SQL vs NoSQL Databases: ความแตกต่างหลักและกรณีการใช้งาน
เรียนรู้ความแตกต่างระหว่างฐานข้อมูล SQL และ NoSQL: โมเดลข้อมูล การสเกล ความสอดคล้อง และเมื่อใดที่แต่ละแบบเหมาะกับแอปของคุณ
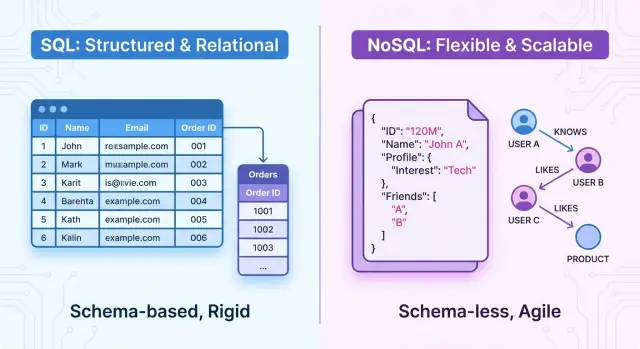
ภาพรวม: SQL และ NoSQL แบบย่อ
การเลือกใช้ระหว่างฐานข้อมูล SQL และ NoSQL จะกำหนดวิธีออกแบบ สร้าง และสเกลแอปของคุณ โมเดลฐานข้อมูลมีผลกับทุกอย่างตั้งแต่โครงสร้างข้อมูลและรูปแบบการสืบค้น ไปจนถึงประสิทธิภาพ ความเชื่อถือได้ และความเร็วที่ทีมของคุณพัฒนาผลิตภัณฑ์ได้
โดยสรุป SQL databases เป็นระบบ เชิงสัมพันธ์ ข้อมูลจัดเก็บในตารางที่มีสกีมาคงที่ แถว และคอลัมน์ ความสัมพันธ์ระหว่างเอนทิตีชัดเจน (ผ่าน foreign keys) และคุณสืบค้นโดยใช้ SQL ซึ่งเป็นภาษาที่บอกว่าต้องการอะไร ระบบเหล่านี้เน้น ธุรกรรมแบบ ACID ความสอดคล้องสูง และโครงสร้างที่ชัดเจน
NoSQL databases เป็นระบบ ไม่เชิงสัมพันธ์ แทนที่จะใช้โมเดลตารางเดียวที่เข้มงวด จะมีหลายโมเดลข้อมูลออกแบบมาสำหรับความต้องการต่างกัน เช่น:
- Key‑value stores
- Document databases
- Wide‑column stores
- Graph databases
นั่นหมายความว่า “NoSQL” ไม่ใช่เทคโนโลยีเดียว แต่เป็นคำรวมหลายแนวทาง แต่ละแบบมีข้อแลกเปลี่ยนของตัวเองในด้านความยืดหยุ่น ประสิทธิภาพ และการสร้างแบบจำลองข้อมูล หลายระบบ NoSQL ผ่อนปรนการรับประกันความสอดคล้องเพื่อแลกกับการสเกลสูง ความพร้อมใช้งาน หรือความหน่วงต่ำ
บทความนี้มุ่งเน้นที่ ความแตกต่างระหว่าง SQL และ NoSQL — โมเดลข้อมูล ภาษาในการสืบค้น ประสิทธิภาพ การสเกล และความสอดคล้อง (ACID vs eventual consistency) เป้าหมายคือช่วยให้คุณ เลือก SQL หรือ NoSQL สำหรับโปรเจกต์เฉพาะและเข้าใจว่าแต่ละประเภทเหมาะกับงานแบบใด
คุณไม่จำเป็นต้องเลือกอย่างใดอย่างหนึ่งเพียงอย่างเดียวสักหน่อย สถาปัตยกรรมสมัยใหม่มักใช้ polyglot persistence คือ SQL และ NoSQL อยู่ร่วมกันในระบบเดียว โดยแต่ละตัวรับภาระงานที่มันเหมาะที่สุด
ฐานข้อมูล SQL (เชิงสัมพันธ์) คืออะไร?
ฐานข้อมูล SQL (เชิงสัมพันธ์) เก็บข้อมูลเป็นรูปแบบตารางที่มีโครงสร้าง และใช้ Structured Query Language (SQL) เพื่อกำหนด สืบค้น และจัดการข้อมูลนั้น มันสร้างบนแนวคิดทางคณิตศาสตร์ของ relation ซึ่งคุณสามารถคิดเป็นตารางที่จัดระเบียบดี
โครงสร้างหลัก: ตาราง แถว คอลัมน์ และสกีมา
ข้อมูลจัดระเบียบเป็น ตาราง แต่ละตารางแทนเอนทิตีหนึ่งประเภท เช่น customers, orders หรือ products.
- แถว (record) คืออินสแตนซ์เดียวของเอนทิตีนั้น เช่น ลูกค้าหนึ่งคน
- คอลัมน์ (field) คือแอตทริบิวต์เฉพาะ เช่น
emailหรือorder_date
ทุกตารางมี สกีมาคงที่: โครงสร้างที่กำหนดล่วงหน้าว่า
- คอลัมน์ใดมีอยู่บ้าง
- ชนิดข้อมูลของพวกมัน (เช่น
INTEGER,VARCHAR,DATE) - ข้อจำกัด (เช่น
NOT NULL,UNIQUE)
สกีมาได้รับการบังคับโดยฐานข้อมูล ซึ่งช่วยให้ข้อมูลคงที่และคาดเดาได้
คีย์และความสัมพันธ์
ฐานข้อมูลเชิงสัมพันธ์โดดเด่นในการสร้างแบบจำลองความสัมพันธ์ระหว่างเอนทิตี
- primary key ระบุแถวแต่ละแถวให้เป็นเอกลักษณ์ (เช่น
customer_id) - foreign key เป็นคอลัมน์ที่อ้างถึง primary key ในตารางอื่น เชื่อมแถวที่เกี่ยวข้อง
คีย์เหล่านี้ช่วยให้คุณกำหนด ความสัมพันธ์ เช่น:
- หนึ่งต่อหลาย (one‑to‑many) (ลูกค้าหนึ่งคน หลายคำสั่งซื้อ)
- หลายต่อหลาย (many‑to‑many) (สินค้าหลายชิ้นอยู่ในคำสั่งซื้อหลายรายการ)
ธุรกรรมและคุณสมบัติ ACID
ฐานข้อมูลเชิงสัมพันธ์รองรับ ธุรกรรม—ชุดของการดำเนินการที่ทำงานเป็นหน่วยเดียว ธุรกรรมถูกกำหนดด้วยคุณสมบัติ ACID:
- Atomicity: ทุกการดำเนินการสำเร็จทั้งหมด หรือไม่มีเลย
- Consistency: ธุรกรรมย้ายฐานข้อมูลจากสถานะที่ถูกต้องไปยังอีกสถานะที่ถูกต้อง
- Isolation: ธุรกรรมพร้อมกันจะไม่รบกวนกัน
- Durability: เมื่อ commit แล้วข้อมูลจะถูกเก็บอย่างถาวร
การรับประกันเหล่านี้สำคัญสำหรับระบบการเงิน การจัดการสต็อก และแอปพลิเคชันที่ต้องการความถูกต้อง
ฐานข้อมูล SQL ที่นิยม
ระบบฐานข้อมูลเชิงสัมพันธ์ที่เป็นที่นิยมได้แก่:
- MySQL และ MariaDB
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
ทั้งหมดนี้ใช้ SQL เป็นหลัก และมีส่วนขยาย เครื่องมือ และฟีเจอร์ด้านการดูแล ปรับแต่ง และความปลอดภัยของตนเอง
ฐานข้อมูล NoSQL (ไม่เชิงสัมพันธ์) คืออะไร?
NoSQL คือ สโตร์ข้อมูลไม่เชิงสัมพันธ์ ที่ไม่ใช้โมเดลตาราง–แถว–คอลัมน์แบบ SQL แบบดั้งเดิม แทนที่จะเน้นโมเดลข้อมูลที่ยืดหยุ่น การสเกลแนวนอน และความพร้อมใช้งานสูง มักแลกกับการรับประกันธุรกรรมที่เข้มงวด
โมเดลข้อมูลที่ยืดหยุ่น
หลายระบบ NoSQL ถูกเรียกว่า ไม่มีสกีมา หรือ สกีมายืดหยุ่น แทนที่จะกำหนดสกีมาล่วงหน้า คุณสามารถเก็บระเบียนที่มีฟิลด์หรือโครงสร้างต่างกันในคอลเลกชันหรือบัคเก็ตเดียวได้
สิ่งนี้มีประโยชน์สำหรับ:
- ข้อกำหนดแอปที่เปลี่ยนแปลงบ่อย
- การจัดการข้อมูลกึ่งมีโครงสร้าง (logs, events, โปรไฟล์ผู้ใช้)
- เก็บข้อมูลแบบเนสเต็ด เช่น เอกสาร JSON
เพราะฟิลด์สามารถเพิ่มหรือละเว้นได้ต่อระเบียน นักพัฒนาสามารถทำซ้ำได้รวดเร็วโดยไม่ต้องมิกเกรตทุกครั้งที่โครงสร้างเปลี่ยน
ประเภทหลักของ NoSQL
NoSQL เป็นคำรวมหลายโมเดลแตกต่างกัน:
- Document databases: เก็บข้อมูลเป็นเอกสารที่คล้าย JSON มีฟิลด์เนสเต็ด ตัวอย่าง: MongoDB, Couchbase
- Key–value stores: อาร์เรย์แบบสัมพันธ์ที่ง่าย คีย์แม็ปไปยังค่า เหมาะสำหรับแคชและ session ตัวอย่าง: Redis, Amazon DynamoDB (โหมดคีย์‑ค่า)
- Column‑family stores: จัดข้อมูลตาม column family เพื่อ throughput การเขียนสูงและตารางกว้าง ตัวอย่าง: Apache Cassandra, HBase
- Graph databases: เน้นโหนดและความสัมพันธ์ เหมาะกับข้อมูลที่เชื่อมโยงสูง ตัวอย่าง: Neo4j, Amazon Neptune
โมเดลความสอดคล้อง
หลายระบบ NoSQL ให้ความสำคัญกับความพร้อมใช้งานและการทนต่อพาร์ติชัน จึงมักให้ eventual consistency แทนการทำธุรกรรม ACID ครอบคลุมทั้งชุดข้อมูล บางระบบมีระดับความสอดคล้องที่ปรับได้หรือฟีเจอร์ธุรกรรมจำกัด (ต่อเอกสาร ต่อพาร์ติชัน หรือช่วงคีย์) ให้คุณเลือกได้ระหว่างการรับประกันที่เข้มขึ้นกับประสิทธิภาพที่สูงขึ้นสำหรับการทำงานเฉพาะ
โมเดลข้อมูล: โครงสร้าง สกีมา และความสัมพันธ์
การออกแบบข้อมูลคือจุดที่ SQL และ NoSQL แตกต่างอย่างชัดเจน มันกำหนดวิธีออกแบบฟีเจอร์ สืบค้นข้อมูล และพัฒนาแอป
โครงสร้างและสกีมา
SQL databases ใช้สกีมาที่ออกแบบไว้ล่วงหน้า คุณออกแบบตารางและคอลัมน์ก่อน และมีชนิดข้อมูลและข้อจำกัดที่เข้มงวด:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
ทุกแถวต้องปฏิบัติตามสกีมา การเปลี่ยนแปลงมักต้องใช้มิกเกรชัน (ALTER TABLE, การเติมข้อมูลย้อนหลัง ฯลฯ)
NoSQL databases มักสนับสนุนสกีมายืดหยุ่น ตัวอย่างสโตร์เอกสารอาจอนุญาตให้เอกสารแต่ละชิ้นมีฟิลด์ต่างกัน:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
ฟิลด์สามารถเพิ่มหรือเปลี่ยนได้ต่อเอกสารโดยไม่ต้องมิกเกรตกลาง บางระบบ NoSQL ยังรองรับสกีมาแบบเลือกบังคับได้ แต่โดยทั่วไปจะยืดหยุ่นกว่า
การทำ normalization กับ denormalization
โมเดลเชิงสัมพันธ์สนับสนุน normalization: แยกข้อมูลเป็นตารางที่เกี่ยวข้องเพื่อลดการซ้ำซ้อนและรักษาความสมบูรณ์ แบบนี้ช่วยให้เขียนข้อมูลได้เร็วและขนาดจัดเก็บเล็ก แต่การอ่านอาจต้อง JOIN หลายตาราง
โมเดล NoSQL มักสนับสนุน denormalization: ฝังข้อมูลที่เกี่ยวข้องเข้าด้วยกันตามการอ่านที่คาดหวัง ซึ่งเพิ่มประสิทธิภาพการอ่านและทำให้การสืบค้นง่าย แต่การเขียนอาจซับซ้อนขึ้นเพราะข้อมูลเดียวกันอาจอยู่หลายที่
การออกแบบความสัมพันธ์
ใน SQL ความสัมพันธ์ชัดเจนและถูกบังคับ:
- one‑to‑many: foreign keys (users → orders)
- many‑to‑many: ตารางเชื่อม (users_roles)
ใน NoSQL ความสัมพันธ์มักทำโดย:
- Embedding (เอกสารผู้ใช้มีอาเรย์คำสั่งซื้อ) สำหรับข้อมูลที่ผูกแน่น
- Referencing (มี user_id ในเอกสาร order) สำหรับข้อมูลที่ผูกหลวมหรือชุดใหญ่
การเลือกขึ้นกับรูปแบบการเข้าถึง:
- หากคุณดึงผู้ใช้และ 10 คำสั่งซื้อล่าสุดเสมอ การฝังอาจเหมาะ
- หากคำสั่งใหญ่มาก อัปเดตบ่อย หรือเข้าถึงแยกต่างหาก การอ้างอิงและสืบค้นแยกมักดีกว่า
ผลต่อข้อกำหนดที่เปลี่ยนไป
กับ SQL การเปลี่ยนสกีมาต้องวางแผนมากกว่า แต่ให้การรับประกันที่เข้มงวดและความสอดคล้องทั่วทั้งชุดข้อมูล การรีแฟกเตอร์ต้องมีกระบวนการชัดเจน: มิกเกรชัน การเติมข้อมูลย้อนหลัง การอัปเดตข้อจำกัด
กับ NoSQL ความต้องการเปลี่ยนแปลงมักรองรับได้ง่ายในระยะสั้น คุณสามารถเริ่มเก็บฟิลด์ใหม่ได้ทันทีและค่อยๆ อัปเดตเอกสารเก่า ข้อเสียคือโค้ดแอปต้องรองรับรูปร่างเอกสารหลายแบบและเคสขอบ
การเลือกแบบ normalized (SQL) หรือ denormalized (NoSQL) ไม่ใช่เรื่อง “ดีกว่า” แต่เป็นการจับคู่โครงสร้างข้อมูลกับรูปแบบการสืบค้น ปริมาณการเขียน และความถี่เปลี่ยนแปลงของโดเมนคุณ
ภาษาในการสืบค้นและรูปแบบการเข้าถึง
SQL: เชิงประกาศและมาตรฐาน
ฐานข้อมูล SQL ถูกสืบค้นด้วยภาษาประกาศ: คุณบอก สิ่งที่ต้องการ ไม่ใช่วิธีการดึงข้อมูล คำสั่งพื้นฐานอย่าง SELECT, WHERE, JOIN, GROUP BY, ORDER BY ช่วยให้คุณตั้งคำถามซับซ้อนได้ในคำสั่งเดียว
เพราะ SQL เป็นมาตรฐาน (ANSI/ISO) ระบบเชิงสัมพันธ์ส่วนใหญ่มีไวยากรณ์แกนกลางที่คล้ายกัน ผู้ขายเพิ่มส่วนขยาย แต่ทักษะและคำสั่งมักย้ายข้ามระบบได้ ทำให้มีระบบนิเวศเครื่องมือใหญ่: ORMs, query builders, เครื่องมือรายงาน, BI, เฟรมเวิร์กมิกเกรชัน และตัวปรับแต่งคิวรี
NoSQL: API และรูปแบบที่หลากหลาย
ระบบ NoSQL เปิดเผยการสืบค้นในรูปแบบต่างกัน:
- Document stores (MongoDB, Couchbase) ใช้อ็อบเจกต์สืบค้นคล้าย JSON และบางครั้งมีภาษาสืบค้นของตัวเอง
- Key‑value stores (Redis, DynamoDB‑style APIs) มักเน้นการค้นหาด้วย primary key และชุดการค้นหา secondary index เล็กน้อย
- Wide‑column stores (Cassandra, HBase) ปรับให้เหมาะกับการสืบค้นที่ตามรูปแบบ primary‑key และ clustering‑key ที่กำหนดไว้
- Search engines (Elasticsearch, Solr) ใช้ DSL สำหรับ full‑text และการค้นหาตามความเกี่ยวข้อง
บางระบบ NoSQL มี aggregation pipelines หรือกลไกแบบ MapReduce สำหรับงานวิเคราะห์ แต่การ JOIN ข้ามคอลเลกชันหรือพาร์ติชันมักจำกัดหรือไม่มี โดยปกติข้อมูลที่เกี่ยวข้องจะฝังหรือ denormalize
รูปแบบการเข้าถึงและความสามารถในการผลิตงาน
การสืบค้นเชิงสัมพันธ์มักพึ่งพา JOIN‑หนัก: normalize ข้อมูล แล้วประกอบกลับตอนอ่านด้วย JOIN นี่ทรงพลังสำหรับการรายงาน ad‑hoc แต่ JOIN ซับซ้อนอาจยากต่อการปรับแต่ง
รูปแบบ NoSQL มักเป็น มุ่งรอบเอกสารหรือคีย์: ออกแบบข้อมูลรอบการสืบค้นที่พบบ่อยที่สุด การอ่านรวดเร็วและเรียบง่าย—มักเป็นการค้นหาด้วยคีย์เดียว—แต่หากรูปแบบการเข้าถึงเปลี่ยนทีหลัง อาจต้องออกแบบข้อมูลใหม่
สำหรับการเรียนรู้และความสามารถในการผลิต:
- โมเดลประกาศของ SQL และแหล่งเรียนรู้มากมายทำให้เรียนรู้ง่ายและทนทาน
- การสืบค้น NoSQL อาจง่ายขึ้นสำหรับรูปแบบที่เรียบและชัดเจน แต่แต่ละระบบมีไวยากรณ์และข้อจำกัดต่างกัน ทักษะจึงเคลื่อนย้ายได้ยากกว่า
ทีมที่ต้องการสืบค้นข้ามความสัมพันธ์แบบ ad‑hoc มักเลือก SQL ส่วนทีมที่มีรูปแบบการเข้าถึงคงที่ในสเกลสูง มักพบว่า NoSQL เหมาะสมกว่า
ความสอดคล้อง ธุรกรรม และการแลกเปลี่ยนตาม CAP
ACID: การรับประกันที่เข้มงวดในระบบ SQL
ฐานข้อมูล SQL ส่วนใหญ่ถูกออกแบบรอบ ธุรกรรม ACID:
- Atomicity: ธุรกรรมสำเร็จทั้งหมดหรือไม่เลย
- Consistency: ทุกธุรกรรมที่ commit ย้ายข้อมูลไปสู่สถานะที่ถูกต้อง
- Isolation: ธุรกรรมพร้อมกันไม่รบกวนกัน (ระดับ isolation เช่น READ COMMITTED, REPEATABLE READ, SERIALIZABLE)
- Durability: เมื่อ commit แล้ว ข้อมูลจะคงอยู่ผ่านการชนและข้อผิดพลาด
นี่ทำให้ SQL เหมาะกับงานที่ความถูกต้องสำคัญกว่าปริมาณการเขียนดิบ เช่น การเงิน การจัดการสต็อก การจอง
BASE และ eventual consistency ในหลายระบบ NoSQL
หลายระบบ NoSQL มุ่งสู่ BASE:
- Basically Available: ระบบพยายามพร้อมให้บริการและตอบสนอง
- Soft state: ข้อมูลอาจไม่สอดคล้องระหว่างรีพลิกาในช่วงสั้น
- Eventual consistency: หากไม่มีการอัปเดตใหม่ สำเนาจะคอนเวิร์จในเวลาหนึ่ง
การเขียนอาจเร็วและกระจาย แต่การอ่านอาจเห็นข้อมูลที่ล้าสมัยเล็กน้อย
CAP theorem ในการปฏิบัติ
CAP บอกว่าระบบกระจายภายใต้การแบ่งพาร์ติชันต้องเลือกระหว่าง:
- Consistency (C): ลูกค้าทุกคนเห็นข้อมูลเดียวกันพร้อมกัน
- Availability (A): ทุกคำขอได้รับการตอบสนอง
คุณไม่สามารถรับประกันทั้ง C และ A ในขณะที่เกิดพาร์ติชันได้
รูปแบบทั่วไป:
- การติดตั้ง SQL มักเน้น ความสอดคล้องที่เข้มงวด: เหมาะกับ การชำระเงิน สต็อก ยอดบัญชี การจอง และงานที่การอ่านล้าสมัยอาจมีผลทางการเงินหรือกฎหมาย
- การตั้งค่า NoSQL มักเน้น ความพร้อมใช้งานและ eventual consistency: เหมาะกับ การวิเคราะห์ ฟีดโซเชียล แคตตาล็อกสินค้า บันทึก และแคช ที่ยอมรับความไม่สอดคล้องชั่วคราวได้
ระบบสมัยใหม่มักผสมโหมดต่าง ๆ (เช่น ปรับระดับความสอดคล้องต่อการทำงาน) เพื่อให้ส่วนต่าง ๆ ของแอปเลือกการรับประกันตามต้องการ
ความสามารถในการปรับขนาดและความต่างด้านประสิทธิภาพ
วิธีที่ SQL มักสเกล
ฐานข้อมูล SQL แบบดั้งเดิมออกแบบมาสำหรับโหนดเดียวที่ทรงพลัง
คุณมักเริ่มด้วย การสเกลแนวตั้ง: เพิ่ม CPU, RAM, และดิสก์ที่เร็วขึ้นในเครื่องเดียว หลายเอนจินยังรองรับ read replicas: โหนดเพิ่มเติมที่รับโหลดอ่านเท่านั้น ในขณะที่การเขียนทั้งหมดไปยัง primary แบบนี้เหมาะกับ:
- ปริมาณการเขียนปานกลาง
- คิวรีเชิงวิเคราะห์หนักหรือการรายงาน
- เวิร์กโหลดที่ความสอดคล้องมีความสำคัญ
แต่การสเกลแนวตั้งมีขีดจำกัดด้านฮาร์ดแวร์และค่าใช้จ่าย และ read replicas อาจนำมาซึ่ง replication lag
NoSQL และการสเกลแนวนอน
ระบบ NoSQL ถูกออกแบบเพื่อ สเกลแนวนอน: กระจายข้อมูลข้ามหลายโหนดด้วย sharding หรือ partitioning แต่ละชาร์ดถือส่วนข้อมูล ดังนั้นทั้งการอ่านและการเขียนสามารถ กระจาย ได้ เพิ่ม throughput
แนวทางนี้เหมาะกับ:
- งานเขียนจำนวนมาก
- ชุดข้อมูลขนาดใหญ่เกินเครื่องเดียว
- แอประดับโลกที่ต้องการข้อมูลใกล้ผู้ใช้
ข้อแลกเปลี่ยนคือความซับซ้อนด้านการปฏิบัติการ: เลือก shard key, จัดการการรีบาลานซ์, และจัดการคิวรีข้ามชาร์ด
รูปแบบประสิทธิภาพและการจัดทำดัชนี
สำหรับงานอ่านหนักที่มี JOIN และการรวมเชิงซับซ้อน ฐานข้อมูล SQL ที่ออกแบบดัชนีดีสามารถเร็วมาก ตัว optimizer ใช้สถิติและแผนคิวรี
หลายระบบ NoSQL เน้น รูปแบบการเข้าถึงคีย์แบบตรง พวกมันเก่งเรื่อง latency ต่ำและ throughput สูงเมื่อคิวรีคาดการณ์ได้และข้อมูลถูกออกแบบรอบการอ่านมากกว่าการสืบค้น ad‑hoc
Latency ในคลัสเตอร์ NoSQL อาจต่ำ แต่การสืบค้นข้ามพาร์ติชัน ดัชนีทุติยภูมิ และการดำเนินการหลายเอกสารอาจช้าหรือจำกัด ด้านการปฏิบัติการ การสเกล NoSQL มักหมายถึงการจัดการคลัสเตอร์เพิ่มเติม ขณะที่การสเกล SQL มักเป็นเรื่องฮาร์ดแวร์และการจัดดัชนีบนโหนดไม่กี่ตัว
เมื่อใดที่ควรเลือก SQL โดยทั่วไป
งานที่เน้นธุรกรรมและสำคัญเชิงธุรกิจ
ฐานข้อมูลเชิงสัมพันธ์โดดเด่นเมื่อคุณต้องการ OLTP ปริมาณสูงและเชื่อถือได้:
- ระบบการเงิน (การชำระเงิน การบัญชี การเทรด)
- ระบบจัดการคำสั่งซื้อและสต็อก
- ERP, CRM, และแพลตฟอร์มการเรียกเก็บเงิน
ระบบเหล่านี้พึ่งพาธุรกรรม ACID ความสอดคล้องที่ชัดเจน และพฤติกรรมการ rollback หากการโอนเงินต้อง ไม่ เกิดการคิดเงินซ้ำหรือสูญหาย ฐานข้อมูล SQL มักปลอดภัยกว่าตัวเลือก NoSQL ทั่วไป
ข้อมูลมีโครงสร้างและความสัมพันธ์ซับซ้อน
เมื่อโมเดลข้อมูลของคุณชัดเจนและคงที่ และเอนทิตีเชื่อมโยงกันมาก ฐานข้อมูลเชิงสัมพันธ์มักเป็นทางเลือกที่เป็นธรรมชาติ ตัวอย่าง:
- ลูกค้า คำสั่งซื้อ ใบแจ้งหนี้ สินค้า และการจัดส่ง
- บันทึกสุขภาพที่มีผู้ป่วย การเยี่ยมรักษา การสั่งยา และผลตรวจ
สกีมาที่เป็นปกติ foreign keys และ JOIN ช่วยให้บังคับความสมบูรณ์และสืบค้นความสัมพันธ์ซับซ้อนได้โดยไม่ต้องซ้ำข้อมูล
การวิเคราะห์บนสกีมาที่กำหนดชัด
เพื่อการรายงานและ BI บนข้อมูลที่มีสกีมาชัด (star/snowflake schemas, data marts) SQL และ data warehouses ที่เข้ากันได้กับ SQL มักเป็นตัวเลือกที่เหมาะ สม ทีมวิเคราะห์คุ้นเคยกับ SQL และเครื่องมือที่มีรวมได้โดยตรง
ความเป็นผู้ใหญ่ ทักษะ และการปฏิบัติตาม
การถกเถียงมักมองข้ามความเป็นผู้ใหญ่ของการปฏิบัติการ SQL ฐานข้อมูลเชิงสัมพันธ์เสนอ:
- ความน่าเชื่อถือและเครื่องมือที่พิสูจน์แล้ว
- กลุ่มวิศวกร DBA และนักวิเคราะห์ที่เชี่ยวชาญ SQL จำนวนมาก
- ฟีเจอร์สำหรับการตรวจสอบ การควบคุมการเข้าถึง การเข้ารหัส และการสำรองข้อมูลที่ช่วยให้เป็นไปตามกรอบกฎหมาย
เมื่อการตรวจสอบ ใบรับรอง หรือความเสี่ยงทางกฎหมายมีความสำคัญ ฐานข้อมูล SQL มักเป็นทางเลือกที่ชัดเจนกว่าในการเทียบกับการตัดสินใจ SQL vs NoSQL
เมื่อใดที่ควรเลือก NoSQL โดยทั่วไป
NoSQL เหมาะเมื่อการสเกล ความยืดหยุ่น และประสบการณ์ที่ต้องพร้อมใช้งานสำคัญกว่าการ JOIN ซับซ้อนและการรับประกันธุรกรรมเข้มงวด
ระบบที่มีทราฟฟิกสูงและขนาดใหญ่
ถ้าคุณคาดว่าจะมีปริมาณการเขียนมหาศาล การกระชากทราฟฟิก หรือชุดข้อมูลเติบโตเป็นเทราไบต์ NoSQL (เช่น key‑value หรือ wide‑column) มักสเกลแนวนอนได้ง่ายกว่า ชาร์ดและการจำลองมักติดตั้งมาโดยออกแบบ ช่วยให้เพิ่มความจุด้วยการเพิ่มโหนด
รูปแบบนี้พบบ่อยใน:
- เว็บและแอปมือถือที่มีทราฟฟิกสูง
- แบ็กเอนด์เกมและ leaderboard แบบเรียลไทม์
- Ad tech, recommendation engines, และบริการ personalization
ข้อมูลยืดหยุ่นระหว่างการพัฒนาผลิตภัณฑ์อย่างรวดเร็ว
เมื่อโมเดลข้อมูลเปลี่ยนบ่อย การออกแบบยืดหยุ่นมีคุณค่า Document databases ให้คุณเพิ่มฟิลด์และโครงสร้างโดยไม่ต้องมิกเกรตเสมอ
เหมาะสำหรับ:
- ระบบจัดการเนื้อหาและแคตตาล็อกสินค้า
- โปรไฟล์ผู้ใช้และการตั้งค่าที่เปลี่ยนได้
- ฟีดกิจกรรมและบันทึกเหตุการณ์ที่มีประเภทเหตุการณ์ใหม่เกิดขึ้นบ่อย
IoT แคช และข้อมูลแบบ time‑series
NoSQL แข็งแกร่งในงาน append‑heavy และข้อมูลเรียงตามเวลา:
- เทเลเมทรีจากอุปกรณ์ IoT
- เมตริก การบันทึก และการมอนิเตอร์
- เลเยอร์แคชสำหรับข้อมูลที่อ่านบ่อย (sessions, tokens, feature flags)
ฐานข้อมูลคีย์‑ค่าและ time‑series ถูกจูนมาเพื่อการเขียนที่เร็วและการอ่านที่เรียบง่าย
การกระจายทั่วโลกและประสบการณ์พร้อมใช้งานตลอด
แพลตฟอร์ม NoSQL หลายตัวให้ความสำคัญกับ geo‑replication และการเขียนหลายภูมิภาค ทำให้ผู้ใช้ทั่วโลกอ่านเขียนด้วย latency ต่ำ เหมาะเมื่อ:
- แอปต้องพร้อมใช้งานแม้ภูมิภาคเกิดเหตุขัดข้อง
- ผู้ใช้ในทวีปต่าง ๆ ต้องการการตอบสนองระดับท้องถิ่น
ข้อแลกเปลี่ยนคือมักยอมรับ eventual consistency แทน ACID เคร่งครัดข้ามภูมิภาค
ข้อจำกัดและข้อแลกเปลี่ยน
การเลือก NoSQL มักหมายถึงสละฟีเจอร์บางอย่างที่ SQL ให้โดยปกติ:
- ความสอดคล้องที่อ่อนหรือปรับได้; ไม่ใช่ว่าการอ่านทุกครั้งจะเห็นการเขียนล่าสุด
- การสืบค้น ad‑hoc และการ JOIN ที่จำกัด; ต้องออกแบบรอบรูปแบบการเข้าถึงล่วงหน้า
- ความรับผิดชอบด้านความสมบูรณ์ของข้อมูลย้ายไปยังเลเยอร์แอปพลิเคชันมากขึ้น
เมื่อยอมรับข้อแลกเปลี่ยนเหล่านี้ NoSQL ให้การสเกล ความยืดหยุ่น และการเข้าถึงระดับโลกที่ดีกว่าในหลายกรณี
รูปแบบผสมและ polyglot persistence
Polyglot persistence หมายถึงการใช้เทคโนโลยีฐานข้อมูลหลายแบบในระบบเดียวโดยเจตนา เลือกเครื่องมือที่เหมาะสมกับงาน แทนที่จะบังคับทุกอย่างเข้าไปในที่จัดเก็บเดียว
การตั้งค่าผสมทั่วไป
รูปแบบที่พบบ่อยคือ:
- SQL สำหรับข้อมูลหลัก: คำสั่งซื้อ การชำระเงิน โปรไฟล์ผู้ใช้ การตั้งค่า ที่ต้องการความสอดคล้องธุรกรรมและการสืบค้น
- NoSQL สำหรับ sessions และแคช: สโตร์คีย์‑ค่า สำหรับ session, rate limits, feature flags; บางครั้งใช้ document store สำหรับการตั้งค่าผู้ใช้หรือฟีดกิจกรรม
วิธีนี้เก็บ “system of record” ไว้ในฐานข้อมูลเชิงสัมพันธ์ ขณะเดียวกันถ่ายงานอ่านหนักหรือชั่วคราวไปยัง NoSQL
การผสมหลายประเภทของ NoSQL
คุณยังสามารถผสม NoSQL ประเภทต่าง ๆ:
- Key‑value สำหรับแคชและ session
- Document สำหรับเนื้อหาหรือข้อมูลผู้ใช้ที่สกีมาเป็นไปได้
- Wide‑column หรือ time‑series สำหรับเมตริกและบันทึกเหตุการณ์
- Search engine สำหรับ full‑text และการค้นหาวิเคราะห์
เป้าหมายคือจัดให้แต่ละ datastore ตรงกับรูปแบบการเข้าถึง: การค้นหาง่าย การรวม หรือการอ่านแบบเรียงตามเวลา
การรวมระบบและต้นทุนการปฏิบัติการ
สถาปัตยกรรมผสมพึ่งพาจุดเชื่อมต่อ:
- ETL หรือ streaming เพื่อซิงก์ข้อมูลระหว่างสโตร์หรือสร้างมุมมองสำหรับอ่าน
- Event streaming เพื่อเผยแพร่การเปลี่ยนแปลง (เช่น จาก SQL ไปยัง cache หรือ analytics)
- APIs ที่ซ่อนที่เก็บข้อมูลเบื้องหลังเพื่อให้บริการไม่ต้องรู้ว่าข้อมูลอยู่ที่ไหน
ข้อแลกเปลี่ยนคือ ภาระการปฏิบัติการเพิ่มขึ้น: ต้องเรียนรู้ ดูแล รักษาความปลอดภัย สำรอง และแก้ปัญหาหลายเทคโนโลยี Polyglot persistence เหมาะเมื่อแต่ละ datastore แก้ปัญหาที่ชัดเจนและวัดผลได้จริง
วิธีเลือก SQL หรือ NoSQL สำหรับโปรเจกต์
การเลือกไม่ใช่ตามเทรนด์ แต่จับคู่งานกับเครื่องมือให้เหมาะ
1. เริ่มจากข้อมูลและความสัมพันธ์ของคุณ
ถามตัวเอง:
- ข้อมูลเป็นตารางตามธรรมชาติไหม มีเอนทิตีชัดเจน (ผู้ใช้ คำสั่ง ใบแจ้งหนี้)?
- มีการ JOIN มากและความสัมพันธ์ซับซ้อนหรือไม่?
ถ้า ใช่ ฐานข้อมูลเชิงสัมพันธ์มักเป็นค่าเริ่มต้น หากข้อมูลเป็นลักษณะเอกสาร เนสเต็ด หรือมีความหลากหลายสูง ฐานข้อมูลเอกสารหรือ NoSQL อาจเหมาะกว่า
2. ชัดเจนเรื่องความต้องการความสอดคล้องและธุรกรรม
- ต้องการธุรกรรม ACID ข้ามหลายแถวหรือหลายตารางเพื่อความถูกต้องหรือไม่?
- ยอมให้บางการอ่านเห็นข้อมูลล้าสมัยได้หรือไม่?
ความสอดคล้องเข้มงวดและธุรกรรมซับซ้อนมักเอื้อต่อ SQL ในขณะที่ปริมาณการเขียนสูงกับความสอดคล้องยืดหยุ่นมักเอื้อต่อ NoSQL
3. เข้าใจการสเกลและประสิทธิภาพที่คาดหวัง
- ปริมาณการอ่าน/เขียนคาดหวังตอนนี้และใน 2–3 ปีข้างหน้า?
- ต้อง latency ต่ำข้ามภูมิภาคหรือไม่?
หลายโปรเจกต์สเกลไกลกับ SQL ด้วยการจัดดัชนีและฮาร์ดแวร์ที่ดี หากคาดการณ์การสเกลมากกับรูปแบบการเข้าถึงเรียบง่าย (key lookups, time‑series) NoSQL อาจคุ้มค่ากว่า
4. รูปแบบการสืบค้นและการรายงาน
- ต้องการการวิเคราะห์ ad‑hoc, JOIN และรายงานแบบยืดหยุ่นหรือไม่?
- ใครจะสืบค้นข้อมูล (เฉพาะวิศวกรหรือทั้งนักวิเคราะห์และผู้ใช้งานธุรกิจ)?
SQL เหมาะสำหรับคิวรีเชิงซับซ้อน เครื่องมือ BI และการสำรวจแบบ ad‑hoc หลาย NoSQL ออกแบบมารอบเส้นทางการเข้าถึงที่คาดการณ์ได้ และอาจทำให้คิวรีใหม่ๆ ยากขึ้น
5. ทักษะทีม เครื่องมือ และโฮสติ้ง
- ทีมของคุณคุ้นเคยอะไร: SQL, การออกแบบสกีมา, หรือระบบ NoSQL เฉพาะ?
- อะไรพร้อมใช้งานในสภาพแวดล้อมโฮสติ้งของคุณ (Postgres/MySQL managed, managed MongoDB, DynamoDB)?
- ระบบนิเวศไหนมีไลบรารี ดริฟเวอร์ และการมอนิเตอร์ที่ดีกว่าสำหรับสแต็กของเรา?
เลือกเทคโนโลยีที่ทีมสามารถปฏิบัติการได้อย่างมั่นใจ โดยเฉพาะสำหรับงาน production troubleshooting และมิกเกรชัน
6. ต้นทุนและความซับซ้อนด้านการปฏิบัติการ
- เราจ่ายได้ไหมที่จะรันและจัดการคลัสเตอร์ NoSQL ที่กระจาย หรือ managed SQL จะครอบคลุมความต้องการ?
- ค่าใช้จ่ายการจัดเก็บและการอ่าน/เขียนเปรียบเทียบอย่างไรสำหรับโหลดที่คาดหวัง?
ฐานข้อมูล SQL แบบ managed เดียวมักถูกและเรียบง่ายจนกว่าจะโตเกินขีดจำกัดชัดเจน
7. ทดสอบด้วยโหลดที่สมจริง
ก่อนตัดสินใจ:
- สร้างโมเดลตัวอย่างของข้อมูลทั้งในสกีมาของ SQL และโมเดล NoSQL ที่เลือก
- สร้างคิวรีและการเขียนที่สำคัญบางรายการ
- รัน load test ด้วยปริมาณข้อมูลและทราฟฟิกสมจริง
- วัด latency, throughput, อัตราข้อผิดพลาด และความพยายามเชิงปฏิบัติการ
ใช้การวัดเหล่านั้น—ไม่ใช่สมมติฐาน—ในการตัดสินใจ สำหรับหลายโปรเจกต์ การเริ่มด้วย SQL เป็นทางเลือกที่ปลอดภัย แล้วเพิ่ม NoSQL เมื่อต้องการสำหรับงานเฉพาะที่ต้องการสเกลหรือความยืดหยุ่นพิเศษ
ตำนานที่พบบ่อยเกี่ยวกับ SQL และ NoSQL
ตำนาน 1: NoSQL จะมาแทนที่ SQL
NoSQL ไม่ได้มาเพื่อฆ่าฐานข้อมูลเชิงสัมพันธ์ แต่มาเพื่อเติมเต็ม
ฐานข้อมูลเชิงสัมพันธ์ยังคงครองระบบบันทึกหลัก: การเงิน HR ERP สต็อก และงานที่ความสอดคล้องและธุรกรรมสำคัญ NoSQL โดดเด่นเมื่อสกีมายืดหยุ่น ปริมาณการเขียนมหาศาล หรือต้องการอ่านแบบกระจายทั่วโลกมากกว่าการ JOIN เชิงซับซ้อน
องค์กรส่วนใหญ่ใช้ทั้งสองแบบ เลือกเครื่องมือให้ตรงกับภาระงาน
ตำนาน 2: SQL ไม่สามารถสเกลแนวนอน
ฐานข้อมูลเชิงสัมพันธ์เคยสเกลขึ้นบนเซิร์ฟเวอร์ที่ใหญ่กว่า แต่เอนจินสมัยใหม่รองรับ:
- read replicas
- sharding/partitioning
- Distributed SQL (NewSQL)
การสเกลฐานข้อมูลเชิงสัมพันธ์อาจซับซ้อนกว่าการเพิ่มโหนดในคลัสเตอร์ NoSQL แต่ทำได้ด้วยการออกแบบและเครื่องมือที่เหมาะสม
ตำนาน 3: NoSQL ไม่มีสกีมาเลย
“ไม่มีสกีมา” หมายถึง “แอปเป็นผู้บังคับสกีมา ไม่ใช่ฐานข้อมูล”
สโตร์เอกสาร คีย์‑ค่า และ wide‑column ยังคงมีโครงสร้าง แต่โครงสร้างนั้นถูกบังคับโดยแอปหรือ validator มากกว่าโดยฐานข้อมูลโดยตรง ความยืดหยุ่นทรงพลัง แต่หากไม่มีข้อตกลงด้านข้อมูลและการตรวจสอบ จะนำไปสู่ความไม่สอดคล้องได้ง่าย
ตำนาน 4: แบบใดแบบหนึ่งเร็วกว่าตลอดไป
ประสิทธิภาพขึ้นกับการออกแบบข้อมูล ดัชนี และรูปแบบงานมากกว่าการติดป้าย "SQL" หรือ "NoSQL"
คอลเลกชัน NoSQL ที่ขาดดัชนีจะช้ากว่าตารางเชิงสัมพันธ์ที่ปรับจูนดีสำหรับหลายคิวรี ในทางกลับกัน สกีมาเชิงสัมพันธ์ที่ไม่ออกแบบตามรูปแบบการเข้าถึงจะช้ากว่าโมเดล NoSQL ที่เหมาะกับคิวรีเหล่านั้น
ตำนาน 5: SQL ปลอดภัยและเชื่อถือได้กว่า NoSQL เสมอไป
หลายระบบ NoSQL รองรับ durability, encryption, auditing, และ access control ได้ดี ขณะเดียวกันฐานข้อมูลเชิงสัมพันธ์ที่กำหนดค่าไม่ดีอาจไม่ปลอดภัย
ความปลอดภัยและความเชื่อถือได้ขึ้นกับผลิตภัณฑ์ การปรับใช้ การตั้งค่า และความเป็นผู้ใหญ่เชิงปฏิบัติการ ไม่ใช่เพียงป้าย "SQL" หรือ "NoSQL"
กลยุทธ์การย้ายและการอยู่ร่วมกัน
ทีมมักย้ายระหว่าง SQL และ NoSQL ด้วยเหตุผลสองประการ: การสเกลและความยืดหยุ่น ผลิตภัณฑ์ที่มีทราฟฟิกสูงอาจเก็บ relational DB เป็น system of record แล้วเพิ่ม NoSQL เพื่อรองรับการอ่านที่สเกลหรือฟีเจอร์ที่ต้องการสกีมายืดหยุ่น
รูปแบบการย้าย
การย้ายแบบ big‑bang เสี่ยง ทางปลอดภัยกว่าคือ:
- การย้ายทีละส่วน: แยก bounded context หนึ่ง (เช่น product catalog) แล้วย้ายข้อมูลและทราฟฟิกเฉพาะส่วนนั้นไปยัง NoSQL ขณะที่ส่วนอื่นยังอยู่ใน SQL
- dual writes: ช่วงหนึ่ง บริการเขียนทั้ง SQL และ NoSQL เมื่อร้านใหม่พิสูจน์แล้วในโปรดักชัน ค่อยเลิกเส้นทางเก่า
- sync pipelines: เก็บฐานข้อมูลหนึ่งเป็น primary แล้วสตรีมข้อมูลไปยังอีกตัวด้วย CDC, คิวข้อความ หรืองาน ETL
กับดักสกีมาและโมเดล
การย้ายจาก SQL ไปยัง NoSQL มักทำให้ทีมก๊อบปี้ตารางเป็นเอกสารหรือคีย์‑ค่า ซึ่งมักนำไปสู่:
- ข้อมูล NoSQL ที่ยัง over‑normalized ต้อง JOIN ที่เลเยอร์แอปมาก
- เอกสารที่โตขึ้นไม่มีขอบเขต
วางแผนรูปแบบการเข้าถึงก่อน แล้วออกแบบสกีมา NoSQL รอบคิวรีจริง
อยู่ร่วมกันและตาข่ายความปลอดภัย
รูปแบบทั่วไปคือ SQL สำหรับข้อมูลเชิงอ้างอิง และ NoSQL สำหรับมุมมองอ่านหนัก ลงทุนใน:
- การ backfill และ rollback ที่ทำซ้ำได้
- การยืนยันข้อมูลระหว่างสโตร์
- การทดสอบโหลดที่สะท้อนรูปแบบการสืบค้นจริง
วิธีนี้ทำให้การย้าย SQL vs NoSQL เป็นการควบคุมได้ แทนที่จะเป็นการย้ายทางเดียวที่เจ็บปวด
สรุปและคำแนะนำเชิงปฏิบัติ
SQL และ NoSQL แตกต่างกันหลัก ๆ ในสี่ด้าน:
- โมเดลข้อมูล – SQL ใช้ตาราง แถว และสกีมาที่ชัดเจน; NoSQL ใช้เอกสาร คีย์‑ค่า wide columns หรือกราฟ ที่ยืดหยุ่นกว่า
- การสืบค้น – SQL เสนอภาษาสืบค้นเดียวที่ทรงพลัง; NoSQL มักใช้ API หรือไวยากรณ์เฉพาะฐานข้อมูล
- ความสอดคล้อง & ธุรกรรม – SQL มุ่งธุรกรรม ACID; หลาย NoSQL แลกความรับประกันบางส่วนเพื่อความพร้อมใช้งานและสเกล
- การสเกล – SQL โดยทั่วไปสเกลขึ้น (และปัจจุบันขยายออกได้ด้วย clustering); NoSQL ถูกออกแบบสำหรับการชาร์ดและการจำลองข้ามหลายโหนด
ไม่มีหมวดหมู่ใดดีกว่าทุกกรณี คำตอบขึ้นกับ ความต้องการจริง ของคุณ ไม่ใช่คำชวนเชื่อ
วิธีเลือกในทางปฏิบัติ
-
เขียนความต้องการของคุณลง:
- โครงสร้างข้อมูลและความสัมพันธ์
- รูปแบบการสืบค้นและความต้องการรายงาน
- ความคาดหวังเรื่องความสอดคล้อง vs ความพร้อมใช้งาน
- ทราฟฟิกสูงสุด ขนาดข้อมูล และเป้าหมายความหน่วง
- ทักษะทีมและเครื่องมือที่มี
-
เลือกโดยมีเหตุผลเป็นค่าเริ่มต้น:
- เลือก SQL สำหรับระบบเชิงธุรกรรม การวิเคราะห์ และข้อมูลธุรกิจที่มีโครงสร้างชัดเจน
- พิจารณา NoSQL สำหรับงานเขียนหนักมาก ขนาดใหญ่ หรือข้อมูลกึ่งมีโครงสร้างที่เปลี่ยนบ่อย
-
เริ่มเล็กและวัดผล:
- สร้าง thin vertical slice หรือ proof‑of‑concept
- เก็บเมตริก: latency คิวรี throughput อัตราข้อผิดพลาด และความพยายามในการปฏิบัติการ
- ทำซ้ำสกีมา ดัชนี และการแบ่งพาร์ติชันตามการใช้งานจริง
-
เปิดใจรับสถาปัตยกรรมผสม:
- ใช้หลายฐานข้อมูลถ้าส่วนต่าง ๆ ของระบบมีความต้องการต่างกันมาก
- บันทึกการตัดสินใจ ข้อแลกเปลี่ยน และรูปแบบในเอกสารภายในของคุณ (เช่น
/docs/architecture/datastores)
สำหรับการอ่านเชิงลึกเพิ่มเติม ขยายภาพรวมนี้ด้วยมาตรฐานภายใน ตารางเช็คลิสต์การย้าย และการอ่านเพิ่มใน handbook วิศวกรรมหรือ /blog.
คำถามที่พบบ่อย
What is the core difference between SQL and NoSQL databases?
SQL (เชิงสัมพันธ์):
- ใช้ตารางที่มีแถวและคอลัมน์
- บังคับสกีมาคงที่ (ระบุคอลัมน์ ชนิดข้อมูล ข้อจำกัด)
- ใช้ SQL เป็นภาษาสืบค้นมาตรฐาน
- เน้นธุรกรรมแบบ ACID และความสอดคล้องที่เข้มงวด
NoSQL (ไม่เชิงสัมพันธ์):
- ใช้โมเดลยืดหยุ่น (เอกสาร, คีย์‑ค่า, wide‑column, กราฟ)
- มักอนุญาตข้อมูลแบบยืดหยุ่นหรือไม่มีสกีมา
- ใช้อินเทอร์เฟซสืบค้นหรือ DSL เฉพาะฐานข้อมูล
- มักแลกความสอดคล้องบางส่วนเพื่อความสามารถในการปรับขนาดและความพร้อมใช้งาน
When is an SQL database usually the better choice?
ใช้ SQL เมื่อต้องการ:
- ข้อมูลมีโครงสร้างชัดเจนและเชิงสัมพันธ์ (ผู้ใช้ คำสั่ง ใบแจ้งหนี้)
- ต้องการธุรกรรม ACID ข้ามหลายแถวหรือหลายตาราง
- ความถูกต้องและความสอดคล้องสำคัญกว่าความเร็วล้วนๆ
- คาดว่าจะมีการสืบค้น ad‑hoc จำนวนมาก การ JOIN และงานรายงาน
- ต้องการการปฏิบัติตามกฎระเบียบ, การตรวจสอบ และการบำรุงรักษาระยะยาว
สำหรับระบบบันทึกข้อมูลธุรกิจใหม่ๆ ส่วนใหญ่ SQL เป็นตัวเลือกเริ่มต้นที่เหมาะสม
When is a NoSQL database usually the better choice?
NoSQL เหมาะเมื่อ:
- ต้องการสเกลการเขียนและพื้นที่จัดเก็บแบบแนวนอนข้ามหลายโหนด
- ข้อมูลเป็นกึ่งมีโครงสร้าง มีเนสติ้ง หรือเปลี่ยนรูปแบบบ่อย
- รูปแบบการเข้าถึงชัดเจนและออกแบบรอบการค้นหาแบบคีย์/เอกสารได้
- ยอมรับความไม่สอดคล้องชั่วคราวได้ (เช่น ฟีด บันทึก มุมมองเชิงวิเคราะห์)
- จัดการข้อมูล IoT, time‑series, แคช หรือต้นฉบับที่ผู้ใช้สร้างในระดับใหญ่
How do schemas and data modeling differ between SQL and NoSQL?
SQL databases:
- ใช้สกีมาที่กำหนดไว้ล่วงหน้า; ทุกแถวต้องตรงตามโครงสร้างตาราง
- ส่งเสริมการทำ normalization เพื่อลดการซ้ำซ้อนและบังคับความสมบูรณ์ของข้อมูล
- ใช้ foreign keys และ constraints ในการจัดการความสัมพันธ์
NoSQL databases:
- อนุญาตให้เอกสาร/ระเบียนแต่ละชิ้นมีฟิลด์ต่างกันภายในคอลเลกชันเดียวกัน
- มักส่งเสริมการ denormalization และการฝังข้อมูลที่เกี่ยวข้อง
- แอปพลิเคชันมีบทบาทมากขึ้นในการบังคับกฎข้อมูล
นั่นหมายความว่าการควบคุมสกีมาเปลี่ยนจากฐานข้อมูล (SQL) ไปอยู่ที่แอปพลิเคชัน (NoSQL)
How do SQL and NoSQL differ in consistency and transactions?
SQL databases:
- มุ่งเน้นธุรกรรม ACID พร้อมความสอดคล้องที่เข้มงวด
- เหมาะเมื่อการอ่านต้องเห็นสถานะที่ถูกต้องเป็นปัจจุบันเสมอ
Many NoSQL systems:
- ให้ความสำคัญกับความพร้อมใช้งานและความทนต่อการแบ่งพาร์ติชัน
- ใช้แนวคิด BASE และ eventual consistency: สำเนาจะสอดคล้องกันเมื่อเวลาผ่านไป
- อาจมีการปรับแต่งระดับความสอดคล้องต่อการทำงานหรือพาร์ติชัน
เลือก SQL เมื่อการอ่านข้อมูลล้าสมัยเป็นสิ่งอันตราย; เลือก NoSQL เมื่อยอมรับความล้าสมัยชั่วคราวเพื่อแลกกับสเกลและความพร้อมใช้งาน
How do SQL and NoSQL databases usually scale?
SQL databases มักจะ:
- เริ่มจากการสเกลแนวตั้ง (เซิร์ฟเวอร์ตัวเดียวที่ทรงพลังขึ้น)
- เพิ่ม read replicas เพื่อสเกลการอ่าน
- บางครั้งใช้ sharding หรือ distributed SQL เพื่อสเกลออก
NoSQL databases มักจะ:
- ออกแบบมาสำหรับการสเกลแนวนอนตั้งแต่ต้น
- แบ่งข้อมูลเป็นชาร์ดหรือพาร์ติชันข้ามหลายโหนด
- เพิ่มความจุด้วยการเพิ่มโหนดทั่วไปได้ง่าย
ข้อแลกเปลี่ยนคือคลัสเตอร์ NoSQL ดูแลจัดการซับซ้อนขึ้น ในขณะที่ SQL อาจถึงขีดจำกัดของเครื่องเดียวได้เร็วกว่า
Can I use SQL and NoSQL together in the same system?
ใช่. Polyglot persistence เป็นเรื่องปกติ:
- ใช้ SQL เป็นระบบบันทึกหลัก (payments, accounts, core entities)
- เพิ่ม NoSQL สำหรับ sessions, แคช, ฟีด, บันทึก หรือการค้นหา
รูปแบบการรวมข้อมูลรวมถึง:
- Change data capture หรือ event streams จาก SQL ไปยัง NoSQL
- งาน ETL เป็นช่วง ๆ เพื่อสร้างมุมมองสำหรับการอ่าน
- บริการที่ซ่อนที่เก็บข้อมูลภายใน API เพื่อให้บริการไม่ต้องรู้ว่าข้อมูลอยู่ที่ไหน
กุญแจคือเพิ่มแต่ละ datastore เมื่อมันแก้ปัญหาได้ชัดเจน
How should I approach migrating between SQL and NoSQL?
เพื่อลดความเสี่ยง:
- ระบุบริบทจำกัด (เช่น product catalog) ที่จะย้าย
- ออกแบบข้อมูลรอบรูปแบบการเข้าถึงใหม่ ไม่ใช่การแปะตารางเดิมเป็นเอกสาร
- ใช้ dual writes หรือ CDC เพื่อให้ทั้งสองระบบซิงก์กันชั่วคราว
- ยืนยันความถูกต้องของข้อมูลระหว่างสโตร์และวางแผนการ backfill ที่ทำซ้ำได้
- ย้ายทราฟฟิกทีละน้อย โดยเตรียม rollback ไว้
หลีกเลี่ยงการย้ายแบบ big‑bang; ทำแบบเพิ่มทีละส่วนและมอนิเตอร์อย่างใกล้ชิด
What factors should I evaluate when choosing between SQL and NoSQL?
พิจารณา:
- โครงสร้างข้อมูล: ตารางเชิงสัมพันธ์ชัดเจน vs เอกสาร/เหตุการณ์ที่ยืดหยุ่น
- ความต้องการความสอดคล้อง: ACID เข้มงวด vs ยอมรับความล้าสมัยได้
- การสเกลและความหน่วง: ปริมาณการเขียน ค่าความเร็วทั่วโลก
- รูปแบบการสืบค้น: การ JOIN และการวิเคราะห์ ad‑hoc vs การค้นหาแบบคีย์/เอกสารที่คาดการณ์ได้
- ทักษะทีมและเครื่องมือ: ทีมคุ้นเคยอะไรบ้าง
- ค่าใช้จ่ายและการปฏิบัติการ: ตัวเลือกแบบ managed vs รันคลัสเตอร์กระจาย
สร้างโปรโตไทป์ทั้งสองตัวสำหรับฟลูว์สำคัญแล้ววัดความหน่วง ผลตอบแทน และความซับซ้อนก่อนตัดสินใจ
What are some common myths about SQL vs NoSQL databases?
ความเข้าใจผิดที่พบบ่อย:
- “NoSQL จะเข้ามาแทนที่ SQL” – ในความเป็นจริงทั้งสองเติมเต็มกัน
- “SQL ไม่สามารถสเกลแนวนอนได้” – ระบบสมัยใหม่รองรับ replicas, sharding, และ distributed SQL
- “NoSQL ไม่มีสกีมา” – แปลว่าแอปตรวจสอบสกีมา; โครงสร้างยังมีอยู่แต่บังคับโดยแอปหรือ validator
- “แบบใดแบบหนึ่งเร็วกว่าตลอดเวลา” – ประสิทธิภาพขึ้นกับการออกแบบข้อมูล ดัชนี และรูปแบบงาน
ประเมินผลิตภัณฑ์และสถาปัตยกรรมเฉพาะ ไม่ใช่พึ่งพาตำนานบนระดับหมวดหมู่