15 ก.ย. 2568·3 นาที
ทำไมฐานโค้ดที่สร้างโดย AI จึงอาจง่ายต่อการเขียนใหม่
โค้ดที่สร้างด้วย AI มักตามรูปแบบซ้ำได้ ทำให้การเขียนทับหรือทดแทนง่ายกว่าระบบที่คนออกแบบเฉพาะตัว นี่คือเหตุผลและวิธีใช้อย่างปลอดภัย
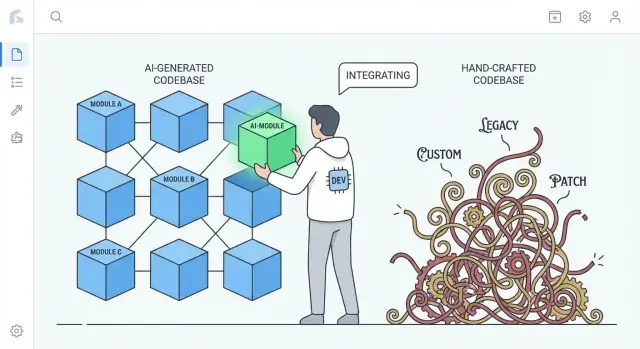
ความหมายของ “ง่ายต่อการทดแทน” ในโปรเจ็กต์จริง
“ง่ายต่อการทดแทน” แทบจะไม่หมายความว่าให้ลบแอปทั้งหมดแล้วเริ่มใหม่ ในทีมจริง การทดแทนเกิดขึ้นในระดับต่างๆ และคำว่า “เขียนใหม่” ขึ้นอยู่กับสิ่งที่คุณกำลังสลับออก
การทดแทน vs การเขียนใหม่: สิ่งที่สามารถทำได้จริง
การทดแทนอาจเป็น:
- โมดูล (กฎการเรียกเก็บเงิน, การสร้าง PDF, เทมเพลตอีเมล)
- บริการ (API แนะนำ, worker พื้นหลัง)
- พื้นผิวหน้าหน้าเว็บ (หน้า หน่วยฟีเจอร์ หรือ UI ทั้งหมด)
- การเขียนแอปทั้งแอปใหม่ (หายาก แพง และบางครั้งจำเป็น)
เมื่อคนพูดว่าฐานโค้ด "ง่ายต่อการเขียนใหม่" พวกเขามักหมายความว่าคุณสามารถ เริ่มใหม่เฉพาะชิ้นโดยไม่ต้องคลี่ทุกอย่างออก ให้ธุรกิจยังทำงานได้ และย้ายอย่างค่อยเป็นค่อยไป
การเปรียบเทียบจริง: โค้ดที่สร้างด้วย AI vs โค้ดที่ปรับแต่งมาก
ข้อโต้แย้งนี้ไม่ใช่ว่า “โค้ด AI ดีกว่า” แต่มันเกี่ยวกับแนวโน้มทั่วไป
- โค้ดที่ปรับแต่งด้วยคนอย่างหนัก อาจสะสมรูปแบบเฉพาะต่างๆ, นามธรรมที่ฉลาด, หรือ "เฟรมเวิร์กย่อย" ภายในแอป นั่นอาจเป็นวิศวกรรมที่ดี แต่ก็อาจสร้างระบบส่วนตัวที่มีคนเข้าใจได้ไม่กี่คน
- โค้ดที่สร้างด้วย AI มักเอนเอียงไปทางค่าเริ่มต้นที่คุ้นเคย: ไลบรารีกระแสหลัก, การจัดชั้นตามธรรมเนียม, และรูปแบบที่คล้ายกับตัวอย่างอ้างอิงทั่วไป
ความแตกต่างนี้สำคัญตอนเขียนทับ: โค้ดที่ติดตามคอนเวนชันที่เข้าใจกันโดยกว้างมักถูกแทนที่ด้วยการใช้งานแบบคอนเวนชันได้ง่ายขึ้นโดยไม่ต้องเจรจาหรือประหลาดใจมาก
ตั้งความคาดหวัง: โค้ด AI อาจรกได้
โค้ดที่สร้างด้วย AI อาจไม่สอดคล้อง ซ้ำซ้อน หรือขาดการทดสอบ "ง่ายต่อการทดแทน" ไม่ได้หมายความว่ามันสะอาด—แต่หมายความว่ามันมักจะ ไม่ “พิเศษ” มากนัก หากซับซิสเต็มถูกสร้างจากส่วนประกอบที่เป็นมาตรฐาน การสลับมันออกมักเหมือนการเปลี่ยนชิ้นส่วนมาตรฐานมากกว่าการย้อนรอยเครื่องจักรที่กำหนดเอง
ภาพรวม: ทำไมการมาตรฐานช่วยลดต้นทุนการสลับ
ไอเดียหลักเรียบง่าย: การมาตรฐานลดต้นทุนการสลับ เมื่อโค้ดประกอบด้วยรูปแบบที่คุ้นเคยและรอยต่อที่ชัดเจน คุณสามารถสร้างใหม่ รีแฟกเตอร์ หรือเขียนทับชิ้นส่วนได้โดยไม่ต้องกลัวว่าจะทำลายการพึ่งพาที่ซ่อนอยู่ ส่วนต่อไปนี้อธิบายว่ามันส่งผลอย่างไรในเรื่องโครงสร้าง ความเป็นเจ้าของ การทดสอบ และความเร็วในการพัฒนา
รูปแบบมาตรฐานช่วยลดต้นทุนการเริ่มต้นใหม่
ข้อดีเชิงปฏิบัติของโค้ดที่สร้างด้วย AI คือมันมักเริ่มจากรูปแบบที่คุ้นเคย: โครงโฟลเดอร์ที่คาดเดาได้, การตั้งชื่อน่าเข้าใจ, คอนเวนชันของเฟรมเวิร์กกระแสหลัก และวิธีปกติในการ routing, validation, การจัดการข้อผิดพลาด และการเข้าถึงข้อมูล แม้โค้ดจะไม่สมบูรณ์ แต่โดยทั่วไปมันอ่านได้เหมือนตัวอย่างสตาร์ทเตอร์หลายๆ แห่ง
ความคุ้นเคยชนะความเป็นต้นฉบับเมื่อคุณต้องเขียนทับ
การเขียนทับแพงเพราะคนต้องเข้าใจก่อน โค้ดที่ตามคอนเวนชันที่รู้จักกันช่วยลดเวลาการ "ถอดรหัส" วิศวกรใหม่สามารถจับคู่สิ่งที่เห็นกับโมเดลในหัวที่มีอยู่แล้ว: การตั้งค่าอยู่ที่ไหน, คำขอไหลอย่างไร, การเชื่อมต่อพึ่งพาถูกจัดวางอย่างไร, และการทดสอบควรอยู่ที่ใด
นี่ทำให้เร็วขึ้นในการ:
- หาจุดรอยต่อสำหรับการทดแทน (โมดูล, บริการ, endpoints)
- ทำพฤติกรรมซ้ำในการใช้งานใหม่
- เปรียบเทียบเก่าและใหม่ข้างกันโดยไม่ต้องแปลระหว่างสไตล์
ในทางกลับกัน ฐานโค้ดที่ปรับแต่งสูงมักสะท้อนสไตล์ส่วนบุคคล: นามธรรมเฉพาะตัว, มินิ-เฟรมเวิร์กที่ทำเอง, โค้ดกาวที่ฉลาด หรือรูปแบบโดเมนที่เข้าใจได้เฉพาะบริบทประวัติศาสตร์ ทางเลือกเหล่านั้นอาจสวยงาม—แต่เพิ่มต้นทุนการเริ่มต้นใหม่เพราะการเขียนทับต้องเรียนรู้โลกทัศน์ของผู้เขียนก่อน
คุณสามารถบังคับใช้คอนเวนชันได้ทั้งสองทาง
นี่ไม่ใช่เวทมนตร์ที่จำกัดเฉพาะ AI ทีมสามารถ (และควร) บังคับโครงสร้างและสไตล์โดยใช้เทมเพลต, linters, formatters, และ scaffolding tools ความแตกต่างคือ AI มักผลิต "ทั่วไปเป็นค่าเริ่มต้น" ขณะที่ระบบที่คนเขียนบางครั้งจะเบี่ยงออกไปสู่การปรับแต่งถ้าไม่บังคับคอนเวนชันอย่างแข็งขัน
โค้ดที่ไม่ค่อยมี 'กาว' แบบเฉพาะ อาจหมายถึงการพึ่งพาน้อยลง
ปัญหาการเขียนทับส่วนใหญ่ไม่ได้มาจาก business logic หลัก แต่มาจากกาวที่ปรับแต่งเอง—helpers เฉพาะ, มินิ-เฟรมเวิร์กที่ทำเอง, เมทาโปรแกรมมิง, และคอนเวนชันแบบครั้งเดียวที่เชื่อมทุกอย่างเข้าด้วยกัน
อะไรคือ 'กาวแบบเฉพาะ'
กาวแบบเฉพาะคือสิ่งที่ไม่ใช่ส่วนของผลิตภัณฑ์ แต่ผลิตภัณฑ์ไม่สามารถทำงานได้หากไม่มีมัน ตัวอย่าง: container DI ที่ทำเอง, ชั้น routing ที่ทำเอง, base class วิเศษที่ auto-register models, หรือ helpers ที่เปลี่ยนสถานะแบบ global "เพื่อความสะดวก" มันมักเริ่มจากการประหยัดเวลาและกลายเป็นความรู้ที่จำเป็นสำหรับทุกการเปลี่ยนแปลง
ทำไมกาวเฉพาะเพิ่มการผูกและความเสี่ยงตอนเขียนทับ
ปัญหาไม่ใช่การมีอยู่ของกาว แต่คือมันกลายเป็นการผูกที่มองไม่เห็น เมื่อกาวเป็นเอกลักษณ์ของทีม มันมักจะ:
- สร้างการพึ่งพาโดยปริยาย (สิ่งต่างๆ ทำงานเพราะ helpers ทำงานตามลำดับที่เจาะจง)
- กระจายสมมติฐานข้ามไฟล์ (คอนเวนชันการตั้งชื่อกลายเป็นพฤติกรรม)
- ทำให้รีแฟกเตอร์ "ง่ายๆ" เสี่ยง (เปลี่ยนกาวแล้วพังทั้งระบบ)
ระหว่างการเขียนทับ กาวประเภทนี้ยากที่จะทำซ้ำอย่างถูกต้องเพราะกฎมักไม่ถูกเขียนลง กลายเป็นค้นพบโดยการทำให้โปรดักชันล้มเหลว
ทำไมโค้ดที่สร้างด้วย AI มักหลีกเลี่ยงความฉลาดจัด
ผลลัพธ์จาก AI มักโน้มไปหาการใช้ไลบรารีมาตรฐาน รูปแบบที่คุ้นเคย และการเชื่อมต่อแบบชัดเจน มันอาจไม่ประดิษฐ์มินิ-เฟรมเวิร์กเมื่อโมดูลหรือ service ปกติทำงานได้ การยับยั้งนี้อาจเป็นข้อดี: hook วิเศษน้อยลงหมายถึงการพึ่งพาที่ซ่อนอยู่น้อยลง และทำให้การดึงออกและทดแทนซับซิสเต็มง่ายขึ้น
ข้อแลกเปลี่ยน: ความยืดยาวมากกว่าความฉลาด
ข้อเสียคือโค้ด "ธรรมดา" อาจยาวกว่า—มีพารามิเตอร์มากขึ้น การเดินสายที่ตรงไปตรงมาและ shortcut น้อยลง แต่ความยืดยาวมักถูกกว่าความลึกลับ เมื่อคุณตัดสินใจเขียนทับ คุณต้องการโค้ดที่อ่านง่าย ลบง่าย และตีความยาก
โครงสร้างที่คาดเดาได้สนับสนุนการเขียนทับแบบค่อยเป็นค่อยไป
"โครงสร้างที่คาดเดาได้" ไม่เกี่ยวกับความสวยงามเท่าไหร่ แต่เกี่ยวกับความสม่ำเสมอ: โฟลเดอร์เดียวกัน กฎการตั้งชื่อเดียวกัน และการไหลของคำขอที่ซ้ำกันในทุกที่ โครงการที่สร้างด้วย AI มักชอบค่าเริ่มต้นที่คุ้นเคย—controllers/, services/, repositories/, models/—พร้อม endpoints CRUD ที่ซ้ำกันและ pattern การตรวจสอบที่คล้ายกัน
ความสม่ำเสมอนั้นสำคัญเพราะเปลี่ยนการเขียนทับจากหน้าผาให้เป็นบันได
รูปแบบที่คาดเดาได้หน้าตาเป็นอย่างไร
คุณจะเห็นรูปแบบซ้ำผ่านฟีเจอร์ต่างๆ:
- ขอบเขตโฟลเดอร์ชัดเจน (API → service → data access)
- การตั้งชื่อสอดคล้อง (
UserService,UserRepository,UserController) - ลำดับ CRUD ที่คล้ายกัน (list → get → create → update → delete)
- รูปแบบมาตรฐานสำหรับข้อผิดพลาด การล็อก และวัตถุ request/response
เมื่อทุกฟีเจอร์สร้างแบบเดียวกัน คุณสามารถเขียนทับชิ้นเดียวได้โดยไม่ต้องเรียนรู้ระบบใหม่ทุกครั้ง
สลับทีละชิ้น
การเขียนทับแบบค่อยเป็นค่อยไปทำงานได้ดีที่สุดเมื่อคุณแยกรอยต่อได้ แต่ละชั้นมีงานจำกัดและการเรียกส่วนใหญ่ผ่านชุดอินเทอร์เฟซเล็กๆ
วิธีปฏิบัติที่เป็นประโยชน์คือสไตล์ "strangler": รักษา API สาธารณะให้คงที่ และเปลี่ยนอินเทอร์นอลทีละน้อย
ตัวอย่าง: เปลี่ยนชั้นการเข้าถึงข้อมูลโดยไม่แตะ API
สมมติแอปมี controller เรียก service และ service เรียก repository:
OrdersController→OrdersService→OrdersRepository
คุณต้องการย้ายจาก SQL ตรงๆ ไปยัง ORM หรือจากฐานข้อมูลหนึ่งไปยังอีกอัน ในโค้ดที่คาดเดาได้ การเปลี่ยนแปลงสามารถจัดการได้:
- สร้าง
OrdersRepositoryV2(การใช้งานใหม่) - เก็บ signature เดิมไว้ (
getOrder(id),listOrders(filters)) - สลับการเชื่อมต่อในที่เดียว (dependency injection หรือ factory)
- รันเทสต์และเปิดใช้ทีละฟีเจอร์
โค้ด controller และ service จะยังคงไม่เปลี่ยนแปลงมากนัก
เปรียบเทียบ: สถาปัตยกรรมที่ปรับแต่งด้วยมือ
ระบบที่ปรับแต่งสูงมักเยี่ยมยอด—แต่บ่อยครั้งฝังแนวคิดเฉพาะ: นามธรรมที่กำหนดเอง, เมทาโปรแกรมมิงเจ๋งๆ, หรือพฤติกรรมข้ามส่วนที่ซ่อนอยู่ใน base class นั่นทำให้การเปลี่ยนแต่ละครั้งต้องมีบริบทเชิงประวัติศาสตร์มากมาย ด้วยโครงสร้างที่คาดเดาได้ คำถามว่า "เปลี่ยนตรงไหน?" มักง่ายขึ้น ซึ่งทำให้การเขียนทับเล็กๆ ทำได้สัปดาห์ต่อสัปดาห์
การผูกผู้ออกแบบน้อยลงทำให้การลบเป็นที่ยอมรับมากขึ้น
ตัวบล็อกเงียบๆ ในการเขียนทับหลายครั้งไม่ใช่เทคนิค แต่เป็นสังคม ทีมมักมี ความเสี่ยงจากความเป็นเจ้าของ ที่มีคนคนเดียวเข้าใจระบบจริงๆ เมื่อคนนั้นเขียนโค้ดจำนวนมากด้วยมือ โค้ดจะเริ่มรู้สึกเหมือนวัตถุส่วนตัว: "การออกแบบของฉัน" "วิธีฉลาดของฉัน" การยึดติดนี้ทำให้การลบมีต้นทุนทางอารมณ์ แม้จะสมเหตุสมผลทางเศรษฐกิจก็ตาม
โค้ดที่สร้างด้วย AI สามารถลดผลกระทบนี้ได้ เพราะร่างเริ่มต้นอาจมาจากเครื่องมือ (และมักตามรูปแบบที่คุ้นเคย) โค้ดจึงรู้สึกน้อยกว่าเป็นลายเซ็นและมากกว่าเป็นการใช้งานที่สลับออกได้ ผู้คนมักสบายใจกับการพูดว่า "มาลบโมดูลนี้เถอะ" เมื่อมันไม่รู้สึกเหมือนลบผลงานฝีมือของใครคนใดคนหนึ่ง
ทำไมสิ่งนี้เปลี่ยนพฤติกรรมการเขียนทับ
เมื่อการผูกผู้เขียนลดลง ทีมมักจะ:
- ตั้งคำถามกับโค้ดปัจจุบันได้อย่างเสรีขึ้น
- ลบส่วนใหญ่โดยไม่ต้องเจรจาเรื่องความภาคภูมิใจหรือการเมือง
- เลือกสร้างซ้ำหรือทดแทนเร็วกว่าการแพตช์แบบระมัดระวังเป็นเดือนๆ
- กระจายความรู้เร็วขึ้น เพราะไม่มีใครถือว่าส่วนภายในเป็น "เขตของใคร"
ข้อสังเกตเชิงปฏิบัติ
การตัดสินใจเขียนทับยังต้องขับเคลื่อนด้วยต้นทุนและผลลัพธ์: ไทม์ไลน์การส่งมอบ ความเสี่ยง การดูแลรักษา และผลกระทบต่อผู้ใช้ "ลบง่าย" เป็นคุณสมบัติที่ช่วยได้ แต่อย่าใช้มันเป็นกลยุทธ์โดยลำพัง
Prompt และร่องรอยการสร้างเป็นเอกสารได้
แชร์ชิ้นงานใหม่
เผยชิ้นงานทดลองของคุณบนโดเมนที่กำหนดเองเพื่อเก็บข้อเสนอแนะตั้งแต่เนิ่นๆ
ประโยชน์ที่ถูกมองข้ามของโค้ดที่สร้างด้วย AI คือ อินพุต ของการสร้างสามารถทำหน้าที่เป็นสเปกที่มีชีวิตได้ Prompt, เทมเพลต, และการตั้งค่าตัวสร้างสามารถอธิบายเจตนาเป็นภาษาธรรมดา: ฟีเจอร์ควรทำอะไร ข้อจำกัดใดสำคัญ (ความปลอดภัย ประสิทธิภาพ สไตล์) และอะไรคือคำจำกัดความของ "เสร็จ"
Prompt เป็นสเปกที่มีชีวิต
เมื่อทีมใช้ prompt ที่ทำซ้ำได้ (หรือไลบรารี prompt) และเทมเพลตที่เสถียร พวกเขาจะสร้างร่องรอยการตัดสินใจที่เดิมจะฝังอยู่ในความทรงจำหรือ commit message
prompt ที่ดีอาจระบุสิ่งที่ผู้ดูแลในอนาคตมักต้องเดา:
- flow ของผู้ใช้ที่คาดหวังและกรณีขอบเขต
- คอนเวนชันการตั้งชื่อและโครงโฟลเดอร์
- วิธีการจัดการข้อผิดพลาดและการล็อก
- สิ่งที่ต้องทดสอบ (และสิ่งที่สามารถม็อกได้)
นั่นแตกต่างจากฐานโค้ดที่คนเขียนหลายแห่ง ซึ่งการตัดสินใจสำคัญกระจัดกระจายอยู่ใน commit messages ความรู้ปากเปล่า และคอนเวนชันที่ไม่เขียน
ร่องรอยการสร้างช่วยให้คุณทำซ้ำพฤติกรรมได้
ถ้าคุณเก็บร่องรอยการสร้าง (prompt + model/version + inputs + ขั้นตอน post-processing) การเขียนทับจะไม่เริ่มจากหน้ากระดาษว่าง คุณสามารถใช้รายการตรวจสอบเดียวกันเพื่อสร้างพฤติกรรมเดิมภายใต้โครงสร้างที่สะอาดกว่า แล้วเปรียบเทียบผล
ในการปฏิบัติ สิ่งนี้ทำให้การเขียนทับเปลี่ยนเป็น: “สร้างฟีเจอร์ X ใหม่ภายใต้มาตรฐานใหม่ แล้วยืนยันความเท่าเทียม” แทนที่จะเป็น “ย้อนรอยว่าฟีเจอร์ X ควรทำอะไร”
คำเตือนสำคัญ: จัดการ prompt เหมือนโค้ด
สิ่งนี้จะทำงานก็ต่อเมื่อ prompt และ config ถูกจัดการด้วยวินัยเดียวกับซอร์สโค้ด:
- version พวกมันในรีโป (ไม่ใช่โน้ตของใครคนใดคนหนึ่ง)
- ต้องมีการทบทวนเมื่อเปลี่ยนแปลง
- บันทึกว่า prompt/config ใดสร้างโมดูลใด
หากไม่ทำเช่นนั้น prompt จะกลายเป็น dependency อีกชิ้นที่ไม่มีเอกสาร แต่ถ้าทำ มันจะเป็นเอกสารที่หลายระบบที่คนสร้างมักอยากมี
การทดสอบที่แข็งแรงเปลี่ยนการเขียนทับเป็นวิศวกรรมปกติ
"ง่ายต่อการทดแทน" ไม่ได้ขึ้นกับว่าโค้ดเขียนโดยคนหรือเครื่อง แต่มันขึ้นกับว่าคุณสามารถเปลี่ยนได้อย่างมั่นใจ การเขียนทับกลายเป็นวิศวกรรมปกติเมื่อการทดสอบบอกคุณอย่างรวดเร็วและเชื่อถือได้ว่าพฤติกรรมยังคงเดิม
โค้ดที่สร้างด้วย AI ช่วยเรื่องนี้ได้—เมื่อคุณขอ หลายทีมสั่งให้สร้างเทสต์โครงร่างพร้อมฟีเจอร์ (unit tests พื้นฐาน, integration tests เส้นทางมีความสุข, ม็อกง่ายๆ) เทสต์เหล่านั้นอาจไม่สมบูรณ์แต่สร้างตาข่ายนิรภัยเริ่มต้นที่มักขาดในระบบที่คนเขียนโดยเลื่อนการทดสอบไว้ภายหลัง
ให้ความสำคัญกับ contract tests ที่รอยต่อ
ถ้าต้องการให้ทดแทนได้ ให้โฟกัสการทดสอบไปที่รอยต่อที่ชิ้นส่วนพบกัน:
- API ภายนอก: requests, responses, error codes, retries, pagination
- อแดปเตอร์: ผู้ให้บริการชำระเงิน, อีเมล, ที่เก็บไฟล์, คิว
- โมเดลข้อมูล: migrations, serialization, กฎการตรวจสอบ
การทดสอบสัญญาช่วยล็อกสิ่งที่ต้องคงไว้แม้ว่าจะสลับอินเทอร์นอล
ใช้ coverage เป็นเข็มทิศ ไม่ใช่รางวัล
ตัวเลข coverage ช่วยชี้ว่าเสี่ยงที่ไหน แต่การไล่ตาม 100% มักให้เทสต์เปราะบางที่ขัดขวางรีแฟกเตอร์ แทนที่จะทำเช่นนั้น:
- เพิ่มเทสต์ที่ความผิดพลาดจะมีต้นทุนสูง (เงิน ข้อมูล ความน่าเชื่อถือผู้ใช้)
- เลือกเทสต์ที่ให้สัญญาณสูงกว่านับมากกว่าสารพัดเทสต์ตื้นๆ
- เมื่อเขียนทับ ให้เปรียบเทียบการใช้งานเก่าและใหม่ด้วย contract tests เดียวกัน
เมื่อมีเทสต์ที่แข็งแรง การเขียนทับจะหยุดเป็นโครงการฮีโร่และกลายเป็นชุดก้าวที่ปลอดภัยและย้อนกลับได้
ข้อบกพร่องทั่วไปของโค้ด AI มองเห็นและแยกได้ง่าย
ขยายการเขียนทับไปยังมือถือ
สร้างแอป Flutter จากแชทและรักษามาตรฐานเดียวกันทั้งเว็บและมือถือ
โค้ดที่สร้างด้วย AI มักล้มเหลวในวิธีที่คาดเดาได้ คุณมักเห็นการซ้ำซ้อนของตรรกะ, สาขาที่ "เกือบเหมือนกัน" จัดการกรณีขอบเขตต่างกัน, หรือฟังก์ชันที่โตขึ้นโดยการเติมแก้ไข โม้ทั้งหมดนี้ไม่สมบูรณ์แบบ—แต่มันมีข้อดี: ปัญหาโดยมากมองเห็นได้
ข้อบกพร่องที่เห็นชัดชนะบั๊กฉลาดๆ ที่ซับซ้อน
ระบบที่คนออกแบบอาจซ่อนความซับซ้อนไว้หลังนามธรรมฉลาด, การปรับให้เหมาะสมจิ๋ว, หรือพฤติกรรมที่ผูกแน่น เหล่านั้นเจ็บปวดเพราะดูถูกต้องและผ่านการตรวจสอบผิวเผินได้
โค้ดจาก AI มีแนวโน้มไม่สอดคล้องอย่างตรงไปตรงมา: พารามิเตอร์ถูกละเลยในเส้นทางหนึ่ง, การตรวจสอบมีในไฟล์หนึ่งแต่ไม่อีกไฟล์, หรือสไตล์การจัดการข้อผิดพลาดเปลี่ยนทุกไม่กี่ฟังก์ชัน ข้อผิดพลาดเหล่านี้เด่นเมื่อรีวิวและสแตติกแอนาลิซิส ทำให้แยกได้ง่ายเพราะมันไม่ขึ้นกับอนุรักษ์นิยมเชิงลึก
ผู้ที่เหมาะเป็นเป้าสำหรับการเขียนทับมักปรากฏผ่านการซ้ำ
การทำซ้ำคือสัญญาณ เมื่อคุณเห็นลำดับขั้นตอนเดียวกันซ้ำ—parse input → normalize → validate → map → return—ในหลาย endpoints หรือบริการ คุณพบรอยต่อที่เหมาะสมสำหรับการทดแทน AI มัก "แก้" คำขอใหม่โดยพิมพ์ซ้ำคำตอบก่อนพร้อมการปรับแต่ง ซึ่งสร้างกลุ่มของ near-duplicates
วิธีปฏิบัติ: ทำเครื่องหมายชิ้นที่ซ้ำใดๆ เป็นผู้สมัครให้สกัดหรือทดแทน โดยเฉพาะเมื่อ:
- ปรากฏใน 3+ ที่ด้วยความต่างเล็กน้อย
- ความต่างเป็นเรื่องการจัดการกรณีขอบเขตหรือข้อความข้อผิดพลาด
- โค้ดไม่มีเจ้าของชัดเจนและถูกแพตช์อยู่เรื่อยๆ
กฎธรรมดา: รวมการทำซ้ำให้เป็นโมดูลที่มีการทดสอบ
ถ้าคุณสามารถตั้งชื่อพฤติกรรมที่ซ้ำได้เป็นประโยค มันควรจะเป็นโมดูลเดียว เอาชิ้นที่ซ้ำออกแล้วแทนที่ด้วยคอมโพเนนต์ที่มีการทดสอบดี (utility, shared service, หรือ library function) เขียนเทสต์ที่ยึดกรณีขอบเขต แล้วลบสำเนา คุณเปลี่ยนหลายชิ้นที่เปราะให้เป็นจุดเดียวให้ปรับปรุง—และเป็นจุดเดียวที่จะเขียนทับในอนาคตหากจำเป็น
ความอ่านง่ายและความสอดคล้องมีค่าสูงกว่าการปรับแต่งเพื่อประสิทธิภาพ
โค้ดที่สร้างด้วย AI มักโดดเด่นเมื่อคุณขอให้มันเน้นความชัดเจนมากกว่าความฉลาด ด้วย prompt และกฎ linting ที่เหมาะสม มันมักเลือก flow การควบคุมที่คุ้นเคย การตั้งชื่อตามธรรมเนียม และโมดูล "น่าเบื่อ" มากกว่านวัตกรรม นั่นอาจเป็นชัยระยะยาวมากกว่าประสิทธิภาพไม่กี่เปอร์เซ็นต์จากการปรับแต่งด้วยมือ
ทำไมโค้ดที่อ่านง่ายเขียนทับได้ง่ายกว่า
การเขียนทับสำเร็จเมื่อคนใหม่สามารถสร้างแบบจำลองระบบได้อย่างรวดเร็ว โค้ดที่อ่านง่ายและสอดคล้องกันลดเวลาตอบคำถามพื้นฐานเช่น "คำขอนี้เข้าจากที่ไหน?" และ "ข้อมูลมีรูปแบบแบบไหนที่นี่?" หากทุกบริการทำตามรูปแบบเดียวกัน ทีมใหม่สามารถทดแทนทีละชิ้นโดยไม่ต้องเรียนรู้คอนเวนชันท้องถิ่นใหม่อยู่เรื่อยๆ
ความสอดคล้องยังลดความกลัว เมื่อโค้ดคาดเดาได้ วิศวกรสามารถลบและสร้างใหม่ด้วยความมั่นใจเพราะพื้นที่ผิวเข้าใจง่ายและความเสี่ยงดูเล็กลง
ข้อแลกเปลี่ยนกับทริกประสิทธิภาพที่ปรับแต่งโดยมือ
โค้ดที่ปรับแต่งสูงเพื่อประสิทธิภาพอาจยากที่จะเขียนทับเพราะเทคนิคการปรับแต่งมักเล็ดลอดไปทั่ว: caching ชั้นเฉพาะ, การปรับแต่ง concurrency แบบโฮมเมด, หรือการผูกแน่นกับโครงสร้างข้อมูลแบบพิเศษ ทางเลือกเหล่านี้อาจถูกต้องแต่สร้างข้อจำกัดแอบแฝงที่ไม่ชัดจนกว่าจะมีบางอย่างพัง
ข้อควรระวัง: ประสิทธิภาพยังสำคัญ—วัดมัน
ความอ่านง่ายไม่ใช่ข้ออ้างให้อืด ก่อนเขียนทับ เก็บเมตริกพื้นฐาน (latency percentiles, CPU, memory, cost) หลังจากแทนที่คอมโพเนนต์ ให้วัดอีกครั้ง หากประสิทธิภาพถดถอย ปรับปรุงเส้นทางร้อนที่จำเป็น—โดยไม่เปลี่ยนทั้งฐานโค้ดให้กลายเป็นปริศนา
สร้างใหม่ vs รีแฟกเตอร์ vs เขียนทับ: เลือกการรีเซ็ตที่ถูกต้อง
เมื่อฐานโค้ดที่ช่วยด้วย AI เริ่มรู้สึก "แปลก" คุณไม่จำเป็นต้องเขียนใหม่ทั้งระบบ ตัวรีเซ็ตที่ดีที่สุดขึ้นกับว่าชิ้นไหนของระบบ ผิด เทียบกับแค่ รก
ตัวเลือกรีเซ็ตสามแบบ
Regenerate คือการสร้างส่วนของโค้ดใหม่จากสเปกหรือ prompt—มักเริ่มจากเทมเพลตหรือ pattern ที่รู้จัก—แล้วต่อจุดเชื่อมต่อ (routes, contracts, tests) มันไม่ใช่การลบทั้งหมด แต่คือการสร้างชิ้นนี้ใหม่จากคำอธิบายที่ชัดเจน
Refactor คงพฤติกรรมไว้แต่เปลี่ยนโครงสร้างภายใน: เปลี่ยนชื่อ แยกโมดูล, ทำให้เงื่อนไขเรียบง่าย, ลบการทำซ้ำ, ปรับปรุงเทสต์
Rewrite แทนที่คอมโพเนนต์หรือระบบด้วยการใช้งานใหม่ โดยปกติเพราะการออกแบบปัจจุบันไม่สามารถทำให้ดีได้โดยไม่เปลี่ยนพฤติกรรม ขอบเขต หรือการไหลของข้อมูล
เมื่อ regenerate เหมาะ
Regeneration เหมาะเมื่อโค้ดเป็น boilerplate และคุณค่าจริงอยู่ที่ อินเทอร์เฟซ มากกว่าภายใน:
- หน้าจอ CRUD และแผงแอดมิน
- อแดปเตอร์ API และชั้นบางของการรวมระบบ
- scaffolding: routing, serializers, DTOs, validation พื้นฐาน, การจัดการข้อผิดพลาดทั่วไป
ถ้าสเปกชัดและขอบเขตสะอาด การสร้างซ้ำมักเร็วกว่าการแกะทีละนิด
เมื่อการสร้างซ้ำเสี่ยง (หรือล้มเหลว)
ระวังเมื่อโค้ดฝังความรู้โดเมนที่สั่งสมมาหรือเงื่อนไขความถูกต้องที่ละเอียดอ่อน:
- กฎธุรกิจที่หนักด้วยโดเมนและกรณีขอบเขตมาก
- ความยุ่งยากของ concurrency (คิว, locks, retries, idempotency)
- โลจิกที่เกี่ยวกับ compliance (audit trails, retention, privacy)
ในพื้นที่เหล่านี้ "ใกล้เคียง" อาจผิดพลาดได้แพง—การสร้างซ้ำอาจช่วยได้แต่ต้องพิสูจน์ความเท่าเทียมด้วยเทสต์และรีวิวที่แข็งแรง
ประตูการรีวิวและการเปิดใช้งานทีละน้อย
ปฏิบัติต่อโค้ดที่สร้างซ้ำเหมือน dependency ใหม่: ต้องมีการรีวิวจากมนุษย์, รัน test suite เต็มรูปแบบ, และเพิ่มเทสต์เฉพาะสำหรับความล้มเหลวที่เคยเจอ เปิดใช้งานทีละน้อย—หนึ่ง endpoint, หนึ่งหน้า, หนึ่งอแดปเตอร์—ด้วย feature flag หรือการปล่อยแบบค่อยเป็นค่อยไปถ้าเป็นไปได้
ค่าเริ่มต้นที่มีประโยชน์คือ: สร้างซ้ำโครงภายนอก, รีแฟกเตอร์รอยต่อ, เขียนทับเฉพาะส่วนที่สมมติฐานยังคงผิด
ความเสี่ยงและแนวป้องกันสำหรับโค้ดที่ออกแบบให้ "ทดแทนได้"
ล็อกพฤติกรรมของอินเทอร์เฟซ
กำหนดสัญญาที่ขอบเขตของคุณ แล้วสร้างซ้ำภายในโดยไม่ทำให้ลูกค้าเสียหาย
"ง่ายต่อการทดแทน" จะยังเป็นประโยชน์ถ้าทีมปฏิบัติต่อการทดแทนเป็นกิจกรรมที่มีการออกแบบ ไม่ใช่ปุ่มรีเซ็ตโดยสบายๆ โค้ดที่สร้างด้วย AI อาจถูกสลับเร็วกว่า—แต่ก็ล้มเหลวเร็วกว่าได้ถ้าคุณเชื่อใจมันเกินไป
ความเสี่ยงหลักที่ต้องระวัง
โค้ดที่สร้างด้วย AI มักดูสมบูรณ์แม้จะไม่ใช่ นั่นสร้าง ความมั่นใจผิดพลาด โดยเฉพาะเมื่อเดโมเส้นทางสมบูรณ์ผ่าน
ความเสี่ยงที่สองคือ กรณีขอบเขตขาดหาย: อินพุตแปลกๆ, timeouts, คอนดิชัน concurrency, และการจัดการข้อผิดพลาดที่ไม่ได้ครอบคลุมใน prompt หรือข้อมูลตัวอย่าง
สุดท้ายมี ความไม่แน่นอนเรื่องไลเซนส์/IP ถึงแม้ความเสี่ยงจะต่ำในหลายสถานการณ์ ทีมควรมีนโยบายว่าที่มาและเครื่องมือใดที่ยอมรับได้ และวิธีติดตามแหล่งที่มา
แนวป้องกันที่ทำให้การเขียนทับปลอดภัย
วางการทดแทนไว้หลังประตูเดียวกับการเปลี่ยนแปลงอื่นๆ:
- Code review โดยมีมุมมองเฉพาะสำหรับ "โค้ดที่สร้าง": ความชัดเจน, โหมดล้มเหลว, การตรวจสอบอินพุต, และการล็อก
- การตรวจสอบความปลอดภัย (SAST, สแกน dependency, ตรวจหาคีย์ลับ) และกฎว่าโค้ดที่สร้างไม่สามารถเลี่ยงได้
- นโยบาย dependency: เลือกไลบรารีที่รู้จักและน้อยที่สุด; ปักเวอร์ชัน; หลีกเลี่ยงการดึงเฟรมเวิร์กใหม่เพียงเพราะ prompt แนะนำ
- ร่องรอยการตรวจสอบ: เก็บ prompt, เวอร์ชันโมเดล/เครื่องมือ, และบันทึกการสร้างในรีโปเพื่อให้การเปลี่ยนแปลงอธิบายได้ในภายหลัง
อธิบายขอบเขตก่อนสลับโมดูล
ก่อนแทนที่คอมโพเนนต์ ให้เขียนลงว่า ขอบเขตและข้อเท็จจริง คืออะไร: อินพุตที่ยอมรับได้, สิ่งที่รับประกัน, สิ่งที่ห้ามทำ (เช่น "ห้ามลบข้อมูลลูกค้า"), และความคาดหวังด้านประสิทธิภาพ/latency นี่คือ "สัญญา" ที่คุณทดสอบ—ไม่ว่าจะเขียนโค้ดโดยใครหรืออะไร
เช็คลิสต์แบบเบา
- กำหนดสัญญาของโมดูล (อินพุต/เอาต์พุต, ข้อเท็จจริง)
- เพิ่ม/ยืนยันเทสต์สำหรับกรณีขอบเขต
- รันการสแกนความปลอดภัย + dependency
- ตรวจสอบความอ่านง่ายและการจัดการความล้มเหลว
- บันทึกเมตาดาต้าของ prompt/เครื่องมือ
- ส่งทีละน้อยภายใต้ flag และเฝ้าระวัง
ข้อสรุปเชิงปฏิบัติและแผนก้าวต่อไปง่ายๆ
โค้ดที่สร้างด้วย AI มักง่ายต่อการเขียนทับเพราะมักตามรูปแบบที่คุ้นเคย หลีกเลี่ยงการเป็นงานฝีมือเฉพาะตัว และสร้างใหม่ได้รวดเร็วยามความต้องการเปลี่ยน รูปแบบที่คาดเดาได้ลดต้นทุนทั้งเชิงเทคนิคและเชิงสังคมของการลบและทดแทนส่วนต่างๆ ของระบบ
เป้าหมายไม่ใช่ "ทิ้งโค้ด" แต่ทำให้การทดแทนเป็นตัวเลือกปกติที่มีแรงต้านต่ำ—รองรับด้วยสัญญาและการทดสอบ
ขั้นตอนปฏิบัติที่คุณทำได้สัปดาห์นี้
เริ่มจากการมาตรฐานคอนเวนชันเพื่อให้โค้ดที่สร้างซ้ำได้หรือเขียนทับมาเข้ากับแนวทางเดียวกัน:
- ล็อกคอนเวนชัน: การจัดรูปแบบ, โครงโฟลเดอร์, การตั้งชื่อ, การจัดการข้อผิดพลาด, และรูปแบบ API ติดต่อสั้นๆ ใน CONTRIBUTING.md
- เพิ่มการทดสอบสัญญาที่ขอบเขต: โฟกัสที่อินพุต/เอาต์พุตของโมดูลและบริการ (HTTP endpoints, queue messages, DB access layers) เทสต์เหล่านี้ควรผ่านแม้จะเปลี่ยนการใช้งานภายใน
- ติดตาม prompt และสเปก: เก็บ prompt, โน้ตความต้องการ, และร่องรอยการสร้างไว้กับโค้ดเพื่อให้การเขียนทับในอนาคตทำซ้ำเจตนา ไม่ใช่แค่ข้อความ
ถ้าคุณใช้ workflow แบบ vibe-coding ให้มองหาเครื่องมือที่ทำให้แนวทางเหล่านี้ง่าย: เก็บสเปกคู่กับรีโป, จับร่องรอยการสร้าง, และรองรับการย้อนกลับอย่างปลอดภัย ตัวอย่างเช่น Koder.ai ถูกออกแบบรอบการสร้างผ่านแชทพร้อม snapshot และการย้อนกลับ ซึ่งเข้ากับแนวทาง "ออกแบบให้ทดแทนได้"—สร้างชิ้นแล้วสร้างใหม่ภายใต้สัญญา แล้ว revert อย่างรวดเร็วถ้าเทสต์ความเท่าเทียมล้มเหลว
ลองโครงการนำร่อง 'โมดูลที่ทดแทนได้'
เลือกโมดูลที่สำคัญแต่แยกได้อย่างปลอดภัย—การสร้างรายงาน, การส่งการแจ้งเตือน, หรือพื้นที่ CRUD เดียว กำหนดอินเทอร์เฟซสาธารณะ เพิ่มการทดสอบสัญญา แล้วอนุญาตให้สร้างซ้ำ/รีแฟกเตอร์/เขียนทับอินเทอร์นอลจนมันน่าเบื่อ วัด cycle time, อัตราข้อบกพร่อง, และความพยายามในการรีวิว; ใช้ผลลัพธ์เพื่อกำหนดกฎสำหรับทั้งทีม
เพื่อนำไปปฏิบัติ ให้เก็บเช็คลิสต์ไว้ใน playbook ภายใน (หรือแชร์ผ่าน /blog) และบังคับให้ "contracts + conventions + traces" เป็นข้อกำหนดสำหรับงานใหม่ ถ้าคุณกำลังประเมินเครื่องมือ สนใจที่จะบันทึกความต้องการก่อนดู /pricing
คำถามที่พบบ่อย
ในโปรเจ็กต์จริง 'ง่ายต่อการทดแทน' หมายความว่าอะไรจริงๆ?
"แทนที่" มักหมายถึงการสลับ ชิ้น หนึ่งของระบบในขณะที่ส่วนที่เหลือยังทำงานอยู่ เป้าหมายทั่วไปได้แก่:
- โมดูล (PDF, กฎการเรียกเก็บเงิน, เทมเพลต)
- บริการ (ระบบแนะนำ, งานพื้นหลัง)
- พื้นที่ UI (หน้าเดียว/ฟีเจอร์เดียว)
การลบแล้วเขียนใหม่ทั้งแอปเป็นเรื่องไม่บ่อย; การเขียนทับที่สำเร็จมักเป็นแบบค่อยเป็นค่อยไป
ความหมายคือ AI-generated code ดีกว่าโค้ดที่เขียนด้วยมือหรือ?
ข้อโต้แย้งนี้เกี่ยวกับ แนวโน้มทั่วไป ไม่ใช่คุณภาพแบบตัดสินว่าโค้ด AI ดีกว่าเสมอ โค้ดที่สร้างด้วย AI มักจะ:
- ใช้ไลบรารีกระแสหลักและการจัดชั้นที่เป็นมาตรฐาน
- หลีกเลี่ยง 'มินิ-เฟรมเวิร์ก' แบบกำหนดเองเว้นแต่จะถูกชักชวน
- มีโครงสร้างที่คุ้นเคยคล้ายตัวอย่างในบทเรียน
รูปร่างที่ 'ไม่พิเศษ' นี้มักจะเข้าใจได้เร็วกว่าจึงสลับออกได้ปลอดภัยกว่า
ทำไมรูปแบบมาตรฐานจึงทำให้การเขียนทับถูกลง?
รูปแบบมาตรฐานจะลดต้นทุนเวลาในการถอดรหัสเมื่อเขียนทับ หากวิศวกรสามารถสังเกตได้อย่างรวดเร็วว่า:
- คำขอเข้ามาจากที่ไหนและไหลอย่างไร
- การตรวจสอบและการจัดการข้อผิดพลาดอยู่ที่ใด
- การเข้าถึงข้อมูลอยู่ที่ไหน
…พวกเขาจะทำซ้ำพฤติกรรมในการใช้งานใหม่ได้โดยไม่ต้องเรียนรู้อินเทอร์นัลที่เป็นส่วนตัวก่อน
อะไรคือ 'bespoke glue' และทำไมมันถึงทำให้การเขียนทับเสี่ยง?
Glue แบบกำหนดเอง (คอนเทนเนอร์ DI ที่ทำเอง, คลาสฐานวิเศษ, สถานะแบบ global ที่เปลี่ยนแปลง) สร้างการเชื่อมโยงที่ไม่ชัดเจนในโค้ด ในการทดแทนคุณจะพบว่าต้อง:
- ค้นพบลำดับการทำงานที่ซ่อนอยู่
- ทำซ้ำพฤติกรรมที่ไม่มีเอกสารโดยใช้การลองผิดลองถูก
- ทำให้สิ่งที่ 'ไม่ควรเชื่อมกัน' หยุดทำงาน
การเชื่อมต่อแบบ wiring ที่ชัดเจนและเป็นไปตามมาตรฐานมักจะลดความประหลาดใจเหล่านี้ได้
จะทำการเขียนทับแบบค่อยเป็นค่อยไปได้อย่างไรโดยไม่ทำให้ธุรกิจหยุดชะงัก?
แนวทางที่เป็นปฏิบัติคือการทำให้ขอบเขตนิ่งและสลับอินเตอร์นอล:
- กำหนดสัญญาของโมดูล (อินพุต/เอาต์พุต, ข้อเท็จจริงที่ต้องคงไว้)
- เพิ่มการทดสอบสัญญาที่ขอบเขต
- ทำ V2 ตามอินเทอร์เฟซเดียวกัน
- สลับการเชื่อมต่อในที่เดียว (DI/factory)
- เปิดใช้งานด้วย feature flag แล้วเฝ้าระวัง
นี่คือสไตล์ 'strangler': บันได ไม่ใช่หน้าผา
อะไรคือ 'author attachment' และมันมีผลต่อการเขียนทับอย่างไร?
เพราะโค้ดที่สร้างด้วย AI มักดูเหมือนมาจากเครื่องมือ ผู้คนมักรู้สึกว่ามันไม่ใช่ 'ผลงานลายเซ็น' ของใครคนใดคนหนึ่ง นั่นทำให้ทีมมักจะ:
- ตั้งคำถามกับโค้ดปัจจุบันได้อิสระขึ้น
- ลบและสร้างใหม่ได้โดยไม่ต้องต่อรองเรื่องความภาคภูมิใจ
- กระจายความรู้ได้เร็วขึ้นเพราะไม่มีการยึดถือ 'พื้นที่ที่เป็นของใคร'
มันไม่ลบข้อควรพิจารณาทางวิศวกรรม แต่ลดแรงต้านทางสังคมเมื่อต้องเปลี่ยนแปลง
จะใช้ prompts และร่องรอยการสร้างเป็นเอกสารอย่างไร?
ถ้าคุณเก็บ prompt, เทมเพลต และการตั้งค่าการสร้างไว้ในรีโป มันสามารถทำหน้าที่เป็นสเปกแบบย่อ:
- ฟีเจอร์ควรทำอะไร
- ข้อจำกัด (ความปลอดภัย, ประสิทธิภาพ, สไตล์)
- การจัดการข้อผิดพลาดและการทดสอบที่คาดหวัง
เวอร์ชันพวกมันในรีโปและบันทึกว่าพารามิเตอร์ใดสร้างโมดูลไหน มิฉะนั้น prompt จะกลายเป็น dependency ที่ไม่มีเอกสารอีกชิ้นหนึ่ง
การทดสอบแบบไหนสำคัญที่สุดหากต้องการให้คอมโพเนนต์สามารถทดแทนได้?
เน้นการทดสอบที่รอยต่อซึ่งเกิดการทดแทน:
- API ภายนอก (requests/responses, pagination, error codes)
- อแดปเตอร์ (การชำระเงิน, อีเมล, ที่เก็บไฟล์, คิว)
- สัญญาข้อมูล (serialization, validation, migrations)
เมื่อการทดสอบสัญญาเหล่านี้ผ่าน คุณจะเขียนทับอินเทอร์นอลได้โดยไม่ต้องกลัวมาก
ข้อบกพร่องทั่วไปของโค้ด AI ที่ทำให้การทดแทนง่ายขึ้นคืออะไร?
โค้ดที่สร้างด้วย AI มักล้มเหลวในรูปแบบที่มองเห็นได้:
- การทำซ้ำและ near-duplicate
- การตรวจสอบหรือการจัดการข้อผิดพลาดไม่สอดคล้องกัน
- ฟังก์ชันที่โตขึ้นโดยการเติม 'แก้ไข' ต่อเนื่อง
ใช้การทำซ้ำเป็นสัญญาณ: สกัดพฤติกรรมซ้ำเป็นโมดูลเดียวที่มีการทดสอบ แล้วลบสำเนาออก
เมื่อไหร่ควร regenerate vs refactor vs rewrite และมีเกราะป้องกันอะไรบ้าง?
ใช้การ regenerate กับส่วนที่เป็น boilerplate และมีอินเทอร์เฟซชัดเจน; refactor สำหรับการปรับโครงสร้าง; rewrite เมื่อสถาปัตยกรรม/ขอบเขตผิดหลัก
เกณฑ์ป้องกัน ได้แก่:
- กำหนดสัญญาและข้อเท็จจริงก่อนสลับ
- เพิ่ม/ยืนยันการทดสอบกรณีขอบเขต
- รันการสแกนความปลอดภัยและ dependency
- ต้องมีการตรวจสอบโดยมนุษย์ (มุมมอง 'generated code')
- ปล่อยทีละน้อยและเฝ้าดู
สิ่งนี้ช่วยให้ "ง่ายต่อการทดแทน" ไม่กลายเป็น "ง่ายต่อการทำลาย"