21 ก.ค. 2568·4 นาที
สร้างเว็บแอปสำหรับวิเคราะห์ผลกระทบจากเหตุการณ์ — ทีละขั้นตอน
เรียนรู้วิธีออกแบบและสร้างเว็บแอปที่คำนวณผลกระทบจากเหตุการณ์โดยใช้การแม็ปการพึ่งพาบริการ สัญญาณใกล้เรียลไทม์ และแดชบอร์ดที่ชัดเจนสำหรับทีม
เรียนรู้วิธีออกแบบและสร้างเว็บแอปที่คำนวณผลกระทบจากเหตุการณ์โดยใช้การแม็ปการพึ่งพาบริการ สัญญาณใกล้เรียลไทม์ และแดชบอร์ดที่ชัดเจนสำหรับทีม
ก่อนจะสร้างการคำนวณหรือแดชบอร์ด ให้ตัดสินใจก่อนว่า “ผลกระทบ” หมายถึงอะไรในองค์กรของคุณ ถ้าข้ามขั้นตอนนี้ไป คุณจะได้คะแนนที่ดูมีหลักวิทยาศาสตร์แต่ใช้การไม่ได้
ผลกระทบคือผลลัพธ์ที่วัดได้ของเหตุการณ์ต่อสิ่งที่ธุรกิจให้ความสำคัญ มิติทั่วไปได้แก่:
เลือก 2–4 มิติหลักและกำหนดให้ชัดเจน เช่น: “ผลกระทบ = ลูกค้าที่จ่ายที่ได้รับผล + นาทีความเสี่ยงของ SLA” ไม่ใช่ “ผลกระทบ = ทุกอย่างที่ดูแย่บนกราฟ”
บทบาทต่าง ๆ ต้องตัดสินใจต่างกัน:
ออกแบบผลลัพธ์ของ “ผลกระทบ” ให้แต่ละกลุ่มตอบคำถามหลักโดยไม่ต้องแปลค่าเมตริก
ตัดสินใจความหน่วงที่ยอมรับได้ “เรียลไทม์” มีค่าใช้จ่ายสูงและมักไม่จำเป็น; near-real-time (เช่น 1–5 นาที) มักเพียงพอสำหรับการตัดสินใจ
จดเป็นข้อกำหนดผลิตภัณฑ์เพราะมันมีผลต่อการรับข้อมูล การแคช และ UI
MVP ของคุณควรสนับสนุนการดำเนินการโดยตรง เช่น:
ถ้าเมตริกไม่เปลี่ยนการตัดสินใจ มันไม่น่าจะเป็น “ผลกระทบ” — มันเป็นแค่อุปกรณ์ตรวจวัด
ก่อนออกแบบหน้าจอหรือเลือกฐานข้อมูล ให้เขียนว่า "การวิเคราะห์ผลกระทบ" ต้องตอบอะไรได้ในเหตุการณ์จริง เป้าหมายไม่ใช่ความแม่นยำสมบูรณ์วันแรก แต่มุ่งผลลัพธ์ที่สม่ำเสมอ อธิบายได้ และผู้ตอบเชื่อถือได้
เริ่มด้วยข้อมูลที่คุณต้องดึงหรืออ้างอิงเพื่อคำนวณผลกระทบ:
ทีมส่วนใหญ่ไม่มีการแม็ป dependency หรือลูกค้าอย่างสมบูรณ์วันแรก ตัดสินใจว่าคุณจะให้ผู้คนป้อนอะไรด้วยตนเองเพื่อให้แอปยังคงมีประโยชน์:
ออกแบบฟิลด์พวกนี้ให้เป็นฟิลด์ชัดเจน (ไม่ใช่บันทึกอิสระ) เพื่อให้ค้นหาได้ภายหลัง
รีลีสแรกของคุณควรสร้างได้อย่างน่าเชื่อถือ:
การวิเคราะห์ผลกระทบเป็นเครื่องมือช่วยตัดสินใจ ดังนั้นข้อจำกัดสำคัญ:
เขียนข้อกำหนดเป็นข้อความที่ทดสอบได้ หากคุณตรวจสอบไม่ได้ คุณจะพึ่งพามันไม่ได้ระหว่างการล่ม
แบบจำลองข้อมูลเป็นสัญญาระหว่างการรับข้อมูล การคำนวณ และ UI ถ้าทำถูก คุณสามารถสับเปลี่ยนแหล่งข้อมูล ปรับปรุงการให้คะแนน และยังตอบคำถามเดิมได้: “อะไรเสียหาย?”, “ใครบ้างที่ได้รับผล?”, “นานเท่าไร?”
อย่างน้อย ให้มีเรคคอร์ดชั้นแรกเหล่านี้:
รักษา ID ให้คงที่และสอดคล้องข้ามแหล่งข้อมูล ถ้ามี service catalog อยู่แล้ว ให้ใช้เป็นแหล่งความจริงและแม็ปตัวระบุจากเครื่องมือภายนอกเข้าไป
เก็บ timestamp หลายค่าใน incident เพื่อรองรับการรายงานและการวิเคราะห์:
เก็บ หน้าต่างเวลา ที่คำนวณได้สำหรับการให้คะแนนผลกระทบ (เช่น บั๊กล 5 นาที) เพื่อให้การเล่นซ้ำและการเปรียบเทียบเป็นเรื่องตรงไปตรงมา
แบบจำลองสองกราฟหลัก:
รูปแบบเรียบง่ายคือ customer_service_usage(customer_id, service_id, weight, last_seen_at) เพื่อให้คุณสามารถจัดอันดับผลกระทบตาม “ลูกค้าใช้บริการมากน้อยแค่ไหน”
Dependency มีวิวัฒนาการ และการคำนวณผลกระทบควรสะท้อนสิ่งที่เป็น ในขณะนั้น เพิ่มการมีผลบังคับใช้ (effective dating) ให้กับขอบเชื่อม:
dependency(valid_from, valid_to)ทำเช่นเดียวกันกับ subscription ของลูกค้าและ snapshot การใช้งาน ด้วยเวอร์ชันประวัติ คุณจะสามารถเล่นซ้ำเหตุการณ์ในอดีตและรายงาน SLA ให้สอดคล้องได้
การวิเคราะห์ผลกระทบต้องอาศัยอินพุตที่ดี เป้าหมายคือดึงสัญญาณจากเครื่องมือที่คุณใช้แล้วแปลงเป็นสตรีมเหตุการณ์สากลที่แอปของคุณสามารถคิดวิเคราะห์ได้
เริ่มจากรายการแหล่งสั้น ๆ ที่บอกว่า “มีการเปลี่ยนแปลง” ในเหตุการณ์:
อย่าพยายามรับข้อมูลทุกอย่างพร้อมกัน เลือกแหล่งที่ครอบคลุมการตรวจจับ การยกระดับ และการยืนยัน
เครื่องมือต่างกันรองรับรูปแบบการรวมข้อมูลต่างกัน:
แนวทางใช้งานจริง: webhooks สำหรับสัญญาณสำคัญ บวก batch imports เพื่อเติมช่องว่าง
ปรับทุกรายการเข้ามาให้อยู่ในรูปทรง “event” เดียว ถึงแม้แหล่งจะเรียกมันว่า alert, incident, หรือ annotation ก็ตาม ขั้นต่ำให้มาตรฐาน:
คาดว่าข้อมูลจะยุ่ง ใช้คีย์ idempotency (source + external_id) เพื่อ deduplicate ยอมรับเหตุการณ์มาถึงผิดลำดับโดยเรียงตาม occurred_at (ไม่ใช่เวลา arrival) และใช้ค่าเริ่มต้นอย่างปลอดภัยเมื่อฟิลด์หาย (พร้อมติดธงตรวจสอบ)
คิว "บริการที่ไม่แม็ป" เล็ก ๆ ใน UI ป้องกันข้อผิดพลาดเงียบและทำให้ผลลัพธ์เชื่อถือได้
ถ้าแผนผัง dependency ผิด พื้นที่ผลกระทบก็จะผิด แม้ว่าสัญญาณและการให้คะแนนจะสมบูรณ์ เป้าหมายคือสร้างกราฟ dependency ที่เชื่อถือได้ทั้งระหว่างเหตุการณ์และหลังจากนั้น
ก่อนแม็ปขอบ ให้กำหนดโหนด สร้างรายการ service catalog สำหรับทุกระบบที่อาจอ้างถึงในเหตุการณ์: API, worker, data store, ผู้ให้บริการภายนอก และคอมโพเนนต์ร่วมที่สำคัญอื่นๆ
แต่ละบริการควรมีอย่างน้อย: เจ้าของ/ทีม, ชั้น/ความสำคัญ (เช่น ฝั่งลูกค้าหรือภายใน), เป้าหมาย SLA/SLO, และลิงก์ไปยัง runbooks และเอกสาร on-call (เช่น /runbooks/payments-timeouts)
ใช้แหล่งสองแบบเสริมกัน:
จัดประเภทเป็นชนิดขอบแยกกันเพื่อให้ผู้คนเข้าใจความมั่นใจ: “ประกาศโดยทีม” vs “สังเกตใน 7 วันที่ผ่านมา”
Dependency ควรมี ทิศทาง: Checkout → Payments ไม่เท่ากับ Payments → Checkout ทิศทางช่วยในการตรึกตรอง (“ถ้า Payments เสียหาย upstream ใดอาจล้ม?”)
นอกจากนี้ โมเดล hard vs soft dependencies:
ความแตกต่างนี้ป้องกันการประเมินผลกระทบเกินจริงและช่วยให้ผู้ตอบเหตุการณ์ลำดับความสำคัญได้ดีขึ้น
สถาปัตยกรรมเปลี่ยนทุกสัปดาห์ ถ้าไม่เก็บสแนปชอต คุณจะวิเคราะห์เหตุการณ์สองเดือนก่อนหน้าไม่ถูกต้อง
เก็บเวอร์ชันกราฟ dependency ตามเวลา (รายวัน, ต่อการ deploy, หรือเมื่อมีการเปลี่ยน) เมื่อคำนวณ blast radius ให้แก้ไข timestamp ของเหตุการณ์ให้เป็นสแนปชอตที่ใกล้เคียงที่สุด เพื่อให้ “ใครบ้างที่ได้รับผล” สะท้อนความจริง ณ ขณะนั้น — ไม่ใช่สถาปัตยกรรมวันนี้
เมื่อคุณเริ่มรับสัญญาณ (alerts, การเผา SLO, synthetic checks, ตั๋วลูกค้า) แอปต้องมีวิธีสม่ำเสมอที่จะเปลี่ยนอินพุตยุ่ง ๆ เป็นคำชี้แจงชัดเจน: อะไรเสียหาย แย่แค่ไหน และใครบ้างที่ได้รับผล?
MVP ใช้รูปแบบใดก็ได้จากนี้:
ไม่ว่าจะเลือกแบบใด ให้เก็บค่าระหว่างขั้นตอน (threshold hit, weights, tier) เพื่อให้คนเข้าใจ ทำไม คะแนนเกิดขึ้น
หลีกเลี่ยงการยุบทุกอย่างเป็นตัวเลขเดียวเร็วเกินไป ติดตามมิติแยกกันก่อน แล้วสรุปเป็นความรุนแรงรวม:
สิ่งนี้ช่วยให้ผู้ตอบสื่อสารได้ชัดเจน (เช่น “ใช้งานได้แต่ช้า” vs “ผลลัพธ์ไม่ถูกต้อง”)
ผลกระทบไม่ใช่แค่สุขภาพของบริการ — มันคือใครบ้างที่รู้สึกถึงมัน
ใช้ การแม็ปการใช้งาน (tenant → service, แผนลูกค้า → ฟีเจอร์, ทราฟฟิกผู้ใช้ → endpoint) แล้วคำนวณลูกค้าที่ได้รับผลภายใน หน้าต่างเวลา ที่สอดคล้องกับเหตุการณ์ (start time, mitigation time และช่วง backfill ถ้ามี)
ชัดเจนเกี่ยวกับสมมติฐาน: ตัวอย่างล็อก การประมาณทราฟฟิก หรือเทเลเมทรีบางส่วน
ผู้ปฏิบัติจะต้อง override: false-positive, rollout บางส่วน, กลุ่ม tenants ที่รู้จักจำกัด
อนุญาตการแก้ไขด้วยมือสำหรับความรุนแรง มิติ และลูกค้าที่ได้รับผล แต่ต้องบันทึก:
ร่องรอยตรวจสอบนี้รักษาความเชื่อถือในแดชบอร์ดและเร่งการทบทวนหลังเหตุการณ์
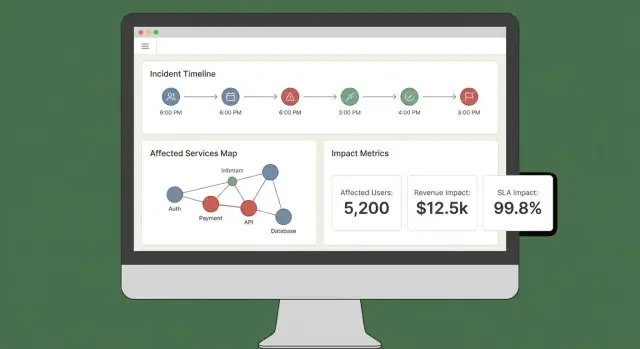
แดชบอร์ดผลกระทบที่ดีตอบคำถามสามข้อได้อย่างรวดเร็ว: อะไรได้รับผล? ใครบ้างได้รับผล? และเรามั่นใจแค่ไหน? ถ้าผู้ใช้ต้องเปิดห้าหน้าต่างเพื่อต่อเรื่อง เขาจะไม่เชื่อหรือไม่ทำตามแนะนำ
เริ่มจากมุมมองไม่กี่แบบที่อยู่เสมอและสอดคล้องกับเวิร์กโฟลว์เหตุการณ์จริง:
คะแนนผลกระทบที่ไม่มีคำอธิบายรู้สึกเป็นเชิงอารมณ์เท่านั้น ทุกคะแนนควรย้อนกลับไปยังอินพุตและกฎ:
ลิ้นชักหรือพาเนล “อธิบายผลกระทบ” แบบเรียบง่ายช่วยได้โดยไม่รกมุมมองหลัก
ให้การแยกข้อมูลตาม บริการ, ภูมิภาค, ชั้นลูกค้า, และ ช่วงเวลา ได้ง่าย ให้ผู้ใช้คลิกจุดในกราฟหรือแถวเพื่อเจาะลงไปยังหลักฐานดิบ (มอนิเตอร์ โล้ก หรือเหตุการณ์ที่ทำให้เกิดการเปลี่ยนแปลง)
ระหว่างเหตุการณ์ คนต้องการอัปเดตพกพาได้ รวมถึง:
ถ้าคุณมี status page อยู่แล้ว ให้เชื่อมโยงโดยใช้เส้นทางสัมพันธ์เช่น /status เพื่อทีมคอมส์จะอ้างอิงได้เร็ว
การวิเคราะห์ผลกระทบจะมีประโยชน์ได้ก็ต่อเมื่อผู้คนเชื่อถือ ซึ่งหมายถึงการควบคุมว่าดูอะไรได้บ้างและเก็บบันทึกการเปลี่ยนแปลงอย่างชัดเจน
กำหนดชุดบทบาทเล็ก ๆ ที่สอดคล้องกับการทำงานจริงของเหตุการณ์:
ตั้งสิทธิให้สอดคล้องกับการกระทำ ไม่ใช่ชื่อตำแหน่ง เช่น “can export customer impact report” เป็นสิทธิที่มอบให้แก่ commanders และ admin บางคนได้
การวิเคราะห์ผลกระทบมักเกี่ยวข้องกับตัวระบุบัญชี แผนสัญญา และข้อมูลติดต่อ ใช้หลัก least privilege โดยค่าเริ่มต้น:
บันทึกการกระทำสำคัญพร้อมบริบทเพียงพอสำหรับการทบทวน:
เก็บล็อกแบบ append-only พร้อม timestamp และตัวตนผู้กระทำ ทำให้ค้นหาได้ต่อเหตุการณ์เพื่อใช้งานในการทบทวนหลังเหตุการณ์
เอกสารสิ่งที่รองรับได้ตอนนี้—ระยะเวลาการเก็บ การควบคุมการเข้าถึง การเข้ารหัส และการครอบคลุมการบันทึก—และสิ่งที่อยู่ในแผนงาน
หน้าสั้น ๆ “Security & Audit” ในแอปของคุณ (เช่น /security) ช่วยตั้งความคาดหวังและลดคำถามเฉพาะหน้าในเวลาวิกฤต
การวิเคราะห์ผลกระทบมีความหมายตอนเกิดเหตุเมื่อมันขับเคลื่อนการกระทำ แอปของคุณควรทำหน้าที่เหมือน “ผู้ช่วย” ในช่องเหตุการณ์: เปลี่ยนสัญญาณที่เข้ามาเป็นอัปเดตที่ชัดเจน และเตือนเมื่อผลกระทบเปลี่ยนอย่างมีนัยสำคัญ
เริ่มจากการรวมกับที่ผู้ตอบทำงานอยู่แล้ว (มักเป็น Slack, Microsoft Teams, หรืvเครื่องมือจัดการเหตุการณ์) เป้าหมายไม่ใช่แทนที่ช่อง แต่โพสต์อัปเดตที่มีบริบทและเก็บบันทึกร่วมกัน
รูปแบบใช้งานที่เป็นไปได้: ถือช่องเหตุการณ์เป็นทั้งอินพุตและเอาต์พุต:
ถ้าคุณทำต้นแบบเร็ว ให้สร้างเวิร์กโฟลว์ end-to-end ก่อน (มุมมองเหตุการณ์ → สรุป → แจ้งเตือน) ก่อนปรับแต่งการให้คะแนน ในการพัฒนาเร็ว ๆ แพลตฟอร์มอย่าง Koder.ai สามารถช่วย: คุณสามารถวนพัฒนา UI React และ backend Go/PostgreSQL ผ่านเวิร์กโฟลว์แชท แล้วส่งออกซอร์สโค้ดเมื่อทีมเห็นพ้องว่า UX ตรงตามความจริง
หลีกเลี่ยงการแจ้งซ้ำโดยทริกเกอร์เมื่อผลกระทบข้ามเกณฑ์ที่ชัดเจน ตัวทริกเกอร์ทั่วไปได้แก่:
เมื่อข้ามเกณฑ์ ให้ส่งข้อความที่อธิบาย ทำไม (อะไรเปลี่ยน) ใคร ควรลงมือ และ ควรทำอะไรต่อไป
การแจ้งเตือนทุกฉบับควรรวมลิงก์ “ขั้นตอนถัดไป” เพื่อให้ผู้ตอบทำงานได้เร็ว:
เก็บลิงก์เหล่านี้ให้คงที่และเป็นเส้นทางสัมพันธ์เพื่อให้ทำงานข้ามสภาพแวดล้อมได้
สร้างสองรูปแบบสรุปจากข้อมูลชุดเดียว:
รองรับสรุปเรียงตามตาราง (เช่น ทุก 15–30 นาที) และการ “สร้างอัปเดต” ตามความต้องการ พร้อมขั้นตอนอนุมัติก่อนส่งภายนอก
การวิเคราะห์ผลกระทบจะมีประโยชน์เมื่อผู้คนเชื่อถือ มาตรการตรวจสอบควรพิสูจน์สองอย่าง: (1) ระบบให้ผลลัพธ์ที่เสถียร อธิบายได้ และ (2) ผลลัพธ์ตรงกับสิ่งที่องค์กรเห็นตรงกันหลังเหตุการณ์
เริ่มจากเทสต์อัตโนมัติที่ครอบคลุมสองพื้นที่ที่มักผิดพลาดมากที่สุด: ตรรกะการให้คะแนนและการรับข้อมูล
เก็บเฟิกซ์เจอร์การทดสอบให้อ่านง่าย: เมื่อใครสักคนเปลี่ยนกฎ พวกเขาควรเข้าใจว่าทำไมคะแนนเปลี่ยน
โหมด replay เป็นทางลัดสู่ความมั่นใจ รันเหตุการณ์ย้อนหลังผ่านแอปและเปรียบเทียบสิ่งที่ระบบจะแสดงตอนนั้นกับสิ่งที่ผู้ตอบสรุปล่าสุด
คำแนะนำปฏิบัติ:
เหตุการณ์จริงไม่ค่อยสะอาด ชุดการตรวจสอบควรรวมสถานการณ์เช่น:
สำหรับแต่ละกรณี ให้เทสต์ไม่เพียงคะแนน แต่รวมถึงคำอธิบาย: สัญญาณไหน และ dependency/ลูกค้าใด ที่ขับเคลื่อนผลลัพธ์
กำหนดความแม่นยำในเชิงปฏิบัติการแล้วติดตามมัน
เปรียบเทียบผลกระทบที่คำนวณได้กับผลทบทวนหลังเหตุการณ์: บริการที่ได้รับผล ระยะเวลา จำนวนลูกค้า การละเมิด SLA และความรุนแรง บันทึกความแตกต่างเป็นปัญหาการตรวจสอบ (missing data, wrong dependency, bad threshold, delayed signal)
เป้าหมายคือไม่ต้องสมบูรณ์แบบ แต่มีความประหลาดใจน้อยลงและเห็นพ้องกันได้เร็วขึ้นระหว่างเหตุการณ์
การส่งมอบ MVP สำหรับการวิเคราะห์ผลกระทบเหตุการณ์เน้นความเชื่อถือได้และวง feedback การตัดสินใจ deployment แรกควรเน้นความคล่องตัวในการเปลี่ยนแปลง ไม่ใช่สเกลทฤษฎีในอนาคต
เริ่มด้วย modular monolith เว้นแต่คุณมีทีมแพลตฟอร์มแข็งและขอบเขตบริการชัดเจน หนึ่งหน่วยที่ deploy ได้ช่วยลดความซับซ้อนการโยกย้าย ดีบัก และการทดสอบ end-to-end
แยกเป็นบริการเมื่อเกิดความเจ็บปวดจริง:
ทางสายกลางที่ใช้ได้จริงคือ หนึ่งแอป + background workers (คิว) + edge การรับข้อมูลแยกเมื่อจำเป็น
ถ้าต้องการเคลื่อนไหวเร็วโดยไม่ผูกมัดแพลตฟอร์มใหญ่ Koder.ai ช่วยเร่ง MVP: เวิร์กโฟลว์ "vibe-coding" แบบแชทเหมาะกับการสร้าง UI React, API Go, และโมเดลข้อมูล PostgreSQL พร้อมสแนปชอต/rollback ขณะปรับกฎการให้คะแนนและเวิร์กโฟลว์
ใช้ ฐานข้อมูลเชิงสัมพันธ์ (Postgres/MySQL) สำหรับเอนทิตีหลัก: incidents, services, customers, ownership, และสแนปชอตผลกระทบที่คำนวณแล้ว สอบถามง่าย ตรวจสอบได้ และพัฒนาได้สะดวก
สำหรับสัญญาณปริมาณมาก (metrics, เหตุการณ์จาก logs) เพิ่ม time-series store หรือ storage แบบคอลัมน์เมื่อการเก็บและการคำนวณรวบยอดแพงใน SQL
พิจารณา graph database เฉพาะเมื่อคำถาม dependency เป็นคอขวดหรือโมเดล dependency ไดนามิกมาก ทีมส่วนใหญ่ไปได้ไกลด้วยตาราง adjacency บวกแคช
แอปวิเคราะห์ผลกระทบกลายเป็นส่วนหนึ่งของชุดเครื่องมือจัดการเหตุการณ์ ดังนั้นใส่ instrumentation เหมือนซอฟต์แวร์โปรดักชัน:
แสดงมุมมอง “health + freshness” ใน UI เพื่อให้ผู้ตอบเชื่อถือ (หรือสงสัย) ตัวเลข
กำหนดขอบเขต MVP ให้ชัด: ชุดเครื่องมือเล็ก ๆ เพื่อรับข้อมูล ชุดคะแนนผลกระทบที่ชัด และแดชบอร์ดที่ตอบ “ใครบ้างได้รับผลและมากแค่ไหน” จากนั้นวนปรับปรุง:
ปฏิบัติต่อโมเดลเป็นผลิตภัณฑ์: ทำเวอร์ชัน มิเกรตอย่างปลอดภัย และเอกสารการเปลี่ยนแปลงสำหรับการทบทวนหลังเหตุการณ์
ผลกระทบคือ ผลลัพธ์ที่วัดได้ ของเหตุการณ์ที่มีต่อตัวชี้วัดทางธุรกิจที่สำคัญ
คำนิยามเชิงปฏิบัติระบุ 2–4 มิติหลัก (เช่น ลูกค้าที่จ่ายได้รับผลกระทบ + นาทีความเสี่ยงของ SLA) และชัดเจนว่าจะไม่รวม “สิ่งที่ดูแย่บนกราฟ” ซึ่งช่วยให้ผลลัพธ์เชื่อมโยงกับการตัดสินใจ ไม่ใช่แค่อุปกรณ์ตรวจวัด
เลือกมิติที่แผนการปฏิบัติการของทีมจะใช้ใน 10 นาทีแรก
มิติที่เหมาะสมกับ MVP ที่พบบ่อย:
จำกัดให้เหลือ 2–4 มิติเพื่อให้การให้คะแนนยังอธิบายได้
ออกแบบผลลัพธ์ให้แต่ละบทบาทตอบคำถามหลักได้โดยไม่ต้องแปลค่าตัวชี้วัด:
ถ้าตัวชี้วัดใดใช้ไม่ได้กับบทบาทเหล่านี้ ให้ถือว่าไม่ใช่ “ผลกระทบ”
“เรียลไทม์” มักมีค่าใช้จ่ายสูง; ทีมหลายแห่งพอใจกับ near-real-time (1–5 นาที)
เขียนเป้าหมายด้านความหน่วงเวลาเป็นข้อกำหนดเพราะมันส่งผลต่อ:
และแสดงสถานะความสดของข้อมูลใน UI (เช่น “ข้อมูลสด ณ 2 นาทีที่แล้ว”)
เริ่มจากการระบุ การตัดสินใจ ที่ผู้ตอบเหตุการณ์ต้องทำ แล้วทำให้แต่ละผลลัพธ์รองรับหนึ่งการตัดสินใจ:
ถ้าตัวชี้วัดไม่เปลี่ยนการตัดสินใจ ให้เก็บไว้เป็นเทเลเมทรีไม่ใช่ผลกระทบ
อินพุตขั้นต่ำที่ต้องมีมักรวมถึง:
อนุญาตฟิลด์ที่สามารถแก้ไขได้อย่างชัดเจนเพื่อให้แอปยังใช้ได้เมื่อข้อมูลหายหรือสัญญาณผิดพลาด:
บังคับเก็บว่าใคร/เมื่อไหร่/ทำไม เพื่อรักษาความเชื่อมั่น
MVP ที่เชื่อถือได้ควรสร้างได้:
ทางเลือกเพิ่มเติม: ประมาณค่าใช้จ่าย (เครดิต SLA, ภาระซัพพอร์ต, ความเสี่ยงรายได้) พร้อมช่วงความมั่นใจ
เปลี่ยนทุกรายการเข้ามาเป็นรูปแบบ "event" เดียวเพื่อให้การคำนวณสอดคล้อง
อย่างน้อยให้มีมาตรฐาน:
occurred_at, detected_at, เริ่มจากเรียบง่ายและอธิบายได้:
เก็บค่าระหว่างขั้นตอน (ว่าชนเกณฑ์ไหน, น้ำหนัก, ชั้น) เพื่อให้คนเห็นว่า ทำไมคะแนนถึงเปลี่ยน
ชุดข้อมูลนี้เพียงพอที่จะคำนวณว่า “อะไรเสียหาย”, “ใครบ้างที่ได้รับผลกระทบ” และ “นานเท่าไร”
resolved_atservice_id) ที่แปลงจากแท็ก/ชื่อของเครื่องมือsource + payload ดิบต้นฉบับ (เพื่อการตรวจสอบ/ดีบัก)จัดการข้อมูลยุ่งด้วยคีย์ idempotency (source + external_id) และทนทานต่อเหตุการณ์มาถึงผิดลำดับโดยเรียงตาม occurred_at