29 มี.ค. 2568·3 นาที
การสร้างเว็บแอปเพื่อรันเวิร์กโฟลว์การมอดเรตเนื้อหา
เรียนรู้วิธีออกแบบและสร้างเว็บแอปสำหรับการมอดเรตเนื้อหา: คิว บทบาท นโยบาย การยกระดับ บันทึกตรวจสอบ การวิเคราะห์ และการรวมระบบที่ปลอดภัย
กำหนดขอบเขตและตัวชี้วัดความสำเร็จ
ก่อนออกแบบเวิร์กโฟลว์การมอดเรตเนื้อหา ให้ตัดสินใจว่าคุณกำลังมอดเรตอะไรจริง ๆ และคำว่า “ดี” เป็นอย่างไร ขอบเขตที่ชัดเจนช่วยป้องกันไม่ให้คิวของคุณเต็มไปด้วยกรณีย่อย ซ้ำซ้อน และคำขอที่ไม่ควรอยู่ในนั้น
เนื้อหาอะไรนับเป็น “content” บ้าง
จดทุกรูปแบบเนื้อหาที่อาจสร้างความเสี่ยงหรือทำให้ผู้ใช้ได้รับอันตราย ตัวอย่างทั่วไปได้แก่ ข้อความที่ผู้ใช้สร้าง (คอมเมนต์ โพสต์ รีวิว), รูปภาพ, วิดีโอ, ไลฟ์, ฟิลด์โปรไฟล์ (ชื่อ ประวัติ รูปประจำตัว), ข้อความตรง (DM), กลุ่มชุมชน และรายการตลาด (ชื่อ หัวข้อ รูปภาพ ราคาตั้ง)
นอกจากนั้นให้จด แหล่งที่มา: การส่งจากผู้ใช้, การนำเข้าอัตโนมัติ, การแก้ไขรายการเดิม และรายงานจากผู้ใช้รายอื่น สิ่งนี้ช่วยหลีกเลี่ยงการสร้างระบบที่ใช้งานได้แค่ “โพสต์ใหม่” แต่พลาดการแก้ไข การอัปโหลดซ้ำ หรือการละเมิดใน DM
เป้าหมายของคุณ (และการแลกเปลี่ยน)
ทีมส่วนใหญ่จะจัดสมดุลระหว่างเป้าหมายสี่ประการ:
- ความเร็ว: เวลาถึงการตัดสินใจสั้น เพื่อให้เนื้อหาที่เป็นอันตรรถได้รับการจัดการอย่างรวดเร็ว
- ความสม่ำเสมอ: กรณีที่คล้ายกันได้รับผลลัพธ์คล้ายกันในผู้ตรวจคนต่าง ๆ
- การปฏิบัติตามนโยบาย & ความปลอดภัย: การตัดสินใจสอดคล้องกับกฎและภาระหน้าที่ตามกฎหมาย
- ควบคุมค่าใช้จ่าย: เวลาของผู้ตรวจมีจำกัด; การอัตโนมัติและการให้ลำดับความสำคัญมีความสำคัญ
ระบุอย่างชัดเจนว่าเป้าหมายใดเป็นหลักในแต่ละด้าน ตัวอย่างเช่น กรณีการละเมิดร้ายแรงสูงอาจให้ความสำคัญกับความเร็วมากกว่าความสม่ำเสมอที่สมบูรณ์แบบ
การกระทำที่ต้องรองรับ
ลิสต์ผลลัพธ์ทั้งหมดที่ผลิตภัณฑ์ของคุณต้องการ: อนุมัติ, ปฏิเสธ/ลบ, แก้ไข/เซ็นเซอร์, ติดป้าย/จำกัดอายุ, จำกัดการมองเห็น, วางภายใต้การตรวจสอบ, ยกระดับให้หัวหน้า, และการกระทำระดับบัญชีเช่น การเตือน การล็อกชั่วคราว หรือการแบน
ตัวชี้วัดความสำเร็จที่ต้องติดตาม
กำหนดเป้าหมายที่วัดได้: เวลาตัดสินใจค่ากลางและเปอร์เซ็นไทล์ที่ 95, ขนาดค้างงาน, อัตราการถูกกลับคำหลังอุทธรณ์, ความแม่นยำตามนโยบายจากการสุ่ม QA, และเปอร์เซ็นต์ของไอเทมร้ายแรงสูงที่ถูกจัดการภายใน SLA
ผู้มีส่วนได้ส่วนเสียที่ควรเชิญมาร่วมตั้งแต่ต้น
รวมผู้ตรวจ ทีมผู้นำ นโยบาย ฝ่ายซัพพอร์ต วิศวกรรม และกฎหมาย ความไม่สอดคล้องที่นี่จะทำให้ต้องแก้ไขงานซ้ำในภายหลัง—โดยเฉพาะเรื่องความหมายของ “การยกระดับ” และใครเป็นผู้ตัดสินใจขั้นสุดท้าย
จำลองเวิร์กโฟลว์การมอดเรตตั้งแต่ต้นจนจบ
ก่อนสร้างหน้าจอและคิว ให้ร่างวงจรชีวิตของชิ้นเนื้อหาเดียวอย่างครบถ้วน เวิร์กโฟลว์ที่ชัดเจนช่วยป้องกัน “สถานะปริศนา” ที่ทำให้ผู้ตรวจสับสน ทำให้การแจ้งเตือนขาดตอน และทำให้การตรวจสอบลำบาก
แม็ปวงจรชีวิตเป็นสถานะที่ชัดเจน
เริ่มด้วยโมเดลสถานะเรียบง่ายที่คุณสามารถวางในไดอะแกรมและฐานข้อมูลได้:
Submitted → Queued → In review → Decided → Notified → Archived
ทำให้สถานะแยกจากกันอย่างชัดเจน และนิยามการเปลี่ยนผ่านที่อนุญาต (และโดยใคร) ตัวอย่าง: “Queued” สามารถย้ายไป “In review” ได้เมื่อถูกมอบหมายเท่านั้น และ “Decided” ควรไม่สามารถเปลี่ยนแปลงได้ ยกเว้นผ่านกระบวนการอุทธรณ์
แยกสัญญาณอัตโนมัติออกจากการตัดสินของมนุษย์
ตัวจัดประเภทอัตโนมัติ การจับคีย์เวิร์ด ขีดจำกัดอัตรา และรายงานผู้ใช้ควรถูกมองเป็น สัญญาณ ไม่ใช่การตัดสินใจ การออกแบบแบบ “มนุษย์ในวงจร” ช่วยให้ระบบไม่เบี้ยว:
- สัญญาณมีผลต่อการจัดลำดับความสำคัญและการแนะนำการกระทำ
- การตัดสินใจของผู้ตรวจเป็นผลลัพธ์ที่เป็นเกณฑ์สำคัญ
การแยกเช่นนี้ยังทำให้การปรับปรุงโมเดลง่ายขึ้นในอนาคตโดยไม่ต้องเขียนตรรกะนโยบายใหม่
วางแผนสำหรับการอุทธรณ์และการรีวิวซ้ำ
การตัดสินใจจะถูกท้าทาย เพิ่มฟลว์ระดับหนึ่งสำหรับ:
- การส่งอุทธรณ์ของผู้ใช้ (เชื่อมกับเคสต้นฉบับ)
- การรีวิวใหม่โดยผู้ตรวจคนอื่นหรือทีมเฉพาะทาง
- ผลลัพธ์ที่เป็นไปได้: ยืนยัน, ยกเลิก, แก้ไข, หรือขอข้อมูลเพิ่มเติม
โมเดลการอุทธรณ์เป็นเหตุการณ์รีวิวใหม่แทนการแก้ไขประวัติ แบบนี้คุณสามารถเล่าเรื่องราวเต็มได้ว่ามีอะไรเกิดขึ้นบ้าง
ตัดสินใจว่าต้องเก็บอะไรไว้ให้ตรวจสอบได้
สำหรับการตรวจสอบและข้อพิพาท ให้กำหนดขั้นตอนที่ต้องถูกบันทึกพร้อมเวลาและตัวดำเนินการ:
- การเปลี่ยนแปลงการมอบหมาย
- หลักฐานที่ถูกเปิดดู (เมื่อเหมาะสม)
- การตัดสินใจ เหตุผลทางนโยบาย และการดำเนินการบังคับใช้
- การแจ้งเตือนที่ส่งออกไป
ถ้าคุณอธิบายการตัดสินใจหลังทีหลังไม่ได้ ให้สมมติว่ามันยังไม่เกิดขึ้น
ออกแบบบทบาท สิทธิ์ และโครงสร้างทีม
เครื่องมือมอดเรตอยู่รอดหรือพังจากการควบคุมการเข้าถึง ถ้าทุกคนทำได้ทุกอย่าง คุณจะได้การตัดสินใจที่ไม่สม่ำเสมอ การเปิดเผยข้อมูลโดยไม่ตั้งใจ และไม่มีความรับผิดชอบชัดเจน เริ่มจากการนิยามบทบาทที่สอดคล้องกับวิธีการทำงานจริงของทีม Trust & Safety แล้วแปลงเป็นสิทธิ์ที่แอปของคุณบังคับใช้ได้
บทบาทหลักที่ควรรองรับ
ทีมส่วนใหญ่ต้องการชุดบทบาทที่ชัดเจนเล็ก ๆ:
- Moderator: ตรวจสอบไอเทมในคิว มอบผลลัพธ์ (อนุมัติ/ลบ/ติดป้าย) และทิ้งบันทึกภายใน
- Senior reviewer: ทำได้ทุกอย่างที่ moderator ทำได้ บวกการ override, จัดการการยกระดับ และการโค้ช
- Policy editor: ปรับปรุงข้อความนโยบาย คำนิยามกฎ และแนวทางการตัดสินใจ แต่ไม่สามารถมอดเรตโดยตรง
- Admin: จัดการผู้ใช้ บทบาท การตั้งค่าทีม การรวมระบบ และการกระทำความเสี่ยงสูง
- Read-only: ดูแดชบอร์ด เคส และรายการบันทึกตรวจสอบได้ แต่ไม่เปลี่ยนแปลงอะไร
การแยกหน้าที่เช่นนี้ช่วยหลีกเลี่ยง “การเปลี่ยนนโยบายโดยไม่ตั้งใจ” และทำให้อำนาจการกำกับดูแลนโยบายแตกต่างจากการบังคับใช้งานประจำวัน
สิทธิ์แบบ least-privilege (RBAC)
ใช้งาน role-based access control ให้แต่ละบทบาทได้เฉพาะสิ่งที่ต้องการ:
- จำกัดว่าใครสามารถ ดูข้อมูลผู้ใช้ที่ละเอียดอ่อน (PII, รายงาน, สัญญาณอุปกรณ์)
- จำกัดการกระทำที่มีผลกระทบสูง เช่น ตัดสินใจเป็นชุด, การลงโทษระดับบัญชี, และ การลบเคส
- แยกสิทธิ์ตามความสามารถ (เช่น
can_apply_outcome,can_override,can_export_data) แทนการแยกตามหน้าเว็บ
ถ้าคุณเพิ่มฟีเจอร์ใหม่ (exports, automations, การรวมภายนอก) คุณสามารถผูกกับสิทธิ์โดยไม่ต้องนิยามโครงสร้างองค์กรใหม่ทั้งหมด
โครงสร้างหลายทีม (ภาษา ภูมิภาค ผลิตภัณฑ์)
วางแผนสำหรับหลายทีมตั้งแต่แรก: กลุ่มภาษา ทีมตามภูมิภาค หรือสายผลิตภัณฑ์ที่แยกต่างหาก โมเดลทีมอย่างชัดเจน แล้วกำหนดขอบเขตคิว การมองเห็นเนื้อหา และการมอบหมายตามทีม วิธีนี้ป้องกันการรีวิวข้ามภูมิภาคผิดพลาดและทำให้การวัดงานต่อทีมเป็นไปได้
การเลียนแบบผู้ใช้ (impersonation) และการอนุมัติ
บางครั้งแอดมินต้องเลียนแบบผู้ใช้เพื่อตรวจดีบักการเข้าถึงหรือทำซ้ำปัญหาผู้ตรวจ จัดการการเลียนแบบเป็นการกระทำที่ละเอียดอ่อน:
- ต้องมี สิทธิ์เฉพาะ ในการเลียนแบบ
- บันทึก ใครเลียนแบบใคร, เมื่อไร, และเหตุผล
- แสดงแบนเนอร์ “กำลังเลียนแบบ” แบบถาวรและปิดการกระทำที่มีความเสี่ยงโดยค่าเริ่มต้น
สำหรับการกระทำที่ไม่สามารถย้อนกลับหรือความเสี่ยงสูง ให้เพิ่ม การอนุมัติแอดมิน (หรือการตรวจสอบสองคน) ความฝืดเล็กน้อยนี้ปกป้องจากความผิดพลาดและการละเมิดจากภายใน ขณะเดียวกันก็ยังคงให้การมอดเรตประจำวันเร็ว
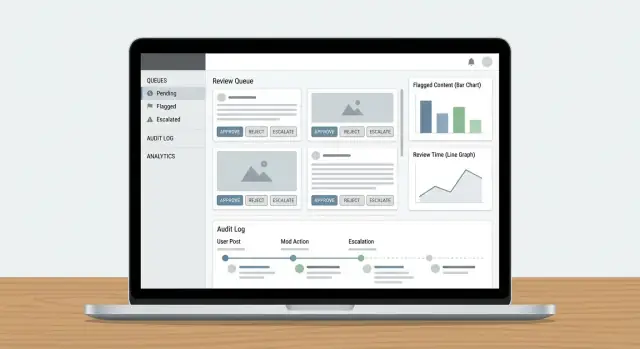
สร้างคิว การให้ลำดับความสำคัญ และการมอบหมาย
คิวคือที่ทำงานของการมอดเรต กลายเป็นการจัดการได้ แทนที่จะเป็นรายการไม่สิ้นสุด แยกงานเป็นคิวที่สะท้อนความเสี่ยง ความเร่งด่วน และเจตนา—แล้วทำให้ยากที่ไอเทมจะหลุดผ่านช่องว่าง
กำหนดประเภทคิว
เริ่มจากชุดคิวเล็ก ๆ ที่ตรงกับการทำงานของทีมจริง ๆ:
- New items: เนื้อหาใหม่รอการรีวิวครั้งแรก
- High-risk: ไอเทมที่มีแนวโน้มทำให้เกิดอันตราย (เช่น สัญญาณผู้เยาว์, สัญญาณทำร้ายตัวเอง, รูปแบบหลอกลวงที่รู้จัก)
- Escalations: ทุกสิ่งที่ผู้ตรวจไม่มั่นใจหรือที่ต้องผู้เชี่ยวชาญ
- Appeals: คำขอจากผู้ใช้ขอให้พิจารณาการตัดสินใหม่
- Backlog: ไอเทมเก่า ความเร่งด่วนน้อย หรือล้นในช่วงพีค
เก็บคิวให้แยกกันเมื่อเป็นไปได้ (ไอเทมควรมีหนึ่ง “บ้าน”) และใช้แท็กสำหรับคุณสมบัติรอง
เลือกกฎการให้ลำดับความสำคัญที่ไม่ถูกเล่นงานได้ง่าย
ภายในแต่ละคิว กำหนดกฎให้คะแนนที่กำหนดว่าอะไรควรขึ้นสู่อันดับบนสุด:
- ความรุนแรง (หมวดหมู่นโยบาย + ความมั่นใจ)
- การแพร่กระจาย/การเข้าถึง (ยอดดู ยอดแชร์ จำนวนผู้ติดตาม)
- รายงานผู้ใช้ (จำนวน ชื่อเสียงของผู้รายงาน ผู้รายงานไม่ซ้ำ)
- ตัวจับเวลา SLA (อายุ วันกำหนดยกระดับ เวลาตั้งแต่รายงานแรก)
ทำให้ลำดับความสำคัญอธิบายได้ใน UI (“ทำไมฉันเห็นชิ้นนี้?”) เพื่อให้ผู้ตรวจเชื่อถือการเรียงลำดับ
ป้องกันงานซ้ำด้วยการ claim + timeout
ใช้ claiming/locking: เมื่อผู้ตรวจเปิดไอเทม ไอเทมจะถูกมอบหมายให้พวกเขาและซ่อนจากคนอื่น เพิ่ม timeout (เช่น 10–20 นาที) เพื่อให้ไอเทมที่ถูกละทิ้งกลับเข้าคิวเสมอ บันทึกเหตุการณ์ claim, release, และ completion เสมอ
จัดการความเป็นธรรม: หลีกเลี่ยงอคติ “งานง่าย”
ถ้าระบบให้รางวัลความเร็ว ผู้ตรวจอาจเลือกเคสที่เร็วและข้ามเคสยาก ตอบโต้ด้วย:
- มอบหมายงานบางส่วนโดยอัตโนมัติ\n- ผสมระดับความยาก (smart batching)\n- สลับคิวที่มีผลกระทบสูงผ่านทีม\n เป้าหมายคือการครอบคลุมที่สม่ำเสมอ ไม่ใช่แค่ปริมาณงานสูง
แปลงนโยบายเป็นกฎที่บังคับใช้ได้
สร้างบน React และ Go
รับ frontend React พร้อม backend Go และ PostgreSQL ที่คุณสามารถต่อยอดได้
นโยบายที่มีอยู่แค่เป็น PDF จะถูกตีความแตกต่างกันโดยผู้ตรวจแต่ละคน เพื่อให้การตัดสินสม่ำเสมอ (และตรวจสอบได้) แปลงข้อความนโยบายเป็นข้อมูลเชิงโครงสร้างและตัวเลือกใน UI ที่เวิร์กโฟลว์ของคุณจะบังคับใช้
สร้าง taxonomy ของนโยบาย
เริ่มจากการแบ่งนโยบายเป็นพจนานุกรมร่วมที่ผู้ตรวจสามารถเลือกได้ พจนานุกรมที่มีประโยชน์มักประกอบด้วย:
- Category (เช่น Harassment, Adult content, Misinformation)
- Violation type (เช่น Hate speech vs. general insult)
- Severity level (เช่น Low/Medium/High/Critical)
- Required evidence (สิ่งที่ต้องมีเพื่อใช้บังคับนโยบาย—วลีเฉพาะ บริบท รายงาน ลิงก์ เวลาประทับ)
taxonomy นี้เป็นรากฐานสำหรับคิว การยกระดับ และการวิเคราะห์ในภายหลัง
ใช้เทมเพลตการตัดสินใจเพื่อลดความไม่สม่ำเสมอ
แทนที่จะให้ผู้ตรวจเขียนการตัดสินใจทุกครั้ง ให้มี decision templates ผูกกับรายการ taxonomy เทมเพลตสามารถเติมล่วงหน้า:
- การกระทำที่แนะนำ (remove, label, restrict, warn, no action)
- ข้อความสำหรับผู้ใช้ (แก้ไขได้แต่มีแนวทาง)
- เช็คลิสต์ภายใน (หลักฐานที่ต้องยืนยัน)
เทมเพลตทำให้เส้นทางปกติเร็ว ในขณะที่ยังอนุญาตข้อยกเว้นได้
รองรับการจัดการเวอร์ชันนโยบายและวันที่มีผล
นโยบายเปลี่ยนแปลง เก็บนโยบายเป็นเร็กคอร์ดที่มีเวอร์ชันและ วันที่มีผล และบันทึกเวอร์ชันที่ถูกนำไปใช้ในแต่ละการตัดสินใจ วิธีนี้ป้องกันความสับสนเมื่อเคสเก่าถูกอุทธรณ์และทำให้คุณอธิบายผลลัพธ์ย้อนหลังได้
เก็บเหตุผลเชิงโครงสร้าง (ไม่ใช่แค่ข้อความฟรี)
ข้อความฟรีวิเคราะห์ยากและลืมง่าย บังคับให้ผู้ตรวจเลือกหนึ่งหรือหลาย เหตุผลเชิงโครงสร้าง (จาก taxonomy) และเลือกเขียนโน้ตเพิ่มเติม เหตุผลเชิงโครงสร้างช่วยการจัดการอุทธรณ์ การสุ่มตัวอย่าง QA และการรายงานแนวโน้ม โดยไม่บังคับให้ผู้ตรวจเขียนยาว
ออกแบบแดชบอร์ดผู้ตรวจและ UX
ส่งบันทึกตรวจสอบตั้งแต่เนิ่นๆ
สร้างเหตุการณ์ audit และประวัติการตัดสินใจเพื่อให้การสืบสวนและอุทธรณ์อธิบายได้
แดชบอร์ดผู้ตรวจสำเร็จเมื่อมันลดการ “ค้นหา” ข้อมูลและเพิ่มการตัดสินใจที่มั่นใจและทำซ้ำได้ ผู้ตรวจควรเข้าใจว่าเกิดอะไรขึ้น ทำไมถึงสำคัญ และจะต้องทำอะไรต่อไป—โดยไม่ต้องเปิดหลายแท็บ
แสดงเนื้อหาพร้อมบริบทที่เหมาะสม
อย่าแสดงโพสต์แยกออกมาแล้วหวังผลลัพธ์ที่สม่ำเสมอ เสนอแผงบริบทกะทัดรัดที่ตอบคำถามทั่วไปได้ในทันที:
- มุมมองบทสนทนา/เธรด: ข้อความก่อนหน้าและหลังไอเทมที่ถูกทำเครื่องหมาย โดยไฮไลต์ชัดเจนที่เนื้อหาที่ถูกรายงาน
- ประวัติผู้ใช้: การเตือน การระงับ การลบก่อนหน้า และผลการอุทธรณ์ (จำกัดช่วงเวลาเพื่อให้เกี่ยวข้อง)
- การกระทำก่อนหน้า: ใครเคยจัดการไอเทมนี้ก่อนหน้า ตัดสินใจอย่างไร และมีโน้ตอะไรบ้าง
เก็บมุมมองเริ่มต้นให้กระชับ โดยมีตัวเลือกขยายสำหรับการดูลึก ผู้ตรวจควรแทบไม่ต้องออกจากแดชบอร์ดเพื่อจะตัดสินใจ
การกระทำที่เร็วและจับคู่กับการตัดสินใจจริง
แถบการกระทำของคุณควรจับคู่กับผลลัพธ์นโยบาย ไม่ใช่ปุ่ม CRUD ทั่วไป รูปแบบทั่วไปได้แก่:
- Approve / Reject ด้วยคลิกเดียว
- การติดป้าย (เช่น spam, harassment, self-harm, misinformation) เพื่อการรายงานและการฝึกสอน
- แก้ไขหรือเซ็นเซอร์ (เมื่อกฎอนุญาตให้ลบบางส่วน)
- ยกระดับ ให้ผู้เชี่ยวชาญหรือการรีวิวระดับสอง
- ขอข้อมูลเพิ่มเติม (สำหรับกรณีคลุมเครือ) พร้อมข้อความเทมเพลต
ทำให้การกระทำที่มองเห็นและขั้นตอนที่ไม่สามารถย้อนกลับชัดเจน (ยืนยันเฉพาะเมื่อจำเป็น) จับรหัสเหตุผลสั้น ๆ และโน้ตตัวเลือกสำหรับการตรวจสอบภายหลัง
ฟีเจอร์ความเร็ว: คีย์ลัดและการกระทำเป็นชุด
งานปริมาณสูงต้องการแรงเสียดทานต่ำ เพิ่มคีย์ลัดสำหรับการกระทำหลัก (approve, reject, next item, add label) และแสดง cheat-sheet คีย์ลัดใน UI
สำหรับคิวที่งานซ้ำมาก (เช่น สแปมชัดเจน) รองรับ การเลือกแบบเป็นชุด โดยมีเกราะป้องกัน: แสดงจำนวนตัวอย่าง ยืนยันรหัสเหตุผล และบันทึกการกระทำแบบเป็นชุด
ออกแบบเพื่อความปลอดภัยของผู้ตรวจ
การมอดเรตอาจทำให้ผู้คนเจอเนื้อหาที่เป็นอันตราย เพิ่มค่าเริ่มต้นด้านความปลอดภัย:
- เบลอสื่อที่อ่อนไหว โดยค่าเริ่มต้น พร้อมคลิกเพื่อเปิดดู
- แบนเนอร์เตือน สำหรับสัญญาณทำร้ายตัวเอง เนื้อหาทางเพศ หรือความรุนแรงชัดเจน
- สวิตช์ ซ่อนเนื้อหา ด่วนที่ยังคงให้ตัดสินใจได้โดยไม่ต้องเปิดดูนาน
การเลือกเช่นนี้ปกป้องผู้ตรวจขณะยังคงรักษาความแม่นยำของการตัดสินใจ
เพิ่มบันทึกตรวจสอบและการตรวจสอบย้อนหลัง
บันทึกตรวจสอบเป็น “แหล่งความจริง” ของคุณเมื่อมีคนถามว่า: ทำไมโพสต์นี้ถูกลบ? ใครอนุมัติการอุทธรณ์? แบบจำลองหรือคนเป็นผู้ตัดสินขั้นสุดท้าย? หากไม่มีการติดตาม จะกลายเป็นการเดาและความไว้วางใจในผู้ตรวจจะลดลงอย่างรวดเร็ว
บันทึกทุกการตัดสินใจ (และหลักฐาน)
สำหรับการกระทำแต่ละครั้ง ให้บันทึก ใคร ทำ อะไร เปลี่ยนแปลงอย่างไร เวลาใด และ ทำไม (รหัสนโยบาย + โน้ต) สำคัญไม่แพ้กัน: เก็บ ภาพก่อน/หลัง ของวัตถุที่เกี่ยวข้อง—ข้อความเนื้อหา แฮชสื่อ สัญญาณที่ตรวจพบ ป้าย และผลลัพธ์สุดท้าย หากไอเทมสามารถเปลี่ยนแปลงได้ (แก้ไข ลบ) ภาพสแนปชอตช่วยป้องกันไม่ให้ “ระเบียน” ไหลไป
รูปแบบที่ปฏิบัติได้คือบันทึกเหตุการณ์แบบ append-only:
{
"event": "DECISION_APPLIED",
"actor_id": "u_4821",
"subject_id": "post_99102",
"queue": "hate_speech",
"decision": "remove",
"policy_code": "HS.2",
"reason": "slur used as insult",
"before": {"status": "pending"},
"after": {"status": "removed"},
"created_at": "2025-12-26T10:14:22Z"
}
\n\n
บันทึกเหตุการณ์คิวเพื่อความชัดเจนในการปฏิบัติงาน
นอกเหนือจากการตัดสินใจ ให้บันทึกกลไกเวิร์กโฟลว์: claimed, released, timed out, reassigned, escalated, และ auto-routed เหตุการณ์เหล่านี้อธิบายว่า “ทำไมถึงใช้เวลา 6 ชั่วโมง” หรือ “ทำไมไอเทมนี้ถึงกระเด้งระหว่างทีม” และจำเป็นสำหรับการตรวจจับการละเมิด (เช่น ผู้ตรวจคัดเลือกงานง่าย)
ทำให้ร่องรอยการตรวจสอบค้นหาได้สำหรับการสืบสวน
ให้ผู้สืบสวนกรองตามผู้ใช้, content ID, policy code, ช่วงเวลา, คิว และประเภทการกระทำ รวมการส่งออกเป็นไฟล์เคส โดยมีเวลาไม่เปลี่ยนแปลงและอ้างอิงไปยังไอเทมที่เกี่ยวข้อง (ซ้ำ อัปโหลดซ้ำ อุทธรณ์)
กำหนดกฎการเก็บข้อมูลที่สอดคล้องกับการปฏิบัติตามข้อกำหนด
ตั้งหน้าต่างการเก็บข้อมูลชัดเจนสำหรับเหตุการณ์ตรวจสอบ สแนปชอต และโน้ตของผู้ตรวจ เก็บนโยบายไว้อย่างชัดเจน (เช่น 90 วันสำหรับบันทึกคิวทั่วไป ยาวกว่าสำหรับ legal holds) และอธิบายว่าคำขอลบหรือแก้ไขมีผลกับหลักฐานที่เก็บไว้อย่างไร
เชื่อมโยงรายงาน การแจ้งเตือน และการกระทำของผู้ใช้
เครื่องมือมอดเรตมีประโยชน์เมื่อมันปิดวงจร: รายงานกลายเป็นงานรีวิว การตัดสินถูกส่งถึงคนที่เหมาะสม และการกระทำระดับผู้ใช้ถูกดำเนินการอย่างสอดคล้อง นี่คือจุดที่ระบบจำนวนมากพัง—คนหนึ่งแก้คิว แต่ไม่มีอะไรเปลี่ยนแปลงต่อ
การรับเข้า: รวมทุกรูปแบบของรายงาน
มอง รายงานผู้ใช้, สัญญาณอัตโนมัติ (สแปม/CSAM/แฮชที่ตรงกัน/สัญญาณความเป็นพิษ), และ การยกระดับภายใน (ซัพพอร์ต ผู้จัดการชุมชน กฎหมาย) เป็นวัตถุแกนเดียว: รายงาน ที่สามารถสร้างงานรีวิวหนึ่งงานหรือหลายงาน
ใช้ router รายงานเดียวที่:\n
- ลดการทำซ้ำ (เนื้อหาเดียวถูกรายงานหลายครั้ง)\n- ลิงก์ไอเทมที่เกี่ยวข้อง (ผู้แต่งเดียวกัน เธรดเดียวกัน)\n- ประยุกต์การคัดกรองเบื้องต้น (ความรุนแรง หมวดหมู่ เขตอำนาจ)\n- สร้าง/อัปเดตไอเทมในคิวการมอดเรต
ถ้าการยกระดับจากซัพพอร์ตเป็นส่วนหนึ่งของฟลว์ ลิงก์เข้าด้วยกันโดยตรง (เช่น /support/tickets/1234) เพื่อให้ผู้ตรวจไม่ต้องสลับบริบท
ผลลัพธ์: แจ้งผู้ใช้โดยไม่เพิ่มความเสี่ยงใหม่
การตัดสินการมอดเรตควรสร้างข้อความแจ้งแบบเทมเพลต: เนื้อหาถูกลบ มีการเตือน ไม่มีการกระทำ หรือมีการกระทำบัญชี รักษาข้อความสั้นและสอดคล้อง—อธิบายผล ยกอ้างนโยบายที่เกี่ยวข้อง และให้ คำแนะนำการอุทธรณ์
เชิงปฏิบัติ ส่งการแจ้งเตือนผ่านเหตุการณ์อย่าง moderation.decision.finalized เพื่อให้ระบบอีเมล/ในแอป/พุชสามารถสมัครรับได้โดยไม่ทำให้ผู้ตรวจช้าลง
การกระทำของผู้ใช้: เชื่อมกับการควบคุมบัญชี
การตัดสินมักต้องการการกระทำที่เกินกว่าเนื้อหาเดียว:
- การระงับ (ชั่วคราว/ถาวร)
- การจำกัด (ขีดจำกัดการโพสต์ ขีดจำกัด DM การ shadow ban เมื่อกฎหมายอนุญาต)
- อัปเดตระดับความน่าเชื่อถือ / ความเสี่ยง
ทำให้การกระทำเหล่านี้ชัดเจนและย้อนกลับได้ พร้อมระยะเวลาและเหตุผลชัดเจน ลิงก์ทุกการกระทำกลับไปยังการตัดสินและรายงานต้นทางเพื่อการตรวจสอบ และจัดทางลัดไปยังการอุทธรณ์เพื่อให้การทบทวนสามารถทำได้โดยไม่ต้องสืบสวนด้วยตนเอง
เลือกรูปแบบข้อมูลและกลยุทธ์การจัดเก็บ
โมเดลข้อมูลของคุณคือ “แหล่งความจริง” ว่าเกิดอะไรขึ้นกับแต่ละไอเทม: อะไรถูกรีวิว ใครเป็นผู้รีวิว ใครเป็นนโยบาย และผลลัพธ์คืออะไร ถ้าคุณตั้งชั้นนี้ถูก ทุกอย่างที่เหลือ—คิว แดชบอร์ด การตรวจสอบ และการวิเคราะห์—จะง่ายขึ้น
แยกเนื้อหา การตัดสินใจ และรหัสนโยบาย
หลีกเลี่ยงการเก็บทุกอย่างในเร็กคอร์ดเดียว รูปแบบปฏิบัติได้คือเก็บ:
- การอ้างอิงเนื้อหา (สิ่งที่ถูกรีวิว): ID คงที่ ประเภทเนื้อหา (โพสต์/คอมเมนต์/รูป/วิดีโอ), ID ผู้แต่ง เวลาสร้าง, และพอยน์เตอร์ไปยังตำแหน่งเนื้อหาดิบ
- การตัดสินใจมอดเรต (สิ่งที่ผู้ตรวจทำ): ID การตัดสินใจ, ID ผู้รีวิว, ผลลัพธ์การตัดสินใจ, เวลาต่าง ๆ, โน้ตข้อความ, และฟิลด์เชิงโครงสร้าง (เช่น ความมั่นใจ ความรุนแรง)
- รหัสนโยบาย (ทำไมตัดสิน): รหัสนโยบายมาตรฐาน เช่น
HARASSMENT.H1หรือNUDITY.N3เก็บเป็นการอ้างอิงเพื่อให้นโยบายสามารถพัฒนาโดยไม่ต้องเขียนประวัติใหม่
แบบนี้ทำให้การบังคับใช้นโยบายสอดคล้องและการรายงานชัดเจนขึ้น (เช่น “รหัสนโยบายที่ถูกละเมิดสูงสุดสัปดาห์นี้”)
เก็บสื่อขนาดใหญ่ให้ปลอดภัย
อย่าเก็บรูป/วิดีโอขนาดใหญ่ตรงในฐานข้อมูล ใช้ object storage และเก็บเพียง object keys + metadata ในตารางเนื้อหา
สำหรับผู้ตรวจ ให้สร้าง signed URLs ที่มีอายุสั้น เพื่อเข้าถึงสื่อโดยไม่ทำให้สาธารณะเข้าถึงได้ Signed URLs ช่วยให้ควบคุมการหมดอายุและเพิกถอนการเข้าถึงได้เมื่อจำเป็น
ทำดัชนีให้เร็วในจุดที่จำเป็น
คิวและการสืบสวนขึ้นกับการค้นหาเร็ว เพิ่มดัชนีสำหรับ:
- ตัวกรองคิว (สถานะ ลำดับความสำคัญ ผู้ตรวจที่มอบหมาย เวลาเริ่มสร้าง)
- การค้นหาข้อความ (เหตุผลที่ถูกรายงาน ข้อความเนื้อหาเมื่ออนุญาต)
- คิวรีบันทึกตรวจสอบ (actor ประเภทการกระทำ ช่วงเวลา content ID)
ติดตามการเปลี่ยนสถานะเพื่อป้องกันไอเทม “ติดค้าง”
โมเดลการมอดเรตเป็นสถานะชัดเจน (เช่น NEW → TRIAGED → IN_REVIEW → DECIDED → APPEALED) เก็บ เหตุการณ์การเปลี่ยนสถานะ (พร้อมเวลาและ actor) เพื่อให้คุณตรวจจับไอเทมที่ยังไม่ก้าวหน้า
การป้องกันง่าย ๆ: ฟิลด์ last_state_change_at บวกการแจ้งเตือนสำหรับไอเทมที่เกิน SLA และงานซ่อมที่นำไอเทมที่ค้าง IN_REVIEW หลัง timeout กลับเข้าคิว
ความปลอดภัย ความเป็นส่วนตัว และความต้านทานการละเมิด
เครื่องมือ Trust & Safety มักจัดการข้อมูลที่ละเอียดอ่อนที่สุดของผลิตภัณฑ์: เนื้อหาที่ผู้ใช้สร้าง รายงาน ตัวระบุบัญชี และบางครั้งคำขอทางกฎหมาย พิจารณาแอปมอดเรตเป็นระบบความเสี่ยงสูงและออกแบบความปลอดภัยและความเป็นส่วนตัวตั้งแต่แรก
การเข้าถึงที่ปลอดภัยสำหรับผู้ตรวจและแอดมิน
เริ่มจากการพิสูจน์ตัวตนที่เข้มแข็งและการควบคุมเซสชันที่เข้มงวด สำหรับทีมส่วนใหญ่ นั่นคือ:
- SSO (SAML/OIDC) เพื่อให้การเข้าถึงเป็นไปตามนโยบายตัวตนของบริษัท
- MFA สำหรับบทบาทที่มีสิทธิ์ (admins, policy editors, exports)
- ระยะเวลาเซสชันสั้น และขอการยืนยันตัวใหม่สำหรับการกระทำเสี่ยง (bulk actions, exports, เปลี่ยนบทบาท)
- IP allowlists สำหรับเครื่องมือภายในเท่านั้น เมื่อเหมาะสม (เช่น เวิร์กสเตชันผู้รับเหมา หรือช่วงเครือข่ายออฟฟิศ)
จับคู่นี้กับ RBAC เพื่อให้ผู้ตรวจเห็นเฉพาะสิ่งที่ต้องการ (เช่น หนึ่งคิว หนึ่งภูมิภาค หนึ่งประเภทเนื้อหา)
ปกป้องเนื้อหาและข้อมูลผู้ใช้ที่ละเอียดอ่อน
เข้ารหัสข้อมูล ระหว่างการส่ง (HTTPS ทุกที่) และ ขณะพัก (การเข้ารหัสฐานข้อมูล/สตอเรจที่จัดการ) แล้วมุ่งลดการเปิดเผย:
- แสดง ตัวอย่างที่ถูกเซ็นเซอร์ โดยค่าเริ่มต้น (เบลอสื่อ ปิดบังเบอร์โทร/อีเมล) พร้อมการเปิดดูที่ถูกบันทึก
- แยกสิทธิ์การดูออกจากสิทธิ์การส่งออก
- จำกัดการเข้าถึงฟิลด์ความเสี่ยงสูง (ที่อยู่จริง ข้อมูลการชำระเงิน) ให้กับบทบาทเล็ก ๆ
ถ้าคุณจัดการข้อมูลที่ต้องได้รับความยินยอมหรือประเภทพิเศษ ให้แสดงธงเหล่านั้นให้ผู้ตรวจเห็นและบังคับใช้งานใน UI (เช่น การเปิดดูจำกัดหรือกฎการเก็บข้อมูล)
ความต้านทานการละเมิดสำหรับรายงานและอุทธรณ์
จุดรับรายงานและอุทธรณ์มักเป็นเป้าการสแปมและการคุกคาม เพิ่ม:
- จำกัดอัตรา ต่อผู้ใช้/IP/อุปกรณ์
- การป้องกันบ็อต (ท้าทายในช่วงสไปก์, ตรวจจับความผิดปกติ)
- ควบคุมต้นทุน (จำกัดต่อวัน, เพิ่มความฝืดสำหรับการใช้ผิดซ้ำ)
สุดท้าย ทำให้ทุกการกระทำที่ละเอียดอ่อนสามารถตรวจสอบได้ผ่านบันทึก (ดู /blog/audit-logs) เพื่อให้คุณสืบสวนความผิดพลาดของผู้ตรวจ บัญชีที่ถูกเจาะ หรือการโจมตีแบบประสานงาน
การวิเคราะห์ QA และการปรับปรุงอย่างต่อเนื่อง
เวิร์กโฟลว์การมอดเรตจะดีขึ้นต่อเมื่อคุณวัดผลได้ การวิเคราะห์ควรบอกว่าการออกแบบคิว กฎการยกระดับ และการบังคับใช้นโยบายของคุณให้ผลการตัดสินที่สม่ำเสมอหรือไม่—โดยไม่ทำให้ผู้ตรวจหมดไฟหรือปล่อยเนื้อหาอันตรายค้างนาน
ตัวชี้วัดที่เชื่อมโยงกับการปฏิบัติงานจริง
เริ่มจากชุดตัวชี้วัดเล็ก ๆ ที่ผูกกับผลลัพธ์:
- Throughput: ไอเทมที่รีวิวต่อชั่วโมง/วัน แยกตามคิว ประเภทเนื้อหา และทีม
- Turnaround times: time-to-first-review และ time-to-resolution (ติดตามตามคิวและช่วงความสำคัญ)
- สัญญาณความถูกต้อง (ตัวชี้วัดทดแทน): อัตราการถูกยกคำหลังอุทธรณ์ การแก้ไขโดยแอดมิน และอัตราที่ยืนยันการละเมิดหลังการยกระดับ
ใส่สิ่งเหล่านี้ในแดชบอร์ด SLA เพื่อให้ผู้นำฝ่ายปฏิบัติการเห็นว่าคิวใดตามไม่ทัน และคอขวดมาจากการขาดบุคลากร กฎไม่ชัดเจน หรือการเพิ่มขึ้นของรายงาน
ความไม่ลงรอยและการสุ่มตัวอย่าง: ระบบเตือนล่วงหน้า
ความไม่ลงรอยไม่ใช่เรื่องแย่เสมอไป—มันบอกถึงกรณีขอบ ตรวจสอบ:
- อัตราความไม่ลงรอยของผู้ตรวจ บนไอเทมเดียวกัน (เช่น ตัวอย่างที่รีวิวซ้ำ)
- ผลการสุ่มตรวจ QA: อัตราผ่าน/ไม่ผ่านจากผู้ตรวจ QA และเหตุผลบ่อยที่สุด
ใช้บันทึกตรวจสอบเชื่อมทุกการตัดสินตัวอย่างกับผู้ตรวจ รหัสที่ใช้ และหลักฐาน นี่ให้ความสามารถอธิบายเวลาการโค้ชผู้ตรวจและประเมินว่า UI กำลังชักจูงให้คนเลือกไม่สอดคล้องหรือไม่
ค้นหาช่องว่างนโยบายและความต้องการฝึกอบรม
การวิเคราะห์มอดเรตควรช่วยตอบว่า: “เรากำลังเจออะไรที่นโยบายของเราไม่ครอบคลุมดี?” มองหากลุ่มเช่น:
- ความไม่ลงรอยสูงในหมวดนโยบายเฉพาะ\n- การใช้เหตุผล “อื่น/ไม่ชัดเจน” บ่อย\n- การยกระดับที่เด้งระหว่างทีม
เปลี่ยนสัญญาณเหล่านั้นเป็นการกระทำที่ชัดเจน: เขียนตัวอย่างนโยบายใหม่ เพิ่มต้นไม้ตัดสินใจในแดชบอร์ดผู้ตรวจ หรืออัปเดต presets การบังคับใช้ (เช่น ค่าเริ่มต้นสำหรับการระงับ vs การเตือน)
ปิดวงโดยไม่ทำลายความไว้วางใจ
มองการวิเคราะห์เป็นส่วนหนึ่งของระบบมนุษย์ในวงจร แบ่งปันประสิทธิภาพระดับคิวภายในทีม แต่จัดการตัวชี้วัดรายบุคคลอย่างระมัดระวังเพื่อไม่กระตุ้นให้เร่งความเร็วแลกกับคุณภาพ จับคู่ KPI เชิงปริมาณกับการประชุมปรับความเข้าใจ (calibration) และการอัปเดตนโยบายเล็ก ๆ บ่อยครั้ง—เพื่อให้เครื่องมือและผู้คนพัฒนาพร้อมกัน
การทดสอบ การเปิดตัว และการปฏิบัติการต่อเนื่อง
เครื่องมือมอดเรตล้มเหลวบ่อยสุดที่ขอบ: โพสต์แปลกประหลาด เส้นทางยกระดับหายาก และช่วงเวลาที่หลายคนแตะเคสเดียวกัน ถือว่าการทดสอบและการเปิดตัวเป็นส่วนหนึ่งของผลิตภัณฑ์ ไม่ใช่ช่องตรวจสอบสุดท้าย
ทดสอบด้วยสถานการณ์ที่สมจริง (ไม่ใช่แค่เส้นทางที่สมบูรณ์)
สร้าง “แพ็กสถานการณ์” เล็ก ๆ ที่สะท้อนงานจริง ประกอบด้วย:
- กรณียาก (สื่อผสม บัญชีถูกลบ เนื้อหาแก้ไข ความกำกวมทางภาษา)
- อุทธรณ์และการย้อนกลับ (การตัดสินถูกท้าทาย รีวิวใหม่ และถูกยกเลิก)
- ยกระดับ (ส่งต่อผู้เชี่ยวชาญ กฎหมาย) และ SLA ตามเวลา
- ความขนานกัน (สองผู้ตรวจเปิดไอเทมเดียวกัน เงื่อนไข race บนการกระทำ รายงานซ้ำ)
ใช้ปริมาณข้อมูลในสเตจจิ้งที่คล้ายโปรดักชันเพื่อดูปัญหาความช้าในคิวและปัญหาการแบ่งหน้า/ค้นหาแต่เนิ่น ๆ
เปิดใช้งานแบบเป็นขั้นตอนเพื่อปกป้อง Throughput
รูปแบบการเปิดตัวที่ปลอดภัยคือ:
- ทีมทดลอง: หนึ่งคิว จำกัดการกระทำ มีวงจร feedback รายวัน
- โหมดเงา (Shadow mode): รันระบบใหม่คู่กับของเก่า (บันทึกการตัดสินแต่ไม่บังคับใช้ต่อผู้ใช้)
- ย้ายเต็มรูปแบบ: สลับการบังคับใช้ เก็บเส้นทาง rollback และดูตัวชี้วัดหลักรายชั่วโมงในสัปดาห์แรก
โหมด shadow มีประโยชน์พิเศษสำหรับตรวจสอบกฎการบังคับใช้อัตโนมัติโดยไม่เสี่ยงผลบวกปลอม
จดคู่มือปฏิบัติและฝึกอบรมเพื่อความสม่ำเสมอ
เขียน playbooks สั้น ๆ แบบภารกิจ: “วิธีประมวลผลรายงาน,” “เมื่อไหร่ให้ยกระดับ,” “วิธีจัดการอุทธรณ์,” และ “ทำอย่างไรเมื่อระบบไม่แน่ใจ” แล้วฝึกด้วยแพ็กสถานการณ์เดียวกันเพื่อให้ผู้ตรวจได้ฝึกฟลว์ที่พวกเขาจะใช้จริง
ปฏิบัติการต่อเนื่อง: นโยบายเปลี่ยน คิวเติบโต
วางแผนการบำรุงรักษาเป็นงานต่อเนื่อง: ประเภทเนื้อหาใหม่ กฎการยกระดับที่อัปเดต การสุ่มตัวอย่าง QA เป็นระยะ และการวางแผนความจุเมื่อคิวเพิ่มขึ้น เก็บกระบวนการปล่อยนโยบายที่ชัดเจนเพื่อให้ผู้ตรวจเห็นว่ามีอะไรเปลี่ยนและเมื่อใด—และเพื่อให้สามารถเชื่อมการเปลี่ยนแปลงกับการวิเคราะห์การมอดเรตได้
สร้างสิ่งนี้ให้เร็วขึ้นด้วย Koder.ai (ตัวเลือก)
ถ้าคุณจะนำไปทำเป็นเว็บแอป งานมากส่วนหนึ่งคือโครงสร้างซ้ำ ๆ: RBAC, คิว, การเปลี่ยนสถานะ, บันทึกตรวจสอบ, แดชบอร์ด และกาวเชิงเหตุการณ์ระหว่างการตัดสินใจและการแจ้งเตือน Koder.ai สามารถเร่งการสร้างโดยให้คุณอธิบายเวิร์กโฟลว์การมอดเรตผ่านอินเทอร์เฟซแชทและสร้างรากฐานงานที่ใช้งานได้ให้คุณแก้ไขต่อ—โดยปกติจะเป็น frontend React และ backend Go + PostgreSQL
สองวิธีปฏิบัติที่ใช้ได้กับงาน Trust & Safety:
- โหมดวางแผนก่อน: ระบุตัวตน (Content, Report, ReviewTask, Decision, PolicyCode, AuditEvent), การเปลี่ยนสถานะของ state machine, และ SLA ก่อนจะสร้างโค้ด
- สแนปชอตและการย้อนกลับ: มีประโยชน์เมื่อคุณปรับแต่งกฎการยกระดับ การให้คะแนนคิว หรือเกราะป้องกันการกระทำเป็นชุด และต้องการการวนซ้ำที่ปลอดภัยและรวดเร็ว
เมื่อฐานรากพร้อม คุณสามารถส่งออกซอร์สโค้ด เชื่อมสัญญาณโมเดลที่มีอยู่เป็น “อินพุต” และเก็บการตัดสินใจของผู้ตรวจเป็นผู้มีอำนาจสุดท้าย—สอดคล้องกับสถาปัตยกรรมมนุษย์ในวงจรที่อธิบายไว้ข้างต้น.
คำถามที่พบบ่อย
How do I define the scope of “content” for a moderation web app?
เริ่มจากการระบุ ทุกประเภทเนื้อหา ที่คุณจะจัดการ (โพสต์ ความเห็น DM โปรไฟล์ รายการ สื่อ) และ ทุกแหล่งที่มา (การส่งใหม่ แก้ไข การนำเข้า รายงานจากผู้ใช้ และสัญญาณอัตโนมัติ) แล้วกำหนดสิ่งที่ ไม่อยู่ในขอบเขต (เช่น โน้ตภายในของแอดมิน เนื้อหาที่ระบบสร้างขึ้น) เพื่อไม่ให้คิวกลายเป็นที่ทิ้งขยะ
เช็คปฏิบัติ: ถ้าคุณไม่สามารถระบุประเภทเนื้อหา แหล่งที่มา และทีมเจ้าของได้ มันอาจยังไม่ควรสร้างงานมอดเรต
What success metrics should I track for a moderation workflow?
เลือก KPI ปฏิบัติการเล็ก ๆ ที่สะท้อนทั้งความเร็วและคุณภาพ:
- เวลาตัดสินใจกลาง (median) และ p95
- ขนาด backlog (รวมและแยกตามคิว)
- การปฏิบัติตาม SLA สำหรับไอเทมความรุนแรงสูง
- อัตราการถูกยกเลิกหลังอุทธรณ์ (และเหตุผล)
- ความแม่นยำจากการสุ่ม QA
ตั้งเป้าต่อคิว (เช่น high-risk vs backlog) เพื่อไม่ให้เผลอไปปรับปรุงงานที่ไม่เร่งด่วนขณะที่เนื้อหาเป็นอันตรอยังคงรออยู่
What’s a good end-to-end state machine for moderation cases?
ใช้โมเดลสถานะที่เรียบง่ายและชัดเจนแล้วบังคับให้มีการเปลี่ยนผ่านที่อนุญาต เช่น:
SUBMITTED → QUEUED → IN_REVIEW → DECIDED → NOTIFIED → ARCHIVED
ทำให้สถานะ แยกกันอย่างชัดเจน และถือว่า “Decided” ควรไม่เปลี่ยนเว้นแต่จะผ่านการ อุทธรณ์/รีวิวใหม่ วิธีนี้ป้องกัน “สถานะปริศนา,” การแจ้งเตือนผิดพลาด และการแก้ไขที่ตรวจสอบยาก
How should I integrate automated classifiers without letting them “decide”?
มองระบบอัตโนมัติเป็น สัญญาณ ไม่ใช่ผลการตัดสินขั้นสุดท้าย:
- โมเดล/การจับคีย์เวิร์ด/รายงานจะช่วยกำหนด ลำดับความสำคัญ, การแนะนำการกระทำ, และ การกำหนดเส้นทาง
- การตัดสินใจของผู้ตรวจสอบเป็นผลลัพธ์ที่เป็น ผู้มีอำนาจเด็ดขาด
แบบนี้จะทำให้นโยบายอธิบายได้ และทำให้สามารถปรับปรุงโมเดลภายหลังโดยไม่ต้องเขียนตรรกะนโยบายใหม่
How do I design an appeals and re-review process?
ทำให้อุทธรณ์เป็นวัตถุชั้นหนึ่งที่เชื่อมกับการตัดสินใจต้นฉบับ:
- การอุทธรณ์ของผู้ใช้สร้าง เหตุการณ์รีวิวใหม่ (อย่าไปเขียนประวัติเดิมทับ)
- ส่งให้ผู้ตรวจคนอื่นหรือทีมเฉพาะทาง
- ผลลัพธ์ที่เป็นไปได้: ยืนยัน, เปลี่ยนแปลง, แก้ไข, หรือ ขอข้อมูลเพิ่มเติม
บันทึกด้วยว่าเวอร์ชันนโยบายใดถูกใช้ตอนตัดสินครั้งแรกและเวอร์ชันใดถูกใช้ระหว่างการอุทธรณ์
What roles and permissions should a moderation tool support?
เริ่มจากชุด RBAC เล็ก ๆ ที่ชัดเจน:
- Moderator: ตรวจสอบ/ใช้ผลลัพธ์/เขียนบันทึกภายใน
- Senior reviewer: สามารถ override, จัดการการยกระดับ และโค้ช
- Policy editor: ปรับปรุงข้อความนโยบาย/คำจำกัดความกฎ แต่ไม่สามารถมอดเรตโดยตรง
- : จัดการผู้ใช้ บทบาท การตั้งค่าทีม การรวมระบบ และการกระทำที่มีความเสี่ยงสูง
How should I structure queues and prioritization rules?
ใช้ หลายคิว ที่มีความเป็นเจ้าของชัดเจน:
- New items
- High-risk
- Escalations
- Appeals
- Backlog
จัดลำดับภายในคิวด้วยสัญญาณที่อธิบายได้ เช่น ความรุนแรง การเข้าถึง ผู้รายงานที่ไม่ซ้ำ และตัวจับเวลา SLA ใน UI แสดง “ทำไมฉันเห็นชิ้นนี้?” เพื่อให้ผู้ตรวจเชื่อถือการจัดลำดับและตรวจจับการเล่นเกมได้
How do I prevent two reviewers from working the same item?
ใช้การ claim/lock พร้อม timeout:
- เมื่อตรวจสอบเปิดไอเทม ไอเทมจะกลายเป็น มอบหมาย และซ่อนจากคนอื่น
- ถ้าทิ้งไว้ จะมี timeout คืนไปที่คิว
- บันทึกเหตุการณ์ claim, release, timeout, และ completion
วิธีนี้ลดงานซ้ำซ้อนและให้ข้อมูลสำหรับวิเคราะห์คอขวดหรือพฤติกรรม cherry-picking
How do I translate moderation policies into enforceable rules in the app?
เปลี่ยนนโยบายเป็นพจนานุกรมเชิงโครงสร้างและ templates การตัดสินใจ:
- Category → violation type → severity → required evidence
- Decision templates ที่เติมค่าแนะนำการกระทำ ข้อความผู้ใช้ และเช็คลิสต์ภายใน
- บังคับใช้ รหัสเหตุผลเชิงโครงสร้าง (และมีช่องบันทึกเพิ่มเติมได้)
- รองรับ เวอร์ชันนโยบาย พร้อมวันที่เริ่มใช้ และบันทึกเวอร์ชันที่ถูกใช้กับแต่ละการตัดสินใจ
สิ่งนี้ช่วยให้การตัดสินสม่ำเสมอ วิเคราะห์ได้ และทำให้อุทธรณ์ตรวจสอบได้ง่ายขึ้น
What should be included in audit logs for a moderation system?
บันทึกทุกสิ่งที่จำเป็นเพื่อสร้างเรื่องราว:
- ใครทำอะไร เมื่อไหร่ และทำไม (policy code + บันทึก)
- กลไกของเวิร์กโฟลว์ (claimed, released, reassigned, escalated)
- ภาพก่อน/หลังสำหรับเนื้อหาและสถานะเมื่อไอเทมสามารถเปลี่ยนได้
ทำให้บันทึกค้นหาได้ตาม actor, content ID, policy code, queue, และช่วงเวลา และกำหนดกฎการเก็บข้อมูล (รวมถึง legal holds และวิธีที่คำขอลบข้อมูลมีผลต่อหลักฐานที่เก็บไว้)