18 มี.ค. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับจัดการ Runbooks ปฏิบัติการ
คู่มือทีละขั้นตอนในการสร้างเว็บแอปจัดการ runbooks ปฏิบัติการ: โมเดลข้อมูล, ตัวแก้ไข, การอนุมัติ, การค้นหา, สิทธิ์, บันทึกตรวจสอบ และการเชื่อมต่อสำหรับการตอบสนองเหตุการณ์
ชี้เป้าก่อนว่าเป้าหมายคืออะไรและใครจะใช้แอปนี้
ก่อนเลือกฟีเจอร์หรือเทคสแต็ก ให้ตกลงร่วมกันว่าคำว่า “runbook” หมายถึงอะไรในองค์กรของคุณ บางทีมใช้ runbooks เป็น playbook สำหรับ incident response (สถานการณ์ความกดดันสูงและต้องการความเร็ว) ขณะที่ทีมอื่นหมายถึง SOPs (งานที่ทำซ้ำได้), งานบำรุงรักษาตามตาราง หรือเวิร์คโฟลว์การสนับสนุนลูกค้า หากคุณไม่กำหนดขอบเขตก่อน แอปจะพยายามรองรับเอกสารทุกรูปแบบ—แต่จะก็มักจะทำได้ไม่ดีในงานใดงานหนึ่ง
ระบุประเภท runbook (และนิยามว่า “ดี” คืออะไร)
เขียนรายการหมวดหมู่ที่คาดว่าจะเก็บในแอป พร้อมตัวอย่างสั้น ๆ สำหรับแต่ละหมวด:
- Playbooks สำหรับเหตุการณ์: ขั้นตอนเมื่อเกิด “ความหน่วงของ API”, เส้นทางการยกระดับ, คำสั่ง rollback
- SOPs: “Provision ลูกค้าใหม่”, “เปลี่ยนรหัสผ่าน/credential”, “ตรวจสอบความจุรายสัปดาห์”
- งานบำรุงรักษา: “แพตช์ฐานข้อมูล”, “ต่ออายุใบรับรอง”
นอกจากนี้ให้กำหนดมาตรฐานขั้นต่ำ: ฟิลด์ที่ต้องมี (เจ้าของ, บริการที่ได้รับผลกระทบ, วันที่ทบทวนล่าสุด), ความหมายของคำว่า “เสร็จ” (ทุกขั้นตอนถูกติ๊ก, บันทึกโน้ต), และสิ่งที่ควรหลีกเลี่ยง (บทความยาว ๆ อ่านยาก)
ระบุผู้ใช้เป้าหมายและข้อจำกัดของพวกเขา
จดรายชื่อผู้ใช้หลักและสิ่งที่พวกเขาต้องการในเวลานั้น:
- วิศวกร on-call: ความเร็ว, ความชัดเจน, ความลื่นไหลขณะ multitasking
- ฝ่ายปฏิบัติการ/สนับสนุน: กระบวนการที่สม่ำเสมอ, ลดการ handoff, คำนิยามที่ชัดเจน
- ผู้จัดการ/หัวหน้า: มองเห็นความคุ้มครอง, จังหวะการทบทวน, ความเป็นเจ้าของ
ผู้ใช้ต่างกันจะให้ความสำคัญต่างกัน การออกแบบเพื่อกรณี on-call มักจะบังคับให้ UI ต้องเรียบง่ายและคาดเดาได้
กำหนดผลลัพธ์และตัวชี้วัดความสำเร็จที่วัดได้
เลือก 2–4 ผลลัพธ์หลัก เช่น ลดเวลาตอบสนอง, การดำเนินการที่สม่ำเสมอ, การทบทวง่ายขึ้น แล้วผูกตัวชี้วัดที่ติดตามได้:
- เวลาในการหาคู่มือที่ถูกต้อง (search-to-open)
- อัตราการทำงานเสร็จสำหรับงานที่ต้องทำซ้ำ
- เวลาที่ใช้แก้ปัญหาเมื่อมี playbook เทียบกับไม่มี
- จังหวะการทบทวน: % ของ runbooks ที่ทบทวนใน 90 วันล่าสุด
การตัดสินใจเหล่านี้ควรชี้นำทุกการเลือกตั้งแต่การนำทางไปจนถึงสิทธิ์การเข้าถึง
เก็บข้อกำหนดจากเวิร์คโฟลว์ปฏิบัติการจริง
ก่อนเลือกเทคสแต็กหรือร่างหน้าจอ ให้สังเกตว่าการปฏิบัติการทำงานอย่างไรเมื่อบางอย่างล้มเหลว แอปจัดการ runbook จะสำเร็จเมื่อตรงกับนิสัยจริง: ที่ที่คนหาคำตอบ, ความหมายของ “พอใช้ได้” ระหว่างเหตุการณ์, และสิ่งที่ถูกมองข้ามเมื่อทุกคนลำบาก
เริ่มจากปัญหาที่จะแก้ไข
สัมภาษณ์วิศวกร on-call, SRE, ฝ่ายสนับสนุน และเจ้าของบริการ ถามตัวอย่างล่าสุดเฉพาะเจาะจง ไม่ใช่ความคิดเห็นทั่วไป ปัญหาทั่วไปได้แก่ เอกสารกระจัดกระจายในเครื่องมือต่าง ๆ, ขั้นตอนเก่าที่ไม่ตรงกับสภาพการผลิต, และความเป็นเจ้าของไม่ชัดเจน (ไม่มีใครรู้ควรอัปเดตรันบุ๊กเมื่อมีการเปลี่ยนแปลง)
เก็บแต่ละปัญหาเป็นเรื่องสั้น: เกิดอะไรขึ้น ทีมพยายามอะไร แล้วอะไรผิด และอะไรที่จะช่วยได้ เรื่องเล่าเหล่านี้จะเป็น acceptance criteria ในภายหลัง
ตรวจสอบแหล่งข้อมูลที่มีและความต้องการนำเข้า
จดว่าตอนนี้ runbooks และ SOPs อยู่ที่ไหน: wiki, Google Docs, repo Markdown, PDF, ความคิดเห็นในตั๋ว และ postmortem ของเหตุการณ์ สำหรับแต่ละแหล่งให้สังเกต:
- รูปแบบและโครงสร้าง (ตาราง, เช็คลิสต์, ภาพหน้าจอ, ลิงก์)
- ปริมาณและประวัติที่ต้องเก็บไว้
- เมตาดาต้าที่ต้องการ (บริการ, สภาพแวดล้อม, ความรุนแรง, เจ้าของ)
ข้อมูลนี้จะบอกว่าคุณต้องใช้ตัวนำเข้าจำนวนมาก, การย้ายข้อมูลแบบคัดลอก/วางง่าย ๆ หรือทั้งสองอย่าง
วาดแผนผังเส้นทาง runbook ตั้งแต่ต้นจนจบ
จดวงจรชีวิตทั่วไป: สร้าง → ทบทวน → ใช้งาน → อัปเดต ให้สังเกตว่าใครมีส่วนร่วมในแต่ละขั้นตอน ที่ไหนที่ต้องอนุมัติ และอะไรเป็นตัวกระตุ้นให้อัปเดต (การเปลี่ยนแปลงบริการ, บทเรียนจาก incident, การทบทวนรายไตรมาส)
ระบุข้อคาดหวังด้านการปฏิบัติตามและการตรวจสอบ
แม้คุณจะไม่อยู่ในอุตสาหกรรมที่ถูกควบคุม ทีมมักต้องการคำตอบว่า “ใครเปลี่ยนอะไร, เมื่อไร, และทำไม” กำหนดข้อกำหนดการติดตามตรวจสอบขั้นต่ำตั้งแต่ต้น: สรุปการเปลี่ยนแปลง, ผู้อนุมัติ, เวลาที่บันทึก, และความสามารถในการเปรียบเทียบเวอร์ชันระหว่างการใช้งาน playbook ในเหตุการณ์
ออกแบบโมเดลข้อมูลสำหรับ runbooks และเวอร์ชัน
แอป runbook จะสำเร็จหรือล้มเหลวตามว่าโมเดลข้อมูลสอดคล้องกับวิธีที่ทีมปฏิบัติการจริงทำงานหรือไม่: มี runbooks หลายรายการ, บล็อกที่ใช้ร่วมกัน, การแก้ไขบ่อยครั้ง, และความเชื่อมั่นสูงใน “สิ่งที่เป็นความจริง ณ เวลานั้น” เริ่มจากการกำหนดวัตถุหลักและความสัมพันธ์ระหว่างกัน
วัตถุหลัก
ขั้นต่ำให้มีการจำลอง:
- Runbook: ชื่อย่อ, สรุป, สถานะ (draft/published/archived), ธงความรุนแรง/กรณีใช้งาน, last_reviewed_at
- Step: รายการที่มีลำดับภายใน runbook (มีสาขาตัดสินใจได้)
- Tag: ป้ายเบา ๆ สำหรับการค้นหาและกรอง
- Service: บริการที่ runbook ครอบคลุม (payments, API, data pipeline)
- Owner: บุคคล/ทีมที่รับผิดชอบความถูกต้อง
- Version: snapshot ที่ไม่เปลี่ยนแปลงของ runbook ณ จุดเวลาใดเวลาหนึ่ง
- Execution: การบันทึก “การรัน” ของ runbook ระหว่างเหตุการณ์หรืองานปกติ
ความสัมพันธ์ที่สะท้อนการปฏิบัติการ
Runbooks ไม่ค่อยอยู่โดด ๆ วางแผนลิงก์เพื่อให้แอปสามารถแสดงเอกสารที่เหมาะสมภายใต้ความกดดันได้:
- Runbook ↔ Service (many-to-many): บริการหนึ่งอาจมีหลาย runbooks; runbook หนึ่งอาจครอบคลุมหลายบริการ
- Runbook ↔ Incident type / alert rule: เก็บการอ้างอิงถึงตัวระบุการแจ้งเตือนหรือหมวดหมู่ incident เพื่อให้ integrations เสนอ playbook ที่เหมาะสม
- Runbook ↔ Tags: สำหรับความกังวลข้ามส่วน (database, customer-impacting, rollback)
การจัดการเวอร์ชัน: draft เทียบกับ published
ปฏิบัติต่อเวอร์ชันเป็นระเบียน เพิ่มต่อท้าย ไม่แก้ไขซ้ำ Runbook ชี้ไปยัง current_draft_version_id และ current_published_version_id
- การแก้ไขสร้าง draft ใหม่
- การเผยแพร่จะ “ยกระดับ” draft เป็น published (สร้าง published version ใหม่ที่ไม่เปลี่ยนแปลง)
- เก็บเวอร์ชันเก่าไว้เพื่อตรวจสอบและ postmortem; พิจารณานโยบายเก็บภวังค์เฉพาะสำหรับ drafts แต่ไม่ใช่ published versions
เก็บเนื้อหาแบบรวยและไฟล์แนบ
สำหรับขั้นตอน ให้เก็บเนื้อหาเป็น Markdown (เรียบง่าย) หรือ JSON blocks ที่มีโครงสร้าง (ดีสำหรับเช็คลิสต์, callouts, และเทมเพลต) เก็บไฟล์แนบไว้ข้างนอกฐานข้อมูล: เก็บเมตาดาต้า (filename, size, content_type, storage_key) แล้ววางไฟล์ใน object storage
โครงสร้างนี้เตรียมคุณให้พร้อมสำหรับ audit trail ที่เชื่อถือได้และประสบการณ์ execution ที่ราบรื่นในภายหลัง
วางแผนชุดฟีเจอร์และเส้นทางผู้ใช้
แอป runbook จะสำเร็จเมื่อคงความคาดเดาได้ภายใต้ความกดดัน เริ่มจากการกำหนด MVP ที่รองรับวงจรหลัก: เขียน runbook, เผยแพร่, และใช้งานได้อย่างเชื่อถือในเวลาทำงาน
MVP: สิ่งขั้นต่ำที่จำเป็นให้มีประโยชน์
เก็บการเปิดตัวแรกให้แคบ:
- List / library: เรียกดู runbooks ตามบริการ, ทีม, และแท็ก
- View: หน้าพอ่าน-only ที่สะอาด โหลดเร็ว และพิมพ์ได้ดี
- Create: เริ่มจากศูนย์ด้วยชื่อ สรุป และขั้นตอนที่มีลำดับ
- Edit: แก้ไขแบบ draft โดยไม่กระทบเวอร์ชันที่เผยแพร่
- Publish: การกระทำที่ชัดเจนเพื่อทำให้เวอร์ชันเป็น “ทางการ”
- Search: ค้นหาแบบ full-text ข้ามชื่อ, สรุป, และข้อความในขั้นตอน
ถ้าทำหกอย่างนี้ไม่ได้เร็ว ฟีเจอร์เพิ่มจะไม่ช่วย
สิ่งที่ควรเพิ่มทีหลัง (ไม่ขัดขวางการเปิดตัวครั้งแรก)
เมื่อพื้นฐานเสถียรแล้ว ให้เพิ่มความสามารถที่ช่วยควบคุมและให้ข้อมูลเชิงลึก:
- Templates สำหรับประเภทเหตุการณ์ที่พบบ่อยและการบำรุงรักษาที่ทำซ้ำ
- Approvals และผู้ทบทวนสำหรับระบบที่มีความเสี่ยงสูง
- Executions (เช็คลิสต์) เพื่อบันทึกสิ่งที่ทำและเมื่อไหร่
- Analytics เช่น runbooks ที่ใช้บ่อยที่สุด, เนื้อหาล้าสมัย, และการค้นหาที่ไม่มีผลลัพธ์
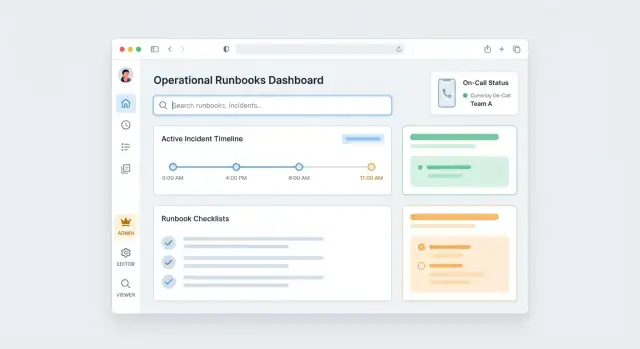
เลย์เอาต์: สามพื้นที่ทำงานหลัก
ทำให้แผนผัง UI สอดคล้องกับวิธีคิดของผู้ปฏิบัติ:
- Runbook Library: หาและกรองอย่างรวดเร็ว
- Editor: ร่าง แก้ไข และพรีวิวมุมมองที่เผยแพร่
- Execution View: โหมด “ทำขั้นตอน” ที่โฟกัสพร้อมติดตามความคืบหน้า
แผนผังหน้าเรียบง่าย (การนำทางที่คาดเดาได้)
- /runbooks (library)
- /runbooks/new
- /runbooks/:id (published view)
- /runbooks/:id/edit (draft editor)
- /runbooks/:id/versions
- /runbooks/:id/execute (execution mode)
- /search
ออกแบบเส้นทางผู้ใช้ตามบทบาท: ผู้เขียนที่สร้างและเผยแพร่, ผู้ตอบสนองที่ค้นหาและรัน, และผู้จัดการที่ทบทวนความสดใหม่และสถานะ
สร้าง editor ที่ทำให้ขั้นตอนชัดเจนและทำซ้ำได้
Editor ควรทำให้การเขียนกระบวนการที่ “ถูกต้อง” เป็นวิธีที่ง่ายที่สุด หากคนสามารถสร้างขั้นตอนที่สะอาดและสม่ำเสมอได้อย่างรวดเร็ว runbooks ของคุณจะใช้งานได้เมื่อมีความเครียดและเวลาจำกัด
เลือกรูปแบบ editor ที่ตรงกับผู้ใช้
มีสามแนวทางที่พบบ่อย:
- Markdown editor: รวดเร็วสำหรับผู้ชำนาญ แต่อาจทำให้ฟอร์แมตไม่สอดคล้อง
- Block editor: เนื้อหามีโครงสร้าง (ขั้นตอน, callouts, ลิงก์) อ่านง่าย เป็นสมดุลที่ดีสำหรับทีมผสม
- Form-based steps: แต่ละขั้นตอนเป็นฟอร์มที่มีฟิลด์เฉพาะ (action, expected result, owner, links) ให้ผลลัพธ์ที่สม่ำเสมอที่สุด เหมาะเมื่อต้องการการทำซ้ำอย่างเข้มงวด
หลายทีมเริ่มด้วย block editor แล้วเพิ่มข้อจำกัดแบบฟอร์มสำหรับประเภทขั้นตอนที่สำคัญ
ทำให้ขั้นตอนเป็นวัตถุชั้นหนึ่ง
แทนที่จะเป็นเอกสารยาวเดียว ให้เก็บ runbook เป็นรายการขั้นตอนที่มีลำดับ ชนิดของขั้นตอนเช่น:
- Text (บริบท)
- Command (มีปุ่มคัดลอกและ “expected output” ได้)
- Link (ไปยังแดชบอร์ด, ตั๋ว, เอกสาร)
- Decision (การแตกกิ่ง if/then)
- Checklist (หลายรายการย่อย)
- Caution note (คำเตือนที่มองเห็นชัด)
ขั้นตอนที่มีชนิดทำให้การเรนเดอร์เป็นไปอย่างสม่ำเสมอ, ค้นหาได้ดีขึ้น, นำกลับมาใช้ได้ปลอดภัยกว่า และ UX การรันดีขึ้น
เพิ่ม guardrails เพื่อป้องกัน “ขั้นตอนลึกลับ”
Guardrails ช่วยให้เนื้อหาอ่านง่ายและปฏิบัติตามได้:\n
- ฟิลด์บังคับ (เช่น ทุก command ต้องมีคำสั่งและสภาพแวดล้อม)
- การตรวจสอบความถูกต้อง (ลิงก์เสีย, พื้นที่ว่างที่ยังเป็น placeholder, เงื่อนไขที่ขาดหาย)
- พรีวิว ที่ตรงกับโหมด execution เพื่อให้ผู้เขียนเห็นสิ่งที่ผู้ตอบสนองจะเห็น
- กฎการจัดรูปแบบ (จำกัดหัวเรื่อง, มาตรฐานการตั้งชื่อเช่น “Verify…”, “Rollback…”, “Escalate…”)
ทำให้การนำกลับมาใช้เป็นเรื่องง่าย
รองรับ เทมเพลต สำหรับรูปแบบที่พบบ่อย (triage, rollback, การตรวจหลังเหตุการณ์) และปุ่ม Duplicate runbook ที่คัดลอกโครงสร้างพร้อมเตือนให้ผู้ใช้ปรับฟิลด์สำคัญ (ชื่อบริการ, ช่องทาง on-call, แดชบอร์ด) การนำกลับมาใช้ลดความแปรปรวน—และความแปรปรวนคือที่ที่เกิดข้อผิดพลาด
เพิ่มการอนุมัติ ความเป็นเจ้าของ และการเตือนทบทวน
รักษาการเปลี่ยนแปลงให้ย้อนกลับได้
ทดลองเปลี่ยนแปลงและย้อนกลับอย่างรวดเร็วเมื่อการไหลไม่ถูกต้อง
runbooks จะมีประโยชน์ก็ต่อเมื่อคนเชื่อถือได้ ระดับการกำกับที่เบา ๆ—เจ้าของชัดเจน, เส้นทางการอนุมัติที่คาดเดาได้, และการทบทวนเป็นรอบ—จะรักษาเนื้อหาให้ถูกต้องโดยไม่ทำให้การแก้ไขทุกครั้งกลายเป็นคอขวด
ออกแบบโฟลว์การทบทวนแบบเรียบง่าย
เริ่มด้วยสถานะชุดเล็ก ๆ ที่ตรงกับการทำงานของทีม:
- Draft: กำลังเขียนหรืออัปเดต
- In review: รอข้อเสนอแนะจากผู้ทบทวนเฉพาะ
- Approved: พร้อม แต่ยังไม่เปิดเผยต่อทุกคน (เป็น buffer ทางเลือก)
- Published: เวอร์ชันที่ใช้ระหว่างเหตุการณ์และงานประจำ
ทำให้การเปลี่ยนสถานะเป็นสิ่งชัดเจนใน UI (เช่น “Request review”, “Approve & publish”) และบันทึกว่าใครทำสิ่งใดเมื่อไร
เพิ่มความเป็นเจ้าของและวันที่ทบทวน
ทุก runbook ควรมีอย่างน้อย:
- Primary owner: รับผิดชอบความถูกต้อง
- Backup owner: ครอบคลุมช่วงวันหยุดและการหมุนเวียน
- Review due date (หรือ “ทบทวนทุก X วัน”): เพื่อไม่ให้ runbooks เน่าเปื่อยโดยไม่รู้ตัว
ปฏิบัติต่อความเป็นเจ้าของเหมือนแนวคิด on-call: เจ้าของเปลี่ยนตามโครงสร้างทีม และการเปลี่ยนแปลงเหล่านั้นควรปรากฏเห็นได้ชัด
บังคับให้มีสรุปการเปลี่ยนแปลงเมื่อแก้ไข
เมื่อมีผู้แก้ไข runbook ที่เผยแพร่ ให้ขอสรุปการเปลี่ยนแปลงสั้น ๆ และ (เมื่อจำเป็น) คอมเมนต์บังคับเช่น “ทำไมเราถึงเปลี่ยนขั้นตอนนี้?” สิ่งนี้สร้างบริบทร่วมสำหรับผู้ทบทวนและลดการย้อนกลับซ้ำ ๆ ในการอนุมัติ
วางแผนการแจ้งเตือนโดยไม่ผูกติดกับผู้ให้บริการเดียว
การทบทวน runbook จะใช้ได้ต่อเมื่อคนได้รับการเตือน ส่งการเตือนสำหรับ “ขอทบทวน” และ “ใกล้ถึงวันทบทวน” แต่หลีกเลี่ยงการผูก死กับอีเมลหรือ Slack กำหนดอินเทอร์เฟซการแจ้งเตือนเรียบง่าย (events + recipients) แล้วค่อยต่อเชื่อมผู้ให้บริการ: Slack วันนี้, Teams พรุ่งนี้ โดยไม่ต้องเขียนโค้ดแกนหลักใหม่
จัดการการพิสูจน์ตัวตนและสิทธิ์อย่างปลอดภัย
runbooks มักมีข้อมูลที่เราไม่อยากเผยแพร่กว้าง ๆ: URL ภายใน, ช่องทางการยกระดับ, คำสั่งกู้คืน และบางครั้งรายละเอียดการกำหนดค่าที่มีความอ่อนไหว ให้ถือการพิสูจน์ตัวตนและการอนุญาตเป็นฟีเจอร์หลัก ไม่ใช่งานเสริมที่มาทีหลัง
เริ่มด้วย RBAC แบบเรียบง่าย
อย่างน้อยให้มีบทบาทสามแบบ:
- Viewer: อ่าน runbooks และใช้ execution mode ได้
- Editor: สร้างและอัปเดตรันบุ๊กที่ได้รับสิทธิ์เข้าถึง
- Admin: จัดการสิทธิ์, ทีม/บริการ, และการตั้งค่าทั่วไป
ทำให้บทบาทเหล่านี้สอดคล้องกันใน UI (ปุ่ม, การเข้าถึง editor, การอนุมัติ) เพื่อให้ผู้ใช้ไม่ต้องเดาว่าทำอะไรได้บ้าง
ขอบเขตการเข้าถึงตามทีมหรือบริการ (และบางครั้งตาม runbook)
องค์กรส่วนใหญ่จัดการปฏิบัติการตาม ทีม หรือ บริการ, และสิทธิ์ควรตามโครงสร้างนั้น รูปแบบปฏิบัติได้คือ:
- ผู้ใช้เป็นสมาชิกของหนึ่งหรือหลายทีม
- Runbooks ถูกแท็กกับบริการ (เจ้าของโดยทีม)
- สิทธิ์ถูกมอบที่ระดับทีม/บริการ
สำหรับเนื้อหาที่มีความเสี่ยงสูง เพิ่ม override ระดับ runbook เป็นทางเลือก (เช่น “เฉพาะ Database SREs เท่านั้นที่แก้ไข runbook นี้”) เพื่อให้ระบบจัดการได้ง่ายแต่ยังรองรับข้อยกเว้น
ปกป้องขั้นตอนที่มีข้อมูลอ่อนไหว
บางขั้นตอนควรเห็นได้เฉพาะกลุ่มเล็ก ๆ รองรับส่วนที่จำกัดการมองเห็นเช่น “รายละเอียดที่อ่อนไหว” ที่ต้องการสิทธิ์สูงกว่าในการดู แนะนำให้ทำ redaction (“ซ่อนสำหรับผู้ดู”) มากกว่าการลบเนื้อหาเพื่อให้ runbook ยังคงอ่านได้ภายใต้ความกดดัน
ทำให้การพิสูจน์ตัวตนยืดหยุ่น
แม้เริ่มจากอีเมล/รหัสผ่าน ให้ออกแบบชั้น auth เพื่อเพิ่ม SSO ได้ในภายหลัง (OAuth, SAML) ใช้วิธีที่เสียบปลั๊กได้สำหรับผู้ให้บริการตัวตนและเก็บตัวระบุผู้ใช้ที่คงที่เพื่อไม่ให้การสลับไป SSO ทำลายความเป็นเจ้าของ การอนุมัติ หรือ audit trail
ทำให้การค้นหา runbook ง่ายเมื่อมีความกดดัน
เป็นเจ้าของซอร์สโค้ด
ส่งออกซอร์สโค้ดไปยัง repo ของคุณเพื่อการตรวจสอบ ความปลอดภัย และความเป็นเจ้าของระยะยาว
เมื่อบางอย่างเสีย ใคร ๆ ก็ไม่อยากเรียกดูเอกสาร พวกเขาต้องการ runbook ที่ถูกต้องภายในวินาที แม้จะจำคำศัพท์ได้เลือนราง การค้นหาเป็นฟีเจอร์ของผลิตภัณฑ์ ไม่ใช่สิ่งที่เสริม
สร้างการค้นหาที่ทำงานเหมือนสมองของผู้ on-call
ทำกล่องค้นหาเดียวที่สแกนมากกว่าชื่อเรื่อง ดัชนีชื่อ, แท็ก, บริการเจ้าของ, และ เนื้อหารายขั้นตอน (รวมคำสั่ง, URL, และสตริงข้อผิดพลาด) ผู้ใช้มักจะวางสแนิปต์ล็อกหรือข้อความแจ้งเตือน—การค้นหาระดับขั้นตอนคือสิ่งที่ทำให้มันตรงกับผลลัพธ์
รองรับการจับคู่ทนทาน: คำบางส่วน, การสะกดผิด, และคิวรีแบบ prefix แสดงผลลัพธ์พร้อมไฮไลต์ข้อความเพื่อให้ผู้ใช้ยืนยันว่านี่คือขั้นตอนที่ต้องการโดยไม่ต้องเปิดหลายแท็บ
เพิ่มฟิลเตอร์ที่ตัดเสียงรบกวนทันที
การค้นหาจะเร็วเมื่อผู้ใช้สามารถจำกัดบริบทได้ ให้ฟิลเตอร์ที่สะท้อนความคิดของทีมปฏิบัติการ:
- บริการ (หรือส่วนประกอบระบบ)
- ความรุนแรง (SEV/priority)
- สภาพแวดล้อม (prod/stage/dev, region)
- ทีม/เจ้าของ
- วันที่ทบทวนล่าสุด (หรือ “ทบทวนเลยกำหนด”)\n ทำให้ฟิลเตอร์คงอยู่ข้ามเซสชันสำหรับผู้ใช้ on-call และแสดงฟิลเตอร์ที่กำลังใช้อย่างชัดเจน
สอนระบบให้รู้คำพ้องความหมายและภาษาจริงของเหตุการณ์
ทีมไม่ได้ใช้คำศัพท์เดียวกันเสมอไป “DB”, “database”, “postgres”, “RDS” และชื่อเล่นภายในอาจหมายความเหมือนกัน เพิ่มพจนานุกรมคำพ้องแบบ lightweight ที่อัปเดตได้โดยไม่ต้อง deploy (ผ่าน UI admin หรือ config) ใช้ขยายคำค้นเวลาเรียกใช้และ/หรือระหว่างการดัชนี
เก็บคำที่พบบ่อยจากชื่อเหตุการณ์และป้ายแจ้งเตือนเพื่อรักษาความสอดคล้องของคำพ้องกับสถานการณ์จริง
ออกแบบหน้าดู runbook ให้สแกนได้ ไม่ใช่อ่านยาว
หน้า runbook ควรมีข้อมูลแน่นและสแกนได้ง่าย: สรุปที่ชัดเจน, ข้อกำหนดเบื้องต้น, และสารบัญขั้นตอน แสดงเมตาดาต้าที่สำคัญด้านบน (บริการ, ความเหมาะสมของสภาพแวดล้อม, วันที่ทบทวนล่าสุด, เจ้าของ) และทำให้ขั้นตอนสั้น มีหมายเลข และพับได้
รวมปุ่ม “คัดลอก” สำหรับคำสั่งและ URL และบริเวณ “runbooks ที่เกี่ยวข้อง” ขนาดกะทัดรัดสำหรับกระโดดไปยังการทำตามขั้นตอนที่พบบ่อย (เช่น rollback, verification, escalation)
นำโหมด execution มาใช้สำหรับเหตุการณ์และงานประจำ
Execution mode คือจุดที่ runbooks หยุดเป็นแค่ “เอกสาร” และกลายเป็นเครื่องมือที่คนพึ่งพาได้ในช่วงความกดดัน ถือมันเป็นมุมมองที่โฟกัส ปราศจากสิ่งรบกวน นำผู้ใช้จากขั้นตอนแรกถึงสุดท้าย พร้อมบันทึกสิ่งที่เกิดขึ้นจริง
UI ที่โฟกัส: ขั้นตอน, สถานะ, และเวลา
แต่ละขั้นตอนควรมีสถานะชัดเจนและพื้นที่ควบคุมเรียบง่าย:
- กล่องติ๊กหรือปุ่ม Mark complete (รวม Skip เมื่อต้องการ)
- สถานะขั้นตอนเช่น Not started / In progress / Blocked / Done
- ตัวจับเวลาแบบเลือกได้: ตัวจับเวลารันรวม (ตั้งแต่เริ่มรัน) และตัวจับเวลาแต่ละขั้นตอน (เวลาที่ใช้)
รายละเอียดเล็ก ๆ ช่วยได้: ปักหมุดขั้นตอนปัจจุบัน, แสดง “ขั้นตอนถัดไป”, และทำให้ขั้นตอนยาวอ่านง่ายด้วยการพับ
บันทึกโน้ต ลิงก์ และหลักฐานขณะปฏิบัติ
ในขณะรัน ผู้ปฏิบัติต้องแนบบริบทโดยไม่ออกจากหน้า รองรับการเพิ่มต่อขั้นตอนเช่น:
- โน้ตอิสระ (สิ่งที่เห็น, สิ่งที่ลอง, ทำไมเลือกเส้นทางนั้น)
- ลิงก์ไปยังแดชบอร์ด, ตั๋ว, หรือเธรดแชท
- ไฟล์แนบเป็นหลักฐาน (ภาพหน้าจอ, โล๊ก, ผลลัพธ์คำสั่ง)
ทำให้การเพิ่มเหล่านี้มี timestamp อัตโนมัติ และเก็บไว้แม้การรันจะหยุดพักแล้วกลับมาทำต่อ
การแตกกิ่งและเส้นทางการยกระดับ
ขั้นตอนจริงไม่เป็นเส้นตรงเสมอ รองรับสาขาแบบ “if/then” เพื่อให้ runbook ปรับตามเงื่อนไข (เช่น “ถ้า error rate > 5% ให้…”) รวมทั้งมีการกระทำ Stop and escalate ที่:
- ทำเครื่องหมายการรันว่า escalated/blocked
- ถามว่าใครถูกติดต่อและทำไม
- ถ้าต้องการ สร้างสรุปการส่งมอบงานสำหรับผู้รับช่วงต่อ
เก็บประวัติการรันเพื่อเรียนรู้
การรันแต่ละครั้งควรสร้าง execution record ที่ไม่เปลี่ยนแปลง: เวอร์ชัน runbook ที่ใช้, เวลาแต่ละขั้นตอน, โน้ต, หลักฐาน, และผลลัพธ์สุดท้าย นี่จะเป็นแหล่งข้อมูลสำหรับการทบทวนหลังเหตุการณ์และปรับปรุง runbook โดยไม่ต้องพึ่งความจำ
เพิ่ม audit trail และประวัติการเปลี่ยนแปลงที่เชื่อถือได้
เมื่อ runbook เปลี่ยน คำถามในเหตุการณ์ไม่ใช่ “อะไรเป็นเวอร์ชันล่าสุด?” แต่เป็น “เราจะเชื่อมันได้ไหม และมันมาถึงจุดนี้ได้อย่างไร?” เส้นเวลาที่ชัดเจนเปลี่ยน runbooks ให้เป็นบันทึกปฏิบัติการที่เชื่อถือได้แทนที่จะเป็นบันทึกที่แก้ไขได้
สิ่งที่ต้องบันทึก (และทำไมสำคัญ)
ขั้นต่ำให้บันทึกทุกการเปลี่ยนแปลงที่มีความหมายพร้อม ใคร, อะไร, และ เมื่อไร ไปอีกขั้นเก็บ snapshot ก่อน/หลัง ของเนื้อหา (หรือ diff ที่มีโครงสร้าง) เพื่อให้ผู้ทบทวนเห็นว่าการเปลี่ยนแปลงคืออะไรโดยไม่ต้องเดา
เก็บเหตุการณ์นอกเหนือการแก้ไขด้วย เช่น:
- Publishing: draft → published, published → archived, rollbacks
- Approval decisions: ใครอนุมัติ/ปฏิเสธ, เวลา, คอมเมนต์ตัวเลือก
- Ownership changes: การมอบหมายเจ้าของหรือทีมใหม่
สิ่งนี้สร้างเส้นเวลาที่เชื่อถือได้สำหรับ post-incident review และการตรวจสอบการปฏิบัติตาม
มุมมอง audit ที่ใช้งานได้ภายใต้ความกดดัน
ให้แท็บ Audit ต่อ runbook แสดงสตรีมเหตุการณ์เรียงตามเวลา พร้อมฟิลเตอร์ (editor, ช่วงวันที่, ประเภทเหตุการณ์) รวม “ดูเวอร์ชันนี้” และ “เปรียบเทียบกับปัจจุบัน” เพื่อให้ผู้ตอบสามารถยืนยันว่าสิ่งที่ปฏิบัติตามตรงกับเจตนาหรือไม่อย่างรวดเร็ว
ถ้าองค์กรต้องการ เพิ่มตัวเลือกส่งออกเช่น CSV/JSON สำหรับ audit เก็บการส่งออกไว้ภายใต้สิทธิ์และขอบเขต (runbook เดี่ยวหรือช่วงเวลา) และพิจารณาการเชื่อมโยงไปยังหน้าแอดมินภายในเช่น /settings/audit-exports
กฎการเก็บรักษาและความต้านทานการเปลี่ยนแปลง
กำหนดกฎการเก็บรักษาที่ตรงกับข้อกำหนดของคุณ: เช่น เก็บ snapshot เต็มรูปแบบ 90 วัน แล้วเก็บ diff และเมตาดาต้า 1–7 ปี เก็บระเบียน audit แบบ append-only, จำกัดการลบ, และบันทึกการยกเว้นโดยแอดมินเป็นเหตุการณ์ที่ตรวจสอบได้ด้วย
เชื่อมแอปกับ alerts, incidents, และเครื่องมือแชท
สร้างโครงร่างแอป
เริ่ม UI ด้วย React และ backend Go + PostgreSQL โดยไม่ต้องเขียน boilerplate
runbooks จะมีประโยชน์มากขึ้นเมื่อเข้าถึงได้ด้วยคลิกเดียวจาก alert ที่กระตุ้นการทำงาน Integrations ช่วยลดการสลับบริบทในเหตุการณ์เมื่อคนตึงเครียดและเวลาเข้มข้น
เริ่มด้วยสัญญา integration ง่าย ๆ (webhooks + APIs)
ทีมส่วนใหญ่ครอบคลุม 80% ของความต้องการด้วยสองรูปแบบ:
- Incoming webhooks จากเครื่องมือแจ้งเตือน/incident มายังแอปของคุณ (สร้างหรืออัปเดต “incident context”, แนะนำ runbooks)
- Outgoing webhooks หรือ API calls จากแอปของคุณกลับไปยังเครื่องมือเหล่านั้น (โพสต์ลิงก์ runbook ที่เลือก, อัปเดตสถานะ, และการตัดสินใจสำคัญ)
payload ขาเข้าขั้นต่ำอาจเล็กมากเช่น:
{
"service": "payments-api",
"event_type": "5xx_rate_high",
"severity": "critical",
"incident_id": "INC-1842",
"source_url": "https://…"
}
(เนื้อหาในบล็อกโค้ดคงเดิม ไม่แปล)
deep links: พาผู้ตอบไปยัง runbook ที่เหมาะสมทันที
ออกแบบสกีม URL เพื่อให้ alert ชี้ไปยังการจับคู่ที่ดีที่สุด โดยปกติโดย service + event type (หรือแท็กเช่น database, latency, deploy) เช่น:
- ลิงก์ไปยัง runbook เฉพาะ:
/runbooks/123 - ลิงก์ไปยังมุมมอง execution พร้อมบริบท:
/runbooks/123/execute?incident=INC-1842 - ลิงก์ไปยังการค้นหาที่ตั้งค่าไว้ล่วงหน้า:
/runbooks?service=payments-api&event=5xx_rate_high
สิ่งนี้ช่วยให้ระบบแจ้งเตือนรวม URL ในการแจ้งเตือนได้ และช่วยให้คนไปยังเช็คลิสต์ที่ถูกต้องโดยไม่ต้องค้นหาเพิ่ม
การแจ้งเตือนในแชทและการแชร์ระหว่างเหตุการณ์
เชื่อมต่อกับ Slack หรือ Microsoft Teams เพื่อให้ผู้ตอบสามารถ:
- โพสต์ลิงก์ runbook ที่เลือกไปยังช่อง incident
- แชร์สรุปสั้น ๆ (“เรากำลังทำตามอะไร, ใครเป็นเจ้าของ, ขั้นตอนปัจจุบัน”)\n- เก็บ runbook ไว้ในสายตาขณะตัดสินใจ
ถ้าคุณมีเอกสารสำหรับการรวมระบบแล้ว ให้เชื่อมโยงจาก UI (เช่น /docs/integrations) และเปิดการตั้งค่าที่ทีมปฏิบัติการคาดหวัง (เพจการตั้งค่าและปุ่มทดสอบอย่างเร็ว)
ปรับใช้ รักษาความปลอดภัย และทำซ้ำโดยไม่ชะลอการปฏิบัติการ
ระบบ runbook เป็นส่วนหนึ่งของตาข่ายความปลอดภัยทางปฏิบัติการ ปฏิบัติต่อมันเหมือนบริการผลิตภัณฑ์: ปรับใช้โดยคาดการณ์ได้ ปกป้องจากความล้มเหลวทั่วไป และปรับปรุงทีละน้อยในขั้นตอนความเสี่ยงต่ำ
โฮสติ้ง, แบ็กอัพ, และการกู้คืนเมื่อเกิดภัยพิบัติ
เริ่มจากโมเดลโฮสติ้งที่ทีมปฏิบัติการของคุณสนับสนุนได้ (แพลตฟอร์มที่จัดการให้, Kubernetes, หรือ VM ง่าย ๆ) ไม่ว่าจะเลือกอย่างไร จงบันทึกไว้ใน runbook ของตัวเอง
การสำรองข้อมูลควรอัตโนมัติและทดสอบได้ ไม่พอแค่ “ถ่าย snapshot” คุณต้องมั่นใจว่าสามารถกู้คืนได้:\n
- สำรองฐานข้อมูลตามตาราง (และก่อนอัปเกรดใหญ่)\n- สำรองที่เข้ารหัสพร้อมการเข้าถึงจำกัด\n- ทดสอบการกู้คืนเป็นประจำ (เช่น รายเดือน) ในสภาพแวดล้อมแยกต่างหาก
สำหรับ DR ให้ตัดสินเป้าหมายล่วงหน้า: สามารถยอมให้ข้อมูลสูญเสียได้เท่าไร (RPO) และต้องการให้แอปคืนสภาพได้เร็วแค่ไหน (RTO) เก็บเช็คลิสต์ DR เบา ๆ ที่รวม DNS, ความลับ, และขั้นตอนกู้คืนที่ผ่านการยืนยัน
พื้นฐานประสิทธิภาพที่ป้องกันแรงเสียดทาน
runbooks มีค่าที่สุดเมื่อความกดดันสูง ดังนั้นมุ่งเป้าให้หน้าโหลดเร็วและพฤติกรรมคาดเดาได้:\n
- แคชสำหรับ endpoints ที่อ่านหนัก (รายการ runbook, เทมเพลต)\n- การแบ่งหน้าและการกรองสำหรับผลการค้นหาและมุมมอง audit\n- การจำกัดอัตราที่การพิสูจน์ตัวตนและการเขียนเพื่อลดการใช้งานผิดปกติและโหลดโดยไม่ได้ตั้งใจ
นอกจากนี้บันทึก slow queries ตั้งแต่แรก มันง่ายกว่าการเดาทีหลัง
กลยุทธ์การทดสอบที่ปกป้องความเชื่อถือ
ให้ความสำคัญกับการทดสอบฟีเจอร์ที่หากเสียจะสร้างพฤติกรรมเสี่ยง:\n
- การตรวจสอบสิทธิ์ (RBAC, ความเป็นเจ้าของ, การอนุมัติ)\n- พฤติกรรม editor (การจัดลำดับขั้นตอน, เทมเพลต, การตรวจสอบความถูกต้อง)\n- การจัดการเวอร์ชัน (diff, โฟลว์การเผยแพร่, rollback)\n เพิ่มชุด end-to-end เล็ก ๆ สำหรับ “เผยแพร่ runbook” และ “รัน runbook” เพื่อจับปัญหาการบูรณาการ
ส่งเป็นขั้นตอน ไม่ใช่ทั้งหมดในครั้งเดียว
ทดลองกับทีมหนึ่งก่อน—โดยเฉพาะกลุ่มที่ on-call บ่อย เก็บความคิดเห็นในเครื่องมือ (คอมเมนต์สั้น ๆ) และทบทวนสั้น ๆ รายสัปดาห์ ขยายอย่างค่อยเป็นค่อยไป: เพิ่มทีมถัดไป, ย้ายชุด SOP ถัดไป, และปรับเทมเพลตตามการใช้งานจริงแทนสมมติฐาน
เร่งการส่งมอบด้วย Koder.ai (โดยไม่เปลี่ยนรูปแบบการเป็นเจ้าของของคุณ)
ถ้าต้องการเปลี่ยนจากแนวคิดเป็นเครื่องมือภายในที่ใช้งานได้อย่างรวดเร็ว แพลตฟอร์ม vibe-coding อย่าง Koder.ai สามารถช่วยให้คุณสร้างต้นแบบแอปจัดการ runbook แบบ end-to-end จากสเป็กที่คุยกันในแชท คุณสามารถทำซ้ำวงจรพื้นฐาน (library → editor → execution mode) แล้วส่งออกซอร์สโค้ดเมื่อพร้อมสำหรับการตรวจสอบ การเสริมความปลอดภัย และการรันภายในกระบวนการวิศวกรรมมาตรฐานของคุณ
Koder.ai เหมาะกับผลิตภัณฑ์ประเภทนี้เพราะสอดคล้องกับทางเลือกการใช้งานทั่วไป (React สำหรับ UI เว็บ; Go + PostgreSQL สำหรับ backend) และรองรับโหมดวางแผน, snapshots, และ rollback—มีประโยชน์เมื่อทำซ้ำฟีเจอร์ที่สำคัญทางปฏิบัติการเช่น versioning, RBAC, และ audit trails
คำถามที่พบบ่อย
What should we define before building a runbook management app?
กำหนดขอบเขตก่อน: ว่าคุณหมายถึง playbooks สำหรับ incident response, SOPs, งานบำรุงรักษา หรืองาน support ใด ๆ
สำหรับแต่ละประเภท runbook ให้ระบุมาตรฐานขั้นต่ำ (เจ้าของ, บริการที่เกี่ยวข้อง, วันที่ทบทวนล่าสุด, เกณฑ์ “เสร็จ” และเน้นไปที่ขั้นตอนสั้น สแกนได้ง่าย) เพื่อป้องกันไม่ให้แอปกลายเป็นที่เก็บเอกสารแบบสุ่ม
Which success metrics work best for a runbook web app?
เริ่มจาก 2–4 ผลลัพธ์หลักและผูกกับตัวชี้วัดที่วัดได้ เช่น:
- เวลาในการหาคู่มือที่ถูกต้อง (search-to-open)
- อัตราการทำงานเสร็จสำหรับงานที่ต้องทำซ้ำ
- เวลาที่ใช้แก้ปัญหาเมื่อมี playbook เทียบกับไม่มี
- % ของ runbooks ที่ถูกทบทวนใน 90 วันที่ผ่านมา
ตัวชี้วัดเหล่านี้ช่วยให้คุณจัดลำดับความสำคัญของฟีเจอร์และตรวจสอบว่าแอปช่วยปรับปรุงการปฏิบัติการจริงหรือไม่
How do we gather requirements that match real on-call behavior?
สังเกตพฤติกรรมจริงระหว่างการเกิดเหตุและงานประจำ แล้วเก็บ:
- เรื่องเล่าความเจ็บปวดเฉพาะ (เกิดอะไรขึ้น, ทีมพยายามอย่างไร, อะไรล้มเหลว)
- ที่ที่ runbooks อยู่ตอนนี้ (wiki, repo, เอกสาร, ตั๋ว)
- วงจรชีวิต (สร้าง → ทบทวน → ใช้ → อัปเดต) และใครรับผิดชอบในแต่ละขั้นตอน
เปลี่ยนเรื่องเล่าเหล่านี้เป็น acceptance criteria สำหรับการค้นหา, การแก้ไข, สิทธิ์การเข้าถึง และการจัดการเวอร์ชัน
What data model do we need for runbooks, steps, and services?
โมเดลข้อมูลพื้นฐานที่ต้องมี:
- Runbook, Step, Tag, Service, Owner
- Version (snapshot ที่ไม่เปลี่ยนแปลง)
- Execution (การรันที่บันทึกไว้)
ใช้ความสัมพันธ์ many-to-many เมื่อความเป็นจริงต้องการ (runbook↔service, runbook↔tags) และเก็บการอ้างอิงถึงกฎการแจ้งเตือน/ประเภท incident เพื่อให้การเชื่อมต่อเสนอ playbook ที่เหมาะสมได้เร็วขึ้น
How should versioning work (draft vs. published)?
ปฏิบัติต่อเวอร์ชันเป็นแบบ append-only, immutable
รูปแบบปฏิบัติได้คือ Runbook ชี้ไปยัง:
current_draft_version_idcurrent_published_version_id
การแก้ไขสร้าง draft ใหม่; การเผยแพร่จะยกระดับ draft เป็น published version ใหม่ เก็บเวอร์ชันที่เผยแพร่ไว้เพื่อการตรวจสอบย้อนหลัง
What features belong in the MVP versus later releases?
MVP ควรรองรับวงจรหลักอย่างน่าเชื่อถือ:
- ไลบรารี/รายการ
- หน้าอ่าน-only ที่โหลดเร็ว
- สร้าง + แก้ไข (draft)
- เผยแพร่
- การค้นหาแบบ full-text
หากสิ่งเหล่านี้ช้า หรือสับสน ฟีเจอร์ที่ “น่าเพิ่ม” จะไม่ถูกใช้งานในช่วงความกดดัน
How do we design an editor that produces clear, repeatable steps?
เลือกรูปแบบ editor ที่ตรงกับทีมของคุณ:
- Markdown: เร็วสำหรับ power users แต่รูปแบบอาจไม่สอดคล้อง
- Block editor: สมดุลระหว่างโครงสร้างและการอ่าน
- Form-based steps: ให้ความสม่ำเสมอสูงสุด
ทำให้ขั้นตอนเป็นวัตถุชั้นหนึ่ง (command/link/decision/checklist/caution) และเพิ่ม guardrails เช่น ฟิลด์บังคับ, การตรวจลิงก์, และการพรีวิวที่ตรงกับ execution mode
What should “execution mode” include for incident response and routine tasks?
มุมมองเช็คลิสต์ที่ปลอดสิ่งรบกวนซึ่งบันทึกสิ่งที่เกิดขึ้น:
- สถานะขั้นตอน (Not started / In progress / Blocked / Done)
- ปุ่ม Mark complete / Skip
- โน้ตต่อขั้นตอน, ลิงก์, และไฟล์เป็นหลักฐาน (มี timestamp)
- การแตกกิ่ง (if/then) และการกระทำ “stop & escalate”
บันทึกการรันแต่ละครั้งเป็น execution record ที่ไม่เปลี่ยนแปลงและผูกกับเวอร์ชันของ runbook ที่ใช้
How do we make runbooks easy to find in seconds during an incident?
ออกแบบการค้นหาเป็นฟีเจอร์หลัก:
- ทำดัชนีชื่อ, แท็ก, บริการ และเนื้อหารายขั้นตอน (คำสั่ง, URL, ข้อความผิดพลาด)
- รองรับการจับคู่บางส่วนและการสะกดผิด
- เพิ่มฟิลเตอร์ที่สะท้อนความคิดของทีมปฏิบัติการ (service, severity, environment, owner, last reviewed)
- เก็บพจนานุกรมคำพ้องความหมายแบบ lightweight เพื่อจับคำที่ทีมใช้จริง
หน้า runbook ควรออกแบบให้สแกนง่าย: ขั้นตอนสั้น, เมตาดาต้าที่เด่น, ปุ่มคัดลอก, และ runbooks ที่เกี่ยวข้อง
How should we handle permissions, governance, and audit trails safely?
เริ่มด้วย RBAC แบบเรียบง่าย (Viewer/Editor/Admin) และกำหนดสิทธิ์ตามทีมหรือบริการ พร้อมตัวเลือก override ระดับ runbook สำหรับเนื้อหาความเสี่ยงสูง
สำหรับการกำกับดูแล เพิ่ม:
- ความเป็นเจ้าของที่ชัดเจน (Primary + Backup)
- วันกำหนดทบทวนและการเตือน
- สรุปการเปลี่ยนแปลงเมื่อแก้ไข
- โฟลว์อนุมัติง่าย ๆ (Draft → In review → Published)
บันทึก audit เป็นเหตุการณ์แบบ append-only (who/what/when, การเผยแพร่, การอนุมัติ, การเปลี่ยนเจ้าของ) และออกแบบ auth ให้รองรับ SSO (OAuth/SAML) ในอนาคตโดยไม่ทำลายตัวบ่งชี้ผู้ใช้