08 พ.ค. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับการให้คะแนนและรีวิวผู้ขาย
เรียนรู้การวางแผน ออกแบบ และสร้างเว็บแอปสำหรับบัตรคะแนนและรีวิวผู้ขาย พร้อมโมเดลข้อมูล เวิร์กโฟลว์ สิทธิการเข้าถึง และคำแนะนำการรายงาน
เรียนรู้การวางแผน ออกแบบ และสร้างเว็บแอปสำหรับบัตรคะแนนและรีวิวผู้ขาย พร้อมโมเดลข้อมูล เวิร์กโฟลว์ สิทธิการเข้าถึง และคำแนะนำการรายงาน
ก่อนจะร่างหน้าจอหรือเลือกฐานข้อมูล ให้เคลียร์ให้ชัดก่อนว่าแอปนี้ มีไว้เพื่ออะไร ใครจะพึ่งพา และคำว่า “ดี” หมายถึงอะไร แอปการให้คะแนนผู้ขายล้มเหลวบ่อยเมื่อต้องพยายามตอบโจทย์ทุกคนพร้อมกัน—หรือเมื่อตอบคำถามพื้นฐานไม่ได้ เช่น “เรากำลังรีวิวผู้ขายรายไหนกันแน่?”
เริ่มจากการตั้งชื่อกลุ่มผู้ใช้หลักและการตัดสินใจประจำวันของพวกเขา:
เทคนิคที่ใช้ได้: เลือกผู้ใช้ "แกนกลาง" หนึ่งคน (มักเป็นฝ่ายจัดซื้อ) และออกแบบรีลีสแรกรอบเวิร์กโฟลว์ของพวกเขา แล้วค่อยเพิ่มกลุ่มถัดไปเมื่ออธิบายได้ชัดเจนว่าความสามารถใหม่จะเปิดการตัดสินใจอะไรได้บ้าง
เขียนผลลัพธ์เป็นการเปลี่ยนแปลงที่วัดได้ ไม่ใช่ฟีเจอร์ ตัวอย่างผลลัพธ์ทั่วไปได้แก่:
ผลลัพธ์เหล่านี้จะเป็นตัวกำหนดการติดตาม KPI และการเลือกการรายงานต่อไป
“ผู้ขาย” อาจหมายถึงสิ่งต่าง ๆ ขึ้นกับโครงสร้างองค์กรและสัญญา ตัดสินใจตั้งแต่ต้นว่าผู้ขายคือ:
การเลือกนี้ส่งผลต่อทุกอย่าง: การรวบรวมคะแนน สิทธิการเข้าถึง และว่าหนึ่งโรงงานที่แย่จะส่งผลต่อความสัมพันธ์โดยรวมหรือไม่
มีรูปแบบสามแบบที่ใช้บ่อย:
ทำให้วิธีการให้คะแนนเข้าใจได้เพียงพอที่ผู้ขาย (และผู้ตรวจสอบภายใน) จะตามได้
สุดท้าย เลือกเมตริกระดับแอปไม่กี่ตัวเพื่อยืนยันการนำไปใช้และมูลค่า:
เมื่อกำหนดเป้าหมาย ผู้ใช้ และขอบเขตแล้ว คุณจะมีฐานที่มั่นคงสำหรับการออกแบบโมเดลการให้คะแนนและเวิร์กโฟลว์ต่อไป
แอปการให้คะแนนผู้ขายอยู่หรือดับตามที่คะแนนสะท้อนประสบการณ์จริงของคน ก่อนจะสร้างหน้าจอ ให้เขียน KPI ช่วงคะแนน และกฎชัดเจนเพื่อให้ฝ่ายจัดซื้อ ปฏิบัติการ และการเงินตีความผลลัพธ์เหมือนกัน
เริ่มจากชุดแกนกลางที่ทีมส่วนใหญ่ยอมรับ:
เก็บคำนิยามให้วัดได้และผูกแต่ละ KPI กับแหล่งข้อมูลหรือคำถามในการรีวิว
เลือกเป็น 1–5 (ง่ายสำหรับคน) หรือ 0–100 (ละเอียดกว่า) แล้วกำหนดความหมายของแต่ละระดับ เช่น “การส่งตรงเวลา: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%” ขอบเขตที่ชัดเจนลดข้อโต้แย้งและทำให้การรีวิวเทียบเคียงได้
กำหนดค่าน้ำหนักของหมวด (เช่น Delivery 30%, Quality 30%, SLA 20%, Cost 10%, Responsiveness 10%) และบันทึกเมื่อค่าน้ำหนักเปลี่ยนไป (สัญญาชนิดต่างกันอาจให้ความสำคัญต่างกัน)
ตัดสินใจว่าจะจัดการข้อมูลที่ขาดอย่างไร:
ไม่ว่าจะเลือกวิธีใด ให้ใช้สม่ำเสมอและแสดงให้เห็นในมุมมอง drill-down เพื่อทีมจะได้ไม่อ่าน "ขาด" เป็น "ดี"
รองรับมากกว่าหนึ่งบัตรคะแนนต่อผู้ขายเพื่อให้ทีมสามารถเปรียบเทียบผลการปฏิบัติงาน ตามสัญญา ภูมิภาค หรือช่วงเวลา ได้ วิธีนี้ป้องกันการเฉลี่ยที่กลบปัญหาเฉพาะไซต์หรือโปรเจกต์
บันทึกว่าข้อพิพาทมีผลกับคะแนนอย่างไร: เมตริกสามารถแก้ไขย้อนหลังได้หรือไม่ ข้อพิพาททำให้คะแนนถูกทำเครื่องหมายชั่วคราวหรือไม่ และเวอร์ชันไหนถือเป็น “ทางการ” กฎง่าย ๆ เช่น “คะแนนคำนวณใหม่เมื่อการแก้ไขได้รับการอนุมัติ โดยมีบันทึกอธิบายการเปลี่ยนแปลง” ป้องกันความสับสนภายหลัง
โมเดลข้อมูลที่ชัดเจนทำให้การให้คะแนนเป็นธรรม รีวิวตามรอยได้ และรายงานน่าเชื่อถือ คุณต้องตอบคำถามง่าย ๆ ได้อย่างชัดเจน—“ทำไมผู้ขายนี้ได้ 72 ในเดือนนี้?” และ “อะไรเปลี่ยนไปตั้งแต่ไตรมาสที่แล้ว?”—โดยไม่ต้องอธิบายลอย ๆ หรือสเปรดชีตด้วยมือ
อย่างน้อย กำหนดเอนทิตีเหล่านี้:
ชุดนี้รองรับทั้งผลการปฏิบัติงานเชิงวัดได้และข้อเสนอเชิงความรู้สึก ซึ่งมักต้องการเวิร์กโฟลว์ต่างกัน
จำลองความสัมพันธ์อย่างชัดเจน:
แนวทางที่ใช้บ่อยคือ:
scorecard_period (เช่น 2025-10)vendor_period_score (คะแนนรวม)vendor_period_metric_score (ต่อเมตริก มีตัวเศษ/ตัวส่วนถ้ามี)เพิ่มฟิลด์ความสอดคล้องในหลายตาราง:
created_at, updated_at และสำหรับการอนุมัติ submitted_at, approved_atcreated_by_user_id และ approved_by_user_id เมื่อจำเป็นsource_system และไอดีภายนอกเช่น erp_vendor_id, crm_account_id, erp_invoice_idconfidence หรือ data_quality_flag เพื่อทำป้ายข้อมูลไม่สมบูรณ์หรือตัวเลขประมาณฟิลด์เหล่านี้ขับเคลื่อนบันทึกตรวจสอบ การจัดการข้อพิพาท และการวิเคราะห์ที่เชื่อถือได้
คะแนนเปลี่ยนเพราะข้อมูลมาช้า สูตรเปลี่ยน หรือใครบางคนแก้แมป แทนที่จะเขียนทับประวัติ ให้เก็บเวอร์ชัน:
calculation_run_id) บนแต่ละแถวของคะแนนสำหรับการเก็บรักษา ให้กำหนดว่าคุณเก็บธุรกรรมดิบยาวนานแค่ไหนเทียบกับคะแนนที่อนุมานบ่อย ๆ มักเก็บคะแนนที่อนุมานนานกว่า (พื้นที่จัดเก็บน้อย คุณค่าการรายงานสูง) และเก็บ ERP extracts ดิบในหน้าต่างนโยบายที่สั้นกว่า
Treat external IDs as first-class fields, not notes:
unique(source_system, external_id))พื้นฐานนี้ทำให้ส่วนถัดไป—การรวมระบบ การติดตาม KPI การควบคุมรีวิว และการตรวจสอบ—ง่ายขึ้นมากเมื่อจะอธิบายและนำไปใช้
แอปการให้คะแนนผู้ขายดีได้เพราะข้อมูลที่ป้อนเข้า วางแผนเส้นทางการนำเข้าหลายแบบตั้งแต่วันแรก ถึงแม้เริ่มด้วยทางเดียว หลายทีมต้องการผสมผสานการป้อนด้วยมือ การอัปโหลดแบบกลุ่ม และการซิงก์ผ่าน API
การป้อนด้วยมือ มีประโยชน์สำหรับซัพพลายเออร์ขนาดเล็ก เหตุการณ์ครั้งเดียว หรือเมื่อทีมต้องบันทึกรีวิวทันที
การอัปโหลด CSV ช่วยบูทสแตรประบบด้วยข้อมูลย้อนหลัง ใบแจ้งหนี้ ตั๋ว หรือบันทึกการส่ง ให้เทมเพลตพร้อมเวอร์ชันเพื่อการนำเข้าที่คาดเดาได้
การซิงก์ API มักเชื่อมกับ ERP/เครื่องมือจัดซื้อ (PO, ใบรับสินค้า, ใบแจ้งหนี้) และระบบบริการอย่าง helpdesk (ตั๋ว การละเมิด SLA) ใช้ incremental sync (ตั้ง cursor ล่าสุด) เพื่อหลีกเลี่ยงการดึงทุกอย่างทุกครั้ง
ตั้งกฎการตรวจสอบชัดเจนเมื่อนำเข้า:
เก็บแถวที่ไม่ถูกต้องพร้อมข้อความผิดพลาดเพื่อให้แอดมินแก้และอัปโหลดใหม่โดยไม่เสียบริบท
การนำเข้าผิดเป็นเรื่องปกติ รองรับ re-runs (idempotent โดยใช้ source IDs), backfills (ช่วงเวลาทางประวัติศาสตร์), และ บันทึกการคำนวณซ้ำ ที่ระบุว่าอะไรเปลี่ยน เมื่อไร และทำไม ซึ่งสำคัญต่อความเชื่อถือเมื่อคะแนนผู้ขายเปลี่ยน
ทีมส่วนใหญ่ใช้การนำเข้ารายวัน/รายสัปดาห์สำหรับเมตริกการเงินและการส่งสินค้า และเหตุการณ์เกือบเรียลไทม์สำหรับเหตุการณ์สำคัญ
แสดงหน้าผู้ดูแลระบบสำหรับการนำเข้า (เช่น /admin/imports) แสดงสถานะ จำนวนแถว คำเตือน และข้อผิดพลาดที่ชัดเจน—เพื่อให้ปัญหาเห็นได้และแก้ไขได้โดยไม่ต้องพึ่งนักพัฒนามาก
บทบาทที่ชัดเจนและเส้นทางอนุมัติที่คาดเดาได้ช่วยป้องกัน "ความอลหม่านของบัตรคะแนน": แก้ไขขัดแย้ง การเปลี่ยนแปลงคะแนนที่ไม่คาดคิด และความไม่แน่ใจเกี่ยวกับผู้ที่จะเห็น ผู้กำหนดสิทธิ์ตั้งแต่ต้น แล้วบังคับใช้ใน UI และ API อย่างสม่ำเสมอ
เซ็ตบทบาทเริ่มต้นที่ใช้งานได้จริง:
หลีกเลี่ยงสิทธิแบบกว้าง ๆ เช่น “จัดการผู้ขายได้” ให้ควบคุมความสามารถเฉพาะ:
พิจารณาแยก “ส่งออก” เป็น “ส่งออกผู้ขายของตนเอง” กับ “ส่งออกทั้งหมด” โดยเฉพาะสำหรับการวิเคราะห์จัดซื้อ
ผู้ใช้ผู้ขายควรมองเห็น เฉพาะข้อมูลของตนเอง: คะแนนของตน รีวิวที่เผยแพร่ และสถานะของรายการเปิด จำกัดรายละเอียดผู้รีวิวตามค่าเริ่มต้น (เช่น แสดงแผนกหรือบทบาทแทนชื่อเต็ม) เพื่อลดความขัดแย้งระหว่างบุคคล หากอนุญาตให้ผู้ขายตอบ ให้เก็บเป็นเธรดและติดป้ายชัดเจนว่าเป็นข้อมูลจากผู้ขาย
จัดการรีวิวและการเปลี่ยนแปลงคะแนนเป็น ข้อเสนอ จนกว่าจะอนุมัติ:
เวิร์กโฟลว์ที่มีกรอบเวลาเป็นประโยชน์: ตัวอย่าง คะแนนอาจต้องได้รับการอนุมัติเฉพาะในช่วงปิดเดือน/ไตรมาส
เพื่อความสอดคล้องและความรับผิดชอบ ให้บันทึกเหตุการณ์สำคัญทุกอย่าง: ใครทำอะไร เมื่อไร จากที่ไหน และค่าเดิม/ค่าใหม่ บันทึกตรวจสอบควรครอบคลุมการเปลี่ยนแปลงสิทธิ รีวิว การแก้ไข การอนุมัติ การเผยแพร่ การส่งออก และการลบ ทำให้ค้นหาและส่งออกได้สำหรับการตรวจสอบ และป้องกันการปลอมแปลง (เก็บแบบ append-only หรือ immutable logs)
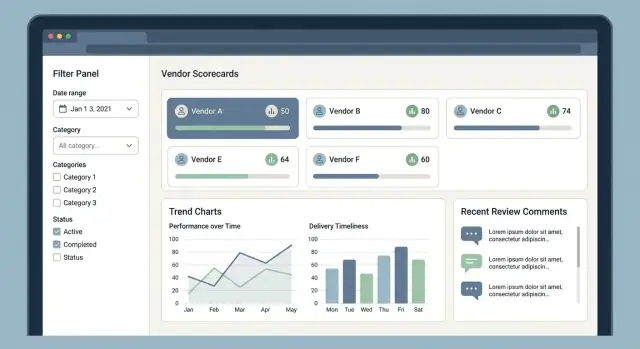
แอปการให้คะแนนผู้ขายสำเร็จหรือล้มเหลวจากว่าผู้ใช้ที่งานยุ่งจะค้นหาผู้ขายที่ถูกต้องได้เร็วแค่ไหน เข้าใจคะแนนทันที และส่งฟีดแบ็กที่เชื่อถือได้โดยไม่มีแรงต้าน เริ่มด้วยชุดหน้าพื้นฐาน “home base” เล็ก ๆ และทำให้ทุกตัวเลขอธิบายได้
นี่คือที่ที่เริ่มเซสชันส่วนใหญ่ เก็บเลย์เอาต์เรียบง่าย: ชื่อผู้ขาย หมวด ภูมิภาค ช่วงคะแนนสถานะ และกิจกรรมล่าสุด
การกรองและค้นหาควรรู้สึกทันทีและคาดเดาได้:
บันทึกมุมมองยอดนิยม (เช่น “ผู้ขายสำคัญใน EMEA ต่ำกว่า 70”) เพื่อให้ทีมจัดซื้อไม่ต้องสร้างตัวกรองใหม่ทุกวัน
โปรไฟล์ผู้ขายควอสรุป “พวกเขาเป็นใคร” และ “ผลการทำงานเป็นอย่างไร” โดยไม่บังคับให้ผู้ใช้เข้าสู่แท็บมากเกินไป วางรายละเอียดการติดต่อและเมตาดาต้าสัญญาไว้ข้างสรุปคะแนนที่ชัดเจน
แสดงคะแนนรวมและการแจกแจง KPI (คุณภาพ การส่ง ต้นทุน การปฏิบัติตาม) แต่ละ KPI ต้องมีแหล่งที่มาชัดเจน: รีวิว เหตุการณ์ หรือเมตริกที่ทำให้เกิดมัน
รูปแบบที่ดีคือ:
ทำให้การป้อนรีวิวเหมาะกับมือถือ: ปุ่มใหญ่ ฟิลด์สั้น และการคอมเมนต์รวดเร็ว แนบรีวิวกับช่วงเวลาและ (ถ้าจำเป็น) PO, ไซต์ หรือโปรเจกต์ เพื่อให้ฟีดแบ็กสามารถลงมือทำได้
รายงานควรตอบคำถามทั่วไป: “ซัพพลายเออร์ตัวไหนกำลังตก?” และ “อะไรเปลี่ยนแปลงเดือนนี้?” ใช้แผนภูมิอ่านง่าย ป้ายกำกับชัดเจน และนำทางด้วยคีย์บอร์ดเพื่อการเข้าถึง
รีวิวคือจุดที่แอปการให้คะแนนผู้ขายมีประโยชน์จริง: พวกมันจับบริบท หลักฐาน และ “เหตุผล” เบื้องหลังตัวเลข เพื่อให้คงความสม่ำเสมอและป้องกันข้อพิพาท ให้ปฏิบัติต่อรีวิวเป็นระเบียนเชิงโครงสร้างก่อน ข้อความอิสระเป็นรอง
ช่วงเวลาต่าง ๆ เรียกรูปแบบรีวิวต่างกัน ชุดเริ่มต้นที่เรียบง่าย:
แต่ละประเภทสามารถแชร์ฟิลด์ทั่วไปได้แต่มีคำถามเฉพาะประเภทเพื่อไม่ให้ยัดเหตุการณ์ลงในฟอร์มรายไตรมาส
ควบคู่กับคอมเมนต์ บันทึกอินพุตเชิงโครงสร้างที่ช่วยการกรองและรายงาน:
โครงสร้างนี้เปลี่ยน "ฟีดแบ็ก" ให้เป็นงานที่ติดตามได้ ไม่ใช่แค่ข้อความในกล่อง
อนุญาตให้ผู้รีวิวแนบหลักฐานที่เดียวกับที่เขียนรีวิว:
เก็บเมตาดาต้า (ใครอัปโหลด เมื่อไร เกี่ยวกับอะไร) เพื่อให้การตรวจสอบไม่เป็นการตามล่าหา
แม้เป็นเครื่องมือภายในก็ต้องมีการดูแล:
หลีกเลี่ยงการแก้ไขเงียบ—ความโปร่งใสปกป้องทั้งผู้รีวิวและผู้ขาย
กำหนดกฎการแจ้งเตือนตั้งแต่ต้น:
เมื่อทำได้ดี รีวิวจะกลายเป็นเวิร์กโฟลว์คำติชมแบบปิดวง แทนที่จะเป็นข้อร้องเรียนครั้งเดียว
การตัดสินใจเชิงสถาปัตยกรรมครั้งแรกไม่ใช่เรื่องของ "เทคโนโลยีล่าสุด" มากเท่ากับว่าคุณจะส่งมอบแพลตฟอร์มการให้คะแนนและรีวิวที่เชื่อถือได้เร็วแค่ไหนโดยไม่สร้างภาระบำรุงรักษามากเกินไป
ถ้าจุดประสงค์คือเคลื่อนไปเร็ว ให้พิจารณาโปโตไทป์เวิร์กโฟลว์ (ผู้ขาย → scorecards → รีวิว → อนุมัติ → รายงาน) ในแพลตฟอร์มที่สร้างแอปจากสเปคอย่างรวดเร็ว ตัวอย่างเช่น Koder.ai เป็นแพลตฟอร์มแบบ vibe-coding ที่คุณสามารถสร้างเว็บ แบ็กเอนด์ และแอปมือถือผ่านอินเตอร์เฟซแชท แล้วส่งออกซอร์สโค้ดเมื่อพร้อมขยาย เป็นวิธีที่ใช้งานได้จริงเพื่อยืนยันโมเดลการให้คะแนนและบทบาท/สิทธิ์ก่อนลงทุนหนักใน UI และการรวมระบบ
สำหรับทีมส่วนใหญ่ modular monolith เป็นจุดที่เหมาะสม: แอปหนึ่งโปรแกรมที่จัดระเบียบเป็นโมดูลชัดเจน (Vendors, Scorecards, Reviews, Reporting, Admin) คุณจะได้พัฒนาง่าย ดีบักง่าย และการรักษาความปลอดภัยและการปรับใช้ที่ตรงไปตรงมา
ย้ายไปสู่ บริการแยก เมื่อมีเหตุผลชัดเจน—เช่น ภาระงานรายงานหนัก ทีมผลิตภัณฑ์หลายทีม หรือข้อกำหนดการแยกอย่างเคร่งครัด พาธวิวัฒนาการที่พบบ่อยคือ: monolith ตอนนี้ แล้วแยก "imports/reporting" เมื่อจำเป็น
REST API มักง่ายต่อการเข้าใจและรวมกับเครื่องมือจัดซื้อ ตั้งทรัพยากรที่คาดเดาได้และมี endpoint บางอย่างเป็น "task" ที่ระบบทำงานหนักให้
ตัวอย่าง:
/api/vendors (สร้าง/อัปเดต vendor, สถานะ)/api/vendors/{id}/scores (คะแนนปัจจุบัน การแจกแจงย้อนหลัง)/api/vendors/{id}/reviews (แสดง/สร้างรีวิว)/api/reviews/{id} (อัปเดต การดำเนินการการดูแล)/api/exports (ขอการส่งออก; คืน job id)เก็บงานหนัก (exports, bulk recalcs) เป็นแบบอะซิงโครนัสเพื่อ UI ตอบสนองได้
ใช้คิวงานสำหรับ:
ช่วยให้ retry ในความล้มเหลวได้โดยไม่ต้องป้องกันด้วยมือ
แดชบอร์ดอาจหนัก ควรแคชเมตริกที่รวมแล้ว (ตามช่วงเวลา หมวด หน่วยธุรกิจ) และ invalidate เมื่อมีการเปลี่ยนแปลงสำคัญหรือรีเฟรชตามตารางเวลา เพื่อให้หน้าจอเปิดเร็วแต่ยังคงข้อมูล drill-down ถูกต้อง
เขียนเอกสาร API (OpenAPI/Swagger ใช้ได้) และเก็บคู่มือภายในแบบเป็นมิตรกับแอดมินในรูปแบบ /blog-style เช่น “How scoring works,” “How to handle disputed reviews,” “How to run exports” และลิงก์จากแอปไปยัง /blog เพื่อให้หาและอัปเดตง่าย
ข้อมูลการให้คะแนนผู้ขายมีผลต่อสัญญาและชื่อเสียง จึงต้องมีการควบคุมความปลอดภัยที่คาดหวังได้ ตรวจสอบได้ และใช้งานง่ายสำหรับผู้ใช้ที่ไม่ใช่สายเทคนิค
เริ่มจากตัวเลือกการลงชื่อที่เหมาะสม:
จับคู่การพิสูจน์ตัวตนกับ RBAC: แอดมินจัดซื้อ ผู้รีวิว ผู้อนุมัติ และผู้ดู-only รักษาสิทธิ์ให้แยกละเอียด (เช่น “ดูคะแนน” vs “ดูข้อความรีวิว”) และรักษาบันทึกตรวจสอบสำหรับการเปลี่ยนแปลงคะแนน การอนุมัติ และการแก้ไข
เข้ารหัสข้อมูล ขณะส่ง (TLS) และ ขณะพัก (ฐานข้อมูล + แบ็กอัพ) จัดการความลับ (รหัสผ่าน DB, คีย์ API, ใบรับรอง SSO) อย่างจริงจัง:
แม้แอปจะเป็น "ภายใน" แต่จุดสิ้นสุดสาธารณะ (รีเซ็ตรหัสผ่าน ลิงก์เชิญ ฟอร์มส่งรีวิว) อาจถูกละเมิด เพิ่ม rate limiting และป้องกันบอท (CAPTCHA หรือ risk scoring) เมื่อจำเป็น และล็อกดาวน์ API ด้วยโทเค็นที่มีสโคป
รีวิวมักมีชื่อ อีเมล หรือรายละเอียดเหตุการณ์ ลดข้อมูลส่วนบุคคลตามค่าเริ่มต้น (ฟิลด์เชิงโครงสร้างแทนข้อความอิสระ) กำหนด นโยบายการเก็บ และมีเครื่องมือให้ลบหรือเซ็นเซอร์เมื่อจำเป็น
บันทึกพอสำหรับการแก้ปัญหา (request IDs, latency, error codes) แต่หลีกเลี่ยงการจับข้อความรีวิวหรือไฟล์แนบที่เป็นความลับ ใช้การมอนิเตอร์และการแจ้งเตือนสำหรับการนำเข้าล้มเหลว ข้อผิดพลาดงานคำนวณ และรูปแบบการเข้าถึงที่ผิดปกติ—โดยไม่เปลี่ยนล็อกเป็นฐานข้อมูลสำรองของเนื้อหาอ่อนไหว
แอปการให้คะแนนผู้ขายมีประโยชน์เท่าที่ช่วยให้เกิดการตัดสินใจได้ รายงานควรตอบสามคำถามอย่างรวดเร็ว: ใครทำได้ดี เทียบกับอะไร และเพราะอะไร?
เริ่มด้วยแดชบอร์ดผู้บริหารที่สรุป คะแนนรวม การเปลี่ยนแปลงคะแนนตามเวลา และ การแจกแจงตามหมวด (คุณภาพ การส่ง การปฏิบัติตาม ต้นทุน บริการ ฯลฯ) เส้นแนวโน้มสำคัญ: ผู้ขายคะแนนสูงแต่กำลังตกอาจแย่กว่าผู้ขายที่คะแนนปานกลางแต่กำลังดีขึ้น
ให้แดชบอร์ดกรองตามช่วงเวลา หน่วยธุรกิจ/ไซต์ หมวดผู้ขาย และสัญญา ใช้ค่าเริ่มต้นที่สม่ำเสมอ (เช่น “90 วันที่ผ่านมา”) เพื่อให้คนสองคนดูจอเดียวกันแล้วได้คำตอบใกล้เคียงกัน
การเปรียบเทียบมีพลังและมีความอ่อนไหว ให้ผู้ใช้เปรียบเทียบผู้ขายภายในหมวดเดียวกัน (เช่น “ผู้จัดหาบรรจุภัณฑ์”) พร้อมบังคับสิทธิ์:
วิธีนี้หลีกเลี่ยงการเปิดเผยโดยไม่ตั้งใจ แต่ยังสนับสนุนการตัดสินใจ
แดชบอร์ดควรลิงก์ไปยังรายงานเจาะลึกที่อธิบายการเคลื่อนของคะแนน:
รายงานที่ดีจบด้วย "อะไรเกิดขึ้น" ที่มีหลักฐาน: รีวิวที่เกี่ยวข้อง เหตุการณ์ ตั๋ว หรือบันทึกการขนส่ง
รองรับ CSV สำหรับการวิเคราะห์ และ PDF สำหรับการแชร์ การส่งออกควรสะท้อนตัวกรองบนหน้าจอ มี timestamp และตัวเลือกใส่ ลายน้ำเพื่อใช้งานภายใน (และชื่อผู้ดู) เพื่อลดการส่งต่อภายนอกองค์กร
หลีกเลี่ยงคะแนนแบบ "กล่องดำ" แต่ละคะแนนควรมีการแจกแจงชัดเจน:
เมื่อผู้ใช้เห็นรายละเอียดการคำนวณ ข้อพิพาทจะแก้ไขเร็วขึ้น และแผนปรับปรุงตกลงกันได้ง่ายขึ้น
การทดสอบแอปการให้คะแนนไม่ใช่แค่จับบั๊ก แต่เป็นการปกป้องความเชื่อถือ ทีมจัดซื้อจำเป็นต้องมั่นใจว่าคะแนนถูกต้อง และผู้ขายต้องเชื่อว่าการรีวิวและการอนุมัติทำอย่างสม่ำเสมอ
เริ่มจากชุดข้อมูลทดสอบขนาดเล็กที่ใช้ซ้ำได้ ซึ่งตั้งใจใส่กรณีขอบ: KPI หาย การส่งล่าที่รายงานช้า ค่าขัดแย้งข้ามการนำเข้า และการโต้แย้ง (เช่น ผู้ขายท้าทายผล SLA) รวมกรณีที่ผู้ขายไม่มีกิจกรรมในช่วง หรือ KPI ที่ควรถูกยกเว้นเพราะวันที่ไม่ถูกต้อง
การคำนวณคะแนนเป็นหัวใจของผลิตภัณฑ์ จงทดสอบเหมือนสูตรการเงิน:
unit tests ควรยืนยันไม่เพียงคะแนนสุดท้าย แต่ชิ้นส่วนระหว่างทาง (คะแนนต่อ KPI การทำให้เป็นมาตรฐาน การหัก/โบนัส) เพื่อให้ง่ายต่อการดีบัก
integration tests ควรจำลองฟลูว์แบบ end-to-end: นำเข้าบัตรคะแนนผู้ขาย, ใช้สิทธิ, และยืนยันว่าบทบาทที่ถูกต้องเท่านั้นที่ดู คอมเมนต์ อนุมัติ หรือยกระดับข้อพิพาท รวมถึงทดสอบบันทึกตรวจสอบและการบล็อกการกระทำ (เช่น ผู้ขายพยายามแก้รีวิวที่อนุมัติ)
รันการทดสอบยอมรับผู้ใช้กับฝ่ายจัดซื้อและกลุ่มผู้ขายนำร่อง ติดตามจุดที่สับสนและปรับข้อความ UI การตรวจสอบ และคำแนะนำ
สุดท้าย รันการทดสอบประสิทธิภาพช่วงรายงานพีค (สิ้นเดือน/สิ้นไตรมาส) มุ่งเน้นเวลาโหลดแดชบอร์ด การส่งออกแบบกลุ่ม และงานคำนวณคะแนนพร้อมกัน
แอปการให้คะแนนผู้ขายสำเร็จเมื่อผู้คนใช้งานจริง นั่นมักหมายถึงการส่งมอบเป็นเฟส ย้ายจากสเปรดชีตอย่างระมัดระวัง และตั้งความคาดหวังว่าอะไรจะเปลี่ยน (และเมื่อไหร่)
เริ่มด้วยเวอร์ชันเล็กสุดที่ยังสร้างบัตรคะแนนที่มีประโยชน์ได้
เฟส 1: บัตรคะแนนภายในเท่านั้น. ให้ฝ่ายจัดซื้อและผู้มีส่วนได้เข้าถึงที่เก็บค่านั้นสะอาดสำหรับบันทึกค่า KPI สร้างบัตรคะแนน และใส่บันทึกภายใน เก็บเวิร์กโฟลว์เรียบง่ายและเน้นความสม่ำเสมอ
เฟส 2: การเข้าถึงผู้ขาย. เมื่อตัวการให้คะแนนภายในเสถียร เริ่มเชิญผู้ขายดูบัตรคะแนนของตน ตอบฟีดแบ็ก และเพิ่มบริบท (เช่น “การล่าช้าเกิดจากท่าเรือปิด”) นี่คือจุดที่การมอบสิทธิ์และบันทึกตรวจสอบสำคัญ
เฟส 3: ออโตเมชัน. เพิ่มการรวมระบบและการคำนวณตามตารางเมื่อคุณมั่นใจในโมเดลการให้คะแนน ออโตเมชันเร็วเกินไปอาจขยายปัญหาข้อมูลหรือคำนิยามที่ไม่ชัดเจน
ถ้าต้องการลดเวลาไปสู่พายลอต Koder.ai เป็นอีกจุดที่ช่วยได้: คุณสามารถตั้งเวิร์กโฟลว์หลัก (บทบาท การอนุมัติ บัตรคะแนน การส่งออก) อย่างรวดเร็ว วนปรับกับผู้มีส่วนได้ในการ "โหมดวางแผน" แล้วส่งออกโค้ดเมื่อต้องการเสริมการรวมและการควบคุมความสอดคล้อง
ถ้าคุณจะแทนที่สเปรดชีต วางแผนช่วงเปลี่ยนผ่าน แทนการตัดขาดครั้งเดียว
จัดเตรียม เทมเพลตนำเข้า ที่สะท้อนคอลัมน์เดิม (ชื่อผู้ขาย ช่วงเวลา ค่า KPI ผู้รีวิว โน้ต) เพิ่ม ตัวช่วยนำเข้า เช่น ข้อผิดพลาดการยืนยัน ("ไม่พบผู้ขาย") ตัวอย่าง และโหมดลองรัน
ตัดสินใจว่าจะย้ายข้อมูลย้อนหลังทั้งหมดหรือเฉพาะช่วงล่าสุด บ่อยครั้งการนำเข้า 4–8 ไตรมาสล่าสุดเพียงพอสำหรับการรายงานแนวโน้มโดยไม่เปลี่ยนงานย้ายข้อมูลให้กลายเป็นโบราณคดีข้อมูล
ทำสั้นและเจาะตามบทบาท:
ปฏิบัติการกำหนดค่านิยามเป็นผลิตภัณฑ์ KPI เปลี่ยน หมวดขยาย และน้ำหนักวิวัฒน์
ตั้ง นโยบายการคำนวณซ้ำ ล่วงหน้า: ถ้าคำนิยาม KPI เปลี่ยนแล้วจะเกิดอะไรขึ้น? คำนวณผลย้อนหลังใหม่หรือเก็บผลเดิมเพื่อการตรวจสอบ? หลายทีมเก็บผลย้อนหลังและคำนวณใหม่เฉพาะจากวันที่มีผลบังคับ
เมื่อเลยพายลอตแล้ว ให้ตัดสินใจว่าฟีเจอร์ใดรวมในแต่ละชั้น (จำนวนผู้ขาย รอบรีวิว การรวมระบบ รายงานขั้นสูง การเข้าถึงพอร์ทัลผู้ขาย) ถ้ากำลังทำแผนเชิงพาณิชย์ ให้ร่างแพ็กเกจและอ้างถึง /pricing สำหรับรายละเอียด
ถ้ากำลังประเมินระหว่างสร้างเอง ซื้อ หรือเร่งความเร็ว ให้ใช้คำถาม "เราส่ง MVP ที่น่าเชื่อถือได้เร็วแค่ไหน?" เป็นข้อมูลสำหรับการจัดแพ็กเกจ แพลตฟอร์มอย่าง Koder.ai (มีระดับตั้งแต่ฟรีจนถึงองค์กร) อาจเป็นสะพานที่ใช้งานได้จริง: สร้างและวนปรับเร็ว ปรับใช้และโฮสต์ แล้วยังมีตัวเลือกส่งออกและเป็นเจ้าของซอร์สโค้ดเมื่อโปรแกรมการให้คะแนนโตเต็มที่
เริ่มโดยตั้งผู้ใช้หลักหนึ่งคนเป็นเป้าหมายแล้วปรับเวอร์ชันแรกให้สอดคล้องกับเวิร์กโฟลว์ของพวกเขา (มักจะเป็นทีมจัดซื้อ) บันทึกไว้ว่า:
เพิ่มฟีเจอร์สำหรับการเงิน/ปฏิบัติการก็ต่อเมื่อคุณอธิบายได้ชัดเจนว่าฟีเจอร์ใหม่ช่วยให้เกิดการตัดสินใจใหม่อะไรได้บ้าง
เลือกนิยามหนึ่งข้อไว้ตั้งแต่ต้นแล้วออกแบบโมเดลข้อมูลรอบ ๆ นิยามนั้น:
ถ้าไม่แน่ใจ ให้โมเดลผู้ขายเป็นพ่อข่าย (parent) และมี "หน่วยผู้ขาย" เป็นลูก (ไซต์/สายบริการ) เพื่อให้สามารถสรุปรวมหรือเจาะรายละเอียดภายหลังได้
ใช้ Weighted KPIs เมื่อมีข้อมูลปฏิบัติการที่เชื่อถือได้และต้องการความโปร่งใส/ออโตเมชัน ใช้ Rubrics เมื่อการประเมินเป็นเชิงคุณภาพและต่างกันระหว่างทีม
ค่าดีฟอลต์ปฏิบัติได้คือ Hybrid:
ไม่ว่าจะเลือกแบบไหน ให้ทำให้วิธีการอธิบายได้ชัดเจนพอให้ผู้ตรวจสอบภายในและผู้ขายเข้าใจ
เริ่มจากชุดเล็กที่ฝ่ายต่างๆ ยอมรับและวัดได้สม่ำเสมอ:
สำหรับแต่ละ KPI ให้ระบุคำนิยาม ระดับ และแหล่งข้อมูลก่อนสร้าง UI หรือรายงาน
เลือกสเกลที่คนอธิบายเป็นคำได้ง่าย (มักเป็น 1–5 หรือ 0–100) แล้วกำหนดขอบเขตเป็นภาษาธรรมดา
ตัวอย่าง:
หลีกเลี่ยงตัวเลขที่มาจากความรู้สึก ขอบเขตที่ชัดเจนช่วยลดความขัดแย้งและทำให้การเปรียบเทียบข้ามทีมเป็นธรรม
กำหนดนโยบายต่อ KPI แล้วบันทึกไว้และใช้แบบสม่ำเสมอ:
เก็บตัวบ่งชี้คุณภาพข้อมูล (เช่น data_quality_flag) เพื่อให้รายงานแยกแยะได้ว่าคะแนนต่ำเพราะผลงานแย่หรือเพราะข้อมูลไม่เพียงพอ
ปฏิบัติต่อข้อพิพาทเป็นเวิร์กโฟลว์ที่ติดตามได้:
เก็บตัวระบุเวอร์ชันการคำนวณ (เช่น calculation_run_id) เพื่อให้ตอบได้ว่า "อะไรเปลี่ยนไปตั้งแต่ไตรมาสที่แล้ว" อย่างเชื่อถือได้
สคีมาเริ่มต้นที่ดีมักประกอบด้วย:
เพิ่มฟิลด์สำหรับการติดตาม: timestamps, actor IDs, source system + external IDs และการอ้างอิงเวอร์ชันของคะแนนเพื่อให้ตัวเลขทุกตัวอธิบายและทำซ้ำได้
วางแผนเส้นทางการนำเข้าหลายแบบไว้แม้เริ่มจากวิธีเดียว:
ตอนนำเข้า บังคับใช้ฟิลด์ที่จำเป็น, ช่วงตัวเลขที่ยอมรับได้ และการตรวจจับแถวซ้ำ เก็บแถวที่ไม่ถูกต้องพร้อมข้อความผิดพลาดเพื่อให้แอดมินแก้ไขและอัปโหลดใหม่ได้โดยไม่สูญเสียบริบท
ใช้การจัดการสิทธิแบบ RBAC และปฏิบัติต่อการเปลี่ยนแปลงเป็นข้อเสนอ:
บันทึกทุกเหตุการณ์สำคัญ (แก้ไข, อนุมัติ, ส่งออก, การเปลี่ยนแปลงสิทธิ) พร้อมค่าก่อน/หลัง เพื่อปกป้องความน่าเชื่อถือและทำให้งานตรวจสอบง่ายขึ้น—โดยเฉพาะเมื่อต่อมามีการให้ผู้ขายเข้าดูหรือโต้ตอบ