01 มี.ค. 2568·4 นาที
วิธีสร้างเว็บแอปเพื่อติดตามการนำเครื่องมือภายในไปใช้
เรียนรู้วิธีออกแบบและสร้างเว็บแอปที่วัดการนำเครื่องมือภายในไปใช้ด้วยตัวชี้วัดชัดเจน การติดตามเหตุการณ์ แดชบอร์ด ความเป็นส่วนตัว และขั้นตอนการปล่อยใช้งาน
เรียนรู้วิธีออกแบบและสร้างเว็บแอปที่วัดการนำเครื่องมือภายในไปใช้ด้วยตัวชี้วัดชัดเจน การติดตามเหตุการณ์ แดชบอร์ด ความเป็นส่วนตัว และขั้นตอนการปล่อยใช้งาน
ก่อนจะสร้างอะไร ลงความเห็นร่วมกันก่อนว่า “การนำไปใช้” หมายถึงอะไรในองค์กรของคุณ เครื่องมือภายในไม่ได้ขายตัวเอง—การนำไปใช้มักเป็นการผสมระหว่างการเข้าถึง พฤติกรรม และนิสัย
เลือกชุดคำนิยามสั้นๆ ที่ทุกคนสามารถพูดตามได้:
เขียนสิ่งเหล่านี้ลงและถือเป็นข้อกำหนดของผลิตภัณฑ์ ไม่ใช่เรื่องเล็กๆ ของการวิเคราะห์
แอปติดตามมีคุณค่าเมื่อมันเปลี่ยนสิ่งที่คุณทำถัดไปได้ ลิสต์การตัดสินใจที่คุณอยากทำให้เร็วขึ้นหรือมีข้อถกเถียงน้อยลง เช่น:
ถ้าตัวชี้วัดจะไม่ขับการตัดสินใจ ก็เป็นตัวเลือกสำหรับ MVP
กำหนดชัดเจนว่าผู้ชมคือใครบ้างและแต่ละคนต้องการอะไร:
กำหนดเกณฑ์ความสำเร็จสำหรับตัวแอปติดตามเอง (ไม่ใช่เครื่องมือที่ถูกติดตาม) เช่น:
ตั้งไทม์ไลน์ง่ายๆ: สัปดาห์ที่ 1 นิยาม + ผู้มีส่วนได้ส่วนเสีย, สัปดาห์ที่ 2–3 การติดตั้ง MVP + แดชบอร์ดพื้นฐาน, สัปดาห์ที่ 4 ทบทวน แก้ช่องว่าง และเผยแพร่จังหวะการทำงานที่ทำซ้ำได้
การวิเคราะห์เครื่องมือภายในได้ผลเมื่อเลขสามารถตอบการตัดสินใจได้ ถ้าติดตามทุกอย่าง คุณจะจมอยู่กับชาร์ตและยังไม่รู้จะแก้ตรงไหน เริ่มจากชุดตัวชี้วัดการนำไปใช้ขนาดเล็กที่สอดคล้องกับเป้าหมายการปล่อยใช้งาน แล้วค่อยเพิ่มชั้นการมีส่วนร่วมและการแบ่งกลุ่ม
Activated users: จำนวน (หรือ %) ผู้ที่ทำขั้นตอนขั้นต่ำเพื่อให้ได้คุณค่า เช่น ลงชื่อเข้าใช้ผ่าน SSO และทำเวิร์กโฟลว์แรกสำเร็จ
WAU/MAU: ผู้ใช้รายสัปดาห์เทียบรายเดือน ช่วยให้เห็นว่าเป็นนิสัยหรือเป็นครั้งคราว
Retention: จำนวนผู้ใช้ใหม่ที่ยังใช้งานหลังจากสัปดาห์หรือเดือนแรก กำหนด cohort ชัดเจน (เช่น “เริ่มใช้ในเดือนตุลาคม”) และกฎว่าอะไรคือ “active”
Time-to-first-value (TTFV): เวลาที่ผู้ใช้ใหม่ต้องใช้เพื่อไปถึงผลลัพธ์ที่มีความหมาย ยิ่งสั้นมักสัมพันธ์กับการนำไปใช้ระยะยาวที่ดีกว่า
หลังจากมีการวัดการนำไปใช้แกนหลักแล้ว ให้เพิ่มชุดการวัดการมีส่วนร่วมเล็กๆ:
แยกตัวเลขตาม แผนก, บทบาท, สถานที่, หรือทีม แต่หลีกเลี่ยงการตัดที่ละเอียดเกินไปซึ่งเอื้อต่อการ “แข่งสกอร์” ของบุคคลหรือกลุ่มเล็กๆ จุดประสงค์คือหาแหล่งที่ต้องการการสอน การฝึกอบรม หรือการออกแบบเวิร์กโฟลว์ ไม่ใช่การมอนิเตอร์แบบละเอียดยิบ
เขียนเกณฑ์เช่น:
แล้วเพิ่มการแจ้งเตือนเมื่อมีการลดลงอย่างรวดเร็ว (เช่น “การใช้ฟีเจอร์ X ลด 30% สัปดาห์ต่อสัปดาห์”) เพื่อให้ตรวจสอบได้เร็ว—ปัญหาการปล่อย, สิทธิ์, หรือการเปลี่ยนกระบวนการมักแสดงก่อน
ก่อนใส่โค้ดติดตาม ให้ชัดเจนว่า “การนำไปใช้” เป็นอย่างไรในงานประจำวัน เครื่องมือภายในมักมีผู้ใช้น้อยกว่าลูกค้าทั่วไป ดังนั้นทุกเหตุการณ์ควรมีเหตุผลชัดเจน: อธิบายได้ว่าเครื่องมือนั้นช่วยให้คนสำเร็จงานจริงหรือไม่
เริ่มจาก 2–4 เวิร์กโฟลว์ทั่วไปและเขียนเป็นขั้นตอนสั้นๆ เช่น:
สำหรับแต่ละการเดินทาง ให้ทำเครื่องหมายช่วงเวลาที่คุณสนใจ: ความสำเร็จครั้งแรก การส่งมอบต่อ (เช่น ส่ง → อนุมัติ) และคอขวด (เช่น ข้อผิดพลาดการตรวจสอบ)
ใช้ events สำหรับการกระทำที่มีความหมาย (create, approve, export) และสถานะที่บ่งชี้ความก้าวหน้า
ใช้ page views อย่างประหยัด—มีประโยชน์ในการเข้าใจการนำทางและจุดที่คนหลุดออก แต่ถ้าใช้แทนการใช้งานจริงจะเสียงดังเกินไป
ใช้ backend logs เมื่อคุณต้องการความน่าเชื่อถือหรือการครอบคลุมข้ามไคลเอนต์ (เช่น การอนุมัติที่เกิดผ่าน API, งานที่ตั้งเวลา, การนำเข้าจำนวนมาก). รูปแบบปฏิบัติได้: บันทึกคลิกใน UI เป็น event และบันทึกการเสร็จสิ้นจริงใน backend
เลือกสไตล์ที่สม่ำเสมอและยึดตามมัน (เช่น verb_noun: create_request, approve_request, export_report). กำหนดคุณสมบัติที่ต้องมีเพื่อให้เหตุการณ์ใช้ร่วมกันได้ข้ามทีม:
user_id (ตัวระบุที่เสถียร)tool_id (เครื่องมือที่เกี่ยวข้อง)feature (การจัดกลุ่มตัวเลือก เช่น approvals)timestamp (UTC)เพิ่มบริบทที่เป็นประโยชน์เมื่อปลอดภัย: org_unit, role, request_type, success/error_code.
เครื่องมือเปลี่ยนแปลงได้ Taxonomy ควรทนต่อการเปลี่ยนแปลงโดยไม่ทำลายแดชบอร์ด:
schema_version (หรือ event_version) ใน payloadโมเดลข้อมูลที่ชัดเจนป้องกันปัญหาการรายงานในภายหลัง เป้าหมายคือทำให้ทุกเหตุการณ์ไม่กำกวม: ใคร ทำ อะไร ใน เครื่องมือไหน และ เมื่อไร ในขณะที่ทำให้ระบบดูแลรักษาง่าย
แอปติดตามการนำไปใช้ภายในส่วนใหญ่เริ่มด้วยตารางไม่กี่ตัว:
เก็บตาราง events ให้สอดคล้อง: event_name, timestamp, user_id, tool_id, และฟิลด์ JSON/properties เล็กๆ สำหรับรายละเอียดที่คุณจะกรอง (เช่น feature, page, workflow_step).
ใช้ IDs ภายในที่เสถียร ซึ่งจะไม่เปลี่ยนเมื่อใครเปลี่ยนอีเมลหรือชื่อ:
idp_subject)กำหนดระยะเวลาที่เก็บเหตุการณ์ดิบ (เช่น 13 เดือน) และวางแผนตาราง rollup รายวัน/รายสัปดาห์ (tool × team × date) เพื่อให้แดชบอร์ดเร็ว
ระบุชัดว่าฟิลด์ใดมาจากไหน:
สิ่งนี้ช่วยหลีกเลี่ยง “ฟิลด์ปริศนา” และทำให้ชัดเจนว่าใครสามารถแก้ข้อมูลที่ผิดได้
การติดตั้งคือจุดที่การติดตามการนำไปใช้กลายเป็นของจริง: คุณแปลงกิจกรรมผู้ใช้เป็นเหตุการณ์ที่เชื่อถือได้ การตัดสินใจสำคัญคือ ที่ไหน ที่สร้างเหตุการณ์—บนไคลเอนต์ บนเซิร์ฟเวอร์ หรือทั้งสอง และอย่างไรให้ข้อมูลเพียงพอที่จะเชื่อถือได้
เครื่องมือภายในส่วนใหญ่ได้ประโยชน์จากแนวทางผสม:
เก็บการติดตามฝั่งไคลเอนต์ให้เรียบง่าย: อย่าบันทึกทุกการพิมพ์ โฟกัสที่ช่วงเวลาที่บ่งชี้ความก้าวหน้าในเวิร์กโฟลว์
ปัญหาเครือข่ายและข้อจำกัดของเบราว์เซอร์เกิดขึ้นได้ เพิ่ม:
ที่ฝั่งเซิร์ฟเวอร์ ให้การรับข้อมูล analytics เป็นแบบ non-blocking: ถ้าการบันทึกเหตุการณ์ล้มเหลว การกระทำทางธุรกิจควรยังสำเร็จได้
ทำ schema checks ที่จุดรับข้อมูล (และถ้าได้ควรทั้งในไลบรารีฝั่งไคลเอนต์ด้วย). ตรวจสอบฟิลด์ที่จำเป็น (event name, timestamp, actor ID, org/team ID), ประเภทข้อมูล และค่าที่อนุญาต ปฏิเสธหรือกักกันเหตุการณ์ที่ผิดรูปแบบเพื่อไม่ให้ปนเปื้อนแดชบอร์ดอย่างเงียบๆ
ใส่ env tags เช่น env=prod|stage|dev และกรองรายงานตามนั้น ป้องกันไม่ให้การรัน QA, สาธิต, และการทดสอบนักพัฒนาทำให้ตัวเลขการนำไปใช้พุ่งขึ้น
ถ้าต้องการกฎง่ายๆ: เริ่มด้วยเหตุการณ์ฝั่งเซิร์ฟเวอร์สำหรับการกระทำแกนหลัก แล้วเพิ่มเหตุการณ์ฝั่งไคลเอนต์เฉพาะที่ต้องการรายละเอียดมากขึ้นเกี่ยวกับเจตนาและ friction ของ UI
ถ้าคนไม่เชื่อใจวิธีการเข้าถึงข้อมูลการนำไปใช้ พวกเขาจะไม่ใช้ระบบ—หรือจะเลี่ยงการติดตามทั้งหมด ถือว่า auth และ permissions เป็นฟีเจอร์สำคัญ ไม่ใช่เรื่องเสริม
ใช้ผู้ให้บริการอัตลักษณ์ของบริษัทเพื่อให้การเข้าถึงสอดคล้องกับวิธีที่พนักงานลงชื่อเข้าใช้แล้ว
โมเดลง่ายๆ ครอบคลุมกรณีการใช้งานส่วนใหญ่:
ทำให้การเข้าถึง แบบขอบเขต (ตามเครื่องมือ แผนก ทีม หรือสถานที่) เพื่อให้ “tool owner” ไม่ได้หมายความว่าเห็นทุกอย่าง จำกัดการส่งออกในแบบเดียวกัน—การรั่วไหลของข้อมูลมักเกิดจาก CSV
เพิ่ม audit logs สำหรับ:
กำหนดค่าเริ่มต้นแบบ least-privilege (เช่น ผู้ใช้ใหม่เริ่มเป็น Viewer) และมีฟลูว์การอนุมัติสำหรับการเข้าถึงระดับ Admin — อ้างอิงไปยังหน้าคำขอภายในหรือฟอร์มง่ายๆ ที่ /access-request นี่ช่วยลดความประหลาดใจและทำให้ง่ายต่อการทบทวน
การติดตามการนำไปใช้เกี่ยวข้องกับข้อมูลพนักงาน ดังนั้นความเป็นส่วนตัวไม่ควรเป็นเรื่องมาทีหลัง ถ้าคนรู้สึกว่าถูกมอนิเตอร์ พวกเขาจะต่อต้านเครื่องมือ—และข้อมูลจะไม่น่าเชื่อถือ ถือความไว้วางใจเป็นข้อกำหนดของผลิตภัณฑ์
เริ่มจากการกำหนดเหตุการณ์ที่ “ปลอดภัย”. ติดตามการกระทำและผลลัพธ์ ไม่ใช่เนื้อหาที่พนักงานพิมพ์
report_exported, ticket_closed, approval_submitted./orders/:id.เขียนกฎเหล่านี้และใส่เป็นส่วนหนึ่งของเช็คลิสต์การติดตั้งเพื่อไม่ให้ฟีเจอร์ใหม่แอบเก็บข้อมูลอ่อนไหวโดยไม่ตั้งใจ
ทำงานร่วมกับ HR, ฝ่ายกฎหมาย และ Security ตั้งแต่ต้น กำหนดวัตถุประสงค์ของการติดตาม (เช่น ความต้องการการฝึกอบรม, จุดคอขวดในเวิร์กโฟลว์) และห้ามใช้บางอย่างอย่างชัดเจน (เช่น การประเมินผลการปฏิบัติงานโดยไม่มีกระบวนการแยกต่างหาก). เอกสารควรระบุ:
ผู้มีส่วนได้ส่วนเสียส่วนใหญ่ไม่ต้องการข้อมูลระดับบุคคล ให้มุมมองแบบรวมโดยดีฟอลต์ และอนุญาตการเจาะลึกที่ระบุตัวบุคคลเฉพาะสำหรับแอดมินบางคนเท่านั้น
ใช้การซ่อนกลุ่มเล็กเพื่อไม่เปิดเผยพฤติกรรมของกลุ่มเล็ก (เช่น ซ่อนการแยกเมื่อขนาดกลุ่ม < 5). นี่ช่วยลดความเสี่ยงการระบุตัวบุคคลเมื่อรวมฟิลเตอร์หลายตัว
เพิ่มประกาศสั้นๆ ในแอป (และในการเริ่มต้นใช้งาน) อธิบายสิ่งที่ถูกเก็บและเหตุผล รักษา FAQ ภายในที่มีตัวอย่างข้อมูลที่ถูก/ไม่ถูกเก็บ ระยะเวลาการเก็บ และวิธียื่นข้อกังวล ลิงก์ไปยัง FAQ จากแดชบอร์ดและหน้าการตั้งค่า (เช่น /internal-analytics-faq)
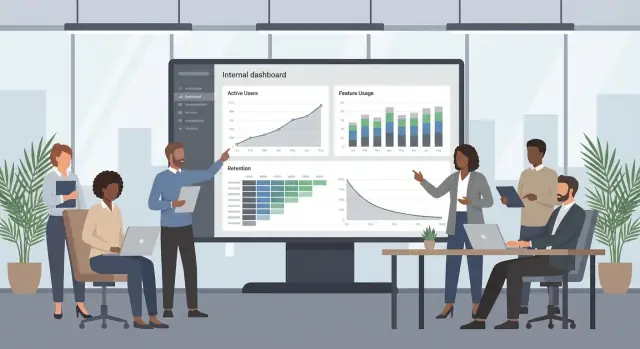
แดชบอร์ดควรตอบคำถามเดียว: “เราควรทำอะไรต่อ?” ถ้าชาร์ตสนใจแต่ไม่ชี้แนะการตัดสินใจ (กระตุ้นการฝึกอบรม แก้ onboarding เลิกใช้ฟีเจอร์) มันคือเสียงรบกวน
สร้างมุมมองภาพรวมเล็กๆ ที่ใช้ได้สำหรับผู้มีส่วนได้ส่วนเสียส่วนใหญ่:
เก็บภาพรวมให้เรียบ: 6–10 ไทล์สูงสุด ช่วงเวลาที่สอดคล้อง และคำนิยามชัดเจน (เช่น นับอย่างไรเป็น “active”)
เมื่อเมตริกเคลื่อนไหว ผู้คนต้องการสำรวจอย่างรวดเร็ว:
ทำให้ตัวกรองชัดเจนและปลอดภัย: ช่วงวันที่, เครื่องมือ, ทีม, เซกเมนต์ พร้อมค่าเริ่มต้นที่เหมาะสมและปุ่มรีเซ็ต
เพิ่มรายการสั้นที่อัปเดตอัตโนมัติ:
แต่ละรายการควรลิงก์ไปยังหน้า drill-down และมีคำแนะนำการลงมือทำที่เสนอ
การส่งออกทรงพลัง—และเสี่ยง ให้อนุญาตการส่งออกเฉพาะข้อมูลที่ผู้ชมสามารถเห็น และหลีกเลี่ยงข้อมูลพนักงานระดับแถวโดยดีฟอลต์ สำหรับรายงานตามตารางเวลา ให้รวม:
ข้อมูลการนำไปใช้ยากจะตีความเมื่อคุณตอบคำถามพื้นฐานไม่ได้ เช่น “ใครเป็นเจ้าของเครื่องมือนี้?”, “ออกแบบมาเพื่อใคร?”, “อะไรเปลี่ยนไปสัปดาห์ที่แล้ว?” เลเยอร์เมตาดาต้าเบาๆ ทำให้เหตุการณ์ดิบกลายเป็นสิ่งที่คนลงมือทำได้ และทำให้แอปติดตามของคุณมีประโยชน์เกินทีมวิเคราะห์
เริ่มด้วยหน้าตัวจดทะเบียนเครื่องมือ (Tool Catalog) ที่เป็นแหล่งข้อมูลอ้างอิงสำหรับเครื่องมือภายในทั้งหมดที่คุณติดตาม ให้ค้นหาและอ่านง่าย พร้อมโครงสร้างเพียงพอสำหรับการรายงาน
รวมข้อมูล:
หน้านี้จะเป็นศูนย์ที่ลิงก์จากแดชบอร์ดและ runbooks เพื่อให้ใครก็ได้เข้าใจอย่างรวดเร็วว่า “การนำไปใช้ที่ดี” ควรเป็นอย่างไร
ให้เจ้าของเครื่องมือแก้ไขหรือกำหนด เหตุการณ์/ฟีเจอร์สำคัญ (เช่น “Submitted expense report”, “Approved request”) และแนบโน้ตเกี่ยวกับเกณฑ์ความสำเร็จ เก็บ ประวัติการเปลี่ยนแปลง ว่าใครเปลี่ยนอะไร เมื่อไร และทำไม เพราะคำนิยามเหตุการณ์เปลี่ยนตามเครื่องมือ
รูปแบบปฏิบัติได้คือเก็บ:
การขึ้นลงของการใช้งานมักสัมพันธ์กับกิจกรรมการปล่อย ไม่ใช่แค่การเปลี่ยนแปลงโค้ด เก็บเมตาดาต้า rollout ต่อเครื่องมือ:
เพิ่มลิงก์เช็คลิสต์ตรงในเรคอร์ดเครื่องมือ เช่น /docs/tool-rollout-checklist เพื่อให้เจ้าของประสานการวัดและการจัดการการเปลี่ยนแปลงได้ในที่เดียว
เป้าหมายไม่ใช่สร้างแพลตฟอร์มวิเคราะห์ที่ “สมบูรณ์แบบ” แต่เป็นการส่งมอบสิ่งที่เชื่อถือได้และทีมสามารถดูแลได้ เริ่มจากการจับคู่สแตกกับทักษะที่มีและสภาพแวดล้อมการ deploy แล้วตัดสินใจอย่างตั้งใจเกี่ยวกับการจัดเก็บและประสิทธิภาพ
สำหรับหลายทีม สแตกเว็บมาตรฐานก็พอเพียง:
เก็บ API การ ingest ให้เรียบง่าย: ชุด endpoint เล็กๆ เช่น /events และ /identify พร้อม payload ที่เวอร์ชัน
ถ้าต้องการไปถึง MVP ให้เร็ว วิธี vibe-coding ช่วยได้สำหรับแอปภายในที่เน้น CRUD (tool catalog, role management, dashboards) และการตั้งค่า ingestion แรก ตัวอย่างเช่น Koder.ai ช่วยทีมสร้างโปรโตไทป์ React-based web app กับ backend Go + PostgreSQL จากสเปคที่ขับเคลื่อนด้วยแชท แล้วค่อย iterate ด้วย planning mode snapshots และ rollback ขณะที่คุณปรับ taxonomy และโมเดลสิทธิ์
โดยทั่วไปคุณต้องการสอง “โหมด” ข้อมูล:
แนวทางที่พบทั่วไป:
แดชบอร์ดไม่ควรคำนวณทุกอย่างเมื่อโหลดหน้า ใช้ background jobs สำหรับ:
เครื่องมือ: Sidekiq (Rails), Celery (Django), หรือคิว Node เช่น BullMQ
กำหนดเป้าหมายบางอย่างและวัดมัน:
ติดตั้ง tracing และ metrics เบื้องต้นในแอปของคุณ และเพิ่มหน้า /health ง่ายๆ เพื่อให้การปฏิบัติการคาดเดาได้
ตัวเลขการนำไปใช้มีประโยชน์ก็ต่อเมื่อคนเชื่อถือได้ เหตุการณ์ที่ขาดหาย การเปลี่ยนชื่อ property หรือบั๊กส่งซ้ำอาจทำให้แดชบอร์ดดูวุ่นวายทั้งที่เครื่องมือไม่ได้ถูกใช้ สร้างการตรวจสอบคุณภาพเป็นส่วนหนึ่งของระบบติดตามเพื่อจับปัญหาเร็วและแก้ไขโดยไม่รบกวนมาก
ปฏิบัติเหตุการณ์เป็นสัญญา API:
user_id, tool, action) ให้บันทึกและกักกันเหตุการณ์แทนที่จะปล่อยให้ปนเปื้อนการวิเคราะห์แดชบอร์ดอาจออนไลน์โดยที่ข้อมูลค่อยๆ เสื่อมคุณภาพ เพิ่มมอนิเตอร์ที่แจ้งเตือนเมื่อพฤติกรรมการติดตามเปลี่ยน
tool_opened, สปิคใน error events, หรือการเพิ่มขึ้นผิดปกติของเหตุการณ์ซ้ำต่อผู้ใช้ต่อวินาทีfeature = null) เป็นเมตริกจริงจัง ถ้ามันเพิ่มขึ้น แปลว่ามีบางอย่างพังเมื่อการติดตามพัง การรายงานการนำไปใช้กลายเป็นอุปสรรคสำหรับการทบทวนของผู้นำ
การส่งตัวติดตามไม่ใช่เส้นชัย—การปล่อยใช้งานครั้งแรกควรออกแบบมาเพื่อเรียนรู้เร็วและสร้างความเชื่อใจ ปฏิบัติต่อการนำไปใช้ภายในเหมือนผลิตภัณฑ์: เริ่มเล็ก วัด ปรับปรุง แล้วขยาย
เลือก 1–2 เครื่องมือที่มีผลกระทบสูงและแผนกเดียวสำหรับพิลอต จำกัดขอบเขต: เหตุการณ์แกนหลักไม่กี่ตัว แดชบอร์ดง่ายๆ และเจ้าของหนึ่งคนที่สามารถลงมือทำตามผลการวัดได้
สร้างเช็คลิสต์ onboarding ที่ใช้ซ้ำได้สำหรับแต่ละเครื่องมือ:
ถ้าคุณ iterate เร็ว ให้ทำให้การปล่อยการปรับปรุงทีละน้อยปลอดภัย: snapshots, rollback, และการแยกสภาพแวดล้อม (dev/stage/prod) ลดความเสี่ยงของการทำลายการติดตามใน production แพลตฟอร์มอย่าง Koder.ai รองรับเวิร์กโฟลว์นี้และอนุญาตส่งออกซอร์สโค้ดเมื่อคุณต้องการย้ายตัวติดตามเข้าสู่ pipeline ปกติ
การนำไปใช้ดีขึ้นเมื่อการวัดผูกกับการสนับสนุน เมื่อเห็น activation ต่ำหรือ drop-off ให้ตอบสนองด้วย enablement:
ใช้ข้อมูลเพื่อลด friction ไม่ใช่ให้คะแนนพนักงาน มุ่งไปที่การลดขั้นตอนอนุมัติที่ซับซ้อน แก้การผสานที่พัง หรือเขียนเอกสารที่เข้าใจยาก ติดตามว่าการเปลี่ยนแปลงเหล่านี้ลดเวลาในการทำงานหรือเพิ่มผลลัพธ์สำเร็จหรือไม่
รันการทบทวนการนำไปใช้เป็นประจำ (สองสัปดาห์หรือรายเดือน) ทำให้เป็นเชิงปฏิบัติ: อะไรเปลี่ยน อะไรเคลื่อนไหว อะไรจะลองต่อไป เผยแพร่แผนการปรับปรุงขนาดเล็กและปิดวงกับทีมเพื่อให้พวกเขาเห็นความก้าวหน้าและยังคงมีส่วนร่วม
การนำไปใช้โดยทั่วไปคือการผสมระหว่าง activation, usage และ retention.
เขียนคำนิยามเหล่านี้ลงและใช้เป็นข้อกำหนดของสิ่งที่แอปต้องวัด
เริ่มจากการระบุการตัดสินใจที่แอปติดตามควรช่วยให้ทำได้ง่ายขึ้น เช่น:
ถ้าตัวชี้วัดจะไม่ขับการตัดสินใจ ให้เก็บไว้พ้นจาก MVP
ชุด MVP ที่ใช้งานได้จริงคือ:
สี่ตัวนี้ครอบคลุมกรวยตั้งแต่คุณค่าแรกจนถึงการใช้งานอย่างต่อเนื่องโดยไม่จมอยู่กับชาร์ตมากเกินไป
ติดตาม การกระทำของ workflow ที่มีความหมาย ไม่ใช่ทุกอย่าง
ใช้รูปแบบการตั้งชื่อต่อเนื่อง (เช่น verb_noun) และกำหนดคุณสมบัติขั้นต่ำ
ฟิลด์ขั้นต่ำที่แนะนำ:
event_nametimestamp (UTC)user_id (เสถียร)ทำให้ identifiers เสถียรและไม่ขึ้นกับความหมาย
user_id แมปกับตัวระบุ IdP ที่คงที่ (เช่น OIDC subject)tool_id (อย่าใช้ชื่อเครื่องมือเป็นคีย์)anonymous_id เว้นแต่จำเป็นจริงๆ สำหรับการติดตามก่อนเข้าสู่ระบบวิธีนี้จะป้องกันไม่ให้แดชบอร์ดเสียเมื่ออีเมล ชื่อ หรือป้ายชื่อเครื่องมือเปลี่ยน
ใช้โมเดลผสมเพื่อความน่าเชื่อถือ:
เพิ่ม batching, retry แบบ backoff, และคิวเล็กๆ ในเครื่องเพื่อไม่ให้เหตุการณ์หาย และให้แน่ใจว่าความล้มเหลวของ analytics จะไม่ขัดขวางการทำธุรกิจ
รักษาระบบสิทธิ์เรียบง่ายและมีขอบเขต:
จำกัดการส่งออกข้อมูลในทางเดียวกัน (CSV มักเป็นช่องทางรั่วไหล) และบันทึก audit logs สำหรับการเปลี่ยนสิทธิ์ แก้ไขการตั้งค่า แชร์แดชบอร์ด การส่งออก และการสร้าง API token
ออกแบบโดยคำนึงถึงความเป็นส่วนตัวเป็นค่าเริ่มต้น:
เผยแพร่ประกาศสั้นๆ และ FAQ ภายใน (เช่น ที่ /internal-analytics-faq) อธิบายสิ่งที่ถูกเก็บและเหตุผล
เริ่มจากมุมมองที่ขับเคลื่อนการกระทำ:
เพิ่ม drill-down ตามเครื่องมือและเซกเมนต์ (ฝ่าย/บทบาท/สถานที่) และแสดง “โอกาสสูงสุด” เช่น ทีมที่ activation ต่ำหรือการลดหลังรีลีส อย่าปล่อย row-level ของพนักงานเป็นค่าเริ่มต้น
create_requestapprove_requestexport_reportรูปแบบที่พบได้บ่อยคือบันทึก “attempted” ใน UI และบันทึก “completed” ในเซิร์ฟเวอร์
tool_id (เสถียร)คุณสมบัติเสริมที่มีประโยชน์ เช่น feature, org_unit, role, workflow_step, และ success/error_code — ใช้เฉพาะเมื่อปลอดภัยและตีความได้