05 พ.ค. 2568·4 นาที
สร้างเว็บแอปเพื่อจัดการไทม์ไลน์การยกระดับลูกค้า
แผนทีละขั้นตอนสำหรับสร้างเว็บแอปที่ติดตามการยกระดับลูกค้า วันครบ SLA เจ้าของงาน การแจ้งเตือน รวมถึงรายงานและการผสานระบบ
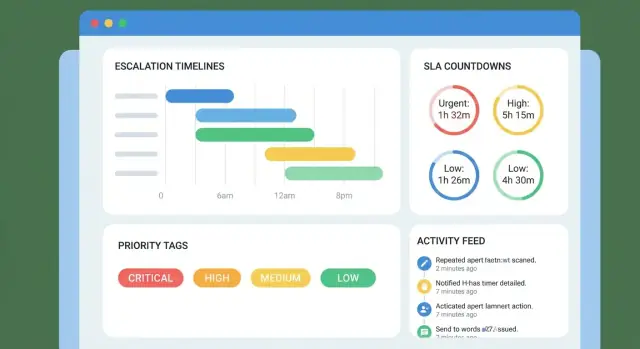
แผนทีละขั้นตอนสำหรับสร้างเว็บแอปที่ติดตามการยกระดับลูกค้า วันครบ SLA เจ้าของงาน การแจ้งเตือน รวมถึงรายงานและการผสานระบบ
ก่อนออกแบบหน้าจอหรือเลือกเทคโนโลยี ให้ระบุให้ชัดว่า “การยกระดับ” หมายถึงอะไรในองค์กรของคุณ มันคือเคสซัพพอร์ตที่กำลังล่วงเวลา เหตุการณ์ที่คุกคามความพร้อมใช้งาน คำร้องเรียนจากลูกค้ารายสำคัญ หรือคำขอใด ๆ ที่ข้ามระดับความรุนแรงหรือไม่? ถ้าทีมต่าง ๆ ใช้คำนี้ต่างกัน แอปของคุณจะสะสมความสับสน
เขียนคำนิยามหนึ่งประโยคที่ทั้งทีมเห็นตรงกัน แล้วเพิ่มตัวอย่างสั้น ๆ เช่น: “การยกระดับคือปัญหาลูกค้าที่ต้องการระดับซัพพอร์ตหรือการมีส่วนร่วมของผู้บริหารที่สูงขึ้น และมีข้อผูกมัดตามเวลาที่ชัดเจน”
กำหนดสิ่งที่ ไม่ ถือเป็นการยกระดับ (เช่น ตั๋วประจำ งานภายใน) เพื่อไม่ให้ v1 อ้วนเกินจำเป็น
เกณฑ์ความสำเร็จควรสะท้อนสิ่งที่คุณต้องการปรับปรุง — ไม่ใช่แค่สิ่งที่คุณต้องการสร้าง ผลลัพธ์ทั่วไปได้แก่:
เลือก 2–4 เมตริกที่คุณติดตามได้ตั้งแต่วันแรก (เช่น อัตราการละเมิด เวลาที่ใช้ในแต่ละขั้นตอนของการยกระดับ จำนวนการมอบหมายซ้ำ)
ระบุผู้ใช้หลัก (เอเยนต์ หัวหน้าทีม ผู้จัดการ) และผู้มีส่วนได้ส่วนเสียรอง (ผู้จัดการบัญชี วิศวกร on-call) สำหรับแต่ละคน ระบุสิ่งที่พวกเขาต้องทำอย่างรวดเร็ว: รับผิดชอบต่อเคส ขยายกำหนดเวลาด้วยเหตุผล ดูขั้นตอนถัดไป หรือสรุปสถานะให้ลูกค้า
จับข้อผิดพลาดปัจจุบันด้วยเรื่องราวที่เป็นรูปธรรม: การส่งมอบที่พลาดระหว่างชั้น ความไม่ชัดเจนของเวลาที่ครบกำหนดหลังการมอบหมายใหม่ หรือการถกเถียง “ใครอนุมัติการขยายเวลา?”
ใช้เรื่องราวเหล่านี้เพื่อแยก must-have (ไทม์ไลน์ + ความเป็นเจ้าของ + ตรวจสอบได้) ออกจากการเพิ่มในภายหลัง (แดชบอร์ดขั้นสูง การทำงานอัตโนมัติซับซ้อน)
เมื่อเป้าหมายชัดเจน ให้เขียนลงไปว่าเคสหนึ่งเคลื่อนผ่านทีมอย่างไร เวิร์กโฟลว์ที่แชร์จะป้องกันไม่ให้ “กรณีพิเศษ” กลายเป็นการจัดการที่ไม่สอดคล้องและการพลาด SLA
เริ่มจากชุดสถานะเรียบง่ายและการเปลี่ยนสถานะที่อนุญาต:
ระบุว่าแต่ละสถานะ หมายถึงอะไร (เกณฑ์เข้า) และอะไรต้องเป็นจริงเพื่อออกจากสถานะนั้น (เกณฑ์ออก) — ตรงนี้ช่วยหลีกเลี่ยงความกำกวม เช่น “Resolved แต่ยังรอการตอบกลับลูกค้า”
การยกระดับควรถูกสร้างโดยกฎที่อธิบายได้ในประโยคเดียว ทริกเกอร์ทั่วไปได้แก่:
ตัดสินใจว่าทริกเกอร์จะสร้างการยกระดับโดยอัตโนมัติ แนะนำตัวแทน หรือขอการอนุมัติ
ไทม์ไลน์ของคุณมีความถูกต้องเท่าที่เหตุการณ์ถูกบันทึก ขั้นต่ำให้เก็บ:
เขียนกฎการเปลี่ยนเจ้าของ: ใครสามารถมอบหมายใหม่ เมื่อใดต้องการการอนุมัติ (เช่น การส่งต่อทีมภายนอกหรือผู้ขาย) และจะเกิดอะไรขึ้นหากเจ้าของออกจากกะ
สุดท้าย ทำแผนผังการพึ่งพาที่ส่งผลต่อเวลา: ตาราง on-call, ระดับชั้น (T1/T2/T3) และ ผู้ขายภายนอก (รวมเวลาตอบกลับของพวกเขา) ซึ่งจะผลักดันการคำนวณไทม์ไลน์และเมทริกซ์การยกระดับในภายหลัง
แอปการยกระดับที่เชื่อถือได้เป็นปัญหาด้านข้อมูลเป็นหลัก หากไทม์ไลน์ SLA และประวัติไม่ได้ออกแบบอย่างชัดเจน UI และการแจ้งเตือนจะรู้สึกผิดพลาดตลอด เริ่มจากการตั้งชื่อเอนทิตีหลักและความสัมพันธ์
อย่างน้อย ควรวางแผนสำหรับ:
ถือแต่ละ milestone เป็น ตัวจับเวลา ที่มี:
start_at (เมื่อเริ่มนาฬิกา)due_at (วันครบที่คำนวณ)paused_at / pause_reason (ทางเลือก)completed_at (เมื่อสำเร็จ)เก็บ เหตุผล ว่าทำไมวันครบเกิดขึ้น (กฎ) ไม่ใช่แค่วันที่คำนวณแล้ว นี่ช่วยให้ข้อพิพาทง่ายขึ้น
SLA ไม่ได้หมายถึง “ตลอดเวลาเสมอไป” ออกแบบ ปฏิทิน ต่อโพลิซี SLA: ชั่วโมงทำการ vs 24/7 วันหยุด และตารางภูมิภาค
คำนวณวันครบในเวลาเซิร์ฟเวอร์ที่สอดคล้องกัน (UTC) แต่เก็บ เขตเวลาเคส/ลูกค้า เพื่อให้ UI แสดงวันครบอย่างถูกต้องและผู้ใช้สามารถเข้าใจได้
ตัดสินใจระหว่าง:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), หรือเพื่อการปฏิบัติตามและความรับผิดชอบ ควรใช้ event log (แม้ว่าคุณอาจเก็บคอลัมน์สถานะปัจจุบันไว้เพื่อประสิทธิภาพ) ทุกการเปลี่ยนแปลงควรบันทึก ใคร, อะไรเปลี่ยน, เมื่อไร, และ แหล่งที่มา (UI, API, อัตโนมัติ) พร้อม correlation ID สำหรับการติดตามการกระทำที่เกี่ยวข้อง
สิทธิ์คือจุดที่เครื่องมือยกระดับจะได้รับความเชื่อถือ—หรือถูกเลี่ยงด้วยสเปรดชีตข้างเคียง กำหนดว่าใครทำอะไรได้ตั้งแต่ต้น แล้วบังคับใช้อย่างสม่ำเสมอใน UI API และการส่งออก
เก็บ v1 ให้เรียบง่ายด้วยบทบาทที่สอดคล้องกับงานของทีมซัพพอร์ตจริง:
ทำให้การตรวจสอบบทบาทชัดเจนในผลิตภัณฑ์: ปิดการควบคุมแทนที่จะให้ผู้ใช้คลิกแล้วเจอข้อผิดพลาด
การยกระดับมักข้ามหลายกลุ่ม วางแผนการสนับสนุนหลายทีมโดยขอบเขตการมองเห็นโดยหนึ่งหรือหลายมิติ:
ค่าเริ่มต้นที่ดีคือ: ผู้ใช้เข้าถึงเคสที่พวกเขาเป็นผู้รับผิดชอบ ผู้ดู หรือเป็นสมาชิกของทีมเจ้าของ—บวกกับบัญชีที่แชร์กับบทบาทของพวกเขาโดยเฉพาะ
ไม่ใช่ข้อมูลทั้งหมดควรเห็นได้ทุกคน ฟิลด์อ่อนไหวทั่วไปได้แก่ PII ของลูกค้า รายละเอียดสัญญา และ โน้ตภายใน ดำเนินการสิทธิ์ระดับฟิลด์ เช่น:
สำหรับ v1 อีเมล/รหัสผ่านพร้อม MFA มักเพียงพอ ออกแบบโมเดลผู้ใช้ให้สามารถเพิ่ม SSO (SAML/OIDC) ในภายหลังโดยไม่ต้องเขียนสิทธิ์ใหม่ (เช่น เก็บบทบาท/ทีมภายใน แผนที่กลุ่ม SSO ตอนล็อกอิน)
ปฏิบัติการเปลี่ยนสิทธิ์เป็นการกระทำที่ต้องตรวจสอบได้ บันทึกรายการเช่นการอัปเดตบทบาท การย้ายทีม การดาวน์โหลดการส่งออก และการแก้ไขการกำหนดค่า—ใคร ทำเมื่อไร และอะไรเปลี่ยน นี่ช่วยปกป้องคุณในเหตุการณ์และทำให้งานตรวจสอบการเข้าถึงง่ายขึ้น
แอปการยกระดับของคุณชนะหรือแพ้ที่หน้าจอรายวัน: สิ่งที่หัวหน้าซัพพอร์ตเห็นแรก วิธีที่พวกเขาเข้าใจเคสอย่างรวดเร็ว และว่ากำหนดถัดไปจะหายไปหรือไม่
เริ่มจากหน้าจอชุดเล็กที่ครอบคลุมงาน 90%:
เก็บการนำทางให้คาดเดาได้: แถบด้านซ้ายหรือแท็บบนที่มี “Queue”, “My Cases”, “Reports”. ให้คิวเป็นหน้าเริ่มต้น
ในรายการเคส แสดงเฉพาะฟิลด์ที่ช่วยคนตัดสินใจว่าจะทำอะไรต่อไป แถวดี ๆ ควรมี: ลูกค้า ความสำคัญ เจ้าของปัจจุบัน สถานะ วันครบถัดไป และ สัญลักษณ์เตือน (เช่น “ครบใน 2 ชม” หรือ “เกินเวลา 1 วัน”)
เพิ่มการกรองและค้นหาอย่างรวดเร็วและใช้งานได้จริง:
ออกแบบให้สแกนได้: ความกว้างคอลัมน์สม่ำเสมอ ชิพสถานะชัดเจน และสีเน้นเดียวยืนหนึ่งสำหรับความเร่งด่วน
มุมมองเคสควรตอบได้ในพริบตา:
วาง การกระทำด่วน ไว้ใกล้ด้านบน (อย่าเก็บไว้ในเมนู): Reassign, Escalate, Add milestone, Add note, Set next deadline. แต่ละการกระทำควอยืนยันว่ามีอะไรเปลี่ยนและอัปเดตไทม์ไลน์ทันที
ไทม์ไลน์ควรอ่านเป็นลำดับข้อผูกมัด ให้แสดง:
ใช้การแสดงแบบค่อย ๆ เปิดเผย: แสดงเหตุการณ์ล่าสุดก่อน พร้อมตัวเลือกขยายดูประวัติย้อนหลัง หากคุณมีร่องรอยการตรวจสอบ ให้เชื่อมโยงจากไทม์ไลน์ (เช่น “ดูบันทึกการเปลี่ยนแปลง”)
ใช้คอนทราสต์ของสีที่อ่านได้ จับคู่สีด้วยข้อความ (“Overdue”) ทำให้การกระทำทุกอย่างเข้าถึงได้ด้วยคีย์บอร์ด และเขียนป้ายที่ตรงกับภาษาผู้ใช้ (“Set next customer update deadline” ไม่ใช่ “Update SLA”). นี่ลดการคลิกพลาดเมื่อความกดดันสูง
การแจ้งเตือนคือ “ชีพจร” ของไทม์ไลน์การยกระดับ: มันทำให้เคสเคลื่อนไหวโดยไม่ต้องจ้องแดชบอร์ด เป้าหมายคือแจ้งคนที่ถูกต้อง ในเวลาที่ถูกต้อง โดยเสียงรบกวนน้อยที่สุด
เริ่มจากชุดเหตุการณ์เล็ก ๆ ที่ชัดเจนกับการกระทำ:
สำหรับ v1 ให้เลือกช่องทางที่ส่งได้เชื่อถือและวัดผลได้:
SMS หรือเครื่องมือแชทเพิ่มเติมได้ในภายหลังเมื่อกฎและปริมาณแน่นอน
แสดงการยกระดับเป็นเกณฑ์ตามเวลาเชื่อมกับไทม์ไลน์เคส:
ทำให้เมทริกซ์สามารถตั้งค่าได้ตามความสำคัญ/คิว เพื่อให้กรณี P1 ไม่เดินตามรูปแบบเดียวกับคำถามการเรียกเก็บเงิน
นำแนวทาง deduplication (“อย่าส่งการแจ้งเตือนเดียวกันสองครั้ง”) batching (รวมการแจ้งเตือนคล้ายกัน) และ quiet hours ที่เลื่อนการเตือนที่ไม่สำคัญ แต่ยังบันทึกไว้
การแจ้งเตือนทุกชิ้นควรรองรับ:
เก็บการกระทำเหล่านี้ใน audit trail เพื่อให้รายงานแยกแยะได้ว่า “ไม่มีใครเห็น” กับ “มีคนเห็นแล้วเลื่อนไป"
แอปไทม์ไลน์การยกระดับส่วนใหญ่ล้มเหลวเมื่อมันบังคับให้คนพิมพ์ข้อมูลซ้ำจากที่อื่น สำหรับ v1 ผสานเฉพาะสิ่งที่ต้องให้ไทม์ไลน์แม่นยำและการแจ้งเตือนทันเวลา
ตัดสินใจว่าช่องทางใดสร้างหรืออัปเดตเคสได้:
เก็บ payload ขาเข้าขนาดเล็ก: หมายเลขเคส customer ID สถานะปัจจุบัน ความสำคัญ timestamp และสรุปสั้น ๆ
แอปของคุณควรแจ้งระบบอื่นเมื่อเกิดเหตุสำคัญ:
ใช้ webhooks พร้อมคำร้องที่เซ็นและ event ID สำหรับการ dedupe
ถ้าซิงค์สองทาง ประกาศแหล่งความจริงต่อฟิลด์ (เช่น เครื่องมือจองตั๋วเป็นเจ้าของสถานะ; แอปของคุณเป็นเจ้าของตัวจับเวลา SLA) กำหนดกฎขัดกัน (“last write wins” มักไม่ถูกต้อง) และใส่ retry logic พร้อม backoff และ dead-letter queue สำหรับความล้มเหลว
สำหรับ v1 นำเข้าลูกค้าและผู้ติดต่อโดยใช้ external ID ที่คงที่และสคีมาขั้นต่ำ: ชื่อบัญชี ระดับ คอนแทคหลัก และการตั้งค่าการยกระดับ หลีกเลี่ยงการทำ mirror CRM ลึก ๆ
เอกสารเช็คลิสต์สั้น ๆ (วิธีการยืนยันตัวตน ฟิลด์ที่ต้องมี อัตราจำกัด retry สภาพแวดล้อมทดสอบ) และเผยแพร่สัญญา API ขั้นต่ำ (แม้เป็นสเป็กหน้าเดียว) และเก็บเวอร์ชันเพื่อไม่ให้การผสานแตก
แบ็กเอนด์ต้องทำสองสิ่งได้ดี: ทำให้เวลาการยกระดับถูกต้อง และรักษาความเร็วเมื่อปริมาณเคสเพิ่ม
เลือกสถาปัตยกรรมที่ง่ายที่สุดที่ทีมดูแลได้ แอป MVC คลาสสิกพร้อม REST API มักเพียงพอสำหรับ v1 หากคุณใช้ GraphQL อยู่แล้วและสำเร็จ มันก็ทำงานได้—แต่หลีกเลี่ยงการเพิ่มเพียงเพราะอยากได้ จับคู่กับฐานข้อมูลที่จัดการได้ (เช่น Postgres) เพื่อให้คุณใช้เวลาไปกับตรรกะการยกระดับ ไม่ใช่งานจัดการ DB
ถ้าต้องการตรวจสอบเวิร์กโฟลว์ end-to-end ก่อนตัดสินใจลงทุนหลายสัปดาห์ แพลตฟอร์มโค้ดเร็ว เช่น Koder.ai ช่วยสร้างต้นแบบลูปหลัก (queue → case detail → timeline → notifications) จากอินเทอร์เฟซแชท แล้ววนปรับในโหมดวางแผนและส่งออกซอร์สโค้ดเมื่อพร้อม สแตกเริ่มต้นคือ React บนเว็บ, Go + PostgreSQL บนแบ็กเอนด์ ซึ่งเหมาะกับแอปที่ต้องการร่องรอยการตรวจสอบแบบนี้
การยกระดับต้องการการประมวลผลตามกำหนด ดังนั้นต้องมีงานแบ็กกราวด์สำหรับ:
ทำให้งาน idempotent (ปลอดภัยเมารันซ้ำ) และ retryable เก็บ timestamp “last evaluated at” ต่อเคส/ไทม์ไลน์เพื่อป้องกันการกระทำซ้ำ
เก็บ timestamp ทั้งหมดใน UTC แปลงเป็นเขตเวลาผู้ใช้เฉพาะที่ขอบ UI/API เพิ่มการทดสอบกรณีขอบ: การเปลี่ยนเวลาออมแสง วันพิเศษ และนาฬิกาที่ถูกหยุดชั่วคราว (เช่น SLA หยุดเมื่อรอลูกค้า)
ใช้การแบ่งหน้า (pagination) สำหรับคิวและมุมมองร่องรอย เพิ่มดรรชนีที่ตรงกับตัวกรองและการเรียงลำดับที่ใช้บ่อย เช่น (due_at), (status), (owner_id), และคอมโพสิตอย่าง (status, due_at)
วางแผนการจัดเก็บไฟล์แยกจาก DB: บังคับขนาด/ชนิดไฟล์ สแกนอัปโหลด (หรือใช้ผู้ให้บริการ) และตั้งกฎการเก็บรักษา (เช่น ลบหลัง 12 เดือน ยกเว้น legal hold) เก็บ metadata ในตารางการจัดการเคส เก็บไฟล์จริงใน object storage
รายงานคือจุดที่แอปการยกระดับหยุดเป็นแค่กล่องจดหมายร่วมและกลายเป็นเครื่องมือการจัดการ สำหรับ v1 มุ่งเป้าหน้ารายงานเดียวที่ตอบสองคำถาม: “เราปฏิบัติตาม SLA ไหม?” และ “การยกระดับติดอยู่ตรงไหน?” ทำให้เรียบง่าย เร็ว และยึดตามคำนิยามที่ทุกคนเห็นตรงกัน
รายงานเชื่อถือได้เท่ากับคำนิยามพื้นฐาน เขียนคำนิยามเหล่านี้เป็นภาษาง่าย ๆ และสะท้อนในโมเดลข้อมูล:
ตัดสินใจด้วยว่าใช้ชั่วโมงใดของ SLA ในรายงาน: ตอบแรก อัปเดตถัดไป หรือการแก้ไข (หรือทั้งสาม)
แดชบอร์ดควรเบาแต่ใช้งานได้:
เพิ่มมุมมองปฏิบัติการสำหรับการบาลานซ์งานประจำวัน:
การส่งออก CSV มักพอสำหรับ v1 ผูกการส่งออกกับสิทธิ์ (ขอบเขตตามทีม การตรวจสอบบทบาท) และบันทึกใน audit log สำหรับแต่ละการส่งออก (ใคร เมื่อไร ตัวกรองที่ใช้ จำนวนแถว) เพื่อป้องกัน “สเปรดชีตปริศนา” และรองรับการปฏิบัติตาม
ส่งหน้ารายงานแรกอย่างรวดเร็ว แล้วทบทวนกับหัวหน้าซัพพอร์ตทุกสัปดาห์เป็นเวลาเดือน รวบรวมข้อเสนอแนะเกี่ยวกับตัวกรองที่ขาด คำนิยามที่น่าสับสน และคำถามประเภท “ฉันตอบ X ไม่ได้” — นั่นคือข้อมูลที่ดีที่สุดสำหรับ v2
การทดสอบแอปไทม์ไลน์การยกระดับไม่ใช่แค่ “มันทำงานไหม?” แต่เป็น “มันทำตามที่ทีมซัพพอร์ตคาดเมื่อความกดดันสูงไหม?” เน้นสถานการณ์สมจริงที่กดดันกฎไทม์ไลน์ การแจ้งเตือน และการส่งมอบเคส
ใส่ความพยายามส่วนใหญ่ในการทดสอบการคำนวณไทม์ไลน์ เพราะข้อผิดพลาดเล็ก ๆ ที่นี่สร้างข้อพิพาท SLA ใหญ่ ๆ
ครอบคลุมกรณีเช่นการนับชั่วโมงทำการ วันหยุด และโซนเวลา เพิ่มการทดสอบสำหรับการหยุด (รอลูกค้า รอวิศวกรรม) การเปลี่ยนความสำคัญกลางเคส และการยกระดับที่เปลี่ยนเป้าหมายการตอบ/แก้ไข ทดสอบกรณีขอบเช่นเคสสร้างหนึ่งนาทีก่อนปิดทำการ หรือการหยุดเริ่มตรงขอบ SLA
การแจ้งเตือนมักล้มเหลวในช่องว่างระหว่างระบบ เขียน integration tests ที่ตรวจว่า:
ถ้าคุณใช้ อีเมล แชท หรือ webhooks ให้ตรวจ payload และเวลา ไม่ใช่แค่ว่า “มีอะไรถูกส่ง”
สร้างข้อมูลตัวอย่างสมจริงที่เผยปัญหา UX ตั้งแต่ต้น: ลูกค้า VIP เคสยาว การมอบหมายซ้ำบ่อย เคสที่เปิดซ้ำ และช่วงที่คิวพุ่ง นี่ช่วยให้คุณยืนยันว่าคิว มุมมองเคส และการแสดงไทม์ไลน์อ่านออกโดยไม่ต้องอธิบาย
รันพายล็อตกับทีมเดียว 1–2 สัปดาห์ เก็บปัญหารายวัน: ฟิลด์หาย ป้ายกำกับสับสน เสียงรบกวนจากการแจ้งเตือน และข้อยกเว้นต่อกฎไทม์ไลน์
ติดตามสิ่งที่ผู้ใช้ทำนอกแอป (สเปรดชีต ช่องทางข้างเคียง) เพื่อหาช่องว่าง
เขียนว่า “เสร็จ” หมายถึงอะไรก่อนการเปิดตัวกว้าง: เมตริก SLA หลักตรงกับผลลัพธ์ที่คาด การแจ้งเตือนสำคัญเชื่อถือได้ ร่องรอยการตรวจสอบสมบูรณ์ และทีมพายล็อตสามารถดำเนินการยกระดับครบวงจรโดยไม่ต้องมีวิธีแก้ข้างเคียง
การส่งเวอร์ชันแรกไม่ใช่เส้นชัย แอปไทม์ไลน์การยกระดับกลายเป็น “ของจริง” เมื่อผ่านความล้มเหลวประจำวัน: งานที่พลาด คิวช้า กำหนดการแจ้งเตือนผิดพลาด และการเปลี่ยนกฎ SLA จงปฏิบัติต่อการปรับใช้และการปฏิบัติการเป็นส่วนหนึ่งของผลิตภัณฑ์
ทำให้กระบวนการปล่อยน่าเบื่อและทำซ้ำได้ อัตโนมัตอย่างน้อย:
ถ้ามีสเตจ ให้ใส่ข้อมูลสมจริง (sanitized) เพื่อยืนยันพฤติกรรมไทม์ไลน์และการแจ้งเตือนก่อนขึ้นโปรดักชัน
การเช็กสถานะปกติจะไม่จับปัญหาร้ายแรงที่สุด เพิ่มการตรวจสอบที่การยกระดับอาจพังเงียบ ๆ:
สร้าง playbook เล็ก ๆ บนการตอบโต้: “ถ้าเตือน SLA ไม่ส่ง ให้ตรวจ A → B → C” ช่วยลดเวลาหยุดทำงานในเหตุการณ์ความดันสูง
ข้อมูลการยกระดับมักรวมชื่อ อีเมลลูกค้า และโน้ตที่อ่อนไหว กำหนดนโยบายตั้งแต่ต้น:
ทำให้นโยบายการเก็บรักษากำหนดค่าได้ เพื่อไม่ต้องเปลี่ยนโค้ดเมื่อเปลี่ยนนโยบาย
แม้ใน v1 แอดมินต้องมีช่องทางดูแลระบบ:
เขียนเอกสารสั้นแบบงาน: “สร้างการยกระดับ”, “หยุดไทม์ไลน์”, “บังคับ SLA”, “ตรวจสอบว่าใครเปลี่ยนอะไร” เพิ่มฟลอว์ onboarding เบา ๆ ในแอปที่ชี้ไปยังคิว มุมมองเคส และการกระทำไทม์ไลน์ พร้อมลิงก์ไปยัง /help สำหรับอ้างอิง
v1 ควรพิสูจน์ลูปหลัก: เคสมีไทม์ไลน์ชัดเจน นาฬิกา SLA ทำงานคาดเดาได้ และคนที่ถูกต้องได้รับการแจ้งเตือน v2 สามารถเพิ่มพลังโดยไม่เปลี่ยน v1 ให้เป็นระบบทุกอย่าง เทคนิคคือเก็บ backlog สั้น ๆ ชัดเจนของการอัปเกรดและดึงเข้ามาเมื่อเห็นรูปแบบการใช้งานจริง
รายการ v2 ที่ดีคือสิ่งที่ (a) ลดงานด้วยตนเองในระดับใหญ่ หรือ (b) ป้องกันความผิดพลาดที่มีต้นทุนสูง หากมันเพิ่มตัวเลือกการตั้งค่าจำนวนมาก ให้เลื่อนไปจนกว่าจะมีหลักฐานว่าหลายทีมต้องการจริง
ปฏิทิน SLA ต่อบัญชีมักเป็นการขยายที่มีความหมายครั้งแรก: ชั่วโมงทำการ วันหยุด หรือเวลาตอบตามสัญญาที่ต่างกัน
ถัดมาเพิ่ม playbook และเทมเพลต: ขั้นตอนการยกระดับสำเร็จรูป ผู้มีส่วนได้ส่วนเสียที่แนะนำ และร่างข้อความที่ช่วยให้การตอบกลับสอดคล้อง
เมื่อการมอบหมายกลายเป็นคอขวด พิจารณาการกำหนดเส้นทางตามทักษะและตาราง on-call เก็บเวอร์ชันแรกเรียบง่าย: ชุดทักษะเล็ก ๆ ผู้รับผิดชอบสำรอง และการควบคุมการบังคับที่ชัดเจน
การยกระดับอัตโนมัติอาจทริกเกอร์เมื่อสัญญาณบางอย่างปรากฏ (การเปลี่ยนความรุนแรง คีย์เวิร์ด ความรู้สึก การติดต่อซ้ำ) เริ่มจาก “เสนอการยกระดับ” (พรอมต์) ก่อนเป็น “ยกระดับอัตโนมัติ” และบันทึกเหตุผลของทุกทริกเกอร์เพื่อสร้างความเชื่อถือและตรวจสอบได้
เพิ่มฟิลด์บังคับก่อนยกระดับ (ผลกระทบ ความรุนแรง ระดับลูกค้า) และขั้นตอนอนุมัติสำหรับการยกระดับความรุนแรงสูง ลดเสียงรบกวนและช่วยให้รายงานถูกต้อง
ถ้าต้องการสำรวจรูปแบบการอัตโนมัติก่อนสร้าง ดู /blog/workflow-automation-basics. หากคุณกำลังปรับขอบเขตต่อการแพ็กเกจ ให้เช็กว่าฟีเจอร์แมปกับชั้นราคาอย่างไรที่ /pricing.
เริ่มด้วยคำนิยามหนึ่งประโยคที่ทุกคนเห็นตรงกัน (พร้อมตัวอย่างสั้น ๆ) รวมถึงสิ่งที่ ไม่ ถือเป็นการยกระดับ (ตั๋วประจำวัน งานภายใน) เพื่อไม่ให้ v1 กลายเป็นระบบตั๋วทั่วไป
จากนั้นเขียน 2–4 เมตริกความสำเร็จที่คุณวัดได้ทันที เช่น อัตราการละเมิด SLA เวลาที่ใช้ในแต่ละสถานะ หรือจำนวนครั้งที่มีการมอบหมายซ้ำ
เลือกผลลัพธ์ที่สะท้อนการปรับปรุงการปฏิบัติงาน ไม่ใช่แค่การเสร็จฟีเจอร์ เมตริก v1 ที่เป็นประโยชน์ได้แก่:
เลือกชุดเล็ก ๆ ที่คุณคำนวณได้จาก timestamp ที่เก็บตั้งแต่วันแรก
ใช้ชุดสถานะที่เล็กและง่ายต่อการแชร์ พร้อมเกณฑ์เข้า/ออกชัดเจน เช่น:
เขียนให้ชัดว่าอะไรต้องเป็นจริงเพื่อเข้าสถานะและอะไรต้องเป็นจริงเพื่อออกจากสถานะแต่ละอัน เพื่อป้องกันความกำกวม เช่น “Resolved แต่ยังรอการยืนยันจากลูกค้า”
เก็บเหตุการณ์ขั้นต่ำที่จำเป็นเพื่อสร้างไทม์ไลน์และปกป้องการตัดสินใจ SLA:
ถ้าคุณอธิบายไม่ได้ว่าทำไมต้องเก็บ timestamp ตัวใด อย่าเก็บใน v1
มองแต่ละ milestone เป็นตัวจับเวลาโดยมีฟิลด์เช่น:
start_atdue_at (คำนวณ)paused_at และ pause_reason (ถ้ามี)completed_atเก็บด้วยว่าเหตุผลหรือกฎใดผลิต (นโยบาย + ปฏิทิน + เหตุผล) แทนที่จะเก็บแค่วงเวลาที่คำนวณเสร็จแล้ว นี่ช่วยให้การตรวจสอบและข้อพิพาทง่ายขึ้นมาก
เก็บ timestamp ทั้งหมดใน UTC แต่เก็บเขตเวลา (time zone) ของเคส/ลูกค้าไว้เพื่อการแสดงผลและความเข้าใจของผู้ใช้ ออกแบบปฏิทิน SLA ให้ชัดเจน (24/7 vs ชั่วโมงทำการ, วันหยุด, ตารางภูมิภาค)
ทดสอบกรณีขอบเช่นการเปลี่ยนแปลงเวลาออมแสง กรณีที่สร้างก่อนปิดทำการหนึ่งนาที และการหยุดนาฬิกาที่เริ่มตรงกับขอบเขต SLA
เก็บบทบาท v1 ให้เรียบง่ายและสอดคล้องกับงานจริง:
เพิ่มข้อจำกัดการเข้าถึงตามทีม/ภูมิภาค/บัญชี และควบคุมระดับฟิลด์สำหรับข้อมูลอ่อนไหว เช่น โน้ตภายในและ PII
ออกแบบหน้าจอที่ใช้ทุกวันก่อน:
ปรับแต่งให้สแกนได้ง่าย ลดการสลับบริบท—การกระทำด่วนไม่ควรถูกซ่อนในเมนู
เริ่มจากชุดการแจ้งเตือนสัญญาณสูงเล็ก ๆ:
เลือกช่องทาง 1–2 ช่องสำหรับ v1 (มักเป็น in-app + อีเมล) แล้วตั้งเมทริกซ์การยกระดับด้วยเกณฑ์ชัดเจน (T–2h, T–0h, T+1h). ป้องกันความเหนื่อยล้าด้วยการ dedupe, การรวมเป็นชุด, และชั่วโมงเงียบ รวมทั้งทำให้การรับทราบ/เลื่อนเวลาเป็นสิ่งที่บันทึกได้
เชื่อมต่อเฉพาะสิ่งที่ทำให้ไทม์ไลน์ถูกต้อง:
หากซิงค์สองทาง ให้กำหนดแหล่งความจริงต่อฟิลด์และกฎขัดกัน (หลีกเลี่ยง "last write wins") และเผยสเป็ก API เวอร์ชันย่อที่เวอร์ชันได้ เพื่อป้องกันการแตกของการผสาน
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับรูปแบบอัตโนมัติ ดู /blog/workflow-automation-basics; สำหรับการพิจารณาแพ็กเกจ ดู /pricing
due_at