26 พ.ย. 2568·3 นาที
วิธีสร้างเว็บแอปเพื่อติดตามคอขวดการปฏิบัติงาน
คู่มือทีละขั้นตอนในการวางแผน ออกแบบ และส่งมอบเว็บแอปที่เก็บข้อมูลเวิร์กโฟลว์ ตรวจหาคอขวด และช่วยทีมแก้ไขความล่าช้า
เริ่มจากปัญหาและการตัดสินใจ
เว็บแอปติดตามกระบวนการจะช่วยได้ก็ต่อเมื่อตอบคำถามชัดเจน: “เราติดตรงไหน และต้องทำอะไรต่อ?” ก่อนจะร่างหน้าจอหรือเลือกสถาปัตยกรรมเว็บ ให้กำหนดความหมายของ “คอขวด” ในการปฏิบัติงานของคุณก่อน
กำหนดว่าคุณจะถือว่าอะไรเป็นคอขวด
คอขวดอาจเป็น ขั้นตอน (เช่น “ตรวจ QA”), ทีม (เช่น “ฝ่ายจัดส่ง”), ระบบ (เช่น “เกตเวย์ชำระเงิน”) หรือแม้แต่ ผู้ให้บริการ ภายนอก (เช่น “รับของจากผู้ให้บริการขนส่ง”) เลือกนิยามที่คุณจะจัดการจริงๆ ตัวอย่างเช่น:
- ขั้นตอนเป็นคอขวดเมื่อเวลาเฉลี่ยในคิวเกิน 24 ชั่วโมง
- ทีมเป็นคอขวดเมื่อ WIP สูงกว่าขีดจำกัดที่ตั้งไว้เป็นเวลา 3 วัน
- ระบบเป็นคอขวดเมื่อเหตุการณ์ทำให้เวลาทั้งกระบวนการพุ่งเกินช่วงที่ตกลงกันไว้
จดการตัดสินใจที่แอปต้องช่วยให้ทำได้
แดชบอร์ดปฏิบัติการควรกระตุ้นการลงมือทำ ไม่ใช่แค่รายงาน เขียนการตัดสินใจที่คุณอยากทำได้เร็วขึ้นและมั่นใจขึ้น เช่น:
- การจัดบุคลากร: “จะย้ายคนจากทีม A ไปทีม B สัปดาห์นี้ไหม?”
- การจัดลำดับความสำคัญ: “คำสั่งซื้อ/ตั๋วไหนควรขึ้นคิวเพื่อปกป้อง SLA?”
- การทำงานอัตโนมัติ: “ขั้นตอนไหนเสถียรพอ (และมีค่าใช้จ่ายสูงพอ) ที่จะทำเป็นอัตโนมัติก่อน?”
ระบุผู้ใช้หลักและสิ่งที่พวกเขาต้องการ
ผู้ใช้ต่างกันต้องการมุมมองต่างกัน:
- ผู้จัดการปฏิบัติการ ต้องการมุมมองชัดเจนว่า “ต้องแทรกแซงที่ไหนวันนี้”
- หัวหน้าทีม ต้องการเจาะลึกคิว รายการกีดขวาง และการส่งต่อ
- นักวิเคราะห์ ต้องการคำนิยามที่สม่ำเสมอและการส่งออกข้อมูลสำหรับการวิเคราะห์เวิร์กโฟลว์
ตั้งเมตริกความสำเร็จให้กับแอปเอง
ตัดสินใจว่าคุณจะรู้ว่าแอปใช้งานได้อย่างไร มาตรวัดที่ดีได้แก่การใช้งาน (ผู้ใช้ต่อสัปดาห์), เวลาที่ประหยัดจากการทำรายงาน, และการแก้ปัญหาเร็วขึ้น (ลดเวลาในการตรวจพบและแก้คอขวด) เมตริกเหล่านี้จะช่วยให้คุณมุ่งที่ผลลัพธ์ ไม่ใช่แค่ฟีเจอร์
เลือกเวิร์กโฟลว์และเขียนแผนผังกระบวนการง่ายๆ
ก่อนออกแบบตาราง แดชบอร์ด หรือการแจ้งเตือน ให้เลือกเวิร์กโฟลว์ที่อธิบายได้ในประโยคเดียว เป้าหมายคือการติดตามว่าหน้าที่ไหนรอ—เริ่มจากขนาดเล็กและเลือก หนึ่งหรือสองกระบวนการ ที่สำคัญและมีปริมาณสม่ำเสมอ เช่น การจัดส่งคำสั่งซื้อ, ตั๋วซัพพอร์ต, หรือการรับพนักงานเข้าใหม่
ขอบเขตที่ชัดเจนทำให้คำจำกัดความของงานเสร็จชัดเจน และป้องกันโครงการหยุดชะงักเพราะทีมต่างๆ ไม่เห็นด้วยว่ากระบวนการควรทำงานอย่างไร
เริ่มจาก 1–2 กระบวนการที่มีสัญญาณชัด
เลือกเวิร์กโฟลว์ที่:
- เกิดขึ้นบ่อย (มีข้อมูลเพียงพอให้เห็นรูปแบบ)
- ข้ามการส่งต่ออย่างน้อยหนึ่งครั้ง (ที่ที่มักเกิดคิว)
- มีผลกระทบต่อผู้ใช้ชัดเจน (เวลา ต้นทุน หรือความพึงพอใจ)
ตัวอย่าง: “ตั๋วซัพพอร์ต” มักดีกว่าคำว่า “customer success” เพราะมีหน่วยงานงานชัดเจนและการกระทำที่มีเวลาบันทึก
ทำแผนผังกระบวนการเป็นขั้นตอนและการส่งต่อด้วยภาษาง่ายๆ
เขียนเวิร์กโฟลว์เป็นรายการขั้นตอนโดยใช้คำที่ทีมใช้จริง คุณไม่ได้เขียนนโยบาย—คุณกำลังระบุ สถานะ ที่ไอเท็มจะเคลื่อนผ่าน
แผนผังกระบวนการแบบน้ำหนักเบาอาจเป็น:
- สร้างตั๋ว → จัดลำดับ → มอบหมาย → ตัวแทนกำลังทำงาน → รอข้อมูลลูกค้า → แก้ไขเสร็จ
ในขั้นตอนนี้ ให้ชี้ชัด การส่งต่อ (triage → assigned, agent → specialist ฯลฯ) เพราะการส่งต่อคือที่ที่เวลาในคิวมักซ่อนอยู่ และเป็นจุดที่คุณต้องวัดในภายหลัง
กำหนดเหตุการณ์เริ่ม/จบและ "เสร็จ" สำหรับแต่ละขั้นตอน
สำหรับแต่ละขั้น ให้เขียนสองอย่าง:
- เหตุการณ์เริ่ม (อะไรยืนยันว่าขั้นตอนเริ่ม?)
- เหตุการณ์จบ (อะไรยืนยันว่าขั้นตอนจบ?)
ทำให้สังเกตได้จริง “ตัวแทนเริ่มตรวจสอบ” มีความเห็นส่วนตัวได้; แต่ “สถานะเปลี่ยนเป็น In Progress” หรือ “เพิ่มบันทึกภายในครั้งแรก” จะติดตามได้
นอกจากนี้ กำหนดความหมายของ "เสร็จ" ให้ชัดเจนเพื่อไม่ให้แอปสับสนระหว่างการทำเสร็จบางส่วนกับการเสร็จจริง ตัวอย่างเช่น “resolved” อาจหมายถึง “ส่งข้อความแจ้งผลและตั้งตั๋วเป็น Resolved” ไม่ใช่แค่ “งานภายในเสร็จ”
จดข้อยกเว้นทั่วไปที่คุณจะติดตามตอนหลัง
การปฏิบัติงานจริงมักมีทางออกที่ยุ่งเหยิง: ต้องทำซ้ำ, การยกระดับ, ข้อมูลขาด, และการเปิดใหม่ อย่าพยายามโมเดลทุกอย่างในวันแรก—เพียง จดข้อยกเว้น เพื่อจะได้เพิ่มทีละอย่างอย่างมีเจตนาในภายหลัง
บันทึกง่ายๆ เช่น “10–15% ของตั๋วถูกยกระดับไปที่ Tier 2” ก็เพียงพอ คุณจะใช้บันทึกเหล่านี้ตัดสินว่าข้อยกเว้นควรเป็นขั้นตอนของตัวเอง แท็ก หรือฟลูว์แยกต่างหากเมื่อขยายระบบ
นิยามเมตริกที่เปิดเผยคอขวดจริงๆ
คอขวดไม่ใช่ความรู้สึก—มันคือความช้าที่ยังวัดได้ที่ขั้นตอนเฉพาะ ก่อนจะสร้างชาร์ต ให้ตัดสินใจว่าตัวเลขไหนจะพิสูจน์ว่าหน้าที่ไหลช้าและเพราะเหตุใด
เลือกชุดเมตริกแกนเล็กๆ
เริ่มจากสี่เมตริกที่ทำงานได้กับเวิร์กโฟลว์ส่วนใหญ่:
- Cycle time: เวลาที่ไอเท็มใช้ตั้งแต่ เริ่ม ถึง เสร็จ
- Wait/queue time: เวลาที่ไอเท็มนั่งเฉยๆ ระหว่างขั้นตอน
- Throughput: จำนวนไอเท็มที่เสร็จในช่วงเวลา
- WIP (work in progress): จำนวนไอเท็มที่อยู่ในระบบในขณะนั้น
เมตริกเหล่านี้ครอบคลุมความเร็ว (cycle), การนิ่งเฉย (queue), ผลลัพธ์ (throughput), และภาระงาน (WIP). ปัญหาความล่าช้าที่ไม่ชัดเจนมักปรากฏเป็น queue time และ WIP ที่เติบโตที่ขั้นตอนใดขั้นตอนหนึ่ง
กำหนดการคำนวณ (รวมกรณีพิเศษ)
เขียนคำนิยามที่ทั้งทีมตกลงกัน แล้วนำไปใช้ให้ตรงตามนั้น
- Cycle time =
done_timestamp − start_timestamp.- กรณีพิเศษ: ไอเท็มที่ถูกเปิดใหม่ (ตัดสินว่าจะถือเป็นรอบใหม่หรือขยายรอบเดิม), ไอเท็มที่ไม่เคยเริ่ม (ยกเว้นจากการคำนวณ cycle time แต่ยังนับใน WIP), การขาด timestamp (ติดธงเป็นคุณภาพข้อมูล)
- Queue time = ผลรวมของช่องว่างระหว่างขั้นตอนที่สถานะเป็น “waiting”.
- กรณีพิเศษ: กลางคืน/สุดสัปดาห์ (เวลาแบบปฏิทิน vs ชั่วโมงทำงาน), สถานะบล็อก (นับแยกจากการรอปกติถ้าต้องการระบุสาเหตุชัดขึ้น)
- Throughput = นับไอเท็มที่มี
done_timestampในหน้าต่างเวลาดังกล่าว.- กรณีพิเศษ: ยกเลิก (ยกเว้นหรือเก็บแยก), การทำงานที่เสร็จบางส่วน
- WIP = นับไอเท็มที่ไม่อยู่ในสถานะสิ้นสุด ณ จุดเวลาใดเวลาหนึ่ง
- กรณีพิเศษ: ไอเท็มรอ (ยังเป็น WIP แต่คุณอาจต้องการแยก “blocked WIP”)
เลือกการแยกข้อมูลที่ผลักดันการตัดสินใจ
เลือกมุมมองที่ผู้จัดการใช้จริง: ทีม, ช่องทาง, สายผลิตภัณฑ์, ภูมิภาค, และ ลำดับความสำคัญ จุดมุ่งหมายคือให้ตอบคำถามว่า “ช้าในที่ไหน สำหรับใคร และภายใต้เงื่อนไขใด?”
ตั้งหน้าต่างเวลาและเป้าหมาย
ตัดสินใจจังหวะการรายงานของคุณ (รายวันและรายสัปดาห์เป็นปกติ) และกำหนดเป้าหมาย เช่น ค่าเกณฑ์ SLA/SLO (ตัวอย่าง: “80% ของไอเท็มความสำคัญสูงเสร็จภายใน 2 วัน”) เป้าหมายทำให้แดชบอร์ดเป็นสิ่งที่ทำได้ ไม่ใช่แค่ของตกแต่ง
วางแหล่งข้อมูลและวิธีเก็บข้อมูล
วิธีที่เร็วที่สุดที่โครงการจะติดขัดคือคิดว่าข้อมูลจะ “มาเอง” ก่อนออกแบบตารางหรือชาร์ต จดว่าแต่ละเหตุการณ์และ timestamp จะมาจากไหน—และจะรักษาให้สม่ำเสมออย่างไร
สำรวจแหล่งข้อมูลที่มีอยู่แล้ว
ทีมปฏิบัติการส่วนใหญ่เก็บงานไว้ในไม่กี่ที่ จุดเริ่มต้นทั่วไปได้แก่:
- สเปรดชีตที่ใช้ในการส่งต่อ บันทึกรายวัน หรือการนับการผลิต
- ระบบ ERP/CRM (คำสั่งซื้อ ลูกค้า ขั้นตอนการปฏิบัติ)
- เครื่องมือบันทึกตั๋ว (คิวซัพพอร์ต, คำขอเปลี่ยนแปลง, งานบำรุงรักษา)
- ฐานข้อมูลภายใน (สแกนคลังสินค้า ตารางกำหนดงาน ข้อมูลการผลิต)
สำหรับแต่ละแหล่ง จดว่ามันให้อะไรได้: ID ระเบียนที่คงที่, ประวัติสถานะ (ไม่ใช่แค่สถานะปัจจุบัน), และอย่างน้อยสอง timestamp (เข้า/ออกขั้นตอน) หากไม่มีสิ่งนั้น การเฝ้าดู queue time และการติดตาม cycle time จะเป็นการเดา
เลือกวิธีจับข้อมูลที่เหมาะกับแหล่ง
โดยทั่วไปมีสามตัวเลือก และหลายแอปมักใช้ผสมกัน:
- API pull: การซิงก์ตามตารางจาก ERP/CRM/เครื่องมือตั๋ว ตรรกะเข้าใจง่าย แต่ต้องจัดการ pagination, rate limits และ incremental updates
- Webhooks: ส่งอัปเดตเมื่อสถานะงานเปลี่ยน ดีสำหรับการแจ้งเตือนใกล้เรียลไทม์ แต่ต้องออกแบบเรื่อง retry และเหตุการณ์มาที่ไม่เรียงลำดับ
- การป้อนข้อมูลด้วยมือ / นำเข้า CSV: เหมาะกับทีมที่เริ่มจากสเปรดชีตหรือกรณีพิเศษ ทำให้ปลอดภัยด้วยเทมเพลต การตรวจสอบความถูกต้อง และข้อความผิดพลาดที่ชัดเจน
วางแผนความถูกต้องของข้อมูล (เพราะมันจะเกิดขึ้น)
คาดว่าจะมี timestamp ขาดซ้ำซ้อน และสถานะไม่สอดคล้อง (“In Progress” vs “Working”). สร้างกฎตั้งแต่แรก:
- ให้ความสำคัญกับ immutable event log มากกว่าการเขียนทับเรคคอร์ด
- ลบรายการซ้ำโดยใช้ source ID + event time + status
- ทำให้สถานะเป็นมาตรฐานของแอปคุณ
- ติดธงเรคคอร์ดที่ไม่สามารถให้การติดตาม cycle time ได้เชื่อถือ
ตัดสินใจความถี่การรีเฟรช
ไม่ใช่ทุกกระบวนการต้องการอัปเดตเรียลไทม์ เลือกตามการตัดสินใจ:
- เรียลไทม์: การจัดส่ง, การคัดกรองซัพพอร์ต, ความเสี่ยง SLA
- รายชั่วโมง: ความสามารถคลังสินค้า, การเฝ้าดู queue time
- รายวัน: รายงานสัปดาห์และการทบทวนปรับปรุงต่อเนื่อง
เขียนมันลงตอนนี้ เพราะมันกำหนดกลยุทธ์ซิงก์ ค่าใช้จ่าย และความคาดหวังกับแดชบอร์ดของคุณ
ออกแบบโมเดลข้อมูลเพื่อการวิเคราะห์ตามเวลา
แอปติดตามคอขวดขึ้นหรือลงอยู่กับว่าคุณตอบคำถามด้านเวลาได้ดีแค่ไหน: “อันนี้ใช้เวลานานเท่าไร?”, “พักรอที่ไหน?”, “อะไรเปลี่ยนก่อนที่มันจะช้าลง?” วิธีที่ง่ายที่สุดในการรองรับคำถามเหล่านี้คือออกแบบข้อมูลรอบเหตุการณ์และ timestamp ตั้งแต่วันแรก
เริ่มจากเอนทิตีหลัก
เก็บโมเดลง่ายและชัดเจน:
- Process: เวิร์กโฟลว์โดยรวม (เช่น “Order Fulfillment”)
- Step: ขั้นตอนภายในกระบวนการ (เช่น “Pick”, “Pack”, “Ship”)
- Work item: หน่วยงานที่เคลื่อนผ่านขั้นตอน (ตั๋ว คำสั่งซื้อ เคลม)
- Event: การเปลี่ยนแปลงสถานะที่ถูกบันทึก (เข้า step, มอบหมาย, บล็อก, เสร็จ)
- User/Team และ Assignment: ใครเป็นผู้รับผิดชอบงานในช่วงเวลา
โครงสร้างนี้ให้คุณวัด cycle time ต่อขั้นตอน queue time ระหว่างขั้นตอน และ throughput ข้ามทั้งกระบวนการโดยไม่ต้องคิดกรณีพิเศษ
เลือก event log มากกว่าฟิลด์ “สถานะปัจจุบัน”
ปฏิบัติการทุกการเปลี่ยนสถานะเป็น immutable event record แทนจะเขียนทับ current_step และเสียประวัติ ให้เพิ่ม event เช่น:
- work_item_id
- from_step → to_step (หรือ “entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
คุณยังเก็บ snapshot สถานะปัจจุบันเพื่อความเร็วได้ แต่การวิเคราะห์ควรพึ่งพา event log
ทำให้เวลาจับตามองและการติดตามต้นทางเป็นเรื่องไม่ต่อรอง
เก็บ timestamp เป็น UTC อย่างสม่ำเสมอ และเก็บ ตัวระบุแหล่งเดิม (เช่น Jira issue key, ERP order ID) บน work items และ events เพื่อให้ทุกชาร์ตสามารถตรวจย้อนกลับเป็นเรคคอร์ดจริงได้
เก็บข้อยกเว้นโดยไม่สร้างงานเยอะ
วางฟิลด์น้ำหนักเบาสำหรับช่วงเวลาที่อธิบายความล่าช้าได้:
- reason_code (ตัวเลือกมาตรฐาน เช่น “Waiting on customer”)
- comment (ข้อความเลือกใส่)
- blocked_flag หรือ severity
ทำให้เป็นฟิลด์ที่ไม่บังคับและง่ายกรอก เพื่อเรียนรู้จากข้อยกเว้นโดยไม่เปลี่ยนแอปให้เป็นแบบฟอร์มยาวๆ
เลือกสถาปัตยกรรมที่เหมาะกับทีมของคุณ
สร้างต้นแบบแอปติดตามคอขวด
อธิบายเวิร์กโฟลว์ในแชท แล้วได้แอป React + Go + Postgres ที่ใช้งานได้จริง
“สถาปัตยกรรมที่ดีที่สุด” คือสิ่งที่ทีมคุณสร้าง เข้าใจ และดูแลได้เป็นปีๆ เริ่มจากสแตกที่ตรงกับทักษะการจ้างและทักษะที่มี ตัวเลือกที่ใช้กันทั่วไปได้แก่ React + Node.js, Django, หรือ Rails ความสม่ำเสมอกลบความใหม่เมื่อต้องดูแลแดชบอร์ดปฏิบัติการที่คนพึ่งพาทุกวัน
แยกความรับผิดชอบเพื่อให้ระบบแก้ไขได้ง่าย
แอปติดตามคอขวดมักทำงานดีกว่าเมื่อแยกเป็นเลเยอร์ชัดเจน:
- Ingestion: รับเหตุการณ์ (การเปลี่ยนสถานะ, timestamp, การส่งต่อ) จากฟอร์ม การเชื่อมต่อ หรือการนำเข้า
- Storage: ฐานข้อมูลเชิงธุรกรรมสำหรับการเขียนที่เชื่อถือได้และประวัติการตรวจสอบ
- Analytics queries: คิวรีที่ปรับให้อ่านได้เร็วเพื่อคำนวณ cycle time, queue time, throughput
- UI/API: เอ็นด์พอยต์และหน้าจอที่ทำให้แดชบอร์ดเร็วและคาดเดาได้
การแยกนี้ทำให้คุณเปลี่ยนส่วนหนึ่งได้โดยไม่ต้องเขียนใหม่ทั้งหมด (เช่น เพิ่มแหล่งข้อมูลใหม่)
ตัดสินใจว่าการคำนวณควรอยู่ที่ไหน
เมตริกบางอย่างคำนวณง่ายพอในคิวรีฐานข้อมูล (เช่น “ค่าเฉลี่ย queue time ตามขั้น 7 วันที่ผ่านมา”) อันอื่นหนักหรือต้อง preprocess (เช่น percentile, การตรวจจับความแปลก, cohort รายสัปดาห์). กฎปฏิบัติที่เป็นประโยชน์:
- ทำ ฟิลเตอร์และการแยกแบบเรียลไทม์ ในฐานข้อมูล
- ใช้ background jobs เพื่อคำนวน aggregate หนักๆ และเก็บไว้โหลดแดชบอร์ดได้เร็ว
- เพิ่ม layer วิเคราะห์ ก็ต่อเมื่อทีมของคุณจะดูแลมันได้มั่นใจ
วางแผนเรื่องประสิทธิภาพตั้งแต่ต้น
แดชบอร์ดปฏิบัติการล้มเหลวเมื่อรู้สึกช้า ใช้ดัชนีบน timestamp, workflow step IDs, และ tenant/team IDs เพิ่ม pagination สำหรับ event logs แคชมุมมองแดชบอร์ดที่ใช้บ่อย (เช่น “วันนี้” และ “7 วันที่ผ่านมา”) และล้างแคชเมื่อมีเหตุการณ์ใหม่เข้ามา
ถ้าต้องการอภิปรายเชิงลึกเกี่ยวกับการแลกเปลี่ยนข้อดีข้อเสีย ให้เก็บบันทึกการตัดสินใจสั้นๆ ใน repo เพื่อการเปลี่ยนแปลงในอนาคตไม่เบี่ยงเบน
ทางลัดสำหรับทีมที่อยากปล่อยเร็ว
ถ้าเป้าหมายคือยืนยันการวิเคราะห์เวิร์กโฟลว์และการแจ้งเตือนก่อนลงทุนเต็มที่ แพลตฟอร์มแบบ vibe-coding อย่าง Koder.ai ช่วยให้คุณตั้งเวอร์ชันแรกได้เร็วขึ้น: คุณอธิบายเวิร์กโฟลว์ เอนทิตี และแดชบอร์ดในแชท แล้วปรับปรับ UI React และ backend Go + PostgreSQL ที่สร้างขึ้นตามความต้องการ
ข้อได้เปรียบเชิงปฏิบัติสำหรับแอปติดตามคอขวดคือความเร็วสู่การรับฟีดแบ็ก: คุณสามารถพิลอตการนำเข้า (API pulls, webhooks, หรือ CSV import), เพิ่มหน้าจอเจาะลึก และปรับคำนิยามเมตริกโดยไม่ต้องรอการตั้งค่าพื้นฐานเป็นสัปดาห์ เมื่อพร้อม Koder.ai ยังรองรับการส่งออกซอร์สโค้ดและการปรับใช้/โฮสต์ ทำให้ย้ายจากต้นแบบเป็นเครื่องมือภายในที่ดูแลต่อได้ง่ายขึ้น
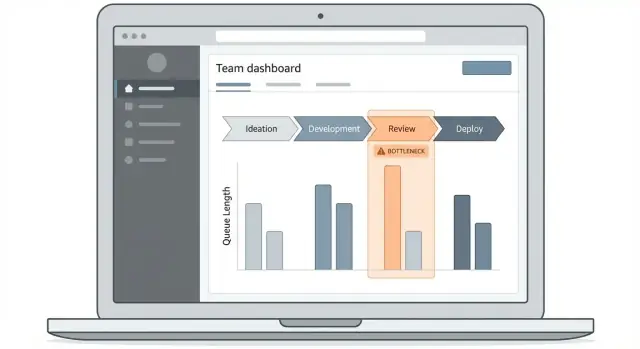
ออกแบบประสบการณ์แดชบอร์ดและการเจาะลึก
แอปติดตามคอขวดสำเร็จหรือล้มเหลวจากว่าผู้ใช้ตอบคำถามได้เร็วไหม: “ตอนนี้งานติดอยู่ที่ไหน และไอเท็มไหนเป็นสาเหตุ?” แดชบอร์ดควรทำเส้นทางนั้นให้เด่น แม้กับคนที่เข้ามาครั้งเดียวต่อสัปดาห์
เริ่มด้วย 2–3 หน้าจอแกนหลัก
เก็บรีลีสแรกให้กระชับ:
- แดชบอร์ดภาพรวม: “กระดานสถานะ” สำหรับ cycle time, queue time, และขั้นตอนที่ถูกบล็อกมากที่สุด
- รายการ work-item: ตารางที่ค้นหาและกรองได้ของไอเท็มที่ได้รับผลกระทบจากความล่าช้า
- รายละเอียดเวิร์กโฟลว์: มุมมองทีละขั้นตอนที่แสดงเวลาในแต่ละขั้นและจุดการส่งต่อ
หน้าจอเหล่านี้สร้างการเจาะลึกที่เป็นธรรมชาติโดยไม่บังคับให้ผู้ใช้เรียนรู้ UI ที่ซับซ้อน
ใช้ภาพที่อธิบายเวลาและการไหล
เลือกแผนภูมิที่ตอบคำถามปฏิบัติการ:
- Stage funnel: แสดงจุดสะสมของปริมาณ (ดีสำหรับดูคิว)
- Time-in-stage bars: เปรียบเทียบขั้นตอนโดย median และ percentile ไม่ใช่แค่ค่าเฉลี่ย
- Trend lines: ตอบว่า “กำลังดีขึ้นหรือแย่ลง?” ในช่วงสัปดาห์
- Heatmaps: เปิดเผยรูปแบบเช่น “วันจันทร์ในขั้นตอน Review” หรือ “การส่งต่อกะกลางคืน”
ใช้ป้ายชัดเจน: “Time waiting” แทนคำกำกวมเช่น “Queue latency” หากเป็นไปได้
ทำให้ฟิลเตอร์สอดคล้องและเด่นชัด
ใช้แถบฟิลเตอร์เดียวกันข้ามหน้าจอ (ตำแหน่งเดียวกัน ค่าเริ่มต้นเดียวกัน): ช่วงวันที่, ทีม, ลำดับความสำคัญ, และ ขั้นตอน แสดงฟิลเตอร์ที่ใช้อยู่เป็นชิปเพื่อให้คนไม่อ่านตัวเลขผิด
ออกแบบเส้นทางเจาะลึกที่ชัดเจน
ทุก KPI tile ควรกดได้และนำไปที่ที่มีประโยชน์:
KPI → ขั้นตอน → รายการไอเท็มที่ได้รับผลกระทบ
ตัวอย่าง: คลิก “Longest queue time” แล้วเปิด รายละเอียดขั้นตอน จากนั้นคลิกเดียวแสดง ไอเท็มที่รออยู่ เรียงตามอายุ ลำดับความสำคัญ และผู้รับผิดชอบ นี่แปลงความสงสัยเป็นรายการงานที่ทำได้จริง ซึ่งเป็นสาเหตุที่ทำให้แดชบอร์ดถูกใช้งานแทนถูกเมิน
เพิ่มการแจ้งเตือนและสัญญาณเตือนล่วงหน้า
ปรับใช้พิลอตอย่างรวดเร็ว
ใช้ Koder.ai hosting เพื่อพัฒนาเครื่องมือภายในและวนปรับปรุงกับผู้ใช้จริง
แดชบอร์ดดีสำหรับการทบทวน แต่คอขวดมักทำให้เสียหายมากที่สุดระหว่างการประชุม การแจ้งเตือนเปลี่ยนแอปของคุณให้เป็นระบบเตือนล่วงหน้า: คุณจะหาเจอปัญหาระหว่างเกิด ไม่ใช่หลังสัปดาห์หายไป
เริ่มด้วยกฎที่ชัดเจนและเรียบง่าย
เริ่มด้วยชุดการแจ้งเตือนเล็กๆ ที่ทีมตกลงกันว่าเป็นสิ่งที่ “ไม่ดี”:
- การเกินเกณฑ์: cycle time หรือ queue time เกินลิมิตที่รู้กัน (เช่น “ขั้นตอน Review > 24 ชั่วโมง”)
- การเพิ่มอย่างผิดปกติ: median cycle time ของวันนี้เพิ่มขึ้น 30% เทียบกับสัปดาห์ที่ผ่านมา
- ไอเท็มติดค้าง: ไม่มีการเปลี่ยนสถานะ N ชั่วโมง/วัน หรือไอเท็มเกินอายุสูงสุด
เก็บเวอร์ชันแรกให้เรียบง่าย กฎไม่กี่ข้อที่ตัดสินการณ์ได้จับปัญหาได้ส่วนใหญ่และน่าเชื่อถือกว่าระบบซับซ้อน
เพิ่มการตรวจจับความผิดปกติแบบน้ำหนักเบา
เมื่อเกณฑ์นิ่งแล้ว ให้เพิ่มสัญญาณ “มันแปลกไหม?” เบื้องต้น:
- เปอร์เซ็นต์การเปลี่ยนแปลงเทียบสัปดาห์ก่อน (เปรียบเทียบวันเดียวกันเพื่อลดการแจ้งเท็จ)
- การไหลของค่าเฉลี่ยเคลื่อนที่ (เช่น ค่าเฉลี่ย 7 วันเพิ่มต่อเนื่อง)
- ความไม่ตรงกันของปริมาณ (input เพิ่มเร็วกว่าผลลัพธ์ในขั้นตอน)
ทำให้ความผิดปกติเป็นคำแนะนำ ไม่ใช่เหตุฉุกเฉิน: ติดป้ายว่า “Heads up” จนกว่าผู้ใช้จะยืนยันว่ามีประโยชน์
ส่งการแจ้งเตือนไปยังที่ที่คนทำงานจริง
รองรับหลายช่องทางให้ทีมเลือก:
- อีเมลสำหรับผู้จัดการและสรุปรายวัน
- Slack/Microsoft Teams สำหรับการจัดการแบบเรียลไทม์
- การแจ้งเตือนในแอปสำหรับผู้รับผิดชอบภายในเครื่องมือ
ทำให้ทุกการแจ้งเตือนเป็นสิ่งที่ลงมือทำได้
การแจ้งเตือนควรตอบว่า “อะไร, ที่ไหน, แล้วทำอะไรต่อ”:
- ขั้นตอนไหน ได้รับผลกระทบ และ ช่วงเวลา
- ตัวขับเคลื่อนหลัก (เช่น ทีม หมวดหมู่ ลำดับความสำคัญ)
- ลิงก์ตรงไปยังการตรวจสอบ เช่น:
/dashboard?step=review&range=7d&filter=stuck
ถ้าการแจ้งเตือนไม่นำไปสู่การกระทำ ผู้คนจะปิดเสียงมัน—ดังนั้นให้ถือคุณภาพการแจ้งเตือนเป็นฟีเจอร์ของผลิตภัณฑ์ ไม่ใช่สิ่งเสริม
จัดการสิทธิ์ ความปลอดภัย และการตรวจสอบ
แอปติดตามคอขวดมักกลายเป็น “แหล่งความจริง” ซึ่งเป็นเรื่องดี—จนกว่าคนผิดจะแก้คำจำกัดความ ส่งออกข้อมูลลับ หรือแชร์แดชบอร์ดข้ามทีม สิทธิ์และบันทึกการตรวจสอบไม่ใช่กระดาษสีแดง; มันปกป้องความเชื่อถือในตัวเลข
กำหนดบทบาทและกฎการเข้าถึง
เริ่มด้วยโมเดลบทบาทเล็กๆ ชัดเจนแล้วขยายเมื่อจำเป็น:
- Viewer: เข้าถึงอ่านได้อย่างเดียวกับแดชบอร์ดและรายงาน
- Manager: กรองตามทีม สร้างมุมมองบันทึก ยืนยันการแจ้งเตือน และเพิ่มบันทึกได้ (แต่ไม่แก้การตั้งค่าระดับโลก)
- Admin: จัดการคำนิยามกระบวนการ สูตร KPI การเชื่อมต่อ และการเข้าถึงผู้ใช้
ระบุชัดว่าบทบาทแต่ละอย่างทำอะไรได้: ดูเหตุการณ์ดิบ vs เมตริกรวม, ส่งออกข้อมูล, แก้เกณฑ์, และจัดการการเชื่อมต่อ
แยกข้อมูลตามทีมหรือหน่วยธุรกิจ
ถ้าหลายทีมใช้แอป ให้บังคับการแยกที่ชั้นข้อมูล ไม่ใช่แค่ UI ทางเลือกทั่วไป:
- Multi-tenant: ทุกเรคคอร์ดมี
tenant_idและทุกคิวรีถูกกำหนดขอบเขตตามมัน - Partitions/projects: "workspaces" แยกตามหน่วยธุรกิจ พร้อมการตั้งค่าและแดชบอร์ดเป็นอิสระ
ตัดสินใจแต่แรกว่าผู้จัดการสามารถเห็นข้อมูลทีมอื่นไหม ทำให้การมองเห็นข้ามทีมเป็นสิทธิ์ที่ตั้งใจ ไม่ใช่ค่าเริ่มต้น
ยืนยันการพิสูจน์ตัวตนอย่างปลอดภัย (SSO หรือรองรับ MFA)
ถ้ององค์กรคุณมี SSO (SAML/OIDC) ให้ใช้เพื่อรวมการควบคุมการเข้าถึงและการถอนสิทธิ์ หากไม่มี ให้ทำระบบล็อกอินที่ พร้อมรองรับ MFA (TOTP หรือ passkeys), รองรับรีเซ็ตรหัสผ่านอย่างปลอดภัย และบังคับหมดเวลาการเข้าสู่ระบบ
ทำให้การเปลี่ยนแปลงตรวจสอบได้
บันทึกการกระทำที่เปลี่ยนผลลัพธ์หรือเปิดเผยข้อมูล: การส่งออก การเปลี่ยนเกณฑ์ การแก้ไขเวิร์กโฟลว์ การอัปเดตสิทธิ์ และการตั้งค่าการเชื่อมต่อ เก็บว่าใครทำ เมื่อไร อะไรเปลี่ยน (ก่อน/หลัง) และที่ไหน (workspace/tenant) ให้มีมุมมอง “Audit Log” เพื่อการตรวจสอบปัญหาได้รวดเร็ว
แปลงข้อมูลเชิงวิเคราะห์เป็นการลงมือทำและการปรับปรุงกระบวนการ
แดชบอร์ดคอขวดมีความหมายเมื่อมันเปลี่ยนสิ่งที่คนทำต่อไป เป้าหมายของส่วนนี้คือเปลี่ยน “ชาร์ตน่าสนใจ” ให้เป็นจังหวะการทำงานที่วนซ้ำ: ตัดสินใจ ลงมือ วัด และเก็บสิ่งที่ได้ผล
สร้างการทบทวนคอขวดแบบน้ำหนักเบา
ตั้งรอบสั้นๆ รายสัปดาห์ (30–45 นาที) พร้อมเจ้าของชัดเจน เริ่มจาก 1–3 คอขวดสูงสุดตามผลกระทบ (เช่น queue time สูงสุด หรือ throughput ลดมากสุด) แล้วตกลงการดำเนินการหนึ่งอย่างต่อคอขวด
รักษากระบวนการให้เล็ก:
- Owner: คนรับผิดชอบหนึ่งคนต่อการลงมือ
- Due date: ทบทวนถัดไปตามค่าเริ่มต้น
- Definition of done: การเปลี่ยนแปลงที่วัดได้ (ไม่ใช่แค่ “หาข้อมูลเพิ่มเติม”)
บันทึกการตัดสินใจตรงในแอปเพื่อให้แดชบอร์ดและบันทึกการกระทำเชื่อมต่อกัน
ติดตามการปรับปรุงเป็นการทดลอง
ปฏิบัติการแก้ไขเหมือนทดลองเพื่อเรียนรู้เร็วและหลีกเลี่ยงการปรับแบบสุ่ม สำหรับแต่ละการเปลี่ยนแปลง ให้บันทึก:
- สมมติฐาน (อะไรช้าและทำไม)
- การเปลี่ยนแปลง (จะทำอะไร)
- ผลที่คาดหวัง (เมตริกใดจะเปลี่ยนและเท่าไร)
- ผลลัพธ์ (สิ่งที่เกิดขึ้นจริง)
เมื่อเวลาผ่านไป นี่จะเป็นเพลย์บุ๊กว่าการลด cycle time หรือ rework อะไรได้ผลและอะไรไม่ได้
เพิ่มบริบทด้วยการใส่คำอธิบายประกอบ
ชาร์ตอาจทำให้เข้าใจผิดถ้าไม่มีบริบท ใส่คำอธิบายสั้นๆ บนไทม์ไลน์ (เช่น พนักงานใหม่เข้าทำงาน การขัดข้องของระบบ อัปเดตนโยบาย) เพื่อให้ผู้ชมตีความการเปลี่ยนแปลงใน queue time หรือ throughput ได้ถูกต้อง
ทำให้การแชร์เป็นเรื่องง่าย
ให้ตัวเลือกส่งออกสำหรับการวิเคราะห์และรายงาน—ดาวน์โหลด CSV และรายงานตามตารางเวลา—เพื่อให้ทีมใส่ผลลัพธ์ในอัปเดตปฏิบัติการและการทบทวนผู้บริหาร ถ้ามีหน้ารายงานอยู่แล้ว ให้ลิงก์จากแดชบอร์ดของคุณ (เช่น /reports)
ปรับใช้ ติดตาม และรักษาความสดของข้อมูล
ทำให้ความล่าช้าเป็นสิ่งที่ลงมือทำได้
สร้างหน้าจอเจาะลงจาก KPI tiles ไปยังรายการไอเท็มที่ติดค้างจริงๆ
แอปติดตามคอขวดมีประโยชน์ก็ต่อเมื่อใช้งานได้ต่อเนื่องและตัวเลขเชื่อถือได้ ถือว่าการปรับใช้และความสดของข้อมูลเป็นส่วนหนึ่งของผลิตภัณฑ์ ไม่ใช่เรื่องหลัง
ใช้สภาพแวดล้อมแยกกันและการปรับใช้ที่ทำซ้ำได้
ตั้ง dev / staging / prod ตั้งแต่ต้น Staging ควรจำลอง production (engine DB เดียวกัน ปริมาณข้อมูลใกล้เคียง background jobs เหมือนกัน) เพื่อจับคิวรีช้าและ migration เสียก่อนผู้ใช้เห็น
อัตโนมัติการปรับใช้ด้วย pipeline ชุดเดียว: รันเทสต์, ใช้ migration, ปรับใช้, แล้วรัน smoke check สั้นๆ (ล็อกอิน, โหลดแดชบอร์ด, ยืนยัน ingestion ทำงาน) รักษาการปรับใช้ให้เล็กและบ่อย เพื่อลดความเสี่ยงและทำให้การ rollback ทำได้จริง
ติดตามสถานะแอปและ pipeline
คุณต้องการการมอนิเตอร์สองด้าน:
- สุขภาพแอป: อัตราข้อผิดพลาด, latency, endpoints ช้า, คิวรีช้า
- สุขภาพข้อมูล: การล้มเหลวในการนำเข้า, ขนาด backlog, และ “เวลาตั้งแต่เหตุการณ์ล่าสุดได้รับ”
แจ้งเตือนสัญญาณที่ผู้ใช้รู้สึก (แดชบอร์ดโหลดช้า) และสัญญาณล่วงหน้า (คิวเติบโต 30 นาที) ติดตามความล้มเหลวในการคำนวณเมตริกด้วย—cycle time หายอาจดูเหมือน “ดีขึ้น” ได้
รักษาความสดของข้อมูล: เหตุการณ์มาช้า การแก้ไข และการเติมข้อมูลย้อนหลัง
ข้อมูลปฏิบัติการมาช้า ไม่เรียง หรือถูกแก้ไข วางแผนสำหรับ:
- Idempotent ingestion (ประมวลผลเหตุการณ์ซ้ำไม่ทำให้เกินนับ)
- Backfills สำหรับช่วงวันที่แหล่งข้อมูลล่ม
- Recomputes เมื่อตารางอ้างอิงเปลี่ยน (เช่น ปฏิทินกะเปลี่ยน)
กำหนดว่า “สด” หมายถึงอะไร (เช่น 95% ของเหตุการณ์ภายใน 5 นาที) และแสดงความสดใน UI
เขียน runbooks เพื่อให้การแก้ปัญหาไม่ต้องเดา
บันทึกขั้นตอนทีละขั้น: วิธีรีสตาร์ทซิงก์ที่ล้ม วิธียืนยัน KPI ของเมื่อวาน และวิธียืนยันว่า backfill ไม่เปลี่ยนตัวเลขย้อนหลังโดยไม่คาดคิด เก็บไว้กับโปรเจ็กต์และลิงก์จาก /docs เพื่อให้ทีมตอบโต้ได้เร็ว
วนปรับกับผู้ใช้และขยายขอบเขต
แอปติดตามคอขวดสำเร็จเมื่อคนเชื่อถือมันและใช้งานจริง เท่านั้นเกิดขึ้นหลังจากเฝ้าดูผู้ใช้จริงลองตอบคำถามจริง (“ทำไมการอนุมัติช้าสัปดาห์นี้?”) แล้วปรับผลิตภัณฑ์ให้ตรงกับเวิร์กโฟลว์เหล่านั้น
เริ่มด้วยพิลอตและเรียนรู้ว่าจุดไหนพัง
เริ่มกับทีมพิลอตหนึ่งทีมและเวิร์กโฟลว์จำนวนน้อย ขอบเขตแคบพอที่คุณจะสังเกตการใช้งานและตอบสนองเร็ว
ในสัปดาห์หรือสองสัปดาห์แรก ให้โฟกัสที่สิ่งที่สับสนหรือหายไป:
- ชาร์ตไหนผู้ใช้อ่านผิดบ่อย?
- พวกเขาติดขัดตรงไหนเมื่อเจาะลึก?
- ข้อมูลไหนที่เขาคาดหวังเห็นแต่หาไม่เจอ?
- คอขวดไหนที่พวกเขารู้สึกว่า “ชัดเจน” แต่ไม่สะท้อนในแอป?
เก็บฟีดแบ็กในเครื่องมือเอง (เช่น ปุ่ม “นี่เป็นประโยชน์ไหม?” บนหน้าจอสำคัญ) แทนการพึ่งพาความจำจากประชุม
ยืนยันเมตริกเพื่อลดการเถียงบนแดชบอร์ด
ก่อนขยายสู่ทีมอื่น ให้ล็อกคำนิยามกับคนที่ต้องรับผิดชอบ หลายการเปิดตัวล้มเหลวเพราะทีมไม่เห็นพ้องว่าเมตริกหมายถึงอะไร
สำหรับแต่ละ KPI (cycle time, queue time, rework rate, SLA breaches) ให้ระบุ:
- เหตุการณ์เริ่มและจบที่ชัดเจน
- การจัดการการหยุดชั่วคราว วันหยุด และ timestamp ที่ขาด
- วิธีนับข้อยกเว้น (ยกเลิก ยกระดับ เปิดใหม่)
จากนั้นทบทวนคำนิยามกับผู้ใช้และเพิ่มคำอธิบายสั้นๆ ใน UI ถ้าปรับคำนิยาม ให้แสดง changelog ชัดเจนเพื่อให้คนเข้าใจว่าทำไมตัวเลขเปลี่ยน
ขยายขอบเขตโดยไม่ทำให้แอปเป็นระเบียบ
เพิ่มฟีเจอร์อย่างระมัดระวังเมื่อเวิร์กโฟลว์การวิเคราะห์ของทีมพิลอตเสถียร การขยายทั่วไปถัดไปรวมถึงขั้นตอนที่กำหนดเอง (ทีมต่างกันตั้งชื่อต่างกัน), แหล่งข้อมูลเพิ่มเติม (ตั๋ว + CRM + สเปรดชีต), และการแยกเชิงลึกขึ้น (ตามสายผลิตภัณฑ์ ภูมิภาค ลำดับความสำคัญ ลูกค้า)
กฎที่เป็นประโยชน์: เพิ่มมิติใหม่ทีละหนึ่งและยืนยันว่ามันช่วยการตัดสินใจ ไม่ใช่แค่เพิ่มรายงาน
ทำให้การเริ่มต้นใช้งานง่ายและทำซ้ำได้
เมื่อขยายสู่ทีมมากขึ้น คุณต้องการความสม่ำเสมอ สร้างคู่มือเริ่มต้นสั้นๆ: วิธีเชื่อมข้อมูล, วิธีอ่านแดชบอร์ดปฏิบัติการ, และวิธีลงมือเมื่อได้รับการแจ้งเตือนคอขวด
ลิงก์ผู้ใช้ไปยังหน้าที่เกี่ยวข้องภายในผลิตภัณฑ์และเนื้อหา เช่น /pricing และ /blog เพื่อให้ผู้ใช้ใหม่หาคำตอบด้วยตัวเองแทนรอการฝึกสอน