07 ส.ค. 2568·3 นาที
ฐานข้อมูลกระจาย: แลกความสอดคล้องเพื่อความพร้อมใช้งาน
เรียนรู้ว่าทำไมฐานข้อมูลกระจายมักผ่อนปรนความสอดคล้องเพื่อรักษาความพร้อมใช้งานเมื่อเกิดความล้มเหลว, วิธีการทำงานของ CAP และควอรัม, และเมื่อใดควรเลือกแนวทางแต่ละแบบ
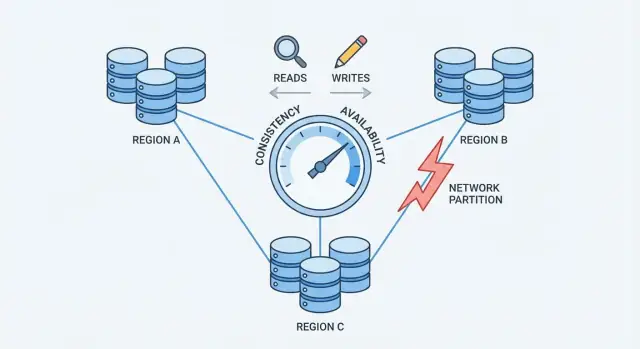
ความหมายของความสอดคล้องและความพร้อมใช้งานในเชิงปฏิบัติ
เมื่อฐานข้อมูลถูกกระจายไปยังเครื่องหลายเครื่อง (replica) คุณจะได้ความเร็วและความทนทาน—แต่คุณก็เพิ่มช่วงเวลาที่เครื่องเหล่านั้นอาจไม่เห็นด้วยหรือไม่สามารถสื่อสารกันได้อย่างเชื่อถือได้
ความสอดคล้อง (ความหมายตามตรง)
ความสอดคล้อง หมายถึง: หลังการเขียนที่สำเร็จ ทุกการอ่านจะได้ค่าที่เหมือนกัน หากคุณอัปเดตอีเมลในโปรไฟล์ การอ่านครั้งถัดไป—ไม่ว่าตอบจาก replica ใด—จะคืนค่าอีเมลใหม่
ในทางปฏิบัติ ระบบที่ให้ความสำคัญกับความสอดคล้องอาจ หน่วงหรือปฏิเสธ บางคำขอในช่วงความล้มเหลวเพื่อหลีกเลี่ยงการคืนคำตอบที่ขัดแย้งกัน
ความพร้อมใช้งาน (ความหมายตามตรง)
ความพร้อมใช้งาน หมายถึง: ระบบตอบคำขอทุกคำขอ แม้บางเซิร์ฟเวอร์จะล้มเหลวหรือตัดการเชื่อมต่อ คุณอาจไม่ได้ข้อมูลล่าสุด แต่คุณได้คำตอบ
ในทางปฏิบัติ ระบบที่เน้นความพร้อมใช้งานอาจยอมรับการเขียนและให้การอ่าน แม้ replica จะแตกต่างกันอยู่ แล้วรวมความต่างภายหลัง
การแลกเปลี่ยนหมายถึงอะไรกับแอปจริง
การ แลกเปลี่ยน หมายความว่าคุณไม่สามารถทำให้ทั้งสองเป้าหมายสูงสุดพร้อมกันได้เสมอไป หาก replica ไม่สามารถประสานกัน ฐานข้อมูลต้องเลือกระหว่าง:
- รอ/ล้มเหลวบางคำขอเพื่อปกป้องความจริงเดียว (ชื่นชอบความสอดคล้อง), หรือ
- ตอบผู้ใช้ต่อไปแม้อาจเสี่ยงข้อมูลล้าสมัยหรือขัดแย้ง (ชื่นชอบความพร้อมใช้งาน)
ตัวอย่างง่าย ๆ: ตะกร้าสินค้า vs โอนเงินธนาคาร
- ตะกร้าสินค้า: ถ้าจำนวนในตะกร้าผิดพลาดชั่วคราวบนอุปกรณ์อื่น มักจะไม่เป็นปัญหาใหญ่ หลายทีมเลือกความพร้อมใช้งานสูงและรวมผลภายหลัง
- โอนเงิน: ถ้าคุณย้ายเงิน $500 แล้วยอดเงินชั่วคราวแสดงผลต่างกัน นั่นเป็นปัญหาร้ายแรง ที่นี่ความสอดคล้องที่เข้มงวดมักคุ้มกับการเกิด "ลองใหม่" บ้างเป็นครั้งคราว
ไม่มีคำตอบเดียวที่ดีที่สุด
สมดุลที่เหมาะสมขึ้นกับความผิดพลาดที่คุณยอมรับได้: การหยุดชั่วคราวหรือช่วงเวลาของข้อมูลผิด/เก่า ระบบจริงส่วนใหญ่เลือกจุดกึ่งกลาง—และทำให้การแลกเปลี่ยนนั้นชัดเจน
ทำไมการกระจายเปลี่ยนกฎ
ฐานข้อมูลถือว่า “กระจาย” เมื่อเก็บและให้บริการข้อมูลจากเครื่องหลายเครื่อง (โหนด) ที่ประสานงานผ่านเครือข่าย ต่อให้แอปเห็นว่าเป็นฐานข้อมูลเดียว แต่ภายใต้ผิวคำขออาจถูกจัดการโดยโหนดต่างกันในที่ต่างกัน
การทำสำเนา: เหตุผลที่ทีมเพิ่มโหนด
ฐานข้อมูลกระจายส่วนใหญ่มักทำสำเนาข้อมูล: เรคอร์ดเดียวกันถูกเก็บบนโหนดหลายตัว ทีมทำเพื่อ:
- ให้บริการยังทำงานได้หากเครื่องใดล้ม
- ลดหน่วงเวลาโดยให้บริการจากโหนดใกล้ ๆ ผู้ใช้
- ขยายการอ่าน (และบางครั้งการเขียน) ข้ามฮาร์ดแวร์มากขึ้น
การทำสำเนามีพลัง แต่ก็ยกคำถามทันที: ถ้าโหนดสองตัวมีสำเนาเดียวกัน จะรับประกันว่าพวกมันเห็นด้วยเสมอได้อย่างไร?
ความล้มเหลวบางส่วนเป็นเรื่องปกติ ไม่ใช่ข้อยกเว้น
บนเซิร์ฟเวอร์เดียว “down” มักชัดเจน: เครื่องขึ้นหรือลง ในระบบกระจาย ความล้มเหลวมักเป็นแบบบางส่วน โหนดหนึ่งอาจยังวิ่งแต่ช้า ลิงก์เครือข่ายอาจทิ้งแพ็กเก็ต แร็คทั้งแร็คอาจสูญเสียการเชื่อมต่อ ทั้งคลัสเตอร์ยังทำงานต่อ
เรื่องนี้สำคัญเพราะโหนดไม่สามารถรู้ได้ทันทีว่าโหนดอื่น “ล้มจริง” หยุดชั่วคราว หรือแค่ช้า ขณะที่พวกมันรอคำตอบ ต้องตัดสินใจว่าจะจัดการการอ่านและการเขียนอย่างไร
การรับประกันเปลี่ยนเมื่อการสื่อสารไม่รับประกัน
บนเซิร์ฟเวอร์เดียว มีแหล่งความจริงเดียว: ทุกการอ่านเห็นการเขียนที่สำเร็จล่าสุด
กับหลายโหนด “ล่าสุด” ขึ้นกับการประสาน หากการเขียนสำเร็จที่โหนด A แต่โหนด B ไม่สามารถเข้าถึงได้ ฐานข้อมูลควรจะ:
- บล็อกการเขียนจนกว่า B จะรับทราบมัน (ปกป้องความสอดคล้อง), หรือ
- ยอมรับการเขียนเลย (ปกป้องความพร้อมใช้งาน)?
แรงตึงนี้—เกิดจริงจากเครือข่ายที่ไม่สมบูรณ์—คือเหตุผลที่การกระจายเปลี่ยนกฎ
การแยกเครือข่าย: ปัญหาหลัก
การแยกเครือข่าย (network partition) คือการขาดการสื่อสารระหว่างโหนดที่ควรทำงานเป็นฐานข้อมูลเดียว โหนดอาจยังทำงานได้ แต่ไม่สามารถแลกเปลี่ยนข้อความได้อย่างเชื่อถือได้—เพราะสวิตช์เสีย ลิงก์โอเวอร์โหลด การเปลี่ยนเส้นทางผิดพลาด กฎไฟร์วอลล์ไม่ถูกต้อง หรือแม้แต่เพื่อนร่วมงานเสียงดังในเครือข่ายคลาวด์
ทำไมพาร์ติชันหลีกเลี่ยงไม่ได้เมื่อขยายขนาด
เมื่อระบบถูกกระจายข้ามหลายเครื่อง (มักข้ามแร็ค โซน หรือภูมิภาค) คุณไม่ได้ควบคุมทุกฮอประหว่างพวกมัน เครือข่ายทิ้งแพ็กเก็ต เพิ่มความหน่วง และบางครั้งแบ่งเป็น "เกาะ" เหตุการณ์เหล่านี้ที่ขนาดเล็กอาจหายาก แต่ที่ขนาดใหญ่จะเกิดบ่อย แม้การขัดจังหวะสั้น ๆ ก็สำคัญ เพราะฐานข้อมูลต้องการการประสานอย่างต่อเนื่องเพื่อเห็นเหตุการณ์ว่าเกิดอะไรขึ้น
พาร์ติชันสร้างข้อมูล "ล่าสุด" ที่ขัดแย้งอย่างไร
ในช่วงพาร์ติชัน ทั้งสองฝั่งยังรับคำขอได้ หากผู้ใช้สามารถเขียนทั้งสองฝั่ง แต่ละฝั่งอาจยอมรับการอัปเดตที่อีกฝั่งไม่เห็น
ตัวอย่าง: โหนด A อัปเดตที่อยู่ผู้ใช้เป็น “New Street” ในขณะที่โหนด B อัปเดตเป็น “Old Street Apt 2” แต่ละฝั่งเชื่อว่าการเขียนของตนเป็นล่าสุด—เพราะไม่มีทางเปรียบเทียบแบบเรียลไทม์
อาการที่ผู้ใช้เห็น
พาร์ติชันไม่ปรากฏเป็นข้อความผิดพลาดชัดเจน แต่แสดงเป็นพฤติกรรมสับสน:
- Timeouts: ฐานข้อมูลรอให้โหนดอื่นยืนยันการเขียนหรือการอ่าน
- Stale reads: รีเฟรชแล้วยังเห็นข้อมูลเก่าเพราะไปโดน replica ที่พลาดการอัปเดต
- Split-brain behavior: ผู้ใช้ต่างคนต่างเห็น “ความจริง” ที่ต่างกัน ขึ้นกับฝั่งที่เข้าถึง
นี่คือจุดกดดันที่บังคับให้ต้องเลือก: เมื่อเครือข่ายไม่รับประกันการสื่อสาร ฐานข้อมูลกระจายต้องตัดสินใจว่าจะให้ความสำคัญกับความสอดคล้องหรือความพร้อมใช้งาน
CAP โดยไม่ต้องใช้ศัพท์เทคนิค
CAP คือวิธีสรุปสั้น ๆ ว่าเกิดอะไรขึ้นเมื่อฐานข้อมูลกระจายอยู่บนเครื่องหลายเครื่อง
คำสามคำ (แบบชัดเจน)
- Consistency (C): หลังการเขียน ค่าที่อ่านภายหลังต้องคืนค่าเดียวกันเสมอ
- Availability (A): ทุกคำขอได้รับการตอบที่ไม่ใช่ข้อผิดพลาด แม้บางเซิร์ฟเวอร์มีปัญหา
- Partition tolerance (P): ระบบยังทำงานได้แม้เครือข่ายจะแยกและเซิร์ฟเวอร์สื่อสารกันไม่แน่นอน
ข้อสรุปสำคัญ
เมื่อ ไม่มีพาร์ติชัน ระบบหลายชนิดสามารถดูทั้งสอดคล้องและพร้อมใช้งานได้
เมื่อ เกิดพาร์ติชัน คุณต้องเลือกว่าจะให้ความสำคัญกับอะไร:
- เลือกความสอดคล้อง: ปฏิเสธหรือล่าช้าบางคำขอจนกว่าเซิร์ฟเวอร์จะตกลงกัน
- เลือกความพร้อมใช้งาน: ยอมรับคำขอบนแต่ละฝั่งแม้คำตอบจะขัดแย้งชั่วคราว
ลำดับเวลาแบบง่ายให้จินตนาการ
- 10:00 ลูกค้าเขียน
balance = 100กับ Server A. - 10:01 เกิด network partition: Server A ติดต่อ Server B ไม่ได้.
- 10:02 ลูกค้าอ่านจาก Server B.
- ถ้าเน้น Consistency Server B ต้องปฏิเสธหรือรอ.
- ถ้าเน้น Availability Server B ตอบ แต่ค่าอาจเป็น
balance = 80.
ความเข้าใจผิดที่พบบ่อย
CAP ไม่ได้หมายความว่า "เลือกได้แค่สองเสมอ" แต่มันหมายความว่า เมื่อเกิดพาร์ติชัน คุณไม่สามารถการันตีได้ทั้งสองอย่างพร้อมกัน นอกพาร์ติชัน ระบบมักจะเข้าใกล้ทั้งสองได้บ่อยครั้ง—จนกว่าเครือข่ายจะมีปัญหา
เลือกความสอดคล้อง: ได้อะไรและเสียอะไร
การเลือก ความสอดคล้อง หมายความว่าฐานข้อมูลให้ความสำคัญกับ "ทุกคนเห็นความจริงเดียวกัน" มากกว่า "ตอบเสมอ" ในทางปฏิบัติ นี้มักชี้ไปที่ ความสอดคล้องแบบเข้มงวด หรือที่อธิบายว่าเป็นพฤติกรรมแบบ linearizable: เมื่อการเขียนได้รับการยืนยัน การอ่านใด ๆ ภายหลัง (จากที่ไหนก็ได้) จะคืนค่านั้นเหมือนมีสำเนาเดียวที่อัปเดต
เกิดอะไรขึ้นระหว่างพาร์ติชัน
เมื่อเครือข่ายแยกและ replica สื่อสารกันไม่ได้อย่างเชื่อถือได้ ระบบที่สอดคล้องอย่างหนักจะไม่สามารถยอมรับการอัปเดตอิสระทั้งสองฝั่งได้อย่างปลอดภัย เพื่อปกป้องความถูกต้อง มันมักจะ:
- บล็อก คำขอขณะที่รอการประสาน, หรือ
- ปฏิเสธ คำขอ (คืนข้อผิดพลาด/timeout) หากไม่สามารถเข้าถึง replica/leader ที่ต้องการได้
จากมุมมองผู้ใช้ นี่อาจดูเหมือนการหยุดชั่วคราวแม้บางเครื่องจะยังทำงานอยู่
สิ่งที่คุณได้
ประโยชน์หลักคือ การคิดง่ายขึ้น โค้ดแอปสามารถทำงานเหมือนกำลังคุยกับฐานข้อมูลเดียว ไม่ใช่ replica หลายตัวที่อาจขัดแย้ง ซึ่งลดช่วงเวลา "แปลก ๆ" เช่น:
- อ่านข้อมูลเก่าหลังจากการอัปเดตที่สำเร็จ
- เห็นค่าต่างกันสำหรับเรคอร์ดเดียวกันขึ้นกับ replica ที่โดน
- สูญเสียสมบัติสำคัญ เช่น ขายเกินสต็อก เพราะการเขียนขัดแย้งกัน
คุณยังได้โมเดลทางความคิดที่ชัดเจนสำหรับการตรวจสอบ บิลลิ่ง และงานที่ต้องถูกต้องทันที
สิ่งที่คุณเสีย
ความสอดคล้องมีต้นทุนจริง:
- ความหน่วงสูงขึ้น: หลายการดำเนินการต้องรอการประสาน (มักข้ามเครื่องหรือภูมิภาค)
- ข้อผิดพลาดมากขึ้นในช่วงความล้มเหลว: พาร์ติชัน replica ช้า หรือปัญหา leader อาจเป็น timeout หรือต้องลองใหม่
ถ้าผลิตภัณฑ์ของคุณทนต่อคำขอล้มเหลวระหว่างการหยุดชั่วคราวไม่ได้ ความสอดคล้องแบบเข้มงวดอาจรู้สึกแพง—แม้บางครั้งจะเป็นตัวเลือกที่ถูกต้องสำหรับความถูกต้อง
เลือกความพร้อมใช้งาน: ได้อะไรและเสียอะไร
สร้างและแชร์เพื่อรับเครดิต
แชร์สิ่งที่คุณสร้างกับ Koder.ai และรับเครดิตในขณะสอนผู้อื่น
การเลือกความพร้อมใช้งานหมายถึงการมุ่งสัญญาง่าย ๆ: ระบบตอบ แม้บางส่วนของโครงสร้างพื้นฐานจะมีปัญหา ในทางปฏิบัติ "ความพร้อมใช้งานสูง" ไม่ได้แปลว่า "ไม่มีข้อผิดพลาดเลย"—แต่คือคำขอส่วนใหญ่ยังได้คำตอบระหว่างการล้มเหลวของโหนด รีพลิก หรือการเชื่อมต่อเครือข่ายเสีย
เกิดอะไรขึ้นระหว่างพาร์ติชัน
เมื่อเครือข่ายแยก replica ไม่สามารถคุยกันได้อย่างเชื่อถือได้ ฐานข้อมูลที่เน้นความพร้อมใช้งานมักจะให้บริการจากฝั่งที่เข้าถึงได้:
- การอ่าน ตอบจากข้อมูลท้องถิ่นที่ replica มี
- การเขียน ยอมรับท้องถิ่นและคิว/จำลองกลับเมื่อการเชื่อมต่อคืน
สิ่งนี้ทำให้แอปยังดำเนินต่อไป แต่หมายความว่า replica ต่าง ๆ อาจยอมรับ "ความจริง" ที่ต่างกันชั่วคราว
สิ่งที่คุณได้
คุณได้ uptime ที่ดีกว่า: ผู้ใช้ยังท่องเว็บ ใส่ของลงตะกร้า โพสต์คอมเมนต์ หรือติดตามเหตุการณ์ได้แม้ภูมิภาคจะโดนแยก
คุณยังได้ประสบการณ์ผู้ใช้ที่ราบเรียบกว่าในช่วงความเครียด แทนที่จะเจอ timeout แอปของคุณอาจแสดงพฤติกรรมที่สมเหตุสมผล ("บันทึกการอัปเดตของคุณแล้ว") แล้วซิงก์ภายหลัง สำหรับงานผู้บริโภคและงานวิเคราะห์หลายอย่าง การแลกเปลี่ยนนี้คุ้มค่า
สิ่งที่คุณเสีย
ราคาที่ต้องจ่ายคือฐานข้อมูลอาจคืน การอ่านล้าสมัย ผู้ใช้อาจอัปเดตโปรไฟล์บน replica หนึ่ง แล้วอ่านจาก replica อีกตัวและยังเห็นค่าดั้งเดิม
คุณยังเสี่ยงกับ ความขัดแย้งของการเขียน ผู้ใช้สองคน (หรือผู้ใช้คนเดียวในสองที่) อาจอัปเดตเรคอร์ดเดียวกันบนฝั่งต่างกันของพาร์ติชัน เมื่อการเชื่อมคืน ระบบต้องรวมประวัติที่ต่างกัน อาจเลือกให้เขียนหนึ่งชนะ ผสานฟิลด์ หรือให้แอปจัดการความขัดแย้ง
การออกแบบแบบเน้นความพร้อมใช้งานคือการยอมรับการไม่เห็นด้วยชั่วคราวเพื่อให้ผลิตภัณฑ์ยังตอบ—แล้วลงทุนในวิธีการตรวจจับและซ่อมแซมความต่างภายหลัง
ควอรัมและโหวต: ทางสายกลาง
ควอรัมเป็นเทคนิคการโหวตที่ฐานข้อมูลรีพลิเคตหลายระบบใช้เพื่อลดช่องว่างระหว่างความสอดคล้องและความพร้อมใช้งาน แทนที่จะเชื่อโหนดเดียว ระบบถามโหนด พอประมาณ เพื่อให้เห็นด้วย
แนวคิด (N, R, W)
มักจะเห็นควอรัมอธิบายด้วยตัวเลขสามตัว:
- N: จำนวน replica สำหรับข้อมูลชิ้นหนึ่ง
- W: จำนวน replica ที่ต้องยืนยันการเขียนก่อนถือว่าสำเร็จ
- R: จำนวน replica ที่ถูกสอบถามสำหรับการอ่าน
กฎง่าย ๆ ที่พบบ่อยคือ: ถ้า R + W > N การอ่านทุกครั้งจะทับกับการเขียนที่สำเร็จบน replica อย่างน้อยหนึ่งตัว ซึ่งลดโอกาสการอ่านข้อมูลล้าสมัย
ตัวอย่างที่เข้าใจง่าย
ถ้าคุณมี N=3 replica:
- แบบใช้ replica เดียว (R=1, W=1): เร็วและมีความพร้อมใช้งานสูง แต่เสี่ยงอ่านจาก replica ที่ล้าสมัย
- การโหวตแบบเสียงข้างมาก (R=2, W=2): การเขียนต้องเข้าถึง 2 replica และการอ่านสอบถาม 2 replica เพิ่มโอกาสเห็นค่าล่าสุดเพราะชุดอ่านและเขียนทับกัน
บางระบบตั้ง W=3 (ทุก replica) เพื่อความสอดคล้องสูง แต่จะทำให้การเขียนล้มเหลวง่ายกว่าเมื่อ replica ใดช้าหรือลง
ควอรัมทำงานอย่างไรระหว่างพาร์ติชัน
ควอรัมไม่กำจัดปัญหาพาร์ติชัน—แต่มันกำหนด ฝ่ายที่สามารถทำงานต่อได้ หากเครือข่ายแบ่งเป็น 2–1 ฝั่งที่มี 2 replica ยังสามารถพอใจ R=2 และ W=2 ได้ ฝั่งเดียวโดดจะทำไม่ได้ ซึ่งช่วยลดการอัปเดตที่ขัดแย้ง แต่ก็หมายความว่าลูกค้าบางส่วนจะเจอข้อผิดพลาดหรือ timeout
การแลกเปลี่ยน
ควอรัมมักหมายถึง ความหน่วงเพิ่มขึ้น (ต้องติดต่อโหนดมากขึ้น), ต้นทุนสูงขึ้น (ทราฟฟิกข้ามโหนดมากขึ้น), และพฤติกรรมการล้มเหลวที่ซับซ้อนกว่า (timeout อาจดูเหมือนไม่พร้อมใช้งาน) แต่ข้อดีคือเป็นทางสายกลางที่ปรับได้: คุณสามารถเลื่อน R และ W ให้เข้ากับการอ่านที่สดขึ้นหรือการยอมรับการเขียนมากขึ้นตามความสำคัญ
ความสอดคล้องในท้ายที่สุดและความผิดปกติที่พบบ่อย
ความสอดคล้องในท้ายที่สุดหมายความว่า replica ถูกปล่อยให้ไม่ซิงก์กันชั่วคราว ตราบใดที่พวกมัน รวมเป็นค่าเดียวกัน ในภายหลัง
อุปมาอุปไมยที่จับต้องได้
คิดถึงเครือร้านกาแฟที่อัปเดตป้าย "สินค้าขาด" สำหรับขนมชิ้นหนึ่ง ร้านหนึ่งขึ้นว่า "ขาด" แต่การอัปเดตไปถึงร้านอื่นอีกไม่กี่นาที ในช่วงนั้นร้านอื่นอาจยังแสดงว่า "มี" และขายชิ้นสุดท้าย ไม่มีระบบไหน "เสีย" แค่การอัปเดตกำลังตามกันทัน
ความผิดปกติที่มักเห็น
เมื่อข้อมูลกำลังแพร่หลาย ลูกค้าอาจเห็นพฤติกรรมที่น่าประหลาดใจ:
- Stale reads: อ่านข้อมูลเก่าจาก replica ที่ยังไม่รับการเขียนล่าสุด
- Read-your-writes gaps: คุณเขียนแล้วอ่านอีกแป๊บแต่ไม่เห็นการเปลี่ยนแปลง
- Out-of-order updates: สองการอัปเดตมาถึงในลำดับต่างกันบน replica ต่างกัน ทำให้มุมมองไม่สอดคล้องชั่วคราว
เทคนิคช่วยให้ replica รวมกัน
ระบบ eventual consistency มักมีกลไกพื้นหลังเพื่อลดช่องว่างความไม่สอดคล้อง:
- Read repair: หากการอ่านตรวจพบ replica ไม่ตรงกัน ระบบจะอัปเดต replica ที่ล้าหลังในพื้นหลัง
- Hinted handoff: ถ้า replica ลง โหนดอีกตัวเก็บ "hint" ของการเขียนไว้ชั่วคราวเพื่อส่งต่อเมื่อมันกลับมา
- Anti-entropy (sync): การไล่ปรับความต่างเป็นช่วง ๆ (เช่น ใช้ merkle trees หรือ checksum) เพื่อหาและแก้ารอยแตก
เมื่อใด eventual consistency เหมาะ
เหมาะเมื่ความพร้อมใช้งานสำคัญกว่าการมีข้อมูลปัจจุบันสมบูรณ์: ฟีดกิจกรรม ตัวนับวิว คำแนะนำ โปรไฟล์ที่แคช บันทึก/เทเลเมทรี และข้อมูลไม่สำคัญที่ "ถูกต้องในไม่กี่วินาที/นาที" เป็นที่ยอมรับ
การแก้ความขัดแย้ง: ประวัติที่ต่างกันถูกรวมอย่างไร
ติดตั้งเครื่องมือวัดสำหรับการแลกเปลี่ยน
เพิ่มเมตริกหน่วงเวลา อัตราข้อผิดพลาด และความล้าสมัย แล้วปรับเกณฑ์
เมื่อฐานข้อมูลยอมรับการเขียนบน replica หลายตัว อาจเกิดความขัดแย้ง: อัปเดตสองครั้งขึ้นไปกับไอเท็มเดียวกันที่เกิดขึ้นอิสระบน replica ต่างกันก่อนที่จะซิงก์
ตัวอย่างคลาสสิกคือผู้ใช้เปลี่ยนที่อยู่จัดส่งบนอุปกรณ์หนึ่ง ในขณะที่เปลี่ยนเบอร์โทรบนอีกอุปกรณ์ ถ้าการอัปเดตแต่ละอันไปตกคนละ replica ในช่วงตัดการเชื่อมต่อ ระบบต้องตัดสินว่าสุดท้ายแล้วเรคอร์ดไหนคือ "ของจริง" เมื่อ replica แลกเปลี่ยนข้อมูลกัน
Last-write-wins (LWW): ง่ายแต่เสี่ยง
หลายระบบเริ่มจาก last-write-wins: อันไหนมี timestamp ใหม่กว่าจะเขียนทับ
มันน่าสนใจเพราะทำได้ง่ายและเร็ว แต่ข้อเสียคืออาจ ทำให้ข้อมูลหายโดยเงียบ ๆ ถ้า "ใหม่สุด" ชนะ การเปลี่ยนที่สำคัญแต่เก่ากว่าอาจถูกทับ แม้สองการอัปเดตจะกระทบคนละฟิลด์
ยังสมมติว่านาฬิกาเชื่อถือได้ด้วย ความเบี้ยวนาฬิการะหว่างเครื่อง/ไคลเอนต์อาจทำให้การอัปเดตที่ผิดเป็นฝ่ายชนะ
เก็บประวัติ: version vectors และแนวคิดที่เกี่ยวข้อง
การจัดการความขัดแย้งที่ปลอดภัยมักต้องติดตามประวัติเชิงสาเหตุ
เชิงแนวคิด version vectors (และรูปแบบย่อย) ผูกเมตาดาต้ากับแต่ละเรคอร์ดที่สรุปว่า "โหนดไหนเห็นอัปเดตไหน" เมื่อ replica แลกเวอร์ชัน ฐานข้อมูลสามารถตรวจสอบได้ว่ารุ่นหนึ่งรวมอีกอัน (ไม่มีความขัดแย้ง) หรือแยกออก (ต้องแก้)
บางระบบใช้ตรรกะเวลาหรือ hybrid logical clocks เพื่อลดการพึ่งพานาฬิกาจริงในขณะที่ยังให้เบาะแสการจัดลำดับ
ผสานแทนการเขียนทับ
เมื่อพบความขัดแย้ง คุณมีทางเลือก:
- การผสานระดับแอป: แอปตัดสินใจรวมฟิลด์ แจ้งผู้ใช้ หรือเก็บทั้งสองเวอร์ชันไว้ตรวจสอบ
- CRDTs: โครงสร้างข้อมูลที่ออกแบบมาให้รวมกันอัตโนมัติและกำหนดได้ (เหมาะกับเคาน์เตอร์ เซ็ต ข้อความร่วมกัน เป็นต้น) พวกมันหลีกเลี่ยงการทำงานแบบ "ผู้ชนะกินทุกคน" ขณะที่ยังคงพร้อมใช้งานสูง
วิธีที่ดีที่สุดขึ้นกับความหมายของคำว่า "ถูกต้อง" สำหรับข้อมูลของคุณ—บางครั้งการสูญเสียการเขียนยอมรับได้ บางครั้งนั่นคือบั๊กทางธุรกิจสำคัญ
จะเลือกอย่างไรสำหรับกรณีใช้งานของคุณ
การเลือกทิศทางความสอดคล้อง/ความพร้อมใช้งานไม่ใช่การโต้วาทีเชิงปรัชญา แต่มันคือการตัดสินใจเชิงผลิตภัณฑ์ เริ่มจากถามว่า: ความเสียหายจากการผิดชั่วคราวคืออะไร และความเสียหายจากการบอกให้ผู้ใช้ "ลองใหม่ที" เป็นอย่างไร?
แมปความเสี่ยงทางธุรกิจกับความต้องการความสอดคล้อง
บางโดเมนต้องคำตอบเดียวที่น่าเชื่อถือทันทีเพราะ "เกือบถูก" ก็ผิดได้:
- การเงินและการเรียกเก็บเงิน: การเรียกเก็บซ้ำ โอเวอร์ดราฟ และการคืนเงินมักต้องความสอดคล้องสูง
- ตัวตนและสิทธิ์เข้าใช้งาน: การล็อกอิน รีเซ็ตรหัสผ่าน การควบคุมการเข้าถึง ควรหลีกเลี่ยงพฤติกรรม split-brain
- สินค้าคงคลังและความจุ: ถ้าการขายเกินไม่ยอมรับได้ (ตั๋ว สินค้าจำนวนจำกัด) ควรเน้นความสอดคล้อง—หรือออกแบบระบบสำรองที่ชัดเจน
ถ้าผลกระทบจากความไม่ตรงกันชั่วคราวต่ำหรือย้อนกลับได้ คุณมักจะเลือกความพร้อมใช้งานมากขึ้น
ตัดสินใจว่าคุณยอมให้ข้อมูลล้าสมัยได้นานแค่ไหน
ประสบการณ์ผู้ใช้หลายอย่างโอเคกับการอ่านเก่าสักเล็กน้อย:
- ฟีดและไทม์ไลน์: โพสต์มาปรากฏช้าสักไม่กี่วินาทีก็มักรับได้
- การวิเคราะห์และแดชบอร์ด: ตัวเลขเป็นชุด/ล่าช้าก็เป็นที่คาดหวัง
- แคชและดัชนีค้นหา: ผู้ใช้ยอมรับว่า "ยังไม่อัปเดต" หากรวดเร็วและเสถียร
ชัดเจนว่าระยะเวลาที่ยอมรับได้คือเท่าไร: วินาที นาที หรือชั่วโมง งบเวลานี้จะกำหนดการตั้งค่าการจำลองและควอรัมของคุณ
เลือกโหมดความล้มเหลวที่ผู้ใช้จะเกลียดน้อยที่สุด
เมื่อ replica ไม่สามารถตกลงกัน คุณมักจะได้หนึ่งในสามผลลัพธ์ UX:
- หมุนรอ/รอคอย (เน้นความถูกต้อง อาจรู้สึกช้า)
- ข้อผิดพลาด / ลองใหม่ (ตรงไปตรงมา แต่ขัดจังหวะ)
- ผลลัพธ์ล้าสมัย (ราบรื่น แต่บางครั้งน่าประหลาดใจ)
เลือกตัวเลือกที่สร้างความเสียหายน้อยที่สุดต่อฟีเจอร์ ไม่ใช่ทั้งระบบ
เช็คลิสต์ด่วน
เชื่อม C (consistency) ถ้า: ผลลัพธ์ผิดสร้างความเสี่ยงทางการเงิน/กฎหมาย ความปลอดภัย หรือการกระทำที่ไม่สามารถย้อนกลับ
เชื่อม A (availability) ถ้า: ผู้ใช้ให้ความสำคัญกับการตอบสนอง ข้อมูลล้าสมัยยอมรับได้ และความขัดแย้งสามารถแก้ได้ภายหลัง
ถ้าสงสัย แยกระบบ: เก็บเรคอร์ดสำคัญให้สอดคล้องอย่างเข้มงวด และปล่อยมุมมองอนุมาน (ฟีด แคช วิเคราะห์) ให้เน้นความพร้อมใช้งาน
แบบแผนการออกแบบเพื่อลดความเจ็บปวดจากการแลกเปลี่ยน
ออกแบบการลองใหม่ที่ปลอดภัยอย่างรวดเร็ว
สร้าง endpoint เขียนแบบ idempotent และ flow ของไคลเอ็นต์ที่ปลอดภัยต่อการลองใหม่โดยไม่ต้องสร้างสแตกใหม่
คุณไม่จำเป็นต้องเลือกค่าเดียวสำหรับทั้งระบบ ฐานข้อมูลกระจายสมัยใหม่หลายตัวให้คุณเลือกความสอดคล้องต่อการดำเนินการ และแอปที่ฉลาดใช้ประโยชน์จากสิ่งนี้เพื่อรักษาประสบการณ์ผู้ใช้ให้ราบเรียบโดยไม่ปิดบังการแลกเปลี่ยน
ใช้ระดับความสอดคล้องต่อการดำเนินการ
ปฏิบัติกับความสอดคล้องเหมือนปุ่มปรับตามสิ่งที่ผู้ใช้กำลังทำ:
- อัปเดตสำคัญ (การชำระเงิน การลดสต็อก การเปลี่ยนรหัสผ่าน): ใช้ความสอดคล้องที่เข้มงวดกว่า (เช่น เขียนแบบควอรัม/linearizable)
- การอ่านไม่สำคัญ (ฟีด แดชบอร์ด "เห็นล่าสุด" ): อนุญาตการอ่านที่อ่อนแอกว่า (ท้องถิ่น/หนึ่ง replica/ eventual) เพื่อความเร็วและความทนทาน
วิธีนี้หลีกเลี่ยงการจ่ายต้นทุนความสอดคล้องสูงสุดสำหรับทุกอย่าง แต่ยังปกป้องการดำเนินการที่จำเป็นจริง ๆ
ผสมแบบแรงและอ่อนในฟลูว์เดียว
รูปแบบที่พบบ่อยคือ แรงสำหรับเขียน อ่อนสำหรับอ่าน:
- เขียนด้วยระดับเข้มงวดเพื่อให้ระบบมีบันทึกที่เป็นทางการ
- อ่านด้วยระดับหลวมกว่า และหากตรวจพบบางอย่าง "ผิด" (ไอเท็มหาย เคาน์เตอร์ล้าสมัย) ให้รีเฟรชด้วยการอ่านที่เข้มงวดกว่า หรือแสดงข้อความว่า "กำลังอัปเดต"
ในบางกรณี ทำแบบกลับกัน: เขียนเร็ว (คิว/แบบ eventual) พร้อม อ่านเข้มงวด เมื่อยืนยันผล ("คำสั่งของฉันไปแล้วหรือยัง?")
ออกแบบสำหรับการลองใหม่: idempotency
เมื่อเครือข่ายสั่นคลอน ลูกค้ามักลองใหม่ ทำให้ลองใหม่ปลอดภัยด้วย idempotency keys เพื่อให้การส่งคำสั่งซ้ำ ๆ (เช่น "ส่งคำสั่งซื้อ") จะไม่สร้างคำสั่งซ้ำ เก็บและใช้ผลลัพธ์แรกเมื่อเห็นคีย์เดิมอีกครั้ง
เวิร์กโฟลว์ยาว: sagas และการชดเชย
สำหรับการกระทำหลายขั้นข้ามบริการ ให้ใช้ saga: แต่ละขั้นมี การกระทำชดเชย (คืนเงิน ปล่อยการจอง ยกเลิกการจัดส่ง) วิธีนี้ทำให้ระบบกู้คืนได้แม้บางส่วนไม่ตรงกันหรือล้มเหลวชั่วคราว
การทดสอบและการมองเห็นสำหรับความสอดคล้อง vs ความพร้อมใช้งาน
คุณจะจัดการการแลกเปลี่ยนไม่ได้ถ้าคุณมองไม่เห็น ปัญหาในโปรดักชันมักดูเหมือน "ข้อผิดพลาดสุ่ม" จนกว่าคุณจะเพิ่มการวัดและการทดสอบที่เหมาะสม
ควรวัดอะไร (และทำไม)
เริ่มจากชุดเมตริกเล็ก ๆ ที่เชื่อมตรงกับผลกระทบต่อผู้ใช้:
- Latency (p50/p95/p99): มองหาสไปก์ในช่วง failover หรือ retry ควอรัม
- Error rate: แยกระหว่างข้อผิดพลาดหนัก (timeouts, 5xx) กับข้อผิดพลาดเบา (คืนผลจาก fallback, ผลลัพธ์บางส่วน)
- Stale read rate: สัดส่วนการอ่านที่คืนค่าข้อมูลเก่ากว่าตัวชี้วัดที่ตั้งไว้ (เช่น เก่ากว่า 2 วินาที)
- Conflict rate: ความถี่ที่การเขียนพร้อมกันต้องการการรวม (รวมถึงการทับแบบ last-write-wins)
ถ้าเป็นไปได้ ติด tag เมตริกตาม โหมดความสอดคล้อง (ควอรัม vs ท้องถิ่น) และ ภูมิภาค/โซน เพื่อหาจุดแตกต่างของพฤติกรรม
ทดสอบพาร์ติชันโดยตั้งใจ
อย่ารอการล้มจริง ในสเตจ ลอง chaos experiments ที่จำลอง:
- ทิ้งแพ็กเก็ตและหน่วงสูงระหว่าง replica
- หนึ่งภูมิภาคไม่สามารถเข้าถึงได้
- พาร์ติชันบางส่วนที่โหนดบางตัวคุยกันได้แค่บางส่วน
ตรวจสอบไม่ใช่แค่ "ระบบยังขึ้น" แต่ให้ดูว่าการรับประกันอะไรยังคงอยู่: การอ่านยังสดไหม การเขียนบล็อกหรือไม่ ลูกค้าได้ข้อผิดพลาดชัดเจนหรือไม่
การแจ้งเตือนที่จับการแลกเปลี่ยนตั้งแต่ต้น
เพิ่มการแจ้งเตือนสำหรับ:
- replication lag เกินหน้าต่างเวลาที่ยอมรับได้
- ล้มเหลวควอรัม (เข้าถึง replica ไม่พอ) และจำนวน retry ที่เพิ่ม
- อัตราความขัดแย้งหรือคิวการรวมที่เพิ่มขึ้น
สุดท้าย ทำให้การรับประกันชัดเจน: เอกสารว่าสัญญาอะไรระหว่างการทำงานปกติและระหว่างพาร์ติชัน และสอนทีมผลิตภัณฑ์และซัพพอร์ตว่าผู้ใช้จะเห็นอะไรและจะตอบอย่างไร
การทำต้นแบบตัวเลือก CAP ให้เร็วขึ้น (โดยไม่ต้องสร้างใหม่ทั้งหมด)
ถ้าคุณกำลังสำรวจการแลกเปลี่ยนเหล่านี้ในผลิตภัณฑ์ใหม่ ควรยืนยันสมมติฐานตั้งแต่ต้น—โดยเฉพาะพฤติกรรมการล้ม ลักษณะการลองใหม่ และรูปร่างของข้อมูลล้าสมัยใน UI
แนวทางปฏิบัติที่ใช้ได้จริงคือทำต้นแบบขนาดเล็กของเวิร์กโฟลว์ (เส้นทางเขียน เส้นทางอ่าน การลองใหม่/ไอดีมพอเทนซี และงานรวมผล) ก่อนตัดสินใจสถาปัตยกรรมเต็มรูปแบบ ด้วย Koder.ai, ทีมสามารถสปินเว็บแอปและแบ็กเอนด์ผ่านเวิร์กโฟลว์ที่ขับเคลื่อนด้วยแชท ทำซ้ำโมเดลข้อมูลและ API ได้รวดเร็ว และทดสอบรูปแบบความสอดคล้องต่าง ๆ (เช่น เขียนเคร่งครัด + อ่านผ่อนปรน) โดยไม่ต้องผ่าน pipeline การสร้างแบบดั้งเดิม เมื่อต้นแบบตรงกับพฤติกรรมที่ต้องการ คุณสามารถส่งออกซอร์สโค้ดและพัฒนาต่อสู่การผลิตได้
คำถามที่พบบ่อย
Why do distributed databases face a consistency vs availability trade-off?
ในฐานข้อมูลที่ทำสำเนา ข้อมูล "เดียวกัน" จะอาศัยอยู่บนเครื่องหลายเครื่อง สิ่งนี้ช่วยเพิ่มความทนทานและลดหน่วงเวลา แต่ก็นำปัญหาการประสานมาด้วย: โหนดอาจช้า ไม่สามารถเข้าถึงได้ หรือตกอยู่ในสภาวะแยกของเครือข่าย ทำให้พวกมันไม่สามารถตกลงกันทันทีว่าการเขียนล่าสุดคืออะไร
What does “consistency” mean in plain terms?
หมายถึง: หลังการเขียนที่สำเร็จ การอ่านใด ๆ ภายหลังจะต้องคืนค่าที่เหมือนกันไม่ว่าจะอ่านจาก replica ใด ในทางปฏิบัติ ระบบมักบังคับโดยการหน่วงหรือปฏิเสธการอ่าน/การเขียนจนกว่า replica เพียงพอ (หรือ leader) จะยืนยันการอัปเดต
What does “availability” mean in plain terms?
หมายถึงระบบจะตอบกลับด้วยการตอบที่ไม่ใช่ข้อผิดพลาดสำหรับทุกคำขอ แม้บางโหนดจะล้มเหลวหรือไม่สามารถสื่อสารได้ คำตอบนั้นอาจเป็นข้อมูลล้าสมัย เป็นผลลัพธ์บางส่วน หรือมาจากความรู้ในเครื่องท้องถิ่น แต่ระบบหลีกเลี่ยงการบล็อกผู้ใช้ระหว่างความล้มเหลว
What is a network partition, and why does it matter so much?
คือการตัดการสื่อสารระหว่างโหนดที่ควรทำงานร่วมกัน โหนดยังอาจทำงานได้ปกติ แต่ข้อความไม่สามารถข้ามการแบ่งได้อย่างเชื่อถือได้ ซึ่งบีบให้ฐานข้อมูลต้องเลือกระหว่าง:
- การบล็อก/ปฏิเสธคำขอเพื่อรักษาความจริงเดียว (consistency), หรือ
- การตอบคำขอบนแต่ละฝั่งแล้วมาตรวจสอบ/รวมผลภายหลัง (availability).
What do users actually experience during partitions or replica disagreement?
ทั้งสองฝั่งอาจรับอัปเดตที่อีกฝั่งยังไม่เห็น ส่งผลให้เกิด:
- Timeouts: รอ replica ที่ไม่สามารถเข้าถึงได้
- Stale reads: อ่านจาก replica ที่ตามไม่ทัน
- Split-brain behavior: ผู้ใช้คนต่าง ๆ เห็น "ความจริง" ที่ต่างกัน
นี่คือผลกระทบที่ผู้ใช้เห็นเมื่อ replica ไม่สามารถประสานกันได้ชั่วคราว
Does CAP theorem really mean you can only pick two out of three?
มันไม่ได้หมายความว่า "เลือกได้แค่สองตลอดไป" แต่หมายความว่า เมื่อเกิดพาร์ติชัน คุณไม่สามารถรับรองทั้ง:
- Consistency (ทุกคนอ่านการเขียนที่ได้รับการยืนยันล่าสุด), และ
- Availability (ทุกคำขอได้รับการตอบ)
นอกช่วงพาร์ติชัน ระบบส่วนใหญ่สามารถดูเหมือนให้ทั้งสองได้ในเวลาปกติ—จนกว่าเครือข่ายจะเกิดปัญหา
How do quorums (N, R, W) help balance consistency and availability?
ควอรัมใช้การโหวตข้าม replica:
- N = จำนวน replica
- W = จำนวน replica ที่ต้องยืนยันการเขียน
- R = จำนวน replica ที่ถามสำหรับการอ่าน
แนวทางที่พบบ่อยคือ R + W > N เพื่อลดการอ่านล้าสมัย ควอรัมไม่ได้กำจัดพาร์ติชัน แต่กำหนดว่าใครมีสิทธิเพื่อให้ระบบก้าวหน้า (เช่น ฝั่งที่ยังมีเสียงข้างมากจะทำงานต่อได้)
What is eventual consistency, and what anomalies should I expect?
ความสอดคล้องแบบท้ายที่สุดยอมให้ replica ไม่สอดคล้องกันชั่วคราว ตราบใดที่พวกมัน รวมเป็นค่าเดียวกัน ในภายหลัง อาการที่พบได้บ่อยรวมถึง:
- Stale reads
- Read-your-writes gaps (คุณไม่เห็นการอัปเดตของตัวเองทันที)
- Out-of-order updates
ระบบมักลดช่องเวลาความไม่สอดคล้องด้วย , , และการไล่เช็ค/ซิงก์เป็นระยะ (anti-entropy)
How are conflicting writes reconciled after a partition heals?
ความขัดแย้งเกิดเมื่อ replica ยอมรับการเขียนต่างกันกับรายการเดียวกันในช่วงการตัดการเชื่อมต่อ กลยุทธ์การแก้ไขรวมถึง:
- Last-write-wins (LWW): ง่ายแต่เสี่ยงจะทับข้อมูลและพึ่งพานาฬิกา
- Version vectors / metadata เชิงสาเหตุ: ตรวจสอบว่ารุ่นหนึ่งรวมอีกอันหรือไม่ (ไม่มีความขัดแย้ง) หรือแยกกัน (ต้องแก้)
- Merging / CRDTs: โครงสร้างข้อมูลที่รวมกันโดยอัตโนมัติและเป็นการตัดสินที่กำหนดได้สำหรับบางชนิดข้อมูล
เลือกวิธีตามความหมายของ “ถูกต้อง” สำหรับข้อมูลของคุณ
How do I choose the right consistency vs availability posture for my application?
เริ่มจากถามว่า: ความผิดพลาดชั่วคราวมีค่าเสียหายเท่าไร และการบอกให้ผู้ใช้ "ลองใหม่ที" มีผลอย่างไร
- เลือก ความสอดคล้องสูง สำหรับเงิน การเรียกเก็บเงิน สิทธิการเข้าถึง และการกระทำที่ไม่สามารถย้อนกลับได้
- เลือก ความพร้อมใช้งาน เมื่อการตอบสนองสำคัญกว่าและข้อมูลล้าสมัยสามารถแก้ไขได้ภายหลัง (เช่น ฟีด การวิเคราะห์ แคช)
รูปแบบปฏิบัติได้แก่ การตั้งระดับความสอดคล้องต่อการดำเนินการ, ใช้คีย์ idempotency สำหรับการลองใหม่ และใช้ saga พร้อมการชดเชยสำหรับเวิร์กโฟลว์หลายขั้นตอน