23 เม.ย. 2568·3 นาที
ฐานข้อมูลเวกเตอร์ขับเคลื่อนการค้นหาเชิงความหมายสำหรับแอป AI
เรียนรู้ว่าฐานข้อมูลเวกเตอร์จัดเก็บอิมเบดดิ้งอย่างไร ทำการค้นหาความคล้ายได้เร็ว และรองรับการค้นหาเชิงความหมาย แชทบอท RAG คำแนะนำ และแอป AI อื่นๆ
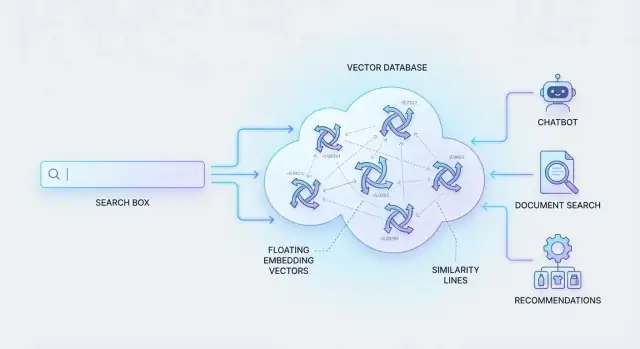
เรียนรู้ว่าฐานข้อมูลเวกเตอร์จัดเก็บอิมเบดดิ้งอย่างไร ทำการค้นหาความคล้ายได้เร็ว และรองรับการค้นหาเชิงความหมาย แชทบอท RAG คำแนะนำ และแอป AI อื่นๆ
การค้นหาเชิงความหมายเป็นวิธีการค้นหาที่เน้นสิ่งที่คุณ หมายถึง มากกว่าคำที่คุณพิมพ์อย่างเป๊ะๆ
ถ้าคุณเคยค้นหาแล้วคิดว่า “คำตอบชัดเจนมาก—ทำไมมันหากไม่เจอ?” คุณกำลังเผชิญขีดจำกัดของการค้นหาด้วยคีย์เวิร์ด ดั้งเดิมการค้นหาจะจับคู่คำศัพท์ ซึ่งใช้ได้เมื่อคำในคำค้นและคำในเนื้อหาทับซ้อนกัน
การค้นหาด้วยคีย์เวิร์ดเจอปัญหากับ:
มันยังอาจให้ค่าน้ำหนักกับคำที่ซ้ำบ่อย จนคืนผลที่ดูเหมือนเกี่ยวข้องแต่ไม่ใช่หน้าที่ตอบคำถามด้วยถ้อยคำต่างกัน
จินตนาการศูนย์ช่วยเหลือที่มีบทความชื่อ “Pause or cancel your subscription.” ผู้ใช้ค้นหา:
"stop my payments next month"
ระบบคีย์เวิร์ดอาจไม่จัดอันดับบทความนั้นสูงถ้ามันไม่มีคำว่า “stop” หรือ “payments” การค้นหาเชิงความหมายออกแบบมาเพื่อเข้าใจว่า “stop my payments” เกี่ยวข้องอย่างใกล้ชิดกับ “cancel subscription” และจะนำบทความนั้นขึ้นมาด้านบน—เพราะความหมายตรงกัน
เพื่อให้สิ่งนี้ทำงาน ระบบจะแทนเนื้อหาและคำค้นเป็น “ลายนิ้วมือความหมาย” (ตัวเลขที่จับความคล้าย) แล้วต้องค้นผ่าน ล้านๆ ลายนิ้วมือนี้อย่างรวดเร็ว
นั่นคือสิ่งที่ ฐานข้อมูลเวกเตอร์ ถูกสร้างมาเพื่อ: เก็บการแทนความหมายเชิงตัวเลขเหล่านี้และดึงรายการที่คล้ายที่สุดอย่างมีประสิทธิภาพ เพื่อให้การค้นหาเชิงความหมายรู้สึกทันทีแม้ในระดับใหญ่
อิมเบดดิ้ง คือการแทนความหมายเป็นตัวเลข แทนที่จะอธิบายเอกสารด้วยคีย์เวิร์ด คุณจะแทนมันเป็นชุดตัวเลข ("เวกเตอร์") ที่จับใจความของเนื้อหา สองชิ้นเนื้อหาที่มีความหมายใกล้เคียงกันจะมีเวกเตอร์ที่อยู่ใกล้กันในช่องเชิงตัวเลขนั้น
คิดว่าอิมเบดดิ้งเหมือนพิกัดบนแผนที่มิติสูง คุณมักจะไม่อ่านตัวเลขเหล่านั้นโดยตรง—มันไม่ใช่สำหรับมนุษย์ คุณค่าของมันอยู่ที่พฤติกรรม: ถ้า “cancel my subscription” กับ “how do I stop my plan?” ให้เวกเตอร์ที่ใกล้กัน ระบบจะถือว่ามันเกี่ยวข้องกันแม้จะไม่มีคำซ้ำกันเลย
อิมเบดดิ้งไม่ได้จำกัดแค่ข้อความ
นี่คือวิธีที่ฐานข้อมูลเวกเตอร์เดียวสามารถรองรับ “ค้นหาด้วยรูปภาพ”, “หาบทเพลงที่คล้ายกัน” หรือ “แนะนำสินค้าที่เหมือนกัน”
เวกเตอร์ไม่ได้มาจากการติดแท็กด้วยมือ แต่ผลิตโดยโมเดลแมชชีนเลิร์นนิงที่ฝึกให้ย่อความหมายเป็นตัวเลข คุณส่งเนื้อหาไปยังโมเดลอิมเบดดิ้ง (โฮสต์โดยคุณหรือผู้ให้บริการ) แล้วมันคืนเวกเตอร์มา แอปของคุณเก็บเวกเตอร์นั้นไว้พร้อมกับเนื้อหาต้นฉบับและเมตาดาต้า
โมเดลอิมเบดดิ้งที่คุณเลือกมีผลโดยตรงต่อผลลัพธ์ โมเดลขนาดใหญ่หรือเฉพาะทางมักให้ความเกี่ยวข้องดีขึ้นแต่มีค่าใช้จ่ายสูงกว่า (และอาจช้ากว่า) โมเดลขนาดเล็กถูกกว่าและเร็วกว่าบางครั้งแต่จะพลาดความหมายเชิงละเอียด—โดยเฉพาะกับภาษาเฉพาะโดเมน หลายทีมมักทดสอบโมเดลหลายตัวตั้งแต่ต้นเพื่อหาจุดสมดุลก่อนจะสเกลต่อ
แนวคิดพื้นฐานของฐานข้อมูลเวกเตอร์คือ: เก็บ “ความหมาย” (เวกเตอร์) พร้อมข้อมูลที่คุณต้องใช้เพื่อระบุ กรอง และแสดงผล
ระเบียนส่วนใหญ่มีลักษณะดังนี้:
doc_18492 หรือ UUID)ตัวอย่าง บทความศูนย์ช่วยเหลืออาจเก็บ:
kb_123{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }เวกเตอร์คือสิ่งที่ขับเคลื่อนความคล้ายเชิงความหมาย ID และเมตาดาต้าคือสิ่งที่ทำให้ผลลัพธ์ใช้งานได้จริง
เมตาดาต้าทำหน้าที่สองอย่าง:
ถ้าไม่มีเมตาดาต้าที่ดี คุณอาจดึง ความหมาย ที่ถูกต้องได้ แต่ยังแสดง บริบท ที่ผิดอยู่ดี
ขนาดอิมเบดดิ้งขึ้นกับโมเดล: 384, 768, 1024, และ 1536 มิติคือสิ่งที่พบบ่อย มิตามากขึ้นอาจจับความละเอียดได้ดีขึ้น แต่ก็เพิ่ม:
โดยคร่าวๆ: การเพิ่มมิตเป็นสองเท่ามักผลักดันต้นทุนและแลตเทนซีย์ขึ้น เว้นแต่คุณจะชดเชยด้วยการเลือกดัชนีหรือการบีบอัด
ชุดข้อมูลจริงเปลี่ยนแปลงได้ ดังนั้นฐานข้อมูลเวกเตอร์มักรองรับ:
การวางแผนการอัปเดตตั้งแต่แรกช่วยป้องกันปัญหา “ความรู้ล้าสมัย” ที่การค้นหาคืนเนื้อหาที่ไม่ตรงกับสิ่งที่ผู้ใช้เห็น
เมื่อข้อความ รูปภาพ หรือสินค้าแปลงเป็นอิมเบดดิ้งแล้ว การค้นหากลายเป็นปัญหาทางเรขาคณิต: “เวกเตอร์ใดใกล้กับเวกเตอร์คำค้นนี้ที่สุด?” เรียกว่า nearest-neighbor search แทนที่จะจับคู่คีย์เวิร์ด ระบบเทียบ ความหมาย โดยวัดความใกล้ของเวกเตอร์สองตัว
จินตนาการแต่ละชิ้นเนื้อหาเป็นจุดในสเปซมัลติไดเมนชัน เมื่อผู้ใช้ค้น คำค้นจะถูกแปลงเป็นจุดอีกจุด การค้นหาความคล้ายคืนรายการที่จุดใกล้กันที่สุด—เพื่อนบ้านใกล้ๆ เหล่านี้มักมีเจตนา หัวข้อ หรืบริบทที่คล้ายกัน แม้จะไม่ใช้คำศัพท์เดียวกัน
ฐานข้อมูลเวกเตอร์มักรองรับวิธีการคำนวณความใกล้เคียงไม่กี่แบบ:
โมเดลอิมเบดดิ้งต่างๆ ถูกฝึกมาโดยคำนึงถึงเมตริกเฉพาะ ดังนั้นจึงสำคัญที่จะใช้เมตริกที่ผู้ให้โมเดลแนะนำ
การค้นหา exact ตรวจสอบทุกเวกเตอร์เพื่อหาค่า nearest neighbors ที่แท้จริง แม่นยำแต่ช้าและแพงเมื่อขยายถึงล้านรายการ
ระบบส่วนใหญ่ใช้ approximate nearest neighbor (ANN) ซึ่งใช้โครงสร้างดัชนีชาญฉลาดเพื่อลดการค้นหาไปยังผู้สมัครที่มีแนวโน้มสูง คุณมักได้ผลลัพธ์ที่ “ใกล้เคียงพอ” กับคำตอบที่ดีที่สุดจริง—เร็วกว่าอย่างมาก
ANN เป็นที่นิยมเพราะให้คุณปรับจูนตามต้องการ:
การปรับจูนนี้แหละที่ทำให้การค้นหาเวกเตอร์ทำงานได้ดีในแอปจริง: คุณสามารถตอบกลับเร็วโดยยังคงผลลัพธ์ที่เกี่ยวข้องสูง
การค้นหาเชิงความหมายเข้าใจง่ายที่สุดเมื่อมองเป็นพายป์ไลน์: แปลงข้อความเป็นความหมาย ค้นหาความหมายที่คล้าย แล้วแสดงผลลัพธ์ที่เป็นประโยชน์ที่สุด
ผู้ใช้พิมพ์คำถาม (ตัวอย่าง: “How do I cancel my plan without losing data?”) ระบบรันข้อความผ่านโมเดลอิมเบดดิ้ง ผลลัพธ์คือเวกเตอร์—อาร์เรย์ของตัวเลขที่แทนความหมายของคำค้นแทนคำพูดเป๊ะๆ
ส่งเวกเตอร์คำค้นไปยังฐานข้อมูลเวกเตอร์ ซึ่งทำการค้นหาความคล้ายเพื่อหาว่าเวกเตอร์ใดในข้อมูลที่เก็บไว้ใกล้เคียงที่สุด
ระบบส่วนใหญ่คืน top-K แมตช์: K ชิ้น/เอกสารที่คล้ายที่สุด
การค้นหาเชิงความคล้ายถูกปรับให้เร็ว ผลลัพธ์ top-K แรกอาจมีรายการที่คล้ายแต่ไม่ตรงเป๊ะ ตัว reranker เป็นโมเดลลำดับสองที่ดูคำค้นและแต่ละผลผู้สมัครร่วมกันแล้วเรียงใหม่ตามความเกี่ยวข้อง
คิดแบบง่ายๆ ว่า: การค้นหาเวกเตอร์ให้ลิสต์ที่แข็งแรง; การเรียงลำดับใหม่คัดเอาตัวที่ดีที่สุดขึ้นมา
สุดท้ายคุณคืนผลที่ดีที่สุดให้ผู้ใช้ (เป็นผลการค้นหา) หรือส่งต่อให้ผู้ช่วย AI (เช่น ระบบ RAG) เป็น “หลักฐาน”
ถ้าคุณสร้างเวิร์กโฟลว์แบบนี้ในแอป แพลตฟอร์มเช่น Koder.ai สามารถช่วยให้คุณต้นแบบได้เร็ว: คุณอธิบายประสบการณ์การค้นหาเชิงความหมายหรือ RAG ในอินเทอร์เฟซแชท แล้วทำซ้ำปรับหน้า React และแบ็กเอนด์ Go/PostgreSQL ขณะรักษา pipeline การดึงข้อมูล (embedding → vector search → optional rerank → answer) ให้เป็นส่วนสำคัญของผลิตภัณฑ์
ถ้าบทความศูนย์ช่วยเหลือเขียนว่า “terminate subscription” และผู้ใช้ค้นว่า “cancel my plan,” การค้นหาด้วยคีย์เวิร์ด อาจพลาดเพราะ “cancel” กับ “terminate” ไม่ตรงกัน
การค้นหาเชิงความหมาย มักจะดึงมันขึ้นมาเพราะอิมเบดดิ้งจับได้ว่าทั้งสองวลีสื่อเจตนาเดียวกัน เพิ่มการเรียงลำดับใหม่แล้ว ผลลัพธ์ชั้นนำมักไม่ใช่แค่ “คล้าย” แต่เป็นคำตอบที่ใช้ได้จริงสำหรับคำถามของผู้ใช้
การค้นหาเวกเตอร์ล้วนๆ เก่งเรื่อง “ความหมาย” แต่ผู้ใช้ไม่ได้ค้นหาโดยความหมายเสมอไป บางครั้งต้องการการจับคู่เป๊ะ: ชื่อบุคคลเต็ม SKU รหัสใบแจ้งหนี้ หรือรหัสข้อผิดพลาดที่ก็อปมาจากล็อก การค้นหาไฮบริดแก้ปัญหานี้โดยรวมสัญญาณเชิงความหมาย (เวกเตอร์) กับสัญญาณแบบเล็กซิคัล (การค้นหาด้วยคีย์เวิร์ดแบบ BM25)
คิวรีไฮบริดมักรันสองเส้นทางพร้อมกัน:
ระบบจะรวมผู้สมัครจากทั้งสองทางเข้าลิสต์เดียวที่จัดอันดับแล้ว
ไฮบริดโดดเด่นเมื่อข้อมูลของคุณมีสตริงที่ต้องตรงกัน:
การค้นหาเชิงความหมายเพียงอย่างเดียวอาจคืนหน้าที่เกี่ยวข้องกว้างๆ; การค้นหาด้วยคีย์เวิร์ดเพียงอย่างเดียวอาจพลาดคำตอบที่ถ้อยคำต่างกัน ไฮบริดครอบคลุมทั้งสองกรณีที่ล้มเหลว
ตัวกรองเมตาดาต้าจำกัดการดึงก่อนการจัดอันดับ (หรือพร้อมกับการจัดอันดับ) ทำให้ความเกี่ยวข้องและความเร็วดีขึ้น ตัวกรองทั่วไปได้แก่:
ระบบส่วนใหญ่ใช้การผสมผสานแบบปฏิบัติ: รันทั้งสองการค้นหา ปรับสกอร์ให้อยู่ในระดับที่เปรียบเทียบได้ แล้วใช้เวท (เช่น “เอียงไปทางคีย์เวิร์ดมากขึ้นสำหรับ ID”) ผลิตภัณฑ์บางตัวยังเรียงลำดับใหม่ในลิสต์ที่รวมด้วยโมเดลเบาๆ หรือกฎ ในขณะที่ตัวกรองรับประกันว่าคุณกำลังจัดอันดับช่วงที่ถูกต้องตั้งแต่แรก
Retrieval-Augmented Generation (RAG) เป็นรูปแบบปฏิบัติที่ช่วยให้คำตอบจาก LLM น่าเชื่อถือขึ้น: ดึงข้อมูลที่เกี่ยวข้องมาก่อน แล้วค่อยให้โมเดลสร้างคำตอบ
แทนที่จะให้โมเดล “จำ” เอกสารบริษัทของคุณ ให้คุณ เก็บเอกสารเหล่านั้น (เป็นอิมเบดดิ้ง) ในฐานข้อมูลเวกเตอร์, ดึงชิ้นที่เกี่ยวข้องเมื่อมีคำถาม และส่งพวกมันเข้า LLM เป็นบริบทสนับสนุน
LLM เขียนได้ดี แต่จะเติมเต็มข้อมูลเมื่อขาดข้อเท็จจริง ฐานข้อมูลเวกเตอร์ช่วยดึงข้อความที่ ความหมายใกล้เคียงที่สุด จากฐานความรู้ของคุณและส่งให้ในพรอมต์
การมีข้อมูลพื้นฐานแบบนี้เปลี่ยนโมเดลจาก “สร้างคำตอบ” เป็น “สรุปและอธิบายแหล่งข้อมูลเหล่านี้” และยังทำให้คำตอบตรวจสอบได้ง่ายขึ้นเพราะคุณติดตามได้ว่าชิ้นไหนถูกดึงมาและสามารถแสดงการอ้างอิงได้
คุณภาพ RAG มักขึ้นกับการแบ่งชิ้นมากกว่าโมเดล
จินตนาการการไหลนี้:
คำถามผู้ใช้ → แปลงเป็นอิมเบดดิ้ง → ฐานข้อมูลเวกเตอร์ดึง top-k ชิ้น (+ ตัวกรองเมตาดาต้า) → สร้างพรอมต์ด้วยชิ้นที่ดึงได้ → LLM สร้างคำตอบ → คืนคำตอบ (และแหล่งอ้างอิง).
ฐานข้อมูลเวกเตอร์อยู่ตรงกลางเป็น “หน่วยความจำความเร็วสูง” ที่จ่ายหลักฐานที่เกี่ยวข้องที่สุดสำหรับแต่ละคำขอ
ฐานข้อมูลเวกเตอร์ไม่ได้ทำให้การค้นหา "ฉลาดขึ้น" เท่านั้น—มันเปิดประสบการณ์ผลิตภัณฑ์ที่ผู้ใช้สามารถอธิบายความต้องการเป็นภาษาธรรมชาติแล้วได้ผลลัพธ์ที่เกี่ยวข้อง นี่คือตัวอย่างใช้งานปฏิบัติที่พบบ่อย
ทีมซัพพอร์ตมักมีฐานความรู้ ตั๋วเก่า ทรานสคริปต์แชท และโน้ตการปล่อยฟีเจอร์—แต่การค้นหาด้วยคีย์เวิร์ดสู้กับคำพ้องและการพูดต่างกันไม่ได้
ด้วยการค้นหาเชิงความหมาย เจ้าหน้าที่หรือแชทบอทสามารถดึงตั๋วเก่าที่ ความหมายเหมือนกัน แม้ถ้อยคำจะต่าง ช่วยให้แก้ปัญหาเร็วขึ้น ลดงานซ้ำ และช่วยให้เจ้าหน้าที่ใหม่เรียนรู้งานได้ไวขึ้น การจับคู่การค้นหาเวกเตอร์กับตัวกรองเมตาดาต้า (สายผลิตภัณฑ์ ภาษา ประเภทปัญหา ช่วงวันที่) ช่วยให้ผลลัพธ์เฉพาะเจาะจงขึ้น
ผู้ช้อปมักไม่รู้ชื่อสินค้าเป๊ะๆ พวกเขาค้นหาด้วยเจตนา เช่น “กระเป๋าเป้เล็กใส่แล็ปท็อปและดูเป็นทางการ” อิมเบดดิ้งจับความชอบเหล่านั้น—สไตล์ ฟังก์ชัน ข้อจำกัด—ทำให้ผลลัพธ์คล้ายคำแนะนำจากพนักงานขายจริง
วิธีนี้ใช้ได้ทั้งคาทาล็อกค้าปลีก การท่องเที่ยว รายการอสังหา กระดานงาน และมาร์เก็ตเพลส คุณยังสามารถผสมความเกี่ยวข้องเชิงความหมายกับเงื่อนไขโครงสร้างเช่น ราคา ขนาด สต๊อก หรือสถานที่ได้
ฟีเจอร์คลาสสิกคือ “หาสิ่งที่คล้ายกัน” ถ้าผู้ใช้ดูรายการ อ่านบทความ หรือดูวิดีโอ คุณสามารถดึงเนื้อหาอื่นที่มีความหมายหรือคุณสมบัติใกล้เคียงได้—แม้หมวดหมู่จะไม่ตรงกัน
ใช้ได้กับ:
ในองค์กร ข้อมูลกระจัดกระจายอยู่ในเอกสาร วิกิ PDF และโน้ตการประชุม การค้นหาเชิงความหมายช่วยให้พนักงานถามด้วยภาษาธรรมชาติ (“นโยบายเบิกค่าใช้จ่ายสำหรับการไปประชุมคืออะไร?”) แล้วเจอแหล่งที่ถูกต้อง
ส่วนที่ไม่สามารถต่อรองได้คือต้องเคารพสิทธิ์การเข้าถึง ผลลัพธ์ต้องกรองตามทีม เจ้าของเอกสาร ระดับความลับ หรือรายการ ACL เพื่อให้ผู้ใช้เห็นเฉพาะสิ่งที่เขามีสิทธิ์เห็น
ถ้าต้องการไปไกลขึ้น เลเยอร์การดึงเดียวกันนี้คือสิ่งที่ขับเคลื่อนระบบถามตอบที่มีหลักฐาน (RAG)
ระบบค้นหาเชิงความหมายดีแค่ไหนขึ้นอยู่กับพายป์ไลน์ที่ป้อนมัน ถ้าเอกสารมาถึงไม่สม่ำเสมอ แบ่งชิ้นไม่ดี หรือไม่เคย re-embed หลังแก้ไข ผลลัพธ์จะเบี่ยงจากที่ผู้ใช้คาดหวัง
ทีมส่วนใหญ่ทำตามลำดับที่ทำซ้ำได้:
ขั้นตอน “แบ่งชิ้น” เป็นจุดที่หลายพายป์ไลน์ชนะหรือแพ้ ชิ้นที่ใหญ่เกินไปจะเบลอความหมาย ชิ้นเล็กเกินไปจะเสียบริบท วิธีปฏิบัติที่ได้ผลคือแบ่งตาม โครงสร้างธรรมชาติ (หัวข้อ ย่อหน้า คู่คำถาม-คำตอบ) และเก็บการทับซ้อนเล็กน้อยเพื่อความต่อเนื่อง
เนื้อหาเปลี่ยนแปลงอยู่เสมอ—นโยบายปรับ ราคาปรับ บทความถูกแก้ไข จงถือว่าอิมเบดดิ้งเป็นข้อมูลที่สกัดได้ซึ่งต้องสร้างใหม่
กลยุทธ์ทั่วไป:
ถ้าบริการหลายภาษา คุณสามารถใช้ โมเดลอิมเบดดิ้งหลายภาษา (ง่ายกว่า) หรือ โมเดลแยกตามภาษา (บางครั้งคุณภาพสูงกว่า) หากทดลองกับโมเดล ให้เวอร์ชันอิมเบดดิ้งของคุณ (เช่น embedding_model=v3) เพื่อรัน A/B และย้อนกลับได้โดยไม่ทำให้การค้นหาพัง
การค้นหาเชิงความหมายอาจดู “ดี” ในเดโมแต่ล้มเหลวในโปรดักชัน ความต่างคือการวัด: คุณต้องมีเมตริกความเกี่ยวข้องที่ชัดเจน และ เป้าหมายความเร็ว ทดสอบกับคำค้นที่เหมือนพฤติกรรมผู้ใช้จริง
เริ่มด้วยชุดเมตริกเล็กๆ แล้วยึดตามมัน:
สร้างชุดประเมินจาก:
เก็บชุดทดสอบให้มีเวอร์ชันเพื่อเปรียบเทียบผลข้ามรีลีส
เมตริกออฟไลน์ไม่ได้จับทุกอย่าง ทำ A/B และเก็บสัญญาณง่ายๆ:
ใช้ฟีดแบ็กนี้อัปเดตการตัดสินความเกี่ยวข้องและหาลวดลายความล้มเหลว
ประสิทธิภาพเปลี่ยนเมื่อ:
รันชุดทดสอบของคุณใหม่หลังการเปลี่ยนแปลงทุกครั้ง มอนิเตอร์เทรนด์เมตริกเป็นรายสัปดาห์ และตั้งการแจ้งเตือนเมื่อ MRR/nDCG ลดลงฉับพลันหรือ p95 พุ่งขึ้น
การค้นหาเวกเตอร์เปลี่ยน วิธี ดึงข้อมูล แต่ไม่ควรเปลี่ยนว่า ใคร ดูได้ ถ้าระบบค้นหาเชิงความหมายหรือ RAG สามารถ “หา” ชิ้นที่ถูกต้อง ก็อาจโดยไม่ได้ตั้งใจคืนชิ้นที่ผู้ใช้ไม่มีสิทธิ์เห็น—เว้นแต่คุณออกแบบสิทธิ์และความเป็นส่วนตัวเข้าไปตั้งแต่ขั้นตอนดึง
กฎที่ปลอดภัยคือชัดเจน: ผู้ใช้ควรดึงเฉพาะเนื้อหาที่พวกเขาสามารถอ่านได้เท่านั้น อย่าไว้ใจแอปให้ “ซ่อน” ผลหลังจากฐานข้อมูลเวกเตอร์คืนมา—เพราะตอนนั้นข้อมูลอาจหลุดออกจากพื้นที่เก็บของคุณแล้ว
แนวทางปฏิบัติได้แก่:
ฐานข้อมูลเวกเตอร์หลายตัวรองรับ ตัวกรองเมตาดาต้า (เช่น tenant_id, department, project_id, visibility) ที่รันควบคู่การค้นหาความคล้าย ใช้ถูกมันเป็นวิธีสะอาดในการใช้สิทธิ์ตอนดึง
รายละเอียดสำคัญ: ให้แน่ใจว่าตัวกรองเป็น ข้อบังคับฝั่งเซิร์ฟเวอร์ ไม่ใช่ตรรกะฝั่งไคลเอนต์ และระวัง “role explosion” (ชุดผสมสิทธิ์มากเกินไป) ถ้าระบบสิทธิ์ซับซ้อน ให้พิจารณาคำนวณ “กลุ่มสิทธิ์ที่มีผล” ล่วงหน้าหรือใช้บริการตรวจสอบสิทธิ์เพื่อสร้าง token ตัวกรองตอนคิวรี
อิมเบดดิ้งสามารถเข้ารหัสความหมายจากข้อความต้นฉบับ ซึ่งไม่จำเป็นต้องเปิดเผย PII ดิบ แต่ก็เพิ่มความเสี่ยง เช่น ข้อเท็จจริงละเอียดอ่อนกลายเป็นสิ่งที่ค้นหาได้ง่ายขึ้น
แนวทางที่ได้ผล:
ถือว่าดัชนีเวกเตอร์เป็นข้อมูลโปรดักชัน:
ถ้าทำได้ดี แนวปฏิบัติเหล่านี้ทำให้การค้นหาเชิงความหมายกลายเป็นสิ่งมหัศจรรย์สำหรับผู้ใช้—โดยไม่กลายเป็นปัญหาด้านความปลอดภัยทีหลัง
ฐานข้อมูลเวกเตอร์อาจดูว่า “เสียบแล้วใช้งานได้” แต่ความผิดหวังส่วนใหญ่เกิดจากการตัดสินใจรอบๆ: การแบ่งชิ้น โมเดลอิมเบดดิ้งที่เลือก และความสม่ำเสมอของการอัปเดต
การแบ่งชิ้นไม่ดี เป็นสาเหตุอันดับหนึ่งของผลลัพธ์ไม่เกี่ยวข้อง ชิ้นที่ใหญ่เกินไปทำให้ความหมายเจือจาง ชิ้นเล็กเกินไปเสียบริบท ถ้าผู้ใช้มักพูดว่า “มันเจอเอกสารถูกแต่พาสเสจไม่ใช่” กลยุทธ์การแบ่งชิ้นคุณน่าจะต้องปรับ
โมเดลอิมเบดดิ้งไม่เหมาะ จะแสดงออกมาเป็นความไม่ตรงของความหมายอย่างสม่ำเสมอ—ผลลัพธ์ดูลื่นไหลแต่หลุดประเด็น เกิดเมื่อโมเดลไม่เหมาะกับโดเมนของคุณ (กฎหมาย การแพทย์ ตั๋วซัพพอร์ต) หรือประเภทเนื้อหา (ตาราง โค้ด ข้อความหลายภาษา)
ข้อมูลล้าสมัย สร้างปัญหาความเชื่อถืออย่างรวดเร็ว: ผู้ใช้ค้นหานโยบายล่าสุดแต่ได้เวอร์ชันไตรมาสก่อน ถ้าข้อมูลต้นทางเปลี่ยน อิมเบดดิ้งและเมตาดาต้าต้องอัปเดตด้วย (และการลบต้องลบจริงๆ)
ช่วงเริ่ม คุณอาจมีเนื้อหาน้อย คิวรีน้อย หรือฟีดแบ็กไม่พอวางจูน กำหนด:
ต้นทุนมักมาจากสี่แหล่งหลัก:
ถ้าคุณเปรียบเทียบผู้ให้บริการ ให้ขอประมาณรายเดือนจากจำนวนเอกสารที่คาดไว้ ขนาดชิ้นเฉลี่ย และ QPS สูงสุด หลายความประหลาดใจเกิดขึ้นหลังการทำดัชนีและช่วงโหลดสูง
ใช้เช็คลิสต์สั้นๆ นี้เพื่อเลือกฐานข้อมูลเวกเตอร์ที่เหมาะกับคุณ:
การเลือกที่ดีไม่ใช่การไล่ตามดัชนีชนิดใหม่ล่าสุด แต่เป็นเรื่องความน่าเชื่อถือ: คุณอัปเดตข้อมูลได้ไหม ควบคุมการเข้าถึงได้ไหม และรักษาคุณภาพได้เมื่อเนื้อหาและการจราจรเติบโต?
การค้นหาด้วยคีย์เวิร์ดจะจับคู่กับ คำที่ตรงกันเป๊ะ. การค้นหาเชิงความหมายจะจับคู่ ความหมาย โดยเปรียบเทียบอิมเบดดิ้ง (เวกเตอร์) ดังนั้นมันสามารถคืนผลที่เกี่ยวข้องได้แม้คำค้นจะใช้การเรียบเรียงที่ต่างกัน (เช่น “stop payments” → “cancel subscription”).
ฐานข้อมูลเวกเตอร์เก็บ อิมเบดดิ้ง (อาร์เรย์ของตัวเลข) พร้อมกับ ID และเมตาดาต้า แล้วทำการค้นหา nearest-neighbor อย่างรวดเร็วเพื่อหาข้อความที่มีความหมายใกล้เคียงกับคำค้น มันถูกออกแบบมาเพื่อการค้นหาความคล้ายที่ขยายได้ถึงระดับล้านๆ เวกเตอร์
อิมเบดดิ้งคือลายนิ้วมือเชิงตัวเลขที่สร้างโดยโมเดล — คุณไม่ต้องอ่านตัวเลขโดยตรง แต่ใช้เพื่อวัดความคล้าย
ในการปฏิบัติ:
บันทึกส่วนใหญ่ประกอบด้วย:
เมตาดาต้าช่วยสองเรื่องสำคัญ:
title/สรุป/ลิงก์ แทนที่จะคืนแค่ ID ภายในถ้าไม่มีเมตาดาต้า คุณอาจดึงความหมายที่ถูกต้องออกมาได้แต่แสดงบริบทที่ผิดหรือรั่วไหลเนื้อหาที่ควรถูกจำกัด
ตัวเลือกที่พบบ่อยได้แก่:
ควรใช้เมตริกที่โมเดลอิมเบดดิ้งถูกฝึกมาให้ใช้ เพราะเมตริกที่ไม่ตรงกับโมเดลอาจลดคุณภาพการจัดอันดับได้
การค้นหาแบบ exact จะเปรียบเทียบคำค้นกับ ทุก เวกเตอร์ ซึ่งแม่นยำแต่ช้าเมื่อขยายถึงขนาดใหญ่ ANN (approximate nearest neighbor) ใช้ดัชนีชาญฉลาดเพื่อลดชุดตัวอย่างที่ต้องตรวจสอบ
คุณสามารถปรับสมดุลได้ระหว่าง:
การค้นหาไฮบริดรวม:
มักเป็นค่าเริ่มต้นที่ดีกว่าเมื่อข้อมูลของคุณมีสตริงที่ต้องตรงกันแน่นอน
RAG (Retrieval-Augmented Generation) ดึงชิ้นข้อมูลที่เกี่ยวข้องจากที่เก็บข้อมูลและนำไปเป็นบริบทให้ LLM
ขั้นตอนโดยย่อ:
สามข้อผิดพลาดที่พบบ่อยที่สุด:
แนวทางลดความเสี่ยงรวมถึง แบ่งชิ้นตามโครงสร้าง บันทึกเวอร์ชันอิมเบดดิ้ง และบังคับตัวกรองเมตาดาต้าฝั่งเซิร์ฟเวอร์ (เช่น , ฟิลด์ ACL)
title, url, tags, language, created_at, tenant_id)เวกเตอร์ช่วยให้วัดความคล้ายเชิงความหมาย; เมตาดาต้าทำให้ผลลัพธ์ใช้งานได้จริง (กรอง การควบคุมการเข้าถึง แสดงผล)
tenant_id