12 ก.ย. 2568·3 นาที
ชุดเริ่มต้นการสังเกตระบบโปรดักชันสำหรับการมอนิเตอร์วันแรก
ชุดเริ่มต้นการสังเกตระบบโปรดักชันสำหรับวันแรก: logs, metrics และ traces ขั้นต่ำที่ควรเพิ่ม พร้อมโฟลว triage ง่ายสำหรับรายงาน “มันช้า”
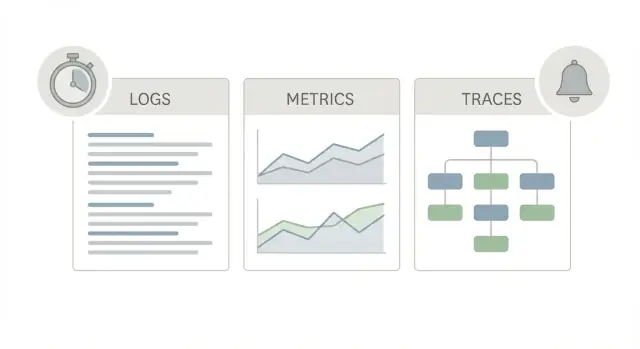
ชุดเริ่มต้นการสังเกตระบบโปรดักชันสำหรับวันแรก: logs, metrics และ traces ขั้นต่ำที่ควรเพิ่ม พร้อมโฟลว triage ง่ายสำหรับรายงาน “มันช้า”
สิ่งที่พังก่อนมักไม่ใช่ทั้งแอป แต่เป็นก้าวหนึ่งที่บังเอิญมีงานเยอะขึ้นทันที เช่น คิวรีตัวเดียวที่พอในเทสต์แต่เมื่อเจอผู้ใช้จริงเริ่มช้า หรือ dependency ตัวเดียวที่เริ่ม timeout ผู้ใช้จริงมีความหลากหลาย: โทรศัพท์ช้ากว่า, เครือข่ายไม่เสถียร, อินพุตแปลกๆ, และทราฟิกพุ่งในเวลาที่ไม่เหมาะสม
เมื่อใครสักคนบอกว่า “มันช้า” ความหมายอาจต่างกันมาก หน้าอาจโหลดช้า, การโต้ตอบหน่วง, การเรียก API ใด API หนึ่ง time out, งาน background สะสม, หรือบริการภายนอกลากทุกอย่างให้ช้า
นั่นคือเหตุผลที่คุณต้องมีสัญญาณก่อนที่ต้องมีแดชบอร์ด วันแรกคุณไม่ต้องมีชาร์ตสมบูรณ์สำหรับทุก endpoint คุณต้องมี logs, metrics, และ traces พอให้ตอบคำถามเดียวได้เร็ว: เวลาไปอยู่ที่ไหน?
มีความเสี่ยงจริงในการติดตั้งสเกลการสังเกตมากเกินไปในตอนแรก เหตุการณ์เยอะเกินไปจะกลายเป็นเสียงรบกวน, เสียค่าใช้จ่าย, และอาจทำให้แอปช้าลง แย่กว่านั้น ทีมอาจเลิกไว้ใจเทเลเมทรีเพราะมันรู้สึกรกและไม่สม่ำเสมอ
เป้าหมายวันแรกที่สมจริงคือเรียบง่าย: เมื่อได้รับรายงาน “มันช้า” คุณต้องหาก้าวที่ช้าเจอภายใน 15 นาที คุณควรรู้ได้ว่าคอขวดอยู่ที่การเรนเดอร์ฝั่งไคลเอนต์, ตัวจัดการ API และ dependency ของมัน, ฐานข้อมูลหรือแคช, หรืองาน background หรือบริการภายนอก
ตัวอย่าง: flow เช็คเอาต์ใหม่รู้สึกช้า แม้ไม่มีเครื่องมือมากมาย คุณยังต้องบอกได้ว่า “95% ของเวลาไปอยู่ที่การเรียกผู้ให้บริการชำระเงิน” หรือ “คิวรีตะกร้าสแกนแถวมากเกิน” ถ้าคุณสร้างแอปเร็วด้วยเครื่องมืออย่าง Koder.ai ระดับพื้นฐานวันแรกนี้สำคัญยิ่งขึ้น เพราะการส่งมอบเร็วมีประโยชน์ก็ต่อเมื่อคุณดีบักได้เร็วเช่นกัน
ชุดเริ่มต้น observability ที่ดีใช้มุมมองสามแบบของแอปเดียวกัน เพราะแต่ละแบบตอบคำถามต่างกัน
Logs คือเรื่องเล่า บอกคุณว่าเกิดอะไรขึ้นสำหรับคำขอหนึ่งคำขอ, ผู้ใช้หนึ่งคน, หรืองาน background หนึ่งงาน บรรทัดล็อกอาจบอกว่า “payment failed for order 123” หรือ “DB timeout after 2s” พร้อมรายละเอียดเช่น request ID, user ID, และข้อความข้อผิดพลาด เมื่อมีรายงานปัญหาแปลกๆ หนึ่งครั้ง logs มักเป็นวิธีเร็วที่สุดในการยืนยันว่ามันเกิดขึ้นและใครได้รับผลกระทบ
Metrics คือสกอร์บอร์ด เป็นตัวเลขที่คุณสามารถเทรนด์และตั้งการแจ้งเตือนได้: อัตราการร้องขอ, อัตราข้อผิดพลาด, latency percentiles, CPU, ความลึกคิว เมตริกบอกคุณว่าสิ่งที่เกิดนั้นหายากหรือแพร่หลาย และกำลังแย่ลงไหม ถ้า latency พุ่งสำหรับทุกคนตอน 10:05 metrics จะบอก
Traces คือแผนที่ trace ติดตามคำขอเดียวขณะที่มันเดินทางผ่านระบบของคุณ (web -> API -> database -> third-party) มันแสดงว่าส่วนไหนใช้เวลาเท่าไรเป็นขั้นตอน ๆ นั่นสำคัญเพราะ “มันช้า” แทบจะไม่เคยเป็นปริศนาใหญ่ชิ้นเดียว มันมักเป็น hop เดียวที่ช้า
ในเหตุการณ์ โฟลวที่เป็นไปได้คือ:
กฎง่าย ๆ: ถ้าคุณชี้คอขวดไม่ได้หลังไม่กี่นาที คุณไม่ต้องการการแจ้งเตือนเพิ่ม คุณต้องการ traces ที่ดีกว่า และ IDs ที่สอดคล้องต่อเนื่องที่เชื่อม traces กับ logs ได้
เหตุการณ์ส่วนใหญ่ที่บอกว่า “เราไม่หาไม่เจอ” ไม่ได้เกิดจากข้อมูลหาย มักเกิดเพราะสิ่งเดียวกันถูกบันทึกต่างกันข้ามบริการ ข้อตกลงร่วมบางอย่างในวันแรกทำให้ logs, metrics, และ traces จับคู่เมื่อต้องการคำตอบเร็ว
เริ่มด้วยการเลือกชื่อบริการหนึ่งชื่อต่อหน่วยที่ดีพลอยและรักษาให้คงที่ ถ้า “checkout-api” กลายเป็น “checkout” ในครึ่งหนึ่งของแดชบอร์ด คุณจะเสียประวัติและทำให้การแจ้งเตือนพัง ทำแบบเดียวกันกับฉลาก environment เลือกชุดเล็ก ๆ เช่น prod และ staging และใช้งานให้ทั่ว
ถัดไป ทำให้การติดตามคำขอทุกคำขอเป็นเรื่องง่าย สร้าง request ID ที่ขอบ (API gateway, web server, หรือ first handler) และส่งต่อมันผ่านการเรียก HTTP, message queues, และงาน background ถ้าตั๋วซัพพอร์ตบอกว่า “มันช้าเวลาตอน 10:42” ID เดียวช่วยให้คุณดึง logs และ trace ที่แน่นอนได้โดยไม่เดา
ชุดข้อตกลงที่ใช้งานได้ดีในวันแรก:
ตกลงเรื่องหน่วยเวลาแต่แรก เลือก milliseconds สำหรับ latency ของ API และ seconds สำหรับงานยาวกว่า และยึดตามมัน หน่วยผสมทำให้ชาร์ตดูโอเคแต่เล่าเรื่องผิด
ตัวอย่างชัดเจน: ถ้า API ทุกตัวล็อก duration_ms, route, status, และ request_id รายงานเช่น “checkout ช้าสำหรับ tenant 418” จะกลายเป็นการกรองที่เร็ว ไม่ใช่การถกเถียงว่าจะเริ่มจากไหน
ถ้าทำได้อย่างเดียวในชุดเริ่มต้น observability ให้ทำให้ logs ค้นหาได้ง่าย นั่นเริ่มจาก structured logs (มักเป็น JSON) และฟิลด์เหมือนกันข้ามทุกบริการ ข้อความโล่ง ๆ เพียงพอสำหรับ dev ท้องถิ่น แต่จะกลายเป็นเสียงรบกวนเมื่อมีทราฟิกจริง, การ retry, และหลายอินสแตนซ์
กฎดี ๆ: บันทึกสิ่งที่คุณจะใช้จริงในเหตุการณ์ ทีมส่วนใหญ่ต้องตอบได้ว่า: นี่คือคำขออะไร? ใครทำมัน? ล้มเหลวที่ไหน? แตะอะไรบ้าง? ถ้าบรรทัดล็อกไม่ได้ช่วยตอบข้อใดข้อหนึ่งนี้ มันน่าจะไม่ควรอยู่
วันแรกเก็บชุดฟิลด์เล็ก ๆ และสม่ำเสมอเพื่อให้กรองและ join เหตุการณ์ข้ามบริการได้:
เมื่อเกิดข้อผิดพลาด ให้ล็อกครั้งเดียวพร้อมคอนเท็กซ์ รวม error type (หรือ code), ข้อความสั้น, stack trace สำหรับข้อผิดพลาดของเซิร์ฟเวอร์, และ dependency ที่เกี่ยวข้อง (เช่น: postgres, payment provider, cache) หลีกเลี่ยงการทำซ้ำ stack trace เดิมในทุก retry แทนให้แนบ request_id เพื่อให้ติดตามโซ่เหตุการณ์ได้
ตัวอย่าง: ผู้ใช้รายงานบันทึกการตั้งค่าไม่ได้ การค้นหาโดย request_id หนึ่งครั้งแสดง 500 บน PATCH /settings แล้วมี timeout downstream ไปยัง Postgres พร้อม duration_ms คุณไม่ต้องการ payload เต็ม ๆ แค่ route, user/session, และชื่อ dependency ก็พอ
ความเป็นส่วนตัวเป็นส่วนหนึ่งของ logging ไม่ใช่งานภายหลัง อย่าบันทึกรหัสผ่าน, โทเค็น, auth headers, body ครบ หรือ PII ที่อ่อนไหว ถ้าต้องระบุตัวผู้ใช้ ให้บันทึก ID คงที่ (หรือค่าแฮช) แทนที่จะเป็นอีเมลหรือเบอร์โทร
ถ้าคุณสร้างแอปบน Koder.ai (React, Go, Flutter) คุ้มค่าที่จะฝังฟิลด์เหล่านี้ในทุกบริการที่สร้างตั้งแต่เริ่ม เพื่อไม่ต้องมาทำ “แก้ไข logging” ตอนเกิด incident แรก
ชุดเริ่มต้น observability ที่ดีเริ่มจากเมตริกชุดเล็กที่ตอบคำถามหนึ่งอย่างเร็ว: ระบบยังสุขภาพดีไหมตอนนี้ และถ้าไม่ ที่ไหนมีปัญหา?
ปัญหาในโปรดักชันส่วนใหญ่ปรากฏเป็นหนึ่งในสี่ “สัญญาณทองคำ”: latency (การตอบช้า), traffic (โหลดเปลี่ยน), errors (ล้มเหลว), และ saturation (ทรัพยากรร่วมเต็ม) ถ้าคุณเห็นสัญญาณทั้งสี่นี้ต่อส่วนหลักของแอป คุณจะสามารถไตรเอจเหตุการณ์ส่วนใหญ่โดยไม่ต้องเดา
Latency ควรเป็น percentiles ไม่ใช่ค่าเฉลี่ย ติดตาม p50, p95, p99 เพื่อเห็นว่าเมื่อกลุ่มเล็กของผู้ใช้มีปัญหา สำหรับ traffic เริ่มจาก requests per second (หรือ jobs per minute สำหรับ workers) สำหรับ errors แยก 4xx กับ 5xx: 4xx ขึ้นมักหมายถึงพฤติกรรม client หรือการเปลี่ยน validation; 5xx ขึ้นชี้ไปที่แอปของคุณหรือ dependency ที่คุณเรียก Saturation คือสัญญาณว่าเราใกล้จะหมดบางอย่าง (CPU, memory, การเชื่อมต่อ DB, backlog คิว)
ชุดขั้นต่ำที่ครอบคลุมแอปส่วนใหญ่:
ตัวอย่าง: ถ้าผู้ใช้บอก “มันช้า” และ p95 ของ API พุ่งในขณะที่ traffic คงที่ ให้เช็ก saturation ถ้า pool DB พุ่งใกล้ max และ timeouts เพิ่ม คุณเจอคอขวด ถ้า DB ดูปกติแต่ queue depth เพิ่ม งาน background อาจกำลังกินทรัพยากรร่วม
ถ้าคุณสร้างแอปบน Koder.ai ให้ถือเช็คลิสต์นี้เป็นนิยาม day-one ของงานที่ต้องเสร็จ การเพิ่มเมตริกเหล่านี้ขณะที่แอปยังเล็กทำได้ง่ายกว่าตอนเกิด incident จริง
เมื่อผู้ใช้บอกว่า “มันช้า” logs บอกคุณว่าเกิดอะไรขึ้น และ metrics บอกว่ามันเกิดบ่อยแค่ไหน Traces บอกว่าตรงไหนใช้เวลาในคำขอเดียว timeline เดียวนี้เปลี่ยนคำบ่นคลุมเครือให้เป็นการแก้ไขที่ชัดเจน
เริ่มจากฝั่งเซิร์ฟเวอร์ ทำ instrumentation ที่คำขอขาเข้าตรงขอบของแอป (first handler) เพื่อให้ทุกคำขอสามารถผลิต trace ได้ ฝั่ง client tracing รอได้
Trace วันแรกที่ดีมีสแปนที่แมปกับส่วนที่มักทำให้ช้าต่อไปนี้:
เพื่อให้ traces ค้นหาและเปรียบเทียบได้ ให้จับ attribute สำคัญไม่กี่ตัวและรักษาความสม่ำเสมอข้ามบริการ
สำหรับสแปนขาเข้า ให้บันทึก route (ใช้เทมเพลต เช่น /orders/:id, ไม่ใช่ URL เต็ม), HTTP method, status code, และ latency สำหรับสแปน DB ให้บันทึกระบบ DB (PostgreSQL, MySQL), ประเภทการทำงาน (select, update), และชื่อตารางถ้าเพิ่มได้ง่าย สำหรับการเรียกภายนอก ให้บันทึกชื่อ dependency (payments, email, maps), host เป้าหมาย, และสถานะ
การ sampling สำคัญในวันแรก มิฉะนั้นค่าใช้จ่ายและเสียงรบกวนจะโตเร็ว ใช้กฎ head-based ง่าย ๆ: trace 100% ของ errors และคำขอที่ช้า (ถ้า SDK รองรับ) และ sample ส่วนน้อยของทราฟิกปกติ (ประมาณ 1–10%) เริ่มสูงเมื่อตราฟฟิกน้อย แล้วลดเมื่อปริมาณเพิ่ม
สิ่งที่เรียกว่า “ดี” คือ trace เดียวที่อ่านเรื่องราวได้จากบนลงล่าง ตัวอย่าง: GET /checkout ใช้ 2.4s, DB ใช้ 120ms, cache 10ms, และการเรียก payment ภายนอกใช้ 2.1s พร้อม retry — ตอนนี้รู้ว่าเป็นปัญหาจาก dependency ไม่ใช่โค้ดของคุณ นี่คือแก่นของชุดเริ่มต้น observability สำหรับโปรดักชัน
เมื่อมีคนบอกว่า “มันช้า” การชนะเร็วที่สุดคือเปลี่ยนอารมณ์คลุมเครือให้เป็นคำถามชัด ๆ โฟลว triage ในชุดเริ่มต้นนี้ใช้ได้แม้แอปคุณยังใหม่
เริ่มด้วยการจำกัดปัญหา แล้วตามหลักฐานตามลำดับ อย่ากระโดดไปหา database ก่อน
หลังจากทำให้เสถียร ทำการปรับปรุงเล็ก ๆ หนึ่งอย่าง: จดบันทึกสิ่งที่เกิดขึ้นและเพิ่มสัญญาณที่ขาด เช่น ถ้าคุณไม่รู้ว่าการช้าจำกัดแค่ภูมิภาคเดียว ให้เพิ่มแท็ก region ในเมตริก latency ถ้าเห็นสแปน DB ยาวแต่ไม่รู้ว่าเป็นคิวรีไหน ให้เพิ่มป้ายชื่อคิวรีอย่างระมัดระวัง หรือฟิลด์ “query name” เล็ก ๆ
ตัวอย่างเร็ว: ถ้า checkout p95 กระโดดจาก 400 ms เป็น 3 s และ traces แสดงสแปน 2.4 s ในการเรียก payment คุณสามารถหยุดการถกเถียงเกี่ยวกับโค้ดและมุ่งที่ผู้ให้บริการ, retries, และ timeouts ได้
เมื่อใครสักคนบอกว่า “มันช้า” คุณอาจเสียเวลาหนึ่งชั่วโมงแค่หาให้ตรงความหมาย ชุดเริ่มต้น observability มีประโยชน์เฉพาะเมื่อช่วยจำกัดปัญหาได้เร็ว
เริ่มด้วยคำถามชัด ๆ สามข้อ:
แล้วดูตัวเลขไม่กี่ตัวที่มักบอกทิศทางต่อไป อย่าหาแดชบอร์ดที่สมบูรณ์แบบ แค่อยากสัญญาณว่า “แย่กว่าปกติ”:
ถ้า p95 ขึ้นแต่ errors คงที่ ให้เปิด trace หนึ่งอันของ route ที่ช้าที่สุดใน 15 นาทีที่ผ่านมา trace เดียวมักบอกว่าเวลาไปกับ DB, การเรียกภายนอก, หรือรอล็อก
แล้วทำการค้นหา log หนึ่งครั้ง ถ้ามีรายงานผู้ใช้เฉพาะ ค้นหาโดย request_id (หรือ correlation ID) และอ่านไทม์ไลน์ ถ้าไม่มี ให้ค้นหาข้อความผิดพลาดที่พบบ่อยที่สุดในหน้าต่างเวลาเดียวกันและดูว่ามันตรงกับการช้าหรือไม่
สุดท้ายตัดสินใจว่าจะบรรเทาตอนนี้หรือลงลึกต่อ ถ้าผู้ใช้ถูกบล็อกและ saturation สูง การ mitigation ด่วน (scale up, rollback, หรือปิด feature flag ที่ไม่สำคัญ) ซื้อเวลาได้ ถ้าผลกระทบน้อยและระบบเสถียร ให้สืบต่อด้วย traces และ slow query logs
หลังรีลีสไม่กี่ชั่วโมง ตั๋วซัพพอร์ตเข้ามา: “เช็คเอาต์ใช้เวลา 20–30 วินาที” ไม่มีใครเลียนแบบได้บนแลปท็อป — นี่คือที่ชุดเริ่มต้นจ่ายผล
แรก ดู metrics ยืนยันอาการ: p95 latency สำหรับ HTTP แสดง spike แต่เฉพาะ POST /checkout เส้นอื่นปกติ และ error rate คงที่ นั่นจำกัดปัญหาจาก "ทั้งไซต์ช้า" เหลือ "endpoint เดียว" หลังรีลีส
ต่อมา เปิด trace ของ POST /checkout ที่ช้า waterfall ของสแปนชี้ผู้กระทำสองอย่างที่พบบ่อย:
PaymentProvider.charge ใช้ 18 วินาที ส่วนใหญ่เป็นการรอDB: insert order ช้า แสดงการรอเป็นเวลานานก่อน query คืนค่ายืนยันด้วย logs โดยใช้ request_id จาก trace: เห็นคำเตือนซ้ำ ๆ เช่น “payment timeout reached” หรือ “context deadline exceeded” และ retries ที่เพิ่มมาในรีลีสใหม่ ถ้าเป็นทาง DB จะเห็น lock wait หรือ slow query ที่ล็อกเกิน threshold
เมื่อสัญญาณทั้งสามสอดคล้อง การแก้ไขชัดเจน:
จุดสำคัญคือคุณไม่ต้องเดา: metrics ชี้ endpoint, traces ชี้สแปนที่ช้า, logs ยืนยันโหมดความล้มเหลวพร้อม request ที่ชัดเจน
เวลาส่วนใหญ่ใน incident สูญหายกับช่องว่างที่หลีกเลี่ยงได้: ข้อมูลมีแต่ noisy, เสี่ยง, หรือขาดรายละเอียดที่เชื่อมอาการกับสาเหตุ
กับ logging กับการบันทึกมากเกินไปโดยเฉพาะ raw request bodies ฟังดูมีประโยชน์จนเริ่มเรียกเก็บพื้นที่มากเกิน, การค้นหาช้า, และอาจบันทึกรหัสผ่านหรือข้อมูลส่วนตัวโดยไม่ตั้งใจ ใช้ฟิลด์มีโครงสร้าง (route, status code, latency, request_id) และล็อกเฉพาะส่วนที่อนุญาต
กับ metrics เลเบลที่มี cardinality สูง (user IDs เต็ม อีเมล) จะระเบิดชุดซีรีส์และทำให้แดชบอร์ดรวมไม่ได้ ใช้เลเบลหยาบ ๆ (route name, HTTP method, status class, dependency name) และเก็บข้อมูลเฉพาะผู้ใช้ใน logs
ข้อผิดพลาดซ้ำ ๆ ที่กีดขวางการวินิจฉัยเร็ว:
ตัวอย่างปฏิบัติ: ถ้า checkout p95 พุ่งจาก 800ms เป็น 4s คุณอยากตอบได้สองคำถามในไม่กี่นาที: มันเริ่มทันทีหลังดีพลอยไหม และเวลาส่วนใหญ่ไปกับโค้ดคุณหรือ dependency (DB, payment provider, cache)? ด้วย percentiles, release tag, และ traces ที่มี route + dependency names คุณจะถึงคำตอบได้เร็ว ถ้าไม่มี คุณจะเผาเวลาไปกับการถกเถียง
ชัยชนะที่แท้จริงคือความสอดคล้อง ชุดเริ่มต้น observability ช่วยได้ก็ต่อเมื่อบริการใหม่ทุกตัวมาพร้อมพื้นฐานเดียวกัน ตั้งชื่อเหมือนกัน และหาง่ายเมื่อเกิดปัญหา
เปลี่ยนการตัดสินใจวันแรกเป็นเทมเพลตสั้น ๆ ที่ทีมใช้ซ้ำ ทำให้เล็กแต่เฉพาะเจาะจง
request_id สำหรับทุกคำขอขาเข้าและพกมันผ่าน logs และ tracesสร้างมุมมอง “home” เดียวที่ใครก็เปิดได้ในเหตุการณ์ หน้าจอเดียวควรแสดง requests per minute, error rate, p95 latency, และเมตริก saturation หลักของคุณ พร้อมตัวกรอง environment และ version
เริ่มต้นด้วยการตั้งการแจ้งเตือนน้อย ๆ สองอันครอบคลุมมาก: spike ของ error rate บน route สำคัญ และ spike ของ p95 latency บน route เดียวกัน ถ้าเพิ่มมากขึ้น ให้แน่ใจว่าแต่ละอันมีการกระทำชัดเจน
สุดท้าย ตั้งการทบทวนรายเดือนแบบวนซ้ำ ลบ alerts ที่เป็นเสียงรบกวน, ปรับชื่อให้คม, และเพิ่มสัญญาณที่ขาดหนึ่งอันซึ่งจะช่วยประหยัดเวลาจาก incident ก่อนหน้า
เพื่อฝังสิ่งนี้ในกระบวนการ build ของคุณ เพิ่ม “observability gate” ลงในเช็คลิสต์การปล่อย: ห้ามดีพลอยถ้ายังไม่มี request IDs, version tags, home view, และสองการแจ้งเตือนพื้นฐาน หากคุณส่งกับ Koder.ai คุณสามารถกำหนดสัญญาณวันแรกในโหมดวางแผนก่อนการดีพลอย แล้วทำซ้ำอย่างปลอดภัยด้วย snapshots และ rollback เมื่อจำเป็น
เริ่มจากจุดที่ผู้ใช้เข้าระบบเป็นที่แรก: web server, API gateway หรือ first handler ของคุณ
request_id และส่งต่อมันในทุกการเรียกภายในroute, method, status, และ duration_ms สำหรับทุกคำขอเพียงเท่านี้มักช่วยให้คุณเจอ endpoint และช่วงเวลาที่ชัดเจนได้เร็ว
ตั้งเป้าตรงนี้เป็นค่าเริ่มต้น: คุณต้องสามารถระบุขั้นตอนที่ช้าได้ภายในเวลาไม่เกิน 15 นาที
วันแรกคุณไม่จำเป็นต้องมีแดชบอร์ดสมบูรณ์แบบ แต่อยากได้สัญญาณพอจะตอบได้ว่า:
ในเหตุการณ์: ยืนยันผลกระทบด้วย metrics, หา bottleneck ด้วย traces, และอธิบายด้วย logs.
เลือกชุดกฎเล็ก ๆ แล้วใช้งานให้ทั่ว:
ตั้งค่าเริ่มต้นเป็น structured logs (เช่น JSON) โดยใช้คีย์เดียวกันทุกที่
ฟิลด์ขั้นต่ำที่ให้ผลทันที:
เริ่มจากสัญญาณ “ทองคำ” สี่อย่างต่อส่วนหลัก:
เช็คลิสต์คร่าว ๆ ต่อคอมโพเนนต์:
เริ่มจากฝั่งเซิร์ฟเวอร์ก่อน ให้คำขอขาเข้าทำให้เกิด trace ได้หนึ่งอันทุกคำขอ ฝั่ง client tracing รอได้
สแปนใน trace วันแรกที่มีประโยชน์ควรแมปกับส่วนที่มักทำให้ช้า:
เพื่อให้ค้นหาได้ เก็บ attributes สําคัญและสม่ำเสมอ: สำหรับสแปนขาเข้า ระบุ (ใช้เทมเพลต เช่น ), HTTP method, status code และ latency; สำหรับ DB ระบุระบบ DB, ประเภท operation, ชื่อตารางถ้าทำได้; สำหรับ external ระบุชื่อ dependency, host เป้าหมาย และสถานะ
ค่าเริ่มต้นเรียบง่ายและปลอดภัยคือ:
เริ่มจากเปอร์เซ็นต์สูงเมื่อทราฟิกยังน้อย แล้วลดลงเมื่อปริมาณขึ้น เป้าหมายคือรักษา traces ให้มีประโยชน์โดยไม่เพิ่มค่าใช้จ่ายหรือเสียงรบกวนจนเกินไป
ใช้โฟลวที่ทำได้ซ้ำและตามหลักฐาน:
จดสิ่งที่ขาดไปหนึ่งอย่างซึ่งจะช่วยให้ครั้งต่อไปเร็วขึ้น แล้วเพิ่มมันเป็นสัญญาณถัดไป
ข้อถามสามข้อชัด ๆ เริ่มต้นได้ภายใน 5 นาที:
แล้วดูตัวเลขไม่กี่ตัว:
หลังรีลีสไม่กี่ชั่วโมง ตั๋วซัพพอร์ตเริ่มเข้ามา: “เช็คเอาต์ใช้เวลา 20–30 วินาที” ใครก็ไม่สามารถเลียนแบบบนแลปท็อปได้ — นี่คือที่ชุดเริ่มต้นช่วยได้
ดู metrics ยืนยันอาการ: p95 latency สำหรับ HTTP แสดง spike แต่เฉพาะ POST /checkout เส้นอื่นปกติ และอัตราข้อผิดพลาดคงที่ — แคบจาก "ทั้งเว็บช้า" เหลือ "endpoint เดียวช้า"
เปิด trace สำหรับ POST /checkout ที่ช้า น้ำตกของสแปนเผยสาเหตุสองผลลัพธ์ทั่วไป:
เวลาส่วนใหญ่ในการจัดการ incident สูญหายไปกับช่องว่างที่หลีกเลี่ยงได้: ข้อมูลมีอยู่ แต่มีเสียงมาก เสี่ยง หรือขาดรายละเอียดที่เชื่อมอาการกับสาเหตุจริงๆ
กับ logging มักพลาดโดยการบันทึกมากเกินไป โดยเฉพาะ raw request bodies — ฟังดูมีประโยชน์แต่ทำให้ค่าเก็บข้อมูลสูง การค้นหาช้า และอาจเก็บรหัสผ่านหรือข้อมูลส่วนบุคคลโดยไม่ตั้งใจ ชอบฟิลด์มีโครงสร้าง (route, status code, latency, request_id) และบันทึกเฉพาะสไลซ์ของ input ที่อนุญาต
กับ metrics กับเลเบลที่มี cardinality สูง (user IDs เต็ม รูปแบบอีเมล) จะระเบิดชุดซีรีส์เมตริกและทำให้แดชบอร์ดรวมลำบาก เก็บเลเบลหยาบ ๆ ในเมตริก และเก็บรายละเอียดเฉพาะผู้ใช้ใน logs
ข้อผิดพลาดที่บ่อยและทำให้ช้า:
service_name ที่คงที่, environment (เช่น prod/staging), และ versionrequest_id ที่ขอบระบบและส่งต่อข้ามการเรียกและงานroute, method, status_code, และ tenant_id (ถ้า multi-tenant)duration_ms)จุดประสงค์คือการที่ตัวกรองเดียวใช้งานได้ข้ามบริการแทนที่จะเริ่มใหม่ทุกครั้ง
timestamp, level, service_name, environment, versionrequest_id (และ trace_id ถ้ามี)route, method, status_code, duration_msuser_id หรือ session_id (ID คงที่ ไม่ใช่อีเมล)บันทึกข้อผิดพลาดครั้งเดียวพร้อมคอนเท็กซ์ (error type/code + message + dependency name) หลีกเลี่ยงการซ้ำ stack trace ทุก retry
ตัวอย่าง: ถ้าผู้ใช้รายงาน “มันช้า” และ p95 ของ API กระโดดขึ้นในขณะที่ traffic คงที่ ให้เช็ก saturation ถ้าการใช้ pool DB ขึ้นใกล้สูงสุดและ timeouts เพิ่ม คุณเจอคอขวดแล้ว
route/orders/:idการ sampling สำคัญ: trace 100% ของข้อผิดพลาดและคำขอช้า (ถ้า SDK รองรับ) และ sample ส่วนน้อยของทราฟิกปกติ (1–10%) เริ่มสูงเมื่อทราฟิกน้อย แล้วลดเมื่อโต
ตัวอย่างที่ดี: trace เดียวอ่านเรื่องราวได้จากบนลงล่าง เช่น GET /checkout ใช้ 2.4s, DB 120ms, cache 10ms, และการเรียก payment ภายนอกใช้ 2.1s พร้อม retry — ตอนนี้รู้แล้วว่าเป็น dependency ไม่ใช่โค้ดของคุณ
ถ้า p95 ขึ้นแต่ errors คงที่ ให้เปิด trace หนึ่งอันของ route ที่ช้าที่สุดใน 15 นาทีที่ผ่านมา แล้วค้นหาไปที่ logs โดยใช้ request_id หรือค้นหา error message ที่พบบ่อยในช่วงเวลาเดียวกัน
สุดท้ายตัดสินใจว่าจะบรรเทาปัญหาตอนนี้หรือขุดลึกต่อ ถ้าผู้ใช้ถูกบล็อกและ saturation สูง ให้ mitigation เร็วๆ เช่น scale up, rollback หรือปิดฟีเจอร์ที่ไม่สำคัญ
PaymentProvider.charge ใช้ 18 วินาที รอเป็นหลักDB: insert order ช้า แสดงการรอเป็นเวลานานก่อน query จะคืนค่าrequest_id จาก trace: เห็นคำเตือนซ้ำ ๆ เช่น “payment timeout reached” หรือ “context deadline exceeded” และเห็น retries ที่เพิ่มมาหลังรีลีส ถ้าเป็นทาง DB logs อาจบอก lock wait หรือ slow query ที่เกินเกณฑ์เมื่อสัญญาณทั้งสามสอดคล้อง การแก้ไขชัดเจน:
จุดสำคัญคือคุณไม่ต้องเดา: metrics ชี้ endpoint, traces ชี้ขั้นตอนที่ช้า, logs ยืนยันโหมดความล้มเหลวและคำขอที่ชัดเจน
ตัวอย่างปฏิบัติ: ถ้า checkout p95 ขึ้นจาก 800ms เป็น 4s คุณควรตอบได้สองคำถามในไม่กี่นาที: มันเริ่มทันทีหลังดีพลอยหรือไม่ และเวลาส่วนใหญ่ไปกับแอปของคุณหรือ dependency? ด้วย percentiles, release tag, และ traces ที่มี route + dependency names คุณจะไปถึงคำตอบได้เร็ว