15 พ.ค. 2568·3 นาที
วิธีสร้างเว็บแอปเพื่อเสริมข้อมูลลูกค้า
เรียนรู้วิธีสร้างเว็บแอปที่เสริมข้อมูลลูกค้า: สถาปัตยกรรม การเชื่อมต่อ การจับคู่ การตรวจสอบความถูกต้อง ความเป็นส่วนตัว การเฝ้าติดตาม และเคล็ดลับการเปิดตัว
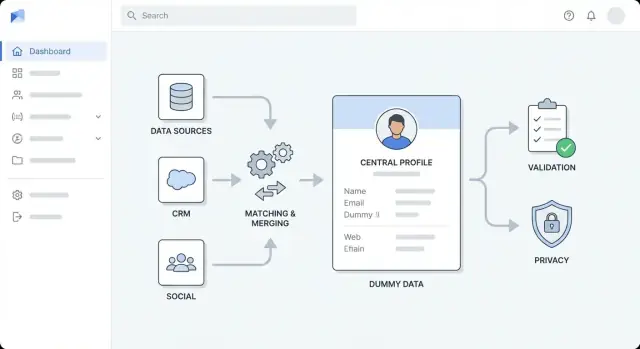
กำหนดเป้าหมาย ผู้ใช้ และขอบเขตการเสริมข้อมูล
ก่อนจะเลือกเครื่องมือหรือร่างไดอะแกรมสถาปัตยกรรม ให้ชัดเจนก่อนว่า “การเสริมข้อมูล” หมายถึงอะไรสำหรับองค์กรของคุณ ทีมมักผสมประเภทการเสริมหลายอย่างแล้วจึงยากจะวัดความคืบหน้า—หรือทะเลาะกันว่าจะแจ้งว่า “เสร็จ” ตอนไหน
อะไรที่นับว่าเป็นการเสริมข้อมูล?
เริ่มจากระบุหมวดฟิลด์ที่คุณต้องการปรับปรุงและเหตุผล:
- Firmographic: ขนาดบริษัท อุตสาหกรรม ที่ตั้งสำนักงานใหญ่ ระดับเงินทุน
- Contact: ตำแหน่งงาน อีเมล/โทรศัพท์ที่ยืนยันแล้ว ลำดับชั้น หน้าที่รับผิดชอบ
- Behavioral: สัญญาณการใช้ผลิตภัณฑ์ ความตั้งใจ คะแนนการมีส่วนร่วม
- ฟิลด์กำหนดเอง: พื้นที่รับผิดชอบภายใน เกณฑ์บัญชี ระดับ ICP
จดว่า ฟิลด์ไหนเป็น จำเป็น, ฟิลด์ไหนเป็น เสริมได้ก็ได้, และฟิลด์ไหนห้ามเสริม (เช่น คุณลักษณะอ่อนไหว)
ใครจะใช้แอป — และเพื่ออะไร?
ระบุผู้ใช้หลักและงานที่พวกเขาต้องทำมากที่สุด:
- Sales ops: ลดข้อมูลซ้ำ ทำให้บัญชีเป็นมาตรฐาน ปรับปรุงการส่งต่อ
- Marketing ops: เสริมข้อมูลลีดเพื่อนำไปแบ่งกลุ่มและกำหนดเป้าหมายให้ดีขึ้น
- Support: แสดงบริบทบัญชีขณะตอบตั๋ว
- Analysts: ได้ชุดข้อมูลเชื่อถือได้สำหรับการรายงาน
แต่ละกลุ่มผู้ใช้มักต้องการเวิร์กโฟลว์ต่างกัน (ประมวลผลเป็นกลุ่ม vs ตรวจสอบทีละระเบียน) ดังนั้นจับความต้องการเหล่านี้ตั้งแต่ต้น
กำหนดผลลัพธ์ ขอบเขต และเกณฑ์ความสำเร็จ
ลิสต์ผลลัพธ์เป็นเชิงวัด: อัตราการจับคู่สูงขึ้น จำนวนข้อมูลซ้ำลดลง การส่งต่อลีด/บัญชีเร็วขึ้น หรือประสิทธิภาพการแบ่งกลุ่มดีขึ้น
ตั้งขอบเขตชัดเจนว่า ระบบใดอยู่ในขอบเขต (CRM, ระบบเรียกเก็บเงิน, analytics ผลิตภัณฑ์, เคาน์เตอร์สนับสนุน) และระบบใดไม่อยู่—อย่างน้อยสำหรับการออกตัวแรก
สุดท้าย ตกลงเมตริกความสำเร็จและอัตราความผิดพลาดที่ยอมรับได้ (เช่น ความครอบคลุมการเสริม ข้อที่ยืนยันได้ อัตราซ้ำ และกฎ "ล้มเหลวอย่างปลอดภัย" เมื่อการเสริมไม่แน่นอน) ซึ่งจะเป็นดาวเหนือสำหรับการพัฒนาต่อไป
ตรึงโมเดลข้อมูลลูกค้าและระบุช่องว่าง
ก่อนจะเสริมอะไร ให้ชัดเจนก่อนว่า “ลูกค้า” คืออะไรในระบบของคุณ—และคุณรู้อะไรเกี่ยวกับพวกเขาอยู่แล้ว สิ่งนี้ช่วยหลีกเลี่ยงการจ่ายค่าการเสริมที่คุณเก็บไม่ได้ และป้องกันการรวมที่สับสนในภายหลัง
สำรวจฟิลด์และแหล่งข้อมูลปัจจุบัน
เริ่มด้วยพจนานุกรมฟิลด์เรียบง่าย (เช่น ชื่อ อีเมล บริษัท โดเมน โทรศัพท์ ที่อยู่ ตำแหน่งงาน อุตสาหกรรม) สำหรับแต่ละฟิลด์ให้จดแหล่งที่มา: ป้อนโดยผู้ใช้ นำเข้า CRM ระบบเรียกเก็บเงิน เครื่องมือสนับสนุน แบบฟอร์มสมัครผลิตภัณฑ์ หรือผู้ให้บริการเสริมข้อมูล
ยังจดด้วยว่าเก็บอย่างไร (จำเป็น vs ไม่จำเป็น) และเปลี่ยนแปลงบ่อยแค่ไหน ตัวอย่างเช่น ตำแหน่งงานและขนาดบริษัทจะเปลี่ยนตามเวลา ขณะที่รหัสลูกค้าภายในไม่ควรเปลี่ยน
กำหนดโมเดลตัวตน: บุคคล บริษัท บัญชี
เวิร์กโฟลว์การเสริมข้อมูลส่วนใหญ่เกี่ยวข้องอย่างน้อยสองเอนทิตี:
- บุคคล (contact/lead): บุคคลที่มีอีเมล โทร หมายเลข และบทบาท
- บริษัท (organization): ธุรกิจที่มีโดเมน ที่ตั้ง และข้อมูล firmographics
ตัดสินใจว่าคุณต้องการ บัญชี (Account) ด้วยหรือไม่ (ความสัมพันธ์เชิงพาณิชย์) ที่สามารถเชื่อมหลายคนกับบริษัทเดียวได้ พร้อมแอตทริบิวต์เช่น แผน วันสัญญา สถานะ
จดความสัมพันธ์ที่คุณรองรับ (เช่น หลายคน → หนึ่งบริษัท; หนึ่งคน → หลายบริษัทตลอดเวลา)
บันทึกปัญหาข้อมูลที่พบบ่อย
ลิสต์ปัญหาที่เกิดซ้ำ: ค่าหาย รูปแบบไม่สอดคล้อง ("US" vs "United States"), ซ้ำจากการนำเข้า ระเบียนเก่า และแหล่งข้อมูลขัดแย้ง (ที่อยู่ระบบเรียกเก็บเงิน vs ที่อยู่ CRM)
เลือกคีย์ที่จำเป็นและตั้งระดับความน่าเชื่อถือ
เลือกตัวระบุที่ใช้จับคู่และอัปเดต—โดยทั่วไปคือ อีเมล, โดเมน, โทรศัพท์, และ รหัสลูกค้าภายใน
กำหนดระดับความเชื่อถือของแต่ละคีย์: คีย์ใดเป็นแหล่งอำนาจ คีย์ใดเป็น "พยายามดีที่สุด" และคีย์ใดห้ามเขียนทับ
ชัดเจนด้านความเป็นเจ้าของและสิทธิการแก้ไข
ตกลงว่าใครเป็นเจ้าของฟิลด์ใด (Sales ops, Support, Marketing, Customer success) และกำหนดกฎการแก้ไข: สิ่งใดที่มนุษย์แก้ได้ สิ่งใดที่ออโตเมชันแก้ได้ และอะไรต้องได้รับอนุมัติ
การกำกับดูแลนี้ช่วยประหยัดเวลาตอนที่ผลการเสริมขัดแย้งกับข้อมูลที่มี
เลือกแหล่งเสริมและสัญญาข้อมูล
ก่อนเขียนโค้ดเชื่อมต่อ ให้ตัดสินใจว่าแหล่งข้อมูลมาจากที่ไหนและคุณได้รับอนุญาตทำอะไรบ้าง สิ่งนี้ป้องกันความล้มเหลวทั่วไป: ส่งฟีเจอร์ที่ใช้งานได้ทางเทคนิคแต่ทำให้ค่าใช้จ่าย ความน่าเชื่อถือ หรือการปฏิบัติตามข้อกำหนดพัง
แหล่งเสริมที่พบบ่อย
คุณมักรวมหลายแหล่งเข้าด้วยกัน:
- ระบบภายใน: CRM, ระบบเรียกเก็บเงิน, ตั๋วสนับสนุน, analytics ผลิตภัณฑ์, แพลตฟอร์มอีเมล, data warehouse
- API ภายนอก: firmographics บริษัท การยืนยันติดต่อ รหัสอุตสาหกรรม technographics สัญญาณความเสี่ยง
- รายการอัปโหลด: CSV จากฝ่ายขาย อีเวนต์ พาร์ทเนอร์ หรือผู้ให้ข้อมูล
- Webhooks: อัพเดตแบบเรียลไทม์จากเครื่องมือที่สังเกตการเปลี่ยนแปลง (เช่น การยืนยันอีเมล ผู้ให้บริการตัวตน)
วิธีประเมินแหล่งข้อมูล
สำหรับแต่ละแหล่ง ให้ให้คะแนนตาม ความครอบคลุม (ให้ข้อมูลที่ใช้ได้บ่อยแค่ไหน), ความสดใหม่ (อัปเดตเร็วแค่ไหน), ราคา (ต่อการเรียก/ต่อเรคคอร์ด), ขีดจำกัดอัตรา, และ ข้อกำหนดการใช้งาน (เก็บอะไรได้บ้าง นานเท่าไร และเพื่อวัตถุประสงค์ใด)
ตรวจสอบด้วยว่าผู้ให้บริการส่ง คะแนนความมั่นใจ และ แหล่งที่มาของข้อมูล ชัดเจนหรือไม่
กำหนดสัญญาข้อมูล
ปฏิบัติต่อทุกแหล่งเป็นสัญญาที่กำหนดชื่อฟิลด์และรูปแบบ ฟิลด์ที่จำเป็น vs ไม่จำเป็น ความถี่อัปเดต ความหน่วงที่คาดหวัง รหัสข้อผิดพลาด และความหมายของคะแนนความมั่นใจ
รวมแผนที่ชัดเจน ("ฟิลด์ผู้ให้บริการ → ฟิลด์มาตรฐานของคุณ") พร้อมกฎสำหรับค่าว่างและค่าขัดแย้ง
แผนสำรองและการตัดสินใจเก็บข้อมูล
วางแผนว่าทำอย่างไรเมื่อแหล่งไม่พร้อมหรือส่งผลความมั่นใจต่ำ: รีไทรพร้อม backoff, คิวไว้ภายหลัง, หรือใช้แหล่งสำรอง
ตัดสินใจว่าอะไร เก็บ (แอตทริบิวต์คงที่ที่ต้องใช้ค้นหา/รายงาน) กับอะไร คำนวณตามต้องการ (การดึงข้อมูลที่แพงหรืออ่อนไหว)
สุดท้าย บันทึกข้อจำกัดการเก็บข้อมูลอ่อนไหว (เช่น ตัวระบุส่วนบุคคล ข้อมูลอนุมาน) และตั้งกฎการเก็บรักษาตามนั้น
ออกแบบสถาปัตยกรรมระดับสูง
ก่อนเลือกเครื่องมือ ตัดสินใจว่ารูปร่างของแอปเป็นอย่างไร สถาปัตยกรรมระดับสูงที่ชัดเจนทำให้การทำงานเสริมข้อมูลคาดเดาได้ ป้องกัน "แก้ขัดชั่วคราว" กลายเป็นความยุ่งเหยิงถาวร และช่วยทีมประเมินความพยายาม
เลือกรูปแบบสถาปัตยกรรมที่เหมาะกับทีม
สำหรับหลายทีม ให้เริ่มด้วย โมดูลาร์โมโนลิธ: แอปหนึ่งที่ดีพลอย แต่แบ่งภายในเป็นโมดูลชัดเจน (ingestion, matching, enrichment, UI) ง่ายต่อการสร้าง ทดสอบ และดีบัก
ย้ายไปสู่ บริการแยก เมื่อมีเหตุผลชัดเจน—เช่น ปริมาณการเสริมสูง ต้องสเกลแยก หรือทีมต่างกันดูแลส่วนต่าง ๆ การแยกที่พบบ่อยคือ:
- API service (คำขอ sync, auth, CRUD ระเบียน)
- Worker service (การเสริมแบบ async, รีไทร)
- UI (ทบทวน อนุมัติ การทำงานเป็นกลุ่ม)
แยกขอบเขตเป็นเลเยอร์
เก็บขอบเขตชัดเจนเพื่อการเปลี่ยนแปลงไม่กระทบกันทั่วทั้งระบบ:
- เลเยอร์การนำเข้า: นำเข้าจาก CRM/ไฟล์ และทำให้เป็นมาตรฐาน
- เลเยอร์การเสริม: เรียกผู้ให้บริการ/แหล่งภายในและเก็บผล
- เลเยอร์การตรวจสอบ: ใช้กฎคุณภาพข้อมูลและทำเครื่องหมายข้อยกเว้น
- เลเยอร์เก็บข้อมูล: โปรไฟล์ลูกค้า payload ดิบ ประวัติการตรวจสอบ
- เลเยอร์การนำเสนอ: มุมมอง UI คิวทบทวน การอนุมัติ
ออกแบบให้รองรับการเสริมแบบอะซิงค์ตั้งแต่วันแรก
การเสริมช้าและล้มเหลวง่าย (ขีดจำกัดอัตรา ไทม์เอาต์ ข้อมูลบางส่วน) จัดการการเสริมเป็น งาน (jobs):
- API สร้างงานและตอบกลับอย่างรวดเร็ว
- Workers ประมวลผลงานผ่าน คิว (มีรีไทรและ backoff)
- UI แสดงสถานะงานและให้รันซ้ำเมื่อจำเป็น
วางสภาพแวดล้อมและการตั้งค่า
ตั้ง dev/staging/prod ตั้งแต่ต้น เก็บคีย์ผู้ให้บริการ เกณฑ์ และฟีเจอร์แฟลกในการตั้งค่า (ไม่ใช่โค้ด) และทำให้เปลี่ยนผู้ให้บริการได้ง่ายตามสภาพแวดล้อม
จัดทำไดอะแกรมหน้าเดียวให้เข้าใจเร็ว
ร่างไดอะแกรมง่าย ๆ แสดง: UI → API → ฐานข้อมูล, plus queue → workers → ผู้ให้บริการเสริม ใช้ไดอะแกรมนี้ในการตรวจสอบเพื่อให้ทุกคนเห็นด้วยก่อนลงมือ
การสร้างต้นแบบเส้นทางด่วน (ไม่บังคับ)
ถ้าจุดประสงค์คือยืนยันเวิร์กโฟลว์และหน้าทบทวนก่อนลงทุนมาก แพลตฟอร์มโค้ดแบบไว (เช่น Koder.ai) ช่วยสร้างต้นแบบแอปหลักได้เร็ว: UI React สำหรับทบทวน/อนุมัติ ชั้น API เป็น Go และเก็บด้วย PostgreSQL
สิ่งนี้มีประโยชน์เมื่อต้องพิสูจน์โมเดลงาน (การเสริมแบบอะซิงค์พร้อมรีไทร) ประวัติการตรวจสอบ และรูปแบบการเข้าถึงตามบทบาท แล้วค่อยส่งออกซอร์สโค้ดเมื่อพร้อมผลิตจริง
ตั้งค่าที่เก็บ ข้อความคิว และบริการสนับสนุน
ก่อนเชื่อมต่อผู้ให้บริการเสริม ให้จัด "ท่อ" ให้ถูกต้อง การตัดสินใจด้านที่เก็บและการประมวลผลพื้นหลังเปลี่ยนยากต่อไป และส่งผลต่อความน่าเชื่อถือ ค่าใช้จ่าย และความสามารถในการตรวจสอบ
ฐานข้อมูลหลัก: โปรไฟล์ + ประวัติ
เลือกฐานข้อมูลหลักสำหรับโปรไฟล์ลูกค้าที่รองรับข้อมูลเชิงโครงสร้างและแอตทริบิวต์ยืดหยุ่น Postgres เป็นตัวเลือกทั่วไปเพราะเก็บฟิลด์หลัก (ชื่อ โดเมน อุตสาหกรรม) พร้อมกับฟิลด์ enrichment แบบกึ่งโครงสร้าง (JSON)
สิ่งสำคัญไม่แพ้กัน: เก็บประวัติการเปลี่ยนแปลง แทนที่จะเขียนทับค่าอย่างเงียบ ๆ ให้จับว่าใคร/อะไรเปลี่ยนฟิลด์ เมื่อไหร่ และทำไม (เช่น "vendor_refresh", "manual_approval") ซึ่งช่วยให้ง่ายต่อการอนุมัติและปลอดภัยเมื่อต้อง rollback
คิว: การเสริมและการรีไทร
การเสริมเป็นงานแบบอะซิงค์: API บังคับจำกัดอัตรา เครือข่ายล้ม และผู้ให้บริการบางรายตอบช้า เพิ่มคิวงานสำหรับงานพื้นหลัง:
- คำขอเสริม (ทีละระเบียนและเป็นกลุ่ม)
- รีไทรพร้อม backoff
- การรีเฟรชตามตาราง (เช่น ทุก 30/90 วัน)
- การจัดการ dead-letter สำหรับงานที่ล้มซ้ำ
สิ่งนี้ทำให้ UI ตอบสนองได้และป้องกันปัญหาผู้ให้บริการทำให้แอปล่ม
แคช: ค้นหาเร็วและติดตามขีดจำกัดอัตรา
แคชเล็ก ๆ (เช่น Redis) ช่วยค้นหาบ่อย ๆ (เช่น "บริษัทโดยโดเมน") และติดตามขีดจำกัดอัตราผู้ให้บริการและหน้าต่างคูลดาวน์ ใช้เพื่อคีย์ idempotency เพื่อป้องกันการเสริมซ้ำเมื่อมีการนำเข้าซ้ำ
การเก็บไฟล์และการกำหนดอายุ
วางแผนที่เก็บวัตถุสำหรับการนำเข้า/ส่งออก CSV รายงานข้อผิดพลาด และไฟล์ diff ที่ใช้ในฟลอว์การทบทวน
กำหนดกฎการเก็บรักษาตั้งแต่ต้น: เก็บ payload ดิบผู้ให้บริการเฉพาะเท่าที่จำเป็นสำหรับดีบักและการตรวจสอบ แล้วลบ/หมดอายุบันทึกตามนโยบายความเป็นส่วนตัว
สร้างท่อการนำเข้าและการทำให้เป็นมาตรฐาน
ชดเชยต้นทุนการสร้าง
ลดต้นทุนการพัฒนาโดยรับเครดิตจากการแชร์สิ่งที่คุณสร้างกับ Koder.ai หรือเชิญเพื่อนร่วมทีม
แอปการเสริมของคุณดีแค่ไหนขึ้นอยู่กับข้อมูลที่ป้อนเข้า การนำเข้าเป็นจุดที่คุณตัดสินใจว่าข้อมูลอย่างไรเข้าระบบ และ normalization คือจุดที่ทำให้ข้อมูลสม่ำเสมอพอจะจับคู่ เสริม และรายงาน
ตัดสินใจว่าข้อมูลเข้ามาอย่างไร
ทีมส่วนใหญ่ต้องการทางเข้าแบบผสม:
- API endpoints สำหรับผลิตภัณฑ์หรือเครื่องมือภายในที่ส่งลูกค้าใหม่/อัปเดต
- Webhooks จาก CRM หรือระบบเรียกเก็บเงินสำหรับการเปลี่ยนแปลงใกล้เรียลไทม์
- การดึงตามตาราง (sync รายวัน) สำหรับระบบที่ไม่รองรับ push
- การนำเข้า CSV สำหรับ backfill และการอัปโหลดครั้งเดียว
ไม่ว่าจะรองรับอะไร ให้เก็บขั้นตอน "raw ingest" ให้เบา: รับข้อมูล ยืนยันตัวตน บันทึกเมตาดาต้า และส่งงานไปเข้าคิวเพื่อประมวลผล
ทำให้เป็นมาตรฐานและทำความสะอาดแต่เนิ่น ๆ
สร้างเลเยอร์ normalization ที่เปลี่ยนอินพุตยุ่งเหยิงเป็นรูปแบบภายในที่สม่ำเสมอ:
- ชื่อ: ตัดช่องว่าง แยกชื่อเต็มเมื่อเป็นไปได้ จัดการเคสตัวอักษร
- โทรศัพท์: แปลงเป็นรูปแบบ E.164 และเก็บสมมติฐานประเทศอย่างชัดเจน
- ที่อยู่: มาตรฐานฟิลด์ (ถนน เมือง ภูมิภาค รหัสไปรษณีย์) และเก็บข้อความเดิมไว้
- โดเมน/อีเมล: ทำให้เป็นตัวพิมพ์เล็ก ลบพารามิเตอร์ติดตามจาก URL ตรวจสอบไวยากรณ์
ตรวจสอบ กักเก็บ และรักษา idempotency
กำหนดฟิลด์ที่จำเป็นต่อแต่ละประเภทระเบียน และ ปฏิเสธหรือกักเก็บ ระเบียนที่ล้มเหลว (เช่น ขาดอีเมล/โดเมนสำหรับการจับคู่บริษัท) รายการกักเก็บควรดูได้และแก้ไขได้ใน UI
เพิ่ม idempotency keys เพื่อป้องกันการประมวลผลซ้ำเมื่อมีการรีไทร (พบได้บ่อยกับ webhooks และเครือข่ายไม่เสถียร) แนวทางง่าย ๆ คือแฮช (source_system, external_id, event_type, event_timestamp)
ติดตามแหล่งที่มาของแต่ละฟิลด์
เก็บแหล่งที่มาสำหรับแต่ละระเบียนและถ้าเป็นไปได้สำหรับแต่ละฟิลด์: แหล่งที่มา, เวลา ingest, และ รุ่นการแปลง ทำให้คำถามในภายหลังตอบได้ง่าย: "ทำไมหมายเลขโทรศัพท์นี้เปลี่ยน?" และ "การนำเข้าไหนทำให้เกิดค่านี้?"
ดำเนินการจับคู่ การลบข้อมูลซ้ำ และการรวม
การเสริมข้อมูลสำเร็จขึ้นอยู่กับการระบุตัวตนอย่างเชื่อถือได้ แอปของคุณต้องมีกฎจับคู่ที่ชัดเจน พฤติกรรมการรวมที่คาดเดาได้ และเครือข่ายความปลอดภัยเมื่อระบบไม่แน่ใจ
กำหนดกฎจับคู่ (และเกณฑ์ความมั่นใจ)
เริ่มจากตัวระบุเชิงกำหนด:
- คีย์ตรง: อีเมล (ทำให้เป็นพิมพ์เล็ก) รหัสลูกค้า หมายเลขภาษี/ VAT หรื่อโดเมนที่ยืนยันแล้ว
จากนั้นเพิ่มการจับคู่เชิงความน่าจะเป็นในกรณีที่คีย์ตรงหายไป:
- จับคู่แบบฟัซซี: ชื่อ + โดเมนบริษัท, ชื่อ + สถานที่, ความคล้ายของโทรศัพท์
ให้คะแนน match score และตั้งเกณฑ์ เช่น:
- Auto-merge เฉพาะเมื่อคะแนนสูงมาก
- เข้าสู่คิวตรวจสอบด้วยตนเอง ในช่วง "อาจใช่"
- ปฏิเสธ ต่ำกว่าช่วงล่าง
วางแผนตรรกะการลบข้อมูลซ้ำและการรวม
เมื่อสองระเบียนเป็นคนเดียวกัน ให้ตัดสินใจว่าฟิลด์จะถูกเลือกอย่างไร:
- ลำดับความสำคัญฟิลด์: "อีเมลที่ยืนยันชนะอีเมลที่ยังไม่ยืนยัน", "เวลาใหม่กว่าชนะ", "CRM อยู่เหนือ enrichment สำหรับเจ้าของติดต่อ"
- คะแนนความเชื่อถือของแหล่ง: จัดอันดับแหล่ง (CRM, เรียกเก็บเงิน, ผู้ให้บริการเสริม) เพื่อแก้ความขัดแย้ง
- การจัดการความขัดแย้ง: เก็บค่าทั้งสองถ้าเป็นไปได้ (เช่น หมายเลขโทรศัพท์หลายหมายเลข) หรือนำค่าที่แพ้เก็บไว้ในประวัติ
ประวัติการตรวจสอบและเวิร์กโฟลว์ทบทวน
การรวมทุกครั้งควรสร้าง เหตุการณ์ audit: ใคร/อะไรเป็นผู้ทำ ท่าก่อน/หลัง ค่าเดิม/ใหม่ คะแนนจับคู่ และ ID ระเบียนที่เกี่ยวข้อง
สำหรับการจับคูที่ไม่ชัดเจน ให้มีหน้าจอทบทวนแบบเปรียบเทียบและตัวเลือก "รวม / ไม่รวม / ขอข้อมูลเพิ่ม"
มาตรการป้องกันการรวมจำนวนมากโดยไม่ได้ตั้งใจ
ต้องการการยืนยันพิเศษสำหรับการรวมจำนวนมาก จำกัดการรวมต่อหนึ่งงาน และรองรับการพรีวิวแบบ "dry run"
เพิ่มทางย้อนกลับ (undo) หรือการย้อนรวมโดยใช้ประวัติการตรวจสอบเพื่อให้ข้อผิดพลาดไม่ถาวร
รวม API การเสริมและจัดการความน่าเชื่อถือ
การเสริมคือจุดที่แอปของคุณพบโลกภายนอก—ผู้ให้บริการหลายราย การตอบกลับไม่สอดคล้อง และความพร้อมใช้งานที่คาดเดาไม่ได้ ปฏิบัติต่อแต่ละผู้ให้บริการเป็นตัวเชื่อมต่อแบบปลั๊กอินเพื่อเพิ่ม เปลี่ยน หรือปิดแหล่งได้โดยไม่กระทบท่อที่เหลือ
สร้างคอนเนคเตอร์ผู้ให้บริการ (auth, retry, mapping ข้อผิดพลาด)
สร้างคอนเนคเตอร์ต่อผู้ให้บริการหนึ่งตัวโดยมีอินเทอร์เฟซสม่ำเสมอ (เช่น enrichPerson(), enrichCompany()) เก็บตรรกะเฉพาะผู้ให้บริการไว้ในคอนเนคเตอร์:
- การตรวจสอบสิทธิ์ (API keys, OAuth tokens, การรีเฟรชโทเคน)
- รีไทรแบบมาตรฐานสำหรับความผิดพลาดชั่วคราว
- การแมปข้อผิดพลาด (แปลงข้อผิดพลาดผู้ให้บริการเป็นหมวดของคุณ เช่น
invalid_request,not_found,rate_limited,provider_down)
สิ่งนี้ทำให้เวิร์กโฟลว์ด้านล่างจัดการกับประเภทข้อผิดพลาดของคุณ ไม่ใช่ quirks ของแต่ละผู้ให้บริการ
จัดการขีดจำกัดอัตราด้วยการควบคุมความถี่และ backoff
API ส่วนใหญ่มีโควต้า เพิ่มการ throttle แยกตามผู้ให้บริการ (และบางครั้งแยกตาม endpoint) เพื่อไม่ให้เกินขีดจำกัด
เมื่อชนขีดจำกัด ใช้ exponential backoff พร้อม jitter และเคารพ header Retry-After
วางแผนสำหรับ "ความล้มเหลวช้า" ด้วย: ไทม์เอาต์และการตอบกลับบางส่วนควรถูกบันทึกเป็นเหตุการณ์ที่รีไทรได้ ไม่ใช่การหายไปอย่างเงียบ ๆ
เก็บคะแนนความมั่นใจและหลักฐาน (ภายในนโยบาย)
ผลการเสริมไม่แน่นอนเสมอไป เก็บคะแนนความมั่นใจจากผู้ให้บริการเมื่อมี และคะแนนของคุณเองจากคุณภาพการจับคู่และความสมบูรณ์ของฟิลด์
เมื่อสัญญาและนโยบายความเป็นส่วนตัวอนุญาต เก็บหลักฐานดิบ (URL แหล่งที่มา ตัวระบุ เวลา) เพื่อสนับสนุนการตรวจสอบและความไว้วางใจของผู้ใช้
กลยุทธ์หลายผู้ให้บริการ: เลือก "ดีที่สุดที่หาได้"
รองรับหลายผู้ให้บริการโดยกำหนดกฎการเลือก: ถูกสุดก่อน, ความมั่นใจสูงสุดก่อน, หรือเลือกฟิลด์ต่อฟิลด์ตาม "ดีที่สุดที่มี"
บันทึกว่าผู้ให้บริการใดให้แอตทริบิวต์แต่ละตัวเพื่ออธิบายการเปลี่ยนแปลงและย้อนกลับหากจำเป็น
กฎการรีเฟรชตามตาราง
ข้อมูลเสริมล้าสมัย กำหนดนโยบายรีเฟรชเช่น "re-enrich ทุก 90 วัน", "รีเฟรชเมื่อฟิลด์สำคัญเปลี่ยน", หรือ "รีเฟรชเมื่อคะแนนความมั่นใจตก"
ทำให้ตารางปรับได้ตามลูกค้าและประเภทข้อมูลเพื่อตัดต้นทุนและการแจ้งเตือนที่เกินจำเป็น
เพิ่มกฎคุณภาพข้อมูลและการตรวจสอบ
จับคู่ระดับกับขอบเขต
เริ่มจากฟรี แล้วขยับเป็น Pro, Business หรือ Enterprise เมื่อการใช้งานเติบโต
การเสริมมีประโยชน์เมื่อค่าที่ได้ไว้ใจได้ ให้การตรวจสอบเป็นฟีเจอร์หลัก: ช่วยปกป้องผู้ใช้จากการนำเข้าเละ การตอบจากผู้ให้บริการที่ไม่น่าเชื่อถือ และการทำลายข้อมูลระหว่างการรวม
กำหนดกฎการตรวจสอบระดับฟิลด์
เริ่มด้วย "แคตตาล็อกกฎ" ต่อฟิลด์ ใช้ร่วมกับฟอร์ม UI ท่อการนำเข้า และ API สาธารณะ
กฎทั่วไปรวมการตรวจสอบรูปแบบ (อีเมล โทร รหัสไปรษณีย์), ค่าที่อนุญาต (รหัสประเทศ รายชื่ออุตสาหกรรม), ช่วงค่า (จำนวนพนักงาน ช่วงรายได้), และการพึ่งพา (ถ้า country = US ให้ state เป็นฟิลด์จำเป็น)
เก็บกฎเป็นรุ่นเพื่อเปลี่ยนแปลงอย่างปลอดภัยเมื่อเวลาเปลี่ยน
เพิ่มการตรวจสอบคุณภาพที่สะท้อนการใช้งานจริง
นอกเหนือการตรวจสอบพื้นฐาน ให้รันเช็คลึกที่ตอบคำถามทางธุรกิจ:
- ความสมบูรณ์: เรามีฟิลด์ขั้นต่ำพอใช้งานหรือไม่?
- ความเป็นเอกลักษณ์: ตัวระบุที่ควรเป็นเอกลักษณ์ (โดเมน หมายเลขภาษี) ถูกซ้ำหรือไม่?
- ความสอดคล้อง: ฟิลด์ที่เกี่ยวข้องสอดคล้องกันหรือไม่ (ประเทศ vs รหัสโทรศัพท์)?
- ความทันสมัย: ค่านี้เก่าแค่ไหน ควรรีเฟรชหรือไม่?
ให้คะแนนระเบียนและแหล่งที่มา
เปลี่ยนเช็ครายการเป็นสกอร์การ์ด: ต่อระเบียน (สุขภาพโดยรวม) และต่อแหล่ง (ให้ค่าที่ถูกต้องและทันสมัยบ่อยแค่ไหน)
ใช้สกอร์นี้ชี้นำการออโตเมต เช่น อนุญาตให้เขียนทับอัตโนมัติเฉพาะการเสริมที่คะแนนสูงกว่าที่กำหนด
ส่งข้อผิดพลาดไปที่กำหนดไว้อย่างชัดเจน
เมื่อระเบียนล้มเหลวในการตรวจสอบ อย่าทิ้งมัน
ส่งไปยังคิว "data-quality" เพื่อรีไทร (ปัญหาชั่วคราว) หรือส่งทบทวนด้วยมือ (ข้อมูลไม่ดี) เก็บ payload ล้มเหลว ข้อผิดพลาดของกฎ และข้อเสนอแนะการแก้ไข
ทำให้ข้อผิดพลาดอ่านเข้าใจได้
คืนข้อความชัดเจนที่ทำได้จริงสำหรับการนำเข้าและไคลเอนต์ API: ฟิลด์ไหนล้มเหลว ทำไม และตัวอย่างค่าที่ถูกต้อง
สิ่งนี้ลดภาระซัพพอร์ตและเร่งการทำความสะอาด
สร้าง UI สำหรับการทบทวน อนุมัติ และงานเป็นกลุ่ม
ท่อการเสริมของคุณจะให้คุณค่าก็ต่อเมื่อคนสามารถทบทวนการเปลี่ยนแปลงและผลักอัปเดตเข้าไปยังระบบปลายทางอย่างมั่นใจ UI ควรทำให้ชัดเจนว่า "เกิดอะไรขึ้น ทำไม และฉันควรทำอะไรต่อ"
หน้าจอหลักที่ต้องออกแบบ
โปรไฟล์ลูกค้า คือฐานบ้าน แสดงตัวระบุสำคัญ (อีเมล โดเมน ชื่อบริษัท) ค่าฟิลด์ปัจจุบัน และป้ายสถานะการเสริม (เช่น ยังไม่เสริม, กำลังดำเนินการ, ต้องทบทวน, อนุมัติ, ปฏิเสธ)
เพิ่ม ไทม์ไลน์การเปลี่ยนแปลง ที่อธิบายการอัปเดตเป็นภาษาธรรมดา: "ขนาดบริษัทอัปเดตจาก 11–50 เป็น 51–200" ให้แต่ละรายการคลิกดูรายละเอียดได้
เสนอ คำแนะนำการรวม เมื่อพบข้อมูลซ้ำ แสดงระเบียนที่เป็นคู่แข่งแบบเคียงข้างกับระเบียนที่แนะนำเป็น "survivor" พร้อมพรีวิวผลลัพธ์การรวม
งานเป็นกลุ่มที่ตรงกับการปฏิบัติงานจริง
ทีมส่วนใหญ่ทำงานเป็นชุด รวมการกระทำแบบกลุ่ม เช่น:
- เสริมระเบียนที่เลือก (หรือส่งคิวให้ประมวลผลตอนกลางคืน)
- อนุมัติ/ปฏิเสธการรวมที่แนะนำ
- ส่งออกผล (CSV) สำหรับตรวจสอบหรือทบทวนออฟไลน์
ใช้ขั้นตอนยืนยันชัดเจนสำหรับการกระทำทำลายล้าง (รวม ทับ) พร้อมหน้าต่าง "undo" ถ้าเป็นไปได้
ค้นหาเร็ว ตัวกรอง และแหล่งที่มาของแต่ละฟิลด์
เพิ่มการค้นหาแบบรวมและตัวกรองตาม อีเมล โดเมน บริษัท สถานะ และคะแนนคุณภาพ
ให้ผู้ใช้บันทึกมุมมอง เช่น "ต้องทบทวน" หรือ "การอัปเดตความมั่นใจต่ำ"
สำหรับทุกฟิลด์ที่เสริม ให้แสดง แหล่งที่มา: ผู้ให้บริการ เวลา และความมั่นใจ
แผง "ทำไมค่านี้" แบบง่ายช่วยสร้างความไว้วางใจและลดการคุยกลับไปมา
เวิร์กโฟลว์แนะนำสำหรับผู้ใช้ที่ไม่เชี่ยวชาญ
ทำให้การตัดสินใจเป็นแบบไบนารีและแนะนำ: "รับค่าที่แนะนำ", "เก็บของเดิม", หรือ "แก้ไขด้วยมือ" ถ้าต้องการการควบคุมลึก ให้ซ่อนไว้ภายใต้โหมด "ขั้นสูง"
พื้นฐานด้านความปลอดภัย ความเป็นส่วนตัว และการปฏิบัติตาม
วนพัฒนาโดยไม่ต้องกลัว
ใช้ snapshot และ rollback เพื่อปรับกฎการจับคู่และลำดับการรวมอย่างปลอดภัยเมื่อเรียนรู้
แอปการเสริมข้อมูลเกี่ยวข้องกับตัวระบุที่อ่อนไหว (อีเมล โทรศัพท์ รายละเอียดบริษัท) และมักดึงข้อมูลจากบุคคลที่สาม ถือความปลอดภัยและความเป็นส่วนตัวเป็นฟีเจอร์หลัก ไม่ใช่งานที่ทำทีหลัง
การควบคุมการเข้าถึงตามบทบาท (RBAC)
เริ่มจากบทบาทชัดเจนและค่าเริ่มต้นแบบ least-privilege:
- Admin: จัดการผู้ใช้ บทบาท คอนเนคเตอร์ นโยบายการเก็บรักษา
- Ops: รันงานเสริม แก้ไขข้อขัดแย้ง อนุมัติการรวม
- Viewer: อ่านอย่างเดียวสำหรับรายงานและซัพพอร์ต
เก็บสิทธิ์ให้ละเอียด (เช่น "ส่งออกข้อมูล", "ดู PII", "อนุมัติการรวม") และแยกสภาพแวดล้อมเพื่อให้ข้อมูลผลิตไม่อยู่ใน dev
ปกป้องข้อมูลอ่อนไหว
ใช้ TLS สำหรับการรับส่งทั้งหมด และ การเข้ารหัสเมื่อเก็บ สำหรับฐานข้อมูลและที่เก็บวัตถุ
เก็บคีย์ API ในตัวจัดการความลับ (ไม่ใช่ไฟล์ env ใน source control) หมุนคีย์เป็นประจำ และจำกัดสโคปคีย์ตามสภาพแวดล้อม
ถ้าแสดง PII ใน UI ให้ตั้งค่าเริ่มต้นที่ปลอดภัย เช่น มาร์กข้อมูลบางส่วน (เช่น เหลือเฉพาะ 2–4 หลักสุดท้าย) และต้องมีสิทธิพิเศษเพื่อเปิดดูทั้งหมด
ความยินยอมและข้อจำกัดการใช้งานข้อมูล
ถ้าการเสริมขึ้นกับความยินยอมหรือข้อกำหนดตามสัญญา ให้เข้ารหัสข้อจำกัดเหล่านั้นในเวิร์กโฟลว์:
- ติดตาม แหล่งข้อมูล, วัตถุประสงค์, และ การใช้งานที่อนุญาต ต่อฟิลด์
- บันทึกสิ่งที่เก็บและเหตุผล (หน้าภายในสั้น ๆ เช่น /privacy หรือ /docs/data-handling ช่วยได้)
- หลีกเลี่ยงการรวบรวมฟิลด์ที่ไม่จำเป็น—ข้อมูลน้อยลงช่วยลดความเสี่ยง
การตรวจสอบ เก็บรักษา และการลบ
สร้างประวัติการตรวจสอบสำหรับทั้งการเข้าถึงและการเปลี่ยนแปลง:
- บันทึก ใครดู/ส่งออก ระเบียน
- บันทึก ใครเปลี่ยนอะไรและเมื่อไร (ค่าก่อน/หลัง, job ID, ผู้ให้บริการ)
สุดท้าย รองรับคำขอความเป็นส่วนตัวด้วยเครื่องมือปฏิบัติการ: กำหนดตารางเก็บรักษา การลบระเบียน และเวิร์กโฟลว์ "ลืมฉัน" ที่ลบสำเนาในล็อก แคช และแบ็กอัพเมื่อเป็นไปได้ (หรือทำเครื่องหมายหมดอายุ)
การเฝ้าติดตาม วิเคราะห์ และการควบคุมการปฏิบัติการ
การเฝ้าติดตามไม่ใช่แค่เรื่อง uptime—มันคือวิธีรักษาความไว้วางใจในกระบวนการเสริมเมื่อปริมาณ ผู้ให้บริการ และกฎเปลี่ยนไป
ปฏิบัติให้การรันเสริมแต่ละครั้งเป็นงานที่วัดได้พร้อมสัญญาณชัดเจนเพื่อติดตามตามเวลา
เมตริกที่ช่วยได้จริง
เริ่มจากชุดเมตริกปฏิบัติการเล็ก ๆ ที่ผูกกับผลลัพธ์:
- Job throughput (เรคคอร์ด/นาที) และ time-to-complete ต่อการรัน
- อัตราความสำเร็จ vs อัตราความล้มเหลว, แยกตามประเภทความล้มเหลว (validation, matching, provider)
- latency ของผู้ให้บริการ (p50/p95) และไทม์เอาต์ต่อแหล่ง
- อัตราการจับคู่ (ความถี่ที่แนบการเสริมได้อย่างมั่นใจ)
- การป้องกันการซ้ำ (จำนวนรายการที่จะรวมผิดพลาดถ้าไม่มีการตรวจสอบ)
ตัวเลขเหล่านี้ตอบได้เร็วว่า: "เรากำลังปรับปรุงข้อมูลจริงหรือแค่ย้ายไปมา?"
แจ้งเตือนและเกราะป้องกัน
เพิ่มการแจ้งเตือนที่เกิดจากการเปลี่ยนแปลง ไม่ใช่จากเสียงรบกวน:
- พุ่งขึ้นของความล้มเหลวหรือรายการกักเก็บ
- คิวสะสมหรือตัวประมวลผลช้า (สัญญาณท่อค้าง)
- ผู้ให้บริการตอบผิดพังบ่อย (429/5xx), latency สูงขึ้น หรือไทม์เอาต์เพิ่มขึ้น
ผูกแจ้งเตือนไปยังการกระทำที่จับต้องได้ เช่น หยุดผู้ให้บริการ ลด concurrency หรือสลับไปใช้ข้อมูลแคช/เก่าชั่วคราว
แดชบอร์ดผู้ดูแลสำหรับปฏิบัติการ
จัดมุมมองผู้ดูแลสำหรับการรันล่าสุด: สถานะ จำนวน รีไทร และรายการ ระเบียนกักเก็บ พร้อมเหตุผล
รวมการควบคุม "replay" และการกระทำแบบกลุ่มที่ปลอดภัย (รีไทร provider timeouts ทั้งหมด, รัน matching ใหม่)
การติดตามด้วยล็อก
ใช้ structured logs และ correlation ID ที่ตามหนึ่งระเบียนตลอดเส้นทาง (ingestion → match → enrichment → merge)
สิ่งนี้ทำให้ซัพพอร์ตลูกค้าและดีบักเหตุการณ์ได้เร็วขึ้นมาก
แผนปฏิบัติการเหตุการณ์และการย้อนกลับ
เขียน playbook สั้น ๆ: ต้องทำอะไรเมื่อผู้ให้บริการเสื่อม คุณภาพการจับคู่พัง หรือข้อมูลซ้ำรั่วไหล
เก็บตัวเลือกย้อนกลับ (เช่น ย้อนรวมภายในหน้าต่างเวลา) และบันทึกไว้ใน /runbooks
ทดสอบ การเปิดตัว และแผนการวนปรับปรุง
การทดสอบและการเปิดตัวคือจุดที่แอปการเสริมกลายเป็นสิ่งที่วางใจได้ เป้าหมายไม่ใช่ "ทดสอบมากขึ้น" แต่เป็นความมั่นใจว่ากฎการจับคู่ การรวม และการตรวจสอบทำงานคาดเดาได้กับข้อมูลโลกจริงที่มีความยุ่งเหยิง
ทดสอบส่วนที่เสี่ยงก่อน
ให้ลำดับความสำคัญการทดสอบตรรกะที่จะทำร้ายระเบียนอย่างเงียบ ๆ:
- กฎการจับคู่: ทดสอบหน่วยสำหรับการจับคู่แบบตรง แบบฟัซซี และแบบผสม (เช่น อีเมล + โดเมนบริษัท). รวมกรณีใกล้เคียงและการสลับฟิลด์
- ผลลัพธ์การรวม: ทดสอบลำดับความสำคัญฟิลด์ (ความสำคัญแหล่ง), การจัดการความขัดแย้ง, และกฎ "ห้ามเขียนทับ"
- ขอบเขตการตรวจสอบ: อีเมลเสีย รูปแบบโทรศัพท์ระหว่างประเทศ ขาดประเทศ ตัวระบุซ้ำ และค่าที่ "ไม่รู้"
ใช้ชุดข้อมูลสังเคราะห์ (ชื่อ โดเมน ที่อยู่ที่สร้างขึ้น) เพื่อทดสอบความแม่นยำโดยไม่ใช้ข้อมูลจริงของลูกค้า
เก็บชุด "golden" เวอร์ชันที่คาดหวังผลการจับคู่/รวมไว้เป็นรุ่นเพื่อให้การถดถอยชัดเจน
เปิดตัวเป็นขั้นเพื่อลดผลกระทบ
เริ่มเล็กแล้วขยาย:
- Pilot scope: หนึ่งทีมหรือหนึ่งเซ็กเมนต์ (เช่น leads SMB เท่านั้น)
- การกระทำจำกัด: เริ่มด้วย "ข้อเสนอการอัปเดต" ที่ต้องได้รับอนุมัติก่อนเขียนกลับไปยัง CRM
- ไต่ระดับ: ขยายปริมาณระเบียน แล้วเปิดการเขียนอัตโนมัติสำหรับฟิลด์ความเสี่ยงต่ำ
กำหนดเมตริกความสำเร็จก่อนเริ่ม (ความแม่นยำการจับคู่ อัตราการอนุมัติ การลดการแก้ไขด้วยมือ และเวลาในการเสริม)
เอกสารเวิร์กโฟลว์และเช็คลิสต์การเชื่อมต่อ
สร้างเอกสารสั้นสำหรับผู้ใช้และผู้เชื่อมต่อ (ลิงก์จากพื้นที่ผลิตภัณฑ์ของคุณหรือ /pricing ถ้าคุณล็อกฟีเจอร์) รวมเช็คลิสต์การเชื่อมต่อ:
- วิธี auth API, ขีดจำกัดอัตรา และพฤติกรรมรีไทร
- ฟิลด์ที่จำเป็นสำหรับคำขอการเสริม
- payload ของ webhook/event (และการทำรุ่น)
- รหัสข้อผิดพลาดและกฎ "การเสริมบางส่วน"
- ความคาดหวังประวัติการตรวจสอบและการเก็บรักษา
เพื่อการปรับปรุงต่อเนื่อง นัดการทบทวนเบา ๆ: วิเคราะห์การตรวจสอบที่ล้มเหลว การแทนที่ด้วยมือบ่อย และการจับคู่ที่ผิด จากนั้นปรับกฎและเพิ่มการทดสอบ
การอ้างอิงปฏิบัติ: /blog/data-quality-checklist.
สร้างเอง vs เร่งความเร็ว: หมายเหตุเชิงปฏิบัติ
ถ้าคุณรู้เวิร์กโฟลว์เป้าหมายแล้วแต่ต้องการลดเวลาจากสเปค→แอปที่ใช้งานได้ ให้พิจารณาใช้ Koder.ai เพื่อสร้างการใช้งานเริ่มต้น (UI React, บริการ Go, ที่เก็บ PostgreSQL) จากแผนแบบแชทที่มีโครงสร้าง
ทีมมักใช้วิธีนี้เพื่อตั้งหน้าจอทบทวน การประมวลผลงาน และประวัติการตรวจสอบอย่างรวดเร็ว—แล้ววนปรับด้วยโหมดการวางแผน snapshots และ rollback เมื่อความต้องการเปลี่ยน เมื่อคุณต้องการการควบคุมเต็มที่ คุณสามารถส่งออกซอร์สโค้ดและต่อยอดในพายป์ไลน์เดิมของคุณได้ Koder.ai มีระดับฟรี, pro, business และ enterprise เพื่อให้คุณเลือกตามการทดลองหรือการใช้งานจริง