26 ส.ค. 2568·3 นาที
การสร้างผลิตภัณฑ์ AI-First โดยให้โมเดลเป็นตรรกะของแอป
คู่มือปฏิบัติ: สร้างผลิตภัณฑ์ AI-first โดยให้โมเดลเป็นส่วนของตรรกะแอป — สถาปัตยกรรม prompt เครื่องมือ ข้อมูล การประเมิน ความปลอดภัย และการมอนิเตอร์
ความหมายของการสร้างผลิตภัณฑ์แบบ AI-First
การสร้าง "ผลิตภัณฑ์ AI-first" ไม่ได้หมายความว่าแค่ "เพิ่มแชทบอท" แต่หมายความว่าโมเดลเป็นส่วนจริงจังของตรรกะแอปของคุณ — เช่นเดียวกับเครื่องยนต์กฎ (rules engine), ดัชนีการค้นหา หรืออัลกอริทึมแนะนำ
แอปของคุณไม่ได้เพียงแค่ ใช้ AI; มันถูก ออกแบบโดยคำนึงถึง ว่าโมเดลจะตีความอินพุต เลือกการกระทำ และผลิตผลลัพธ์เชิงโครงสร้างที่ระบบส่วนอื่นพึ่งพา
ในทางปฏิบัติ: แทนที่จะเขียนทุกเส้นทางการตัดสินใจไว้ตายตัว ("ถ้า X ให้ทำ Y"), ให้โมเดลจัดการกับส่วนที่ไม่ชัดเจน—ภาษา, เจตนา, ความกำกวม, การจัดลำดับความสำคัญ—ในขณะที่โค้ดของคุณจัดการสิ่งที่ต้องแม่นยำ: สิทธิ์, การชำระเงิน, การเขียนฐานข้อมูล และการบังคับใช้โยบาย
เมื่อใดที่ AI-first เหมาะ (และเมื่อใดไม่เหมาะ)
AI-first เหมาะที่สุดเมื่อปัญหามี:
- อินพุตที่หลากหลาย (ข้อความอิสระ เอกสารรกๆ เป้าหมายผู้ใช้ที่ต่างกัน)
- กรณีขอบเยอะเกินกว่าที่จะเขียนกฎด้วยมือได้
- มูลค่าอยู่ที่การตัดสินใจ สรุป หรือสังเคราะห์ มากกว่าความแน่นอนแบบเป๊ะๆ
ระบบอัตโนมัติแบบใช้กฎมักเหมาะกว่าเมื่อข้อกำหนดคงที่และแม่นยำ—เช่น การคำนวณภาษี, ตรรกะสินค้าคงคลัง, การตรวจสอบคุณสมบัติ, หรือเวิร์กโฟลว์ความสอดคล้องที่ผลลัพธ์ต้องเหมือนกันทุกครั้ง
เป้าหมายผลิตภัณฑ์ที่ AI-first สนับสนุนโดยทั่วไป
ทีมมักจะนำตรรกะที่ขับเคลื่อนด้วยโมเดลมาใช้เพื่อ:
- เพิ่มความเร็ว: ร่างคำตอบ, ดึงฟิลด์, ส่งต่อคำขอได้เร็วขึ้น
- ปรับแต่งประสบการณ์: ปรับคำอธิบาย แผน หรือคำแนะนำให้เหมาะกับผู้ใช้
- สนับสนุนการตัดสินใจ: เน้นข้อแลกเปลี่ยน สร้างตัวเลือก สรุปหลักฐาน
ข้อแลกเปลี่ยนที่ต้องยอมรับ (และออกแบบรองรับ)
โมเดลอาจ ไม่คงที่ บางครั้งผิดอย่างมั่นใจ พฤติกรรมอาจเปลี่ยนตาม prompt, ผู้ให้บริการ, หรือบริบทที่เรียกคืน นอกจากนี้ยังมี ต้นทุน ต่อคำขอ, อาจเพิ่ม latency, และเสี่ยงด้าน ความปลอดภัยและความเชื่อถือ (ความเป็นส่วนตัว ผลลัพธ์อันตราย การละเมิดนโยบาย)
แนวคิดที่ถูกต้องคือ: มองโมเดลเป็นส่วนประกอบหนึ่ง ไม่ใช่กล่องคำตอบวิเศษ ปฏิบัติต่อมันเหมือน dependency ที่มีสเป็ก, โหมดความล้มเหลว, การทดสอบ และการมอนิเตอร์—เพื่อให้ได้ความยืดหยุ่นโดยไม่ต้องหวังพึ่งปาฏิหาริย์
เลือกกรณีใช้งานที่เหมาะและกำหนดความสำเร็จ
ไม่ทุกฟีเจอร์จะได้ประโยชน์จากการให้โมเดลเป็นผู้ขับเคลื่อนดีที่สุด กรณีใช้งาน AI-first ที่ดีเริ่มจากงานที่ชัดเจนและจบด้วยผลลัพธ์ที่วัดได้ซึ่งคุณติดตามเป็นสัปดาห์
เริ่มจากงาน ไม่ใช่จากโมเดล
เขียนเรื่องงานเป็นประโยคสั้น: "เมื่อ ___ ฉันต้องการ ___ เพื่อจะได้ ___" แล้วทำให้ผลลัพธ์วัดได้
ตัวอย่าง: “เมื่อฉันได้รับอีเมลลูกค้ายาว ๆ ฉันต้องการคำตอบที่เสนอซึ่งสอดคล้องกับนโยบาย เพื่อที่ฉันจะตอบภายในไม่เกิน 2 นาที” นี่ชัดเจนกว่าการพูดว่า "เพิ่ม LLM ให้กับอีเมล"
ทำแผนที่จุดตัดสินใจ
ระบุช่วงเวลาที่โมเดลจะเป็นผู้ตัดสินใจ จุดตัดสินใจเหล่านี้ควรชัดเจนเพื่อให้คุณทดสอบได้
จุดตัดสินใจทั่วไปได้แก่:
- จำแนกเจตนาและส่งไปยังเวิร์กโฟลว์ที่เหมาะสม
- ตัดสินใจว่าจะถามคำถามชี้แจงหรือดำเนินการต่อ
- เลือกเครื่องมือ (ค้นหา, ดึงข้อมูล CRM, ร่างข้อความ, สร้าง ticket)
- ตัดสินใจเมื่อใดควรยกระดับให้มนุษย์
ถ้าคุณไม่สามารถตั้งชื่อการตัดสินใจได้ แปลว่าคุณยังไม่พร้อมปล่อยฟีเจอร์ที่ขับเคลื่อนโดยโมเดล
เขียนเกณฑ์ยอมรับพฤติกรรม
ปฏิบัติต่อพฤติกรรมของโมเดลเหมือนข้อกำหนดผลิตภัณฑ์อื่น กำหนดว่า "ดี" และ "ไม่ดี" เป็นอย่างไรด้วยภาษาที่เข้าใจง่าย
ตัวอย่าง:
- ดี: ใช้นโยบายล่าสุด อ้างหมายเลขคำสั่งที่ถูกต้อง ถามคำถามชัดเจนหนึ่งข้อเมื่อขาดข้อมูล
- ไม่ดี: สร้างส่วนลดที่ไม่มีอยู่จริง อ้างถึงภูมิภาคที่ไม่รองรับ หรือตอบโดยไม่ตรวจสอบข้อมูลที่จำเป็น
เกณฑ์เหล่านี้จะเป็นพื้นฐานสำหรับชุดการประเมินของคุณในภายหลัง
ระบุข้อจำกัดแต่เนิ่น ๆ
จดข้อจำกัดที่มีผลต่อการออกแบบของคุณ:
- เวลา (เป้าหมาย latency)
- งบประมาณ (ต้นทุนต่อภารกิจ)
- การปฏิบัติตาม (การจัดการ PII, ข้อกำหนดการตรวจสอบ)
- ภาษาที่รองรับ (ภาษา น้ำเสียง ความคาดหวังทางวัฒนธรรม)
กำหนดเมตริกความสำเร็จที่ติดตามได้
เลือกชุดเมตริกเล็ก ๆ ที่ผูกกับงาน:
- อัตราการทำงานสำเร็จ
- ความแม่นยำ (หรือการปฏิบัติตามนโยบาย) ในกรณีตัวอย่างที่เป็นตัวแทน
- คะแนนพึงพอใจผู้ใช้หรือการให้ข้อเสนอแนะเชิงคุณภาพ
- เวลาที่ประหยัดได้ต่อนาทีงาน (หรือเวลาแก้ปัญหา)
ถ้าคุณวัดความสำเร็จไม่ได้ คุณจะโต้แย้งกันเรื่องความรู้สึกแทนการปรับปรุงผลิตภัณฑ์
ออกแบบการไหลของผู้ใช้ที่ขับเคลื่อนด้วย AI และขอบเขตระบบ
การไหลแบบ AI-first ไม่ใช่แค่ "หน้าจอที่เรียก LLM" แต่มันคือการเดินทางตั้งแต่ต้นจนจบที่โมเดลตัดสินใจบางอย่าง ผลิตภัณฑ์ดำเนินการอย่างปลอดภัย และผู้ใช้ยังคงทราบว่าสถานะเป็นอย่างไร
วาดแผนผังลูปตั้งแต่ต้นจนจบ
เริ่มจากการวาดพรรณนาท่อเป็นสายเรียบง่าย: inputs → model → actions → outputs
- Inputs: สิ่งที่ผู้ใช้ให้มา (ข้อความ ไฟล์ ตัวเลือก) รวมถึงบริบทแอป (ระดับบัญชี พื้นที่ทำงาน กิจกรรมล่าสุด)
- Model step: สิ่งที่โมเดลรับผิดชอบตัดสิน (จำแนก ร่าง สรุป เลือกการกระทำถัดไป)
- Actions: สิ่งที่ระบบของคุณอาจทำ (ค้นหา สร้างงาน อัพเดตระเบียน ส่งอีเมล)
- Outputs: สิ่งที่ผู้ใช้เห็น (ร่าง คำอธิบาย หน้าการยืนยัน หรือข้อผิดพลาดพร้อมแนวทางถัดไป)
แผนผังนี้ช่วยชัดเจนว่าจุดไหนยอมรับความไม่แน่นอนได้ (เช่น การร่าง) และจุดไหนที่ไม่ควรยอมรับ (เช่น การเปลี่ยนแปลงบิล)
วาดขอบเขตระบบ: โมเดลกับโค้ดที่เป็น deterministic
แยก เส้นทาง deterministic (การตรวจสิทธิ์ กฎธุรกิจ การคำนวณ การเขียนฐานข้อมูล) ออกจาก การตัดสินใจขับเคลื่อนโดยโมเดล (การตีความ การจัดลำดับ ความสามารถในการสร้างภาษาแบบธรรมชาติ)
กฎที่มีประโยชน์: โมเดลสามารถ แนะนำ แต่โค้ดต้อง ตรวจสอบ ก่อนการกระทำที่ไม่สามารถย้อนกลับได้
ตัดสินใจว่ารันโมเดลที่ไหน
เลือก runtime ตามข้อจำกัด:
- Server: เหมาะกับข้อมูลส่วนตัว เครื่องมือที่สม่ำเสมอ และบันทึกการตรวจสอบ
- Client: เหมาะสำหรับผู้ช่วยน้ำหนักเบาและความเป็นส่วนตัวจากการประมวลผลในเครื่อง แต่ควบคุมยากกว่า
- Edge: latency ดีขึ้นทั่วโลก แต่ขึ้นกับ dependency น้อยกว่า
- Hybrid: แยกการตรวจจับเจตนาแบบเร็วที่ edge และงานหนักที่เซิร์ฟเวอร์
งบประมาณ latency, ต้นทุน และสิทธิ์ข้อมูล
ตั้งงบประมาณ latency และต้นทุนต่อคำขอ (รวม retries และการเรียกเครื่องมือ) แล้วออกแบบ UX รอบ ๆ มัน (การสตรีม ผลลัพธ์แบบก้าวหน้า “ดำเนินการต่อในพื้นหลัง”)
จดแหล่งข้อมูลและสิทธิ์ที่ต้องการในแต่ละขั้นตอน: โมเดลอ่านอะไร เขียนอะไร และอะไรที่ต้องการการยืนยันจากผู้ใช้ นี่จะเป็นสัญญาสำหรับทั้งวิศวกรรมและความน่าเชื่อถือ
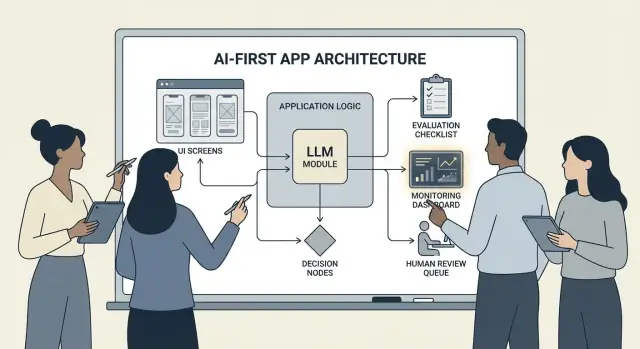
รูปแบบสถาปัตยกรรม: การออร์เคสตรา สเตท และเทรซ
เมื่อโมเดลเป็นส่วนหนึ่งของตรรกะแอปของคุณ “สถาปัตยกรรม” ไม่ได้หมายถึงแค่เซิร์ฟเวอร์และ API—แต่หมายถึงวิธีการที่คุณรันชุดการตัดสินใจของโมเดลอย่างเชื่อถือได้โดยไม่เสียการควบคุม
Orchestration: พ่อเพลงของงาน AI
Orchestration คือเลเยอร์ที่จัดการการดำเนินงานของงาน AI ตั้งแต่ต้นจนจบ: prompt และเทมเพลต การเรียกเครื่องมือ หน่วยความจำ/บริบท การ retry เวลา timeout และ fallback
Orchestrator ที่ดีปฏิบัติต่อโมเดลเป็นส่วนประกอบหนึ่งใน pipeline มันตัดสินใจว่าจะใช้ prompt ใด เมื่อใดให้เรียกเครื่องมือ (ค้นหา ฐานข้อมูล อีเมล การชำระเงิน) วิธีบีบอัดหรือดึงบริบท และทำอย่างไรหากโมเดลคืนค่าสิ่งที่ไม่ถูกต้อง
ถ้าคุณต้องการเคลื่อนจากไอเดียไปสู่ orchestration ที่ใช้งานได้เร็ว ๆ workflow แบบ vibe-coding จะช่วยให้คุณต้นแบบ pipeline เหล่านี้โดยไม่ต้องสร้างโครงแอปใหม่ทั้งหมด ตัวอย่างเช่น Koder.ai ช่วยให้ทีมสร้างเว็บแอป (React), แบ็กเอนด์ (Go + PostgreSQL), และแอปมือถือ (Flutter) ผ่านการคุย—แล้ววนปรับ flow อย่าง "inputs → model → tool calls → validations → UI" ด้วยฟีเจอร์อย่างโหมดวางแผน snapshots และ rollback พร้อมการส่งออกซอร์สโค้ดเมื่อพร้อมจะย้ายเป็น repo ของตัวเอง
เครื่องสถานะสำหรับงานหลายขั้นตอน
ประสบการณ์หลายขั้นตอน (triage → เก็บข้อมูล → ยืนยัน → ดำเนินการ → สรุป) ทำงานได้ดีเมื่อคุณมองเป็น workflow หรือ state machine
รูปแบบง่าย ๆ คือ: แต่ละขั้นมี (1) อินพุตที่อนุญาต (2) ผลลัพธ์ที่คาดหวัง (3) การเปลี่ยนสถานะ นี่จะป้องกันการคุยเถียงไปเรื่อย ๆ และทำให้กรณีขอบชัดเจน—เช่นจะเกิดอะไรขึ้นถ้าผู้ใช้เปลี่ยนใจหรือให้ข้อมูลไม่ครบ
การใช้ครั้งเดียว vs การให้เหตุผลหลายรอบ
การเรียกครั้งเดียวเหมาะกับงานที่จำกัด: จำแนกข้อความ ร่างคำตอบสั้น ดึงฟิลด์จากเอกสาร ถูกกว่า เร็วกว่า และตรวจสอบง่ายกว่า
การให้เหตุผลหลายรอบเหมาะเมื่อต้องถามคำถามชี้แจง หรือเมื่อจำเป็นต้องเรียกเครื่องมือซ้ำ ๆ (เช่น วางแผน → ค้นหา → ปรับ → ยืนยัน) ใช้ด้วยความตั้งใจและจำกัดจำนวนรอบ/เวลา
Idempotency: หลีกเลี่ยงผลข้างเคียงซ้ำ
โมเดลอาจ retry เครือข่ายล้มเหลว ผู้ใช้กดสองครั้ง ถ้าขั้นตอน AI อาจทำให้เกิดผลข้างเคียง—ส่งอีเมล จอง หรือเรียกเก็บเงิน—ทำให้มัน idempotent
กลยุทธ์ทั่วไป: แนบ idempotency key กับแต่ละการกระทำ "execute" เก็บผลลัพธ์ของการกระทำนั้น และทำให้ retries คืนค่าเดิมแทนการทำซ้ำ
เทรซ: ทำให้ทุกขั้นตอนตรวจดีบักได้
เพิ่มความสามารถในการตรวจสอบเพื่อให้ตอบได้ว่า: โมเดลเห็นอะไร? ตัดสินใจอย่างไร? เครื่องมือใดถูกเรียก?
บันทึกเทรซแบบมีโครงสร้างต่อการรันแต่ละครั้ง: เวอร์ชัน prompt อินพุต ID บริบทที่เรียกคืน คำขอ/การตอบของเครื่องมือ ข้อผิดพลาดการตรวจสอบ retry และผลสุดท้าย นี่จะเปลี่ยน "AI ทำอะไรแปลก ๆ" ให้เป็นไทม์ไลน์ที่ตรวจสอบได้และแก้ไขได้
Prompting เป็นตรรกะผลิตภัณฑ์: สัญญาชัดเจนและรูปแบบ
เมื่อโมเดลเป็นส่วนหนึ่งของตรรกะแอปของคุณ prompts หยุดเป็นแค่คำโฆษณาและกลายเป็นสเป็กที่ปฏิบัติได้ ปฏิบัติต่อพวกมันเหมือนข้อกำหนดผลิตภัณฑ์: ขอบเขตชัดเจน ผลลัพธ์ที่คาดได้ และการควบคุมการเปลี่ยนแปลง
เริ่มด้วย system prompt ที่กำหนดสัญญา
system prompt ควรกำหนดบทบาทของโมเดล สิ่งที่ทำได้และไม่ได้ และกฎความปลอดภัยที่สำคัญสำหรับผลิตภัณฑ์ของคุณ เก็บให้เสถียรและนำกลับมาใช้ได้
รวมถึง:
- บทบาทและเป้าหมาย: มันคือใคร (เช่น "ผู้ช่วยคัดแยกการสนับสนุน") และความสำเร็จคืออะไร
- ขอบเขต: คำขอที่ต้องปฏิเสธหรือยกระดับ
- กฎความปลอดภัย: การจัดการ PII คำเตือนทางการแพทย์/กฎหมาย ห้ามเดา
- นโยบายการใช้เครื่องมือ: ควรเรียกเครื่องมือเมื่อใดเทียบกับการตอบตรง ๆ
สร้างโครง prompt ด้วยอินพุต/เอาต์พุตที่ชัดเจน
เขียน prompt เหมือนนิยาม API: ระบุอินพุตที่คุณให้ (ข้อความผู้ใช้ ระดับบัญชี locale ย่อหน้าพื้นที่นโยบาย) และเอาต์พุตที่คาดหวัง เพิ่ม 1–3 ตัวอย่างที่ตรงกับทราฟฟิกจริง รวมถึงกรณียาก
รูปแบบที่มีประโยชน์คือ: Context → Task → Constraints → Output format → Examples
ใช้รูปแบบจำกัดสำหรับผลลัพธ์ที่เครื่องอ่านได้
ถ้าโค้ดต้องกระทำกับผลลัพธ์ อย่าเชื่อพรรณนา ขอเป็น JSON ที่ตรงตามสกีมาและปฏิเสธสิ่งอื่น
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
เวอร์ชัน prompt และปล่อยอย่างปลอดภัย
เก็บ prompt ในการควบคุมเวอร์ชัน ติดแท็กรีลีส และปล่อยเหมือนฟีเจอร์: การปรับทีละน้อย, A/B เมื่อเหมาะสม, และ rollback ได้เร็ว บันทึกเวอร์ชัน prompt กับแต่ละการตอบเพื่อดีบัก
สร้างชุดทดสอบ prompt
สร้างชุดกรณีเล็ก ๆ ที่เป็นตัวแทน (เส้นทางปกติ คำขอกำกวม การละเมิดนโยบาย อินพุตยาว หลายภาษา) รันอัตโนมัติเมื่อมีการเปลี่ยน prompt และล้มเหลวเมื่อตัวออกผลแตกสัญญา
การเรียกใช้เครื่องมือ: ให้โมเดลตัดสินใจ ให้โค้ดทำ
Keep full code control
Own your repo when ready by exporting source code from Koder.ai.
การเรียกเครื่องมือเป็นวิธีที่ชัดเจนที่สุดในการแยกความรับผิดชอบ: โมเดลตัดสินใจ จะทำอะไร และ จะใช้ความสามารถใด ในขณะที่โค้ดของแอปทำการกระทำนั้นและคืนผลที่ตรวจสอบแล้ว
วิธีนี้เก็บข้อเท็จจริง การคำนวณ และผลข้างเคียง (สร้าง ticket อัปเดตเรคคอร์ด ส่งอีเมล) ไว้ในโค้ดที่ deterministic และตรวจสอบได้ แทนที่จะไว้วางใจข้อความอิสระ
ออกแบบชุดเครื่องมือเล็ก ๆ และมีเจตนา
เริ่มด้วยเครื่องมือไม่กี่ตัวที่ครอบคลุม 80% ของคำขอและปลอดภัยง่าย:
- Search (เอกสาร/ฐานความรู้ของคุณ) เพื่อตอบคำถามผลิตภัณฑ์
- DB lookup (อ่านอย่างเดียวก่อน) สำหรับสถานะผู้ใช้/บัญชี/คำสั่ง
- Calculator สำหรับราคายอดรวม การแปลง และคณิตศาสตร์ตามกฎ
- Ticketing เพื่อเปิดคำร้องเมื่อต้องใช้มนุษย์ติดตาม
รักษาจุดประสงค์ของแต่ละเครื่องมือให้น้อยที่สุด เครื่องมือที่ทำ "ได้ทุกอย่าง" จะทดสอบยากและใช้ผิดง่าย
ตรวจสอบอินพุต ทำความสะอาดเอาต์พุต
ปฏิบัติต่อโมเดลเหมือนผู้เรียกที่ไม่ไว้ใจได้
- ตรวจสอบอินพุตเครื่องมือ ด้วยสกีมาที่เข้มงวด (ชนิด ค่าในช่วง enum) ปฏิเสธหรือซ่อมแซมอาร์กิวเมนต์ที่ไม่ปลอดภัย (เช่น ID ขาดหาย คำค้นกว้างเกินไป)
- ทำความสะอาดเอาต์พุตของเครื่องมือ ก่อนส่งกลับให้โมเดล: ตัดความลับ ปรับรูปแบบ และคืนเฉพาะฟิลด์ที่โมเดลต้องการ
นี่ลดความเสี่ยงจาก prompt-injection ผ่านข้อความที่เรียกคืนและจำกัดการรั่วไหลของข้อมูลโดยไม่ได้ตั้งใจ
เพิ่มสิทธิ์และอัตราจำกัดต่อเครื่องมือ
แต่ละเครื่องมือควรบังคับใช้:
- การตรวจสิทธิ์ (ใครเข้าถึงระเบียนใด ทำการใดได้)
- การจำกัดอัตรา (ต่อลูกค้า/เซสชัน/เครื่องมือ) เพื่อลดการใช้งานมากเกินไปและลูปที่ไม่หยุด
ถ้าเครื่องมือเปลี่ยนสถานะ (ticketing คืนเงิน) ต้องการการอนุญาตที่เข้มงวดกว่าและเขียนบันทึกตรวจสอบ
รองรับเส้นทาง "ไม่ใช้เครื่องมือ" เสมอ
บางครั้งการกระทำที่ดีที่สุดคือไม่ทำอะไร: ตอบจากบริบทที่มี ถามคำถามชี้แจง หรืออธิบายข้อจำกัด
ทำให้ "ไม่ใช้เครื่องมือ" เป็นผลลัพธ์ชั้นหนึ่งเพื่อไม่ให้โมเดลเรียกเครื่องมือเพียงเพื่อให้ดูเหมือนทำงาน
ข้อมูลและ RAG: ทำให้โมเดลยึดโยงกับความเป็นจริงของคุณ
ถ้าคำตอบของผลิตภัณฑ์ต้องตรงกับนโยบาย สต็อก สัญญา หรือความรู้ภายใน คุณต้องมีวิธีให้โมเดลยึดโยงกับข้อมูลของ คุณ — ไม่ใช่แค่ความรู้ที่ฝึกมา
RAG vs fine-tuning vs context แบบง่าย
- Context แบบง่าย (แปะย่อหน้าสั้น ๆ ใน prompt) เหมาะเมื่อความรู้เล็ก คงที่ และส่งได้ทุกครั้ง (เช่น ตารางราคาเล็ก)
- RAG (Retrieval-Augmented Generation) เหมาะเมื่อข้อมูลมาก เปลี่ยนบ่อย หรือต้องการการอ้างอิง (เช่น บทความศูนย์ช่วยเหลือ เอกสารผลิตภัณฑ์ ข้อมูลบัญชีเฉพาะ)
- Fine-tuning เหมาะเมื่อต้องการสไตล์/รูปแบบสม่ำเสมอหรือรูปแบบเฉพาะโดเมน — ไม่ควรใช้เป็นวิธีหลักในการ "เก็บข้อเท็จจริง" ใช้เพื่อปรับปรุงวิธีเขียนและการปฏิบัติตามกฎ; จับคู่กับ RAG เพื่อความถูกต้องล่าสุด
พื้นฐานการนำเข้า: การแบ่งชิ้น ข้อมูลเมตา ความสดใหม่
คุณภาพ RAG เป็นปัญหาการนำเข้าข้อมูลเป็นหลัก
แบ่งเอกสารเป็นชิ้นที่เหมาะกับโมเดล (มักเป็นไม่กี่ร้อยโทเค็น) โดยให้สอดคล้องกับขอบเขตตามธรรมชาติ (หัวข้อ คำถามที่พบบ่อย) เก็บ metadata เช่น ชื่อเอกสาร หัวข้อ เวอร์ชันผลิตภัณฑ์ ผู้ชม locale และสิทธิ์
วางแผนเรื่อง ความสดใหม่: กำหนดการรีอินเด็กซ์ ติดตาม "อัปเดตล่าสุด" และหมดอายุชิ้นเก่า ชิ้นข้อมูลหมดอายุที่จัดอันดับสูงจะทำให้ฟีเจอร์เสื่อมคุณภาพอย่างเงียบ ๆ
การอ้างอิงและคำตอบที่ปรับเทียบ
ให้โมเดลอ้างอิงแหล่งที่มาโดยคืน: (1) คำตอบ (2) รายการ ID ชิ้น/แหล่งที่มา และ (3) คำชี้แจงความเชื่อมั่น
ถ้าการเรียกคืนบางเบา ให้สั่งให้โมเดลพูดสิ่งที่ ไม่สามารถ ยืนยันและเสนอแนวทางต่อไป ("ผมหาเอกสารนี้ไม่พบ นี่คือผู้ที่ควรติดต่อ") หลีกเลี่ยงการให้มันเติมเต็มช่องว่าง
ข้อมูลส่วนตัว: การควบคุมการเข้าถึงและการลบข้อมูล
บังคับใช้การเข้าถึง ก่อนการเรียกคืน (กรองตามสิทธิ์ผู้ใช้/องค์กร) และอีกครั้ง ก่อนการสร้าง (ลบฟิลด์ละเอียดอ่อน)
ปฏิบัติต่อ embeddings และดัชนีเป็นที่เก็บข้อมูลที่ละเอียดอ่อนพร้อมบันทึกการตรวจสอบ
เมื่อการเรียกคืนล้มเหลว: การลดระดับอย่างสวยงาม
ถ้าผลลัพธ์ชั้นนำไม่เกี่ยวข้องหรือว่าง ให้ fallback ไปที่: ถามคำถามชี้แจง ส่งต่อให้ฝ่ายมนุษย์ หรือสลับไปยังโหมดตอบที่ไม่ใช้ RAG อธิบายข้อจำกัดแทนการเดา
ความน่าเชื่อถือ: ราวด์การ์ด การตรวจสอบ และแคช
เมื่อโมเดลอยู่ในตรรกะแอปของคุณ "พอใช้ได้ส่วนใหญ่" ไม่พอ ความน่าเชื่อถือหมายถึงผู้ใช้เห็นพฤติกรรมสม่ำเสมอ ระบบบริโภคเอาต์พุตได้อย่างปลอดภัย และความล้มเหลวลดทอนอย่างเรียบร้อย
กำหนดเป้าหมายความน่าเชื่อถือ (ก่อนเพิ่มการแก้ไข)
เขียนว่าความน่าเชื่อถือคืออะไรสำหรับฟีเจอร์:
- เอาต์พุตสม่ำเสมอ: อินพุตคล้ายกันต้องได้คำตอบที่คล้ายกัน (โทน ระดับรายละเอียด ขอบเขต)
- รูปแบบคงที่: การตอบต้องถูก parse ได้เสมอ (JSON รายการ)
- พฤติกรรมจำกัด: ขีดจำกัดชัดเจนในสิ่งที่โมเดลควรทำ (ไม่เดา อ้างแหล่งที่มา ถามคำถามเมื่อไม่แน่ใจ)
เป้าหมายเหล่านี้จะเป็นเกณฑ์ยอมรับสำหรับทั้ง prompt และโค้ด
ราวด์การ์ด: ตรวจสอบ กรอง และบังคับใช้โยบาย
ปฏิบัติต่อเอาต์พุตของโมเดลเหมือนอินพุตที่ไม่ไว้ใจได้
- การตรวจสกีมา: กำหนดรูปแบบเข้มงวด (เช่น JSON พร้อมคีย์ที่ต้องมี) และปฏิเสธสิ่งที่ parse ไม่ได้
- ตัวกรองเนื้อหา: รันการตรวจคำหยาบ ตัวตรวจ PII หรือตัววาลิเดตนโยบายทั้งบนอินพุตผู้ใช้และเอาต์พุตของโมเดล
- กฎธุรกิจ: บังคับข้อจำกัดในโค้ด (ช่วงราคา กฎคุณสมบัติ การกระทำที่อนุญาต) ถึงแม้ prompt จะกล่าวถึงสิ่งเหล่านี้
ถ้าการตรวจล้มเหลว ให้คืน fallback ที่ปลอดภัย (ถามคำถามชี้แจง สลับเทมเพลตง่าย ๆ หรือส่งต่อมนุษย์)
Retry ที่ช่วยได้จริง
หลีกเลี่ยงการทำซ้ำแบบตาบอด ลองใหม่ด้วย prompt ที่ เปลี่ยนแปลง เพื่อจัดการโหมดล้มเหลว:
- "คืนเฉพาะ JSON ที่ถูกต้อง ห้ามมี markdown"
- "ถ้าไม่แน่ใจ ให้ตั้ง
confidenceเป็นต่ำและถามคำถามหนึ่งข้อ"
จำกัด retries และบันทึกเหตุผลการล้มเหลวแต่ละครั้ง
กระบวนการหลังประมวลผลที่ deterministic
ใช้โค้ดเพื่อปรับปกติเอาต์พุตของโมเดล:
- ทำให้หน่วย เวลา และชื่อเป็นมาตรฐาน
- ลบรายการซ้ำ
- ใช้กฎการจัดอันดับหรือเกณฑ์ตัด
นี่ลดความแปรปรวนและทำให้ง่ายต่อการทดสอบ
แคชโดยไม่ทำให้เกิดปัญหาความเป็นส่วนตัว
แคชผลลัพธ์ที่ซ้ำกัน (เช่น คำถามเหมือนกัน embeddings ตอบเครื่องมือ) เพื่อลดต้นทุนและ latency
แนะนำ:
- TTL สั้นสำหรับข้อมูลเฉพาะผู้ใช้
- คีย์แคชที่ไม่รวม PII ดิบ (หรือแฮชอย่างระมัดระวัง)
- ธง "ห้ามแคช" สำหรับฟลูว์ที่ละเอียดอ่อน
ถ้าทำดี แคชจะเพิ่มความสม่ำเสมอพร้อมรักษาความเชื่อมั่นของผู้ใช้
ความปลอดภัยและความเชื่อถือ: ลดความเสี่ยงโดยไม่ทำลาย UX
Deploy your AI product
Go from prototype to a hosted app without rebuilding your project setup.
ความปลอดภัยไม่ใช่เลเยอร์ปฏิบัติตามกฎหมายที่ติดเพิ่มภายหลัง ในผลิตภัณฑ์ AI-first โมเดลอาจมีผลต่อการกระทำ คำพูด และการตัดสินใจ—ดังนั้นความปลอดภัยต้องเป็นส่วนหนึ่งของสัญญาผลิตภัณฑ์: ผู้ช่วยอนุญาตทำอะไรบ้าง ต้องปฏิเสธเมื่อไร และเมื่อไหร่ต้องขอความช่วยเหลือ
ความเสี่ยงสำคัญที่ต้องออกแบบ
ตั้งชื่อความเสี่ยงที่แอปของคุณเผชิญจริง ๆ แล้วจับคู่แต่ละข้อกับการควบคุม:
- ข้อมูลละเอียดอ่อน: ตัวบ่งชี้ส่วนบุคคล รหัสผ่าน เอกสารส่วนตัว และสิ่งที่ถูกกํากับ
- คำแนะนำอันตราย: คำแนะนำที่อาจก่อให้เกิดอันตรายตัวเอง ความรุนแรง การกระทำที่ผิดกฎหมาย หรือการกระทำทางการแพทย์/การเงินที่ไม่ปลอดภัย
- อคติและผลลัพธ์ที่ไม่เป็นธรรม: คุณภาพการบริการหรือคำแนะนำที่ไม่สม่ำเสมอข้ามกลุ่มผู้ใช้งาน
หัวข้อที่อนุญาต/จำกัด/บล็อก + เส้นทางยกระดับ
เขียนนโยบายชัดเจนที่ผลิตภัณฑ์ของคุณบังคับ ใช้ภาษาที่เป็นรูปธรรม: หมวดหมู่ ตัวอย่าง และการตอบที่คาดหวัง
ใช้สามชั้น:
- อนุญาต: ตอบตามปกติ
- จำกัด: ตอบพร้อมข้อจำกัด (เช่น ข้อมูลทั่วไปเท่านั้น ห้ามขั้นตอนแบบทีละขั้น)
- บล็อก: ปฏิเสธและส่งต่อเส้นทางยกระดับ (ฝ่ายสนับสนุน แหล่งข้อมูล หรือมนุษย์)
การยกระดับควรเป็นฟลูว์ของผลิตภัณฑ์ ไม่ใช่แค่ข้อความปฏิเสธ ให้ตัวเลือก “คุยกับคน” และให้การส่งต่อมีบริบทที่ผู้ใช้แชร์แล้ว (ด้วยความยินยอม)
การตรวจโดยมนุษย์สำหรับการกระทำที่มีผลสูง
ถ้าโมเดลสามารถก่อผลจริงได้—การชำระเงิน คืนเงิน การเปลี่ยนแปลงบัญชี การยกเลิก ลบข้อมูล—ให้เพิ่มจุดตรวจ
รูปแบบที่ดีรวมถึง: หน้าการยืนยัน, "ร่างแล้วอนุมัติ", ขีดจำกัด (วงเงิน), และคิวตรวจโดยมนุษย์สำหรับกรณีขอบ
การเปิดเผย การยินยอม และนโยบายที่ทดสอบได้
แจ้งผู้ใช้เมื่อพวกเขากำลังโต้ตอบกับ AI ข้อมูลใดถูกใช้ และสิ่งใดถูกเก็บ ขอความยินยอมเมื่อต้องการโดยเฉพาะการบันทึกการสนทนาหรือการใช้ข้อมูลเพื่อนำระบบไปปรับปรุง
ปฏิบัติต่อนโยบายความปลอดภัยภายในเหมือนโค้ด: เวอร์ชัน อธิบายเหตุผล และเพิ่มการทดสอบ (prompt ตัวอย่าง + ผลลัพธ์ที่คาดหวัง) เพื่อไม่ให้ความปลอดภัยถอยหลังเมื่อ prompt หรือโมเดลเปลี่ยน
การประเมิน: ทดสอบโมเดลเหมือนชิ้นส่วนสำคัญอื่น ๆ
ถ้า LLM สามารถเปลี่ยนสิ่งที่ผลิตภัณฑ์ของคุณทำได้ คุณต้องมีวิธีทวนซ้ำเพื่อพิสูจน์ว่ามันยังทำงาน—ก่อนที่ผู้ใช้จะค้นพบการถดถอยให้คุณ
ปฏิบัติต่อตัว prompt เวอร์ชันโมเดล สกีมเครื่องมือ และการตั้งค่า retrieval เหมือน artifacts ที่ต้องผ่านการทดสอบก่อนปล่อย
สร้างชุดประเมินจากข้อมูลจริง
เก็บเจตนาจริงจากตั๋วสนับสนุน คำค้นหา บันทึกแชท (ด้วยความยินยอม) และบันทึกการขาย แปลงเป็นกรณีทดสอบที่รวม:
- คำขอเส้นทางปกติ
- prompt กำกวมที่ต้องถามคำชี้แจง
- กรณีขอบ (ข้อมูลขาด ข้อจำกัดขัดแย้ง รูปแบบแปลก)
- สถานการณ์ที่อ่อนไหวต่อโยบาย (ข้อมูลส่วนบุคคล เนื้อหาที่ไม่อนุญาต)
แต่ละกรณีควรมีพฤติกรรมที่คาดหวัง: คำตอบ การตัดสินใจที่ทำ (เช่น "เรียกเครื่องมือ A") และโครงสร้างที่ต้องมี (ฟิลด์ JSON การอ้างอิง)
เลือกเมตริกที่สอดคล้องกับความเสี่ยงผลิตภัณฑ์
คะแนนเดียวไม่พอ ใช้ชุดเมตริกเล็ก ๆ ที่ผูกกับผลลัพธ์ผู้ใช้:
- ความแม่นยำ / ความสำเร็จของงาน: แก้ปัญหาผู้ใช้ได้หรือไม่
- ความยึดโยง: ข้ออ้างอิงได้รับการสนับสนุนด้วยบริบทหรือแหล่งข้อมูลหรือไม่
- ความถูกต้องของรูปแบบ: เอาต์พุตตรงกับสัญญา (JSON ตาราง บูลเล็ต) หรือไม่
- อัตราการปฏิเสธ: ปฏิเสธเมื่อควรหรือไม่ และไม่ปฏิเสธเมื่อไม่ควร
ติดตาม ต้นทุน และ latency พร้อมกับคุณภาพ; โมเดล "ดีกว่า" ที่เพิ่มเวลาเป็นสองเท่าอาจทำให้การแปลงลดลง
รันการประเมินออฟไลน์สำหรับการเปลี่ยนแปลงทุกครั้ง
รันการประเมินออฟไลน์ก่อนปล่อยและหลังการเปลี่ยนแปลง prompt โมเดล เครื่องมือ หรือการตั้งค่า retrieval เก็บผลลัพธ์เป็นเวอร์ชันเพื่อเปรียบเทียบและหาจุดที่เกิดปัญหาได้เร็ว
เพิ่มการทดสอบออนไลน์พร้อมราวด์การ์ด
ใช้ A/B test ออนไลน์เพื่อวัดผลลัพธ์จริง (อัตราสำเร็จ การแก้ไข คะแนนผู้ใช้) แต่เพิ่มเกราะป้องกัน: กำหนดเงื่อนไขหยุด (เช่น การเพิ่มขึ้นของเอาต์พุตไม่ถูกต้อง การปฏิเสธ กระบวนการเครื่องมือผิดพลาด) และ rollback อัตโนมัติเมื่อตัวชี้วัดเกินเกณฑ์
การมอนิเตอร์ในโปรดักชัน: การเปลี่ยนแปลง ความล้มเหลว และข้อเสนอแนะ
Build orchestration pipelines
Turn inputs to model to tool calls into a real app flow you can test end to end.
การส่งฟีเจอร์ AI-first ไม่ใช่จุดสิ้นสุด เมื่อผู้ใช้จริงเข้ามา โมเดลจะเผชิญกับสำนวนใหม่ กรณีขอบ และข้อมูลที่เปลี่ยนไป การมอนิเตอร์เปลี่ยน "ทำงานในสเตจิ้ง" ให้เป็น "ยังคงทำงานในเดือนหน้า"
บันทึกสิ่งที่สำคัญ (โดยไม่เก็บความลับ)
เก็บบริบทพอที่จะทำซ้ำการล้มเหลว: เจตนาผู้ใช้ เวอร์ชัน prompt การเรียกเครื่องมือ และเอาต์พุตสุดท้าย
บันทึกอินพุต/เอาต์พุตโดยลบข้อมูลส่วนบุคคลตามความเป็นส่วนตัว ปฏิบัติต่อบันทึกเป็นข้อมูลละเอียดอ่อน: ตัดอีเมล เบอร์โทร โทเค็น และข้อความอิสระที่อาจมีรายละเอียดส่วนตัว เก็บ "debug mode" ที่เปิดได้ชั่วคราวสำหรับเซสชันเฉพาะ แทนการบันทึกสูงสุดเป็นค่าปริยาย
ดูสัญญาณที่ใช่
มอนิเตอร์อัตราความผิดพลาด การล้มเหลวของเครื่องมือ การละเมิดสกีมา และการเปลี่ยนแปลง (drift) ติดตามอย่างเป็นรูปธรรม:
- อัตราความสำเร็จ/timeout ของการเรียกเครื่องมือ (โมเดลเลือกเครื่องมือถูกไหม และมันรันสำเร็จไหม)
- ความสอดคล้องของรูปแบบ/สกีมา (ตัวตรวจของคุณปฏิเสธบ่อยแค่ไหน)
- การใช้ fallback (บ่อยแค่ไหนที่ต้องสลับไปเส้นทางที่ปลอดภัยกว่าหรือเรียบง่ายกว่า)
- บล็อกความปลอดภัย (บ่อยแค่ไหนที่ต้องปฏิเสธหรือทำความสะอาด)
สำหรับ drift เปรียบเทราฟฟิกปัจจุบันกับ baseline: การเปลี่ยนแปลงหัวข้อ ภาษา ความยาวเฉลี่ยของ prompt และเจตนา "ไม่รู้" การเปลี่ยนแปลงไม่เสมอไปหมายถึงปัญหา—แต่เป็นสัญญาณให้ประเมินใหม่
แจ้งเตือน runbook และการตอบโต้เหตุการณ์
ตั้งเกณฑ์เตือนและ runbook ผู้รับผิดชอบ เตือนควรแมปกับการกระทำ: rollback เวอร์ชัน prompt ปิดเครื่องมือที่ไม่เสถียร เข้มงวดการตรวจสอบ หรือสลับไปที่ fallback
วางแผนการตอบเหตุการณ์สำหรับพฤติกรรมไม่ปลอดภัยหรือไม่ถูกต้อง กำหนดว่าใครสามารถเปิด/ปิดสวิตช์ความปลอดภัยอย่างไร วิธีแจ้งผู้ใช้ และจะบันทึก/เรียนรู้อย่างไรจากเหตุการณ์
ปิดวงด้วยข้อเสนอแนะผู้ใช้
ใช้ลูปข้อเสนอแนะ: นิ้วโป้งขึ้น/ลง รหัสเหตุผล รายงานบั๊ก ขอคำอธิบายสั้น ๆ ว่า "ทำไม?" (ข้อเท็จจริงผิด ไม่ทำตามคำสั่ง ไม่ปลอดภัย ช้าเกินไป) เพื่อให้คุณส่งต่อปัญหาไปยังการแก้ไขที่ถูกต้อง—prompt เครื่องมือ ข้อมูล หรือนโยบาย
UX สำหรับตรรกะที่ขับเคลื่อนโดยโมเดล: ความโปร่งใสและการควบคุม
ฟีเจอร์ที่ขับเคลื่อนโดยโมเดลดูวิเศษเมื่อมันทำงาน และเปราะบางเมื่อมันไม่ทำ UX ต้องคาดหวังความไม่แน่นอนและยังช่วยให้ผู้ใช้ทำงานเสร็จได้
แสดง "เหตุผล" โดยไม่ทำให้ผู้ใช้ล้นข้อมูล
ผู้ใช้เชื่อถือเอาต์พุตจาก AI มากขึ้นเมื่อเห็นที่มาของมัน—ไม่ใช่เพราะอยากได้คำอธิบายยืดยาว แต่เพราะช่วยพวกเขาตัดสินใจว่าจะทำอย่างไรต่อ
ใช้การเปิดเผยแบบก้าวหน้า:
- เริ่มด้วยผลลัพธ์ (คำตอบ ร่าง คำแนะนำ)
- เสนอปุ่ม "ทำไม?" หรือ "แสดงที่มา" เพื่อเผยอินพุตสำคัญ: คำขอของผู้ใช้ เครื่องมือที่ใช้ และแหล่งที่มาหรือเรคคอร์ดที่ดู ตรวจสอบให้อ่านง่าย
- ถ้าใช้การเรียกคืน ให้แสดงการอ้างอิงที่ชี้ไปยังส่วนที่เกี่ยวข้อง (เช่น "อ้างอิง: นโยบาย §3.2") ทำให้ง่ายต่อการสแกน
ถ้ามีบทความอธิบายเชิงลึก ให้เชื่อมโยงภายในด้วยข้อความ (เช่น หน้าเกี่ยวกับการยึดข้อมูล RAG) แทนยัดรายละเอียดลงใน UI
ออกแบบสำหรับความไม่แน่นอน (โดยไม่เตือนแบบน่ากลัว)
โมเดลไม่ใช่เครื่องคิดเลข อินเทอร์เฟซควรสื่อระดับความเชื่อมั่นและเชิญให้ตรวจสอบ
รูปแบบปฏิบัติได้:
- สัญญาณความเชื่อมั่นเป็นภาษาธรรมดา ("น่าจะถูก" "ต้องตรวจ") แทนความแม่นยำปลอม
- ตัวเลือกมากกว่าคำตอบเดียว: "นี่คือ 3 วิธีที่จะตอบ" เพื่อลดความเสี่ยงจากการเดาผิดครั้งแรก
- การยืนยันสำหรับการกระทำที่มีผลสูง (ส่งอีเมล ลบข้อมูล จอง) ถามคำถามชัดเจน: "ส่งข้อความนี้ไปยัง 12 ผู้รับหรือไม่?"
ทำให้การแก้ไขและการกู้คืนทำได้ง่าย
ผู้ใช้ควรปรับทิศทางผลลัพธ์ได้โดยไม่ต้องเริ่มใหม่:
- แก้ไขในบรรทัดพร้อมปุ่ม "นำการเปลี่ยนแปลงไปใช้" ให้โมเดลทำงานต่อจากการแก้ไขของผู้ใช้
- "Regenerate" พร้อมตัวควบคุม (น้ำเสียง ความยาว ข้อจำกัด) แทนการสุ่มคำตอบใหม่
- "เลิกทำ" และประวัติที่มองเห็นได้เพื่อย้อนกลับข้อผิดพลาด
ให้ทางหนีออก (escape hatch)
เมื่อโมเดลล้มเหลว—หรือผู้ใช้ไม่แน่ใจ—ให้โฟลว์ที่ deterministic หรือความช่วยเหลือจากมนุษย์
ตัวอย่าง: "สลับเป็นแบบฟอร์มด้วยมือ", "ใช้เทมเพลต", หรือ "ติดต่อ support" นี่ไม่ใช่ทางเลือกที่น่าอับอาย แต่เป็นวิธีปกป้องการสำเร็จงานและความเชื่อถือ
จากต้นแบบสู่โปรดักชัน (โดยไม่ต้องสร้างใหม่ทั้งหมด)
ทีมส่วนมากไม่ล้มเพราะ LLM ทำไม่ได้ แต่ล้มเพราะเส้นทางจากต้นแบบไปสู่ฟีเจอร์ที่เชื่อถือได้ ทดสอบได้ และมอนิเตอร์ได้นานกว่าที่คิด
วิธีปฏิบัติที่ช่วยย่นระยะทางคือการทำให้ "โครงกระดูกผลิตภัณฑ์" เป็นมาตรฐานตั้งแต่เนิ่น ๆ: state machines, สกีมเครื่องมือ, การตรวจสอบ, เทรซ และเรื่องการ deploy/rollback แพลตฟอร์มเช่น Koder.ai อาจมีประโยชน์เมื่อคุณต้องการตั้งค่าเวิร์กโฟลว์ AI-first อย่างรวดเร็ว—สร้าง UI, backend, และฐานข้อมูลพร้อมกัน—แล้ววนปรับด้วย snapshots/rollback โดเมนที่กำหนดเอง และโฮสติ้ง เมื่อพร้อมดำเนินงานจริง คุณสามารถส่งออกซอร์สโค้ดและต่อด้วยสแต็ก CI/CD และ observability ที่คุณเลือก