18 ต.ค. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับการนำเข้า ส่งออก และตรวจสอบข้อมูล
เรียนรู้วิธีออกแบบเว็บแอปที่นำเข้า/ส่งออก CSV/XLSX/JSON ตรวจสอบข้อมูลด้วยข้อความข้อผิดพลาดชัดเจน รองรับบทบาท บันทึก audit และการประมวลผลที่เชื่อถือได้
เรียนรู้วิธีออกแบบเว็บแอปที่นำเข้า/ส่งออก CSV/XLSX/JSON ตรวจสอบข้อมูลด้วยข้อความข้อผิดพลาดชัดเจน รองรับบทบาท บันทึก audit และการประมวลผลที่เชื่อถือได้
ก่อนจะออกแบบหน้าจอหรือเลือกตัวแยกไฟล์ ให้ระบุอย่างชัดเจนว่า ใคร เป็นคนย้ายข้อมูลเข้าออกจากผลิตภัณฑ์ของคุณและ ทำไม ระบบนำเข้าข้อมูลจะถูกออกแบบต่างกันไปถ้าเป็นเพื่อผู้ปฏิบัติงานภายในเทียบกับเครื่องมือนำเข้า Excel แบบ self-serve สำหรับลูกค้า
เริ่มจากการระบุบทบาทที่จะเกี่ยวข้องกับการนำเข้า/ส่งออก:
สำหรับแต่ละบทบาท ให้กำหนดระดับทักษะที่คาดหวังและความทนทานต่อความซับซ้อน ลูกค้ามักต้องการตัวเลือกน้อยลงและคำอธิบายในผลิตภัณฑ์ที่ชัดเจนกว่า
เขียนสถานการณ์สำคัญของคุณและจัดลำดับความสำคัญ ตัวอย่างที่พบบ่อยได้แก่:
จากนั้นกำหนดเมตริกความสำเร็จที่วัดได้ เช่น การนำเข้าที่ล้มเหลวน้อยลง เวลาการแก้ปัญหาข้อผิดพลาดที่เร็วขึ้น และตั๋วซัพพอร์ตที่เกี่ยวกับ "ไฟล์ของฉันอัปโหลดไม่ได้" ลดลง เมตริกเหล่านี้จะช่วยให้คุณตัดสินใจเรื่องการแลกเปลี่ยน (เช่น ลงทุนเพื่อรายงานข้อผิดพลาดที่ชัดเจนขึ้นเทียบกับรองรับฟอร์แมตไฟล์เพิ่มเติม)
ระบุอย่างชัดเจนว่าคุณจะรองรับอะไรในวันแรก:
สุดท้าย ระบุความต้องการด้านการปฏิบัติตามตั้งแต่เนิ่นๆ: ไฟล์มี PII หรือไม่ ระยะเวลาเก็บ การตรวจสอบ (ใครนำเข้าเมื่อไรและมีการเปลี่ยนแปลงอะไร) การตัดสินใจเหล่านี้จะมีผลต่อการจัดเก็บ การบันทึก และสิทธิ์ทั่วทั้งระบบ
ก่อนจะคิดถึง UI การจับคอลัมน์หรือกฎการตรวจสอบ CSV ให้เลือกสถาปัตยกรรมที่ทีมของคุณสามารถส่งมอบและดูแลได้ Imports/exports เป็นโครงสร้างพื้นฐานที่ค่อนข้าง “น่าเบื่อ” — ความรวดเร็วในการทำซ้ำและการดีบักสำคัญกว่าความใหม่
สแต็กเว็บหลักๆ สามารถขับเคลื่อนเว็บแอปสำหรับนำเข้าได้ เลือกตามทักษะที่มีและการจ้างงาน:
กุญแจคือความสม่ำเสมอ: สแต็กควรทำให้การเพิ่มชนิดการนำเข้าใหม่ กฎการตรวจสอบใหม่ หรือฟอร์แมตการส่งออกใหม่ ทำได้โดยไม่ต้องเขียนระบบใหม่ทั้งหมด
ถ้าต้องการเร่งการสร้างสรรค์โดยไม่ผูกมัดกับต้นแบบเฉพาะทาง แพลตฟอร์มแบบ vibe-coding อย่าง Koder.ai อาจเป็นประโยชน์: คุณอธิบายลำดับการนำเข้า (upload → preview → mapping → validation → background processing → history) ในแชท แล้วสร้าง UI React กับ backend Go + PostgreSQL ได้อย่างรวดเร็ว พร้อมโหมดวางแผน และ snapshot/rollback
ใช้ฐานข้อมูลเชิงสัมพันธ์ (Postgres/MySQL) สำหรับระเบียนที่มีโครงสร้าง, upsert และล็อกตรวจสอบการเปลี่ยนแปลงข้อมูล
เก็บการอัปโหลดต้นฉบับ (CSV/Excel) ใน object storage (S3/GCS/Azure Blob) การเก็บไฟล์ดิบมีคุณค่าอย่างยิ่งต่อฝ่ายสนับสนุน: คุณสามารถทำซ้ำปัญหาการแยกวิเคราะห์ รันงานใหม่ และอธิบายการตัดสินใจการจัดการข้อผิดพลาด
ไฟล์ขนาดเล็กสามารถประมวลผล แบบซิงโครนัส (อัปโหลด → ตรวจสอบ → นำไปใช้) เพื่อประสบการณ์ที่ตอบสนองเร็ว สำหรับไฟล์ใหญ่ ให้ย้ายงานไปยัง งานเบื้องหลัง:
สิ่งนี้ยังช่วยให้คุณรองรับการ retry และการเขียนแบบจำกัดอัตราด้วย
ถ้าคุณกำลังสร้าง SaaS ให้ตัดสินใจตั้งแต่ต้นว่าจะคั่นข้อมูลของ tenant อย่างไร (การคั่นระดับแถว, สกีมาแยก, หรือฐานข้อมูลแยก) ทางเลือกนี้จะมีผลต่อ API การส่งออก สิทธิ์ และประสิทธิภาพ
จดเป้าหมายสำหรับ uptime, ขนาดไฟล์สูงสุด, จำนวนแถวที่คาดว่าจะนำเข้า, เวลาที่ต้องใช้ให้เสร็จ และงบประมาณ ตัวเลขเหล่านี้จะกำหนดการเลือกคิวงาน ยุทธศาสตร์การแบทช์ และการทำดัชนี ก่อนที่คุณจะขัดเกลา UI
ฟลูว์รับข้อมูลกำหนดโทนของทุกการนำเข้า ถ้ามันดูคาดเดาได้และยืดหยุ่น ผู้ใช้จะกลับมาลองอีกเมื่อเกิดข้อผิดพลาด และตั๋วซัพพอร์ตจะลดลง
เสนอโซนลากแล้วปล่อยและตัวเลือกเลือกไฟล์แบบคลาสสิกสำหรับเว็บ UI การลากวางเหมาะสำหรับผู้ใช้ที่คุ้นเคย ขณะที่ตัวเลือกไฟล์เข้าถึงได้และคุ้นเคยสำหรับคนทั่วไป
ถ้าลูกค้าคุณนำเข้าจากระบบอื่น ให้เพิ่ม endpoint API ด้วย รองรับ multipart uploads (ไฟล์ + เมทาดาต้า) หรือ pre-signed URL สำหรับไฟล์ใหญ่
เมื่ออัปโหลด ให้ทำการแยกเบาๆ เพื่อสร้าง “ตัวอย่าง” โดยไม่ commit ข้อมูลทันที:
ตัวอย่างนี้จะเป็นพื้นฐานสำหรับขั้นตอนต่อมา เช่น การจับคอลัมน์และการตรวจสอบ
เก็บไฟล์ต้นฉบับอย่างปลอดภัยเสมอ (object storage เป็นตัวเลือกทั่วไป) เก็บให้ไม่เปลี่ยนแปลงเพื่อที่จะ:
ปฏิบัติต่อแต่ละการอัปโหลดเป็นระเบียนชั้นหนึ่ง เก็บเมทาดาต้าเช่น ผู้ที่อัปโหลด, เวลาที่อัปโหลด, ระบบต้นทาง, ชื่อไฟล์ และ checksum (เพื่อตรวจจับสำเนาและความสมบูรณ์) สิ่งนี้มีคุณค่าสำหรับการตรวจสอบและการดีบัก
รันการตรวจสอบเบื้องต้นอย่างรวดเร็วและล้มเหลวตั้งแต่ต้นเมื่อจำเป็น:\n\n- ประเภทไฟล์และขีดจำกัดขนาด\n- ความสามารถในการอ่านพื้นฐาน (อ่านได้หรือไม่)\n- คอลัมน์ที่ต้องมี (ตามชนิดการนำเข้า)\n\nถ้าการตรวจสอบล้มเหลว ให้ส่งข้อความที่ชัดเจนและบอกวิธีแก้ไข เป้าหมายคือปิดกั้นไฟล์ที่เสียหายจริงๆ อย่างรวดเร็ว โดยไม่ปฏิเสธข้อมูลที่ยังสามารถแมปหรือทำความสะอาดได้ในขั้นตอนต่อมา
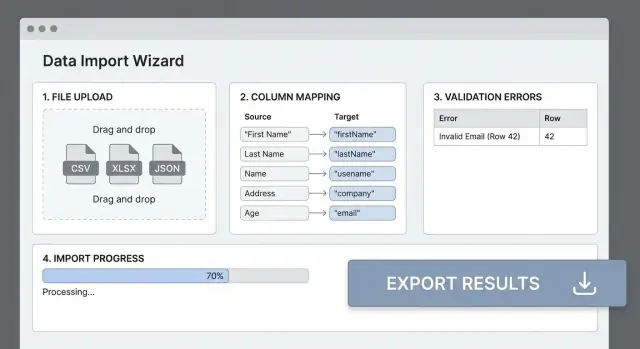
ความล้มเหลวส่วนใหญ่เกิดจากเฮดเดอร์ในไฟล์ไม่ตรงกับฟิลด์ของแอป UI การจับคอลัมน์ที่ชัดเจนจะเปลี่ยน “CSV ที่รก” ให้เป็นอินพุตที่คาดเดาได้และช่วยให้ผู้ใช้ไม่ต้องลองผิดลองถูก
แสดงตารางง่ายๆ: คอลัมน์ต้นทาง → ฟิลด์ปลายทาง. ตรวจจับการจับคู่ที่น่าจะเป็น (การจับชื่อแบบไม่สนใจตัวพิมพ์, คำพ้องความหมาย เช่น “E-mail” → email) แต่ให้ผู้ใช้แก้ไขได้เสมอ
เพิ่มฟีเจอร์อำนวยความสะดวกเล็กๆ น้อยๆ:
ถ้าลูกค้านำเข้าในฟอร์แมตเดิม ๆ ทุกสัปดาห์ ให้ทำให้เป็นหนึ่งคลิก ให้พวกเขาบันทึกเทมเพลตที่กำหนดขอบเขตได้ตาม:
เมื่ออัปโหลดไฟล์ใหม่ ให้แนะนำเทมเพลตตามความทับซ้อนของคอลัมน์ และรองรับการเวอร์ชันเพื่อให้ผู้ใช้ปรับเทมเพลตโดยไม่ทำให้การรันเก่าพัง
เพิ่มการแปลงเบา ๆ ที่ผู้ใช้สามารถใช้ต่อฟิลด์ที่แมปแล้ว:
เก็บการแปลงให้ชัดเจนใน UI (“Applied: Trim → Parse Date”) เพื่อให้ผลลัพธ์อธิบายได้
ก่อนประมวลผลทั้งไฟล์ ให้แสดง ตัวอย่างผลลัพธ์ที่แมปแล้ว ประมาณ 20 แถว แสดงค่าต้นฉบับ ค่าหลังแปลง และคำเตือน (เช่น “ไม่สามารถแยกวันที่ได้”) นี่คือที่ผู้ใช้จะพบข้อผิดพลาดตั้งแต่ต้น
ให้ผู้ใช้เลือก ฟิลด์คีย์ (email, external_id, SKU) และอธิบายว่าจะเกิดอะไรขึ้นเมื่อซ้ำ แม้ว่าคุณจะทำ upsert ภายหลัง ขั้นตอนนี้กำหนดความคาดหวัง: เตือนเกี่ยวกับคีย์ซ้ำในไฟล์และแนะนำว่าบันทึกไหนจะ “ชนะ” (แถวแรก แถวสุดท้าย หรือเป็นข้อผิดพลาด)
การตรวจสอบคือความแตกต่างระหว่าง “อัปโหลดไฟล์” กับฟีเจอร์นำเข้าที่ผู้ใช้เชื่อถือได้ เป้าหมายไม่ใช่แค่เข้มงวด แต่เพื่อป้องกันข้อมูลไม่ดีแพร่กระจาย ในขณะเดียวกันให้ฟีดแบ็กที่ชัดเจนและทำได้จริง
จัดการการตรวจสอบเป็นสามชุดที่แตกต่างกัน โดยแต่ละชุดมีวัตถุประสงค์ต่างกัน:
การแยกชั้นเหล่านี้ทำให้ระบบขยายง่ายและอธิบายใน UI ได้ง่ายขึ้น
ตัดสินใจว่าจะให้การนำเข้าทำอะไร:
คุณสามารถรองรับทั้งสองแบบ: ตั้ง strict เป็นค่าดีฟอลต์ และมีตัวเลือก “อนุญาตการนำเข้าแบบบางส่วน” สำหรับแอดมิน
ทุกข้อผิดพลาดควรตอบ: เกิดอะไรขึ้น ที่ไหน และจะแก้ไขอย่างไร\n\nตัวอย่าง: “แถว 42, คอลัมน์ ‘Start Date’: ต้องเป็นวันที่ที่ถูกต้องในรูปแบบ YYYY-MM-DD.”\n\nแยกความแตกต่างระหว่าง:\n\n- Errors: บล็อกการประมวลผลสำหรับแถวนั้น (หรือทั้งไฟล์ใน strict mode)\n- Warnings: ยอมให้ผ่าน แต่เน้น (เช่น “แผนกไม่รู้จัก จะปล่อยว่างไว้”)
ผู้ใช้ไม่ค่อยแก้ได้ทั้งหมดในครั้งเดียว ทำให้การอัปโหลดใหม่เป็นเรื่องง่ายโดยเก็บผลการตรวจสอบที่ผูกกับพยายามการนำเข้า และให้ผู้ใช้อัปโหลดไฟล์ที่แก้ไขได้ง่ายๆ จับคู่กับรายงานข้อผิดพลาดที่ดาวน์โหลดได้ (กล่าวถึงด้านล่าง) เพื่อให้พวกเขาแก้เป็นกลุ่ม
แนวทางปฏิบัติที่ใช้ง่ายคือแบบไฮบริด:
วิธีนี้ทำให้การตรวจสอบยืดหยุ่นโดยไม่กลายเป็น “เขาวงกตของการตั้งค่า” ที่ยาก debug
การนำเข้ามักล้มเหลวด้วยเหตุผลเบสิก: ฐานข้อมูลช้า, ไฟล์พุ่งที่เวลาเร่ง, หรือแถวเดียวที่ “ไม่ดี” บล็อกทั้งแบทช์ ความน่าเชื่อถือส่วนใหญ่คือการย้ายงานหนักออกจาก path ของ request/response และทำให้ทุกขั้นตอนปลอดภัยที่จะรันซ้ำ
รันการแยก การตรวจสอบ และการเขียนในงานเบื้องหลัง (คิว/worker) เพื่อไม่ให้การอัปโหลดชนกับเว็บ timeout นอกจากนี้ยังช่วยให้ขยาย worker ได้เมื่อผู้ใช้เริ่มนำเข้า spreadsheet ที่ใหญ่ขึ้น
รูปแบบที่ใช้งานได้จริงคือแบ่งงานเป็นชิ้น (เช่น 1,000 แถวต่อ job) งาน “parent” จะตารางงานชิ้นย่อย รวบรวมผล และอัปเดตความคืบหน้า
ออกแบบการนำเข้าเป็นเครื่องสถานะ (state machine) เพื่อให้ UI และทีมปฏิบัติการทราบว่าจะเกิดอะไรขึ้นเสมอ:\n\n- queued → running → completed\n- queued/running → failed (พร้อมเหตุผล)\n- queued/running → canceled (โดยผู้ใช้หรือระบบ)\n\nเก็บ timestamp และจำนวนการพยายามต่อการเปลี่ยนสถานะเพื่อให้ตอบคำถามว่า “เริ่มเมื่อไหร่?” และ “พยายามไปกี่ครั้งแล้ว?” ได้โดยไม่ต้องค้นจากล็อก
แสดงความคืบหน้าที่วัดได้: แถวที่ประมวลผล แถวที่เหลือ และข้อผิดพลาดที่พบจนถึงตอนนี้ ถ้าคุณพยากรณ์ throughput ได้ ให้เพิ่ม ETA โดยใช้ข้อความกว้างๆ เช่น “~3 นาที” แทนการนับถอยหลังที่แม่นยำ
การ retry ไม่ควรสร้างข้อมูลซ้ำหรืออัปเดตซ้ำ เทคนิคทั่วไป:\n\n- ใช้ import_id บวก row_number (หรือ row hash) เป็นคีย์ idempotency\n- Upsert โดยใช้คีย์ธรรมชาติ (เช่น external_id) แทนการ insert เสมอ\n- เขียนใน transaction ต่อชิ้นเพื่อให้ความล้มเหลวบางส่วนไม่ทำให้สถานะเสียหาย
จำกัดการนำเข้าพร้อมกันต่อ workspace และ throttle ขั้นตอนที่เขียนหนัก (เช่น สูงสุด N แถว/วินาที) เพื่อหลีกเลี่ยงการโอเวอร์โหลดฐานข้อมูลและรักษาประสบการณ์สำหรับผู้ใช้อื่น
ถ้าผู้คนไม่เข้าใจว่าเกิดอะไรขึ้น พวกเขาจะลองส่งไฟล์เดิมซ้ำจนยอมแพ้ ปฏิบัติต่อแต่ละการนำเข้าเป็น “การรัน” ชั้นหนึ่งที่มีประวัติชัดเจนและข้อผิดพลาดที่ปฏิบัติได้
เริ่มจากการสร้างหน่วยงาน import run เมื่อไฟล์ถูกส่ง ระเบียนนี้ควรจับสิ่งสำคัญ:\n\n- ใคร เป็นผู้เริ่ม (ผู้ใช้ + องค์กร)\n- อะไร ถูกนำเข้า (ชื่อไฟล์ต้นทาง ขนาด checksum ชนิดเอนทิตี)\n- เมื่อไหร่ (timestamp เริ่ม/เสร็จ)\n- อย่างไร ถูกตีความ (การตั้งค่าแมปที่ใช้, เวอร์ชันการแปลง)\n- ผลลัพธ์ (สำเร็จ/ล้มเหลว/บางส่วน, แถวที่ประมวลผล, แถวที่ปฏิเสธ)
นี่คือหน้าประวัติการนำเข้า: รายการรันพร้อมสถานะ จำนวน และหน้า “ดูรายละเอียด”
ล็อกแอปเหมาะสำหรับวิศวกร แต่ผู้ใช้ต้องการ ข้อผิดพลาดที่ค้นหาได้ เก็บข้อผิดพลาดเป็นระเบียนเชิงโครงสร้างที่เชื่อมกับ import run ทั้งสองระดับ:\n\n- ระดับแถว: หมายเลขแถว ตัวระบุหลัก (ถ้าตรวจพบ) snapshot ของค่าดิบ\n- ระดับฟิลด์: ชื่อคอลัมน์ โค้ดข้อผิดพลาด (เช่น REQUIRED, INVALID_DATE), ข้อความที่อ่านเข้าใจได้, ความรุนแรง
ด้วยโครงสร้างนี้คุณจะสามารถทำฟิลเตอร์เร็วและได้ข้อมูลเช่น “3 ประเภทข้อผิดพลาดยอดนิยมสัปดาห์นี้”
ในหน้ารายละเอียดรัน ให้มีฟิลเตอร์ตาม ประเภท, คอลัมน์, ความรุนแรง และช่องค้นหา (เช่น “email”) จากนั้นเสนอโบนัส รายงานข้อผิดพลาดแบบดาวน์โหลดได้ (CSV) ที่รวมแถวต้นฉบับพร้อมคอลัมน์พิเศษเช่น error_columns และ error_message พร้อมคำแนะนำชัดเจน เช่น “แก้รูปแบบวันที่เป็น YYYY-MM-DD”
“dry run” ตรวจสอบทุกอย่างด้วยการแมปและกฎเดียวกัน แต่ ไม่เขียน ข้อมูล เหมาะสำหรับการนำเข้าแรกและให้ผู้ใช้ซ้ำๆ ก่อน commit
การนำเข้าจะรู้สึกว่า “เสร็จ” เมื่อแถวลงฐานข้อมูล แต่ต้นทุนระยะยาวมักอยู่ที่การอัปเดตที่ยุ่งเหยิง ซ้ำกัน และประวัติการเปลี่ยนแปลงไม่ชัดเจน ส่วนนี้เกี่ยวกับการออกแบบแบบจำลองข้อมูลเพื่อให้การนำเข้าคาดเดาได้ ย้อนกลับได้ และอธิบายได้
เริ่มจากกำหนดว่าแต่ละแถวที่นำเข้าจะแมปกับโดเมนโมเดลอย่างไร สำหรับแต่ละเอนทิตี ให้ระบุว่าการนำเข้าสามารถ:\n\n- สร้างเร็กคอร์ดใหม่เท่านั้น\n- อัปเดตเร็กคอร์ดที่มีอยู่เท่านั้น\n- ทำทั้งสองอย่าง (กรณี SaaS ทั่วไป)
การตัดสินใจนี้ควรชัดเจนใน UI การตั้งค่านำเข้าและเก็บกับงานเพื่อให้พฤติกรรมทำซ้ำได้
ถ้ารองรับ “สร้างหรืออัปเดต” คุณต้องมีคีย์ upsert ที่เสถียร — ฟิลด์ที่ระบุเร็กคอร์ดเดียวกันตลอดเวลา ตัวเลือกทั่วไป:\n\n- external_id (ดีที่สุดเมื่อมาจากระบบอื่น)\n- อีเมล (ใช้ได้กับผู้ใช้/ผู้ติดต่อ แต่เปลี่ยนได้)\n- คีย์ผสม (เช่น account_id + sku)
กำหนดกฎการชน: ถ้าสองแถวมีคีย์เดียวกัน หรือคีย์ตรงกับหลายเร็กคอร์ดจะทำอย่างไร? ค่าเริ่มต้นที่ดีคือ “ให้ล้มแถวพร้อมข้อผิดพลาดที่ชัดเจน” หรือ “แถวสุดท้ายชนะ” แต่ให้เลือกอย่างมีเหตุผล
ใช้ transaction ในจุดที่ปกป้องความสอดคล้อง (เช่น สร้าง parent และ child) หลีกเลี่ยง transaction ใหญ่สำหรับไฟล์ 200k แถว เพราะจะล็อกตารางและทำให้ retry ยาก เลือกการเขียนเป็นชิ้น (เช่น 500–2,000 แถวต่อแบทช์) พร้อม upsert ที่ idempotent
การนำเข้าควรเคารพความสัมพันธ์: ถ้าแถวอ้างอิง parent (เช่น Company) ให้บังคับว่าต้องมีอยู่หรือสร้างในขั้นตอนควบคุม การล้มเหลวตั้งแต่ต้นด้วยข้อผิดพลาด “parent หาย” ป้องกันข้อมูลที่เชื่อมไม่ครบ
เพิ่มล็อกตรวจสอบสำหรับการเปลี่ยนแปลงที่ขับเคลื่อนโดยการนำเข้า: ใครเริ่มนำเข้า เมื่อไร ไฟล์ต้นทาง และสรุประดับเร็กคอร์ดของสิ่งที่เปลี่ยน (เก่า vs ใหม่) สิ่งนี้ช่วยฝ่ายสนับสนุน สร้างความเชื่อมั่นให้ผู้ใช้ และทำให้การ rollback ง่ายขึ้น
การส่งออกดูเรียบง่ายจนกว่าลูกค้าจะพยายามดาวน์โหลด “ทุกอย่าง” ก่อนกำหนดส่งงาน ระบบส่งออกที่ปรับขนาดได้ควรจัดการชุดข้อมูลใหญ่โดยไม่ทำให้แอปช้าและไม่สร้างไฟล์ที่ไม่สอดคล้อง
เริ่มด้วยสามตัวเลือก:
การส่งออกแบบ incremental มีประโยชน์สำหรับ integration และลดภาระเทียบกับการดึงทั้งหมดซ้ำๆ
ไม่ว่าเลือกอะไร ให้รักษา เฮดเดอร์ที่สม่ำเสมอ และลำดับคอลัมน์ที่เสถียรเพื่อไม่ให้กระบวนการถัดไปพัง
การส่งออกขนาดใหญ่ไม่ควรโหลดแถวทั้งหมดขึ้นหน่วยความจำ ใช้ การแบ่งหน้า/สตรีม เพื่อเขียนแถวไปพร้อมกับการดึง ลด timeout และรักษาความตอบสนองของเว็บแอป
สำหรับชุดข้อมูลใหญ่ ให้สร้างการส่งออกในงานเบื้องหลังและแจ้งผู้ใช้เมื่อตั้งค่าเสร็จ รูปแบบที่พบบ่อยคือ:\n\n1. ผู้ใช้ขอส่งออก\n2. แอปเข้าคิวงาน\n3. งานเขียนไฟล์ไปยัง object storage\n4. UI แสดงลิงก์ดาวน์โหลดและเก็บในประวัติการส่งออก
รูปแบบนี้เข้ากันได้ดีกับงานเบื้องหลังสำหรับนำเข้า และกับรูปแบบ “ประวัติการรัน + ไฟล์ดาวน์โหลด” เดียวกันที่คุณใช้สำหรับรายงานข้อผิดพลาด
การส่งออกมักถูกตรวจสอบ ให้รวมเสมอ:\n\n- นโยบาย เขตเวลา ชัดเจน (เช่น เก็บใน UTC, ส่งออกตามโซนเวลาผู้ใช้)\n- รูปแบบ วันที่ ที่สม่ำเสมอ (ISO-8601 สำหรับ JSON; ฟอร์แมตชัดเจนสำหรับ CSV/Excel)\n- ใส่ timestamp “generated at” และสำหรับ incremental export ให้ระบุ cutoff time ที่ใช้
รายละเอียดเหล่านี้ลดความสับสนและช่วยให้การ reconcile เชื่อถือได้
การนำเข้าและส่งออกเป็นฟีเจอร์ทรงพลังเพราะย้ายข้อมูลจำนวนมากอย่างรวดเร็ว นั่นก็หมายความว่าเป็นจุดที่มักเกิดบั๊กด้านความปลอดภัย เช่น บทบาทที่ให้สิทธิ์มากเกินไป ลิงก์ไฟล์รั่ว หรือบรรทัดล็อกที่รวมข้อมูลส่วนบุคคล
เริ่มจากการใช้ระบบพิสูจน์ตัวตนเดียวกับที่ใช้ในแอป — อย่าสร้างเส้นทาง auth พิเศษสำหรับการนำเข้า\n ถ้าผู้ใช้ทำงานในเบราว์เซอร์ การใช้ session-based auth (พร้อม SSO/SAML ถ้าต้องการ) มักเหมาะสม ถ้าการนำเข้า/ส่งออกเป็นงานอัตโนมัติ (งานกลางคืน พาร์ทเนอร์ integration) ให้พิจารณา API keys หรือ OAuth ที่มีการกำหนดขอบเขตและการหมุนเวียน
กฎปฏิบัติ: UI และ API ของการนำเข้าควรบังคับสิทธิ์เดียวกัน แม้ว่าจะถูกใช้โดยกลุ่มผู้ใช้ต่างกัน
ปฏิบัติต่อความสามารถการนำเข้า/ส่งออกเป็นสิทธิ์ที่ชัดเจน บทบาททั่วไปได้แก่:\n\n- Can import (อัปโหลดไฟล์ รันการนำเข้า)\n- Can export (สร้างและดาวน์โหลดการส่งออก)\n- Can view history (ดู import runs ข้อผิดพลาด จำนวน)\n- Can download files (ดาวน์โหลดการอัปโหลดต้นฉบับ รายงานข้อผิดพลาด)
ทำให้สิทธิ์ “ดาวน์โหลดไฟล์” เป็นสิทธิ์แยกต่างหาก หลายการรั่วไหลเกิดขึ้นเมื่อคนสามารถดูรายละเอียดการนำเข้าแต่ระบบสมมติว่าพวกเขาสามารถดาวน์โหลดไฟล์ได้
พิจารณาขอบเขตระดับแถวหรือ tenant: ผู้ใช้ควรนำเข้า/ส่งออกข้อมูลเฉพาะบัญชีหรือ workspace ที่เขาเป็นสมาชิก
สำหรับไฟล์ที่เก็บ (อัปโหลด, รายงานข้อผิดพลาดที่สร้างขึ้น, แฟ้มส่งออก) ให้ใช้ object storage แบบส่วนตัวและลิงก์ดาวน์โหลดอายุสั้น เข้ารหัสเมื่อจำเป็นตามข้อกำหนดการปฏิบัติตาม และทำให้สอดคล้อง: ไฟล์ต้นฉบับ, ไฟล์ staging ที่ประมวลผลแล้ว, และรายงานที่สร้างขึ้นควรปฏิบัติตามกฎเดียวกัน
ระวังล็อก: redaction ฟิลด์ที่ละเอียดอ่อน (อีเมล เบอร์โทร หมายเลขบัตร ที่อยู่) และอย่าล็อกแถวดิบเป็นค่าดีฟอลต์ เมื่อจำเป็นต้อง debug ให้จำกัดการล็อกที่มีรายละเอียดสูงไว้เฉพาะแอดมินและตั้งเวลาหมดอายุ
ปฏิบัติต่อการอัปโหลดทุกชิ้นเป็นอินพุตที่ไม่ไว้วางใจ:\n\n- บังคับตรวจสอบประเภทไฟล์ (อย่าเชื่อแค่ชื่อไฟล์)\n- กำหนดขีดจำกัดขนาดเพื่อป้องกัน DoS และการอัปโหลดโดยไม่ได้ตั้งใจขนาดใหญ่\n- พิจารณาสแกนมัลแวร์ถ้าระดับความเสี่ยงหรืออุตสาหกรรมต้องการ
นอกจากนี้ ตรวจสอบโครงสร้างตั้งแต่ต้น: ปฏิเสธไฟล์ที่เสียรูปแบบอย่างชัดเจนก่อนถึงงานเบื้องหลัง และให้ข้อความที่ชัดเจนแก่ผู้ใช้ว่าผิดอย่างไร
บันทึกเหตุการณ์ที่คุณต้องการในกรณีตรวจสอบ: ใครอัปโหลดไฟล์ ใครเริ่มนำเข้า ใครดาวน์โหลดการส่งออก การเปลี่ยนสิทธิ์ และความพยายามเข้าถึงที่ล้มเหลว
รายการ audit ควรรวม actor, timestamp, workspace/tenant, และวัตถุที่เกี่ยวข้อง (import run ID, export ID) โดยไม่เก็บข้อมูลแถวที่ละเอียดอ่อนมากเกินไป สิ่งนี้สอดคล้องกับ UI ประวัติการนำเข้าและช่วยให้ตอบคำถามว่า “ใครเปลี่ยนอะไร เมื่อไร?” ได้อย่างรวดเร็ว
ถ้าการนำเข้าและการส่งออกแตะต้องข้อมูลลูกค้า คุณจะเจอกรณีขอบเมื่อเวลาผ่านไป: การเข้ารหัสที่แปลก ๆ เซลล์ที่รวมกัน แถวที่กรอกไม่เต็ม การซ้ำกัน และปัญหา “เมื่อวานยังใช้ได้” ความสามารถในการปฏิบัติการช่วยให้ปัญหาเหล่านี้ไม่กลายเป็นฝันร้ายของฝ่ายสนับสนุน
เริ่มด้วยการทดสอบรอบที่จุดที่มักเกิดปัญหา: การแยก การแมป และการตรวจสอบ\n\n- การทดสอบการแยก: ใช้ชุดไฟล์ตัวอย่าง CSV/XLSX ที่เป็นตัวแทน (ตัวคั่นต่างกัน รูปแบบวันที่ต่างกัน คอลัมน์ว่าง ตัวเลขใหญ่ UTF‑8 vs Windows-1252). ยืนยันจำนวนแถวและว่าฟิลด์สำคัญถูกแยกถูกต้อง\n- การทดสอบการแมป+การแปลง: ให้ชุดคอลัมน์ต้นทางและยืนยันว่าแมปเป็นฟิลด์ภายในที่ถูกต้องและใช้การแปลง (trim, การปรับเคส, แปลงสกุลเงิน/เปอร์เซ็น)\n- การทดสอบกฎการตรวจสอบ: สำหรับแต่ละกฎ (required, unique, range, foreign-key existence) รวมแถวที่ “ดี” และ “ไม่ดี” และยืนยันโค้ด/ข้อความข้อผิดพลาดที่แน่นอน
แล้วเพิ่มอย่างน้อยหนึ่ง end-to-end test สำหรับฟลูว์ทั้งหมด: upload → background processing → การสร้างรายงาน การทดสอบเหล่านี้จับความไม่เข้ากันของสัญญาระหว่าง UI, API และ worker (เช่น payload ของงานขาดการตั้งค่าแมป)
ติดตามสัญญาณที่สะท้อนผลกระทบต่อผู้ใช้:\n\n- งานล้มเหลว (จำนวนและอัตรา)\n- เวลาในการประมวลผล (p50/p95)\n- อัตราข้อผิดพลาดการตรวจสอบ (การเพิ่มขึ้นอย่างฉับพลันมักหมายถึงการเปลี่ยนเทมเพลต)\n- ความลึกของคิว และ throughput ของ worker
เชื่อมต่อการแจ้งเตือนกับอาการ (failure เพิ่มขึ้น queue ลึกขึ้น) แทนที่จะตั้งเตือนไปทุก exception
ให้ทีมภายในมีอินเทอร์เฟซแอดมินเล็กๆ เพื่อ รันงานซ้ำ, ยกเลิก การนำเข้าค้าง และ ตรวจสอบความล้มเหลว (เมทาดาต้าไฟล์อินพุต, การตั้งค่าแมปที่ใช้, สรุปข้อผิดพลาด, และลิงก์ไปยังล็อก/trace)
สำหรับผู้ใช้ ลดข้อผิดพลาดที่ป้องกันได้ด้วยคำแนะนำภายในหน้า ดาวน์โหลดเทมเพลตตัวอย่าง และขั้นตอนถัดไปที่ชัดเจนในหน้าข้อผิดพลาด เก็บหน้าแนะนำกลางและลิงก์จาก UI การนำเข้า (เช่น /docs)
การส่งมอบระบบนำเข้า/ส่งออกไม่ใช่แค่ "push to production" ให้ปฏิบัติเหมือนฟีเจตคุณสมบัติที่มีค่าดีฟอลต์ที่ปลอดภัย ทางการกู้คืนที่ชัดเจน และพื้นที่สำหรับวิวัฒนาการ
ตั้งค่าสภาพแวดล้อมแยก dev/staging/prod พร้อมฐานข้อมูลแยกและ object storage แยกหรือตามพาธ สำหรับไฟล์อัปโหลดและแฟ้มส่งออก ใช้คีย์การเข้ารหัสและ credentials ต่างกันในแต่ละสภาพแวดล้อม และให้ worker ชี้ไปที่คิวที่ถูกต้อง
Staging ควรสะท้อน production: concurrency งานเดียวกัน timeout และขีดจำกัดขนาดไฟล์ เพื่อทดสอบประสิทธิภาพและสิทธิ์โดยไม่เสี่ยงกับข้อมูลจริง
การนำเข้ามักมีอายุยืน ลูกค้าจะเก็บสเปรดชีตเก่าไว้ ใช้ database migrations ตามปกติ แต่ เก็บเวอร์ชันเทมเพลตการนำเข้า (และ preset การแมป) เพื่อให้การเปลี่ยนสกีมาไม่ทำลาย CSV ของไตรมาสก่อนหน้า
แนวปฏิบัติคือเก็บ template_version กับแต่ละ import run และรองรับโค้ดที่เข้ากันได้กับเวอร์ชันเก่าจนกว่าคุณจะประกาศเลิกใช้งาน
ใช้ feature flags เพื่อปล่อยการเปลี่ยนแปลงอย่างปลอดภัย:\n\n- กฎการตรวจสอบใหม่ (เตือนก่อน แล้วเปลี่ยนเป็น error)\n- ฟอร์แมตการส่งออกใหม่ (เพิ่ม JSON เคียงกับ CSV)\n- ตัวเลือกการแมปใหม่ (เช่น แยกคอลัมน์ Full name)\n flags ช่วยให้ทดสอบกับผู้ใช้ภายในหรือกลุ่มลูกค้าจำนวนน้อยก่อนเปิดให้ทุกคน
เขียนเอกสารสำหรับการสืบสวนข้อผิดพลาดโดยใช้ประวัติการนำเข้า, job ID, และล็อก รายการตรวจสอบง่ายๆ ช่วยได้: ยืนยันเวอร์ชันเทมเพลต, ตรวจแถวที่ล้มเหลวครั้งแรก, ตรวจการเข้าถึง storage, แล้วดู worker logs ลิงก์สิ่งนี้จาก runbook ภายในและที่เหมาะสมจาก UI แอดมิน (เช่น /admin/imports)
เมื่อฟลูว์หลักเสถียร ให้ขยายเหนือการอัปโหลดด้วย:\n\n- การนำเข้าผ่าน API สำหรับ pipeline อัตโนมัติ\n- Webhooks สำหรับ “import finished” หรือ “export ready”\n- ตัวเชื่อมต่อกับเครื่องมือยอดนิยม (Google Sheets, S3, Snowflake)\n การอัปเกรดเหล่านี้ลดงานด้วยมือและทำให้เว็บแอปนำเข้าข้อมูลของคุณเป็นส่วนหนึ่งของกระบวนการของลูกค้ามากขึ้น
ถ้าคุณกำลังสร้างฟีเจอร์นี้เป็นผลิตภัณฑ์และต้องการลดเวลาจนได้ "รุ่นใช้งานครั้งแรก" ให้พิจารณาใช้ Koder.ai เพื่อสร้างต้นแบบของ import wizard, หน้าสถานะงาน, และหน้าประวัติรันครบวงจร จากนั้นส่งออกซอร์สโค้ดไปยังกระบวนการวิศวกรรมแบบปกติ วิธีนี้เหมาะเมื่อเป้าหมายคือความน่าเชื่อถือและความเร็วในการทำซ้ำ (ไม่ใช่ UI ที่ปรับแต่งจนสมบูรณ์ตั้งแต่วันแรก)
เริ่มจากการระบุ ใคร จะนำเข้าหรือส่งออก (แอดมิน ผู้ปฏิบัติงาน ลูกค้า) และกรณีการใช้งานสำคัญ (การโหลดข้อมูลขนาดใหญ่ตอนเริ่มใช้งาน, การซิงก์เป็นรอบ, การส่งออกครั้งเว้นครั้ง)
เขียนข้อจำกัดของวันแรกให้ชัดเจน:
การตัดสินใจเหล่านี้จะเป็นตัวกำหนดสถาปัตยกรรม ความซับซ้อนของ UI และภาระงานฝ่ายสนับสนุน
ใช้การประมวลผลแบบ ซิงโครนัส เมื่อไฟล์มีขนาดเล็กและการตรวจสอบ+การเขียนเสร็จภายในเวลาที่เว็บร้องขออนุญาตได้
ให้ใช้ งานเบื้องหลัง (background jobs) เมื่อ:
รูปแบบที่ใช้บ่อยคือ: อัปโหลด → เข้าคิว → แสดงสถานะ/ความคืบหน้า → แจ้งเตือนเมื่อเสร็จ
เก็บทั้งสองแบบไว้เพื่อเหตุผลต่างกัน:
เก็บไฟล์ดิบให้คงที่ (immutable) และเชื่อมโยงกับ import run
สร้างขั้นตอนตัวอย่างที่ตรวจจับเฮดเดอร์และแยกตัวอย่างข้อมูลเล็กๆ (เช่น 20–100 แถว) ก่อน commit ใดๆ
รองรับความหลากหลายที่พบบ่อย:
ล้มเหลวเร็วเมื่อเป็นบล็อกจริงๆ (ไฟล์อ่านไม่ได้ คอลัมน์ที่จำเป็นหาย) แต่ไม่ปฏิเสธข้อมูลที่ยังสามารถแมปหรือแปลงได้ในขั้นตอนถัดไป
ใช้ตารางแมปง่ายๆ: คอลัมน์ต้นทาง → ฟิลด์ปลายทาง.
แนวปฏิบัติที่ดี:
แสดงตัวอย่างที่แมปแล้วเสมอเพื่อให้ผู้ใช้จับข้อผิดพลาดก่อนประมวลผลทั้งไฟล์
รองรับการแปลงข้อมูลที่เรียบง่ายและชัดเจนเพื่อให้ผู้ใช้คาดเดาผลลัพธ์ได้:
แสดง “ต้นฉบับ → แปลงแล้ว” ในตัวอย่าง และเตือนเมื่อแปลงใช้ไม่ได้
แยกการตรวจสอบเป็นชั้น:
ใน UI ให้ข้อความที่ทำได้จริงพร้อมระบุแถว/คอลัมน์ (เช่น “แถว 42, Start Date: ต้องเป็นรูปแบบ YYYY-MM-DD”).
ตัดสินใจว่าการนำเข้าจะเป็น (ล้มทั้งไฟล์) หรือ (ยอมรับแถวที่ถูกต้อง) และพิจารณาให้ทั้งสองแบบสำหรับแอดมินได้
ทำให้การประมวลผลสามารถ retry ได้อย่างปลอดภัย:
import_id + row_number หรือ row hash)external_id) แทนการ insert เสมอสร้างบันทึก import run เมื่อไฟล์ถูกส่งทันที และเก็บข้อผิดพลาดแบบโครงสร้าง ไม่ใช่แคล็อก
คุณสมบัติที่มีประโยชน์:
ปฏิบัติต่อการนำเข้า/ส่งออกเป็นฟังก์ชันที่มีสิทธิพิเศษ:
ถ้าจัดการ PII ให้กำหนดนโยบายการเก็บรักษาและการลบตั้งแต่ต้น
นอกจากนี้ ควร throttle การนำเข้าพร้อมกันต่อ workspace เพื่อปกป้องฐานข้อมูลและผู้ใช้คนอื่น
error_columns และ error_messageสิ่งนี้ช่วยลดพฤติกรรม “ลองส่งซ้ำจนสำเร็จ” และลดตั๋วซัพพอร์ต