09 ก.ย. 2568·2 นาที
วิธีสร้างหน้าแสดงสถานะสำหรับ SaaS พร้อมประวัติเหตุการณ์
เรียนรู้วิธีวางแผน สร้าง และเผยแพร่หน้าแสดงสถานะ SaaS ที่มีประวัติเหตุการณ์ ข้อความชัดเจน และระบบสมัครรับ เพื่อให้ลูกค้าทราบข้อมูลระหว่างการขัดข้อง
เรียนรู้วิธีวางแผน สร้าง และเผยแพร่หน้าแสดงสถานะ SaaS ที่มีประวัติเหตุการณ์ ข้อความชัดเจน และระบบสมัครรับ เพื่อให้ลูกค้าทราบข้อมูลระหว่างการขัดข้อง
หน้าแสดงสถานะของ SaaS เป็นเว็บไซต์สาธารณะ (หรือสำหรับลูกค้าเท่านั้น) ที่แสดงว่าผลิตภัณฑ์ของคุณทำงานอยู่หรือไม่ตอนนี้ — และคุณกำลังทำอะไรหากมันไม่ได้ทำงาน มันกลายเป็นแหล่งความจริงเดียวในช่วงเหตุการณ์ แยกจากโซเชียลมีเดีย ตั๋วซัพพอร์ต และข่าวลือต่าง ๆ
มันช่วยผู้คนได้มากกว่าที่คุณคิด:
เว็บไซต์สถานะที่ดีมักประกอบด้วยสามชั้นที่เกี่ยวข้องกัน (แต่ต่างกัน):
เป้าหมายคือความชัดเจน: สถานะเรียลไทม์ตอบคำถามว่า “ฉันใช้ผลิตภัณฑ์ได้ไหม?” ขณะที่ประวัติตอบว่า “เรื่องนี้เกิดขึ้นบ่อยแค่ไหน?” และโพสต์มอร์เท็มตอบว่า “ทำไมเกิดขึ้น และมีการเปลี่ยนแปลงอะไรบ้าง?”
หน้าแสดงสถานะจะได้ผลเมื่อการอัปเดต รวดเร็ว, ใช้ภาษาชัดเจน, และ ซื่อสัตย์เกี่ยวกับผลกระทบ คุณไม่จำเป็นต้องมีการวินิจฉัยที่สมบูรณ์แบบเพื่อสื่อสาร แต่คุณ ต้องมี เวลาประทับ ขอบเขต (ใครได้รับผลกระทบ) และเวลาการอัปเดตถัดไป
คุณจะพึ่งพามันในช่วง การหยุดทำงาน, ประสิทธิภาพลดลง (เช่น การเข้าสู่ระบบช้า เว็บฮุคล่าช้า) และ การบำรุงรักษาที่วางแผนไว้ ซึ่งอาจทำให้เกิดการหยุดชั่วคราวหรือความเสี่ยง
เมื่อคุณปฏิบัติต่อหน้าแสดงสถานะเป็นผิวนิ้วของผลิตภัณฑ์ (ไม่ใช่หน้า ops ชั่วคราว) การตั้งค่าที่เหลือจะง่ายขึ้นมาก: คุณสามารถกำหนดเจ้าของ สร้างเทมเพลต และเชื่อมต่อการมอนิเตอร์โดยไม่ต้องคิดขึ้นใหม่ทุกครั้งที่เกิดเหตุการณ์
ก่อนเลือกเครื่องมือหรือออกแบบเค้าโครง ให้ตัดสินใจว่าหน้าที่ของหน้าแสดงสถานะคืออะไร เป้าหมายที่ชัดเจนและเจ้าของที่ชัดเจนคือสิ่งที่ทำให้หน้าสถานะยังเป็นประโยชน์ในช่วงเหตุการณ์ — เมื่อทุกคนยุ่งและข้อมูลยุ่งเหยิง
ทีม SaaS ส่วนใหญ่สร้างหน้าแสดงสถานะเพื่อผลลัพธ์เชิงปฏิบัติสามอย่าง:
จดสัญญาณที่วัดได้ 2–3 อย่างที่คุณติดตามหลังเปิดตัว: ตั๋วซ้ำลดลงระหว่างเหตุการณ์, เวลาถึงอัปเดตแรกเร็วขึ้น, หรือมีลูกค้าเพิ่มการสมัครรับ
ผู้อ่านหลักของคุณมักเป็น ลูกค้าที่ไม่เชิงเทคนิค ที่ต้องการรู้:
ซึ่งหมายถึงการลดคำศัพท์เทคนิค ใช้ “ลูกค้าบางรายไม่สามารถเข้าสู่ระบบได้” แทน “อัตรา 5xx สูงขึ้นใน auth” หากต้องให้รายละเอียดเชิงเทคนิค ให้ใส่เป็นประโยครองสั้น ๆ
เลือคน้ำเสียงที่คุณรักษาได้ภายใต้ความกดดัน: สงบ ตรงไปตรงมา และโปร่งใส ตัดสินใจก่อน:
ทำให้ความรับผิดชอบชัดเจน: หน้าแสดงสถานะไม่ควรเป็น “งานของทุกคน” มิฉะนั้นจะกลายเป็นงานของไม่มีใคร
คุณมีสองทางเลือกที่พบบ่อย:
ถ้าแอปหลักของคุณอาจล่ม ไซต์แยกต่างหากมักจะปลอดภัยกว่า คุณยังสามารถลิงก์ไปยังมันเด่นจากแอปและศูนย์ช่วยเหลือ (ตัวอย่าง /help)
หน้าแสดงสถานะมีประโยชน์เท่ากับ “แผนที่” เบื้องหลัง ก่อนเลือกสีหรือเขียนข้อความ ให้ตัดสินใจว่าคุณรายงานอะไรจริง ๆ เป้าหมายคือสะท้อนประสบการณ์ของลูกค้ามากกว่าการจัดโครงสร้างองค์กรของคุณ
ลิสต์ชิ้นส่วนที่ลูกค้าอาจอธิบายเมื่อพูดว่า “มันเสีย” สำหรับผลิตภัณฑ์ SaaS หลายรายการ ชุดเริ่มต้นที่ใช้ได้จริงมักเป็น:
ถ้าคุณให้บริการหลายภูมิภาคหรือหลายระดับ ให้เก็บไว้ด้วย (เช่น “API – US” และ “API – EU”) ใช้ชื่ิอลูกค้าเข้าใจได้: “Login” ชัดกว่า “IdP Gateway”
เลือกการจัดกลุ่มที่ตรงกับการคิดของลูกค้า:
หลีกเลี่ยงรายการยาวเกินไป หากมีการผสานรวมเป็นจำนวนมาก ให้พิจารณาใช้คอมโพเนนต์แม่ (“Integrations”) พร้อมลูกย่อยที่มีผลกระทบรุนแรงไม่กี่รายการ (เช่น “Salesforce”, “Webhooks”)
โมเดลง่าย ๆ ที่สม่ำเสมอช่วยป้องกันความสับสนในช่วงเหตุการณ์ ระดับทั่วไปประกอบด้วย:
เขียนเกณฑ์ภายในสำหรับแต่ละระดับ (แม้จะไม่เผยแพร่) เช่น “Partial Outage = หนึ่งภูมิภาคล่ม” หรือ “Degraded = p95 latency เกิน X เป็นเวลา Y นาที” ความสม่ำเสมอสร้างความไว้วางใจ
การขัดข้องส่วนใหญ่เกี่ยวข้องผู้ให้บริการภายนอก: โฮสติ้งคลาวด์ การส่งอีเมล ผู้ให้บริการชำระเงิน หรือผู้ให้บริการยืนยันตัวตน บันทึกการพึ่งพาเหล่านี้เพื่อให้อัปเดตเหตุการณ์ของคุณถูกต้อง
ว่าจะเผยแพร่หรือไม่ขึ้นกับผู้ชม ถ้าลูกค้าได้รับผลโดยตรง (เช่น การชำระเงิน) การแสดงคอมโพเนนต์การพึ่งพาอาจเป็นประโยชน์ หากมันเพิ่มเสียงรบกวนหรือชวนให้โทษคนอื่น ให้เก็บไว้เป็นข้อมูลภายในแต่กล่าวถึงในอัปเดตเมื่อเกี่ยวข้อง (เช่น “เรากำลังตรวจสอบข้อผิดพลาดที่เพิ่มขึ้นจากผู้ให้บริการชำระเงินของเรา”)
เมื่อคุณมีโมเดลคอมโพเนนต์นี้ การตั้งค่าหน้าสถานะที่เหลือจะง่ายขึ้นมาก: ทุกเหตุการณ์จะมีคำตอบที่ชัดเจนว่า “ที่ไหน” (คอมโพเนนต์) และ “แย่แค่ไหน” (สถานะ) ตั้งแต่เริ่มต้น
หน้าแสดงสถานะมีประโยชน์ที่สุดเมื่อมันตอบคำถามของลูกค้าได้ภายในไม่กี่วินาที ผู้คนมักเข้ามาด้วยความเครียดและต้องการความชัดเจน — ไม่ใช่การนำทางมากมาย
จัดลำดับความสำคัญสิ่งสำคัญไว้บนสุด:
เขียนด้วยภาษาง่าย ๆ “อัตราข้อผิดพลาดของคำขอ API สูงขึ้น” ชัดกว่า “Partial outage in upstream dependency” ถ้าต้องใช้คำศัพท์เทคนิค ให้เพิ่มคำแปลสั้น ๆ (“คำขอบางคำอาจล้มเหลวหรือหมดเวลา”)
รูปแบบที่เชื่อถือได้คือ:
สำหรับรายการคอมโพเนนต์ ให้ใช้ป้ายชื่อที่ลูกค้าเข้าใจ หากบริการภายในคือ “k8s-cluster-2” ลูกค้าน่าจะต้องการเห็นคำว่า “API” หรือ “Background Jobs” มากกว่า
ทำให้หน้าอ่านได้ในช่วงความกดดัน:
วางชุดลิงก์เล็ก ๆ ใกล้บนสุด (เฮเดอร์หรือใต้แบนเนอร์):
เป้าหมายคือความมั่นใจ: ลูกค้าควรเข้าใจทันทีว่าเกิดอะไรขึ้น อะไรได้รับผลกระทบ และเมื่อไหร่ที่เขาจะได้ยินข่าวจากคุณครั้งต่อไป
เมื่อเกิดเหตุการณ์ ทีมของคุณกำลังบริหารการวินิจฉัย บรรเทาผล และคำถามจากลูกค้าพร้อมกัน เทมเพลตลดการเดาใจทำให้อัปเดตคงที่ ชัดเจน และเร็ว โดยเฉพาะเมื่อคนต่าง ๆ อาจเป็นผู้โพสต์
อัปเดตที่ดีเริ่มด้วยข้อเท็จจริงหลักชุดเดียวกันทุกครั้ง อย่างน้อยให้มาตรฐานฟิลด์เหล่านี้เพื่อให้ลูกค้ารู้ว่าเกิดอะไรขึ้น:
ถ้าคุณเผยแพร่หน้าประวัติเหตุการณ์ การรักษาฟิลด์เหล่านี้ให้สม่ำเสมอทำให้เหตุการณ์ในอดีตสแกนและเปรียบเทียบได้ง่าย
มุ่งหวังอัปเดตสั้น ๆ ที่ตอบคำถามเดิมของลูกค้าทุกครั้ง นี่คือตัวอย่างเทมเพลตที่ใช้งานได้จริงซึ่งคุณสามารถคัดลอกไปใส่ในเครื่องมือจัดการสถานะได้:
Title: สรุปสั้นและเฉพาะเจาะจง (เช่น “API errors for EU region”)
Start time: YYYY-MM-DD HH:MM (TZ)
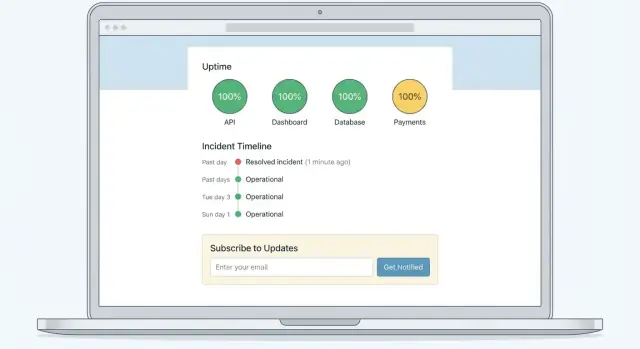
Affected components: API, Dashboard, Payments
Impact: สิ่งที่ผู้ใช้เห็น (ข้อผิดพลาด, หมดเวลา, ประสิทธิภาพลดลง) และใครได้รับผลกระทบ
What we know: ประโยคเดียวเกี่ยวกับสาเหตุ หากยืนยันแล้ว (หลีกเลี่ยงการคาดเดา)
What we’re doing: การดำเนินการที่เป็นรูปธรรม (rollback, scaling, vendor escalation)
Next update: เวลาที่คุณจะโพสต์อีกครั้ง
Updates:
ลูกค้าไม่ได้ต้องการแค่อินฟอร์เมชัน แต่ต้องการความคาดเดาได้
การบำรุงรักษาที่วางแผนไว้ควรรู้สึกสงบและมีโครงสร้าง มาตรฐานโพสต์การบำรุงรักษาด้วย:
ใช้ภาษาที่เฉพาะเจาะจง (สิ่งที่จะเปลี่ยนและผู้ใช้จะสังเกตเห็นอะไร) และหลีกเลี่ยงการสัญญาเกินจริง — ลูกค้าให้ความสำคัญกับความถูกต้องมากกว่าความหวังดี
หน้าประวัติเหตุการณ์เป็นมากกว่าแค่บันทึก — มันเป็นวิธีให้ลูกค้า (และทีมของคุณเอง) เข้าใจบ่อยแค่ไหนที่เกิดปัญหา ประเภทปัญหาที่ซ้ำ และวิธีการตอบของคุณ
ประวัติชัดเจนสร้างความมั่นใจผ่านความโปร่งใส มันยังสร้างการมองเห็นแนวโน้ม: ถ้าคุณเห็นเหตุการณ์ “ความหน่วงของ API” เกิดซ้ำทุกสองสัปดาห์ นั่นคือสัญญาณให้ลงทุนปรับปรุงประสิทธิภาพและจัดลำดับความสำคัญกระบวนการทบทวนหลังเหตุการณ์ เป็นเวลานาน การรายงานที่สม่ำเสมอช่วยลดตั๋วซัพพอร์ตเพราะลูกค้าสามารถค้นหาคำตอบเองได้
เลือกหน้าต่างการเก็บรักษาที่ตรงกับความคาดหวังของลูกค้าและความเป็นผู้ใหญของผลิตภัณฑ์
ไม่ว่าคุณจะเลือกอะไร ให้ระบุชัดเจน (เช่น “เก็บประวัติเหตุการณ์เป็นเวลา 12 เดือน”)
ความสม่ำเสมอทำให้การสแกนง่าย ใช้รูปแบบชื่อที่คาดเดาได้ เช่น:
YYYY-MM-DD — สรุปสั้น ๆ (เช่น “2025-10-14 — การส่งอีเมลล่าช้า”)
สำหรับแต่ละเหตุการณ์ แสดงอย่างน้อย:
ถ้าคุณเผยแพร่โพสต์มอร์เท็ม ให้ลิงก์จากหน้ารายละเอียดเหตุการณ์ไปยังรายงาน (ตัวอย่าง: “Read the postmortem” ที่ลิงก์ไปยัง /blog/postmortems/2025-10-14-email-delays) วิธีนี้ทำให้ไทม์ไลน์สะอาดแต่ยังให้รายละเอียดสำหรับลูกค้าที่สนใจ
หน้าแสดงสถานะของ SaaS คือหน้าที่ทุ่มเทเพื่อแสดง สถานะการให้บริการปัจจุบัน และ อัปเดตเหตุการณ์ ในที่เดียวที่เป็นแหล่งจริงเดียว (single source of truth) สำหรับลูกค้า การมีหน้าดังกล่าวช่วยลดคำถาม “มันล่มไหม?” ที่ส่งมายังฝ่ายซัพพอร์ต กำหนดความคาดหวังระหว่างการขัดข้อง และสร้างความไว้วางใจกับข้อความที่มีเวลาและชัดเจน
สถานะเรียลไทม์ตอบคำถาม “ฉันยังใช้ผลิตภัณฑ์ได้ไหมตอนนี้?” โดยแสดงสถานะระดับคอมโพเนนต์
ประวัติเหตุการณ์ตอบคำถาม “เหตุการณ์ลักษณะนี้เกิดขึ้นบ่อยแค่ไหน?” โดยแสดงไทม์ไลน์ของเหตุการณ์และงานบำรุงรักษาที่ผ่านมา
โพสต์มอร์เท็มตอบคำถาม “ทำไมมันถึงเกิดขึ้นและมีการเปลี่ยนแปลงอย่างไร?” โดยอธิบายสาเหตุที่แท้จริงและขั้นตอนป้องกัน (มักจะลิงก์จากหน้ารายละเอียดเหตุการณ์)
เริ่มด้วยผลลัพธ์ที่วัดได้ 2–3 อย่าง:
เขียนเป้าหมายเหล่านี้ลงและทบทวนเป็นประจำเพื่อให้หน้าไม่กลายเป็นของที่ไม่ได้ใช้
มอบหมายเจ้าของที่ชัดเจนและผู้สำรอง (เช่น วงรอบ on-call) ทีมทั่วไปมักจะมี:
กำหนดกฎล่วงหน้า: ใครโพสต์ได้ ต้องการการอนุมัติหรือไม่ และจังหวะการอัปเดตขั้นต่ำ (เช่น ทุก 30–60 นาทีในเหตุการณ์ใหญ่)
เลือกคอมโพเนนต์ตามที่ลูกค้าจะอธิบายปัญหา ไม่ใช่ชื่อตัวบริการภายใน ตัวอย่างคอมโพเนนต์ทั่วไปได้แก่:
ถ้าความเสถียรแตกต่างตามภูมิภาค ให้แยกตามภูมิภาค เช่น “API – US” และ “API – EU”
ใช้ชุดสถานะเล็ก ๆ ที่สม่ำเสมอและเขียนเกณฑ์ภายในสำหรับแต่ละสถานะ เช่น:
ความสม่ำเสมอสำคัญกว่าความแม่นยำสมบูรณ์ ลูกค้าควรเรียนรู้ความหมายของแต่ละสถานะจากการใช้งานซ้ำ ๆ
อัปเดตเหตุการณ์ที่เป็นประโยชน์ควรมีสิ่งต่อไปนี้เสมอ:
แม้จะยังไม่ทราบสาเหตุสุดท้าย คุณก็ยังสื่อสารขอบเขต ผลกระทบ และสิ่งที่กำลังทำต่อไปได้
โพสต์อัปเดตเริ่มต้น “Investigating” อย่างรวดเร็ว (มักภายใน 10–15 นาที หลังยืนยันผลกระทบ) แล้ว:
หากจะพลาดจังหวะ ให้โพสต์บันทึกสั้น ๆ เพื่อรีเซ็ตความคาดหวัง แทนที่จะหายไปนิ่ง ๆ
เครื่องมือที่ให้บริการ (hosted) เหมาะสำหรับการเปิดใช้งานเร็วและมักจะออนไลน์แม้แอปหลักล่ม รวมถึงระบบสมัครรับและการผสานรวม
DIY ให้การควบคุมเต็มที่แต่คุณต้องออกแบบเรื่องความทนทาน:
เสนอช่องทางที่ลูกค้าใช้จริง (โดยทั่วไปอีเมลและ SMS รวมถึง Slack/Teams หรือ RSS)
รักษาการสมัครรับเป็นแบบ opt-in ชัดเจนว่า:
ทดสอบการส่งและขีดจำกัดอัตราเป็นระยะเพื่อให้การแจ้งเตือนยังใช้งานได้เมื่อการจราจรพุ่งขึ้น