24 ต.ค. 2568·3 นาที
ทำไมการทำดัชนีฐานข้อมูลจึงเป็นตัวเร่งประสิทธิภาพที่สำคัญที่สุด
เรียนรู้ว่าดัชนีฐานข้อมูลลดเวลาในการค้นหาอย่างไร เมื่อใดที่ช่วยหรือทำให้แย่ลง และขั้นตอนปฏิบัติในการออกแบบ ทดสอบ และบำรุงรักษาดัชนีสำหรับแอปจริง
เรียนรู้ว่าดัชนีฐานข้อมูลลดเวลาในการค้นหาอย่างไร เมื่อใดที่ช่วยหรือทำให้แย่ลง และขั้นตอนปฏิบัติในการออกแบบ ทดสอบ และบำรุงรักษาดัชนีสำหรับแอปจริง
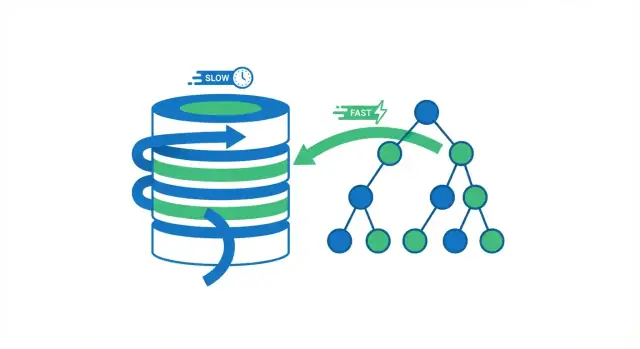
ดัชนีฐานข้อมูลเป็นโครงสร้างค้นหาแยกต่างหากที่ช่วยให้ฐานข้อมูลค้นหาแถวได้เร็วขึ้น มันไม่ใช่สำเนาที่สองของตาราง คิดเสมือนหน้าดัชนีในหนังสือ: คุณใช้ดัชนีเพื่อกระโดดไปยังบริเวณที่ใกล้เคียง แล้วอ่านหน้าที่ต้องการจริง ๆ
ถ้าไม่มีดัชนี ฐานข้อมูลมักมีตัวเลือกเดียวที่ปลอดภัย: อ่านผ่านหลายแถวเพื่อตรวจว่าตัวไหนตรงตามคำค้น ซึ่งอาจไม่เป็นปัญหาถ้าตารางมีแค่ไม่กี่พันแถว แต่เมื่อโตขึ้นเป็นล้านแถว “การตรวจหลายแถว” จะกลายเป็นการอ่านดิสก์มากขึ้น แรงกดดันต่อหน่วยความจำเพิ่มขึ้น และงาน CPU มากขึ้น — ทำให้คำค้นที่เคยรู้สึกเหมือนไม่มีปัญหาเริ่มช้าลง
ดัชนีลดปริมาณข้อมูลที่ฐานข้อมูลต้องตรวจเพื่อให้ตอบคำถาม เช่น “หา order ที่มี ID 123” หรือ “ดึงผู้ใช้ที่มีอีเมลนี้” แทนที่จะสแกนทุกอย่าง ฐานข้อมูลจะตามโครงสร้างกะทัดรัดที่ค่อย ๆ แคบการค้นหา
แต่การทำดัชนีไม่ใช่ยาวิเศษ บางคำค้นยังต้องประมวลผลแถวจำนวนมาก (รายงานกว้าง ๆ ตัวกรองที่มี selectivity ต่ำ การรวมกลุ่มหนัก ๆ) และดัชนีก็มีค่าใช้จ่ายจริง: พื้นที่จัดเก็บเพิ่มขึ้นและการเขียนช้าลง เพราะการแทรกและการอัปเดตต้องอัปเดตดัชนีด้วย
คุณจะได้เห็น:
เมื่อฐานข้อมูลรันคำค้น มันมีตัวเลือกกว้าง ๆ สองแบบ: สแกนทั้งตารางทีละแถว หรือกระโดดไปยังแถวที่ตรงเลย ผลประโยชน์จากดัชนีส่วนใหญ่เกิดจากการหลีกเลี่ยงการอ่านที่ไม่จำเป็น
การสแกนตารางทั้งหมด คือการอ่านทุกแถว ตรวจดูว่าแต่ละแถวตรงตามเงื่อนไข WHERE หรือไม่ แล้วจึงส่งผลกลับ วิธีนี้รับได้กับตารางเล็ก แต่จะช้าลงอย่างทำนายได้เมื่อโตขึ้น — แถวมากขึ้นหมายถึงงานมากขึ้น
ด้วย ดัชนี ฐานข้อมูลมักจะหลีกเลี่ยงการอ่านแถวส่วนใหญ่ได้ แทนที่จะสแกนทุกอย่าง มันจะเช็กดัชนีก่อน (โครงสร้างกะทัดรัดที่สร้างมาเพื่อการค้นหา) เพื่อหาว่าแถวที่ตรงอยู่ที่ไหน แล้วอ่านเฉพาะแถวเหล่านั้น
คิดถึงหนังสือ หากต้องการหน้าทุกหน้าที่กล่าวถึง “photosynthesis” คุณอาจอ่านหนังสือทั้งหมด (การสแกนเต็ม) หรือใช้ดัชนีของหนังสือแล้วกระโดดไปที่หน้าที่ระบุ (การค้นด้วยดัชนี) วิธีที่สองเร็วกว่ามากเพราะข้ามหน้าส่วนใหญ่ได้
ฐานข้อมูลใช้เวลามากในส่วนที่รอการอ่าน โดยเฉพาะเมื่อข้อมูลยังไม่อยู่ในหน่วยความจำ การลดจำนวนแถว (และเพจ) ที่ต้องแตะต้องมักจะลด:
การทำดัชนีช่วยได้มากเมื่อ ข้อมูลมีขนาดใหญ่ และรูปแบบคำค้นมีความคัดสรร (เช่น ดึง 20 แถวจาก 10 ล้านแถว) หากคำค้นคืนแถวเกือบทั้งหมด หรือถ้าตารางเล็กพอที่จะอยู่ทั้งหมดในหน่วยความจำ การสแกนอาจเร็วพอหรือเร็วกว่าก็ได้
ดัชนีทำงานโดยจัดระเบียบค่าเพื่อให้ฐานข้อมูลสามารถกระโดดไปยังสิ่งที่ต้องการได้แทนที่จะเช็กทุกแถว
โครงสร้างดัชนีที่ใช้บ่อยที่สุดในฐานข้อมูล SQL คือ B-tree (หรือ “B+tree”) โดยแนวคิดคือ:
เพราะมันเรียงลำดับ B-tree ดีทั้งกับการค้นหาแบบ เท่ากับ (WHERE email = ...) และ การค้นหาช่วง (WHERE created_at >= ... AND created_at < ...) ฐานข้อมูลสามารถนำทางไปยังย่านค่าที่ถูกต้องแล้วสแกนไปข้างหน้าเป็นลำดับได้
คนมักพูดว่าการค้นใน B-tree เป็นแบบ “ลอการิทึม” ในทางปฏิบัติหมายความว่า: เมื่อข้อมูลโตจากพันเป็นล้าน ขั้นตอนการค้นเติบโตช้า ไม่ได้เติบโตแบบสัดส่วนโดยตรง
แทนที่จะเป็น “ข้อมูลเพิ่มสองเท่าหมายถึงงานเพิ่มสองเท่า” มันเหมือนกับ “ข้อมูลมากขึ้นมากแต่ต้องเพิ่มขั้นตอนนำทางเพียงเล็กน้อย” เพราะฐานข้อมูลเดินตามตัวชี้ผ่านไม่กี่ระดับของต้นไม้
บางเอนจินมี ดัชนีแฮช ซึ่งเร็วมากสำหรับการค้นหาแบบ equality เพราะค่าจะถูกแปลงเป็นแฮชและใช้เพื่อหาที่อยู่โดยตรง
ข้อแลกเปลี่ยน: ดัชนีแฮชมักไม่ช่วยเรื่องการค้นช่วงหรือการสแกนเรียงลำดับ และการรองรับแตกต่างกันในแต่ละฐานข้อมูล
PostgreSQL, MySQL/InnoDB, SQL Server และอื่น ๆ เก็บและใช้ดัชนีต่างกัน (ขนาดเพจ การจัดเก็บแบบคลัสเตอร์ คอลัมน์ที่รวมไว้ การมองเห็น) แต่แนวคิดหลักคือ: ดัชนีสร้างโครงสร้างกะทัดรัดที่นำทางได้ ทำให้ฐานข้อมูลหาตำแหน่งแถวที่ตรงได้โดยงานน้อยกว่าการสแกนทั้งตารางมาก
ดัชนีไม่ได้ทำให้ "SQL" ทั้งหมดเร็วขึ้น — มันทำให้รูปแบบการเข้าถึงเฉพาะเร็วขึ้น เมื่อดัชนีสอดคล้องกับการกรอง การเข้าร่วม หรือการจัดเรียงของคำค้น ฐานข้อมูลจะสามารถกระโดดไปหาชุดแถวที่เกี่ยวข้องแทนที่จะอ่านทั้งตาราง
1) เงื่อนไข WHERE (โดยเฉพาะคอลัมน์ที่มี selectivity สูง)
ถ้าคำค้นมักจะกรองตารางใหญ่ลงให้เหลือชุดแถวเล็ก ๆ ดัชนีมักเป็นที่แรกที่ควรมอง ตัวอย่างคลาสสิกคือการค้นผู้ใช้โดยตัวระบุ
ถ้าไม่มีดัชนีบน users.email ฐานข้อมูลอาจต้องสแกนทุกแถว:
SELECT * FROM users WHERE email = '[email protected]';
ถ้ามีดัชนีบน email มันจะหาตำแหน่งของแถวที่ตรงได้อย่างรวดเร็วและหยุด
2) คอลัมน์ที่ใช้ JOIN (foreign key และคอลัมน์อ้างอิง)
การ JOIN เป็นจุดที่ความไม่ประสิทธิภาพเล็ก ๆ จะกลายเป็นค่าใช้จ่ายใหญ่ หากคุณ JOIN orders.user_id กับ users.id การมีดัชนีบนคอลัมน์ JOIN (เช่น orders.user_id และ primary key users.id) ช่วยให้ฐานข้อมูลจับคู่แถวโดยไม่ต้องสแกนซ้ำ ๆ
3) ORDER BY (เมื่อคุณต้องการผลลัพธ์ที่เรียงแล้ว)
การเรียงลำดับเมื่อฐานข้อมูลต้องเก็บแถวจำนวนมากแล้วค่อยเรียงนั้นมีค่าใช้จ่ายสูง หากคุณมักรัน:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
ดัชนีที่สอดคล้องกับ user_id และคอลัมน์การเรียงสามารถให้เอนจินอ่านแถวในลำดับที่ต้องการได้เลย แทนที่จะต้อง sort ผลลัพธ์ขนาดใหญ่
4) GROUP BY (เมื่อการจัดกลุ่มสอดคล้องกับดัชนี)
การจัดกลุ่มอาจได้ประโยชน์เมื่อฐานข้อมูลสามารถอ่านข้อมูลในลำดับกลุ่มได้ ไม่รับประกันเสมอไป แต่ถ้าคุณกลุ่มโดยคอลัมน์ที่ใช้กรองหรือเป็นลำดับตามดัชนี เอนจินอาจทำงานน้อยลง
ดัชนี B-tree ดีเป็นพิเศษกับ เงื่อนไขช่วง — นึกถึงวันที่ ราคา และคำค้นแบบ “ระหว่าง”:
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
สำหรับแดชบอร์ด รายงาน และหน้ากิจกรรมล่าสุด รูปแบบนี้มีอยู่ทั่วไป และดัชนีบนคอลัมน์ช่วงมักให้การปรับปรุงทันที
ธีมง่าย ๆ คือ: ดัชนีช่วยได้มากเมื่อมันสะท้อนวิธีที่คุณค้นหาและเรียง ถ้าคำค้นของคุณตรงกับรูปแบบการเข้าถึงเหล่านั้น ฐานข้อมูลจะทำการอ่านแบบมุ่งเป้าแทนการสแกนกว้าง
ดัชนีช่วยได้มากเมื่อมันกรองจำนวนแถวที่ต้องแตะได้ชัดเจน คุณสมบัตินี้เรียกว่า selectivity
selectivity พูดง่าย ๆ ว่า: มีแถวกี่แถวที่ตรงกับค่าหนึ่ง ๆ? คอลัมน์ที่มี selectivity สูงมีค่าจำนวนมาก ทำให้แต่ละการค้นพบเจอแถวน้อย
email, user_id, order_number (มักจะเป็นเอกลักษณ์หรือใกล้เคียง)is_active, is_deleted, status ที่มีค่าบ่อย ๆ ไม่กี่ค่ากับ selectivity สูง ดัชนีจะพากระโดดไปยังชุดแถวเล็ก ๆ ได้ แต่กับ selectivity ต่ำ ดัชนีชี้ไปยังชิ้นส่วนใหญ่ของตาราง ทำให้ฐานข้อมูลยังต้องอ่านและกรองมาก
สมมติว่าตารางมี 10 ล้านแถว และมีคอลัมน์ is_deleted ที่ 98% เป็น false ดัชนีบน is_deleted จะไม่ช่วยมากสำหรับ:
SELECT * FROM orders WHERE is_deleted = false;
ชุดผลที่ตรงยังเป็นเกือบทั้งตาราง การใช้ดัชนีอาจช้ากว่าสแกนแบบลำดับเพราะเอนจินต้องกระโดดระหว่างรายการดัชนีและเพจของตารางมากขึ้น
ตัววางแผนจะประเมินค่าใช้จ่าย หากดัชนีไม่ช่วยลดงานมากพอ — เพราะมีแถวตรงมากเกินไป หรือคำค้นต้องคอลัมน์มาก — มันอาจเลือกสแกนตารางทั้งหมด
การแจกแจงข้อมูลไม่คงที่ คอลัมน์ status อาจกระจายดีในตอนแรกแล้วค่อยมีค่าเดียวโดดเด่น ถ้าสถิติไม่อัปเดต ตัววางแผนอาจเลือกแผนที่ไม่ดี และดัชนีที่เคยมีประโยชน์อาจหยุดช่วย
ดัชนีคอลัมน์เดียวเป็นจุดเริ่มที่ดี แต่คำค้นจริงมักกรองด้วยคอลัมน์หนึ่งและเรียง/กรองด้วยอีกคอลัมน์ นี่คือที่ที่ ดัชนีรวมคอลัมน์ (composite) โชว์ประโยชน์: ดัชนีเดียวสามารถรองรับหลายส่วนของคำค้นได้
ฐานข้อมูลส่วนใหญ่ (โดยเฉพาะกับ B-tree) สามารถใช้ดัชนีรวมได้อย่างมีประสิทธิภาพจาก คอลัมน์ซ้ายสุด ไปข้างหน้า นึกว่าดัชนีเรียงตามคอลัมน์ A ก่อน แล้วภายในนั้นเรียงตาม B เป็นต้น
นั่นหมายความว่า:
account_id แล้วเรียงหรือกรอง created_atcreated_at (เพราะมันไม่ใช่คอลัมน์ซ้ายสุด)งานทั่วไปคือ “แสดงกิจกรรมล่าสุดของบัญชีนี้” รูปแบบคำค้นนี้:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
มักได้ประโยชน์มากจาก:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
ฐานข้อมูลสามารถกระโดดไปยังส่วนของบัญชีในดัชนี แล้วอ่านแถวตามลำดับเวลาทันที แทนที่จะสแกนแล้วเรียงผลลัพธ์ขนาดใหญ่
ดัชนีครอบคลุม มีคอลัมน์ที่คำค้นต้องทั้งหมด ทำให้ฐานข้อมูลคืนผลจากดัชนีโดยไม่ต้องมองแถวในตาราง (ลดการอ่านและ I/O แบบสุ่ม)
ระวัง: เพิ่มคอลัมน์มากเกินไปจะทำให้ดัชนีใหญ่และแพงขึ้น
ดัชนีกว้างอาจทำให้การเขียนช้าลงและใช้พื้นที่มาก เพิ่มเฉพาะสำหรับคำค้นที่มีคุณค่าและตรวจสอบด้วย EXPLAIN และการวัดจริงก่อนและหลัง
ดัชนีมักถูกพูดว่าเป็น “ความเร็วฟรี” แต่ไม่ฟรี ดัชนีต้องได้รับการบำรุงรักษาทุกครั้งที่ตารางเปลี่ยน และใช้ทรัพยากรจริง
เมื่อคุณ INSERT แถวใหม่ ฐานข้อมูลไม่ได้เขียนแถวเพียงครั้งเดียว — มันยังต้องแทรก entry ลงในดัชนีแต่ละตัวที่มีในตารางนั้นด้วย เช่นเดียวกับ DELETE และหลาย UPDATE
นี่คือเหตุผลที่ “มีดัชนีมาก” อาจทำให้โหลดเขียนหนัก ๆ ช้าลง การ UPDATE ที่แตะคอลัมน์ที่มีดัชนีอาจมีค่าใช้จ่ายสูงเป็นพิเศษ: อาจต้องลบ entry เก่าแล้วเพิ่ม entry ใหม่ (และในบางเอนจินอาจเกิด page split หรือการปรับสมดุลภายใน)
ถ้าแอปของคุณเขียนหนัก — event ของคำสั่งซื้อ ข้อมูลเซ็นเซอร์ บันทึก — การทำดัชนีทุกอย่างอาจทำให้ฐานข้อมูลรู้สึกหน่วงแม้ว่าการอ่านจะเร็ว
ดัชนีแต่ละตัวใช้พื้นที่ดิสก์ ในตารางขนาดใหญ่ ดัชนีอาจมีขนาดเท่าหรือเกินกว่าขนาดตาราง โดยเฉพาะถ้ามีดัชนีซ้อนทับกันหลายตัว
มันยังส่งผลต่อหน่วยความจำ ฐานข้อมูลพึ่งพาแคชชิงอย่างมาก; หาก working set ของคุณรวมดัชนีขนาดใหญ่มาก แคชต้องเก็บเพจมากขึ้นเพื่อให้ความเร็ว หากไม่ได้ หน่วยความจำจะถูกใช้งานมากขึ้นและคุณจะเห็นการอ่านจากดิสก์บ่อยขึ้นและประสิทธิภาพที่ไม่แน่นอน
การทำดัชนีคือการเลือกว่าจะเร่งอะไร ถ้า workload เน้นอ่าน ดัชนีเพิ่มอาจคุ้มค่า ถ้าเน้นเขียน ให้จัดลำดับความสำคัญบนดัชนีที่รองรับคำค้นที่สำคัญที่สุดและหลีกเลี่ยงดัชนีซ้ำ ๆ กฎปฏิบัติ: เพิ่มดัชนีเมื่อคุณสามารถระบุคำค้นที่มันช่วยได้ — และยืนยันว่ากำไรด้านการอ่านชดเชยค่าใช้จ่ายด้านการเขียนและการบำรุงรักษา
การเพิ่มดัชนี น่าจะ ช่วย — แต่คุณควรยืนยัน เครื่องมือสองอย่างที่ทำให้เรื่องนี้เป็นข้อเท็จจริงคืแผนคำค้น (EXPLAIN) และการวัดก่อน/หลังจริง
รัน EXPLAIN (หรือ EXPLAIN ANALYZE) บนคำค้นที่คุณสนใจ
EXPLAIN ANALYZE): ถ้าผลคาดการณ์ 100 แถวแต่จริง ๆ แตะ 100,000 แถว ตัว optimizer ประเมินผิด — มักเพราะสถิติไม่สดหรือเงื่อนไขมี selectivity น้อยกว่าคาดORDER BY ขั้นตอนการ sort อาจหายไป ซึ่งคือการชนะครั้งใหญ่เทียบเบสไลน์ของคุณโดยบันทึกความหน่วง (p50/p95), จำนวนแถวที่สแกน และผลกระทบต่อ CPU/IO เก็บผลแผนปัจจุบัน (EXPLAIN / EXPLAIN ANALYZE) เพื่อเปรียบเทียบ
ระวังแคช: การรันครั้งแรกอาจช้ากว่าเพราะข้อมูลยังไม่อยู่ในหน่วยความจำ หลายรันถัดไปอาจดูเร็วขึ้นแม้ไม่มีดัชนี เพื่อหลีกเลี่ยงการหลอกตัวเอง ให้เปรียบเทียบหลายรอบและดูว่ารูปทรงแผนเปลี่ยนหรือไม่ (ดัชนีถูกใช้ แถวที่อ่านน้อยลง) นอกเหนือจากเวลาเพียงอย่างเดียว
ถ้า EXPLAIN ANALYZE แสดงว่าจำนวนแถวน้อยลงและขั้นตอนที่แพง ๆ (เช่น sort) ลดลง คุณก็พิสูจน์ได้ว่าดัชนีช่วยจริง ไม่ใช่แค่คาดหวัง
คุณอาจเพิ่มดัชนีที่ "ถูกต้อง" แต่ยังไม่เห็นการปรับปรุงถ้าคำค้นเขียนในลักษณะที่ป้องกันไม่ให้ฐานข้อมูลใช้ดัชนี ปัญหาเหล่านี้มักเป็นเรื่องบอบบาง เพราะคำค้นยังให้ผลถูกต้อง — แค่ถูกบังคับให้ใช้แผนที่ช้ากว่า
1) Wildcard นำหน้า
เมื่อเขียน:
WHERE name LIKE '%term'
ฐานข้อมูลไม่สามารถใช้ B-tree ปกติเพื่อกระโดดไปยังจุดเริ่มต้นได้ เพราะมันไม่รู้ว่า “%term” จะเริ่มที่ไหนในลำดับ มักต้องสแกนแถวจำนวนมาก
ทางเลือก:
WHERE name LIKE 'term%'2) ใช้ฟังก์ชันบนคอลัมน์ที่มีดัชนี
ตัวอย่างดูเหมือนไม่เป็นอันตราย:
WHERE LOWER(email) = '[email protected]'
แต่ LOWER(email) เปลี่ยนนิพจน์ ดังนั้นดัชนีบน email จะถูกใช้โดยตรงไม่ได้
ทางเลือก:
WHERE email = ...LOWER(email) (ขึ้นกับฐานข้อมูล)การแปลงชนิดข้อมูลโดยอ้อม: การเปรียบเทียบชนิดข้อมูลต่างกันอาจทำให้ฐานข้อมูลต้องแคสต์ด้านหนึ่ง ซึ่งอาจปิดกั้นดัชนี ตัวอย่าง: เปรียบเทียบคอลัมน์ integer กับลิตเทอรัลสตริง
การตั้งค่าการเรียงลำดับ/encoding ที่ไม่ตรงกัน: ถ้าการเปรียบเทียบใช้ collation ต่างจากที่สร้างดัชนีไว้ (พบได้บ่อยกับคอลัมน์ข้อความข้าม locale) optimizer อาจหลีกเลี่ยงดัชนี
LIKE '%x')?LOWER(col), DATE(col), CAST(col)) ?EXPLAIN เพื่อยืนยันว่าฐานข้อมูลเลือกอะไรจริง ๆ หรือไม่?ดัชนีไม่ใช่ "ตั้งแล้วลืม" เมื่อเวลาผ่านไป ข้อมูลเปลี่ยน รูปแบบคำค้นเปลี่ยน และรูปร่างทางกายภาพของตารางและดัชนีจะเปลี่ยน ดัชนีที่เลือกมาได้ดีอาจค่อย ๆ สูญเสียประสิทธิภาพหรือกลับเป็นภาระถ้าไม่ดูแล
ฐานข้อมูลส่วนใหญ่พึ่งพาตัววางแผน (optimizer) เพื่อเลือกวิธีรันคำค้น: จะใช้ดัชนีไหน จะเลือกลำดับการ JOIN อย่างไร และดัชนี lookup คุ้มค่าหรือไม่ เพื่อการตัดสินใจนี้ ตัววางแผนใช้ สถิติ — สรุปการกระจายค่า จำนวนแถว และความเอนเอียงของข้อมูล
เมื่อ สถิติล้าสมัย การประมาณจำนวนแถวของตัววางแผนอาจผิดพลาดมาก ส่งผลให้เลือกแผนที่ไม่ดี เช่น เลือกดัชนีที่คืนแถวมากกว่าที่คาด หรือไม่ใช้ดัชนีที่ควรจะเร็ว
การแก้ปัญหาทั่วไป: กำหนดตารางเวลาการอัปเดตสถิติเป็นประจำ (มักเรียกว่า “ANALYZE” หรือชื่อคล้ายกัน) หลังการโหลดข้อมูลขนาดใหญ่ ลบข้อมูลจำนวนมาก หรืองาน churn มาก ควรรีเฟรชสถิติโดยเร็วกว่าวันปกติ
เมื่อมีการแทรก อัปเดต และลบ ดัชนีอาจสะสม bloat (เพจว่างที่ไม่ใช้) และ fragmentation (ข้อมูลกระจายที่เพิ่ม I/O) ผลคือดัชนีใหญ่ขึ้น การอ่านมากขึ้น และการสแกนช้าลง โดยเฉพาะสำหรับคำค้นช่วง
การแก้ปัญหาทั่วไป: บ่อยครั้งต้อง rebuild หรือ reorganize ดัชนีที่ถูกใช้งานหนักเมื่อมันเติบโตไม่สมส่วนหรือประสิทธิภาพไหลลง เครื่องมือและผลกระทบต่างกันตามฐานข้อมูล จึงควรทำด้วยการวัด ไม่ใช่เป็นกฎทั่วถึง
ตั้งการมอนิเตอร์สำหรับ:
วงป้อนกลับนี้ช่วยให้คุณจับได้เมื่อจำเป็นต้องบำรุงรักษา หรือเมื่อดัชนีควรถูกปรับหรือเอาออก สำหรับการยืนยันการปรับปรุง ให้ดูข้อความในเอกสารที่อ้างถึงการพิสูจน์ผลลัพธ์ เช่น /blog/how-to-prove-an-index-helps-explain-and-measurements
การเพิ่มดัชนีควรเป็นการเปลี่ยนที่มีเหตุผล ไม่ใช่การเดา เวิร์กโฟลว์เบา ๆ ช่วยให้คุณมุ่งไปที่ผลลัพธ์ที่วัดได้และป้องกัน "index sprawl"
เริ่มจากหลักฐาน: บันทึกคำค้นช้า APM traces หรือรายงานผู้ใช้ เลือกคำค้นที่ช้าและเกิดบ่อย — รายงานหายาก 10 วินาทีสำคัญน้อยกว่าการค้น 200 ms ที่เกิดบ่อย
จับ SQL ที่แน่นอนและรูปแบบพารามิเตอร์ (เช่น: WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50) รายละเอียดเล็กน้อยเปลี่ยนได้ว่าดัชนีไหนช่วยได้
บันทึกความหน่วงปัจจุบัน (p50/p95), แถวที่สแกน และผลกระทบต่อ CPU/IO เก็บผลแผนปัจจุบัน (EXPLAIN / EXPLAIN ANALYZE) เพื่อเปรียบเทียบ
เลือกคอลัมน์ที่ตรงกับการกรองและการเรียงของคำค้น เลือกดัชนีที่เล็กที่สุดที่ทำให้แผนหยุดสแกนช่วงกว้าง
ทดสอบในสเตจด้วยปริมาณข้อมูลใกล้เคียงโปรดักชัน ดัชนีอาจดูดีบนชุดข้อมูลเล็กแต่ผิดหวังเมื่อขยาย
บนตารางใหญ่ ใช้ตัวเลือกออนไลน์ถ้ามี (เช่น PostgreSQL CREATE INDEX CONCURRENTLY) กำหนดเวลาเปลี่ยนแปลงช่วงโหลดต่ำถ้าฐานข้อมูลอาจล็อกการเขียน
รันคำค้นเดิมและเปรียบเทียบ:
ถ้าดัชนีเพิ่มค่าใช้จ่ายการเขียนหรือบีบหน่วยความจำ ให้ลบมันออกอย่างสะอาด (เช่น DROP INDEX CONCURRENTLY) เก็บ migration ให้ย้อนกลับได้
ใน migration หรือโน้ตสคีมา เขียนว่าดัชนีนี้รองรับคำค้นไหนและเมตริกอะไรดีขึ้น เวลาต่อมาเพื่อนร่วมงานจะรู้ว่าทำไมมันอยู่และเมื่อไหร่จะลบได้
ถ้าคุณสร้างบริการใหม่และอยากหลีกเลี่ยง "index sprawl" ตั้งแต่ต้น Koder.ai ช่วยให้คุณวนลูปทั้งวงได้เร็ว: สร้างแอป React + Go + PostgreSQL จากการคุย ปรับสคีมาและ migration ตามความต้องการ แล้วส่งออกซอร์สโค้ดเมื่อพร้อมรับช่วงต่อ ในทางปฏิบัติช่วยให้ข้ามจาก “endpoint นี้ช้า” เป็น “นี่คือ EXPLAIN plan ดัชนีเล็กที่สุด และ migration ที่ย้อนกลับได้” โดยไม่ต้องรอพัฒนาพร้อมกันทั้งระบบ
ดัชนีเป็นแรงขับใหญ่ แต่ไม่ใช่ปุ่มวิเศษ บางครั้งส่วนที่ช้าของคำขอเกิดขึ้นหลังจากฐานข้อมูลหาตำแหน่งแถวแล้ว หรือรูปแบบคำค้นทำให้การทำดัชนีไม่ใช่คำตอบแรก
ถ้าคำค้นใช้ดัชนีดีแล้วแต่ยังช้า ให้มองหาสาเหตุทั่วไปเหล่านี้:
OFFSET 999000 อาจช้าแม้มีดัชนี ให้ใช้ keyset pagination แทนSELECT * หรือคืนหมื่นแถวขึ้นไป จะคอขวดที่เครือข่าย การแปลงเป็น JSON หรือการประมวลผลฝั่งแอปหากต้องการวิเคราะห์ปัญหาเชิงลึกให้จับคู่แนวทางนี้กับเวิร์กโฟลว์ใน /blog/how-to-prove-an-index-helps
อย่าคาดเดา วัดเวลาที่ใช้จริง (การรันฐานข้อมูล vs จำนวนแถวที่คืน vs โค้ดแอป) ถ้าฐานข้อมูลเร็วแต่ API ช้า การทำดัชนีเพิ่มจะไม่ช่วย
โครงสร้างดัชนีฐานข้อมูลเป็นโครงสร้างข้อมูลแยกต่างหาก (บ่อยครั้งเป็น B-tree) ที่เก็บค่าของคอลัมน์บางตัวในรูปแบบที่ค้นหาได้และเรียงลำดับ พร้อมตัวชี้กลับไปยังแถวในตาราง ฐานข้อมูลใช้ดัชนีนี้เพื่อ หลีกเลี่ยงการอ่านตารางทั้งหมดในกรณีของคำค้นที่เฉพาะเจาะจง
มันไม่ใช่สำเนาตารางทั้งฉบับ แต่จะทำการสำเนาเฉพาะข้อมูลของคอลัมน์บางตัวและเมตาดาทาบางอย่าง ซึ่งเป็นสาเหตุที่ดัชนีใช้พื้นที่เก็บข้อมูลเพิ่มขึ้น
ถ้าไม่มีดัชนี ฐานข้อมูลอาจต้องทำการสแกนตารางทั้งหมด: อ่านหลายแถว (หรือทั้งหมด) แล้วตรวจสอบทีละแถวว่าตรงตามเงื่อนไข WHERE หรือไม่
เมื่อมีดัชนี ฐานข้อมูลมักจะกระโดดไปหาตำแหน่งของแถวที่ตรงกันได้เลย แล้วอ่านเฉพาะแถวเหล่านั้น ส่งผลให้ลดการอ่านจากดิสก์ งาน CPU ในการกรองข้อมูล และแรงกดดันต่อแคชหน่วยความจำ
ดัชนีแบบ B-tree เก็บค่าต่าง ๆ ในลำดับเรียง และจัดเป็นเพจที่ชี้ไปยังเพจอื่น ๆ ทำให้ฐานข้อมูลสามารถนำทางไปยัง “ย่าน” ของค่าที่ต้องการได้อย่างรวดเร็ว
ด้วยเหตุนี้ B-tree จึงเหมาะทั้งกับ:
WHERE email = ...)WHERE created_at >= ... AND created_at < ...)ดัชนีแบบแฮช (hash) เร็วมากสำหรับการค้นหาที่ตรงเป๊ะ (=) เพราะจะแปลงค่าเป็นแฮชแล้วชี้ไปยังบั๊กเก็ตโดยตรง
ข้อแลกเปลี่ยน:
ในการใช้งานจริง B-tree มักเป็นค่าพื้นฐานเพราะรองรับรูปแบบคำค้นได้หลากหลายกว่า
ดัชนีช่วยได้ดีกับรูปแบบการเข้าถึงข้อมูลต่อไปนี้:
WHERE ที่คัดกรองได้ดี (ผลลัพธ์มีไม่กี่แถว)JOIN (เช่น foreign key กับ primary key)ORDER BY ที่ตรงกับลำดับในดัชนี (ช่วยหลีกเลี่ยงการ sort)GROUP BY เมื่อข้อมูลถูกอ่านเป็นกลุ่มตามลำดับความคัดสรร (selectivity) คือ “จำนวนแถวที่ตรงกับค่าหนึ่ง ๆ” ดัชนีให้ผลดีเมื่อเงื่อนไขช่วยกรองตารางขนาดใหญ่ให้เหลือชุดเล็ก ๆ
email, user_id, order_number (มักจะเป็นเอกลักษณ์หรือใกล้เคียง)เพราะตัวประมาณต้นทุนของตัววางแผน (optimizer) คาดว่าการใช้ดัชนีจะไม่ลดงานได้มากพอ
เหตุผลที่พบบ่อย:
ใน B-tree ส่วนใหญ่ ดัชนีถูกเรียงโดยคอลัมน์แรกก่อน แล้วภายในค่านั้นเรียงตามคอลัมน์ที่สอง เป็นต้น ดังนั้นฐานข้อมูลจะใช้ดัชนีได้อย่างมีประสิทธิภาพเมื่อเงื่อนไขเริ่มจากคอลัมน์ซ้ายสุด
ตัวอย่าง:
(account_id, created_at) ดีสำหรับ WHERE account_id = ? แล้วกรอง/เรียงด้วย created_atcreated_at เพราะมันไม่ใช่คอลัมน์ซ้ายสุดดัชนีที่ครอบคลุม (covering index) รวมคอลัมน์ทั้งหมดที่คำค้นต้องการ ทำให้ฐานข้อมูลสามารถคืนผลจากดัชนีได้เลยโดยไม่ต้องอ่านแถวจากตาราง
ข้อดี:
ค่าใช้จ่าย:
ใช้ดัชนีครอบคลุมสำหรับคำค้นที่มีมูลค่าสูงเจาะจง ไม่ใช่เผื่อไว้เฉพาะ
ดูสองอย่าง:
EXPLAIN / EXPLAIN ANALYZE เพื่อยืนยันว่าแผนเปลี่ยนไป (เช่น Seq Scan → Index Scan/Seek, จำนวนแถวที่อ่านน้อยลง, ขั้นตอนการ sort หายไป)อย่าลืมตรวจดูผลกระทบต่อการเขียน (INSERT/UPDATE/DELETE) เพราะดัชนีใหม่อาจทำให้การเขียนช้าลง
ถ้าคำค้นคืนค่าส่วนใหญ่ของตาราง ผลได้จากดัชนีมักจะน้อย
is_activeis_deletedstatusดัชนีบนคอลัมน์ boolean หรือคอลัมน์ที่มีความคัดสรรต่ำมักจะให้ผลไม่ดี เพราะมักจะตรงกับส่วนใหญ่ของตาราง และใช้ดัชนีอาจช้ากว่าสแกนแบบลำดับ