15 พ.ย. 2568·3 นาที
สร้างเว็บแอปสำหรับติดตามสถานะแอปและ KPI ทางธุรกิจ
เรียนรู้วิธีสร้างเว็บแอปที่รวมเวลาออนไลน์ ค่าหน่วง และข้อผิดพลาดกับรายได้ การแปลง และการยกเลิกสมัคร—พร้อมแดชบอร์ด การแจ้งเตือน และการออกแบบข้อมูล
เรียนรู้วิธีสร้างเว็บแอปที่รวมเวลาออนไลน์ ค่าหน่วง และข้อผิดพลาดกับรายได้ การแปลง และการยกเลิกสมัคร—พร้อมแดชบอร์ด การแจ้งเตือน และการออกแบบข้อมูล
มุมมองรวม “สถานะแอป + KPI ทางธุรกิจ” คือพื้นที่เดียวที่ทีมเห็นได้ว่า ระบบทำงานหรือไม่ และ ผลิตภัณฑ์ส่งมอบผลลัพธ์ที่ธุรกิจใส่ใจหรือเปล่า แทนที่จะสลับไปมาระหว่างเครื่องมือ observability สำหรับเหตุการณ์กับเครื่องมือวิเคราะห์สำหรับผลการใช้งาน คุณเชื่อมจุดต่างๆ ในเวิร์กโฟลว์เดียว
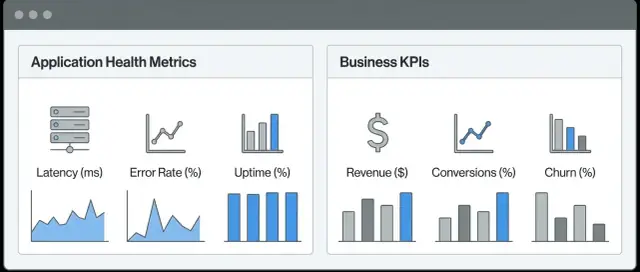
เมตริกเชิงเทคนิค อธิบายพฤติกรรมของซอฟต์แวร์และโครงสร้างพื้นฐานของคุณ ตอบคำถามเช่น: แอปตอบสนองไหม มีข้อผิดพลาดไหม ช้าไหม ตัวอย่างทั่วไปได้แก่ ค่าหน่วงเวลา อัตราข้อผิดพลาด ปริมาณงาน การใช้ CPU/หน่วยความจำ ความลึกคิว และความพร้อมใช้งานของการพึ่งพา
เมตริกเชิงธุรกิจ (KPI) อธิบายผลลัพธ์ของผู้ใช้และรายได้ ตอบคำถามเช่น: ผู้ใช้สำเร็จไหม เราทำเงินไหม ตัวอย่างเช่น การลงทะเบียน การเปิดใช้งาน อัตราการแปลง การชำระเงินที่สำเร็จ มูลค่าการสั่งซื้อเฉลี่ย การยกเลิกสมัคร การคืนเงิน และปริมาณตั๋วซัพพอร์ต
เป้าหมายไม่ใช่แทนที่หมวดใดหมวดหนึ่ง—แต่เพื่อ เชื่อมโยงทั้งสอง เพื่อให้การเพิ่มขึ้นของข้อผิดพลาด 500 ไม่ใช่แค่ “สีแดงบนชาร์ต” แต่เชื่อมชัดกับ “อัตราการแปลงเช็คเอาต์ลดลง 12%”
เมื่อสัญญาณสุขภาพและ KPI ใช้อินเทอร์เฟซและช่วงเวลาร่วมกัน ทีมมักจะเห็น:
คู่มือนี้เน้นที่ โครงสร้างและการตัดสินใจ: วิธีการกำหนดเมตริก เชื่อมตัวระบุ เก็บและคิวรีข้อมูล และนำเสนอแดชบอร์ดกับการแจ้งเตือน มันตั้งใจไม่ผูกกับผู้ให้บริการใด ๆ ดังนั้นคุณสามารถประยุกต์ใช้แนวทางนี้ไม่ว่าคุณจะใช้เครื่องมือสำเร็จรูป สร้างเอง หรือผสมทั้งสองแบบ
ถ้าคุณพยายามติดตามทุกอย่าง คุณจะได้แดชบอร์ดที่ไม่มีใครไว้วางใจ เริ่มด้วยการตัดสินใจว่าแอปมอนิเตอร์ต้องช่วยอะไรภายใต้ความกดดัน: ตัดสินใจได้เร็วและถูกต้องระหว่างเหตุการณ์และติดตามความคืบหน้าเป็นสัปดาห์ต่อสัปดาห์
เมื่อมีอะไรผิด พาเนลของคุณควรตอบอย่างรวดเร็ว:
หากชาร์ตใดช่วยตอบคำถามเหล่านี้ไม่ได้ ให้พิจารณาลบออก
เก็บชุดแกนหลักให้เล็กและสม่ำเสมอระหว่างทีม รายการเริ่มต้นที่ดี:
เมตริกเหล่านี้สอดคล้องกับโหมดความล้มเหลวทั่วไปและง่ายต่อการตั้งการแจ้งเตือนในภายหลัง
เลือกเมตริกที่แทนช่องทางลูกค้าและความเป็นจริงของรายได้:
สำหรับแต่ละเมตริก กำหนด เจ้าของ นิยาม/แหล่งข้อมูลเป็น “แหล่งความจริง” และ รอบการทบทวน (รายสัปดาห์หรือรายเดือน) หากไม่มีใครเป็นเจ้าของ เมตริกจะค่อย ๆ ทำให้เข้าใจผิดได้—และการตัดสินใจในเหตุการณ์จะแย่ลง
ถ้าแผนภูมิสุขภาพของคุณอยู่ในเครื่องมือหนึ่งและแดชบอร์ด KPI อยู่ในอีกเครื่องมือหนึ่ง ก็ง่ายที่จะแย้งกันว่า "เกิดอะไรขึ้น" ระหว่างเหตุการณ์ ยึดการมอนิเตอร์รอบเส้นทางลูกค้าบางเส้นทางที่ประสิทธิภาพมีผลชัดเจนต่อผลลัพธ์
เลือกฟลูว์ที่ขับเคลื่อนรายได้หรือการรักษาโดยตรง เช่น onboarding, search, checkout/payment, account login, หรือ content publishing สำหรับแต่ละเส้นทาง ให้กำหนดขั้นตอนหลักและความหมายของ “สำเร็จ”
ตัวอย่าง (checkout):
แมปสัญญาณเทคนิคที่มีผลอย่างมากต่อแต่ละขั้นตอน นี่คือที่มอนิเตอร์สุขภาพกลายเป็นเรื่องเกี่ยวข้องกับธุรกิจ
สำหรับ checkout ตัวชี้นำล่วงหน้าอาจเป็น “p95 ค่าหน่วงเวลาของ API การชำระเงิน” ในขณะที่ตัวชี้วัดตามหลังคือ “อัตราการแปลงเช็คเอาต์” การเห็นทั้งสองบนไทม์ไลน์เดียวทำให้สายเหตุผลชัดเจนขึ้น
พจนานุกรมเมตริกป้องกันความสับสนและข้อถกเถียง “KPI เดียวกัน คำนวณต่างกัน” สำหรับทุกเมตริก ให้บันทึก:
Page views, การลงทะเบียนดิบ หรือ “sessions ทั้งหมด” อาจมีเสียงรบกวนโดยไม่มีบริบท ให้เลือกเมตริกที่ผูกกับการตัดสินใจ (อัตราสำเร็จ มูลค่ารายได้ต่อการเยี่ยมชม) และลดการซ้ำซ้อนของ KPI: นิยามทางการเดียวดีกว่าหลายแดชบอร์ดที่ขัดแย้งกัน 2%
ก่อนเขียนโค้ด UI ให้ตัดสินใจว่าคุณกำลังสร้างอะไร แอป “สุขภาพ + KPI” มักมีห้าส่วนหลัก: collectors (เมตริก/ล็อก/เทรซและเหตุการณ์ผลิตภัณฑ์), ingestion (คิว/ETL/สตรีมมิง), storage (time-series + warehouse), data API (สำหรับคิวรีและสิทธิ์ที่สอดคล้อง), และ UI (แดชบอร์ด + การเจาะลึก) การแจ้งเตือน อาจเป็นส่วนของ UI หรือมอบหมายให้ระบบ on-call ที่มีอยู่
ถ้าคุณต้องการต้นแบบ UI และเวิร์กโฟลว์อย่างรวดเร็ว แพลตฟอร์ม vibe-coding อย่าง Koder.ai สามารถช่วยตั้งค่าเปลือกแดชบอร์ด React พร้อม backend Go + PostgreSQL จากสเปกที่สร้างด้วยแชท แล้ววนปรับการนำทางเจาะลึกและตัวกรองก่อนตัดสินใจเขียนแพลตฟอร์มข้อมูลเต็มรูปแบบ
วางแผนแวดล้อมแยกกันตั้งแต่ต้น: ข้อมูลโปรดักชันไม่ควรรวมกับสเตจ/เดฟ เก็บ project ID, API key, และบัคเก็ต/ตารางเก็บข้อมูลแยก หากต้องการเปรียบเทียบ prod vs staging ให้ทำผ่านมุมมองควบคุมใน API—ไม่ใช่แชร์ท่อข้อมูลดิบ
หน้าจอเดียวไม่จำเป็นต้องเขียนซ้ำการแสดงผลทั้งหมด คุณสามารถ:
ถ้าเลือกฝัง ให้กำหนดมาตรฐานการนำทางชัดเจน (เช่น “จากการ์ด KPI ไปยังมุมมอง trace”) เพื่อไม่ให้ผู้ใช้รู้สึกถูกเด้งไปมาระหว่างเครื่องมือ
แดชบอร์ดของคุณจะเชื่อถือได้เท่ากับข้อมูลเบื้องหลัง ก่อนสร้างท่อข้อมูล ให้ลงรายการระบบที่ “รู้” ว่ามีอะไรเกิดขึ้นแล้ว จากนั้นตัดสินใจว่าควรรีเฟรชแต่ละระบบบ่อยแค่ไหน
เริ่มจากแหล่งที่อธิบายความน่าเชื่อถือและประสิทธิภาพ:
กฎปฏิบัติ: ถือว่าสัญญาณสุขภาพเป็น ใกล้เวลาเรียลไทม์ โดยค่าเริ่มต้น เพราะพวกมันขับเคลื่อนการแจ้งเตือนและการตอบเหตุการณ์
KPI ทางธุรกิจมักอยู่ในเครื่องมือที่ทีมต่างกันเป็นเจ้าของ:
ไม่ใช่ทุก KPI ต้องการการอัปเดตวินาทีต่อวินาที รายได้รายวันอาจเป็นแบบแบตช์ ขณะที่อัตราการแปลงเช็คเอาต์อาจต้องการข้อมูลที่สดกว่า
สำหรับแต่ละ KPI ให้เขียนความคาดหวัง latency ง่ายๆ: “อัปเดตทุก 1 นาที”, “รายชั่วโมง”, หรือ “วันทำการถัดไป” แล้วสะท้อนสิ่งนั้นตรงใน UI (เช่น: “ข้อมูล ณ 10:35 UTC”) สิ่งนี้ป้องกันการแจ้งเตือนผิดพลาดและข้อโต้แย้งเรื่องตัวเลขที่ไม่ถูกต้องเพราะหน่วงเวลา
เพื่อเชื่อม spike ของข้อผิดพลาดกับรายได้ที่หายไป คุณต้องมีไอดีที่สอดคล้องกัน:
กำหนด “แหล่งความจริง” หนึ่งสำหรับแต่ละตัวระบุและตรวจสอบให้ระบบทั้งหมดพกพามัน (เหตุการณ์ analytics, logs, ระเบียน billing) ถ้าระบบใช้คีย์ต่างกัน ให้ทำตารางแมปตั้งแต่เนิ่นๆ การเย็บย้อนหลังกินทรัพยากรและเสี่ยงผิดพลาด
ถ้าคุณพยายามเก็บทุกอย่างในฐานข้อมูลเดียว มักจะได้แดชบอร์ดช้า ค้นหาคลุมแพง หรือทั้งสองอย่าง วิธีที่ชัดเจนคือถือว่า เทเลเมทริกสุขภาพ และ KPI ทางธุรกิจ เป็นรูปแบบข้อมูลต่างกันที่มีรูปแบบการอ่านต่างกัน
เมตริกสุขภาพ (ค่าหน่วง อัตราข้อผิดพลาด CPU ความลึกคิว) มีปริมาณสูงและถูกคิวรีโดยช่วงเวลา: “15 นาทีล่าสุด”, “เปรียบเทียบกับเมื่อวาน”, “p95 ตามบริการ” ฐานข้อมูลแบบ time-series ถูกปรับให้ทำ rollup และ range scan ได้เร็ว
เก็บ tags/labels ให้จำกัดและสอดคล้องกัน (service, env, region, endpoint group) ป้ายที่ไม่จำกัดจะเพิ่ม cardinality และค่าใช้จ่าย
KPI ทางธุรกิจ (การลงทะเบียน การแปลง churn รายได้ คำสั่งซื้อ) มักต้องการการ join, backfill, และรายงานแบบ “as-of” ดังนั้น warehouse/lake เหมาะสำหรับ:
เว็บแอปไม่ควรคุยตรงกับทั้งสองที่จากเบราว์เซอร์ สร้าง backend API ที่คิวรีแต่ละที่ บังคับสิทธิ์ และคืนสกีมาแบบสอดคล้อง แนวทางทั่วไป: พาเนลสุขภาพเรียก time-series store; พาเนล KPI เรียก warehouse; endpoint เจาะลึกอาจดึงทั้งคู่แล้วรวมตามช่วงเวลา
ตั้งชั้นให้ชัด:
สรุปล่วงหน้ามุมมองแดชบอร์ดทั่วไป (รายชั่วโมง/รายวัน) เพื่อให้ผู้ใช้ส่วนใหญ่ไม่กระตุ้นการคิวรีที่แพง
UI ของคุณจะใช้งานได้เท่ากับ API ข้างหลัง API ที่ดีทำให้มุมมองแดชบอร์ดทั่วไปเร็วและคาดเดาได้ ในขณะเดียวกันยังให้คนคลิกเจาะลึกได้โดยไม่ต้องโหลดผลิตภัณฑ์คนละชิ้น
ออกแบบ endpoint ให้ตรงกับการนำทางหลัก ไม่ใช่ฐานข้อมูลเบื้องหลัง:
GET /api/dashboards และ GET /api/dashboards/{id} เพื่อดึงเค้าโครงที่บันทึก นิยามชาร์ต และตัวกรองเริ่มต้นGET /api/metrics/timeseries สำหรับชาร์ตสุขภาพและ KPI พร้อมพารามิเตอร์ from, to, interval, timezone, และ filtersGET /api/drilldowns (หรือ /api/events/search) สำหรับ “แสดงคำขอ/คำสั่งซื้อ/ผู้ใช้ที่อยู่เบื้องหลังเซ็กเมนต์ของชาร์ต”GET /api/filters สำหรับรายการค่าที่เป็นไปได้ (region, plans, environments) และขับไทป์อะฮีดแดชบอร์ดไม่ค่อยต้องการข้อมูลดิบ; พวกมันต้องการสรุป:
เพิ่ม caching สำหรับคำขอซ้ำ (แดชบอร์ดเดียว ช่วงเวลาเดียวกัน) และบังคับ rate limit สำหรับคิวรีกว้าง พิจารณาขีดจำกัดแยกระหว่างการเจาะลึกแบบโต้ตอบกับการรีเฟรชที่ตั้งเวลา
ทำให้ชาร์ตเปรียบเทียบได้โดยคืนขอบเขตบัคเก็ตและหน่วยที่เหมือนกันเสมอ: timestamps จัดแนวกับ interval ที่เลือก, ฟิลด์ unit ชัดเจน (ms, %, USD), และกฎการปัดเศษคงที่ ความสอดคล้องป้องกันการกระโดดของชาร์ตเมื่อผู้ใช้เปลี่ยนตัวกรองหรือเปรียบเทียบแวดล้อม
แดชบอร์ดสำเร็จเมื่อมันตอบคำถามได้เร็ว: “เราปลอดภัยไหม?” และ “ถ้าไม่ ลองดูตรงไหนต่อ?” ออกแบบโดยรอบการตัดสินใจ ไม่ใช่ทุกสิ่งที่วัดได้
ทีมส่วนใหญ่ทำได้ดีกว่ากับมุมมองที่มีจุดประสงค์ไม่กี่หน้า แทนที่จะเป็นแดชบอร์ดยักษ์เดียว:
วาง time picker เดียวที่ด้านบนของทุกหน้า และรักษาความสอดคล้อง เพิ่มตัวกรองระดับโลกที่ผู้ใช้ใช้งานจริง—region, plan, platform, และอาจ customer segment เป้าหมายคือเปรียบเทียบ “US + iOS + Pro” กับ “EU + Web + Free” โดยไม่ต้องสร้างชาร์ตใหม่
รวมอย่างน้อยหนึ่งพาเนลความสัมพันธ์ต่อหน้า ที่ซ้อนสัญญาณเทคนิคและธุรกิจบนแกนนเวลาชุดเดียว เช่น:
นี่ช่วยให้ผู้มีส่วนได้ส่วนเสียที่ไม่ใช่เทคนิคเห็นผลกระทบ และช่วยวิศวกรจัดลำดับความสำคัญการแก้ไขที่ปกป้องผลลัพธ์
หลีกเลี่ยงความยุ่งเหยิง: ลดชาร์ต ใช้ฟอนต์ใหญ่ขึ้น ป้ายชัดเจน ชาร์ตสำคัญทุกชาร์ตควรแสดง Thresholds (ดี / เตือน / แย่) และสถานะปัจจุบันอ่านได้โดยไม่ต้องเอาเมาส์ชี้ ถ้าเมตริกยังไม่มีขอบเขตดี/แย่ที่ตกลงกันไว้ มันมักไม่พร้อมสำหรับหน้าแรก
การมอนิเตอร์มีประโยชน์เมื่อมันขับการกระทำที่ถูกต้อง SLO ช่วยกำหนดว่า “พอเพียง” ในแบบที่สอดคล้องกับประสบการณ์ผู้ใช้—และการแจ้งเตือนช่วยให้คุณตอบก่อนที่ลูกค้าจะสังเกต
เลือก SLI ที่ผู้ใช้สัมผัสจริง: ข้อผิดพลาด ค่าหน่วง เวลา และความพร้อมใช้งานบนเส้นทางสำคัญ เช่น การเข้าสู่ระบบ การค้นหา การชำระเงิน—not เมตริกภายใน
เมื่อเป็นไปได้ ให้แจ้งเตือนตาม อาการผลกระทบผู้ใช้ ก่อนที่จะแจ้งเตือนตามสาเหตุ:
การแจ้งเตือนตามสาเหตุยังมีค่า แต่การแจ้งเตือนตามอาการช่วยลดเสียงรบกวนและโฟกัสทีมไปที่สิ่งที่ผู้ใช้สัมผัส
เพื่อเชื่อมมอนิเตอร์สุขภาพกับ KPI ธุรกิจ ให้เพิ่มชุดการแจ้งเตือนเล็ก ๆ ที่แทนความเสี่ยงต่อรายได้หรือการเติบโต เช่น:
ผูกแต่ละการแจ้งเตือนกับ “การกระทำที่คาดหวัง”: ตรวจสอบ ถอนการปล่อย เปลี่ยนผู้ให้บริการ หรือแจ้งฝ่ายซัพพอร์ต
กำหนดระดับความรุนแรงและกฎการส่งล่วงหน้า:
ให้แน่ใจว่าทุกการแจ้งเตือนตอบคำถาม: อะไรได้รับผลกระทบ แย่แค่ไหน และควรทำอะไรต่อ?
การผสานมอนิเตอร์สุขภาพกับแดชบอร์ด KPI ทางธุรกิจเพิ่มความเสี่ยง: หน้าจอเดียวอาจแสดงอัตราข้อผิดพลาดถัดจากรายได้ churn หรือลูกค้าเฉพาะ ถ้าการจัดการสิทธิ์และความเป็นส่วนตัวทำช้าคุณจะจำกัดผลิตภัณฑ์มากเกินไป (ไม่มีใครใช้) หรือเปิดเผยข้อมูลเกินไป (ความเสี่ยงจริง)
เริ่มจากการกำหนดบทบาทรอบการตัดสินใจ ไม่ใช่องค์กรตัวเป็นๆ เช่น:
จากนั้นตั้งค่าเริ่มต้นเป็น least-privilege: ผู้ใช้ควรเห็นข้อมูลขั้นต่ำที่ต้องการ และขอสิทธิ์เพิ่มเติมเมื่อจำเป็น
จัดการ PII เป็นชั้นข้อมูลแยกต่างหากด้วยการควบคุมเข้มงวดขึ้น:
ถ้าต้องเชื่อมสัญญาณ observability กับระเบียนลูกค้า ให้ทำด้วยตัวระบุที่ไม่ใช่ PII (tenant_id, account_id) และเก็บการแมปไว้หลังการควบคุมสิทธิ์เข้มงวด
ทีมจะสูญเสียความไว้วางใจเมื่อสูตร KPI เปลี่ยนโดยเงียบๆ บันทึก:
แสดงสิ่งนี้เป็นบันทึกตรวจสอบและแนบกับวิดเจ็ตสำคัญ
ถ้าหลายทีมหรือหลายลูกค้าใช้แอป ให้วางแผน tenancy ตั้งแต่ต้น: โทเค็นที่มีสโคป, คิวรีที่ตระหนักถึง tenant, และการแยกตัวโดยค่าเริ่มต้น ง่ายกว่าการแก้ไขภายหลังเมื่อการรวม analytics และการตอบเหตุการณ์เกิดขึ้นแล้ว
การทดสอบผลิตภัณฑ์ “สุขภาพแอป + KPI” ไม่ใช่แค่เช็คว่าแผนภูมิโหลดยังไง แต่ว่าผู้คนเชื่อถือเลขหรือไม่ และสามารถลงมือได้เร็วแค่ไหน ก่อนให้ใครนอกทีมเห็น ให้ตรวจสอบความถูกต้องและความเร็วภายใต้เงื่อนไขสมจริง
ปฏิบัติต่อแอปมอนิเตอร์เป็นผลิตภัณฑ์หลักและตั้งเป้าหมาย เช่น:
รันการทดสอบด้วย "วันที่แย่จริง" ด้วย—เมตริกที่มีความหลากหลายสูง ช่วงเวลายาว และช่วงทราฟฟิกสูง
แดชบอร์ดอาจดูปกติขณะท่อข้อมูลเงียบล้มเหลว เพิ่มการเช็คอัตโนมัติและแสดงในมุมมองภายใน:
เช็คเหล่านี้ควรล้มเหลวเสียงดังในสเตจเพื่อคุณจะไม่ค้นพบปัญหาในโปรดักชัน
สร้างชุดข้อมูลสังเคราะห์ที่มีกรณีมุม: ค่าเป็นศูนย์ การสปाइक การคืนสินค้า เหตุการณ์ซ้ำ และเขตเวลา แล้ว replay รูปแบบทราฟฟิกจริงจากโปรดักชัน (พร้อมทำให้ตัวระบุไม่ระบุตัวตน) ลงในสเตจเพื่อตรวจสอบแดชบอร์ดและการแจ้งเตือนโดยไม่เสี่ยงต่อผู้ใช้จริง
สำหรับ KPI หลักแต่ละตัว กำหนดขั้นตอนความถูกต้องที่ทำซ้ำได้:
ถ้าคุณอธิบายตัวเลขให้ผู้มีส่วนได้ส่วนเสียที่ไม่ใช่เทคนิคไม่เกินหนึ่งนาทีไม่ได้ แสดงว่าไม่พร้อมส่ง
แอปที่รวม “สุขภาพ + KPI” ใช้งานได้ก็ต่อเมื่อคนเชื่อมั่น ใช้มัน และอัปเดตต่อเนื่อง ปฏิบัติต่อการเปิดตัวเหมือนการปล่อยผลิตภัณฑ์: เริ่มเล็ก พิสูจน์คุณค่า สร้างนิสัย
เลือกเส้นทางลูกค้าเดี่ยวที่ทุกคนใส่ใจ (ตัวอย่างเช่น checkout) และบริการแบ็กเอนด์ที่รับผิดชอบหลัก สำหรับสไลซ์บาง ๆ นั้น ให้ส่งมอบ:
วิธี “หนึ่งเส้นทาง + หนึ่งบริการ” ทำให้เห็นชัดว่าแอปมีไว้เพื่ออะไร และทำให้การโต้เถียงในช่วงแรกเกี่ยวกับเมตริกที่สำคัญจัดการได้ง่าย
ตั้งการทบทวนสั้น 30–45 นาที รายสัปดาห์ร่วมกับผลิตภัณฑ์ ซัพพอร์ต และวิศวกรรม รักษาให้อยู่ในเชิงปฏิบัติ:
มองแดชบอร์ดที่ไม่ถูกใช้เป็นสัญญาณให้ทำให้เรียบง่าย มองการแจ้งเตือนที่มีเสียงรบกวนเป็นบั๊ก
กำหนดความรับผิดชอบ (แม้จะแชร์กัน) และรันเช็กลิสต์น้ำหนักเบารายเดือน:
เมื่อสไลซ์แรกเสถียร ขยายไปยังเส้นทางหรือบริการถัดไปด้วยรูปแบบเดิม
หากคุณต้องการไอเดียการนำไปใช้และตัวอย่าง ให้เรียกดูบล็อก หากคุณกำลังประเมินการสร้างกับการซื้อ ให้เปรียบเทียบตัวเลือกและขอบเขตในหน้าการกำหนดราคา
ถ้าคุณต้องการเร่งเวอร์ชันทำงานแรก (UI แดชบอร์ด + ชั้น API + การยืนยันตัวตน) Koder.ai สามารถเป็นจุดเริ่มต้นที่ใช้งานได้จริง—โดยเฉพาะทีมที่ต้องการ frontend React กับ backend Go + PostgreSQL พร้อมตัวเลือกส่งออกซอร์สโค้ดเมื่อพร้อมนำไปสู่เวิร์กโฟลว์วิศวกรรมมาตรฐานของคุณ
มันคือเวิร์กโฟลว์เดียว (โดยทั่วไปเป็นแดชบอร์ด + ประสบการณ์เจาะลึก) ที่คุณเห็นทั้ง สัญญาณสุขภาพทางเทคนิค (ค่าหน่วง เวลา ข้อผิดพลาด ความอิ่มตัว) และ ผลลัพธ์ทางธุรกิจ (การแปลง รายได้ การยกเลิกสมัคร) บนแกนนเวลาขณะเดียวกัน
เป้าหมายคือการเชื่อมโยง: ไม่ใช่แค่ “มีบางอย่างเสีย” แต่เป็น “ข้อผิดพลาดในการชำระเงินเพิ่มขึ้นและการแปลงลดลง” เพื่อให้คุณสามารถจัดลำดับความสำคัญการแก้ไขตามผลกระทบได้
เพราะการแก้เหตุการณ์จะง่ายขึ้นเมื่อคุณยืนยันทันทีว่าเกิด ผลกระทบต่อลูกค้า หรือไม่
แทนที่จะเดาว่า spike ของค่าหน่วงเวลาสำคัญหรือไม่ คุณสามารถตรวจสอบกับ KPI เช่น การซื้อ/นาที หรืออัตราการเปิดใช้งาน และตัดสินใจได้ว่าจะส่งเตือน ถอนการปล่อย หรือเฝ้าดูต่อไป
เริ่มจากคำถามเหตุการณ์:
จากนั้นเลือก 5–10 เมตริกสุขภาพ (ความพร้อมใช้งาน ค่าหน่วง เวลา อัตราข้อผิดพลาด ความอิ่มตัว ทราฟฟิก) และ 5–10 KPI (ลงทะเบียน การเปิดใช้งาน การแปลง รายได้ การรักษาลูกค้า) แล้วเก็บหน้าแรกให้น้อยและชัดเจน
เลือก 3–5 เส้นทางสำคัญ ที่มีผลต่อรายได้หรือการเก็บรักษาโดยตรง (เช่น การชำระเงิน/เช็คเอาต์ การเข้าสู่ระบบ การฝึกใช้งาน การค้นหา การเผยแพร่)
สำหรับแต่ละเส้นทาง กำหนด:
วิธีนี้ทำให้แดชบอร์ดสอดคล้องกับผลลัพธ์มากกว่ารายงานโครงสร้างพื้นฐาน
พจนานุกรมเมตริกช่วยป้องกันความสับสนและข้อโต้แย้ง “KPI เดียวกัน สูตรต่างกัน” สำหรับแต่ละเมตริกให้บันทึก:
ถือว่าถ้าเมตริกไม่มีเจ้าของ ให้พิจารณาว่าตกทอดเป็นสถานะล้าสมัยจนกว่าจะมีผู้ดูแล
ถ้าระบบต่างๆ ไม่สามารถแชร์ตัวระบุตัวตนที่สอดคล้องกัน คุณจะเชื่อมข้อผิดพลาดกับผลลัพธ์ไม่ได้อย่างน่าเชื่อถือ
มาตรฐานที่ควรพกพาไปทุกที่:
user_idaccount_id/org_idorder_id/invoice_idถ้าคีย์ต่างกัน ระบุแม่บทการแมปตั้งแต่เนิ่นๆ เพราะการเย็บย้อนหลังมักมีค่าใช้จ่ายสูงและผิดพลาดได้ง่าย
สถาปัตยกรรมแบ่งปันเป็นสิ่งปฏิบัติได้:
เพิ่ม data API ชั้นกลางที่คิวรีทั้งสองฝั่ง บังคับสิทธิ์ และคืน bucket/หน่วยที่สอดคล้องให้ UI
ใช้กฎนี้:
“Single pane” ไม่ได้หมายความว่าต้องเขียนซ้ำทุกอย่าง
เตือนที่ อาการ ของผลกระทบผู้ใช้ก่อน แล้วค่อยเพิ่มการเตือนที่เป็นสาเหตุ
ตัวอย่างการเตือนอาการที่ดี:
เพิ่มชุดการแจ้งเตือนที่แสดงผลกระทบทางธุรกิจ (การลดลงของการแปลง ความล้มเหลวในการชำระเงิน การลดลงของ orders/นาที) พร้อมการกระทำที่คาดหวังชัดเจน (ตรวจสอบ ถอนการปล่อย เปลี่ยนผู้ให้บริการ แจ้งฝ่ายซัพพอร์ต)
การรวมข้อมูลรายได้/KPI กับข้อมูลปฏิบัติการเพิ่มความเสี่ยงด้านความเป็นส่วนตัวและความไว้วางใจ
ควรดำเนินการ:
ใช้ตัวระบุที่ไม่ใช่ PII (เช่น ) สำหรับการเชื่อมข้ามระบบ
account_id