที่ router แปลงเป็นชาร์ดได้) ระบบสามารถส่งตรงไปยังที่เดียว
นั่นคือเหตุผลที่ทีมหมกมุ่นทำให้การอ่านที่พบบ่อย “รับรู้คีย์ชาร์ด” หนึ่งชาร์ดหมายถึงการเดินทางของเครือข่ายน้อยกว่า การล็อกน้อยกว่า การประสานงานน้อยกว่า และความหน่วงต่ำกว่า เป็นส่วนใหญ่การหน่วงเกิดจากฐานข้อมูลทำงานเองไม่ใช่การโต้แย้งในคลัสเตอร์
เมื่อคิวรีไม่สามารถกำหนดเส้นทางแน่นอน (ตัวอย่างกรองด้วยฟิลด์ที่ไม่ใช่คีย์ชาร์ด) ระบบอาจ broadcast คิวรีไปหลายหรือทุกชาร์ด แต่ละชาร์ดรันคิวรีท้องถิ่น แล้ว router/coordination จะรวมผล—เรียง ลบซ้ำ นำ limit มาประยุกต์ และรวม partial aggregates
การแฟนเอาต์เพิ่ม tail latency: แม้ 9 ชาร์ดตอบไว หนึ่งชาร์ดช้าอาจกีดขวางคำขอทั้งหมด และมันเพิ่มโหลด: คำขอของผู้ใช้หนึ่งคำขอกลายเป็นคำขอ N ชาร์ด
Join ข้ามชาร์ดแพงเพราะข้อมูลที่เดิมจะอยู่ภายในฐานข้อมูลเดียวต้องเดินทางระหว่างชาร์ด หรือไปยัง coordinator แม้ aggregation ง่าย ๆ (COUNT, SUM, GROUP BY) อาจต้องแผนสองเฟส: คำนวณผลย่อยในแต่ละชาร์ด แล้วรวมผล
ส่วนใหญ่ระบบเริ่มด้วยดัชนีท้องถิ่น: แต่ละชาร์ดมีดัชนีเฉพาะข้อมูลของตัวเอง ถูกดูแลรักษาถูก แต่ไม่ช่วยการกำหนดเส้นทาง — คิวรีอาจยังคงต้องกระจาย
ดัชนีแบบ global ช่วยให้กำหนดเส้นทางเป้าหมายได้บนฟิลด์ที่ไม่ใช่คีย์ชาร์ด แต่เพิ่มภาระการเขียน การประสาน และปัญหาการสเกลและความสอดคล้องของตัวเอง
การเขียนคือจุดที่ sharding หยุดรู้สึกว่าเป็นแค่การขยายและเริ่มเปลี่ยนการออกแบบฟีเจอร์ การเขียนที่กระทบชาร์ดเดียวเร็วและเรียบง่าย การเขียนที่กระทบหลายชาร์ดช้า เกิดข้อผิดพลาด และยากที่จะถูกต้อง
ถ้าคำขอถูกกำหนดเส้นทางไปชาร์ดเดียว (โดยทั่วไปผ่านคีย์ชาร์ด) ฐานข้อมูลสามารถใช้กลไกธุรกรรมปกติ คุณจะได้ atomicity และ isolation ภายในชาร์ดนั้น และปัญหาส่วนใหญ่เป็นปัญหาเดียวกับโหนดเดี่ยว—แค่มีซ้ำ N ครั้ง
เมื่อคุณต้องอัปเดตข้อมูลบนสองชาร์ดในหนึ่ง "การกระทำตรรกะ" (เช่น โอนเงิน ย้ายคำสั่งซื้อระหว่างลูกค้า อัปเดต aggregate ที่เก็บไว้ที่อื่น) คุณเข้าสู่ดินแดนของธุรกรรมแบบกระจาย
ธุรกรรมแบบกระจายยากเพราะต้องการการประสานระหว่างเครื่องที่อาจช้า แยกส่วน หรือรีสตาร์ทได้เสมอ โปรโตคอลแบบ two-phase commit เพิ่มการเดินทางหลายรอบ อาจบล็อกเมื่อ timeout และทำให้ความล้มเหลวไม่ชัดเจน: ชาร์ด B ทำการเปลี่ยนแปลงก่อน coordinator ตายหรือไม่? หาก client รีไทร คุณจะทำซ้ำการเขียนหรือไม่? หากไม่รีไทร คุณจะสูญเสียมันไหม?
วิธีลดความถี่ของธุรกรรมข้ามชาร์ดมี:
ในระบบชาร์ด การรีไทรเป็นสิ่งที่หลีกเลี่ยงไม่ได้ ทำให้การเขียนต้อง idempotent โดยใช้ operation IDs คงที่ (เช่น idempotency key) และเก็บมาร์กเกอร์ว่า "ใช้แล้ว" ในฐานข้อมูล เพื่อให้หาก timeout และ client รีไทร ความพยายามครั้งที่สองจะเป็น no-op แทนที่จะเป็นการคิดเงินสองครั้ง คำสั่งซ้ำ หรือเคาน์เตอร์ที่ไม่สอดคล้อง
Sharding แยกข้อมูลข้ามเครื่อง แต่ไม่ลดความจำเป็นเรื่อง redundancy Replication คือสิ่งที่ทำให้ชาร์ดยังใช้ได้เมื่อโหนดตาย—และทำให้คำถามว่า "อะไรคือความจริงตอนนี้?" ยากขึ้น
ส่วนใหญ่ระบบ replicate ภายในแต่ละชาร์ด: มี primary (leader) ยอมรับการเขียน และมี replica หลายตัวคัดลอกการเปลี่ยนแปลง หาก primary ล้ม ระบบโปรโมต replica (failover) Replica ยังช่วยให้การอ่านลดภาระ
การแลกเปลี่ยนคือเวลาที่อ่าน: replica อาจล้าหลังเป็นมิลลิวินาทีหรือวินาที ช่องว่างนี้เป็นเรื่องปกติ แต่สำคัญเมื่อผู้ใช้คาดว่าจะเห็นการอัปเดตทันที
ในการตั้งค่าชาร์ด มักได้ ความสอดคล้องแข็งแรงภายในชาร์ด และ การรับประกันที่อ่อนกว่าเมื่อข้ามชาร์ด โดยเฉพาะเมื่อมีการดำเนินการข้ามชาร์ด
กับ sharding “แหล่งความจริงเดียว” มักหมายถึง: สำหรับข้อมูลแต่ละชิ้น มีที่ที่เป็น authoritative ที่เขียนได้หนึ่งแห่ง (โดยปกติคือ leader ของชาร์ด) แต่ระดับโลกจะไม่มีเครื่องเดียวที่ยืนยันสถานะล่าสุดของทุกอย่างได้ทันที คุณมีหลายความจริงท้องถิ่นที่ต้องเก็บให้สอดคล้องผ่าน replication
ข้อจำกัดยุ่งยากเมื่อข้อมูลที่ต้องตรวจสอบอยู่ต่างชาร์ด:
การเลือกเหล่านี้ไม่ใช่รายละเอียดการพัฒนา—มันกำหนดความหมายของคำว่า "ถูกต้อง" สำหรับผลิตภัณฑ์ของคุณ
Rebalancing คือสิ่งที่รักษาความใช้ได้ของฐานข้อมูลชาร์ดเมื่อตัวแปรเปลี่ยนไป ข้อมูลโตไม่สม่ำเสมอ คีย์ที่คิดว่า "บาลานซ์" เกิดการเอนเอียง คุณเพิ่มโหนดใหม่ หรือคุณต้องปลดฮาร์ดแวร์ เหตุการณ์เหล่านี้สามารถเปลี่ยนชาร์ดเป็นคอขวดได้แม้ออกแบบแรกจะดูสมบูรณ์
ไม่เหมือนฐานข้อมูลตัวเดียว ชาร์ดฝังตำแหน่งข้อมูลเข้าไปในการกำหนดเส้นทาง เมื่อย้ายข้อมูลคุณไม่เพียงคัดลอกไบต์—คุณเปลี่ยนที่ที่คำขอต้องไป นั่นแปลว่าการรีบาลานซ์เป็นเรื่องเมตาดาต้าและพฤติกรรมของไคลเอ็นต์มากพอ ๆ กับสตอเรจ
ทีมส่วนใหญ่ตั้งเป้าทำงานออนไลน์เพื่อหลีกเลี่ยงการหยุดบริการ:
การเปลี่ยนแผนที่ชาร์ดเป็นเหตุการณ์ที่ทำให้แตกหักหากไคลเอ็นต์แคชการตัดสินใจการกำหนดเส้นทาง ระบบที่ดีถือเมตาดาต้าเป็นการกำหนดค่า: version มัน รีเฟรชบ่อย ๆ และชัดเจนว่าทำอย่างไรเมื่อไคลเอ็นต์เจอคีย์ที่ย้ายไปแล้ว (redirect, retry, หรือ proxy)
การรีบาลานซ์มักทำให้ประสิทธิภาพชั่วคราวดรอป (เขียนเพิ่ม cache churn โหลดคัดลอกพื้นหลัง) การย้ายเป็นส่วน ๆ พบได้บ่อย—บางช่วงย้ายก่อนอื่น—ดังนั้นต้องมีการมองเห็นชัดเจนและแผน rollback (เช่น พลิกแผนที่กลับแล้วระบาย dual-writes) ก่อนเริ่ม cutover
Sharding สมมติว่างานจะแพร่กระจาย ความแปลกคือคลัสเตอร์อาจดู "สมดุล" ทางตัวเลข (แถวต่อชาร์ดเท่ากัน) แต่พฤติกรรมจริงในโปรดักชันอาจต่างกันมาก
จุดร้อนเกิดเมื่อชิ้นเล็ก ๆ ของ keyspace ได้ทราฟฟิกส่วนใหญ่—คิดบัญชีคนดัง สินค้ายอดนิยม หรือ tenant ที่รันงานหนัก—ถ้าคีย์เหล่านี้แมปไปชาร์ดเดียว ชาร์ดนั้นจะเป็นคอขวดแม้ชาร์ดอื่นว่าง
"การเอนเอียง" ไม่ใช่เรื่องเดียว:
ทั้งสองไม่จำเป็นต้องตรงกัน ชาร์ดที่มีข้อมูลน้อยอาจเป็นจุดร้อนถ้ามันเป็นเจ้าของคีย์ที่ถูกร้องขอบ่อย
ไม่ต้อง tracing ระดับสูง เริ่มจากแดชบอร์ดต่อชาร์ด:
ถ้าหนึ่งชาร์ดมี latency เพิ่มตาม QPS ขณะที่ชาร์ดอื่นคงที่ นั่นมักเป็นจุดร้อน
การแก้แลกเปลี่ยนความเรียบง่ายเพื่อความสมดุล:
Sharding ไม่ได้แค่เพิ่มเซิร์ฟเวอร์—มันเพิ่มวิธีที่ระบบจะพังและที่ค้นหาข้อผิดพลาด หลายเหตุการณ์ไม่ใช่ "ฐานข้อมูลตาย" แต่เป็น "ชาร์ดหนึ่งตาย" หรือ "ระบบไม่เห็นด้วยว่าข้อมูลอยู่ที่ไหน"
รูปแบบที่พบซ้ำ:
บนฐานข้อมูลโหนดเดียว คุณไล่ดูล็อกชุดเดียวและเมตริกชุดเดียว ในระบบชาร์ดคุณต้องมีการมองเห็นที่ตามคำขอข้ามชาร์ด
ใช้ correlation IDs ในทุกคำขอและกระจายจากเลเยอร์ API ผ่าน router ไปยังแต่ละชาร์ด จับคู่กับ distributed tracing เพื่อให้คิวรีแบบ scatter-gather แสดงว่าชาร์ดไหนช้าหรือพัง เมตริกต้องแยก ต่อชาร์ด (latency, queue depth, อัตราความผิดพลาด) มิฉะนั้นชาร์ดร้อนจะซ่อนในค่าเฉลี่ยของฟลีท
ความล้มเหลวของ sharding มักปรากฏเป็นบั๊กความถูกต้อง:
"กู้คืนฐานข้อมูล" กลายเป็น "กู้หลายส่วนตามลำดับถูกต้อง" คุณอาจต้องกู้เมตาดาต้าก่อน แล้วแต่ละชาร์ด แล้วตรวจสอบขอบเขตชาร์ดและกฎการกำหนดเส้นทางให้ตรงกับจุดเวลา DR แผนควรซ้อมเพื่อพิสูจน์ว่าคุณประกอบคลัสเตอร์ให้สอดคล้องได้ ไม่ใช่แค่กู้แต่ละเครื่อง
Sharding มักถูกมองเป็น "สวิตช์สเกล" แต่ก็เป็นการเพิ่มความซับซ้อนถาวร ถ้าคุณตอบเป้าหมายประสิทธิภาพและความน่าเชื่อถือโดยไม่ต้องแบ่งข้อมูลข้ามโหนดเดียว คุณมักจะได้สถาปัตยกรรมที่เรียบง่ายกว่า ดีบักง่ายกว่า และขอบเขตเหตุการณ์น้อยกว่า
ก่อนชาร์ด ลองตัวเลือกที่รักษาฐานข้อมูลตรรกะเดียว:
วิธีปฏิบัติที่ดีเพื่อลดความเสี่ยงคือสร้างต้นแบบส่วน "plumbing" (ขอบเขตการกำหนดเส้นทาง idempotency workflows migration observability) ก่อนที่จะผูกฐานข้อมูล production
ตัวอย่าง: ด้วย Koder.ai คุณสามารถสปินบริการเล็ก ๆ ที่สมจริงจากแชท—มักเป็น React admin UI บวก backend Go กับ PostgreSQL—และทดสอบ API ที่รู้จักคีย์ชาร์ด idempotency keys และพฤติกรรม cutover ใน sandbox ปลอดภัย เพราะ Koder.ai รองรับโหมดวางแผน สแนปชอต/ย้อนกลับ และส่งออกซอร์สโค้ด คุณจึงสามารถทำซ้ำการตัดสินใจออกแบบเกี่ยวกับการชาร์ด แล้วนำโค้ดและ runbook ที่ได้ไปใช้จริงเมื่อมั่นใจ
Sharding เหมาะเมื่อชุดข้อมูลหรือต้นทางการเขียนชัดเจนว่าเกินขีดจำกัดโหนดเดียว และ รูปแบบคิวรีของคุณสามารถใช้คีย์ชาร์ดได้อย่างเชื่อถือได้ (มี join ข้ามชาร์ดน้อย คิวรี scatter-gather น้อย)
มันไม่เหมาะเมื่อผลิตภัณฑ์ต้องการคิวรี ad-hoc มาก ธุรกรรมหลายเอนทิตีบ่อย ข้อจำกัดความไม่ซ้ำกันระดับโลกจำนวนมาก หรือทีมไม่สามารถรับภาระการปฏิบัติการ (rebalancing resharding incident response)
ถามตัวเอง:
แม้จะเลื่อนการชาร์ดออกไป ก็ออกแบบเส้นทางย้ายล่วงหน้า: เลือกตัวระบุที่จะไม่ขัดขวางคีย์ชาร์ดในอนาคต หลีกเลี่ยงการเขียนสมมติฐานโหนดเดี่ยว และซ้อมวิธีย้ายข้อมูลด้วย downtime ต่ำ เวลาดีที่สุดที่จะวางแผน resharding คือก่อนคุณจะต้องการมันจริง ๆ
Sharding (การแบ่งแนวนอน) แบ่งชุดข้อมูลตรรกะเดียวออกเป็นเครื่องหลายเครื่อง (“ชาร์ด”) โดยแต่ละชาร์ดเก็บแถวที่ต่างกัน
การทำ replication ต่างกันตรงที่ replication เก็บสำเนาของข้อมูลชุดเดียวกันบนโหนดหลายตัว เพื่อเพิ่มความพร้อมใช้งานและขยายการอ่าน ส่วน sharding แยกข้อมูลกันไปเพื่อให้แต่ละโหนดเก็บระเบียนที่แตกต่างกัน
การสเกลแนวตั้งคือการอัปเกรดเซิร์ฟเวอร์ฐานข้อมูลตัวเดียว (เพิ่ม CPU/RAM/ดิสก์เร็วขึ้น) ซึ่งทางปฏิบัติจะง่ายกว่า แต่สุดท้ายมีข้อจำกัดหรือค่าใช้จ่ายสูง
Sharding ขยายแบบแนวนอกโดยเพิ่มเครื่องมากขึ้น แต่จะนำมาซึ่งการกำหนดเส้นทาง การปรับสมดุล และความท้าทายด้านความถูกต้องข้ามชาร์ด
ทีมมักชาร์ดเมื่อโหนดเดียวกลายเป็นคอขวดซ้ำ ๆ เช่น:
Sharding ช่วยกระจายข้อมูลและทราฟฟิกเพื่อเพิ่มความจุโดยการเพิ่มโหนด
ระบบชาร์ดทั่วไปประกอบด้วย:
ประสิทธิภาพและความถูกต้องขึ้นกับการที่ชิ้นส่วนเหล่านี้คงสถานะสอดคล้องกัน
คีย์ชาร์ดคือฟิลด์ (หรือชุดฟิลด์) ที่ใช้ตัดสินใจว่าแถวจะเก็บไว้ที่ชาร์ดไหน มันแทบจะกำหนดทั้งประสิทธิภาพ ต้นทุน และว่าฟีเจอร์ใดจะง่ายหรือยากในอนาคต เพราะมันคุมว่าจะต้องส่งคำขอไปชาร์ดเดียวหรือไปหลายชาร์ด
คีย์ที่ดีมักมี ความหลากหลายสูง (high cardinality), การกระจายที่สม่ำเสมอ, และสอดคล้องกับ รูปแบบการเข้าถึง ที่พบบ่อย เช่น tenant_id หรือ user_id
คีย์ชาร์ดที่แย่มีตัวอย่างเช่น:
คีย์เหล่านี้มักทำให้เกิดจุดร้อนหรือเปลี่ยนคำสั่งปกติให้กลายเป็นการกระจาย-รวบรวม (scatter-gather)
สามกลยุทธ์ทั่วไป:
ระบบจริงมักผสมกัน เช่นคีย์ผสม (tenant_id + user_id) หรือ sub-sharding เพื่อกระจายภายใน tenant หนัก
ถ้าคำขอมีคีย์ชาร์ด ระบบสามารถส่งไปยังชาร์ดเดียว—เส้นทางที่เร็วที่สุด
ถ้าไม่ ระบบอาจกระจายคิวรีไปยังหลายชาร์ด (fan-out) แต่ละชาร์ดรันคิวรีแล้วรวมผลเข้าด้วยกัน วิธีนี้ทำให้ tail latency เพิ่มขึ้นเพราะชาร์ดช้าตัวเดียวอาจก่อให้คำขอทั้งหมดช้า และคำขอผู้ใช้ 1 ครั้งกลายเป็นคำขอ N ครั้งไปยังชาร์ดต่าง ๆ
การเขียนที่กระทบชาร์ดเดียวสามารถใช้ธุรกรรมปกติได้และเร็ว
การเขียนข้ามชาร์ดต้องการการประสานงานระหว่างเครื่อง เช่นโปรโตคอลแบบ two-phase commit ซึ่งเพิ่มความหน่วงและความไม่ชัดเจนเวลาล้มเหลว วิธีลดความจำเป็นมีเช่น:
Sharding แยกข้อมูลข้ามเครื่อง แต่ยังต้องมี redundancy ผ่าน replication เพื่อให้ชาร์ดใช้งานได้เมื่อโหนดตาย
โดยทั่วไปจะได้ความสอดคล้องระดับแข็งแรงภายในชาร์ด (strong consistency) แต่ข้ามชาร์ดอาจให้รับประกันที่อ่อนกว่า เช่น replica อาจล้าหลังเป็นมิลลิวินาทีหรือวินาที ซึ่งสำคัญเมื่อผู้ใช้คาดว่าจะเห็นการเปลี่ยนแปลงทันที
ข้อจำกัดระดับโลกเช่น uniqueness, foreign keys, counters ยากเมื่อต้องตรวจสอบข้ามชาร์ด — มักต้องใช้ดัชนีกลาง ชาร์ดเฉพาะ หรือการออกแบบระดับแอปพลิเคชัน
การปรับสมดุล (rebalancing) และ resharding ยากเพราะการย้ายข้อมูลเปลี่ยนตำแหน่งข้อมูล ซึ่งหมายถึงการเปลี่ยนแผนที่การกำหนดเส้นทาง
แนวทางออนไลน์ทั่วไปคือ: copy → overlap → cutover
ต้อง version และรีเฟรช metadata อย่างสม่ำเสมอ มีแผนสังเกตการณ์และ rollback ก่อนเริ่ม cutover
ชาร์ดสมมติว่าการโหลดจะกระจาย แต่ระบบอาจดูสมดุลในแง่จำนวนแถวแต่แปรปรวนมากในเชิงทราฟฟิก
จุดร้อนเกิดจาก key แคบ ๆ ที่ได้ทราฟฟิกสูง เช่นบัญชีคนดัง สินค้ายอดนิยม หรืองานแบตช์ของ tenant หากพวกนี้อยู่บนชาร์ดเดียว ชาร์ดนั้นจะเป็นคอขวด
ตรวจจับด้วยแดชบอร์ดต่อชาร์ด: p95 per shard, QPS per shard, พื้นที่ที่ใช้ต่อชาร์ด
บรรเทาได้โดย: เลือกคีย์ที่กระจายทราฟฟิก, ใช้ bucketing/salting, ใช้แคช, จำกัดอัตรา/โควต้า per-tenant, หรือแยกชาร์ดที่ร้อน
ชาร์ดเพิ่มจำนวนวิธีที่ระบบจะพังและเพิ่มพื้นที่ค้นหาข้อผิดพลาด
ปัญหาทั่วไปได้แก่:
การดีบักต้องติดตามคำขอข้ามชาร์ด: ใช้ correlation IDs, distributed tracing และเมตริกแยกต่อชาร์ด
แผนแบ็กอัพ/กู้คืนต้องกู้ metadata ก่อน แล้วค่อยกู้แต่ละชาร์ด และทดสอบการประกอบระบบเพื่อให้แน่ใจสอดคล้อง
ก่อนชาร์ด ลองวิธีที่ยังคงฐานข้อมูลตรรกะเดียวไว้เช่น:
วิธีลดความเสี่ยงคือทดลองโครงสร้างพื้นฐาน (routing, idempotency, migration workflows, observability) ในสภาพแวดล้อมเล็ก ๆ ก่อนจะย้าย production
โดยทั่วไป sharding เหมาะเมื่อข้อมูลหรืออัตราการเขียนเกินขีดจำกัดของโหนดเดียว คิวรีสำคัญมากกว่า 90% สามารถกำหนดเส้นทางด้วยคีย์ชาร์ดได้