29 พ.ย. 2568·4 นาที
วิธีสร้างเว็บแอปเพื่อจัดการวงจรข้อเสนอแนะลูกค้า
เรียนรู้วิธีออกแบบและสร้างเว็บแอปที่เก็บ ส่งต่อ ติดตาม และปิดวงจรข้อเสนอแนะลูกค้าพร้อมเวิร์กโฟลว์ บทบาท และเมตริกที่ชัดเจน
เรียนรู้วิธีออกแบบและสร้างเว็บแอปที่เก็บ ส่งต่อ ติดตาม และปิดวงจรข้อเสนอแนะลูกค้าพร้อมเวิร์กโฟลว์ บทบาท และเมตริกที่ชัดเจน
แอปจัดการข้อเสนอแนะไม่ใช่แค่ “ที่เก็บข้อความ” มันเป็นระบบที่ช่วยให้ทีมของคุณย้ายจาก ข้อมูลเข้า ไปยัง การลงมือ ไปยัง การติดตามผลที่ลูกค้าเห็นได้ แล้วเรียนรู้จากสิ่งที่เกิดขึ้นได้อย่างสม่ำเสมอ
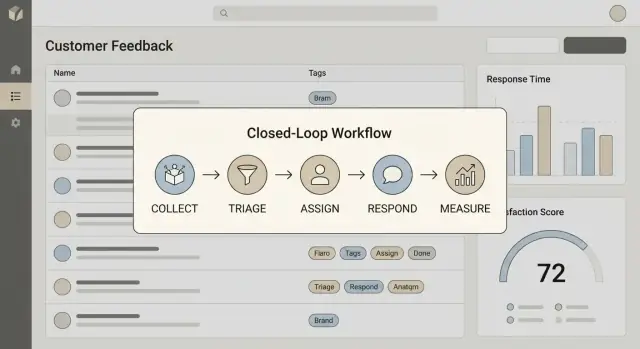
เขียนคำนิยามสั้น ๆ ให้ทีมทวนซ้ำได้ สำหรับหลายทีม การปิดวงจรประกอบด้วยสี่ขั้นตอน:
ถ้าขั้นตอนใดหายไป แอปของคุณจะกลายเป็นหลุมฝังศพ backlog ได้ง่าย
เวอร์ชันแรกควรรองรับบทบาทที่ใช้จริงในแต่ละวัน:
ระบุให้ชัดเจนในเชิง "การตัดสินใจต่อคลิก":
เลือกเมตริกเล็ก ๆ ที่สะท้อนความเร็วและคุณภาพ เช่น time to first response, resolution rate, และ การเปลี่ยนแปลง CSAT หลังการติดตาม เหล่านี้จะเป็นเข็มทิศสำหรับการออกแบบต่อไป
ก่อนออกแบบหน้าจอหรือเลือกฐานข้อมูล ให้ทำแผนที่ว่าเกิดอะไรขึ้นกับข้อเสนอแนะตั้งแต่สร้างจนถึงเมื่อคุณตอบ แผนผังการเดินทางอย่างง่ายช่วยให้ทีมเห็นตรงกันว่า “เสร็จ” คืออะไร และป้องกันการสร้างฟีเจอร์ที่ไม่เข้ากับงานจริง
รายการแหล่งข้อเสนอแนะของคุณและบันทึกว่าข้อมูลแต่ละแหล่งให้ข้อมูลอะไรบ้างอย่างสม่ำเสมอ:
แม้ว่าข้อมูลเข้าเหล่านี้จะแตกต่าง แอปของคุณควรทำให้เป็นรูปแบบ "feedback item" ที่สม่ำเสมอเพื่อให้ทีมสามารถทำ triage ทุกอย่างในที่เดียวได้
โมเดลเริ่มต้นที่ใช้งานได้มักมี:
สถานะเริ่มต้น: New → Triaged → Planned → In Progress → Shipped → Closed จดความหมายของสถานะไว้เพื่อไม่ให้ทีมต่าง ๆ ให้ความหมายต่างกัน (เช่น “Planned” = “Maybe” กับ “Committed”)
การเกิดซ้ำเป็นเรื่องหลีกเลี่ยงไม่ได้ กำหนดกฎตั้งแต่ต้น:
แนวทางที่ใช้กันทั่วไปคือเก็บ canonical feedback item หนึ่งรายการแล้วลิงก์รายการอื่นเป็นซ้ำ โดยรักษาการอ้างอิงผู้ร้องขอไว้เพื่อไม่ให้แยกงานออกเป็นชิ้น ๆ
แอปวงจรข้อเสนอแนะจะชนะหรือแพ้ตั้งแต่วันแรกตามความสามารถที่ผู้คนสามารถประมวลผลข้อเสนอแนะได้เร็ว ตั้งเป้าให้การไหลรู้สึกแบบ: “สแกน → ตัดสินใจ → ไปต่อ” ขณะเดียวกันยังเก็บบริบทไว้สำหรับการตัดสินใจภายหลัง
Inbox คือคิวที่แชร์ของทีม ควรสนับสนุนการ triage แบบเร็วผ่านชุดตัวกรองทรงพลังจำนวนน้อย:
เพิ่ม “Saved views” ตั้งแต่ต้น (แม้จะพื้นฐาน) เพราะทีมต่างกันจะสแกนต่างกัน: Support ต้องการ “urgent + paying,” Product ต้องการ “feature requests + high ARR.”
เมื่อผู้ใช้เปิดไอเท็ม พวกเขาควรเห็น:
เป้าหมายคือไม่ต้องสลับแท็บเพื่อตอบคำถามว่า: “นี่ใคร, เขาหมายถึงอะไร, แล้วเราเคยตอบไปแล้วหรือยัง?”
จากมุมมองรายละเอียด การ triage ควรเป็นการตัดสินใจต่อคลิกเดียว:
คุณอาจต้องมีสองโหมด:
ไม่ว่าจะเลือกแบบใด ให้ทำ “ตอบกลับพร้อมบริบท” เป็นขั้นตอนสุดท้าย—เพื่อให้การปิดวงจรเป็นส่วนหนึ่งของเวิร์กโฟลว์ ไม่ใช่เรื่องที่ลืมไว้ทีหลัง
แอปข้อเสนอแนะเร็ว ๆ จะกลายเป็นระบบบันทึกที่แชร์: product ต้องการธีม, support ต้องการการตอบอย่างเร็ว, ผู้นำต้องการการส่งออก หากไม่กำหนดว่าใครทำอะไรได้บ้าง (และพิสูจน์สิ่งที่เกิดขึ้น) ความไว้วางใจจะสลาย
ถ้าจะให้บริการหลายบริษัท ให้ถือว่าแต่ละ workspace/org เป็นขอบเขตแข็งตั้งแต่วันแรก ทุกเรคคอร์ดหลัก (feedback item, customer, conversation, tags, reports) ควรมี workspace_id และทุกการค้นหาควรถูก scope ตามมัน
นี่ไม่ใช่แค่รายละเอียดฐานข้อมูล—มันมีผลกับ URLs, คำเชิญ, และการวิเคราะห์ ค่าเริ่มต้นที่ปลอดภัย: ผู้ใช้เป็นสมาชิกหนึ่งหรือหลาย workspace และสิทธิ์ของพวกเขาถูกประเมินตามแต่ละ workspace
เก็บเวอร์ชันแรกให้เรียบง่าย:
จากนั้นแมปสิทธิ์กับการกระทำ ไม่ใช่หน้าจอ: ดู vs แก้ไข feedback, ผสาน duplicates, เปลี่ยนสถานะ, ส่งออกข้อมูล, และส่ง replies วิธีนี้ง่ายต่อการเพิ่มบทบาท "อ่านอย่างเดียว" ภายหลังโดยไม่ต้องเขียนใหม่ทั้งหมด
audit log ป้องกันข้อโต้แย้งว่า “ใครเปลี่ยนสิ่งนี้?” บันทึกเหตุการณ์สำคัญพร้อม actor, timestamp, และ before/after เมื่อจำเป็น เช่น:
บังคับใช้นโยบายรหัสผ่านที่เหมาะสม ป้องกัน endpoints ด้วย rate limiting (โดยเฉพาะ login และ ingestion) และจัดการ session อย่างปลอดภัย
ออกแบบพร้อม SSO (SAML/OIDC) แม้จะปล่อยทีหลัง: เก็บ identity provider ID และวางแผนการเชื่อมบัญชี นี่จะช่วยให้คำขอขององค์กรไม่บังคับให้คุณ refactor อย่างเจ็บปวด
ช่วงแรก ความเสี่ยงสถาปัตยกรรมที่ใหญ่ที่สุดไม่ใช่ "จะสเกลไหม?" แต่เป็น "จะเปลี่ยนแปลงได้เร็วโดยไม่ทำลายระบบไหม?" แอปข้อเสนอแนะพัฒนาเร็วเมื่อคุณเรียนรู้วิธีการที่ทีมจริง ๆ ทำ triage, routing, และตอบกลับ
modular monolith มักเป็นตัวเลือกที่ดีที่สุดสำหรับเริ่ม คุณได้ deploy หนึ่งชิ้น หนึ่งชุดของ logs และการดีบักง่ายขึ้น—พร้อมกับการจัดโค้ดเป็นโมดูล
การแยกโมดูลเชิงปฏิบัติอาจเป็น:
คิดแบบ “แยกโฟลเดอร์และอินเทอร์เฟซก่อนแยกเป็นบริการ” หากขอบเขตใดเริ่มเจอปัญหา (เช่น ปริมาณการ ingest สูง) คุณจะดึงออกมาได้โดยไม่วุ่นวาย
เลือกเฟรมเวิร์กและไลบรารีที่ทีมของคุณส่งมอบได้มั่นใจ สแตกธรรมดาที่เป็นที่รู้จักมักชนะเพราะ:
เครื่องมือแปลกใหม่รอได้จนกว่าจะมีข้อจำกัดจริง (เช่น อัตราการ ingest สูง, ความหน่วงต้องการต่ำ, สิทธิ์ซับซ้อน) ตอนนั้นจึงค่อยเปลี่ยนโฟกัสจากความชัดเจนไปยังประสิทธิภาพ
เอนทิตีหลักส่วนใหญ่—feedback items, customers, accounts, tags, assignments—เหมาะกับฐานข้อมูลเชิงสัมพันธ์ คุณต้องการการคิวรีที่ดี, constraints, และ transactions สำหรับการเปลี่ยนแปลงเวิร์กโฟลว์
ถ้าการค้นหาข้อความเต็มและการกรองสำคัญ ให้เพิ่ม search index แยกต่างหากภายหลัง (หรือใช้ความสามารถในตัวของ DB ก่อน) หลีกเลี่ยงการสร้างสองแหล่งความจริงเร็วเกินไป
ระบบข้อเสนอแนะสะสมงาน "ทำภายหลัง" รวดเร็ว: ส่งอีเมลตอบกลับ, ซิงค์ integrations, ประมวลผลไฟล์แนบ, สร้าง digest, ยิง webhooks ใส่พวกนี้ในคิว/worker ตั้งแต่แรก
จะช่วยให้ UI ตอบสนอง, ลด timeout, และทำให้ความล้มเหลว retry ได้ โดยไม่จำเป็นต้องแยกเป็น microservices ตั้งแต่วันแรก
ถ้าเป้าหมายคือยืนยันเวิร์กโฟลว์และ UI ให้เร็ว (inbox → triage → replies) ให้พิจารณาใช้แพลตฟอร์มสร้างโค้ดจากการสนทนาเช่น Koder.ai เพื่อสร้างเวอร์ชันแรกจากสเปคแชต มันช่วยให้คุณตั้งค่า React front end กับ Go + PostgreSQL backend, iterate ใน “planning mode,” และยังส่งออกซอร์สโค้ดได้เมื่อพร้อมย้ายไปเวิร์กโฟลว์วิศวกรรมแบบคลาสสิก
เลเยอร์การจัดเก็บของคุณตัดสินว่า วงจรข้อเสนอแนะจะรู้สึกเร็วและเชื่อถือได้—หรือช้าและสับสน ตั้งเป้าสกีมาที่ง่ายต่อการคิวรีสำหรับงานประจำ (triage, assignment, status) พร้อมเก็บรายละเอียดดิบพอที่จะตรวจสอบสิ่งที่เข้ามาจริง ๆ
สำหรับ MVP คุณครอบคลุมความต้องการส่วนใหญ่ด้วยชุดตาราง/คอลเลกชันเล็ก ๆ:
กฎที่มีประโยชน์: เก็บ feedback ให้ lean (สิ่งที่คิวรีบ่อย) และย้าย "ทุกอย่างที่เหลือ" ไปที่ events และ metadata เฉพาะช่องทาง
เมื่อ ticket มาทางอีเมล, แชท, หรือ webhook ให้เก็บ raw incoming payload ตามที่ได้รับ (เช่น header + body ของอีเมลต้นฉบับ หรือ webhook JSON) นี่ช่วยให้คุณ:
รูปแบบทั่วไป: ตาราง ingestions ที่มี source, received_at, raw_payload (JSON/text/blob), และลิงก์ไปยัง feedback_id ที่สร้าง/อัปเดต
หน้าจอส่วนใหญ่ย่อมมีตัวกรองที่คาดเดาได้ เพิ่มดัชนีตั้งแต่ต้นสำหรับ:
(workspace_id, status) สำหรับมุมมอง inbox/kanban(workspace_id, assigned_to) สำหรับ “ไอเท็มของฉัน”(workspace_id, created_at) สำหรับการเรียงและตัวกรองวันที่(tag_id, feedback_id) บนตารางเชื่อมหรือดัชนีค้นหาแท็กเฉพาะถ้าสนับสนุน full‑text search ให้พิจารณาดัชนีค้นหาแยกต่างหาก แทนการใช้ LIKE ซับซ้อนบน production
ข้อเสนอแนะมักมีข้อมูลส่วนบุคคล ตัดสินใจก่อน:
ใช้ retention เป็นนโยบายต่อ workspace (เช่น 90/180/365 วัน) และบังคับใช้ด้วย scheduled job ที่หมดอายุ raw ingestions ก่อน แล้วค่อยลบ events/replies เก่าถ้าจำเป็น
การรับข้อมูลคือจุดที่วงจรข้อเสนอแนะของคุณจะสะอาดและมีประโยชน์—หรือกลายเป็นกองขยะ ตั้งเป้าให้ส่งง่าย และประมวลผลได้สม่ำเสมอ เริ่มจากช่องที่ลูกค้าใช้จริงแล้วค่อยขยาย
ชุดเริ่มต้นที่ใช้งานได้จริงมักรวม:
ไม่ต้องมีการกรองหนักตั้งแต่วันแรก แต่ต้องมีการป้องกันพื้นฐาน:
normalize ทุกเหตุการณ์เป็นฟอร์แมตภายในเดียวที่มีฟิลด์คงที่:
เก็บทั้ง raw payload และ normalized record เพื่อให้ปรับ parser ได้โดยไม่สูญเสียข้อมูล
ส่งการยืนยันทันที (สำหรับ email/API/widget เมื่อเป็นไปได้): ขอบคุณ แจ้งว่าจะเกิดอะไรต่อไป และอย่าให้คำมั่นเกินไป ตัวอย่าง: “เราตรวจทุกรายการ หากต้องการรายละเอียดเพิ่มเติมเราจะตอบกลับ เราไม่สามารถตอบกลับทุกคำขอเป็นรายบุคคลได้ แต่ข้อเสนอแนะของคุณถูกติดตามไว้”
Inbox จะใช้ได้ต่อเมื่อทีมสามารถตอบคำถามสามข้อได้เร็ว: นี่คืออะไร? ใครเป็นเจ้าของ? ด่วนแค่ไหน? Triage คือส่วนที่เปลี่ยนข้อความดิบให้เป็นงานที่เป็นระเบียบ
แท็กแบบอิสระดูยืดหยุ่นแต่จะแตกกระจายเร็ว (“login”, “log-in”, “signin”) เริ่มด้วยพจนานุกรมจำกัดที่สะท้อนวิธีคิดของทีมผลิตภัณฑ์:
อนุญาตให้ผู้ใช้ เสนอ แท็กใหม่ แต่ต้องมีเจ้าของ (เช่น PM/Support lead) อนุมัติ จะช่วยให้การรายงานมีความหมายในอนาคต
สร้าง rules engine ง่าย ๆ ที่ส่งข้อความโดยอัตโนมัติตามสัญญาณที่คาดเดาได้:
ทำให้กฎโปร่งใส: แสดง “Routed because: Enterprise plan + keyword ‘SSO’.” ทีมจะเชื่อถือ automation เมื่อสามารถตรวจสอบได้
เพิ่มตัวจับเวลา SLA ให้ไอเท็มและคิวทุกอัน:
แสดงสถานะ SLA ในมุมมองรายการ (“เหลือ 2 ชม”) และในหน้ารายละเอียด เพื่อแบ่งปันความเร่งด่วนในทีม
วางเส้นทางชัดเจนเมื่อไอเท็มค้าง: คิว overdue, สรุปรายวันถึงเจ้าของ, และบันไดการยกระดับแบบเบา (Support → Team lead → On-call/Manager) เป้าหมายไม่ใช่กดดัน แต่ป้องกันไม่ให้ข้อเสนอแนะสำคัญหายไปอย่างเงียบ ๆ
การปิดวงจรคือจุดที่ระบบข้อเสนอแนะหยุดเป็นแค่ “กล่องรวบรวม” และกลายเป็นเครื่องมือสร้างความไว้วางใจ เป้าหมายง่าย ๆ: ข้อเสนอแนะแต่ละชิ้นเชื่อมโยงกับงานจริงได้ และลูกค้าที่ขอข้อมูลจะได้รับแจ้งว่าผลเป็นอย่างไร—โดยไม่ต้องใช้สเปรดชีต
เริ่มต้นด้วยการให้ feedback item เชื่อมไปยังวัตถุงานภายในหนึ่งหรือหลายชิ้น (bug, task, feature) อย่าพยายามมิเรอร์ tracker ทั้งหมด—เก็บการอ้างอิงแบบเบา ๆ:
work_type (เช่น issue/task/feature)external_system (เช่น jira, linear, github)external_id และ external_url เป็นทางเลือกนี่ช่วยให้โมเดลข้อมูลคงที่แม้เปลี่ยนเครื่องมือภายหลัง และช่วยให้มุมมอง "ข้อเสนอแนะทั้งหมดที่ผูกกับ release นี้" โดยไม่ต้องขูดข้อมูลระบบอื่น
เมื่องานที่ลิงก์อยู่ไปถึง Shipped แอปของคุณควรแจ้งลูกค้าทั้งหมดที่ผูกอยู่กับ feedback items เหล่านั้น
ใช้ข้อความเทมเพลตที่มีตัวแปรนิรภัย (ชื่อ, พื้นที่ผลิตภัณฑ์, สรุป, ลิงก์บันทึกการเปลี่ยนแปลง) ให้แก้ไขได้ก่อนส่งเพื่อหลีกเลี่ยงถ้อยคำไม่เหมาะสม หากมีบันทึกสาธารณะให้ลิงก์แบบ relative เช่น /releases
รองรับการตอบกลับผ่านช่องทางที่ส่งได้อย่างเชื่อถือได้:
ไม่ว่าจะเลือกแบบไหน ให้ติดตามการตอบกลับต่อ feedback item ด้วย timeline ที่ตรวจสอบได้: sent_at, channel, author, template_id, และสถานะการส่ง หากลูกค้าตอบกลับ ให้เก็บข้อความขาเข้าพร้อม timestamp เพื่อพิสูจน์ว่าวงจรถูกปิดจริง ไม่ใช่แค่ถูกมาร์กว่า shipped
รายงานมีประโยชน์เมื่อมันเปลี่ยนสิ่งที่ทีมทำ ถ้าจงใจสร้างมุมมองที่คนเช็คเป็นประจำ แล้วขยายเมื่อมั่นใจว่าข้อมูลเวิร์กโฟลว์ (status, tags, owners, timestamps) สม่ำเสมอ
เริ่มจากแดชบอร์ดเชิงปฏิบัติการที่สนับสนุนการกำหนดเส้นทางและการติดตาม:
เก็บกราฟให้เรียบง่ายและคลิกได้เพื่อให้ผู้จัดการสามารถลงลึกไปยังไอเท็มที่ก่อให้เกิดสัญญาณได้
เพิ่มหน้า “customer 360” ที่ช่วย support และ success ตอบด้วยบริบท:
มุมมองนี้ลดการถามซ้ำและทำให้การติดตามเหมือนตั้งใจมากขึ้น
ทีมจะขอการส่งออกตั้งแต่ต้น ให้รองรับ:
ทำให้การกรองสอดคล้องทุกที่ (ชื่อแท็กเดียวกัน, ช่วงวันที่, คำนิยามสถานะ) ความสอดคล้องนี้ป้องกัน "สองเวอร์ชันของความจริง"
ข้ามแดชบอร์ดที่วัดแค่กิจกรรม (ตั๋วที่สร้าง, แท็กที่เพิ่ม) เลือกเมตริกผลลัพธ์ที่เชื่อมกับการลงมือ: เวลาในการตอบครั้งแรก, % ของไอเท็มที่ได้ข้อสรุป, และปัญหาซ้ำที่ถูกแก้จริง
วงจรข้อเสนอแนะจะใช้ได้เมื่อมันอยู่ในที่ที่คนใช้เวลา Integrations ลดการคัดลอกวาง เก็บบริบทใกล้กับงาน และทำให้การปิดวงจรเป็นนิสัยไม่ใช่โครงการพิเศษ
จัดลำดับความสำคัญกับระบบที่ทีมใช้สื่อสาร สร้าง และติดตามลูกค้า:
เก็บเวอร์ชันแรกให้เรียบง่าย: การแจ้งเตือนทางเดียว + deep links กลับมาในแอปของคุณ แล้วค่อยเพิ่มการเขียนกลับ (เช่น “Assign owner” จาก Slack) ภายหลัง
แม้จะมี integrations แบบเนทีฟไม่กี่อย่าง แต่ webhooks ให้ลูกค้าและทีมภายในเชื่อมต่อระบบอื่นได้
เสนอชุดเหตุการณ์เล็ก ๆ และมีเสถียรภาพ:
feedback.createdfeedback.updatedfeedback.closedรวม idempotency key, timestamps, tenant/workspace id, และ payload ขั้นต่ำพร้อม URL สำหรับดึงรายละเอียดเต็ม วิธีนี้ช่วยหลีกเลี่ยงการทำให้ผู้บริโภคแตกเมื่อคุณเปลี่ยนโมเดลข้อมูล
การเชื่อมต่อมีสิทธิ์ล้มเหลวตามปกติ: token ถูกเพิกถอน, rate limits, ปัญหาเครือข่าย, schema mismatch
ออกแบบสำหรับสิ่งนี้ตั้งแต่แรก:
ถ้าคุณแพ็กเกจเป็นผลิตภัณฑ์ integrations เหล่านี้ยังเป็นปัจจัยการตัดสินใจซื้อด้วย เพิ่มขั้นตอนถัดไปที่ชัดเจนจากแอปของคุณไปยัง /pricing และ /contact สำหรับทีมที่ต้องการเดโมหรือความช่วยเหลือในการเชื่อมต่อสแต็ก
แอปข้อเสนอแนะที่ได้ผลไม่จบที่การปล่อยแรก—มันถูกปรับโดยวิธีที่ทีมจริง ๆ ทำ triage, ลงมือ, และตอบกลับ เป้าหมายของการปล่อยแรกของคุณคือ: ยืนยันเวิร์กโฟลว์, ลดงานด้วยมือ, และเก็บข้อมูลสะอาดที่คุณเชื่อถือได้
จำกัดขอบเขตให้ชัดเพื่อปล่อยเร็วและเรียนรู้ เวอร์ชัน MVP ที่ใช้งานได้จริงมักรวม:
ถ้าฟีเจอร์ไม่ช่วยให้ทีมประมวลผลข้อเสนอแนะจากต้นจนจบ มันรอได้
ผู้ใช้แรกจะยอมรับฟีเจอร์ขาดหาย แต่ไม่ยอมรับข้อเสนอแนะหายหรือ routing ผิดพลาด ให้ทดสอบจุดที่ความผิดพลาดมีค่าเสียหายสูง:
มุ่งหวังความมั่นใจในเวิร์กโฟลว์ มากกว่าการครอบคลุมที่สมบูรณ์แบบ
แม้ MVP ก็ต้องการสิ่งเบื้องต้นที่น่าเบื่อเล็กน้อย:
เริ่มด้วยพายลอต: หนึ่งทีม, ชุดช่องทางจำกัด, และเมตริกความสำเร็จชัดเจน (เช่น “ตอบ 90% ของข้อเสนอแนะความสำคัญสูงภายใน 2 วัน”) รวบรวมจุดติดขัดทุกสัปดาห์ แล้ววนปรับเวิร์กโฟลว์ก่อนเชิญทีมอื่นเข้ามา
ใช้ข้อมูลการใช้งานเป็น roadmap: จุดที่คนคลิก, จุดที่ละทิ้ง, แท็กที่ไม่ถูกใช้, และ workaround ที่เปิดเผยความต้องการจริง
"การปิดวงจร" หมายความว่า คุณสามารถย้ายจาก Collect → Act → Reply → Learn ได้อย่างสม่ำเสมอ ในทางปฏิบัติ รายการข้อเสนอแนะแต่ละชิ้นควรจบลงด้วยผลลัพธ์ที่มองเห็นได้ (shipped, declined, explained, หรือ queued) และ—เมื่อเหมาะสม—มีการตอบกลับลูกค้าแบบเห็นได้พร้อมกรอบเวลา
เริ่มจากเมตริกที่สะท้อนความเร็วและคุณภาพ:
เลือกชุดเล็กๆ เพื่อไม่ให้ทีมไปโฟกัสกับตัวเลขที่ดูดีแต่ไม่มีความหมายจริง
ทำให้ทุกแหล่งข้อมูลเป็นรูปแบบเดียวกันใน "feedback item" ภายในระบบ ขณะเดียวกันเก็บข้อมูลดิบไว้:
วิธีนี้ช่วยให้การคัดกรอง/triage สม่ำเสมอและสามารถประมวลผลซ้ำเมื่อ parser ดีขึ้นได้
เก็บโมเดลหลักให้เรียบง่ายและค้นหาได้ง่าย:
เขียนคำนิยามสถานะร่วมกันสั้นๆ และเริ่มด้วยชุดเส้นตรง:
ให้แต่ละสถานะตอบคำถามว่า “ขั้นตอนถัดไปคืออะไร?” และ “ใครเป็นเจ้าของขั้นตอนถัดไป?” ถ้า "Planned" บางทีมหมายถึง "maybe" ให้แยกชื่อหรือสถานะเพื่อให้รายงานน่าเชื่อถือ
กำหนด duplicates เป็น "ปัญหาหรือคำขอพื้นฐานเดียวกัน" ไม่ใช่แค่ข้อความคล้ายกัน:
วิธีนี้ช่วยไม่ให้งานกระจัดกระจายขณะยังรักษาบันทึกความต้องการของลูกค้าไว้ครบถ้วน
เริ่มด้วยออโตเมชันที่โปร่งใสและตรวจสอบได้:
แสดงสาเหตุที่ระบบจัดเส้นทาง (เช่น “Routed because: Enterprise plan + keyword ‘SSO’.”) เพื่อให้มนุษย์ไว้วางใจและแก้ไขได้ เริ่มจากการแนะนำหรือค่าเริ่มต้นก่อนจะบังคับ routing แบบอัตโนมัติ
ปฏิบัติให้แต่ละ workspace เป็นเขตข้อมูลแยกชัดเจน:
workspace_id ให้กับเรคคอร์ดหลักทั้งหมดworkspace_idจากนั้นกำหนดบทบาทตามการกระทำ (view/edit/merge/export/send replies) ไม่ใช่หน้าจอ และเพิ่ม audit log ตั้งแต่แรกสำหรับการเปลี่ยนสถานะ, การผสาน, การมอบหมาย, และการตอบกลับ
เริ่มจาก monolith แบบโมดูลาร์ที่มีขอบเขตชัดเจน (auth/orgs, feedback, workflow, messaging, analytics) และใช้ฐานข้อมูลเชิงสัมพันธ์สำหรับข้อมูลการทำงานเชิงธุรกรรม
เพิ่ม background jobs ตั้งแต่แรกสำหรับ:
วิธีนี้ช่วยให้ UI ตอบสนองเร็วและความล้มเหลวสามารถ retry ได้โดยไม่ต้องแบ่งเป็น microservices ตั้งแต่เริ่ม
เก็บการอ้างอิงแบบเบาแทนการมิเรอร์ tracker ทั้งหมด:
external_system (jira/linear/github)work_type (bug/task/feature)external_id (และ external_url เป็นทางเลือก)เมื่องานที่ลิงก์ไปถึงสถานะ ให้ทริกเกอร์ workflow เพื่อแจ้งลูกค้าทั้งหมดที่เกี่ยวข้องโดยใช้เทมเพลตและติดตามสถานะการส่ง หากมีบันทึกสาธารณะให้ลิงก์แบบ relative เช่น /releases
ใช้ events timeline เพื่อการตรวจสอบย้อนหลังและป้องกันการยัดข้อมูลเกินในเรคคอร์ดหลักของ feedback