09 เม.ย. 2568·4 นาที
วิธีสร้างเว็บแอปเพื่อติดตามการนำฟีเจอร์ไปใช้และพฤติกรรมผู้ใช้
คู่มือปฏิบัติสำหรับสร้างเว็บแอปที่ติดตามการนำฟีเจอร์ไปใช้และพฤติกรรมผู้ใช้ ตั้งแต่การออกแบบเหตุการณ์ไปจนถึงแดชบอร์ด ความเป็นส่วนตัว และการโรลเอาต์
คู่มือปฏิบัติสำหรับสร้างเว็บแอปที่ติดตามการนำฟีเจอร์ไปใช้และพฤติกรรมผู้ใช้ ตั้งแต่การออกแบบเหตุการณ์ไปจนถึงแดชบอร์ด ความเป็นส่วนตัว และการโรลเอาต์
ก่อนจะเริ่มติดตามอะไร ให้ตัดสินใจก่อนว่า “การนำฟีเจอร์ไปใช้” หมายถึงอะไรสำหรับ ผลิตภัณฑ์ของคุณ ถ้าข้ามขั้นตอนนี้ คุณจะเก็บข้อมูลมากมาย—แล้วก็ยังต้องถกเถียงกันในการประชุมว่ามัน “หมายความว่า” อะไร
การนำไปใช้โดยทั่วไปไม่ใช่เหตุการณ์เดียว เลือกหนึ่งหรือหลายคำนิยามที่สอดคล้องกับวิธีที่คุณมอบคุณค่า:
ตัวอย่าง: สำหรับ “Saved Searches” การนำไปใช้อาจเป็น สร้าง saved search (use), รัน 3+ ครั้งใน 14 วัน (repeat) และ ได้รับการแจ้งเตือนและคลิกเข้าไป (value achieved)
การติดตามของคุณควรตอบคำถามที่นำไปสู่การลงมือทำ เช่น:
เขียนสิ่งเหล่านี้เป็นประโยคการตัดสินใจ (เช่น “ถ้า activation ลดหลังจาก release X เราจะย้อนการเปลี่ยนแปลง onboarding”)
ทีมต่าง ๆ ต้องการมุมมองที่ต่างกัน:
เลือกชุดเมตริกเล็ก ๆ ที่จะทบทวน รายสัปดาห์ และมีการ ตรวจสอบหลังปล่อย แบบกระทัดรัดหลังการ deploy แต่ละครั้ง กำหนดเกณฑ์ชัดเจน (เช่น “อัตราการนำไปใช้ ≥ 25% ในกลุ่มผู้ใช้งานภายใน 30 วัน”) เพื่อให้รายงานขับเคลื่อนการตัดสินใจ ไม่ใช่การถกเถียง
ก่อนจะติดตั้งเหตุการณ์ใด ๆ ให้ตัดสินใจก่อนว่า “สิ่งต่าง ๆ” ที่ระบบวิเคราะห์ของคุณจะอธิบายมีอะไรบ้าง ถ้าคุณระบุเอนทิตีเหล่านี้ถูก รายงานจะเข้าใจได้แม้ผลิตภัณฑ์จะเปลี่ยนไป
กำหนดแต่ละเอนทิตีเป็นภาษาง่าย ๆ แล้วแปลงเป็น ID ที่เก็บได้:
project_created, invite_sent)จดคุณสมบัติขั้นต่ำที่ต้องการสำหรับแต่ละเหตุการณ์: user_id (หรือ anonymous ID), account_id, timestamp และคุณสมบัติที่เกี่ยวข้องไม่กี่ตัว (plan, role, device, feature flag ฯลฯ) หลีกเลี่ยงการเทข้อมูลทุกอย่าง “กันไว้ก่อน”
เลือกมุมมองการรายงานที่สอดคล้องกับเป้าหมายผลิตภัณฑ์:
การออกแบบเหตุการณ์ของคุณควรทำให้การคำนวณเหล่านี้เป็นเรื่องตรงไปตรงมา
ระบุขอบเขตอย่างชัดเจน: เฉพาะเว็บ ก่อน หรือ เว็บ + มือถือ ตั้งแต่วันแรก การติดตามข้ามแพลตฟอร์มจะง่ายขึ้นหากคุณมาตรฐานชื่อเหตุการณ์และคุณสมบัติแต่เนิ่น ๆ
สุดท้าย ตั้งเป้าต่อไปนี้ที่ไม่ต่อรอง: ผลกระทบต่อ ประสิทธิภาพหน้า, ความหน่วงในการรับข้อมูล (dashboards ควรสดแค่ไหน), และ เวลาการโหลดแดชบอร์ด ข้อจำกัดเหล่านี้จะชี้นำตัวเลือกในด้านการติดตาม, การเก็บข้อมูล, และการคิวรีในภายหลัง
สกีมาเหตุการณ์ที่ดีเน้นการทำให้อีเวนท์คาดเดาได้มากกว่าการ “เก็บทุกอย่าง” ถ้าชื่อเหตุการณ์และคุณสมบัติไหลเลื่อน รายงานจะพัง นักวิเคราะห์จะไม่ไว้ใจข้อมูล และวิศวกรจะลังเลที่จะติดตั้งฟีเจอร์ใหม่
เลือกรูปแบบเรียบง่ายและยึดตามมัน รูปแบบทั่วไปคือ verb_noun:
viewed_pricing_pagestarted_trialenabled_featureexported_reportใช้กาลอดีตหรือปัจจุบันแบบเดียวกันทั่วทั้งระบบ และหลีกเลียงคำพ้องความหมาย (clicked, pressed, tapped) เว้นแต่จะแยกความหมายจริง ๆ
เหตุการณ์ทุกชิ้นควรมีชุดคุณสมบัติที่บังคับขนาดเล็กเพื่อให้คุณสามารถแบ่งกลุ่ม กรอง และเชื่อมข้อมูลได้อย่างเชื่อถือ ไม่น้อยกว่าการกำหนด:
user_id (nullable สำหรับผู้ใช้ไม่ระบุชื่อ แต่ควรมีเมื่อทราบ)account_id (ถ้าผลิตภัณฑ์ของคุณเป็น B2B/multi-seat)timestamp (สร้างจากเซิร์ฟเวอร์เมื่อเป็นไปได้)feature_key (ตัวระบุที่เสถียรเช่น "bulk_upload")plan (เช่น free, pro, enterprise)คุณสมบัติเหล่านี้ทำให้การติดตามการนำฟีเจอร์ไปใช้และการวิเคราะห์พฤติกรรมผู้ใช้ทำได้ง่ายขึ้นเพราะไม่ต้องเดาว่าเหตุการณ์ใดขาดหาย
ฟิลด์เสริมเพิ่มบริบท แต่ทำได้ง่ายเกินไป ตัวอย่างทั่วไปของฟิลด์เสริมได้แก่:
device, os, browserpage, referrerexperiment_variant (หรือ ab_variant)รักษาความสอดคล้องของคุณสมบัติเสริมข้ามเหตุการณ์ (ใช้ชื่อคีย์และรูปแบบค่าเดียวกัน) และกำหนด "ค่าที่อนุญาต" เมื่อต้องการ
สมมติว่าสกีมาของคุณจะวิวัฒนาการ เพิ่ม event_version (เช่น 1, 2) และอัปเดตเมื่อความหมายหรือฟิลด์บังคับเปลี่ยน
สุดท้าย เขียนสเปคการติดตั้งที่ระบุแต่ละเหตุการณ์, เมื่อมันถูกยิง, คุณสมบัติที่บังคับ/เสริม, และตัวอย่าง เก็บเอกสารนี้ใน source control เคียงข้างแอปของคุณเพื่อให้การเปลี่ยนแปลงสกีมาถูกตรวจสอบเหมือนโค้ด
ถ้าระบบระบุตัวตนของคุณไม่แน่น เมตริกการนำไปใช้จะมีเสียง: funnels จะไม่ตรงกัน, retention จะดูแย่กว่าจริง, และ "ผู้ใช้งานแอป" จะถูกหารด้วย duplicates เป้าหมายคือรองรับมุมมองสามแบบพร้อมกัน: ผู้เยี่ยมชมไม่ระบุชื่อ, ผู้ใช้ที่ล็อกอิน, และกิจกรรมระดับบัญชี/ workspace
เริ่มทุกอุปกรณ์/เซสชันด้วย anonymous_id (cookie/localStorage) ตอนที่ผู้ใช้ยืนยันตัวตน ให้เชื่อมประวัติ anonymous นั้นกับ user_id
เชื่อมตัวตนเมื่อผู้ใช้พิสูจน์ความเป็นเจ้าของบัญชี (ล็อกอินสำเร็จ, ยืนยัน magic link, SSO) หลีกเลี่ยงการเชื่อมด้วยสัญญาณอ่อน (เช่น พิมพ์อีเมลในฟอร์ม) เว้นแต่จะระบุชัดว่าเป็น “pre-auth”
ปฏิบัติต่อการเปลี่ยนสถานะ auth เป็นเหตุการณ์:
login_success (รวม user_id, account_id, และ anonymous_id ปัจจุบัน)logoutaccount_switched (จาก account_id → account_id)สำคัญ: อย่าเปลี่ยน cookie anonymous ตอน logout ถ้าคุณหมุนค่า cookie จะทำให้ session แตกและเพิ่มจำนวนผู้ใช้เอกเทศแทน ให้เก็บ anonymous_id คงที่ แต่หยุดแนบ user_id หลัง logout
กำหนดกฎการรวมอย่างชัดเจน:
user_id ภายในที่เสถียรเป็นหลัก หากต้องรวมโดยอีเมล ให้ทำที่ฝั่งเซิร์ฟเวอร์และเฉพาะสำหรับอีเมลที่ยืนยันเท่านั้น เก็บ audit trailaccount_id/workspace_id ที่สร้างโดยระบบของคุณ ไม่ใช้ชื่อที่เปลี่ยนได้ง่ายเมื่อรวม ให้สร้างตารางแมปปิง (เก่า → ใหม่) แล้วใช้ที่เวลา query หรือผ่านงาน backfill เพื่อป้องกันไม่ให้ “สองผู้ใช้” ปรากฏใน cohorts
เก็บและส่ง:
anonymous_id (คงที่ต่อเบราว์เซอร์/อุปกรณ์)user_id (คงที่ต่อบุคคล)account_id (คงที่ต่อ workspace)ด้วยคีย์ทั้งสามนี้ คุณสามารถวัดพฤติกรรมก่อนล็อกอิน การนำไปใช้ต่อผู้ใช้ และการนำไปใช้ระดับบัญชีโดยไม่ซ้ำซ้อน
ที่ไหนที่คุณติดตามเหตุการณ์จะเปลี่ยนความน่าเชื่อถือของข้อมูล เหตุการณ์จากเบราว์เซอร์บอกว่าผู้คนพยายามทำอะไร ส่วนเหตุการณ์จากเซิร์ฟเวอร์บอกว่าสิ่งนั้นเกิดขึ้นจริงหรือไม่
ใช้การติดตามฝั่งไคลเอนต์สำหรับปฏิสัมพันธ์ UI และบริบทที่มีในเบราว์เซอร์เท่านั้น ตัวอย่างทั่วไป:
รวมเหตุการณ์เป็นกลุ่มเพื่อลดเครือข่าย: คิวในหน่วยความจำ, flush ทุก N วินาทีหรือเมื่อเกิด N เหตุการณ์ และ flush เมื่อ visibilitychange/page hide
ใช้การติดตามฝั่งเซิร์ฟเวอร์สำหรับเหตุการณ์ที่เป็นผลลัพธ์ที่เสร็จสมบูรณ์หรือเกี่ยวกับการเรียกเก็บเงิน/ความปลอดภัย:
การติดตามฝั่งเซิร์ฟเวอร์มักแม่นยำกว่าเพราะไม่ถูกบล็อกโดย ad blocker, การรีโหลดหน้า, หรือการเชื่อมต่อที่ไม่เสถียร
แบบแผนปฏิบัติได้คือ: ติดตาม intent ในไคลเอนต์ และ success ในเซิร์ฟเวอร์
ตัวอย่าง: ส่ง feature_x_clicked_enable (client) และ feature_x_enabled (server) จากนั้นเสริมเหตุการณ์เซิร์ฟเวอร์ด้วยบริบทจากไคลเอนต์โดยส่ง context_id (หรือ request ID) จากเบราว์เซอร์ไปยัง API
เพิ่มความยืดหยุ่นในจุดที่เหตุการณ์มักหายไป:
localStorage/IndexedDB, retry แบบ exponential backoff, จำกัดจำนวน retries, และ dedupe ด้วย event_idการผสมนี้ให้รายละเอียดพฤติกรรมที่สมบูรณ์โดยไม่แลกกับเมตริกการนำไปใช้ที่ไม่น่าเชื่อถือ
แอปวิเคราะห์การนำฟีเจอร์ไปใช้เป็นหลัก ๆ ท่อข้อมูล: เก็บเหตุการณ์อย่างเชื่อถือได้ เก็บข้อมูลแบบประหยัด และคิวรีให้เร็วพอที่คนจะเชื่อถือผลลัพธ์
เริ่มด้วยชุดบริการที่แยกกันได้และเรียบง่าย:
ถ้าต้องการต้นแบบแอปวิเคราะห์ภายในอย่างรวดเร็ว แพลตฟอร์ม vibe-coding อย่าง Koder.ai สามารถช่วยตั้ง UI แดชบอร์ด (React) และ backend (Go + PostgreSQL) จากสเปคที่ขับเคลื่อนด้วยแชท—มีประโยชน์สำหรับการได้ชิ้นงาน “ทำงานได้” ก่อนจะทำให้ pipeline แข็งแกร่ง
ใช้สองชั้น:
เลือกระดับความสดที่ทีมต้องการจริง ๆ:
หลายทีมใช้ทั้งสองอย่าง: ตัวนับเรียลไทม์สำหรับ “เกิดอะไรขึ้นตอนนี้” บวกกับงานกลางคืนที่คำนวณเมตริก canonical ใหม่ทุกคืน
ออกแบบการเติบโตตั้งแต่เนิ่น ๆ โดยการพาร์ติชัน:
ยังวางแผนนโยบายการเก็บรักษา (เช่น raw 13 เดือน, aggregates เก็บนานกว่า) และเส้นทาง replay เพื่อให้แก้บั๊กโดยการประมวลผลซ้ำแทนการแพตช์แดชบอร์ด
การวิเคราะห์ที่ดีเริ่มจากโมเดลที่ตอบคำถามทั่วไปได้เร็ว (funnels, retention, การใช้ฟีเจอร์) โดยไม่เปลี่ยนทุกคิวรีให้เป็นโครงการวิศวกรรมเฉพาะ
ทีมส่วนใหญ่ได้ผลดีที่สุดกับสองร้าน:
การแยกนี้ทำให้ฐานข้อมูลผลิตภัณฑ์ของคุณเบา และคิวรีวิเคราะห์ถูกและเร็วขึ้น
แนวทางพื้นฐานปฏิบัติได้จริงคือ:
ใน warehouse ให้ denormalize สิ่งที่คิวรีบ่อย (เช่น คัดลอก account_id ลงไปใน events) เพื่อหลีกเลี่ยงการ join ที่หนักหน่วง
พาร์ติชัน raw_events ตามเวลา (รายวันเป็นปกติ) และอาจพาร์ติชันตาม workspace/app ใช้นโยบายการเก็บรักษาแยกตามประเภทเหตุการณ์:
นี่ป้องกันการเติบโตแบบ “ไม่มีที่สิ้นสุด” ที่กลายเป็นปัญหาหลักของการวิเคราะห์
ถือว่าการตรวจสอบคุณภาพเป็นส่วนหนึ่งของการจำลองข้อมูล ไม่ใช่การทำความสะอาดภายหลัง:
เก็บผลการตรวจสอบ (หรือบันทึกเหตุการณ์ที่ถูกปฏิเสธ) เพื่อมอนิเตอร์สุขภาพการติดตั้งและแก้ปัญหาก่อนที่แดชบอร์ดจะคลาดเคลื่อน
เมื่อเหตุการณ์ไหลเข้ามา ขั้นตอนถัดไปคือแปลงคลิกดิบเป็นเมตริกที่ตอบว่า: “ฟีเจอร์นี้ถูกนำไปใช้จริงหรือไม่ และโดยใคร?” ให้มุ่งที่มุมมองสี่แบบที่ทำงานร่วมกัน: funnels, cohorts, retention, และ paths
กำหนด funnel ต่อฟีเจอร์เพื่อดูว่าผู้ใช้หลุดที่ไหน รูปแบบปฏิบัติได้คือ:
feature_used)ยึดขั้นตอน funnel กับ เหตุการณ์ที่เชื่อถือได้ และตั้งชื่อให้อย่างสม่ำเสมอ หาก “first use” เกิดได้หลายทาง ให้ทำเป็นขั้นตอนที่มี เงื่อนไข OR (เช่น import_started OR integration_connected)
Cohorts ช่วยวัดการปรับปรุงเมื่อเวลาผ่านไปโดยไม่ผสมผู้ใช้เก่าและใหม่ Cohort ทั่วไปได้แก่:
ติดตามอัตราการนำไปใช้ภายในแต่ละ cohort เพื่อดูว่าการปรับปรุง onboarding หรือ UI ล่าสุดช่วยหรือไม่
Retention มีประโยชน์ที่สุดเมื่อผูกกับฟีเจอร์ ไม่ใช่แค่ "เปิดแอป" กำหนดเป็นการทำซ้ำของเหตุการณ์แกนกลางของฟีเจอร์ (หรือ value action) ใน Day 7/30 ติดตาม "เวลาไปสู่การใช้ครั้งที่สอง" ด้วย—มักไวต่อการเปลี่ยนแปลงมากกว่า retention ดิบ
แยกเมตริกตามมิติที่อธิบายพฤติกรรม: plan, role, industry, device, และ channel การได้มา เซกเมนต์มักเผยว่าการนำไปใช้ดีในกลุ่มหนึ่งแต่แทบไม่มีในอีกกลุ่มหนึ่ง
เพิ่ม path analysis เพื่อหาลำดับที่พบบ่อยก่อนและหลังการนำไปใช้ (เช่น ผู้ใช้ที่นำไปใช้มักไปที่ pricing, จากนั้น docs, แล้วเชื่อม integration) ใช้ข้อมูลนี้ในการปรับ onboarding และตัดจุดที่เป็น dead end
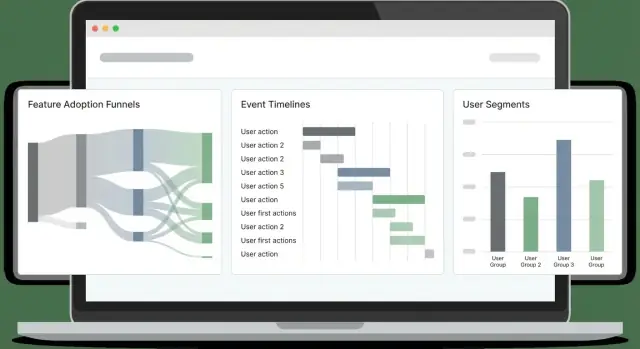
แดชบอร์ดล้มเหลวเมื่อพยายามตอบทุกคนด้วย "มุมมองหลัก" เดียว ให้ออกแบบหน้าจอที่โฟกัสไม่กี่หน้าเพื่อจับกับการตัดสินใจของผู้ชมต่าง ๆ และให้แต่ละหน้าตอบคำถามชัดเจน
ภาพรวมสำหรับผู้บริหารควรเป็นการตรวจสุขภาพด่วน: แนวโน้มการนำไปใช้, ผู้ใช้แอคทีฟ, ฟีเจอร์ยอดนิยม, และการเปลี่ยนแปลงสำคัญตั้งแต่การปล่อยล่าสุด หน้าลงลึกฟีเจอร์สำหรับ PMs และวิศวกรควรแสดงว่าเริ่มที่ไหน หลุดที่ไหน และเซกเมนต์ใดต่างกันอย่างไร
โครงสร้างง่าย ๆ ที่ใช้ได้ดี:
ใส่กราฟแนวโน้มสำหรับ "อะไร", การแบ่งตามเซกเมนต์สำหรับ "ใคร", และ drill-down สำหรับ "ทำไม" การ drill-down ควรให้คนคลิกแท่ง/จุดแล้วเห็นตัวอย่างผู้ใช้หรือ workspace (พร้อมสิทธิ์ที่เหมาะสม) เพื่อให้ทีมยืนยันรูปแบบและตรวจสอบ session จริง
รักษาตัวกรองให้คงที่ข้ามหน้าเพื่อให้ผู้ใช้ไม่ต้องเรียนรู้การควบคุมใหม่ ตัวกรองที่มีประโยชน์ที่สุดสำหรับการติดตามการนำฟีเจอร์คือ:
แดชบอร์ดกลายเป็นส่วนหนึ่งของเวิร์กฟลว์เมื่อผู้คนสามารถแชร์สิ่งที่เห็นได้อย่างตรงตัว เพิ่ม:
ถ้าคุณสร้างสิ่งนี้เป็นส่วนหนึ่งของแอปวิเคราะห์ผลิตภัณฑ์ ให้พิจารณาหน้า /dashboards ที่มีมุมมองที่บันทึกไว้ “Pinned” เพื่อให้ผู้มีส่วนได้ส่วนเสียเข้าถึงรายงานสำคัญได้ทันที
แดชบอร์ดดีสำหรับการสำรวจ แต่ทีมมักรู้ปัญหาเมื่อมีลูกค้าร้องเรียน การแจ้งเตือนจะกลับด้านนั้น: คุณจะรู้เรื่องการขัดข้องไม่กี่นาทีหลังเกิด และสามารถผูกกับการเปลี่ยนแปลงที่ทำได้
เริ่มด้วยการแจ้งเตือนที่ให้สัญญาณสูงไม่กี่รายการปกป้อง flow หลักของการนำไปใช้:
feature_failed) รวมเกณฑ์ทั้งแบบ absolute และแบบอัตรา (errors ต่อ 1,000 sessions)เก็บคำนิยามแจ้งเตือนให้อ่านง่ายและควบคุมเวอร์ชัน (เช่น YAML ใน repo) เพื่อไม่ให้กลายเป็นความรู้ปากต่อปาก
การตรวจจับความผิดปกติพื้นฐานมีประสิทธิภาพโดยไม่ต้องใช้ ML ขั้นสูง:
เพิ่มสตรีมหมุดหมายการปล่อยในชาร์ต: deploys, การไล่ rollout ของ feature flag, การเปลี่ยนแปลงราคา, การปรับ onboarding แต่ละหมุดควรรวม timestamp, เจ้าของ, และโน้ตสั้น ๆ เมื่อเมตริกเปลี่ยน คุณจะเห็นสาเหตุที่เป็นไปได้ทันที
ส่งการแจ้งเตือนไปยังอีเมลและช่องทางแบบ Slack แต่สนับสนุน quiet hours และการเลิกระดับ (เตือน → page) สำหรับปัญหาเฉียบพลัน ทุกการแจ้งเตือนต้องมีเจ้าของและลิงก์ runbook (แม้เป็นหน้า /docs/alerts สั้น ๆ) ที่อธิบายสิ่งที่ควรตรวจสอบเป็นอันดับแรก
ข้อมูลการวิเคราะห์กลายเป็นข้อมูลส่วนบุคคลได้อย่างรวดเร็วถ้าคุณไม่ระวัง ให้ถือความเป็นส่วนตัวเป็นส่วนหนึ่งของการออกแบบการติดตาม ไม่ใช่เรื่องกฎหมายมาทีหลัง: จะลดความเสี่ยง สร้างความไว้วางใจ และป้องกันการทำงานซ้ำที่เจ็บปวด
เคารพข้อกำหนดความยินยอมและให้ผู้ใช้ยกเลิกได้เมื่อจำเป็น ในทางปฏิบัติ หมายถึงเลเยอร์การติดตามควรเช็ก flag ความยินยอมก่อนส่งเหตุการณ์ และสามารถหยุดการติดตามระหว่างเซสชันหากผู้ใช้เปลี่ยนใจ
สำหรับภูมิภาคที่เข้มงวดกว่า พิจารณา “ฟีเจอร์ที่ขึ้นกับความยินยอม”:
ลดข้อมูลที่ละเอียดอ่อน: หลีกเลี่ยงอีเมลดิบในเหตุการณ์; ใช้แฮช/ID ทึบ เหตุการณ์ควรบรรยายพฤติกรรม (เกิดอะไรขึ้น) ไม่ใช่ตัวตน (ใครคือบุคคล) หากต้องผูกเหตุการณ์กับบัญชี ให้ส่ง user_id/account_id ภายในและเก็บแผนที่ในฐานข้อมูลพร้อมการควบคุมความปลอดภัยที่เหมาะสม
หลีกเลี่ยงการเก็บ:
อธิบายสิ่งที่คุณเก็บและเหตุผล; มีหน้าความเป็นส่วนตัวที่อ่านง่าย สร้าง “พจนานุกรรมการติดตาม” เบา ๆ ที่อธิบายแต่ละเหตุการณ์ วัตถุประสงค์ และระยะเวลาเก็บ ใน UI ของผลิตภัณฑ์ ให้ลิงก์ไปยังหน้า privacy และทำให้อ่านง่าย: เก็บอะไร ไม่เก็บอะไร และวิธียกเลิก
ใช้ role-based access ให้เฉพาะทีมที่ได้รับอนุญาตสามารถดูข้อมูลระดับผู้ใช้ ส่วนใหญ่คนทั่วไปต้องการแค่แดชบอร์ดสรุป ให้มุมมองเหตุการณ์ดิบสำหรับกลุ่มเล็ก (เช่น data/product ops) เท่านั้น เพิ่ม audit logs สำหรับการส่งออกและการค้นหาผู้ใช้ และตั้งนโยบายการเก็บรักษาให้ข้อมูลเก่า ๆ หมดอายุอัตโนมัติ
ถ้าทำดี การควบคุมความเป็นส่วนตัวจะไม่ชะลอการวิเคราะห์—แต่จะทำให้ระบบปลอดภัย ชัดเจน และดูแลรักษาง่ายขึ้น
การส่งงานวิเคราะห์ก็เหมือนการส่งฟีเจอร์: เริ่มจากการปล่อยขนาดเล็กที่ตรวจสอบได้ แล้วค่อย ๆ ทำ iteratively ให้ติดตามเป็นโค้ดมีเจ้าของ รีวิว และการทดสอบ
เริ่มด้วยชุดแคบของ golden events สำหรับพื้นที่ฟีเจอร์หนึ่ง (ตัวอย่าง: Feature Viewed, Feature Started, Feature Completed, Feature Error) เหล่านี้ควรจับคำถามที่ทีมจะถามทุกสัปดาห์
จำกัดขอบเขตโดยมีเหตุผล: เหตุการณ์น้อยลงทำให้คุณสามารถยืนยันคุณภาพได้เร็ว และคุณจะเรียนรู้ว่าจริง ๆ ต้องการคุณสมบัติใดบ้างก่อนขยายต่อ
ใช้เช็คลิสต์ก่อนเรียกว่าการติดตั้งเสร็จ:
เพิ่ม คิวรีตัวอย่าง ที่สามารถรันได้ทั้งใน staging และ production ตัวอย่าง:
feature_name” (จับการพิมพ์ผิดเช่น Search vs search)ทำให้การติดตั้งเป็นส่วนหนึ่งของกระบวนการปล่อย:
วางแผนสำหรับการเปลี่ยนแปลง: ยกเลิกการใช้งานเหตุการณ์แทนการลบ, ให้เวอร์ชันคุณสมบัติเมื่อความหมายเปลี่ยน, และกำหนดการตรวจสอบเป็นระยะ
เมื่อเพิ่มคุณสมบัติที่บังคับใหม่หรือแก้บั๊ก ให้ตัดสินใจว่าต้องทำ backfill หรือไม่ (และระบุช่วงเวลาที่ข้อมูลเป็นบางส่วน)
สุดท้าย เก็บไกด์การติดตามสั้น ๆ ในเอกสารและลิงก์จากแดชบอร์ดและ PR templates จุดเริ่มต้นที่ดีคือเช็คลิสต์สั้น ๆ เช่น blog/event-tracking-checklist
เริ่มจากการเขียนลงไปว่า “การนำไปใช้” หมายถึงอะไรสำหรับผลิตภัณฑ์ของคุณ:
จากนั้นเลือกคำนิยามที่สอดคล้องกับวิธีที่ฟีเจอร์มอบคุณค่า และแปลงเป็นเหตุการณ์ที่วัดผลได้
เลือกชุดเมตริกเล็ก ๆ ที่คุณจะทบทวนเป็นประจำ (รายสัปดาห์) และมีการตรวจสอบด่วนหลังการปล่อยฟีเจอร์ เมตริกทั่วไปได้แก่:
เพิ่มเกณฑ์ชัดเจน (เช่น “≥ 25% ภายใน 30 วัน”) เพื่อให้ผลลัพธ์นำไปสู่การตัดสินใจ ไม่ใช่ข้อถกเถียง
กำหนดเอนทิตีหลักล่วงหน้าเพื่อให้รายงานยังเข้าใจได้เมื่อระบบขยายตัว:
ใช้รูปแบบชื่อที่สม่ำเสมอ เช่น verb_noun และยึดตามกาลเดียวกันทั่วทั้งผลิตภัณฑ์
กฎปฏิบัติที่เป็นประโยชน์:
สร้าง “สัญญา” เหตุการณ์ขั้นต่ำเพื่อให้แต่ละเหตุการณ์สามารถแบ่งกลุ่มและเชื่อมโยงได้ในภายหลัง ตัวอย่างพื้นฐาน:
user_id (nullable ถ้าเป็น anonymous)ติดตาม intent ในเบราว์เซอร์ และ success ที่เซิร์ฟเวอร์
แนวทางไฮบริดนี้ช่วยลดการสูญหายของข้อมูลจาก ad blocker หรือการรีโหลดหน้า ในกรณีที่ต้องเชื่อมบริบท ให้ส่ง context_id (request ID) จาก client → API แล้วแนบกับเหตุการณ์ฝั่งเซิร์ฟเวอร์
ใช้คีย์สามตัวที่เสถียร:
anonymous_id (ต่อเบราว์เซอร์/อุปกรณ์)user_id (ต่อบุคคล)account_id (ต่อ workspace)เชื่อม anonymous → identified ก็ต่อเมื่อมีการพิสูจน์ความเป็นเจ้าของที่แน่นอน (ล็อกอินสำเร็จ, magic link ยืนยัน, SSO)
ติดตามการเปลี่ยนสถานะการยืนยันตัวตนเป็นเหตุการณ์ (, , ) และหลีกเลี่ยงการหมุนค่า cookie anonymous ตอน logout เพื่อไม่ให้แตก session และเพิ่มจำนวนผู้ใช้เอกเทศ
การนำไปใช้มักไม่ใช่คลิกเดียว ให้มองเป็น funnel:
ถ้า “first use” เกิดได้หลายทาง ให้กำหนดเป็นเงื่อนไข OR (เช่น OR ) และยึดขั้นตอนกับเหตุการณ์ที่เชื่อถือได้ (มักเป็นฝั่งเซิร์ฟเวอร์สำหรับผลลัพธ์)
เริ่มจากหน้าที่เจาะจงกับการตัดสินใจ:
รักษาตัวกรองให้สอดคล้องข้ามหน้า (ช่วงวันที่, แผน, คุณสมบัติบัญชี, ภูมิภาค, เวอร์ชันแอป) เพิ่ม saved views และการส่งออก CSV เพื่อให้ผู้มีส่วนได้ส่วนเสียแชร์สิ่งที่เห็นได้อย่างแม่นยำ
ใส่มาตรการป้องกันใน pipeline และกระบวนการ:
event_version และเลิกใช้งานแทนการลบสำหรับแต่ละเหตุการณ์ ให้จับอย่างน้อย user_id (หรือ anonymous_id), account_id (ถ้ามี), timestamp และคุณสมบัติที่เกี่ยวข้องเล็กน้อย (plan/role/device/flag)
clicked กับ pressed)report_exported) แทนเสียงรบกวนของ UIfeature_key คงที่ (เช่น bulk_upload) แทนการพึ่งพาชื่อที่แสดงผลจดบันทึกชื่อเหตุการณ์และช่วงเวลาที่มันเกิดในสเปคการติดตั้งที่เก็บใน source control
anonymous_idaccount_id (สำหรับ B2B/multi-seat)timestamp (สร้างจากเซิร์ฟเวอร์เมื่อเป็นไปได้)feature_keyplan (หรือตำแหน่งชั้น)จำกัดคุณสมบัติเสริมและทำให้คีย์กับรูปแบบค่าคงที่ในทุกเหตุการณ์
login_successlogoutaccount_switchedimport_startedintegration_connectedนอกจากนี้ให้ถือว่าความเป็นส่วนตัวเป็นส่วนหนึ่งของการออกแบบ: ขอความยินยอมก่อน, หลีกเลี่ยงอีเมลดิบ/ข้อความอิสระในเหตุการณ์, และจำกัดการเข้าถึงข้อมูลระดับผู้ใช้ด้วยบทบาทและบันทึกตรวจสอบ