16 มิ.ย. 2568·4 นาที
วิธีสร้างเว็บแอปสำหรับการจัดการการพึ่งพาโครงการ
วางแผน ออกแบบ และปล่อยเว็บแอปที่ติดตามการพึ่งพาข้ามทีม เจ้าของความรับผิดชอบ ความเสี่ยง และไทม์ไลน์ พร้อมเวิร์กโฟลว์แจ้งเตือน และรายงานที่ชัดเจน
ชัดเจนกับกรณีการใช้งานและตัวชี้วัดความสำเร็จ
ก่อนจะออกแบบหน้าจอหรือเลือกเทคสแต็ก ให้ชัดเจนกับปัญหาที่จะแก้ แอปการพึ่งพาจะล้มเหลวเมื่อกลายเป็น “ที่ต้องอัปเดตอีกที่หนึ่ง” ในขณะที่ความเจ็บปวดจริง—การเซอร์ไพรส์และการส่งงานล่าช้าระหว่างทีม—ยังคงอยู่
กำหนดปัญหาหลัก
เริ่มด้วยประโยคสั้น ๆ ที่คุณสามารถพูดซ้ำได้ในทุกการประชุม:
การพึ่งพาข้ามทีมทำให้เกิดความล่าช้าและเซอร์ไพรส์นาทีสุดท้าย เพราะความเป็นเจ้าของ เวลา และสถานะไม่ชัดเจน.
ทำให้เฉพาะตัวกับองค์กรของคุณ: ทีมไหนได้รับผลกระทบมากที่สุด งานประเภทใดถูกบล็อก และจุดไหนที่คุณสูญเสียเวลาอยู่ตอนนี้ (การส่งต่อ, การอนุมัติ, ผลลัพธ์, การเข้าถึงข้อมูล ฯลฯ)
ระบุผู้ใช้เป้าหมาย (และสิ่งที่พวกเขาต้องการ)
ลิสต์ผู้ใช้หลักและวิธีที่พวกเขาจะใช้แอป:
- Project managers: ต้องการมุมมองที่เชื่อถือได้ของบล็อกเกอร์ที่กำลังจะมาถึงและสิ่งที่ต้องยกระดับ
- Team leads: ต้องการความชัดเจนในสิ่งที่ทีมต้องส่ง เมื่อไร และการแลกเปลี่ยน
- Exec sponsors: ต้องการมุมมองความเสี่ยงระดับสูงและความรับผิดชอบ
- Individual contributors (ICs): ต้องการคำขอที่ปฏิบัติได้ บริบท และวันที่ครบกำหนด
จับงานหลักที่ต้องทำ (jobs-to-be-done)
เก็บ “งาน” ให้กระชับและทดสอบได้:
- ค้นหา การพึ่งพาตั้งแต่ต้น (ในแผน ไม่ใช่ระหว่างการส่งมอบ)
- สร้าง คำขอการพึ่งพาที่มีขอบเขตและวันที่ชัดเจน
- ยืนยัน (ยอมรับ/ปฏิเสธ) พร้อมวันที่ต่อรอง
- ติดตาม ความคืบหน้าและการเปลี่ยนแปลงเมื่อเวลาผ่านไป
- ยกระดับ เมื่อความเสี่ยงเพิ่มหรือการสัญญาล่าช้า
ตัดสินความหมายของคำว่า “dependency” ที่นี่
เขียนคำนิยามสั้น ๆ หนึ่งย่อหน้า ตัวอย่าง: handoff (ทีม A ให้ข้อมูล), approval (การเซ็นต์โดย Legal), หรือ deliverable (spec การออกแบบ) คำนิยามนี้กลายเป็นโมเดลข้อมูลและกระดูกสันหลังของเวิร์กโฟลว์
ตั้งตัวชี้วัดความสำเร็จ
เลือกชุดผลลัพธ์ที่วัดได้เล็ก ๆ:
- จำนวนบล็อกเกอร์ที่ใช้งานต่อโปรเจกต์ลดลง (หรือการพึ่งพาที่ค้นพบช้าลดลง)
- เวลาระหว่างคำขอ → ยอมรับ → ส่งมอบ เฉลี่ยเร็วขึ้น
- ความคาดการณ์ได้ดีขึ้น (การเลื่อนวันที่น้อยลง อัตราการส่งมอบตรงเวลาสูงขึ้น)
ถ้าคุณวัดไม่ได้ คุณพิสูจน์ไม่ได้ว่าแอปช่วยปรับปรุงการปฏิบัติงานจริง
แม็ปผู้มีส่วนได้ส่วนเสียและเวิร์กโฟลว์ปัจจุบัน
ก่อนออกแบบหน้าจอหรือฐานข้อมูล ให้ชัดว่ามีใครเข้าร่วมการพึ่งพาและงานไหลระหว่างพวกเขาอย่างไร การจัดการการพึ่งพาข้ามทีมล้มเหลวเพราะความคาดหวังไม่ตรงกันมากกว่าเพราะเครื่องมือไม่ดี: “ใครเป็นเจ้าของ?”, “เสร็จคืออะไร?”, “ดูสถานะที่ไหน?”
หาว่าข้อมูลการพึ่งพาอยู่ที่ไหนตอนนี้
ข้อมูลการพึ่งพามักกระจัดกระจาย ทำการสำรวจอย่างรวดเร็วและเก็บตัวอย่างจริง (สกรีนช็อตหรือหน้าเอกสาร) ของ:
- สเปรดชีตที่ติดตามคำขอและวันที่
- ตั๋ว/epic ใน Jira/Asana/Trello
- เอกสารและบันทึกการประชุม (Google Docs/Notion/Confluence)
- เธรดใน Slack/Teams ที่การตัดสินใจและสัญญาเกิดขึ้น
นั่นบอกคุณว่าฟิลด์อะไรที่ผู้คนพึ่งพาแล้ว (วันที่ครบกำหนด ลิงก์ ความสำคัญ) และสิ่งที่ขาด (เจ้าของชัดเจน เกณฑ์การยอมรับ สถานะ)
แม็ปเวิร์กโฟลว์จากต้นจนจบ
เขียนโฟลว์ปัจจุบันเป็นภาษาธรรมดา โดยทั่วไป:
request → accept → deliver → verify
สำหรับแต่ละขั้นตอน ให้บันทึก:
- ใครเป็นตัวเริ่ม (บทบาท/ทีม ไม่ใช่บุคคล)
- ข้อมูลใดที่ต้องมีเพื่อดำเนินการต่อ
- บันทึกอยู่ที่ไหนในปัจจุบัน
- “เสร็จ” หมายถึงอะไร (และใครเซ็นรับ)
หาจุดล้มเหลวและจัดลำดับความเจ็บปวด
มองหารูปแบบเช่น เจ้าของไม่ชัดเจน, วันที่ขาด, สถานะเงียบ, หรือการค้นพบการพึ่งพาช้า ให้ผู้มีส่วนได้ส่วนเสียจัดอันดับสถานการณ์ที่เจ็บปวดที่สุด (เช่น “ยอมรับแต่ไม่ส่งมอบ” กับ “ส่งมอบแต่ไม่ตรวจรับ”) ปรับปรุงสิ่งที่สำคัญที่สุด 1–2 อย่างก่อน
ยึดการสร้างด้วย user stories
เขียน user stories 5–8 เรื่องสะท้อนความเป็นจริง เช่น:
- “ในฐานะ PM ผู้ขอ ฉันสามารถส่งคำขอการพึ่งพาพร้อมวันที่ต้องการและบริบท เพื่อให้ทีมเจ้าของประเมินได้”
- “ในฐานะหัวหน้าทีมเจ้าของ ฉันสามารถยอมรับ/ปฏิเสธพร้อมวันที่สัญญาเพื่อให้ความคาดหวังชัดเจน”
- “ในฐานะผู้มีส่วนได้ส่วนเสีย ฉันสามารถเห็นสถานะได้ในแว้บเดียวเพื่อไม่ต้องไล่เช็คในที่ประชุม”
เรื่องเหล่านี้จะเป็นราวเขตขอบเขตเมื่อคำขอฟีเจอร์เริ่มท่วม
ออกแบบโมเดลข้อมูลของ Dependency
แอปการพึ่งพาสำเร็จหรือล้มเหลวจากว่าทุกคนเชื่อถือข้อมูลหรือไม่ เป้าหมายของโมเดลข้อมูลคือจับ ใครต้องการอะไร จากใคร เมื่อไร และเก็บบันทึกความเปลี่ยนแปลงของสัญญาอย่างชัดเจน
เรกคอร์ด Dependency หลัก
เริ่มจากเอนทิตีเดียว “Dependency” ที่อ่านได้ด้วยตัวเอง:
- Title: สั้นและเฉพาะ (เช่น “Provide legal review for updated checkout copy”)
- Description: บริบท, เกณฑ์การยอมรับ, ลิงก์
- Type: รายการควบคุม (เช่น review, delivery, approval, data access)
- Owning team: ทีมที่คาดว่าจะส่งมอบ
- Requester: บุคคลหรือทีมที่ขอ
พยายามทำฟิลด์เหล่านี้เป็นข้อบังคับเท่าที่ทำได้; ฟิลด์ที่เป็นทางเลือกมักถูกปล่อยว่าง
วันที่และสัญญา
การพึ่งพาจริง ๆ แล้วเกี่ยวกับเวลา ให้เก็บวันที่อย่างชัดเจนและแยกกัน:
- Requested by (วันที่ผู้ขอต้องการ)
- Committed by (วันที่ที่ทีมเจ้าของสัญญา)
- Delivered on (วันที่ทำเสร็จจริง)
- Review window (ช่วงเริ่ม/สิ้นสุดสำหรับการตรวจหรือเซ็นรับ)
การแยกนี้ป้องกันข้อโต้แย้ง (“requested” ไม่เหมือนกับ “committed”)
สถานะและความสัมพันธ์
ใช้โมเดลสถานะง่าย ๆ ที่ทุกคนเห็นตรงกัน: proposed → pending → accepted → delivered และยกเว้นเช่น at risk และ rejected
แม็ปความสัมพันธ์เป็นลิงก์แบบหนึ่งต่อหลายเพื่อให้แต่ละ dependency เชื่อมกับ:
- Projects (หนึ่ง dependency อาจกระทบหลายโครงการ)
- Milestones (ผูกกับจุดตรวจส่งมอบเฉพาะ)
- Tickets (เช่น issue ใน Jira สำหรับการดำเนินงาน)
ความตรวจสอบและความน่าเชื่อถือ
ทำให้การเปลี่ยนแปลงติดตามได้ด้วย:
- Created/updated by
- Change history (การอัปเดตระดับฟิลด์เมื่อเวลาผ่านไป)
- Comments (บันทึกการตัดสินใจ คำชี้แจง การอนุมัติ)
ถ้าทำ audit trail ถูกตั้งแต่ต้น คุณจะหลีกเลี่ยงข้อถกเถียงและทำให้การส่งต่องานราบรื่นขึ้น
โมเดลโปรเจกต์ มายล์สโตน และความเป็นเจ้าของทีม
แอปการพึ่งพาทำงานได้ก็ต่อเมื่อทุกคนเห็นพ้องว่าคืออะไร “โปรเจกต์” “มายล์สโตน” คืออะไร และใครรับผิดชอบเมื่อเกิดการเลื่อน เก็บโมเดลง่ายพอที่ทีมจะยินดีดูแลรักษา
โปรเจกต์และมายล์สโตน: เลือกระดับความละเอียดที่เหมาะสม
ติดตามโปรเจกต์ในระดับที่คนวางแผนและรายงาน—โดยทั่วไปคือริเริ่มงานที่ใช้เวลาหลายสัปดาห์ถึงหลายเดือนและมีผลลัพธ์ชัดเจน หลีกเลี่ยงการสร้างโปรเจกต์สำหรับทุกตั๋ว; นั่นเป็นงานของเครื่องมือการส่งมอบ
มายล์สโตนควรเป็นจุดตรวจสำคัญไม่กี่จุดที่ปลดล็อคงานอื่นได้ (เช่น “API contract approved”, “Beta launch”, “Security review complete”) ถ้ามายล์สโตนละเอียดเกินไป การอัปเดตจะกลายเป็นงานน่าเบื่อและคุณภาพข้อมูลตก
กฎปฏิบัติ: โปรเจกต์ควรมี 3–8 มายล์สโตน แต่ละอันมีเจ้าของ วันที่เป้าหมาย และสถานะ ถ้าต้องการมากกว่านี้ ให้พิจารณาแบ่งโปรเจกต์ให้เล็กลง
ไดเรกทอรีทีม: ทำให้การค้นหาเจ้าของง่าย
การพึ่งพาพังเมื่อคนไม่รู้จะคุยกับใคร เพิ่มไดเรกทอรีทีมที่เบา ๆ รองรับ:
- ชื่อทีมและหน้าที่ (เช่น Payments, Data Platform, Legal)
- ผู้ติดต่อหลัก (คน) และสำรอง/คนรับผิดชอบ
- ช่องทางที่ชอบใช้ (อีเมล, Slack handle, คิวตั๋ว)
ไดเรกทอรีนี้ควรใช้งานได้แม้กับพาร์ทเนอร์ที่ไม่ใช่เทคนิค จึงเก็บฟิลด์ให้อ่านง่ายและค้นหาได้
กฎความเป็นเจ้าของ: ความรับผิดชอบแต่ไม่สับสน
ตัดสินใจตั้งแต่ต้นว่าจะอนุญาตความเป็นเจ้าของร่วมหรือไม่ สำหรับการพึ่งพา กฎที่สะอาดที่สุดคือ:
- เจ้าของผู้รับผิดชอบเดียวต่อมายล์สโตน/การพึ่งพา (หนึ่งคน)
- ผู้ร่วมงานเป็นทางเลือก (หลายคน)
ถ้าสองทีมแชร์ความรับผิดชอบจริง ๆ ให้แม็ปเป็นสองมายล์สโตน (หรือสอง dependency) พร้อมการส่งต่อที่ชัดเจน แทนที่จะใช้รายการ “ร่วมเป็นเจ้าของ” ที่ไม่มีใครขับเคลื่อน
การพึ่งพาข้ามโปรเจกต์และการรวบยอดโปรแกรม
แทนการพึ่งพาเป็นลิงก์ระหว่าง โปรเจกต์/มายล์สโตนที่ขอ กับ โปรเจกต์/มายล์สโตนที่ส่งมอบ โดยมีทิศทาง (“A needs B”) สิ่งนี้เปิดทางให้มุมมองระดับโปรแกรม: คุณสามารถรวบยอดตามริเริ่ม ไตรมาส หรือพอร์ตโฟลิโอได้โดยไม่เปลี่ยนวิธีการทำงานประจำวันของทีม
กลยุทธ์การแท็กที่ยังคงใช้ได้
แท็กช่วยตัดการรายงานโดยไม่บังคับโครงสร้างใหม่ เริ่มด้วยชุดเล็ก ๆ ที่ควบคุมได้:
- พื้นที่ผลิตภัณฑ์
- ไตรมาส (หรือหน้าต่างการปล่อยเป้าหมาย)
- ชื่อริเริ่ม/โปรแกรม
- ลำดับความสำคัญ (เช่น P0–P3)
ชอบ dropdown มากกว่าข้อความอิสระสำหรับแท็กหลัก เพื่อลดกรณีที่ “Payments”, “payments”, “Paymnts” กลายเป็นหมวดหมู่คนละอัน
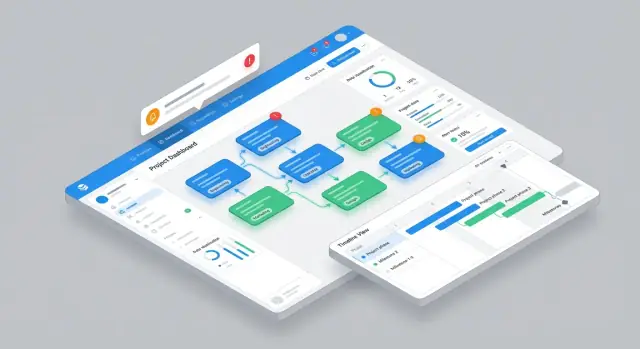
วางแผน UI หลักและการนำทาง
แอปการจัดการการพึ่งพาประสบความสำเร็จเมื่อผู้คนตอบสองคำถามได้ในไม่กี่วินาที: “ฉันต้องทำอะไร?” และ “อะไรบล็อกฉัน?” ออกแบบการนำทางรอบงานเหล่านั้น ไม่ใช่รอบออบเจ็กต์ฐานข้อมูล
มุมมองหลักที่ตรงกับงานจริง
เริ่มด้วยมุมมองหลักสี่แบบ แต่ละแบบปรับให้เหมาะกับช่วงเวลาทำงานที่ต่างกันในสัปดาห์:
- Dependency list สำหรับการไตรจ์และการเรียงลำดับ (เหมาะกับการเช็คประจำวัน)
- Dependency graph เพื่อเข้าใจผลกระทบขึ้น/ลงลำดับได้ทันที
- Timeline เพื่อตรวจหาการชนกันของวันที่และการส่งต่อที่ล่าช้า
- Team inbox เป็นหน้าเริ่มต้นสำหรับผู้ร่วมงาน (“คำขอกำลังรอฉัน”)
เก็บเมนูนำทางระดับสูงให้เรียบง่าย (เช่น Inbox, Dependencies, Timeline, Reports) และให้ผู้ใช้ข้ามมุมมองได้โดยไม่สูญเสียตัวกรอง
การสร้างที่เร็วโดยไม่ละทิ้งความชัดเจน
ทำให้การสร้าง dependency รู้สึกเร็วเหมือนส่งข้อความ ให้ เทมเพลต (เช่น “API contract”, “Design review”, “Data export”) และหน้า Quick Add แบบลิ้นชัก
บังคับเฉพาะสิ่งที่จำเป็นในการจัดเส้นทางงาน: ทีมผู้ขอ, ทีมเจ้าของ, วันที่ครบกำหนด, คำอธิบายสั้น, สถานะ ส่วนที่เหลือเป็นทางเลือกหรือเปิดแสดงเมื่อจำเป็น
การกรอง ค้นหา และมุมมองที่บันทึกได้
คนจะใช้ตัวกรองบ่อย สนับสนุนการค้นหาและกรองโดย ทีม, ช่วงวันที่, ความเสี่ยง, สถานะ, โปรเจกต์ รวมถึง “assigned to me” ให้ผู้ใช้บันทึกการรวมที่ใช้บ่อย (“My Q1 launches”, “High risk this month”)
การเข้าถึงและคำแนะนำเมื่อว่างเปล่า
ใช้ ตัวบ่งชี้ความเสี่ยงที่ปลอดสี (ไอคอน + ป้าย ไม่ใช้สีเพียงอย่างเดียว) และรองรับ การนำทางด้วยคีย์บอร์ด เต็มรูปแบบสำหรับการสร้าง การกรอง และการอัปเดตสถานะ
สภาพแสดงผลเมื่อว่างควรสอน เมื่อรายการว่าง ให้แสดงตัวอย่างสั้น ๆ ของ dependency ที่ชัดเจน:
“Payments team: provide sandbox API keys for Checkout v2 by Mar 14; needed for mobile QA start.”
แนวทางแบบนี้ช่วยปรับปรุงคุณภาพข้อมูลโดยไม่เพิ่มกระบวนการ
สร้างเวิร์กโฟลว์: Request, Accept, Deliver, Close
Keep the Code Portable
Generate the app quickly, then export source code when you’re ready to productionize.
เครื่องมือการพึ่งพาจะสำเร็จเมื่อสะท้อนการทำงานร่วมกันของทีมจริง—โดยไม่บังคับให้คนเข้าประชุมสถานะยาวๆ ออกแบบเวิร์กโฟลว์รอบชุดสถานะเล็ก ๆ ที่ทุกคนรู้จัก และทำให้การเปลี่ยนแต่ละสถานะตอบคำถามเดียว: “เกิดอะไรขึ้นต่อไป และใครเป็นเจ้าของ?”
โฟลว์คำขอการพึ่งพา: create → route → acceptance
เริ่มด้วยฟอร์ม “Create dependency” แบบแนะนำที่จับขั้นต่ำที่ต้องใช้: โปรเจกต์ผู้ขอ ผลลัพธ์ที่ต้องการ วันที่เป้าหมาย และผลกระทบหากพลาด จากนั้น route อัตโนมัติไปยังทีมเจ้าของตามกฎง่าย ๆ (เจ้าของ service/component, ไดเรกทอรีทีม, หรือเลือกเอง)
การยอมรับต้องชัดเจน: ทีมเจ้าของยอมรับ ปฏิเสธ หรือขอชี้แจง หลีกเลี่ยงการยอมรับแบบ “นิ่ม”—ให้เป็นปุ่มที่สร้างความรับผิดชอบและบันทึกเวลา
เกณฑ์การยอมรับ: คำจำกัดความของเสร็จและการเซ็นรับ
เมื่อยอมรับ ให้ระบุ definition of done น้ำหนักเบา: ผลลัพธ์ที่ส่งมอบ (เช่น endpoint API, การทบทวนสเป็ก, data export), การทดสอบการยอมรับหรือขั้นตอนการตรวจรับ, และ เจ้าของการเซ็นรับ ฝั่งผู้ขอ
สิ่งนี้ป้องกันความล้มเหลวที่พบบ่อยคือส่งมอบแล้วใช้ไม่ได้
การจัดการการเปลี่ยนแปลง: วันที่ ขอบเขต การมอบหมายซ้ำ
การเปลี่ยนแปลงเป็นเรื่องปกติ แต่เซอร์ไพรส์ไม่ใช่ ทุกการเปลี่ยนควร:
- บันทึก สิ่งที่เปลี่ยน (วัน ขอบเขต เจ้าของ)
- ระบุเหตุผลสั้น ๆ
- แจ้งทั้งสองทีม
- เก็บประวัติให้เห็นได้ เพื่อจะไม่มีการถกเถียงว่า “ใครพูดอะไร”
เส้นทางการยกระดับ: ธง at-risk และ SLA
ให้ผู้ใช้มีธง at-risk พร้อมระดับการยกระดับ (เช่น Team Lead → Program Lead → Exec Sponsor) และ SLA ทางเลือก (ตอบภายใน X วัน, อัปเดตทุก Y วัน) การยกระดับควรเป็นการกระทำในเวิร์กโฟลว์ ไม่ใช่เธรดโกรธ
โฟลว์การปิด: หลักฐาน การตรวจรับ และบันทึกบทเรียน
ปิด dependency ได้หลังสองขั้นตอน: หลักฐานการส่งมอบ (ลิงก์, ไฟล์แนบ, หรือบันทึก) และ การตรวจรับ โดยผู้ขอ (หรือปิดอัตโนมัติหลังหน้าต่างที่กำหนด) เก็บฟิลด์บทเรียนสั้น ๆ (“อะไรที่บล็อกเรา?”) เพื่อปรับปรุงการวางแผนต่อไปโดยไม่ต้องทำ postmortem เต็มรูปแบบ
เพิ่มบทบาท สิทธิ์ และความตรวจสอบได้
การจัดการการพึ่งพาล้มเหลวเมื่อคนไม่แน่ใจว่าใครมอบสัญญา ใครแก้ไขได้ และใครเปลี่ยนอะไร โมเดลสิทธิ์ที่ชัดเจนป้องกันการเปลี่ยนวันที่โดยไม่ได้ตั้งใจ ปกป้องงานที่ละเอียดอ่อน และสร้างความเชื่อใจระหว่างทีม
กำหนดประเภทบทบาทที่ตรงกับงานจริง
เริ่มด้วยชุดบทบาทเล็ก ๆ และขยายเมื่อมีความต้องการจริง:
- Admin: จัดการการตั้งค่า workspace, integrations, และสิทธิ์ระดับโลก
- Program manager: ดูแลพอร์ตโฟลิโอ, ตั้งกฎกำกับดูแล, และแก้ข้อพิพาท
- Team lead: เป็นเจ้าของคำมั่นสัญญาของทีมและอนุมัติคำขอขาเข้า
- Contributor: สร้างและอัปเดต dependency ที่เกี่ยวข้อง, เพิ่มบันทึก, เสนอการเปลี่ยนแปลง
- Viewer: เข้าอ่านสำหรับผู้มีส่วนได้ส่วนเสียที่ต้องการมองเห็นแต่ไม่มีสิทธิ์แก้ไข
สิทธิ์ตามออบเจ็กต์ (และตามการกระทำ)
นำสิทธิ์มาปรับใช้ระดับออบเจ็กต์—dependencies, projects, milestones, comments/notes—แล้วตามด้วยการกระทำ:
- สร้าง/แก้ไข dependencies
- เปลี่ยน status ของ dependency (เช่น Proposed → Accepted → Delivered → Closed)
- แก้ไขวันที่ที่สัญญาเทียบกับวันที่แนะนำ
- ลบ (มักจำกัดให้ Admin/Program manager)
ค่าเริ่มต้นที่ดีคือ least-privilege: ผู้ใช้ใหม่ไม่ควรลบเรกคอร์ดหรือเขียนทับสัญญา
การมองเห็นข้อมูลและงานที่ละเอียดอ่อน
ไม่ใช่ทุกโปรเจกต์จะมองเห็นได้เท่ากัน เพิ่มขอบเขตการมองเห็นเช่น:
- Internal (ค่าเริ่มต้น): มองเห็นได้กับผู้ใช้ที่ยืนยันตัวใน workspace
- Sensitive: จำกัดให้เฉพาะทีมหรือกลุ่มความปลอดภัย
- Team-private notes: เก็บบันทึกการส่งมอบที่ตรงไปตรงมาให้เฉพาะทีมเจ้าของเห็น ขณะที่สถานะ dependency ยังคงมองเห็นได้สำหรับผู้มีส่วนได้ส่วนเสีย
การควบคุมการอนุมัติและความตรวจสอบได้
กำหนดว่าใครยอมรับ/ปฏิเสธคำขอและใครเปลี่ยนวันที่ที่สัญญา—โดยปกติคือ team lead ของผู้รับ (หรือมอบหมาย) ทำให้กฎชัดเจนใน UI: “เฉพาะทีมเจ้าของเท่านั้นที่ยืนยันวันที่ได้”
สุดท้าย เพิ่ม audit log สำหรับเหตุการณ์สำคัญ: การเปลี่ยนสถานะ, แก้ไขวันที่, เปลี่ยนเจ้าของ, อัปเดตสิทธิ์, และการลบ (รวมใคร เวลา และสิ่งที่เปลี่ยน) ถ้าคุณรองรับ SSO ให้จับคู่กับ audit log เพื่อความชัดเจนในการเข้าถึงและความรับผิดชอบ
พัฒนาแจ้งเตือนและการแจ้งเตือน
Iterate Without Fear
Use snapshots and rollback when you test new status rules or data fields.
แจ้งเตือนคือจุดที่เครื่องมือการพึ่งพาจะกลายเป็นประโยชน์จริงๆ—หรือกลายเป็นเสียงที่ทุกคนเรียนรู้ที่จะเพิกเฉย เป้าหมายคือ: ขับเคลื่อนงานข้ามทีมด้วยการแจ้งคนที่ใช่ในเวลาที่เหมาะสม โดยระดับความเร่งด่วนที่เหมาะสม
เริ่มด้วยทริกเกอร์การแจ้งเตือนที่ชัดเจน
กำหนดเหตุการณ์ที่สำคัญสำหรับการพึ่งพาข้ามทีม:
- New request created (ทีมผู้รับต้องรับทราบ)
- Request accepted / rejected (ผู้ขอต้องได้รับความแน่นอน)
- Due date approaching (ป้องกันเซอร์ไพรส์นาทีสุดท้าย)
- Status changes to “at risk” or “blocked” (กระตุ้นการดำเนินการ)
ผูกแต่ละทริกเกอร์กับเจ้าของและ “ขั้นตอนถัดไป” เพื่อการแจ้งเตือนไม่ใช่แค่ให้ข้อมูล แต่ต้องปฏิบัติได้
เสนอช่องทางโดยไม่บังคับ
รองรับหลายช่องทาง:
- In-app notifications สำหรับประวัติการตรวจสอบและการไตรจ์ที่สะอาด
- Email สำหรับคนที่อยู่ในกล่องจดหมาย
- Slack/Teams (ถ้ามี) สำหรับการมองเห็นทีมอย่างรวดเร็ว
ให้การตั้งค่าปรับได้ที่ระดับผู้ใช้และทีม หัวหน้าการพึ่งพาอาจอยากได้การแจ้งเตือนใน Slack; ผู้สนับสนุนระดับผู้บริหารอาจอยากได้สรุปรายวันทางอีเมล
สมดุลระหว่างการแจ้งแบบเรียลไทม์และสรุป
ข้อความเรียลไทม์เหมาะกับการตัดสินใจ (ยอมรับ/ปฏิเสธ) และการยกระดับ สรุปเหมาะกับการรับรู้ (วันที่ใกล้ครบ, รายการ “รอการตอบ”)
เพิ่มการตั้งค่าเช่น: “ทันทีสำหรับการมอบหมาย”, “สรุปรายวันสำหรับวันที่ครบกำหนด”, และ “สรุปรายสัปดาห์สำหรับสุขภาพโดยรวม” เพื่อลดความอ่อนล้าจากการแจ้งเตือนแต่ยังคงมองเห็นได้
ทำเตือนความจำและตรรกะการยกระดับให้ถูกต้อง
การเตือนควรเคารพ วันทำการ, โซนเวลา, และชั่วโมงเงียบ เช่น: ส่งเตือน 3 วันทำการก่อนวันครบกำหนด และไม่แจ้งนอก 9am–6pm เวลาท้องถิ่น
การยกระดับควรเริ่มเมื่อ:
- คำขอไม่ตอบกลับหลัง SLA ที่กำหนด (เช่น 48 ชั่วโมง)
- วันที่ครบกำหนดเลื่อนไปหรือ dependency ถูกติดธง at risk
ยกระดับไปชั้นรับผิดชอบถัดไป (team lead, program manager) และรวมบริบท: อะไรถูกบล็อก ใคร และต้องการการตัดสินใจอะไร
วางแผนการเชื่อมต่อและการซิงค์ข้อมูล
การเชื่อมต่อทำให้แอป dependency มีประโยชน์ตั้งวันแรกเพราะทีมส่วนใหญ่ติดตามงานที่อื่น เป้าหมายไม่ใช่ “แทนที่ Jira” (หรือ Linear, GitHub, Slack)—แต่เชื่อมการตัดสินใจการพึ่งพากับระบบที่การดำเนินงานเกิดขึ้น
การเชื่อมต่อที่ควรให้ความสำคัญ
เริ่มจากเครื่องมือที่แทนงาน เวลา และการสื่อสาร:
- Jira / Linear สำหรับ issue, สถานะ, ผู้รับมอบหมาย, และบริบท sprint/iteration
- GitHub สำหรับ pull request, releases, และสัญญาณการ deploy
- Google Calendar สำหรับวันที่มายล์สโตน, หน้าต่างเปลี่ยนแปลง, และการประชุมสำคัญ
- Slack สำหรับการแจ้งเตือนและการอนุมัติแบบเบา
เลือก 1–2 ตัวสำหรับพายล็อตก่อน การเชื่อมต่อเยอะเกินไปช่วงแรกจะทำให้การดีบักเป็นงานหลัก
กลยุทธ์นำเข้า: CSV ก่อน แล้วค่อยซิงค์
ใช้ CSV import ครั้งเดียว เพื่อบูตสตาร์ท dependencies, projects, และ owners ที่มีอยู่ เก็บรูปแบบให้ชัด (เช่น ชื่อ dependency, ทีมผู้ขอ, ทีมผู้ให้, วันที่ครบกำหนด, สถานะ)
จากนั้นเพิ่ม ongoing sync เฉพาะฟิลด์ที่ต้องสอดคล้อง (เช่น สถานะ issue ภายนอก หรือวันที่ครบกำหนด) เพื่อลดการเปลี่ยนแปลงที่น่าตกใจและทำให้ง่ายต่อการแก้ปัญหา
การลิงก์ vs การซิงค์ (และเมื่อใด)
ไม่ใช่ทุกฟิลด์ภายนอกควรถูกคัดลอกเข้าสู่ฐานข้อมูลของคุณ
- Linking: เก็บ ID ของระบบภายนอก (เช่น key ของ Jira) และ deep-link ไปยังมัน เหมาะเมื่อเครื่องมือนอกเป็น source of truth
- Syncing: เก็บสำเนาฟิลด์ที่จำเป็นบางอย่าง (สถานะ, วันที่ครบกำหนด, ผู้รับมอบหมาย) เพื่อรองรับการรายงาน การแจ้งเตือน และประวัติการตรวจสอบ—โดยเฉพาะเมื่อคุณต้องการรู้ว่า “อะไรเปลี่ยนเมื่อไร”
แพทเทิร์นปฏิบัติ: เก็บ external IDs เสมอ, ซิงค์ชุดฟิลด์เล็ก ๆ, และอนุญาตการยกเว้นด้วยตนเองเฉพาะเมื่แอปของคุณเป็น source of truth
Webhooks + APIs: ซิงค์แบบขับเคลื่อนด้วยเหตุการณ์
Polling ง่ายแต่ noisy ให้เลือก webhooks เมื่อเป็นไปได้:
- ฟังการเปลี่ยนสถานะ (เช่น “In Progress” → “Done”)
- ฟังการเปลี่ยนวันที่ครบกำหนด (มักเป็นทริกเกอร์สำคัญ)
เมื่อมีเหตุการณ์เข้ามา ให้เข้าคิวงานแบ็กกราวด์เพื่อดึงเรกคอร์ดล่าสุดผ่าน API และอัปเดตออบเจ็กต์ dependency ของคุณ
กำหนดขอบเขตความเป็นเจ้าของข้อมูล
เขียนลงว่าแต่ละระบบเป็นเจ้าของฟิลด์ใด:
- Jira/Linear เป็นเจ้าของ issue status และ assignee
- แอปของคุณเป็นเจ้าของ dependency relationship, commitment date, และการตัดสินใจ accept/decline
- Slack เป็นเจ้าของ ช่องทางการส่งข้อความและประวัติข้อความ (อย่าพยายามจำลองมัน)
กฎ source-of-truth ชัดเจนช่วยป้องกัน “สงครามซิงค์” และทำให้การกำกับดูแลและการตรวจสอบง่ายขึ้น
สร้างรายงานและแดชบอร์ดสุขภาพ
แดชบอร์ดคือที่ที่แอปการพึ่งพาจะได้ความไว้วางใจ: ผู้นำจะเลิกขอ “สไลด์สถานะอีกหน้า” และทีมจะเลิกไล่เช็คอัปเดตในแชท เป้าหมายไม่ใช่กราฟมากมาย แต่เป็นวิธีเร็ว ๆ ในการตอบว่า “อะไรเสี่ยง ทำไม และใครจะทำขั้นต่อไป?”
กำหนดสัญญาณสุขภาพที่ชัดเจน
เริ่มด้วยชุดธงความเสี่ยงเล็ก ๆ ที่คำนวณได้สม่ำเสมอ:
- Overdue: วันที่ที่สัญญาผ่านไปและยังไม่ส่งมอบ
- Blocked: ติดธงว่า blocked หรือขาดข้อมูลจำเป็น
- Missing owner: ไม่มีทีม/บุคคลรับผิดชอบ
- Conflicting dates: ความต้องการของผู้ขอชนกับแผนการส่งมอบของผู้ให้
สัญญาณเหล่านี้ควรมองเห็นได้ทั้งระดับ dependency และรวบยอดเป็นสุขภาพโปรเจกต์/โปรแกรม
สร้างมุมมองพร้อมประชุม
สร้างมุมมองที่ตรงกับการประชุมคุมเกม:
- Upcoming critical dependencies: 2–4 สัปดาห์ถัดไป เรียงตามความเสี่ยงและวันที่ครบกำหนด
- Team capacity impact: แสดงจุดที่คำขอเข้าเกินความสามารถทีม (แม้แค่ตัวชี้ว่า low/medium/high ก็ช่วยได้)
- Program rollups: จัดกลุ่ม dependency ตาม initiative, quarter, หรือ release train เพื่อให้ผู้นำเปรียบเทียบงานได้โดยไม่ต้องรวบรวมเอง
ค่าเริ่มต้นที่ดีคือหน้าหนึ่งที่ตอบว่า: “อะไรเปลี่ยนตั้งแต่สัปดาห์ที่แล้ว?” (ความเสี่ยงใหม่ บล็อกที่แก้แล้ว การเลื่อนวันที่)
ทำให้การแชร์ง่าย
แดชบอร์ดมักต้องออกจากแอป เพิ่มการส่งออกที่รักษาบริบท:
- CSV สำหรับการวิเคราะห์และการกรอง
- PDF สำหรับการประชุมคุมเกมและการอนุมัติ
เมื่อส่งออก ให้รวมเจ้าของ วันที่ครบกำหนด สถานะ และความเห็นล่าสุดเพื่อให้ไฟล์มีความหมายด้วยตัวมันเอง นั่นคือวิธีที่แดชบอร์ดจะแทนที่สไลด์สถานะด้วยการลดงานรายงานด้วยตนเอง
เลือกสแต็กเทคนิคและสถาปัตยกรรมที่ปฏิบัติได้จริง
Plan the Data Model
Map entities, roles, and success metrics first, then generate the app from the plan.
เป้าหมายไม่ใช่หาเทคโนโลยีที่ “สมบูรณ์แบบ” แต่เลือกสแต็กที่ทีมของคุณสร้างและดูแลได้มั่นใจ ขณะเดียวกันก็ทำให้มุมมองการพึ่งพารวดเร็วและเชื่อถือได้
เริ่มด้วยรูปแบบเรียบง่ายและพิสูจน์แล้ว
ฐานปฏิบัติได้คือ:
- เว็บแอป (server-rendered หรือ SPA) สำหรับการใช้งานประจำวัน
- API เดี่ยว (REST หรือ GraphQL) เพื่อขับ UI และ integrations
- ฐานข้อมูลเชิงสัมพันธ์
- งานแบ็กกราวด์สำหรับการแจ้งเตือน ซิงค์ตามกำหนด และการสร้างรายงาน
สิ่งนี้ทำให้ระบบเข้าใจง่าย: การกระทำของผู้ใช้จัดการแบบ synchronous ขณะที่งานหนัก (ส่งเตือน คำนวณเมตริกสุขภาพ) ทำแบบ asynchronous
ฐานข้อมูล: แม็ปลิงก์ให้จริงจัง
การจัดการการพึ่งพาต้องค้นหา “ไอเท็มทั้งหมดที่ถูกบล็อกโดย X” บ่อย ๆ โมเดลเชิงสัมพันธ์ทำได้ดี โดยเฉพาะกับดัชนีที่เหมาะสม
อย่างน้อย วางแผนตารางเช่น Projects, Milestones/Deliverables, และ Dependencies (from_id, to_id, type, status, due dates, owners) เพิ่มดัชนีสำหรับตัวกรองทั่วไป (team, status, due date, project) และการสำรวจลิงก์ (from_id, to_id) เพื่อไม่ให้แอปช้าลงเมื่อจำนวนลิงก์เพิ่มขึ้น
กราฟและไทม์ไลน์: เลือกไลบรารีที่คำนึงถึงประสิทธิภาพ
กราฟการพึ่งพาและไทม์ไลน์แบบ Gantt อาจหนัก เลือกไลบรารีที่รองรับ virtualization (เรนเดอร์เฉพาะสิ่งที่มองเห็น) และอัปเดตแบบ incremental ถือว่า “โชว์ทุกอย่าง” เป็นโหมดขั้นสูง และตั้งค่ามุมมองเริ่มต้นให้เป็นแบบจำกัด (ต่อโปรเจกต์ ต่อทีม ต่อช่วงวัน)
รักษาความเร็วของมุมมอง: แคชและแบ่งหน้า
แบ่งหน้ารายการโดยดีฟอลต์ และแคชผลลัพธ์คำนวณที่ใช้บ่อย (เช่น “blocked count per project”) สำหรับกราฟ ให้โหลดเฉพาะบริเวณใกล้เคียงรอบโหนดที่เลือก แล้วขยายตามต้องการ
พื้นฐานการปรับใช้ที่คุณจะดีใจที่ทำ
ใช้ environment แยก (dev/staging/prod), เพิ่มมอนิเตอร์และการติดตามข้อผิดพลาด, และล็อกเหตุการณ์ที่เกี่ยวกับ audit แอปการพึ่งพากลายเป็น source of truth ได้เร็ว—downtime และข้อผิดพลาดเงียบมีค่าใช้จ่ายจริงในการประสานงาน
ทางลัดถ้ากำลังทำ prototype
ถ้าเป้าหมายหลักคือทดสอบเวิร์กโฟลว์และ UI อย่างรวดเร็ว (inbox, acceptance, escalation, dashboards) ก่อนใช้วิศวกรรมเต็มที่ คุณสามารถพัฒนาโปรโตไทป์บนแพลตฟอร์มสร้างความรู้สึกอย่างเร็วเช่น Koder.ai มันช่วยให้คุณวนโมเดลข้อมูล บทบาท/สิทธิ์ และหน้าจอหลักผ่านแชท แล้วส่งออกรหัสเมื่อพร้อมขึ้นโปรดักชัน (โดยทั่วไป React บนเว็บ, Go + PostgreSQL ที่แบ็กเอนด์) เหมาะสำหรับพายล็อตกับ 2–3 ทีมที่ความเร็วในการวนซ้ำสำคัญกว่าสถาปัตยกรรมสมบูรณ์ตั้งแต่วันแรก
ทดสอบ พายล็อต และเปิดตัวอย่างปลอดภัย
แอปการพึ่งพาช่วยได้เมื่อต้องได้รับความเชื่อถือ ความเชื่อนั้นได้มาจากการทดสอบรอบคอบ พายล็อตที่จำกัด และการเปิดตัวที่ไม่รบกวนทีมระหว่างการส่งมอบ
ทดสอบเวิร์กโฟลว์จากต้นจนจบ
เริ่มจากการยืนยันเส้นทางปกติ: ทีมขอ, ทีมเจ้าของยอมรับ, งานส่งมอบ, และ dependency ปิดพร้อมผลลัพธ์ชัดเจน
แล้วทดสอบกรณีขอบที่มักทำให้การใช้งานจริงพัง:
- การมอบหมายซ้ำ: ย้ายความเป็นเจ้าของไปทีมอื่นและยืนยันว่าประวัติยังครบ
- การปฏิเสธ: ปฏิเสธพร้อมเหตุผล ให้ผู้ขอแก้ไข/ส่งใหม่ได้
- การเปลี่ยนวันที่: อัปเดตวันที่มายล์สโตนและยืนยันว่าช่วงเวลาลงลำดับและรายงานถูกปรับ
การตรวจสอบสิทธิ์และ audit
แอปการพึ่งพาล้มเหลวเมื่อสิทธิ์เข้มงวดเกินไป (คนทำงานไม่ได้) หรือหลวมเกินไป (ทีมเสียการควบคุม) ทดสอบสถานการณ์เช่น:
- ผู้ขอแก้ไขรายละเอียดของตัวเองได้ แต่ ไม่สามารถ แก้ฟิลด์การส่งมอบของทีมผู้รับ
- มีเพียงเจ้าของที่กำหนดเท่านั้นที่ยอมรับ/ตั้งวันที่
- Admin สามารถแทรกแซง และทุกการเปลี่ยนแปลงสำคัญถูกจับใน audit trail (ใคร/อะไร/เมื่อไร)
การแจ้งเตือนโดยไม่เป็นเสียงรบกวน
การแจ้งเตือนควรทำให้คนลงมือ ไม่ใช่ทำให้เพิกเฉย ตรวจสอบว่า:
- ไม่มีการแจ้งซ้ำเมื่อหลายฟิลด์เปลี่ยนพร้อมกัน
- การหน่วงเวลา/การรวมข่าวทำงาน (เช่น สรุปการอัปเดตแทน 10 พิงค์แยกกัน)
- อีเมล/Slack digest มีบริบทพอ (โปรเจกต์, dependency, วันที่, เจ้าของ) เพื่อให้ลงมือได้โดยไม่ต้องหาเพิ่มเติม
เตรียมข้อมูลตัวอย่างสำหรับการทดสอบ
ก่อนชวนทีม เติมข้อมูลเดโมที่สมจริง โปรเจกต์มายล์สโตน และการพึ่งพาข้ามทีม ข้อมูลตัวอย่างที่ดีจะช่วยพบป้ายชื่อที่สับสน สถานะที่ขาด และช่องว่างการรายงานได้เร็วกว่าข้อมูลทดสอบสังเคราะห์
รันพายล็อตขนาดเล็ก แล้วค่อยขยาย
พายล็อตกับ 2–3 ทีม ที่พึ่งพากันจริง ตั้งเวลาสั้น ๆ (2–4 สัปดาห์) เก็บฟีดแบ็กทุกสัปดาห์ และวนปรับ:
- ชื่อสถานะและฟิลด์ที่ต้องกรอก
- กฎการแจ้งเตือน
- มุมมองการรายงาน (อะไรที่ “ต้องทำ” กับอะไรที่ “น่าสนใจ”)
เมื่อทีมพายล็อตยืนยันว่าเครื่องมือช่วยประหยัดเวลา ให้ขยายเป็นคลื่นและเผยแพร่เอกสารสั้น ๆ ว่า “วิธีที่เราทำงานตอนนี้” (แม้แต่เอกสารภายในลิงก์จากหัวแอปก็พอ) เพื่อให้ความคาดหวังสอดคล้อง
คำถามที่พบบ่อย
What should I clarify before building a dependency management app?
เริ่มจากประโยคปัญหาเดียวที่ใช้ได้ในทุกการประชุม: การพึ่งพาข้ามทีมทำให้เกิดความล่าช้าเพราะความเป็นเจ้าของ เวลา และสถานะไม่ชัดเจน. แล้วเลือกชุดผลลัพธ์ที่วัดได้ไม่กี่ตัว เช่น:
- น้อยลงของการพึ่งพาที่ค้นพบช้า
- เวลาระหว่างคำขอ → ยอมรับ → ส่งมอบ เร็วขึ้น
- อัตราการส่งมอบตรงเวลาเพิ่มขึ้น (การคาดการณ์ดีขึ้น)
ถ้าคุณวัดการปรับปรุงไม่ได้ ก็พิสูจน์การยอมรับไม่ได้เช่นกัน
Who are the primary users and what do they need from the app?
จงเน้นบทบาทและความต้องการให้กระชับ:
- Project managers: ต้องเห็นบล็อกเกอร์ล่วงหน้าและรู้ว่าต้องยกระดับอะไรบ้าง
- Team leads: ต้องการคำขอที่ชัดเจน ตัวเลือก และวันที่สัญญา
- Exec sponsors: ต้องการมุมมองรวมของความเสี่ยงและความรับผิดชอบ
- ICs: ต้องการคำขอที่ปฏิบัติได้ พร้อมบริบทและวันที่ครบกำหนด
ออกแบบมุมมองเริ่มต้นรอบคำถามว่า “ฉันต้องทำอะไรบ้าง?” กับ “อะไรบล็อกฉัน?” แทนที่จะออกแบบรอบฐานข้อมูล
How do I define what a “dependency” is in my organization?
เขียนคำนิยามหนึ่งย่อหน้าและยึดตามนั้น ตัวอย่างทั่วไป:
- handoff (ทีม A ให้ข้อมูล/ชิ้นงาน)
- approval (การอนุมัติจาก Legal/Security)
- deliverable (เช่น spec การออกแบบ, สัญญา API)
คำนิยามนี้จะกำหนดฟิลด์ที่ต้องมี สถานะเวิร์กโฟลว์ และเกณฑ์ว่า “เสร็จ” คืออะไร
What fields should the core dependency record include?
เรกคอร์ดขั้นต่ำที่ดีต้องจับ ใครต้องการอะไร จากใคร เมื่อไร พร้อมการติดตามย้อนหลัง:
- ชื่อเรื่อง, คำอธิบาย (พร้อมลิงก์), ประเภท
- ผู้ขอและทีมที่เป็นเจ้าของ
- วันที่ต้องการ (requested-by), วันที่สัญญา (committed-by), วันที่ส่งมอบจริง
- สถานะง่ายๆ และประวัติ/คอมเมนต์
หลีกเลี่ยงฟิลด์ที่เป็นทางเลือกเยอะจนว่างเปล่า; ทำฟิลด์ที่จำเป็นให้บังคับ
What workflow and status model works best for dependencies?
ใช้โฟลว์ที่เรียบง่ายและทำให้การยอมรับชัดเจน:
- Proposed → Pending → Accepted → Delivered (เพิ่มเติมเช่น Rejected, At risk/Blocked)
การยอมรับควรเป็นการกระทำที่ชัดเจน (ปุ่ม + เวลาบันทึก) ไม่ใช่การยอมรับลอย ๆ ในคอมเมนต์ เพราะนั่นคือสิ่งที่สร้างความรับผิดชอบและรายงานที่ชัดเจน
How should I model projects and milestones without making it too complicated?
เลือกความละเอียดที่ทีมวางแผนและรายงานจริงๆ:
- Project ควรเป็นสิ่งที่ใช้เวลาหลายสัปดาห์ถึงหลายเดือน และมีผลลัพธ์ชัดเจน
- โปรเจกต์ควรมี 3–8 milestones แต่ละอันมีเจ้าของและวันที่เป้าหมาย
ถ้ามี milestone เยอะเกินไป การอัปเดตจะกลายเป็นงานน่าเบื่อและคุณภาพข้อมูลจะตก ให้เลื่อนรายละเอียดระดับตั๋วไปไว้ใน Jira/Linear ฯลฯ
How do I handle roles, permissions, and auditability?
ตั้งค่าเริ่มต้นเป็น least-privilege และปกป้องความมุ่งมั่น:
- เฉพาะ team lead ของผู้รับ (หรือผู้รับมอบอำนาจ) เท่านั้นที่ยอมรับ/ปฏิเสธและตั้งวันที่สัญญาได้
- ผู้ขอสามารถแก้ไขรายละเอียดคำขอของตัวเองได้ แต่ไม่ควรแก้วันที่ที่ผู้รับมอบหมายแล้ว
- บันทึกเหตุการณ์สำคัญใน audit log (สถานะ/วันที่/การเปลี่ยนเจ้าของ/การเปลี่ยนสิทธิ)
วิธีนี้ช่วยป้องกันการเปลี่ยนแปลงโดยไม่ตั้งใจและลดข้อถกเถียงว่าใครพูดอะไรเมื่อไหร่
How do I design notifications so they help instead of creating noise?
เริ่มด้วยทริกเกอร์ที่กระทำได้จริง:
- สร้างคำขอใหม่
- ยอมรับ/ปฏิเสธ/ขอชี้แจง
- ใกล้ถึงวันครบกำหนด
- ติดธง at risk/blocked หรือค้างส่ง
ให้การแจ้งเตือนแบบเรียลไทม์สำหรับการตัดสินใจและการยกระดับ และใช้ digest สำหรับการรับรู้ (รายวัน/รายสัปดาห์) เพิ่มการหน่วงเวลาเพื่อหลีกเลี่ยงสแปม
What’s the right approach to integrations and data sync with tools like Jira or Slack?
อย่าพยายามแทนที่เครื่องมือทำงาน ให้เชื่อมโยงการตัดสินใจกับที่ที่งานเกิดขึ้นจริง:
- เก็บ ID ภายนอกเสมอ (linking)
- ซิงค์เฉพาะฟิลด์ที่ต้องใช้สำหรับการแจ้งเตือน/รายงาน (เช่น สถานะ, วันที่ครบกำหนด)
- ใช้ webhooks แทนการ polling สำหรับการเปลี่ยนสถานะ/วันที่
เขียนกฎ source-of-truth ให้ชัดเจน (เช่น Jira คุมสถานะ issue; แอปของคุณคุมการยอมรับและวันที่สัญญา)
How should I pilot and roll out the app to earn trust and adoption?
เริ่มด้วยทีม 2–3 ทีมที่พึ่งพากันจริงๆ ในช่วง 2–4 สัปดาห์:
- ยืนยันเส้นทางปกติ (request → accept → deliver → verify/close)
- ทดสอบกรณีขอบ (การย้ายเจ้าของ, การปฏิเสธ, การเปลี่ยนวันที่)
- ปรับปรุงฟิลด์ที่จำเป็น, ชื่อสถานะ, และกฎการแจ้งเตือน
ขยายการใช้งานเป็นคลื่นเมื่อทีม pilot ยืนยันว่าเครื่องมือนี้ประหยัดเวลา และเผยแพร่เอกสารสั้น ๆ ว่า “วิธีการทำงานตอนนี้” ที่ลิงก์จากหัวแอป