14 ก.ย. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับการตรวจสอบคุณภาพข้อมูลและการแจ้งเตือน
เรียนรู้วิธีวางแผนและสร้างเว็บแอปที่รันการตรวจสอบคุณภาพข้อมูล ติดตามผลลัพธ์ และส่งการแจ้งเตือนทันเวลา พร้อมความชัดเจนเรื่องเจ้าของ บันทึกตรวจสอบ และแดชบอร์ด
เรียนรู้วิธีวางแผนและสร้างเว็บแอปที่รันการตรวจสอบคุณภาพข้อมูล ติดตามผลลัพธ์ และส่งการแจ้งเตือนทันเวลา พร้อมความชัดเจนเรื่องเจ้าของ บันทึกตรวจสอบ และแดชบอร์ด
ก่อนสร้างอะไร ให้แน่ใจว่าทีมเข้าใจตรงกันว่า “คุณภาพข้อมูล” หมายถึงอะไร แอปเว็บสำหรับ การมอนิเตอร์คุณภาพข้อมูล จะมีประโยชน์ก็ต่อเมื่อตกลงกันได้ว่าแอปต้องปกป้องผลลัพธ์ใดและรองรับการตัดสินใจใดบ้าง
หลายทีมผสมผสานมิติต่างๆ กัน เลือกมิติที่สำคัญ อธิบายด้วยภาษาง่าย ๆ และถือคำนิยามเหล่านั้นเป็นข้อกำหนดของผลิตภัณฑ์:
คำนิยามเหล่านี้จะเป็นฐานสำหรับ กฎการตรวจสอบข้อมูล และช่วยคุณตัดสินใจว่าแอปต้องรองรับ การตรวจสอบคุณภาพข้อมูล แบบใดบ้าง
รายการความเสี่ยงจากข้อมูลที่ผิดพลาดและผู้ได้รับผลกระทบ เช่น:
สิ่งนี้ช่วยป้องกันไม่ให้คุณสร้างเครื่องมือตรวจแต่ “ตัวชี้วัดที่น่าสนใจ” แต่พลาดสิ่งที่ทำร้ายธุรกิจจริง ๆ และยังกำหนดรูปแบบ การแจ้งเตือนบนเว็บแอป: ข้อความที่ถูกต้องควรไปถึงเจ้าของที่เหมาะสม
ชัดเจนว่าคุณต้องการ:
ระบุความคาดหวังด้านหน่วงเวลาให้ชัด (นาที เทียบชั่วโมง) เพราะการตัดสินใจนี้จะกระทบการจัดตาราง การเก็บข้อมูล และความเร่งด่วนของการแจ้งเตือน
กำหนดว่าจะวัดว่า “ดีขึ้น” อย่างไรเมื่อตอนที่แอปใช้งานจริง:
เมตริกเหล่านี้ช่วยให้ความพยายามในด้าน data observability มุ่งไปในสิ่งสำคัญ และช่วยจัดลำดับการตรวจสอบ เช่น การเลือกระหว่าง พื้นฐานการตรวจจับความผิดปกติ และการตรวจแบบกฎง่าย ๆ
ก่อนเขียน checks ให้เห็นภาพชัดว่าคุณมีข้อมูลอะไร อยู่ที่ไหน และใครจะแก้เมื่อมีปัญหา บัญชีข้อมูลเล็ก ๆ ตอนนี้จะประหยัดเวลาและความสับสนในอนาคต
รายการทุกที่ที่ข้อมูลกำเนิดหรือถูกแปลง:
สำหรับแต่ละแหล่ง จับคู่ เจ้าของ (บุคคลหรือทีม), ช่องทางติดต่อ (Slack/อีเมล) และความถี่การรีเฟรชที่คาดหวัง หากการเป็นเจ้าของไม่ชัดเจน การแจ้งเตือนก็จะไม่ชัดเช่นกัน
เลือกตาราง/ฟิลด์ที่สำคัญและจดว่ามีอะไรพึ่งพา:
โน้ต dependency ง่ายๆ เช่น orders.status → revenue dashboard ก็พอจะเริ่มได้
จัดลำดับตามผลกระทบและความน่าจะเป็น:
สิ่งเหล่านี้จะเป็นขอบเขตการมอนิเตอร์เริ่มต้นและเซ็ตแรกของเมตริกความสำเร็จ
บันทึกล้มเหลวที่คุณเคยเจอ: pipeline หยุดเงียบ, การตรวจจับช้า, ขาดบริบทในการแจ้งเตือน, การเป็นเจ้าของไม่ชัด เปลี่ยนสิ่งเหล่านี้เป็นข้อกำหนดที่ชัดเจนสำหรับส่วนถัดไป (การกำหนดเส้นทางแจ้งเตือน, บันทึกตรวจสอบ, มุมมองการสอบสวน) หากคุณมีหน้าภายในสั้น ๆ (เช่น /docs/data-owners) ให้ลิงก์จากแอปเพื่อให้ผู้ตอบสามารถลงมือได้เร็ว
ก่อนออกแบบหน้าจอหรือเขียนโค้ด ตัดสินใจว่าแอปจะรันการตรวจแบบใด ตัวเลือกนี้กำหนดทุกอย่าง: ตัวแก้ไขกฎ, การตารางงาน, ประสิทธิภาพ, และความสามารถในการปฏิบัติของการแจ้งเตือน
ทีมส่วนใหญ่ได้ประโยชน์ทันทีจากชุดประเภท check แกนหลัก:
email.”order_total ต้องอยู่ระหว่าง 0 ถึง 10,000.”order.customer_id ต้องมีอยู่ใน customers.id.”user_id ต้องไม่ซ้ำต่อวัน.”ให้คาตาล็อกเริ่มต้นมีแนวคิดชัดเจน คุณสามารถเพิ่ม checks เฉพาะด้านในภายหลังโดยไม่ทำให้ UI ยุ่งยาก
โดยทั่วไปมีสามตัวเลือก:
วิธีที่ใช้ได้จริงคือ “UI ก่อน, ช่องทางหลบหนีเป็นตัวเลือก”: ให้ UI และเทมเพลตรองรับ 80% แล้วเปิดช่องให้ใช้ SQL แบบกำหนดเองสำหรับกรณีที่เหลือ
ทำให้ความร้ายแรงมีความหมายและสม่ำเสมอ:
ระบุทริกเกอร์อย่างชัดเจน: ความล้มเหลวครั้งเดียวเทียบกับ “N ครั้งติดกัน”, เกณฑ์ตามเปอร์เซ็นต์, และหน้าต่างการยับยั้งการแจ้งเตือนแบบเลือกได้
หากรองรับ SQL/สคริปต์ ให้ตัดสินใจก่อน: การเชื่อมต่อที่อนุญาต, timeout, การเข้าถึงแบบ read-only, คำสั่งที่เป็นพารามิเตอร์, และวิธีการทำให้ผลลัพธ์เป็น pass/fail + เมตริก นี่ช่วยรักษาความยืดหยุ่นขณะปกป้องข้อมูลและแพลตฟอร์มของคุณ
แอปคุณภาพข้อมูลจะสำเร็จหรือพังจากความรวดเร็วที่ใครสักคนตอบคำถามสามข้อ: อะไรล้มเหลว, ทำไมมันสำคัญ, และ ใครเป็นเจ้าของ หากผู้ใช้ต้องขุดผ่านบันทึกหรือถอดรหัสชื่อกฎที่กำกวม พวกเขาจะไม่สนใจการแจ้งเตือนและสูญเสียความไว้วางใจในเครื่องมือ
เริ่มจากชุดหน้าจอเล็ก ๆ ที่รองรับวงจรชีวิตตั้งแต่ต้นจนจบ:
ทำให้ฟลูว์หลักชัดเจนและทำซ้ำได้:\n\nสร้าง check → ตั้งตาราง/รัน → ดูผล → ตรวจสอบ → แก้ไข → เรียนรู้.
“ตรวจสอบ” ควรเป็นการกระทำระดับหนึ่ง จากการรันที่ล้มเหลว ผู้ใช้ควรกระโดดไปยัง dataset, เห็นเมตริก/ค่าที่ล้มเหลว, เปรียบเทียบกับรันก่อนหน้า, และบันทึกข้อสังเกตเกี่ยวกับสาเหตุ “เรียนรู้” คือที่ที่คุณแนะนำปรับเกณฑ์ เพิ่ม check ประกอบ หรือเชื่อมลิงก์ไปยัง incident ที่รู้จัก
เริ่มด้วยบทบาทขั้นต่ำ:
ในหน้าผลล้มเหลวแต่ละครั้งต้องแสดง:
แอปตรวจสอบคุณภาพข้อมูลขยายง่ายและแก้บั๊กง่ายเมื่อคุณแยกความรับผิดชอบสี่อย่าง: สิ่งที่ผู้ใช้เห็น (UI), วิธีที่เปลี่ยนแปลง (API), วิธีการรัน checks (workers), และที่เก็บความจริง (storage). การแยกนี้ทำให้ control plane (config และการตัดสินใจ) แยกจาก data plane (การรัน checks และเก็บผลลัพธ์)
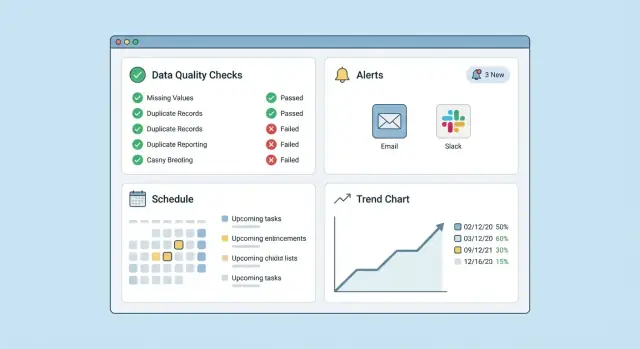
เริ่มจากหน้าจอเดียวที่ตอบว่า “อะไรพังและใครเป็นเจ้าของ?” แดชบอร์ดเรียบๆ พร้อมตัวกรองช่วยได้มาก:
จากแต่ละแถว ผู้ใช้ควรเจาะลึกไปยังหน้ารายละเอียดการรัน: คำจำกัดความของ check, ตัวอย่างที่ล้ม, และรันที่รู้ว่าดีล่าสุด
ออกแบบ API รอบวัตถุที่แอปจัดการ:
เก็บการเขียนให้เล็กและตรวจสอบค่า; ส่งคืน ID และ timestamp เพื่อให้ UI สามารถโพลติดตามและตอบสนองได้
Checks ควรถูกเรียกใช้นอกเว็บเซิร์ฟเวอร์ ใช้ scheduler เพื่อ enqueue งาน (คล้าย cron) และทริกเกอร์ตามต้องการจาก UI จากนั้น workers จะ:\n\n1) ดึง config ของ check, 2) รัน query/validation, 3) บันทึกผล, 4) ประเมินกฎการแจ้งเตือน
การออกแบบนี้ช่วยให้เพิ่มขีดจำกัดความพร้อมใช้งานต่อ dataset และ retry อย่างปลอดภัย
ใช้ที่เก็บแยกสำหรับ:
การแยกนี้ทำให้แดชบอร์ดโหลดเร็วในขณะที่ยังเก็บหลักฐานละเอียดเมื่อเกิดปัญหา
หากต้องการส่ง MVP อย่างรวดเร็ว แพลตฟอร์มแบบ vibe-coding อย่าง Koder.ai สามารถช่วยบูตสแตรป React dashboard, Go API และ PostgreSQL schema จากสเปกที่เขียนไว้ (checks, runs, alerts, RBAC) ผ่านการแชท มันมีประโยชน์ในการตั้งค่า CRUD flow และหน้าจอพื้นฐานอย่างรวดเร็ว เพราะ Koder.ai รองรับการส่งออกซอร์สโค้ด คุณยังคงเป็นเจ้าของและปรับปรุงระบบในรีโปของคุณได้
แอปที่ดีจะดูเรียบง่ายเพราะ data model ด้านล่างมีวินัย เป้าหมายคือทำให้ผลลัพธ์ทุกอย่างอธิบายได้: อะไรวิ่ง ไปที่ dataset ไหน ใช้พารามิเตอร์อะไร และอะไรเปลี่ยนแปลงเมื่อเวลาเปลี่ยน
เริ่มจากวัตถุชั้นหนึ่งขนาดเล็ก:
เก็บ รายละเอียดผลดิบ (ตัวอย่างแถวที่ล้ม, คอลัมน์ที่เกี่ยวข้อง, ชิ้นส่วนผลลัพธ์ของ query) เพื่อการสืบสวน แต่ก็เก็บ เมตริกสรุป สำหรับแดชบอร์ดและแนวโน้มด้วย การแยกนี้ทำให้กราฟเร็วโดยไม่เสียรายละเอียดการดีบัก
อย่าเขียนทับ CheckRun ให้เป็น append-only ประวัติแบบนี้ช่วยในการตรวจสอบ (“เรารู้ว่าอะไรเมื่อวันอังคาร?”) และช่วยดีบัก (“กฎเปลี่ยนหรือข้อมูลเปลี่ยน?”) บันทึกเวอร์ชันหรือแฮชของ config ต่อการรันด้วย
เพิ่มแท็กเช่น team, domain, และ PII flag บน Dataset และ Check แท็กช่วยตัวกรองในแดชบอร์ดและสนับสนุนกฎสิทธิ์ (เช่น เฉพาะบทบาทบางอย่างดูตัวอย่างแถวที่มีแท็ก PII ได้)
เอนจินการรันคือ “runtime” ของแอปมอนิเตอร์: มันตัดสินใจ เมื่อใด ที่ check รัน, อย่างไร ที่รันอย่างปลอดภัย, และ อะไร ถูกบันทึกเพื่อให้ผลลัพธ์เชื่อถือได้และทำซ้ำได้
เริ่มจาก scheduler ที่ทริกเกอร์ check ตามรอบ (คล้าย cron) Scheduler ไม่ควรทำงานหนักเอง—หน้าที่คือ enqueue งาน
คิว (ใช้ DB หรือ message broker) ช่วยให้คุณ:\n\n- ดูดซับสไปก์ของทราฟฟิก (many checks พร้อมกัน)\n- กระจายงานไปยัง workers\n- หยุด/เริ่มการรันโดยไม่สูญหายงาน
checks มักรัน query กับฐานข้อมูลโปรดักชันหรือ warehouse ตั้ง guardrails เพื่อให้ check ผิดพลาดไม่ทำให้ระบบช้า:
จับสถานะ “กำลังทำงาน” และให้ workers เก็บงานที่ถูกทิ้งหลังแครชได้อย่างปลอดภัย
ผลผ่าน/ล้มโดยไม่มีบริบทยากจะเชื่อถือ เก็บบริบทการรันข้างผลลัพธ์ทุกครั้ง:
นี่ช่วยให้คุณตอบได้ว่า: “ตอนนั้นรันอะไรแน่ ๆ?” ในสัปดาห์ถัดไป
ก่อนเปิดใช้งาน check เสนอ:
ฟีเจอร์เหล่านี้ลดความประหลาดใจและทำให้การแจ้งเตือนน่าเชื่อถือตั้งแต่วันแรก
การแจ้งเตือนคือจุดที่การมอนิเตอร์คุณภาพข้อมูลจะสร้างความไว้วางใจหรือถูกเพิกเฉย เป้าหมายไม่ใช่ “บอกทุกอย่างที่ผิด” แต่คือ “บอกฉันว่าต้องทำอะไรต่อ และด่วนแค่ไหน” ทำให้การแจ้งเตือนทุกชิ้นตอบสามคำถาม: อะไรพัง, แย่แค่ไหน, และ ใครเป็นเจ้าของ
checks ต่างกันต้องการทริกเกอร์ต่างกัน รองรับรูปแบบที่ใช้งานได้จริงไม่กี่แบบ:
ทำให้เงื่อนไขเหล่านี้ตั้งค่าได้ต่อ check และแสดงตัวอย่าง (“สิ่งนี้จะทริกเกอร์ 5 ครั้งเดือนที่แล้ว”) เพื่อให้ผู้ใช้ปรับจูนความไวได้
การแจ้งเตือนซ้ำสำหรับเหตุการณ์เดียวกันทำให้คนปิดการแจ้งเตือน เพิ่ม:
ติดตามการเปลี่ยนสถานะ: แจ้งเมื่อ เกิดข้อผิดพลาดใหม่ และแจ้งเพิ่มเติมเมื่อ ฟื้นตัว ตามต้องการ
การกำหนดเส้นทางควรขับเคลื่อนด้วยข้อมูล: ตาม เจ้าของ dataset, ทีม, ความร้ายแรง, หรือ แท็ก (เช่น finance, customer-facing). ตรรกะการกำหนดเส้นทางนี้ควรถูกเก็บใน config ไม่ใช่โค้ด
อีเมลและ Slack ครอบคลุมเวิร์กโฟลว์ส่วนใหญ่และยอมรับง่าย ออกแบบ payload การแจ้งเตือนให้เว็บฮุกในอนาคตต่อยอดได้ง่าย สำหรับการไต่สวนเชิงลึก ให้ลิงก์ตรงไปยังมุมมองการสืบสวน (ตัวอย่าง: /checks/{id}/runs/{runId})
แดชบอร์ดคือจุดที่การมอนิเตอร์คุณภาพข้อมูลเป็นประโยชน์ เป้าหมายไม่ใช่กราฟสวยงาม แต่คือให้ใครสักคนตอบสองคำถามได้อย่างรวดเร็ว: “มีอะไรพังไหม?” และ “ฉันต้องทำอะไรต่อ?”
เริ่มจากมุมมอง "สุขภาพ" กะทัดรัดที่โหลดเร็วและเน้นสิ่งที่ต้องการความสนใจ
แสดง:
หน้าจอนี้ควรรู้สึกเหมือนคอนโซลปฏิบัติการ: สถานะชัดเจน คลิกน้อย และป้ายกำกับสอดคล้องกันทั่วการตรวจสอบ
จาก check ที่ล้ม ให้มุมมองรายละเอียดที่ช่วยสืบสวนโดยไม่บังคับให้คนออกจากแอป
รวมถึง:
ถ้าเป็นไปได้ ให้ปุ่ม "Open investigation" หนึ่งคลิกพร้อมลิงก์ (แบบ relative เท่านั้น) ไปยัง runbook และ queries เช่น /runbooks/customer-freshness และ /queries/customer_freshness_debug.
ความล้มเหลวชัดเจน; แต่การเสื่อมช้า ๆ ไม่ชัด เพิ่มแท็บแนวโน้มสำหรับแต่ละ dataset และแต่ละ check:
กราฟเหล่านี้ทำให้พื้นฐานการตรวจจับความผิดปกติใช้งานได้จริง: คนจะเห็นว่ามันเป็นเหตุการณ์ชั่วคราวหรือเป็นรูปแบบ
ทุกกราฟและตารางควรเชื่อมกลับไปยังประวัติการรันและบันทึกตรวจสอบ ให้ลิงก์ "ดูการรัน" สำหรับแต่ละจุดเพื่อให้ทีมเปรียบเทียบอินพุต เกณฑ์ และการตัดสินการกำหนดเส้นทางการแจ้งเตือน การติดตามนี้สร้างความไว้วางใจในแดชบอร์ดสำหรับงาน data observability และคุณภาพข้อมูล ETL
การตัดสินใจด้านความปลอดภัยตั้งแต่ต้นจะทำให้แอปของคุณจัดการง่ายหรือสร้างความเสี่ยงและงานซ้ำซ้อน เครื่องมือนี้แตะระบบโปรดักชัน, credentials, และบางครั้งข้อมูลที่ถูกกฎระเบียบ จึงต้องปฏิบัติเป็นผลิตภัณฑ์แอดมินภายในตั้งแต่แรก
ถ้าองค์กรใช้ SSO ให้รองรับ OAuth/SAML เมื่อทำได้ จนกว่าเช่นนั้น อีเมล/รหัสผ่านอาจรับได้สำหรับ MVP แต่ต้องมีพื้นฐาน: การแฮชรหัสผ่านแบบมี salt, rate limiting, การล็อกบัญชี และรองรับ MFA
แม้มี SSO ให้เก็บบัญชี admin "break-glass" สำรองไว้ในที่ปลอดภัยสำหรับกรณีฉุกเฉิน อธิบายขั้นตอนและจำกัดการใช้
แยกการ "ดูผล" ออกจาก "เปลี่ยนพฤติกรรม" ชุดบทบาททั่วไป:
บังคับสิทธิ์บน API ไม่ใช่แค่ UI และพิจารณาการแบ่งเป็น workspace/project เพื่อทีมหนึ่งจะไม่แก้ checks ของทีมอื่นโดยไม่ตั้งใจ
หลีกเลี่ยงการเก็บตัวอย่างแถวดิบที่อาจมี PII เก็บสรุปและเมตริกแทน (จำนวน, อัตรา null, min/max, histogram) หากจำเป็นต้องเก็บตัวอย่างเพื่อดีบัก ให้เป็น opt-in พร้อม retention สั้น, masking/redaction, และการควบคุมการเข้าถึงเข้มงวด
เก็บบันทึกตรวจสอบสำหรับ: เหตุการณ์ล็อกอิน, แก้ไข check, เปลี่ยนเส้นทางแจ้งเตือน, และอัปเดตความลับ บันทึกตรวจสอบช่วยลดความงงเมื่อมีการเปลี่ยนแปลงและช่วยการปฏิบัติตามกฎ
credentials และ API keys ไม่ควรอยู่ใน plaintext ในฐานข้อมูล ใช้ vault หรือฉีดความลับผ่าน environment และออกแบบให้หมุนเวียนได้ (รองรับหลายเวอร์ชันพร้อมใช้งาน, เก็บ timestamp การหมุนเวียนล่าสุด, และ flow ทดสอบการเชื่อมต่อ) จำกัดการมองเห็นความลับสำหรับผู้ดูแล และบันทึกการเข้าถึงโดยไม่บันทึกค่าความลับ
ก่อนไว้วางใจแอปให้จับปัญหาข้อมูล พิสูจน์ว่ามันตรวจจับความล้มเหลวได้เชื่อถือได้ หลีกเลี่ยงการแจ้งเตือนผิดพลาด และกู้คืนได้เรียบร้อย ถือการทดสอบเป็นฟีเจอร์ของผลิตภัณฑ์: ปกป้องผู้ใช้จากเสียงรบกวน และปกป้องคุณจากช่องว่างการตรวจจับ
สำหรับแต่ละ check ที่รองรับ (freshness, row count, schema, null rates, custom SQL ฯลฯ) สร้างชุดข้อมูลตัวอย่างและกรณีทดสอบทองคำ: หนึ่งเคสที่ต้องผ่านและหลายเคสที่ต้องล้มในวิธีเฉพาะ เก็บไว้ขนาดเล็ก, ควบคุมเวอร์ชัน, และทำซ้ำได้
กรณีทองคำที่ดีตอบได้: คาดหวังผลลัพธ์อะไร? UI ควรแสดงหลักฐานใด? อะไรควรถูกเขียนลงบันทึกตรวจสอบ?
บั๊กในการแจ้งเตือนมักมีผลมากกว่าบั๊กของ check ทดสอบตรรกะการแจ้งเตือนสำหรับขีดจำกัด, cooldown, และการกำหนดเส้นทาง:
เพิ่มการมอนิเตอร์สำหรับระบบของคุณเองเพื่อจับเมื่อเครื่องมอนิเตอร์ล้มเหลว:
เขียนหน้าคู่มือแก้ปัญหาอย่างชัดเจนครอบคลุมความล้มเหลวทั่วไป (งานติดค้าง, ขาด credentials, ตารางงานล่าช้า, การแจ้งเตือนถูกยับยั้ง) และลิงก์ไว้ภายใน เช่น /docs/troubleshooting รวมขั้นตอน "ตรวจอะไรเป็นอันดับแรก" และที่หาบันทึก, run IDs, และ incident ล่าสุดใน UI
การส่งแอปตรวจสอบคุณภาพข้อมูลไม่ใช่การเปิดตัวครั้งใหญ่ แต่เป็นการสร้างความไว้วางใจทีละน้อย ปล่อยครั้งแรกควรพิสูจน์วงจร end-to-end: รัน checks, แสดงผล, ส่งการแจ้งเตือน, และช่วยใครสักคนแก้ปัญหาจริง
เริ่มด้วยชุดความสามารถแคบแต่เชื่อถือได้:
MVP นี้ควรเน้นความชัดเจนมากกว่าความยืดหยุ่น หากผู้ใช้ไม่เข้าใจว่าทำไม check ล้ม พวกเขาจะไม่ดำเนินการกับการแจ้งเตือน หากต้องการทดสอบ UX อย่างรวดเร็ว คุณสามารถโพรโทไทป์ส่วน CRUD-heavy (แคตาล็อก check, ประวัติการรัน, การตั้งค่าแจ้งเตือน, RBAC) ใน Koder.ai และวนกลับก่อนผูกมัดการพัฒนาเต็มรูปแบบ การสามารถสแนปช็อตและย้อนกลับการเปลี่ยนแปลงมีประโยชน์เมื่อต้องปรับจูนเสียงรบกวนและสิทธิ์
ปฏิบัติต่อแอปมอนิเตอร์เหมือนโครงสร้างพื้นฐานโปรดักชัน:
สวิตช์ฆ่า (kill switch) ง่าย ๆ สำหรับ check เดียวหรือการผนวกรวมทั้งระบบสามารถประหยัดเวลาได้หลายชั่วโมงระหว่างการนำไปใช้เริ่มต้น
ทำให้ 30 นาทีแรกสำเร็จได้ง่าย ให้เทมเพลตเช่น “Daily pipeline freshness” หรือ “Uniqueness for primary keys” พร้อมคู่มือการตั้งค่าสั้น ๆ ที่ /docs/quickstart
นอกจากนี้ กำหนดรูปแบบความเป็นเจ้าของเบา ๆ: ใครรับการแจ้งเตือน ใครแก้ไข checks และคำจำกัดความของ "เสร็จ" หลังจากเกิดการล้ม (เช่น acknowledge → fix → rerun → close)
เมื่อ MVP เสถียร ขยายตามเหตุการณ์จริง:
วนปรับปรุงโดยลดเวลาในการวินิจฉัยและลดเสียงรบกวน เมื่อผู้ใช้รู้สึกว่าแอปช่วยประหยัดเวลา การยอมรับจะขยายตัวเอง
เริ่มจากการเขียนลงไปว่า “คุณภาพข้อมูล” หมายถึงอะไรสำหรับทีมของคุณ—โดยทั่วไปคือ ความถูกต้อง, ความสมบูรณ์, ความทันเวลา, และความไม่ซ้ำกัน จากนั้นแปลงแต่ละมิติเป็นผลลัพธ์ที่จับต้องได้ (เช่น “คำสั่งซื้อโหลดเสร็จภายใน 6 โมงเช้า”, “อัตรา null ของอีเมล \u003c 2%”) และเลือกเมตริกความสำเร็จเช่น ลดเหตุการณ์ในโปรดักชัน, ตรวจพบเร็วขึ้น, และลดการแจ้งเตือนผิดพลาด.
แนะนำให้มีทั้งสองอย่าง:
กำหนดความคาดหวังด้านหน่วงเวลาให้ชัด (เป็นนาทีหรือชั่วโมง) เพราะจะส่งผลต่อการตารางงาน, การจัดเก็บ และความเร่งด่วนของการแจ้งเตือน.
จัดลำดับความสำคัญชุดข้อมูลแรก 5–10 ชุด ที่ห้ามพัง โดยดูจาก:
และบันทึกเจ้าของและความถี่การรีเฟรชที่คาดหวังสำหรับแต่ละ dataset เพื่อให้การแจ้งเตือนไปถึงคนที่สามารถแก้ไขได้.
คาตาล็อกเริ่มต้นที่ใช้งานได้จริงควรรวม:
ชุดนี้ครอบคลุมความผิดพลาดที่มีผลสูงส่วนใหญ่โดยไม่ต้องพึ่งการตรวจจับความผิดปกติขั้นสูงตั้งแต่วันแรก.
ใช้แนวทาง “UI เป็นหลัก, ช่องทางหลบหนีเมื่อจำเป็น”:
หากอนุญาต SQL แบบกำหนดเอง ควรมี guardrails เช่น การเชื่อมต่อแบบ read-only, timeout, parameterization และการทำให้ผลลัพธ์เป็น pass/fail ที่เป็นมาตรฐาน.
หน้าจอขั้นต่ำสำหรับรุ่นแรกที่ยังรู้สึกสมบูรณ์มีดังนี้:
แต่ละมุมมองผลล้มเหลวควรแสดงอย่างชัดเจนว่า , , และ .
ออกแบบระบบเป็นสี่ส่วนหลัก:
การแยกส่วนนี้ช่วยให้ control plane เสถียรในขณะที่ execution engine ขยายตัวได้.
ใช้โมเดลแบบ append-only:
มุ่งที่การกระทำได้จริงและลดเสียงรบกวน:
รวมลิงก์ไปยังมุมมองการสืบสวน (เช่น /checks/{id}/runs/{runId}) และแจ้งเมื่อ recovery ได้ตามต้องการ.
ปฏิบัติต่อผลิตภัณฑ์นี้เหมือนเป็นเครื่องมือแอดมินภายใน:
เก็บทั้งเมตริกสรุปและหลักฐานดิบพอสมควร (อย่างปลอดภัย) เพื่ออธิบายการล้มเหลวในภายหลังและบันทึกค่าเวอร์ชัน/แฮชของ config ต่อการรันเพื่อแยกความแตกต่างระหว่าง “กฎเปลี่ยน” กับ “ข้อมูลเปลี่ยน”.