29 มิ.ย. 2568·5 นาที
สร้างเว็บแอปสำหรับรายงานรวมจากหลายเครื่องมือ
เรียนรู้วิธีออกแบบ สร้าง และปล่อยเว็บแอปที่ดึงข้อมูลจากหลายเครื่องมือมาเป็นศูนย์รายงานเดียว—ปลอดภัย เชื่อถือได้ และใช้งานง่าย
เรียนรู้วิธีออกแบบ สร้าง และปล่อยเว็บแอปที่ดึงข้อมูลจากหลายเครื่องมือมาเป็นศูนย์รายงานเดียว—ปลอดภัย เชื่อถือได้ และใช้งานง่าย
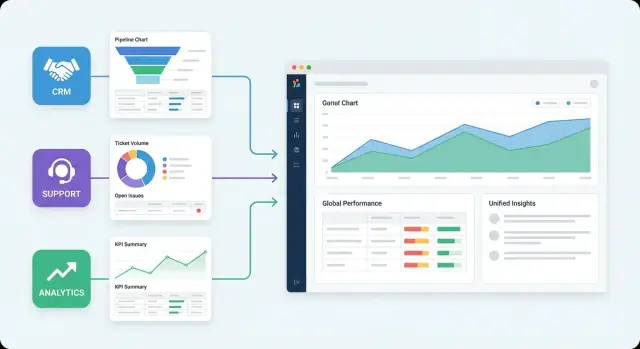
การรายงานแบบศูนย์กลางหมายถึงการดึงข้อมูลจากเครื่องมือที่คุณใช้แล้ว (CRM, บิลลิ่ง, การตลาด, ฝ่ายสนับสนุน, การวิเคราะห์ผลิตภัณฑ์) มาที่จุดเดียวที่ทุกคนสามารถดูตัวเลขเดียวกัน—มีความหมายเหมือนกัน—บนแดชบอร์ดที่อัพเดตตามตารางเวลา
ในการใช้งานจริง มันมาแทนที่ "การแข่งขันส่งต่อสเปรดชีต" ด้วยระบบที่ใช้ร่วมกัน: คอนเนคเตอร์ดึงข้อมูลเข้ามา โมเดลทำให้เป็นมาตรฐาน และแดชบอร์ดตอบคำถามซ้ำ ๆ โดยไม่ต้องมีคนมาสร้างรายงานใหม่ทุกสัปดาห์
ทีมส่วนใหญ่สร้างแอปรายงานด้วยเหตุผลเดียวกัน:
การรวมศูนย์ยังช่วยเพิ่มความรับผิดชอบ: เมื่อคำนิยามเมตริกอยู่ในที่เดียว จะง่ายขึ้นในการสังเกตว่าตัวเลขเปลี่ยนแปลงและทำไม
เมื่อคุณรวมแหล่งข้อมูลได้ คุณสามารถตอบคำถามที่แดชบอร์ดของเครื่องมือเดียวทำไม่ได้ เช่น:
แอปรายงานศูนย์กลางไม่สามารถแก้ปัญหาที่ต้นทางได้:
เป้าหมายไม่ใช่ข้อมูลสมบูรณ์แบบในวันแรก แต่มันคือวิธีที่สอดคล้อง ทำซ้ำได้ เพื่อปรับปรุงการรายงานเมื่อเวลาผ่านไปพร้อมกับลดแรงเสียดทานประจำวันในการหาคำตอบ
การรายงานแบบศูนย์กลางทำงานได้ก็ต่อเมื่อออกแบบรอบการตัดสินใจจริง ๆ ก่อนจะเลือกเครื่องมือหรือเขียนคอนเนคเตอร์ ให้ชัดว่าระบบนี้สำหรับใคร พวกเขาต้องการรู้อะไร และจะรู้ได้อย่างไรว่าโครงการสำเร็จ
แอปรายงานส่วนใหญ่ให้บริการหลายกลุ่ม ระบุชื่อและเขียนลงไปว่ากลุ่มแต่ละกลุ่มต้องการทำอะไรกับข้อมูล:
ถ้าคุณอธิบายแดชบอร์ดไม่ออกเป็นประโยคเดียวสำหรับแต่ละกลุ่ม คุณยังไม่พร้อมจะสร้าง
เก็บ “Top 10” คำถามที่คนถามซ้ำ ๆ และผูกแต่ละคำถามกับการตัดสินใจ ตัวอย่าง:
รายการนี้จะกลายเป็น backlog ของคุณ ทุกอย่างที่ไม่เกี่ยวข้องกับการตัดสินใจเป็นผู้สมัครสำหรับการเลื่อนออกไป
เลือกผลลัพธ์ที่วัดได้:
เขียนลงไปว่าอะไรอยู่ในและนอก: เครื่องมือไหน ทีมไหน ช่วงเวลาที่รองรับ (เช่น ย้อนหลัง 24 เดือน) นี่จะป้องกันไม่ให้โปรเจกต์รายงานกลายเป็นงานผสานข้อมูลไม่รู้จบ
หมายเหตุการวางแผน: ตั้งเป้าสำหรับแผนการสร้างขั้นสุดท้ายที่รองรับคำแนะนำการใช้จริงยาวราว 3,000 คำ—ละเอียดพอจะลงมือทำ แต่สั้นพอที่จะคงโฟกัส
ก่อนออกแบบ pipeline หรือแดชบอร์ด ให้ชัดว่าคุณมีข้อมูลอะไรจริง ๆ และดึงมาได้เชื่อถือได้แค่ไหน สิ่งนี้ป้องกันความล้มเหลวสองอย่างที่พบบ่อย: สร้างรายงานบน “source of truth” ผิดตัว และค้นพบช้าตอนท้ายว่าระบบสำคัญส่งออกได้แค่ CSV รายเดือน
เริ่มแม็ปแต่ละโดเมนธุรกิจกับเครื่องมือที่ควรเป็น “ผู้ชนะ” เมื่อจำนวนไม่ตรงกัน
เขียนสิ่งนี้ลงอย่างชัดเจน มันจะช่วยประหยัดเวลาระหว่างการโต้วาทีเมื่อผู้มีส่วนได้ส่วนเสียเห็นเมตริกข้าง ๆ กัน
สำหรับทุกเครื่องมือ ให้บันทึกวิธีจริงจังในการดึงข้อมูล:
ข้อจำกัดกำหนดความถี่การรีเฟรช กลยุทธ์ backfill และแม้แต่เมตริกที่เป็นไปได้
ระบุสิ่งที่ต้องใช้เพื่อเชื่อมต่ออย่างปลอดภัย:
เก็บข้อมูลรับรองใน secrets manager (ไม่ควรอยู่ในโค้ดหรือการตั้งค่าบนแดชบอร์ด)
ทำตารางเรียบง่าย: source → entities → fields ที่ต้องการ → ความถี่การรีเฟรช ตัวอย่าง: “Zendesk → tickets → created_at, status, assignee_id → ทุก 15 นาที” เมทริกซ์นี้จะเป็นเช็คลิสต์การสร้างและการควบคุมขอบเขตเมื่อคำขอเพิ่มขึ้น
การตัดสินใจนี้กำหนดความรู้สึก “เรียลไทม์” ของตัวเลข ความถี่ที่รายงานพัง และค่าใช้จ่ายด้านโครงสร้างพื้นฐานและการใช้ API ทีมส่วนใหญ่ใช้แบบผสม แต่คุณยังต้องมีค่าเริ่มต้นที่ชัดเจน
1) Live queries (ดึงตามคำขอ)
แอปจะเรียก API ของแต่ละเครื่องมือเมื่อผู้ใช้โหลดแดชบอร์ด
2) Scheduled pipelines (ETL/ELT ไปที่ storage ของคุณ)
คุณคัดลอกข้อมูลตามรอบเวลา (เช่น ทุกชั่วโมง/กลางคืน) แล้วแดชบอร์ดจะคิวรีฐานข้อมูล/warehouse ของคุณเอง
ตำแหน่งของ ETL vs. ELT:
3) Hybrid (scheduled + live/near-real-time เฉพาะส่วน)
ชุดข้อมูลหลักเป็น scheduled แต่ widget ร้อนบางรายการ (เช่น ค่าใช้จ่ายวันนี้ เหตุการณ์เชิงรุก) ใช้ live queries หรือซิงก์บ่อยกว่า
ความสดไม่ฟรี: ใกล้เรียลไทม์มากขึ้นยิ่งจ่ายใน API calls, caching, และการจัดการความล้มเหลว Scheduled ingestion มักเป็นพื้นฐานที่เสถียรที่สุดสำหรับผลิตภัณฑ์รายงาน โดยเฉพาะเมื่อผู้ใช้คาดหวังแดชบอร์ดโหลดเร็วทุกครั้ง
สำหรับทีมส่วนใหญ่: เริ่มด้วย scheduled ELT (โหลดดิบ + ปรับโครงสร้างแบบเบา จากนั้นแปลงเป็นเมตริก) และ เพิ่ม near-real-time เฉพาะเมตริกมูลค่าสูงไม่กี่ตัว.
เลือก Live Queries ถ้า:
เลือก Scheduled ETL/ELT ถ้า:
เลือก Hybrid ถ้า:
แอปรายงานศูนย์กลางสำเร็จหรือล้มเหลวด้วยสองสิ่ง: โมเดลข้อมูลที่เข้าใจได้ และเมตริกที่มีความหมายเหมือนกันทุกที่ ก่อนสร้างแดชบอร์ด ให้กำหนด "คำนามทางธุรกิจ" และคณิตศาสตร์ที่แน่นอนของ KPI
เริ่มด้วยคำศัพท์ร่วมที่เรียบง่าย เอนทิตีทั่วไปได้แก่:
ตัดสินใจว่าแต่ละระบบเป็น source of truth สำหรับเอนทิตีนั้น ๆ (เช่น billing สำหรับ invoices, CRM สำหรับ deals) โมเดลของคุณควรสะท้อนความเป็นเจ้าของนั้น
การรายงานข้ามเครื่องมือต้องการคีย์ที่เชื่อถือได้ เรียงการ join ดังนี้:
ลงทุนทำตารางแม็ปตั้งแต่ต้น—มันเปลี่ยนจาก “ยุ่งแต่พอใช้” เป็น “ทำซ้ำและตรวจสอบได้”
เขียนคำนิยามเมตริกเหมือนข้อกำหนดผลิตภัณฑ์: ชื่อ สูตร ตัวกรอง เกรน และกรณีขอบ เช่น:
มอบเจ้าของคนเดียว (การเงิน, revops, analytics) ที่อนุมัติการเปลี่ยนแปลง
เลือกค่าเริ่มต้นและบังคับใช้ในชั้นคิวรี:
ปฏิบัติตรรกะเมตริกเสมือนโค้ด: เวอร์ชันมัน ใส่วันที่มีผล และเก็บ changelog สั้น ๆ (“MRR v2 ยกเว้นค่าธรรมเนียมครั้งเดียวตั้งแต่ 2025-01-01”) นี่ป้องกันความสับสนเมื่อแดชบอร์ดเปลี่ยนและทำให้ง่ายต่อการตรวจสอบ
แอปรายงานศูนย์กลางน่าเชื่อถือแค่ไหนขึ้นอยู่กับ pipeline คิดว่าคอนเนคเตอร์แต่ละตัวเป็นผลิตภัณฑ์เล็ก ๆ: ต้องดึงข้อมูลสม่ำเสมอ ทำให้มีรูปแบบที่คาดการณ์ได้ และโหลดอย่างปลอดภัย—ทุกครั้ง
การดึงควรชัดเจนเกี่ยวกับ สิ่งที่ ขอ (endpoints, fields, time ranges) และ วิธี ยืนยันตัวตน ทันทีที่ดึงข้อมูลให้ตรวจสอบสมมติฐานพื้นฐาน (IDs ที่ต้องมีอยู่, timestamps แปลงได้, อาร์เรย์ไม่ว่างโดยไม่คาดคิด)
Normalization คือที่ที่คุณทำให้ข้อมูลใช้ร่วมกันได้: มาตรฐาน:
account_id)สุดท้าย โหลดเข้า storage ของคุณในแบบที่รองรับการรันซ้ำอย่างปลอดภัยและการคิวรีที่เร็ว
ทีมส่วนใหญ่รันคอนเนคเตอร์สำคัญทุกชั่วโมงและแหล่งข้อมูลที่เหลือรายวัน ถนัด incremental syncs (เช่น updated_since หรือ cursor) เพื่อให้งานเร็ว แต่ต้องออกแบบรองรับ backfills เมื่อกฎแม็ปเปลี่ยนหรือ API ผู้ขายล่ม
รูปแบบปฏิบัติ:
คาดพบ pagination, rate limits, และความล้มเหลวบางส่วน ใช้ retries พร้อม exponential backoff แต่ทำให้การรัน idempotent: payload เดิมประมวลผลสองครั้งไม่ควรสร้างระเบียนซ้ำ Upserts โดยใช้ external ID เสถียรมักได้ผลดี
เก็บ raw responses (หรือตารางดิบ) ข้าง ๆ ตารางที่ทำความสะอาด เมื่อเลขในแดชบอร์ดผิด ดิบจะช่วยให้คุณตามรอยได้ว่า API ส่งอะไรมาและการแปลงไหนเปลี่ยนมัน
Storage คือที่ที่การรายงานศูนย์กลางจะสำเร็จหรือไม่ คำตอบที่ “ถูก” ขึ้นกับการคิวรี: อ่านบ่อย ๆ จากแดชบอร์ด, การรวมที่หนัก, ประวัติยาว และจำนวนผู้ใช้พร้อมกัน
ฐานข้อมูลสัมพันธ์เหมาะเมื่อแอปยังใหม่และ dataset ปานกลาง คุณได้ความสอดคล้องที่แข็งแรง การทำโมเดลตรงไปตรงมา และประสิทธิภาพคาดการณ์ได้สำหรับคิวรีที่กรอง
ใช้เมื่อคาดว่า:
วางแผนสำหรับ pattern การรายงานทั่วไป: index โดย (org_id, date) และฟิลด์ที่กรองแรง เช่น team_id หรือ source_system ถ้าคุณเก็บเหตุการณ์เหมือน facts ให้พิจารณา partition ตามเดือนตามวันที่เพื่อลดขนาด index และจัดการ vacuum/maintenance
Warehouse ถูกสร้างมาสำหรับงานวิเคราะห์: การสแกนขนาดใหญ่ join ใหญ่ และผู้ใช้หลายคนรีเฟรชแดชบอร์ดพร้อมกัน ถ้าแอปของคุณต้องการประวัติหลายปี เมตริกซับซ้อน หรือการสำรวจแบบ slice-and-dice warehouse มักคุ้มค่า
เคล็ดลับการโมเดล: เก็บตาราง fact แบบ append-only (เช่น usage_events) และตารางมิติ (orgs, teams, tools) และสตandardize คำนิยามเมตริกเพื่อให้แดชบอร์ดไม่ต้องทำตรรกะซ้ำ
Partition ตามวันที่และ cluster/sort โดยฟิลด์ที่กรองบ่อย (org/team) เพื่อลดค่า scan และเร่งคิวรีที่ใช้บ่อย
Lake ดีสำหรับเก็บข้อมูลดิบและประวัติโดยคุ้มค่า โดยเฉพาะเมื่อต้อง ingest หลายแหล่งหรือจำเป็นต้อง replay การแปลง
แยกตัว lake ไม่นำไปสู่การรายงานได้ทันที มักจับคู่กับ query engine หรือ warehouse layer สำหรับแดชบอร์ด
ต้นทุนมักถูกขับเคลื่อนโดย compute (ความถี่การรีเฟรชของแดชบอร์ด จำนวนข้อมูลที่แต่ละคิวรีสแกน) มากกว่าพื้นที่เก็บ คิวรีประวัติทั้งหมดบ่อย ๆ แพง; ออกแบบสรุป (daily/weekly rollups) เพื่อให้แดชบอร์ดเร็ว
กำหนดนโยบายการเก็บรักษาแต่เนิ่น ๆ: เก็บตารางเมตริก curated ให้ hot (เช่น 12–24 เดือน) และเก็บข้อมูลดิบเก่าลง lake เพื่อการปฏิบัติตามและ backfills สำหรับการวางแผนเชิงลึก ดู /blog/data-retention-strategies.
Backend ของคุณคือสัญญาระหว่างข้อมูลรกที่เปลี่ยนแปลงและรายงานที่ผู้คนเชื่อถือ ถ้ามันสม่ำเสมอและคาดเดาได้ UI จะเรียบง่าย
เริ่มจากบริการ "ที่ต้องมี" เล็ก ๆ:
/api/query, /api/metrics)ทำให้ชั้นคิวรีมีความเห็นชอบ: รับตัวกรองจำกัด (ช่วงวันที่, มิติ, เซกเมนต์) และปฏิเสธสิ่งที่จะกลายเป็นการรัน SQL แบบสุ่ม
การรายงานศูนย์กลางล้มเหลวเมื่อ "Revenue" หรือ "Active Users" หมายต่างกันในทุกแดชบอร์ด
ติดตั้ง semantic/metrics layer ที่นิยาม:
เก็บนิยามเหล่านี้ใน config ที่มีเวอร์ชัน (ตารางฐานข้อมูลหรือไฟล์ใน git) เพื่อให้การเปลี่ยนแปลงตรวจสอบได้และย้อนคืนได้
แดชบอร์ดมักเรียกคิวรีซ้ำ วางแผน caching ตั้งแต่เนิ่น ๆ:
จะทำให้ UI เร็วโดยไม่ปกปิดความสดของข้อมูล
เลือกระหว่าง:
เลือกแล้วต้องบังคับ scoping ของ tenant ในชั้นคิวรี — ไม่ใช่ที่ frontend
การสนับสนุนจาก backend ทำให้รายงานนำไปใช้ได้จริง:
ออกแบบฟีเจอร์เหล่านี้ให้เป็นความสามารถ API ชั้นหนึ่งเพื่อให้ใช้งานได้ทุกที่ที่รายงานปรากฏ
ถ้าต้องส่งของภายในไม่กี่สัปดาห์ ให้พิจารณาทำต้นแบบ UI และ API ใน Koder.ai ก่อน มันเป็นแพลตฟอร์มสร้างโค้ดจากแชทที่สามารถสร้าง frontend React และ backend Go พร้อม PostgreSQL จากสเปครายงานแบบง่าย และรองรับโหมดวางแผน snapshots และ rollback—มีประโยชน์เมื่อคุณวนปรับสคีมาและตรรกะเมตริก ถ้าภายหลังต้องการย้ายออก คุณสามารถส่งออกซอร์สโค้ดและพัฒนาต่อใน pipeline ของคุณเอง
แอปรายงานศูนย์กลางสำเร็จหรือล้มเหลวที่ UI ถ้าแดชบอร์ดรู้สึกเหมือน "ฐานข้อมูลที่มีแผนภูมิ" ผู้คนจะยังส่งออกไปสเปรดชีต ออกแบบ frontend รอบคำถามที่ทีมถามจริง ๆ เทียบช่วงเวลา และติดตามความผิดปกติ
เริ่มจากการตัดสินใจที่คนทำ แถบนำทางชั้นบนที่ดีมักแม็ปกับคำถามที่คุ้นเคย: รายได้ การเติบโต การรักษาลูกค้า และสุขภาพฝ่ายสนับสนุน แต่ละส่วนมีแดชบอร์ดไม่กี่ชิ้นที่ตอบ "แล้วไง?" แทนการเททุกเมตริกที่คิดได้
ตัวอย่าง ส่วน Revenue โฟกัสที่ "เราเป็นอย่างไรเมื่อเทียบกับเดือนก่อน?" และ "อะไรเป็นตัวขับการเปลี่ยนแปลง?" แทนที่จะเปิดเผยตาราง invoice, customer, product ดิบ
การใช้งานรายงานมักเริ่มจากการจำกัดขอบเขต วางตัวกรองหลักในที่คงที่และใช้ชื่อเดียวกันข้ามแดชบอร์ด:
ทำให้ตัวกรองติดตาม (sticky) เมื่อผู้ใช้ย้ายหน้าจะได้ไม่ต้องสร้างบริบทใหม่ และชัดเจนว่าเวลาเป็นเขตเวลาอะไร และวันที่เป็นเวลาของเหตุการณ์หรืเวลาโปรเซส
แดชบอร์ดเพื่อสังเกต; drill-down เพื่อเข้าใจ รูปแบบปฏิบัติ:
สรุปเชิงภาพ → ตารางรายละเอียด → ลิงก์ไปยังระเบียนต้นทาง (ถ้ามี)
เมื่อ KPI พุ่ง ผู้ใช้ควรกดเห็นแถวพื้นฐาน (คำสั่งซื้อ ตั๋ว บัญชี) และกระโดดไปยังเครื่องมือต้นทางผ่านลิงก์สัมพัทธ์เช่น /records/123 (หรือ "view in source system" ถ้าคุณรักษาไว้) เป้าหมายคือ ลดเวลาที่ต้องถามทีมข้อมูล
การรายงานศูนย์กลางมักมีความล่าช้า—rate limits งานแบตช์ หรือแหล่งต้นทางล้ม Surface ความจริงนั้นใน UI:
องค์ประกอบเล็ก ๆ นี้ป้องกันความไม่ไว้วางใจและกระทู้ใน Slack ว่าตัวเลข "ผิด" หรือไม่
เพื่อรองรับแอปแดชบอร์ดเกินพิลอตขนาดเล็ก ให้เพิ่มฟีเจอร์ self-serve เบา ๆ:
Self-serve ไม่ใช่ "อะไรก็ได้" แต่หมายความว่าคำถามทั่วไปตอบได้ง่ายโดยไม่ต้องเขียนรายงานใหม่หรือสร้างแดชบอร์ดเฉพาะสำหรับทุกทีม
แอปรายงานศูนย์กลางสร้างความไว้วางใจแบบเดียวกับที่มันเสียไป: ตัวเลขงง ๆ ครั้งเดียว คุณภาพข้อมูลไม่ใช่สิ่งเสริมหลังจากส่งแดชบอร์ด—มันเป็นส่วนหนึ่งของผลิตภัณฑ์
เพิ่มการเช็คที่ขอบของ pipeline ก่อนข้อมูลถึงแดชบอร์ด เริ่มจากง่าย ๆ แล้วขยายเมื่อเรียนรู้รูปแบบข้อผิดพลาด
เมื่อการตรวจสอบล้มเหลว ให้ตัดสินใจว่าจะบล็อกการโหลด (สำหรับตารางสำคัญ) หรือกักกันแบตช์และมาร์กข้อมูลเป็นบางส่วนใน UI
ผู้คนจะถามว่า "ตัวเลขนี้มาจากไหน?" ทำให้คำตอบอยู่ใกล้เพียงคลิกเดียวโดยเก็บ metadata lineage:
metric → model/table → transformation → source connector → source field
สิ่งนี้มีค่ามากสำหรับการดีบักและการ on-board คนใหม่ และป้องกันการเบี่ยงของเมตริกเมื่อคนแก้สูตรโดยไม่เข้าใจผลกระทบ
ปฏิบัติเหมือน pipeline เป็นบริการ production บันทึกการรันทุกครั้งด้วย row counts, durations, ผลการตรวจสอบและ max timestamp ที่โหลด แจ้งเตือนเมื่อ:
ใน UI แสดงชัดเจน "Data last updated" และลิงก์ไปยังหน้า status เช่น /status.
ให้มุมมอง audit สำหรับแอดมินที่ติดตามการเปลี่ยนแปลงของคำนิยามเมตริก ตัวกรอง สิทธิ์ และการตั้งค่าคอนเนคเตอร์ รวม diffs และ actor (ผู้ใช้/บริการ) พร้อมช่อง "เหตุผล" สั้น ๆ สำหรับการแก้ไขโดยตั้งใจ
เขียน runbook สั้น ๆ สำหรับเหตุการณ์ทั่วไป: token หมดอายุ, โควต้า API เกิน, การเปลี่ยนสคีมา, และข้อมูล upstream ช้าระบุการตรวจสอบที่เร็วที่สุด เส้นทางการขึ้นเครือ และวิธีสื่อสารผลกระทบต่อผู้ใช้
แอปรายงานมักอ่านจากหลายเครื่องมือ (CRM, โฆษณา, สนับสนุน, การเงิน) นั่นทำให้ความปลอดภัยไม่ใช่แค่ฐานข้อมูลเดียว แต่เกี่ยวกับการควบคุมทุกขั้นตอน: การเข้าถึงต้นทาง การเคลื่อนย้ายข้อมูล การจัดเก็บ และสิ่งที่แต่ละคนเห็นใน UI
สร้างตัวตน "reporting" เฉพาะในแต่ละเครื่องมือ ติดสิทธิ์น้อยที่สุดที่จำเป็น (read-only, objects เฉพาะ, บัญชีเฉพาะ) และหลีกเลี่ยงการใช้ token admin ส่วนบุคคล หากคอนเนคเตอร์รองรับขอบเขตละเอียด ให้เลือกวิธีนั้น—แม้จะใช้เวลาตั้งค่ามากขึ้นก็ตาม
นำบทบาทการเข้าถึงตามบทบาท (RBAC) มาใช้ในแอปของคุณเพื่อให้สิทธิ์ชัดเจนและตรวจสอบได้ บทบาททั่วไป ได้แก่ Admin, Analyst, Viewer และตัวแปร "Business Unit"
ถ้าทีมต่าง ๆ ควรดูเฉพาะลูกค้าของตัวเอง ภูมิภาค หรือแบรนด์ ให้เพิ่มกฎระดับแถว (เช่น region_id IN user.allowed_regions) บังคับกฎเหล่านี้ที่ชั้นคิวรีฝั่งเซิร์ฟเวอร์—ไม่ใช่แค่ซ่อนในแดชบอร์ด
เก็บ API keys และ OAuth refresh tokens ใน secrets manager (หรือเข้ารหัสเมื่อเก็บถ้านั่นเป็นทางเดียว) อย่าส่งความลับไปยังเบราว์เซอร์ สร้างกระบวนการหมุนเวียน: credential ที่หมดอายุควรล้มเหลวพร้อมการแจ้งเตือนชัดเจน ไม่ใช่ช่องว่างข้อมูลเงียบ ๆ
ใช้ TLS ทุกที่: เบราว์เซอร์ → backend, backend → แหล่งข้อมูล, และ backend → storage เปิดการเข้ารหัสที่เก็บเมื่อ stack รองรับ รวมถึงแบ็กอัพ
เขียนว่าคุณจัดการ PII อย่างไร: ฟิลด์อะไรที่ดึงมา วิธีการมาสก์หรือลดข้อมูล ผู้ใดเข้าถึงมุมมองดิบ vs. มุมมองสรุป กระบวนการรองรับคำขอลบ (ผู้ใช้/ลูกค้า) ที่ทำซ้ำได้ และเก็บบันทึกการเข้าถึงสำหรับเหตุการณ์การยืนยันตัวตนและการส่งออกรายงานที่มีความอ่อนไหว เพื่อให้การตรวจสอบเป็นไปได้
ส่งแอปรายงานไม่ใช่แค่ "go live" การรักษาความเชื่อถือเร็วคือการปฏิบัติกับ deployment และการปฏิบัติการเป็นส่วนหนึ่งของผลิตภัณฑ์: ปล่อยที่คาดการณ์ได้ ความคาดหวังชัดเจนเรื่องความสดของข้อมูล และจังหวะการบำรุงรักษาที่ป้องกันการพังเงียบ ๆ
ตั้งอย่างน้อยสามสภาพแวดล้อม:
สำหรับข้อมูลทดสอบ ชอบผสม: dataset ขนาดเล็กที่เวอร์ชันได้สำหรับการทดสอบเชิงกำหนด และชุดข้อมูล "สังเคราะห์แต่สมจริง" ที่ครอบคลุม edge cases (ค่าว่าง คืนเงิน ขอบเขตเขตเวลา)
เพิ่มการเช็คอัตโนมัตก่อน deploy ทุกครั้ง:
ถ้าคุณเผยแพร่นิยามเมตริก ให้ปฏิบัติกับมันเหมือนโค้ด: รีวิว เวอร์ชัน และ release notes
ระบบรายงานมักคอขวดในสามจุด:
ติดตามโควต้าของ API ต่อแหล่งด้วย หนึ่งแดชบอร์ดใหม่สามารถเพิ่มการเรียกหลายเท่า; ปกป้องแหล่งด้วยการ throttle คำขอและ incremental syncs
กำหนดความคาดหวังเป็นลายลักษณ์อักษร:
หน้า /status แบบภายในช่วยลดคำถามซ้ำในช่วง outage
วางแผนงานประจำ:
ถ้าต้องการจังหวะราบรื่น ให้กำหนด "data reliability" sprints ทุกไตรมาส—การลงทุนเล็ก ๆ ที่ป้องกันสงครามข้อมูลครั้งใหญ่ในอนาคต.
Centralized reporting ดึงข้อมูลจากหลายระบบ (CRM, บิลลิ่ง, การตลาด, ฝ่ายสนับสนุน, การวิเคราะห์ผลิตภัณฑ์) มาที่ที่เดียว ปรับนิยามให้เหมือนกัน และให้แดชบอร์ดอัพเดตตามตารางเวลา
มีไว้เพื่อทดแทนการส่งออกแบบ ad-hoc และสเปรดชีตชั่วคราวด้วย pipeline ที่ทำซ้ำได้ + ตรรกะเมตริกที่ใช้ร่วมกัน.
เริ่มด้วยการระบุผู้ใช้หลัก (leadership, ops, finance, sales, support, analysts) และรวบรวมคำถามซ้ำ ๆ สูงสุดที่ผูกกับการตัดสินใจ
ถ้าคุณอธิบุแดชบอร์ดไม่ได้ว่าแต่ละกลุ่มจะใช้เพื่อตอบคำถามอะไรในประโยคเดียว ให้ลดขอบเขตก่อนจะเริ่มสร้างอะไร.
กำหนดผลลัพธ์ที่วัดได้ เช่น:
เลือกไม่กี่ตัวและติดตามตั้งแต่พิลอตแรกเพื่อหลีกเลี่ยงสถานการณ์ "เราปล่อยแดชบอร์ด แต่ไม่มีใครใช้".
ใช้แผนผัง “source of truth by domain”: billing/ERP สำหรับรายได้, helpdesk สำหรับตั๋ว, CRM สำหรับ pipeline เป็นต้น
เมื่อจำนวนไม่ตรงกัน ให้มีผู้ชนะที่ตกลงกันไว้ล่วงหน้า—จะช่วยลดการโต้เถียงและป้องกันทีมจากการเลือกแดชบอร์ดที่พวกเขาชอบที่สุด.
Live queries จะเรียก API ภายนอกเมื่อโหลดแดชบอร์ด; scheduled ETL/ELT คัดลอกข้อมูลมาที่ storage ของคุณตามรอบเวลา; hybrid ผสมทั้งสอง
ทีมส่วนใหญ่ควรเริ่มด้วย scheduled ELT (โหลดข้อมูลดิบ แล้วแปลงเพื่อคำนวณเมตริก) และเพิ่ม near-real-time เฉพาะเมตริกมูลค่าสูงไม่กี่ตัวเท่านั้น.
Semantic (metrics) layer นิยามสูตร KPI, มิติที่อนุญาต, ตัวกรอง, ตรรกะเวลา และเก็บเวอร์ชันของนิยามเหล่านี้
มันป้องกันไม่ให้ "Revenue" หรือ "Active Users" ถูกคำนวณต่างกันในแต่ละแดชบอร์ด และทำให้การเปลี่ยนแปลงตรวจสอบย้อนหลังได้และย้อนคืนได้.
ลำดับการเชื่อม (join) ที่ควรใช้:
external_id)crm_account_id ↔ billing_customer_id)ลงทุนทำตารางแม็ปตั้งแต่ต้น—มันทำให้การรายงานข้ามเครื่องมือทำซ้ำได้และแก้ไขข้อผิดพลาดได้ง่ายขึ้น.
ออกแบบคอนเนคเตอร์ให้ idempotent และทนทาน:
updated_since/cursor) + backfills แบบจำกัดช่วงคาดว่า schema จะเปลี่ยนและมีความล้มเหลวเป็นบางส่วน; ออกแบบรองรับสิ่งเหล่านี้ตั้งแต่แรก.
เลือกตามรูปแบบการคิวรีและสเกล:
ค่าใช้จ่ายมักมาจาก compute (การสแกนข้อมูล) มากกว่าพื้นที่เก็บ; เพิ่ม rollups/summaries เพื่อให้แดชบอร์ดเร็ว.
การรวมศูนย์ไม่สามารถแก้ปัญหา upstream ได้ด้วยตัวเอง:
แอปรายงานจะทำให้ปัญหาเหล่านี้มองเห็นได้; คุณยังต้องมี governance, การติดตั้ง instrumentation และงานทำความสะอาดเพื่อปรับปรุงความถูกต้องเมื่อเวลาผ่านไป.