14 พ.ย. 2568·3 นาที
ทำไมต้องมี Read Replicas และเมื่อไหร่ที่มันช่วยได้จริง
เรียนรู้ว่าทำไมต้องมี read replicas ปัญหาใดที่ช่วยแก้ และเมื่อไหร่ที่มันช่วยจริง (หรือทำให้แย่ลง) รวมกรณีใช้งานทั่วไป ขีดจำกัด และคำแนะนำการตัดสินใจเชิงปฏิบัติ
เรียนรู้ว่าทำไมต้องมี read replicas ปัญหาใดที่ช่วยแก้ และเมื่อไหร่ที่มันช่วยจริง (หรือทำให้แย่ลง) รวมกรณีใช้งานทั่วไป ขีดจำกัด และคำแนะนำการตัดสินใจเชิงปฏิบัติ
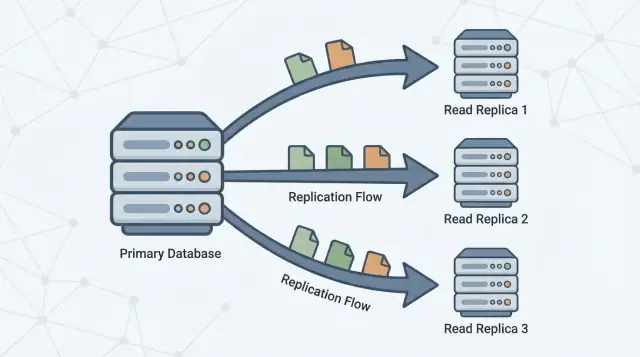
“Read replica” คือสำเนาของฐานข้อมูลหลักของคุณ (บางครั้งเรียกว่า primary) ที่อัพเดตอยู่เสมอโดยรับการเปลี่ยนแปลงจากมัน แอปของคุณสามารถส่งคำสั่งที่เป็นการอ่านเท่านั้น (เช่น SELECT) ไปยัง replica ในขณะที่ primary ยังคงจัดการการเขียนทั้งหมด (เช่น INSERT, UPDATE, DELETE)
คำสัญญาง่าย ๆ คือ: เพิ่มความจุสำหรับการอ่านโดยไม่เพิ่มแรงกดดันให้ primary
ถ้าแอปคุณมีทราฟฟิก “ดึงข้อมูล” จำนวนมาก—หน้าแรก หน้าแสดงสินค้า โปรไฟล์ผู้ใช้ แดชบอร์ด—การย้ายการอ่านบางส่วนไปยัง replica หนึ่งตัวหรือหลายตัวสามารถช่วยให้ primary มุ่งไปที่งานเขียนและการอ่านที่สำคัญได้ ในการตั้งค่าหลายแบบนี่มักทำได้โดยไม่ต้องเปลี่ยนแอปมาก: เก็บฐานข้อมูลหนึ่งตัวเป็นแหล่งความจริงแล้วเพิ่ม replica เป็นจุดเพิ่มเติมสำหรับการสืบค้น
Replica มีประโยชน์ แต่ไม่ใช่ปุ่มวิเศษด้านประสิทธิภาพ พวกมัน ไม่ ทำให้ได้:
คิดว่า replica เป็น เครื่องมือเพิ่มการอ่านที่มีการแลกเปลี่ยน ส่วนที่เหลือของบทความนี้อธิบายว่าเมื่อไหร่ที่มันช่วยจริง ๆ วิธีที่มักเกิดปัญหา และแนวคิดอย่าง replication lag และ eventual consistency ส่งผลอย่างไรเมื่อผู้ใช้เริ่มอ่านจากสำเนาแทนจาก primary
เซิร์ฟเวอร์ฐานข้อมูล primary เดียวมักเริ่มต้นด้วยความรู้สึกว่า “ใหญ่พอแล้ว” มันจัดการการเขียน (insert, update, delete) และยังตอบคำร้องทุกการอ่าน (SELECT) จากแอป แดชบอร์ด และเครื่องมือภายใน
เมื่อการใช้งานเติบโต การอ่านมักเพิ่มเร็วกว่าการเขียน: ทุกการดูหน้าอาจกระตุ้นหลายคิวรี หน้าค้นหาสามารถแตกเป็นการค้นหาแบบกระจาย และคิวรีสไตล์วิเคราะห์สามารถสแกนแถวจำนวนมาก แม้ปริมาณการเขียนจะปานกลาง primary ก็ยังกลายเป็นคอขวดเพราะต้องทำสองงานพร้อมกัน: ยอมรับการเปลี่ยนแปลงอย่างปลอดภัยและรวดเร็ว และ ให้บริการทราฟฟิกการอ่านที่เพิ่มขึ้นด้วยความหน่วงต่ำ
Replica มีขึ้นเพื่อแยกภาระงานนั้น Primary ยังคงมุ่งเน้นที่การประมวลผลการเขียนและรักษา “แหล่งความจริง” ขณะที่ replica หนึ่งตัวหรือหลายตัวจัดการคำถามที่เป็นการอ่าน เมื่อแอปของคุณสามารถกำหนดเส้นทางคิวรีบางส่วนไปยัง replica ได้ คุณจะลดแรงกดดัน CPU, หน่วยความจำ และ I/O บน primary นั่นมักปรับปรุงการตอบสนองโดยรวมและให้พื้นที่หัวใจสำหรับการระเบิดของการเขียน
Replication เป็นกลไกที่ทำให้ replica อัพเดตโดยคัดลอกการเปลี่ยนแปลงจาก primary ไปยังเซิร์ฟเวอร์อื่น ๆ Primary บันทึกการเปลี่ยนแปลง และ replica นำการเปลี่ยนแปลงนั้นไปใช้เพื่อให้สามารถตอบคำถามด้วยข้อมูลที่เกือบจะเหมือนกันได้
รูปแบบนี้พบได้ทั่วไปในระบบฐานข้อมูลและบริการจัดการหลายแห่ง (เช่น PostgreSQL, MySQL และเวอร์ชันบนคลาวด์) การใช้งานจริงจะแตกต่างกัน แต่เป้าหมายเหมือนกัน: เพิ่มความจุการอ่านโดยไม่บังคับให้ primary ต้องอัพสเกลแบบแนวตั้งตลอดไป
คิดว่า primary เป็น “แหล่งความจริง” มันยอมรับการเขียนทั้งหมด—การสร้างคำสั่งซื้อ อัพเดตโปรไฟล์ บันทึกการชำระเงิน—และกำหนดลำดับที่แน่นอนของการเปลี่ยนแปลง
หนึ่งหรือหลาย read replica จะ ตาม primary คัดลอกการเปลี่ยนแปลงเหล่านั้นเพื่อให้สามารถตอบคำถามการอ่าน (เช่น “แสดงประวัติคำสั่งซื้อของฉัน”) โดยไม่เพิ่มภาระให้ primary
การอ่านสามารถให้บริการจาก replica ได้ แต่การเขียนยังคงไปที่ primary
การทำซ้ำมีสองโหมดกว้าง ๆ:
ความล่าช้า—ที่ replica ตาม primary ไม่ทัน—เรียกว่า replication lag มันไม่ใช่ความล้มเหลวโดยอัตโนมัติ มักเป็นการแลกเปลี่ยนปกติที่คุณยอมรับเพื่อขยายการอ่าน
สำหรับผู้ใช้ lag ปรากฏเป็น eventual consistency: หลังจากคุณเปลี่ยนข้อมูล ระบบจะสอดคล้องกันทั่วทั้งระบบ แต่ไม่จำเป็นต้องทันที
ตัวอย่าง: คุณอัปเดตที่อยู่อีเมลแล้วรีเฟรชหน้าโปรไฟล์ หากหน้านั้นให้บริการจาก replica ที่ล้าหลังไม่กี่วินาที คุณอาจเห็นอีเมลเก่าเป็นเวลาสั้น ๆ—จนกว่า replica จะนำการอัปเดตไปใช้และ “ตามทัน”
Replica ช่วยเมื่อ ฐานข้อมูล primary ของคุณยังเขียนได้ดี แต่ถูกรบกวนจากการให้บริการการอ่านมากเกินไป พวกมันมีประสิทธิภาพสูงเมื่อคุณสามารถย้ายส่วนที่มีความหมายของภาระ SELECT ได้โดยไม่ต้องเปลี่ยนวิธีการเขียนข้อมูล
มองหารูปแบบเช่น:
SELECT ต่อ INSERT/UPDATE/DELETE สูงมากก่อนเพิ่ม replica ให้ยืนยันด้วยสัญญาณชัดเจนบางอย่าง:
SELECT (จาก slow query log/APM)บ่อยครั้งการเคลื่อนไหวแรกที่ดีที่สุดคือ การปรับจูน: เพิ่มดัชนีที่ถูกต้อง เขียนคิวรีใหม่ ลด N+1 calls หรือแคชการอ่านร้อน ๆ การเปลี่ยนแปลงเหล่านี้อาจเร็วกว่าหรือถูกกว่าการดำเนินงาน replica
เลือก replicas หาก:
เลือก ปรับจูนก่อน หาก:
Read replicas มีค่าสูงสุดเมื่อ primary ของคุณยุ่งกับการเขียน (การเช็คเอาต์ การสมัคร อัปเดต) แต่ส่วนใหญ่ของทราฟฟิกเป็นการอ่าน ในสถาปัตยกรรม primary–replica การผลักคิวรีที่ถูกต้องไปยัง replica ช่วยปรับปรุงประสิทธิภาพฐานข้อมูลโดยไม่ต้องเปลี่ยนฟีเจอร์ของแอป
แดชบอร์ดมักรันคิวรียาว ๆ: การกรุ๊ป การกรองช่วงวันที่ไกล หรือการ join หลายตาราง คิวรีเหล่านี้สามารถแย่ง CPU หน่วยความจำและแคชกับงานธุรกรรมได้
Replica เหมาะสำหรับ:
คุณเก็บ primary ให้โฟกัสกับธุรกรรมที่เร็วและคาดเดาได้ ขณะที่การอ่านวิเคราะห์สเกลแยกออกไป
การเรียกดูแคตตาล็อก โปรไฟล์ผู้ใช้ และฟีดคอนเทนต์ สามารถสร้างการอ่านซ้ำ ๆ จำนวนมาก เมื่อแรงกดดันจากการอ่านเป็นคอขวด Replica สามารถรับทราฟฟิกและลดการเกิด spike ของความหน่วงได้
สิ่งนี้ได้ผลดีโดยเฉพาะเมื่อการอ่านมีการพลาดแคชบ่อย (คิวรีเอกลักษณ์จำนวนมาก) หรือเมื่อไม่สามารถพึ่งพาแคชแอปได้อย่างเต็มที่
การส่งออกข้อมูล, backfills, การคำนวณสรุปใหม่ และงาน “ค้นหาเรกคอร์ดที่ตรง X ทุกตัว” สามารถกระทบ primary ได้ การรันการสแกนเหล่านี้บน replica มักปลอดภัยกว่า
แค่แน่ใจว่างานยอมรับ eventual consistency: ด้วย replication lag มันอาจจะไม่เห็นการอัปเดตล่าสุด
ถ้าคุณให้บริการผู้ใช้ทั่วโลก วาง replica ใกล้ผู้ใช้สามารถลดเวลาเดินทางของแพ็กเก็ตได้ การแลกเปลี่ยนคือต้องยอมรับการอ่านล้าสมัยได้มากขึ้นในช่วง lag หรือปัญหาเครือข่าย ดังนั้นมันเหมาะกับหน้าที่ “เกือบจะทันที” ก็พอ เช่น การเรียกดู คำแนะนำ เนื้อหาสาธารณะ
Replica ดีเมื่อ “ใกล้เคียงก็พอ” แต่จะกลายเป็นปัญหาเมื่อผลิตภัณฑ์ของคุณเงื่อนไขว่าการอ่านทุกครั้งต้องสะท้อนการเขียนล่าสุดทันที
ผู้ใช้แก้โปรไฟล์ ส่งฟอร์ม หรือเปลี่ยนการตั้งค่า—แล้วโหลดหน้าต่อมาดึงจาก replica ที่ล้าหลังไม่กี่วินาที การอัปเดตสำเร็จ แต่ผู้ใช้เห็นข้อมูลเก่าและกดซ้ำ ส่งซ้ำ หรือสูญเสียความเชื่อมั่น
นี่เจ็บปวดโดยเฉพาะในฟลูว์ที่ผู้ใช้คาดหวังการยืนยันทันที: เปลี่ยนอีเมล, สลับการตั้งค่า, อัพโหลดเอกสาร, หรือโพสต์คอมเมนต์แล้วถูกรีไดเรกต์กลับ
บางการอ่านทนต่อการล้าสมัยไม่ได้แม้สั้น ๆ เช่น:
ถ้า replica ล้าหลัง คุณอาจแสดงยอดตะกร้าผิด ขายเกินสต็อก หรือโชว์ยอดเก่า แม้ระบบจะแก้ไขในภายหลัง ประสบการณ์ผู้ใช้และงานซัพพอร์ตก็จะเสียหาย
แดชบอร์ดภายในมักใช้ตัดสินใจจริง: ตรวจสอบการฉ้อโกง ซัพพอร์ตลูกค้า การจัดคำสั่ง จัดการเนื้อหา ถ้าเครื่องมือแอดมินอ่านจาก replicas คุณเสี่ยงที่จะตัดสินบนข้อมูลไม่สมบูรณ์—เช่น คืนเงินซ้ำซ้อน หรือตกหล่นการเปลี่ยนสถานะล่าสุด
รูปแบบที่ใช้กันทั่วไปคือการกำหนดเส้นทางตามเงื่อนไข:
วิธีนี้รักษาประโยชน์ของ replicas โดยไม่ปล่อยให้ความสอดคล้องกลายเป็นการเดา
Replication lag คือความล่าช้าระหว่างเมื่อการเขียนคอมมิตบน primary กับเมื่อการเปลี่ยนแปลงนั้นมองเห็นได้บน replica ถ้าแอปอ่านจาก replica ในช่วงนั้น มันจะคืนผลที่ “เก่า”—ข้อมูลที่ถูกต้องเมื่อครู่ก่อน แต่ไม่ใช่ตอนนี้
Lag เป็นเรื่องปกติ และมักเพิ่มขึ้นภายใต้ภาระ สาเหตุทั่วไปได้แก่:
Lag ไม่ได้มีผลแค่ความสดของข้อมูล—มันกระทบความถูกต้องจากมุมมองผู้ใช้:
เริ่มจากตัดสินว่าฟีเจอร์ของคุณทนได้แค่ไหน:
ติดตาม replica lag (เวลา/ไบต์ที่ตามหลัง), อัตราการ apply ของ replica, ข้อผิดพลาดการทำซ้ำ, และการใช้ CPU/disk I/O ของ replica ตั้งเตือนเมื่อ lag เกินระดับที่ตกลงกันไว้ (เช่น 5s, 30s, 2m) และเมื่อ lag เพิ่มขึ้นต่อเนื่อง (สัญญาณว่า replica จะตามไม่ทันโดยไม่แทรกแซง)
Read replicas เป็นเครื่องมือสำหรับ การขยายการอ่าน: เพิ่มจุดให้บริการ SELECT พวกมันไม่ใช่เครื่องมือสำหรับ การขยายการเขียน: เพิ่มจำนวน INSERT/UPDATE/DELETE ที่ระบบรับได้
เมื่อคุณเพิ่ม replica คุณเพิ่ม ความจุการอ่าน หากแอปของคุณติดคอขวดที่ endpoints อ่านหนัก (หน้าแสดงสินค้า ฟีด การค้นหา) คุณสามารถกระจายคิวรีเหล่านั้นไปยังหลายเครื่องได้
สิ่งที่มักดีขึ้น:
SELECT มากขึ้น)ความเข้าใจผิดทั่วไปคือ “มี replica มากขึ้น = ความสามารถเขียนเพิ่ม” ในการตั้งค่า primary–replica แบบปกติ การเขียนทั้งหมดยังคงไปที่ primary จริง ๆ แล้ว replica มากขึ้นอาจเพิ่มงานสำหรับ primary เล็กน้อย เพราะต้องสร้างและส่งข้อมูลการทำซ้ำไปยังทุก replica
ถ้าปัญหาของคุณคือ throughput การเขียน Replica จะไม่แก้ มักต้องพิจารณาวิธีอื่น (ปรับคิวรี/ดัชนี การแบตช์ การพาร์ติชัน/ชาร์ด หรือเปลี่ยนโมเดลข้อมูล)
แม้ replica จะให้ CPU สำหรับการอ่านมากขึ้น คุณอาจยังโดน ขีดจำกัดการเชื่อมต่อ ก่อน แต่ละโหนดมีจำนวนการเชื่อมต่อพร้อมกันสูงสุด และการเพิ่ม replica อาจทำให้มีจุดเชื่อมต่อมากขึ้นโดยไม่ลดอุปสงค์ทั้งหมด
กฎปฏิบัติ: ใช้ connection pooling (หรือ pooler) และตั้งค่าจำนวนการเชื่อมต่อแต่ละบริการอย่างรอบคอบ มิฉะนั้น replicas อาจกลายเป็น “ฐานข้อมูลหลายตัวที่อาจถูกโอเวอร์โหลด”
Replica เพิ่มต้นทุนจริง:
การแลกเปลี่ยนชัดเจน: replicas ซื้อ headroom สำหรับการอ่านและการแยกงาน แต่เพิ่มความซับซ้อนและไม่ยกเพดานการเขียน
Read replicas สามารถปรับปรุง ความพร้อมใช้งานของการอ่าน: หาก primary โอเวอร์โหลดหรือไม่พร้อมใช้งานชั่วคราว คุณยังอาจให้บริการเนื้อหาบางประเภทจาก replicas นั่นช่วยให้หน้าที่ลูกค้าเห็นได้และลดผลกระทบเมื่อ primary เกิดเหตุ
สิ่งที่ replicas ไม่ ให้คือแผนความพร้อมใช้งานที่สมบูรณ์ด้วยตัวเอง Replica โดยทั่วไปไม่ได้พร้อมรับการเขียนโดยอัตโนมัติ และ “มีสำเนาที่อ่านได้” แตกต่างจาก “ระบบสามารถรับการเขียนได้อย่างปลอดภัยและรวดเร็วอีกครั้ง”
Failover โดยทั่วไปหมายถึง: ตรวจพบ primary ล้มเหลว → เลือก replica → โปรโมทให้เป็น primary ใหม่ → เปลี่ยนเส้นทางการเขียน (และมักจะรวมถึงการอ่านด้วย) ไปยังโหนดที่ได้รับการโปรโมท
บริการฐานข้อมูลที่จัดการบางรายอัตโนมัติส่วนใหญ่ของกระบวนการนี้ แต่แนวคิดหลักยังคงเหมือนเดิม: คุณกำลังเปลี่ยนว่าใครเป็นคนรับเขียน
ฝึก failover เป็นกิจกรรม ทำ game-day tests ใน staging (และอย่างระมัดระวังใน production ในหน้าต่างความเสี่ยงต่ำ): จำลองการสูญเสีย primary วัดเวลาการกู้คืน ตรวจสอบการกำหนดเส้นทาง และยืนยันว่าแอปจัดการช่วงที่อ่านได้อย่างเดียวและการเชื่อมต่อใหม่ได้ดี
Replica จะช่วยได้ก็ต่อเมื่อทราฟฟิกของคุณไปถึงพวกมันจริง ๆ “การแยกอ่าน/เขียน” คือชุดกฎที่ส่งการเขียนไปที่ primary และการอ่านที่เหมาะสมไปยัง replicas—โดยไม่ทำลายความถูกต้อง
วิธีที่ง่ายที่สุดคือการกำหนดเส้นทางชัดเจนในชั้นเข้าถึงข้อมูลของคุณ:
INSERT/UPDATE/DELETE, การเปลี่ยนสกีมา) ไปที่ primaryวิธีนี้เข้าใจง่ายและเลิกใช้ได้ง่าย คุณยังสามารถเข้ารหัสกฎทางธุรกิจเช่น “หลังเช็คเอาต์ ให้เสิร์ชสถานะคำสั่งจาก primary ช่วงสั้น ๆ”
บางทีมชอบพร็อกซีฐานข้อมูลหรือไดรเวอร์อัจฉริยะที่เข้าใจ endpoint primary vs replica และกำหนดเส้นทางตามประเภทคิวรีหรือการตั้งค่าการเชื่อมต่อ ลดการเปลี่ยนแปลงโค้ดแอป แต่ระวัง: พร็อกซีไม่อาจรู้ได้เสมอว่าการอ่านแบบไหน “ปลอดภัย” ในเชิงผลิตภัณฑ์
ผู้สมัครที่ดีคือ:
หลีกเลี่ยงการส่งการอ่านที่ตามมาทันทีหลังการเขียนของผู้ใช้ไปยัง replica (เช่น “อัปเดตโปรไฟล์ → โหลดโปรไฟล์อีกครั้ง”) เว้นแต่คุณมีกลยุทธ์ความสอดคล้อง
ภายในทรานแซกชัน ให้เก็บการอ่านทั้งหมดบน primary
นอกทรานแซกชัน พิจารณา session แบบ “อ่าน-หลัง-เขียน”: หลังการเขียน ให้ปักหมุดผู้ใช้/เซสชันนั้นไปยัง primary เป็น TTL สั้น ๆ หรือกำหนดเส้นทางคิวรีติดตามไปยัง primary
เพิ่ม replica หนึ่งตัว กำหนดเส้นทางเฉพาะ endpoint/call แล้วเปรียบเทียบก่อน/หลัง:
ขยายการกำหนดเส้นทางเมื่อผลกระทบชัดเจนและปลอดภัย
Read replicas ไม่ใช่ “วางแล้วลืม” พวกมันเป็นเซิร์ฟเวอร์ฐานข้อมูลเพิ่มเติมที่มีขีดจำกัดประสิทธิภาพ โหมดล้มเหลว และงานปฏิบัติการของตัวเอง วินัยด้านมอนิเตอร์เล็กน้อยมักเป็นความต่างระหว่าง “replicas ช่วยได้” กับ “replicas เพิ่มความสับสน”
มุ่งที่ตัวชี้วัดที่อธิบายอาการที่ผู้ใช้เห็นได้:
เริ่มด้วย replica ตัวเดียวถ้าวัตถุประสงค์คือการลดภาระการอ่าน เพิ่มอีกเมื่อมีข้อจำกัดชัดเจน:
กฎปฏิบัติ: ขยาย replicas เมื่อยืนยันแล้วว่าการอ่านเป็นคอขวด (ไม่ใช่ดัชนี คิวรี หรือแคชชิ่งแอป)
Read replicas เป็นเครื่องมือหนึ่งในการขยายการอ่าน แต่ไม่ค่อยใช่คันแรกสุดที่ควรดึง ก่อนเพิ่มความซับซ้อนในการปฏิบัติการ ให้ตรวจสอบว่าการแก้ปัญหาที่ง่ายกว่าช่วยได้หรือไม่
แคช สามารถลบทั้งหมวดของการอ่านออกจากฐานข้อมูล สำหรับหน้าที่อ่านส่วนใหญ่ (รายละเอียดสินค้า โปรไฟล์สาธารณะ การตั้งค่า) แคชแอปหรือ CDN สามารถลดภาระอย่างมาก—โดยไม่เพิ่ม replication lag
ดัชนีและปรับคิวรี มักให้ผลดีกว่าการเพิ่ม replica สำหรับกรณีทั่วไป: คิวรีแพงไม่กี่ตัวเผาผลาญ CPU การเพิ่มดัชนีที่เหมาะสม ลดคอลัมน์ใน SELECT หลีกเลี่ยง N+1 และแก้ JOIN ที่ไม่ดี มักทำให้ความต้องการ replica หายไป
มุมมองวัสดุ/การพรีแอ็กรีเกต เหมาะเมื่อโหลดเป็นเชิงหนักจริง ๆ (วิเคราะห์ แดชบอร์ด) แทนที่จะรันคิวรีซับซ้อนซ้ำ ๆ ให้เก็บผลลัพธ์คำนวณไว้แล้วรีเฟรชตามกำหนด
ถ้า การเขียน เป็นคอขวด (แถวร้อน การรอล็อก ข้อจำกัด I/O การเขียน) Replicas จะช่วยได้ไม่มาก นี่คือเวลาที่การพาร์ติชันตามเวลา/tenant หรือการชาร์ดตาม ID ลูกค้าจะช่วยกระจายภาระการเขียนและลด contention ได้ แม้จะเป็นก้าวสถาปัตยกรรมใหญ่ แต่แก้ข้อจำกัดจริง
ถามตัวเองสี่ข้อ:
ถ้าคุณกำลังทดลองผลิตภัณฑ์หรือเริ่มบริการเร็ว ๆ การวางข้อจำกัดเหล่านี้ไว้ตั้งแต่ต้นช่วยได้ ตัวอย่างเช่น ทีมที่สร้างบน Koder.ai (แพลตฟอร์ม vibe-coding ที่สร้างแอป React กับแบ็กเอนด์ Go + PostgreSQL จากอินเทอร์เฟซแชท) มักเริ่มด้วย primary เดียวเพื่อความเรียบง่าย แล้วค่อยย้ายไปใช้ replicas เมื่อแดชบอร์ด ฟีด หรือรายงานภายในเริ่มแข่งกับทราฟฟิกธุรกรรม การทำงานแบบวางแผนล่วงหน้าช่วยให้ตัดสินใจได้ง่ายขึ้นตั้งแต่แรกว่าจุดไหนรับ eventual consistency ได้และจุดไหนต้องอ่านจาก primary
หากคุณต้องการความช่วยเหลือในการเลือกเส้นทาง ดู pricing สำหรับตัวเลือก หรือเรียกดูไกด์ที่เกี่ยวข้องใน blog.
A read replica คือสำเนาของฐานข้อมูลหลักที่จะรับการเปลี่ยนแปลงอย่างต่อเนื่องและสามารถตอบคำถามที่เป็นการอ่านเท่านั้น (เช่น SELECT) ช่วยเพิ่มความจุสำหรับการอ่านโดยไม่เพิ่มภาระการอ่านให้กับ primary
ไม่ ในการตั้งค่า primary–replica แบบทั่วไป ทุกการเขียนยังต้องไปที่ primary และ replicas อาจเพิ่มงานให้ primary เล็กน้อยเพราะต้องส่งข้อมูลการทำซ้ำไปให้แต่ละตัว
เมื่อระบบของคุณเป็น read-bound: มีทราฟฟิก SELECT จำนวนมากที่กด CPU/IO หรือการเชื่อมต่อของ primary ขณะที่ปริมาณการเขียนค่อนข้างคงที่ และเมื่อคุณต้องแยกงานอ่านหนัก (รายงาน, การส่งออก) ออกจากงานธุรกรรม Replicas จะช่วยได้มาก
ไม่เสมอไป หากคิวรีช้าเพราะขาดดัชนี โจทย์ JOIN ที่ไม่ดี หรือการสแกนข้อมูลจำนวนมาก มันมักจะช้าใน replica เช่นกัน—เพียงแต่ช้าที่อื่น ปรับคิวรีและดัชนีก่อน เมื่อคิวรีไม่กี่รายการกินเวลาทั้งหมด
Replication lag คือความหน่วงระหว่างเมื่อการเขียนถูกคอมมิตบน primary กับเมื่อการเปลี่ยนแปลงนั้นปรากฏบน replica ระหว่างที่มี lag การอ่านจาก replica อาจได้ข้อมูลที่ เก่า ซึ่งเป็นเหตุผลที่การใช้ replicas มักหมายถึงการยอมรับ eventual consistency สำหรับการอ่านบางอย่าง
สาเหตุทั่วไปได้แก่:
หลีกเลี่ยงการอ่านจาก replicas ในจุดที่ต้องสะท้อนการเขียนล่าสุด เช่น:
สำหรับกรณีเหล่านี้ ให้ดึงข้อมูลจาก primary อย่างน้อยในเส้นทางวิกฤต
ใช้กลยุทธ์ อ่านหลังเขียน (read-your-writes):
ติดตามสัญญาณสำคัญเหล่านี้:
ตั้งเตือนเมื่อ lag เกินระดับที่ระบบรับได้ (เช่น 5s/30s/2m)
ทางเลือกที่มักได้ผล:
Replicas เหมาะเมื่องานอ่านได้รับการปรับให้เหมาะสมแล้วและคุณยอมรับความล้าสมัยได้บางส่วน