18 ก.ค. 2568·3 นาที
วิธีสร้างแอปมือถือเพื่อมอนิเตอร์อุปกรณ์ระยะไกล
เรียนรู้วิธีวางแผน สร้าง และเปิดตัวแอปมือถือสำหรับมอนิเตอร์อุปกรณ์ระยะไกล: สถาปัตยกรรม การไหลข้อมูล อัปเดตแบบเรียลไทม์ การแจ้งเตือน ความปลอดภัย และการทดสอบ
เรียนรู้วิธีวางแผน สร้าง และเปิดตัวแอปมือถือสำหรับมอนิเตอร์อุปกรณ์ระยะไกล: สถาปัตยกรรม การไหลข้อมูล อัปเดตแบบเรียลไทม์ การแจ้งเตือน ความปลอดภัย และการทดสอบ
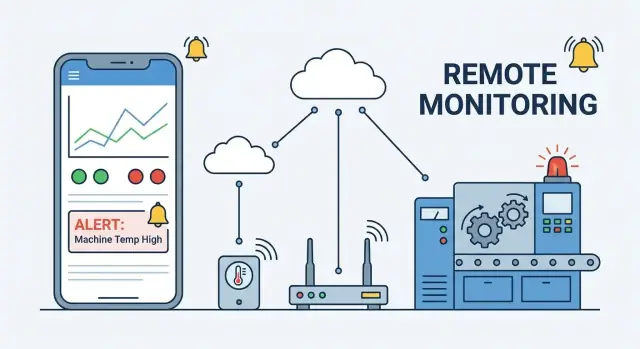
การมอนิเตอร์อุปกรณ์ระยะไกลหมายความว่าคุณสามารถเห็นว่าอุปกรณ์กำลังทำอะไร—และมันยังมีสภาพดีหรือไม่—โดยไม่ต้องอยู่ใกล้เครื่องนั้น แอปมอนิเตอร์บนมือถือเป็น “หน้าต่าง” แจกแจงฟลีทของอุปกรณ์: มันดึงสัญญาณจากแต่ละอุปกรณ์ แปลงเป็นสถานะที่เข้าใจได้ และช่วยให้คนที่เหมาะสมทำงานได้รวดเร็วขึ้น
การมอนิเตอร์ระยะไกลพบได้ทุกที่ที่อุปกรณ์กระจายตัวหรือเข้าถึงยาก ตัวอย่างทั่วไปได้แก่:
ในทุกกรณี งานของแอปคือการลดการคาดเดาและแทนที่ด้วยข้อมูลที่ชัดเจนและเป็นปัจจุบัน
แอปมอนิเตอร์ที่ดีโดยทั่วไปให้พื้นฐานสี่อย่าง:
แอปที่ดีที่สุดยังทำให้การค้นหาและกรองตามไซต์ รุ่น ความรุนแรง หรือเจ้าของทำได้ง่าย—เพราะการมอนิเตอร์ฟลีทเกี่ยวกับความสำคัญมากกว่าการมองแค่อุปกรณ์เดียว
ก่อนสร้างฟีเจอร์ ให้กำหนดว่า “การมอนิเตอร์ที่ดีขึ้น” สำหรับทีมคุณหมายถึงอะไร ตัวชี้วัดความสำเร็จที่พบบ่อยมีดังนี้:
เมื่อเมตริกเหล่านี้ดีขึ้น แอปมอนิเตอร์ไม่ได้แค่รายงานข้อมูล—แต่มันช่วยป้องกันการหยุดทำงานและลดต้นทุนการปฏิบัติการ
ก่อนเลือกระดับโปรโตคอลหรือออกแบบชาร์ต ให้ตัดสินใจว่าแอปนี้สำหรับใครและ “ความสำเร็จ” ในวันแรกเป็นอย่างไร แอปมอนิเตอร์ระยะไกลมักล้มเหลวเมื่อพยายามตอบสนองทุกคนด้วยเวิร์กโฟลว์เดียวกัน
เขียนสถานการณ์จริง 5–10 รายการที่แอปต้องรองรับ เช่น:
สถานการณ์เหล่านี้ช่วยหลีกเลี่ยงการสร้างฟีเจอร์ที่ดูมีประโยชน์แต่ไม่ลดเวลาในการตอบสนอง
อย่างน้อย วางแผนสำหรับ:
ต้องมี: การยืนยันตัวตน + บทบาท, สต็อกอุปกรณ์, สถานะแบบเรียลไทม์(ประมาณ), ชาร์ตพื้นฐาน, การแจ้งเตือน + push, และเวิร์กโฟลว์เหตุการณ์ขั้นต่ำ (ยืนยัน/แก้ไข)\n อยากได้: มุมมองแผนที่, การวิเคราะห์ขั้นสูง, กฎอัตโนมัติ, การลงทะเบียนด้วย QR, แชทในแอป, และแดชบอร์ดที่กำหนดเอง
เลือกตามว่าใครถือโทรศัพท์ในโลกจริง หากช่างภาคสนามใช้ OS เดียว ให้เริ่มจาก OS นั้น หากต้องใช้ทั้งคู่อย่างรวดเร็ว วิธีข้ามแพลตฟอร์มก็ทำได้—แต่จำกัดขอบเขต MVP เพื่อให้ประสิทธิภาพและพฤติกรรมการแจ้งเตือนคาดเดาได้
ถ้าคุณต้องการยืนยัน MVP อย่างรวดเร็ว แพลตฟอร์มอย่าง Koder.ai สามารถช่วยสร้างต้นแบบ UI การมอนิเตอร์และเวิร์กโฟลว์แบ็กเอนด์จากสเปกที่ขับเคลื่อนด้วยแชท (เช่น: รายการอุปกรณ์ + รายละเอียดอุปกรณ์ + การแจ้งเตือน + บทบาท) แล้วทำซ้ำจนถึงการผลิตเมื่อเวิร์กโฟลว์หลักได้รับการพิสูจน์แล้ว
ก่อนเลือกระดับโปรโตคอลหรือออกแบบแดชบอร์ด ให้ชัดเจนเกี่ยวกับข้อมูลที่มี ที่มา และวิธีการเดินทาง แผนที่ข้อมูลที่ชัดเจนช่วยป้องกันสองความล้มเหลวที่พบบ่อย: เก็บทุกอย่าง (และจ่ายไปตลอด) หรือเก็บน้อยเกินไป (และมองไม่เห็นตอนเกิดเหตุ)
เริ่มจากการระบุสัญญาณที่แต่ละอุปกรณ์สามารถสร้างและความน่าเชื่อถือของมัน:\n\n- เซ็นเซอร์: อุณหภูมิ การสั่น การแจ้งระดับแบตเตอรี่ การดึงพลังงาน สถานะประตูเปิด\n- บันทึก: บันทึกเฟิร์มแวร์ รหัสข้อผิดพลาด ดัมพ์การชน เหตุการณ์การเชื่อมต่อ\n- การตรวจสุขภาพ: ping “ฉันยังอยู่” ผลการทดสอบตัวเอง การรีเซ็ต watchdog\n- ตำแหน่ง: GPS การประมาณจาก Wi‑Fi/เซลล์ geofences ตำแหน่งที่ทราบล่าสุด
สำหรับแต่ละรายการ ให้บันทึกหน่วย ขอบเขตที่คาดหวัง และลักษณะที่เป็น “ไม่ดี” สิ่งนี้จะเป็นรากฐานสำหรับกฎการแจ้งเตือนและเกณฑ์ใน UI ต่อไป
ไม่ใช่ข้อมูลทุกชนิดที่ควรส่งแบบเรียลไทม์ ตัดสินใจว่าสิ่งใดต้องอัปเดตใน วินาที (เช่น สัญญาณเตือนความปลอดภัย สถานะเครื่องจักรวิกฤต), อะไรอัปเดตเป็น นาที (แบตเตอรี่ สัญญาณ), และอะไรอัปเดตเป็น ชั่วโมง/วัน (สรุปการใช้งาน) ความถี่ส่งผลต่อแบตเตอรี่ของอุปกรณ์ ค่าใช้จ่ายข้อมูล และความรู้สึก “สด” ของแอป
แนวปฏิบัติที่เป็นประโยชน์คือการกำหนดชั้น:\n\n- Hot telemetry: บ่อย ขนาด payload เล็ก\n- Warm telemetry: สถานะเป็นช่วงๆ\n- Cold telemetry: อัปโหลดแบบกลุ่มเมื่อสะดวก
การเก็บรักษาเป็นการตัดสินใจเชิงผลิตภัณฑ์ ไม่ใช่แค่การตั้งค่าเก็บข้อมูล เก็บ ข้อมูลดิบ พอสำหรับการสืบสวนและยืนยันการแก้ปัญหา แล้วลดทอนเป็น สรุป (min/max/avg, percentiles) สำหรับชาร์ตแนวโน้ม ตัวอย่าง: ดิบ 7–30 วัน เก็บสรุปเป็นรายชั่วโมง 12 เดือน
อุปกรณ์และโทรศัพท์จะออฟไลน์ กำหนดสิ่งที่ต้อง บัฟเฟอร์บนอุปกรณ์ อะไร ทิ้งได้ และวิธีแสดงข้อมูลที่ล่าช้าในแอป (เช่น “อัปเดตล่าสุด 18 นาทีที่แล้ว”) ตรวจสอบให้แน่ใจว่า timestamp มาจากอุปกรณ์ (หรือแก้ไขฝั่งเซิร์ฟเวอร์) เพื่อให้ประวัติถูกต้องหลังการเชื่อมต่อใหม่
แอปมอนิเตอร์ระยะไกลมีความน่าเชื่อถือแค่ระบบด้านหลังที่รองรับมัน ก่อนหน้าจอและแดชบอร์ด ให้เลือกสถาปัตยกรรมที่ตรงกับความสามารถของอุปกรณ์ สภาพเครือข่าย และระดับ "เรียลไทม์" ที่คุณต้องการจริงๆ
การตั้งค่าส่วนใหญ่มีโซ่แบบนี้:\n\nDevice → (optional) Gateway → Cloud backend → Mobile app\n\n- Device: วัดเทเลเมทรี (อุณหภูมิ แบตเตอรี่ ข้อผิดพลาด) และรับคำสั่ง (รีสตาร์ท เปลี่ยนช่วง)\n- Gateway: รวมอุปกรณ์ท้องถิ่น (BLE/Zigbee/Modbus) บัฟเฟอร์ข้อมูล และเชื่อมต่อกับอินเทอร์เน็ต\n- Cloud: ตรวจสอบผู้ใช้/อุปกรณ์ เก็บประวัติเชิงเวลา ทริกเกอร์การแจ้งเตือน และเปิดเผย API\n- Mobile app: แสดงสถานะปัจจุบัน ประวัติ และเหตุการณ์; ส่งคำสั่งจากผู้ใช้
อุปกรณ์เชื่อมตรงสู่คลาวด์ เหมาะเมื่ออุปกรณ์มีการเชื่อมต่อ IP ที่เชื่อถือได้ (Wi‑Fi/LTE) และมีพลังงาน/ซีพียูเพียงพอ\n\n- ข้อดี: ส่วนประกอบน้อย จัดการง่าย หน่วงต่ำ\n- ข้อเสีย: แต่ละอุปกรณ์ต้องจัดการการเชื่อมต่อที่ปลอดภัย อัปเดต และเครือข่ายไม่เสถียร\n สถาปัตยกรรมผ่านเกตเวย์ เหมาะกับอุปกรณ์จำกัดหรือการตั้งค่าอุตสาหกรรม\n\n- ข้อดี: เกตเวย์บัฟเฟอร์ช่วงออฟไลน์ แปลงโปรโตคอล และลดค่าใช้จ่ายเซลลูลาร์โดยการส่งเป็นกลุ่ม\n- ข้อเสีย: ฮาร์ดแวร์เพิ่มขึ้น; เกตเวย์ล้มเหลวอาจกระทบอุปกรณ์จำนวนมาก
การแยกใช้งานที่พบบ่อยคือ MQTT สำหรับ device→cloud และ WebSockets + REST สำหรับ cloud→mobile
[Device Sensors]
|
| telemetry (MQTT/HTTP)
v
[Gateway - optional] ---- local protocols (BLE/Zigbee/Serial)
|
| secure uplink (MQTT/HTTP)
v
[Cloud Ingest] -> [Rules/Alerts] -> [Time-Series Storage]
|
| REST (queries/commands) + WebSocket (live updates)
v
[Mobile App Dashboard]
เลือกสถาปัตยกรรมที่ง่ายที่สุดที่ยังทำงานได้ภายใต้เงื่อนไขเครือข่ายที่แย่ที่สุดของคุณ—แล้วออกแบบทุกอย่างอื่น (โมเดลข้อมูล การแจ้งเตือน UI) รอบการตัดสินใจนั้น
แอปมอนิเตอร์มีความน่าเชื่อถือเท่ากับวิธีที่มันระบุอุปกรณ์ ติดตามสถานะ และจัดการวงจรชีวิตตั้งแต่การลงทะเบียนจนถึงการปลดใช้งาน การจัดการวงจรชีวิตที่ดีช่วยป้องกันอุปกรณ์ปริศนา ระเบียนซ้ำ และหน้าจอสถานะเก่า
เริ่มด้วยกลยุทธ์ตัวตนที่ชัดเจน: ทุกอุปกรณ์ต้องมี ID ที่ไม่ซ้ำและไม่เปลี่ยนแปลง เช่น หมายเลขซีเรียลจากโรงงาน ตัวระบุฮาร์ดแวร์ที่ปลอดภัย หรือ UUID ที่สร้างและเก็บบนอุปกรณ์
ขณะ provision ให้เก็บ metadata ขั้นต่ำที่มีประโยชน์: รุ่น เจ้าของ/ไซต์ วันที่ติดตั้ง และความสามารถ (เช่น มี GPS รองรับ OTA) ทำให้การลงทะเบียนง่าย—สแกน QR โคลมสิทธิ์อุปกรณ์ และยืนยันว่ามันปรากฏในฟลีท
กำหนดโมเดลสถานะที่สอดคล้องกันเพื่อให้แอปมือถือแสดงสถานะเรียลไทม์โดยไม่ต้องเดา:\n\n- ออนไลน์/ออฟไลน์: ตาม heartbeat หรือเวลาเมสเสจล่าสุด\n- Last seen: timestamp พร้อมที่เชื่อมต่อล่าสุด (ถ้าจำเป็น)\n- เวอร์ชันเฟิร์มแวร์: เพื่อตรวจจับอุปกรณ์ที่ล้าสมัย\n- แบตเตอรี่: ระดับล่าสุดและสถานะการชาร์จ (ถ้าใช้ได้)
ทำให้กฎชัดเจน (เช่น “ออฟไลน์ถ้าไม่มี heartbeat เป็นเวลา 5 นาที”) เพื่อให้ทีมสนับสนุนและผู้ใช้ตีความแดชบอร์ดแบบเดียวกัน
ควรปฏิบัติต่อคำสั่งเป็นงานที่ติดตามได้:\n\n1. ส่งคำสั่ง (พร้อม command ID ที่ไม่ซ้ำ)\n2. ยืนยันการรับ (อุปกรณ์ตอบรับ)\n3. รายงานผล (สำเร็จ/ล้มเหลว + รายละเอียด)
โครงสร้างนี้ช่วยให้คุณแสดงความคืบหน้าในแอปและป้องกันความสับสน “มันทำงานไหม?”
อุปกรณ์จะหลุด เชื่อมต่อใหม่ หรือหลับ ออกแบบรับมือ:\n\n- Retries และ timeouts: retry ด้วย backoff; แสดง “pending” เมื่อเหมาะสม\n- Idempotency: คำขอซ้ำด้วย command ID เดิมไม่ควรทำงานซ้ำ\n- ความล้มเหลวที่สง่างาม: เก็บคำสั่งสำหรับส่งภายหลังเมื่ออุปกรณ์เชื่อมต่อใหม่
เมื่อคุณจัดการตัวตน สถานะ และคำสั่งในลักษณะนี้ ส่วนที่เหลือของแอปมอนิเตอร์จะน่าเชื่อถือและใช้งานง่ายขึ้นมาก
แบ็กเอนด์ของคุณคือ “ห้องควบคุม” สำหรับแอปมอนิเตอร์ระยะไกล: มันรับเทเลเมทรี เก็บอย่างมีประสิทธิภาพ และให้ API ที่เร็วและคาดเดาได้กับแอปมือถือ
ทีมส่วนใหญ่ลงเอยด้วยชุดบริการเล็ก ๆ (โค้ดเบสที่แยกต่างหากหรือโมดูลที่แยกอย่างดี):\n\n- Ingestion API: รับเทเลเมทรีจากอุปกรณ์ (มักผ่าน MQTT/HTTP gateways) ตรวจสอบ payload ตั้ง timestamp และคิวงาน\n- Device registry: แหล่งความจริงสำหรับตัวตนอุปกรณ์ metadata (รุ่น เฟิร์มแวร์ ไซต์) และสถานะวงจรชีวิต (provisioned, active, retired)\n- User management: องค์กร บทบาท สิทธิ์ และการบันทึก audit—เพื่อให้คนที่เหมาะสมเห็นฟลีทที่ถูกต้อง
หลายระบบใช้ทั้งสองแบบ: relational สำหรับข้อมูลควบคุม และ time-series สำหรับเทเลเมทรี
แดชบอร์ดมือถือต้องการชาร์ตที่โหลดได้เร็ว เก็บข้อมูลดิบไว้ แต่ก็เตรียมคำนวณล่วงหน้า:\n\n- Rollups (เช่น ค่าเฉลี่ย/สูงสุด/ต่ำสุด 1 นาที 15 นาที 1 ชั่วโมง)\n- ซีรีส์ลดขนาด สำหรับช่วงเวลานาน\n- สถานะล่าสุด ต่ออุปกรณ์ (ระเบียนกะทัดรัดที่แอปสามารถดึงได้ทันที)
ทำให้ API เรียบง่ายและเป็นมิตรกับแคช:\n\n- GET /devices (รายการ + ตัวกรองเช่น ไซต์ สถานะ)\n- GET /devices/{id}/status (สถานะล่าสุดที่ทราบ แบตเตอรี่ การเชื่อมต่อ)\n- GET /devices/{id}/telemetry?from=&to=&metric= (การคิวรีประวัติ)\n- GET /alerts และ POST /alerts/rules (ดูและจัดการการแจ้งเตือน)
ออกแบบการตอบสนองรอบ UI บนมือถือ: ให้ความสำคัญกับ “สถานะปัจจุบันคืออะไร?” ก่อน แล้วให้ประวัติเชิงลึกเมื่อผู้ใช้คลิกลงไป
“เรียลไทม์” ในแอปมอนิเตอร์ระยะไกลมักไม่ใช่ “ทุกมิลลิวินาที” แต่มักหมายถึง “สดพอที่จะลงมือ” โดยไม่ต้องให้วิทยุทำงานตลอดหรือกด backend จนหัวแตก
Polling (แอปถามเซิร์ฟเวอร์เป็นช่วง ๆ) ง่ายและประหยัดแบตเมื่อการอัปเดตไม่บ่อย มักเพียงพอสำหรับแดชบอร์ดที่ดูไม่บ่อยนัก หรือเมื่ออุปกรณ์รายงานทุกไม่กี่นาที
Streaming updates (เซิร์ฟเวอร์ผลักการเปลี่ยนแปลงไปยังแอป) ให้ความรู้สึกทันที แต่ต้องเชื่อมต่อค้างและอาจเพิ่มการใช้พลังงาน—โดยเฉพาะบนเครือข่ายไม่เสถียร
แนวทางปฏิบัติที่สมเหตุสมผลคือ ผสม: poll เบื้องหลังด้วยอัตราต่ำ แล้วสลับเป็น streaming เฉพาะเมื่อผู้ใช้กำลังดูหน้าจออย่างใกล้ชิด
ใช้ WebSockets (หรือช่องทาง push คล้ายกัน) เมื่อ:\n\n- ผู้ปฏิบัติงานต้องดูการเปลี่ยนแปลงสถานะอุปกรณ์แบบสด (เช่น สัญญาณเตือน เหตุการณ์ประตูเปิด/ปิด)\n- คุณกำลังแสดงเมตริกที่เปลี่ยนเร็วเพื่อการแก้ปัญหา\n- คุณสามารถจำกัดให้เป็น “foreground เท่านั้น” และตัดการเชื่อมต่อเมื่อแอปเฉยเมย
ใช้ polling เมื่:\n\n- ผู้ใช้ส่วนใหญ่ต้องการแค่สถานะล่าสุด ไม่ใช่ทุกการเปลี่ยนแปลงย่อยๆ\n- เครือข่ายไม่เสถียร (ลูปการเชื่อมต่อใหม่สามารถเสียพลังงาน)\n- แอปมักอยู่ในพื้นหลัง
ปัญหาแบตและสเกลมักมีสาเหตุเดียวกัน: คำขอมากเกินไป\n\nรวมการอัปเดต (ดึงข้อมูลหลายอุปกรณ์ในคำขอเดียว), แบ่งหน้าประวัติยาว ๆ, และใช้ rate limit เพื่อไม่ให้หน้าจอเดียวขอข้อมูลหลายร้อยอุปกรณ์ทุกวินาที หากมีเทเลเมทรีความถี่สูง ให้ลดขนาดสำหรับมือถือ (เช่น จุดละ 10–30 วินาที) และให้ backend ทำ aggregation
แสดงเสมอ:\n\n- อัปเดตล่าสุด timestamp ต่ออุปกรณ์ (และต่อวิดเจ็ตถ้าจำเป็น)\n- สถานะการเชื่อมต่อ (ออนไลน์/ออฟไลน์/ไม่ทราบ)\n- ความแตกต่างที่ชัดเจนระหว่าง ข้อมูลสด และ ข้อมูลแคช
นี้ช่วยสร้างความเชื่อถือและป้องกันการลงมือบนสถานะที่ล้าสมัย
การแจ้งเตือนคือจุดที่แอปมอนิเตอร์ระยะไกลจะสร้างความเชื่อถือ—หรือทำลายมัน เป้าหมายไม่ใช่ “แจ้งเตือนมากขึ้น” แต่คือส่งให้คนที่ถูกต้องทำงานที่ถูกต้องพร้อมบริบทเพียงพอที่จะแก้ปัญหาได้เร็ว
เริ่มจากชุดเล็ก ๆ ของประเภทการแจ้งเตือนที่สอดคล้องกับปัญหาการปฏิบัติจริง:\n\n- Threshold alerts: เมตริกข้ามขีดจำกัด (อุณหภูมิ แบตเตอรี่ อัตราข้อผิดพลาด) ให้แยกระดับ “เตือน” และ “วิกฤต” เมื่อการดำเนินการที่ต้องการต่างกัน\n- Anomaly flags: ระบบตรวจพบพฤติกรรมผิดปกติ (พลังงานกระชาก ค่าติดค้างของเซ็นเซอร์) มีประโยชน์ถ้าแอปแสดง เหตุผล ที่ถูกทำเครื่องหมาย\n- Offline / heartbeat missed: อุปกรณ์ไม่ได้เช็กอิน แยกแยะจาก “ข้อมูลผิดพลาด” และรวมเวลา last-seen พร้อมประวัติการเชื่อมต่อ
ใช้ การแจ้งเตือนในแอป เป็นบันทึกครบถ้วน (ค้นหาและกรองได้) เพิ่ม push notifications สำหรับปัญหาเร่งด่วน และพิจารณา อีเมล/SMS เฉพาะสำหรับการยกระดับความรุนแรงหรือช่วงหลังเวลาทำการ Push ควรกระชับ: ชื่ออุปกรณ์ ความรุนแรง และการกระทำที่ชัดเจนหนึ่งอย่าง
เสียงรบกวนทำให้การตอบสนองลดลง ใส่:\n\n- Cooldowns (อย่าแจ้งซ้ำทุกนาที)\n- Deduplication (รวมความล้มเหลวซ้ำเป็นเหตุการณ์เดียว)\n- Escalation rules (ถ้าไม่ยืนยันภายใน X นาที แจ้งผู้รับช่วงถัดไป)
ปฏิบัติต่อการแจ้งเตือนเป็นเหตุการณ์ที่มีสถานะ: Triggered → Acknowledged → Investigating → Resolved ทุกขั้นตอนควรถูกบันทึก: ใครยืนยัน เมื่อใด เปลี่ยนอะไรบ้าง และมีหมายเหตุแบบเลือกได้ ร่องรอยนี้ช่วยในการปฏิบัติตามข้อกำหนด การทบทวนหลังเหตุ และการปรับแต่งเกณฑ์เพื่อให้ส่วน /blog/monitoring-best-practices ของคุณอ้างอิงข้อมูลจริงได้ในภายหลัง
แอปมอนิเตอร์ชนะหรือแพ้ด้วยคำถามเดียว: คนคนหนึ่งเข้าใจว่าผิดพลาดอะไรได้ภายในไม่กี่วินาทีหรือไม่? มุ่งสู่หน้าจอที่มองเห็นได้ทันทีที่เน้นข้อยกเว้นก่อน และรายละเอียดอยู่ห่างเพียงการแตะเดียว
หน้าจอหลักมักเป็นรายการอุปกรณ์ ทำให้การจำกัดฟลีททำได้เร็ว:\n\n- ค้นหา ตามชื่ออุปกรณ์ ID หรือซีเรียล\n- ตัวกรอง สำหรับสถานะ (ออนไลน์/ออฟไลน์/เตือน) รุ่น เฟิร์มแวร์ และเวลา last-seen\n- แท็กและการจัดกลุ่ม ตามไซต์ ลูกค้า หรืออาคาร (เช่น “คลังสินค้า A → ห้องเย็น 2”)
ใช้ชิพสถานะชัดเจน (Online, Degraded, Offline) และแสดงบรรทัดรองที่สำคัญเพียงบรรทัดเดียว เช่น last heartbeat (“เห็น 2m ที่แล้ว”)
บนหน้ารายละเอียดอุปกรณ์ หลีกเลี่ยงตารางยาว ๆ ใช้ บัตรสถานะ สำหรับสิ่งสำคัญ:\n\n- การเชื่อมต่อ (สัญญาณ, การเช็กอินล่าสุด)\n- พลังงาน (แบตเตอรี่, การชาร์จ, แรงดัน)\n- สุขภาพ (รหัสข้อผิดพลาด, อุณหภูมิ, uptime)
เพิ่มแผง เหตุการณ์ล่าสุด ที่มีข้อความอ่านง่าย (“ประตูเปิด”, “อัปเดตเฟิร์มแวร์ล้มเหลว”) และ timestamp หากมีคำสั่ง ให้ซ่อนไว้หลังการกระทำที่ชัดเจน (เช่น “Restart device”) พร้อมการยืนยัน
ชาร์ตควรตอบคำถามว่า “อะไรเปลี่ยนไป?” ไม่ใช่โชว์ปริมาณข้อมูล\n\nรวม ตัวเลือกช่วงเวลา (1h / 24h / 7d / กำหนดเอง) แสดง หน่วย ทุกที่ และใช้ป้ายชื่อที่อ่านง่าย เมื่อเป็นไปได้ ใส่เครื่องหมายอธิบายความผิดปกติให้สอดคล้องกับบันทึกเหตุการณ์
อย่าใช้สีเพียงอย่างเดียว จับคู่ ความคอนทราสต์ของสี กับ ไอคอนสถานะ และข้อความ (“Offline”) เพิ่มขนาดเป้าการแตะ รองรับ Dynamic Type และรักษาสถานะสำคัญให้มองเห็นแม้ในแสงสว่างหรือโหมดประหยัดพลังงาน
ความปลอดภัยไม่ใช่ฟีเจอร์ "ทีหลัง" ทันทีที่คุณแสดงสถานะอุปกรณ์แบบเรียลไทม์หรืออนุญาตคำสั่งระยะไกล คุณกำลังจัดการข้อมูลเชิงปฏิบัติการที่ละเอียดอ่อน—และอาจควบคุมอุปกรณ์จริงได้
สำหรับทีมส่วนใหญ่ magic link sign-in เป็นค่าเริ่มต้นที่ดี: ผู้ใช้ป้อนอีเมล รับลิงก์ใช้ครั้งเดียวในเวลาจำกัด และคุณหลีกเลี่ยงปัญหาการรีเซ็ตรหัสผ่าน
เก็บ magic link ให้สั้น-หมดอายุเร็ว (เป็นนาที) ใช้ครั้งเดียว และผูกกับบริบทอุปกรณ์/เบราว์เซอร์เมื่อเป็นไปได้ หากรองรับหลายองค์กร ให้เลือกองค์กรอย่างชัดเจนเพื่อผู้ใช้จะไม่เข้าถึงฟลีทผิด
การยืนยันตัวตนพิสูจน์ว่า ใคร แต่การอนุญาตกำหนดว่า ทำอะไรได้ ใช้ บทบาทตามสิทธิ์ (RBAC) อย่างน้อยสองบทบาท:\n\n- Viewer: ดูเทเลเมทรี ประวัติ และแดชบอร์ดได้\n- Operator/Admin: ส่งคำสั่ง (รีสตาร์ทอุปกรณ์ เปลี่ยนการตั้งค่า) และจัดการการแจ้งเตือน
ในการปฏิบัติ การควบคุมเป็นการกระทำที่เสี่ยงที่สุด ปฏิบัติต่อ endpoint คำสั่งเป็นชุดสิทธิ์แยกต่างหาก ถึงแม้ว่าจะอยู่ใน UI ปุ่มเดียว
ใช้ TLS ทุกที่—ระหว่างแอปมือถือและ API แบ็กเอนด์ และระหว่างอุปกรณ์และบริการ ingestion (MQTT หรือ HTTP จะปลอดภัยถ้าเข้ารหัส)
บนโทรศัพท์ เก็บโทเค็นใน keychain/keystore ของ OS อย่าเก็บใน preferences แบบอ่านได้ ต่อแบ็กเอนด์ ออกแบบ API สิทธิ์น้อยที่สุด: คำขอแดชบอร์ดไม่ควรคืนคีย์ลับ และ endpoint ควบคุมอุปกรณ์ไม่ควรยอมรับ payload ที่ “ทำอะไรก็ได้”\n
บันทึกเหตุการณ์ที่เกี่ยวข้องกับความปลอดภัย (การลงชื่อเข้าใช้ การเปลี่ยนบทบาท ความพยายามส่งคำสั่ง) เป็น audit events ที่ทบทวนได้ สำหรับการกระทำที่อันตราย—เช่น ปิดใช้งานอุปกรณ์ เปลี่ยนเจ้าของ หรือปิดการแจ้งเตือน—ใส่ขั้นตอนยืนยันและแสดงผู้ทำงาน (“ใคร ทำอะไร เมื่อใด”)
แอปมอนิเตอร์ระยะไกลอาจดูสมบูรณ์แบบในห้องแลป แต่ล้มเหลวในภาคสนาม ความแตกต่างมักเป็น “ชีวิตจริง”: เครือข่ายไม่เสถียร เทเลเมทรีเสียงดัง และอุปกรณ์ที่ทำสิ่งไม่คาดคิด การทดสอบควรเลียนแบบเงื่อนไขเหล่านั้นให้ใกล้เคียง
เริ่มจาก unit tests สำหรับการแยกวิเคราะห์ การตรวจสอบ และการเปลี่ยนสถานะ (เช่น อุปกรณ์จาก online เป็น stale เป็น offline) เพิ่ม API tests ที่ยืนยันการยืนยันตัวตน การแบ่งหน้า และการกรองสำหรับประวัติอุปกรณ์
จากนั้นรัน end-to-end tests สำหรับเวิร์กโฟลว์ผู้ใช้สำคัญที่สุด: เปิดแดชบอร์ดฟลีท คลิกเข้าอุปกรณ์ ดูเทเลเมทรีล่าสุด ส่งคำสั่ง และยืนยันผล นี่คือการทดสอบที่จับสมมติฐานที่แตกต่างระหว่าง UI บนมือถือ แบ็กเอนด์ และโปรโตคอลอุปกรณ์
อย่าพึ่งพาอุปกรณ์จริงไม่กี่ตัว สร้างตัวสร้างเทเลเมทรีเทียมที่สามารถ:\n\n- ปล่อยการอ่านที่สมจริง (รวมถึงการกระชากและค่าเซ็นเซอร์ติดค้าง)\n- สลับออนไลน์/ออฟไลน์ รวมถึงช่องว่างยาวและ reconnect storms\n- ส่งการยืนยันหรือข้อผิดพลาดสำหรับคำสั่ง
จับคู่กับการจำลองเครือข่ายบนมือถือ: สลับโหมดเครื่องบิน การสูญเสียแพ็กเกจ และการเปลี่ยนระหว่าง Wi‑Fi กับเซลลูลาร์ เป้าหมายคือยืนยันว่าแอปยังเข้าใจได้เมื่อข้อมูลมาช้า เป็นบางส่วน หรือหายไป
ระบบมอนิเตอร์ระยะไกลมักเจอ:\n\n- Clock skew ระหว่างอุปกรณ์กับเซิร์ฟเวอร์\n- ข้อความซ้ำ (มักเกิดหลังเชื่อมต่อใหม่) ที่ไม่ควรสร้างเหตุการณ์ซ้ำ\n- ข้อมูลขาดหาย ที่ควรแสดงเป็นช่องว่าง ไม่ใช่เส้นที่ทำให้เข้าใจผิด
เขียนการทดสอบเฉพาะที่พิสูจน์ว่า views ประวัติ ป้าย “last seen” และทริกเกอร์การแจ้งเตือนทำงานถูกต้องภายใต้เงื่อนไขเหล่านี้
สุดท้าย ทดสอบด้วยฟลีทขนาดใหญ่และช่วงเวลายาว ยืนยันว่าแอปรับรู้ได้เร็วบนเครือข่ายช้าและโทรศัพท์รุ่นเก่า และแบ็กเอนด์สามารถให้ประวัติเชิงเวลาที่มีประสิทธิภาพโดยไม่บังคับให้แอปมือถือดาวน์โหลดเกินความจำเป็น
การส่งมอบแอปมอนิเตอร์ระยะไกลไม่ใช่เส้นชัย—มันคือจุดเริ่มต้นของการให้บริการที่ผู้คนจะพึ่งพาเมื่อมีปัญหา วางแผนการปล่อยอย่างปลอดภัย การดำเนินงานที่วัดผลได้ และการเปลี่ยนแปลงที่คาดการณ์ได้
เริ่มด้วยการปล่อยเป็นขั้นตอน: ผู้ทดสอบภายใน → ฟลีทนำร่องขนาดเล็ก → เปอร์เซ็นต์ผู้ใช้/อุปกรณ์มากขึ้น → ปล่อยเต็มรูปแบบ จับคู่นี้กับฟีเจอร์แฟล็กเพื่อให้คุณสามารถเปิดแดชบอร์ดใหม่ กฎแจ้งเตือน หรือโหมดการเชื่อมต่อตามลูกค้า รุ่นอุปกรณ์ หรือเวอร์ชันแอป
มีแผนย้อนกลับที่ครอบคลุมมากกว่าแอปสโตร์มือถือ:\n\n- การย้อนกลับแบ็กเอนด์: รักษา API ให้เข้ากันได้ย้อนหลังสำหรับอย่างน้อยหนึ่งรอบการปล่อย\n- การย้อนกลับคอนฟิก: เก็บเกณฑ์การแจ้งเตือนและนโยบายอุปกรณ์เป็นคอนฟิกที่มีเวอร์ชันและย้อนกลับได้\n- Kill switches: สามารถปิดประเภทการแจ้งเตือนที่ส่งเสียงดังหรือสตรีมสดใหม่ได้ทันที
ถ้าแอปของคุณรายงานเวลาทำงานของอุปกรณ์ แต่ท่อรับข้อมูลล่าช้า ผู้ใช้จะเห็นอุปกรณ์ “ออฟไลน์” ทั้งที่จริง ๆ แล้วปกติ ติดตามสุขภาพทั้งโซ่:\n\n- Service uptime (API, MQTT/HTTP gateway, notification workers)\n- Ingestion lag (เวลาจาก timestamp อุปกรณ์ถึงข้อมูลพร้อมใช้งานในแอป)\n- Notification success (อัตราการส่ง push, อัตราเปิด, เวลาในการยืนยัน)\n- Data gaps (เทเลเมทรีขาดหายต่อกลุ่มอุปกรณ์)
คาดการอัปเดตต่อเนื่อง: เฟิร์มแวร์อาจเปลี่ยนฟิลด์เทเลเมทรี ความสามารถคำสั่ง และจังหวะการรายงาน ปฏิบัติต่อเทเลเมทรีเป็นสัญญาที่มีเวอร์ชัน—เพิ่มฟิลด์โดยไม่ทำให้เก่าเสียหาย อธิบายการเลิกใช้ และทำให้ parser ยืดหยุ่นต่อค่าที่ไม่รู้จัก สำหรับ API คำสั่ง ให้ทำเวอร์ชัน endpoint และตรวจสอบ payload ตามรุ่นอุปกรณ์และเวอร์ชันเฟิร์มแวร์
ถ้าคุณกำลังวางงบประมาณและไทม์ไลน์ ดู /pricing. สำหรับการศึกษาเชิงลึก สำรวจหัวข้ออย่าง MQTT vs HTTP และการเก็บข้อมูลแบบ time-series ใน /blog แล้วเปลี่ยนบทเรียนเป็นโรดแมปรายไตรมาสที่ให้ความสำคัญกับการปรับปรุงที่น้อยแต่เชื่อถือได้มากขึ้น
หากต้องการเร่งการส่งมอบในช่วงต้น Koder.ai สามารถช่วยเปลี่ยนข้อกำหนด MVP ข้างต้น (บทบาท, device registry, เวิร์กโฟลว์แจ้งเตือน, แดชบอร์ด) ให้เป็นแบ็กเอนด์เว็บและ UI ที่ใช้งานได้จริงและแม้แต่ประสบการณ์มือถือข้ามแพลตฟอร์ม โดยสามารถส่งออกซอร์สโค้ดและปรับซ้ำตามสเปกในโหมดวางแผน—เพื่อให้ทีมของคุณใช้เวลาในการยืนยันเวิร์กโฟลว์อุปกรณ์มากกว่าการวางโครงสร้างพื้นฐาน
เริ่มจากการกำหนดว่า “การมอนิเตอร์ที่ดีขึ้น” หมายถึงอะไรสำหรับทีมของคุณ:
ใช้เกณฑ์เหล่านี้เป็นข้อยอมรับสำหรับ MVP เพื่อให้ฟีเจอร์ต่างๆ ผูกกับผลลัพธ์เชิงปฏิบัติการ ไม่ใช่แค่แดชบอร์ดที่สวยงาม
บทบาททั่วไปจะเชื่อมโยงกับเวิร์กโฟลว์ที่ต่างกัน:
ออกแบบหน้าจอและสิทธิ์ตามบทบาทเพื่อไม่บังคับให้ทุกคนใช้เวิร์กโฟลว์เดียวกัน
รวมการไหลหลักสำหรับการเห็นปัญหา เข้าใจ และดำเนินการ:
สร้างแผนข้อมูลต่อรุ่นอุปกรณ์:
วิธีนี้จะป้องกันการเก็บข้อมูลมากเกินไป (ค่าใช้จ่าย) หรือเก็บน้อยเกินไป (มองไม่เห็นตอนเกิดเหตุ)
ใช้แนวทางเป็นชั้น:
วิธีนี้ช่วยให้แอปตอบสนองได้ดีในขณะที่ยังรองรับการวิเคราะห์หลังเกิดเหตุ
เลือกตามข้อจำกัดของอุปกรณ์และเครือข่าย:
เลือกตัวเลือกที่ง่ายที่สุดที่ยังทำงานได้ภายใต้สภาพการเชื่อมต่อที่แย่ที่สุดของคุณ
การแยกใช้งานที่เป็นประโยชน์คือ:
หลีกเลี่ยงการสตรีมตลอดเวลา หากผู้ใช้ต้องการเพียงสถานะล่าสุด; แบบผสม (poll พื้นหลัง สตรีมหน้าแรก) มักทำงานได้ดีที่สุด
ปฏิบัติต่อคำสั่งเป็นงานที่ถูกติดตามเพื่อให้ผู้ใช้เชื่อถือผลลัพธ์:
เพิ่มการ retry/timeout และ (command ID เดียวกันไม่ควรถูกดำเนินการสองครั้ง) และแสดงสถานะเช่น vs vs ใน UI
ออกแบบเพื่อการเชื่อมต่อที่ไม่แน่นอนทั้งบนอุปกรณ์และโทรศัพท์:
เป้าหมายคือความชัดเจน: ผู้ใช้ควรรู้ทันทีว่าเมื่อใดข้อมูลล้าสุด
ใช้ RBAC และแยก “ดู” ออกจาก “ควบคุม” capabilities:
ปกป้องทั้งห่วงโซ่ด้วย TLS เก็บโทเค็นใน OS keychain/keystore และเก็บ audit trail สำหรับการลงชื่อเข้าใช้ การเปลี่ยนบทบาท และความพยายามส่งคำสั่ง จัดการ endpoint ควบคุมอุปกรณ์เป็นความเสี่ยงสูงกว่าการอ่านสถานะ
เลื่อนมุมมองแผนที่ วิเคราะห์ขั้นสูง และแดชบอร์ดที่กำหนดเองออกไปจนกว่าจะพิสูจน์ได้ว่าการตอบสนองเวลาดีขึ้น