15 ต.ค. 2568·2 นาที
ทำไมฐานข้อมูลแบบเอกสารถึงได้เปรียบเมื่อแบบข้อมูลเปลี่ยนบ่อย
เรียนรู้ว่าทำไมฐานข้อมูลเอกสารเหมาะกับแบบข้อมูลที่เปลี่ยนเร็ว: สคีมาที่ยืดหยุ่น การทำซ้ำที่เร็วขึ้น การเก็บ JSON แบบเป็นธรรมชาติ และข้อแลกเปลี่ยนที่ควรวางแผน
เรียนรู้ว่าทำไมฐานข้อมูลเอกสารเหมาะกับแบบข้อมูลที่เปลี่ยนเร็ว: สคีมาที่ยืดหยุ่น การทำซ้ำที่เร็วขึ้น การเก็บ JSON แบบเป็นธรรมชาติ และข้อแลกเปลี่ยนที่ควรวางแผน
ฐานข้อมูลเอกสาร เก็บข้อมูลเป็นเอกสารที่มีตัวเองครบ ซึ่งมักจะอยู่ในรูปแบบคล้าย JSON แทนที่จะกระจายวัตถุธุรกิจหนึ่งชิ้นข้ามหลายตาราง เอกสารเดียวสามารถเก็บทุกอย่างเกี่ยวกับวัตถุนั้นได้—ฟิลด์ ย่อยของฟิลด์ และอาเรย์—คล้ายกับวิธีที่แอปหลายตัวแสดงข้อมูลในโค้ดอยู่แล้ว
users หรือ orders)เอกสารในคอลเลกชันเดียวกันไม่จำเป็นต้องเหมือนกันทุกประการ เอกสารผู้ใช้หนึ่งฉบับอาจมี 12 ฟิลด์ อีกฉบับมี 18 ฟิลด์ และทั้งคู่ยังคงอยู่ร่วมกันได้
ลองนึกถึงโปรไฟล์ผู้ใช้ เริ่มด้วย name และ email เดือนหน้าฝ่ายการตลาดต้องการ preferred_language แล้วทีม success ขอ timezone และ subscription_status ต่อมาเพิ่ม social_links (อาเรย์) และ privacy_settings (อ็อบเจ็กต์ซ้อน)
ในฐานข้อมูลเอกสาร คุณมักจะเริ่มเขียนฟิลด์ใหม่ได้ทันที เอกสารเก่าสามารถคงสภาพเดิมจนกว่าคุณจะตัดสินใจจะ backfill (หรือไม่ก็ได้)
ความยืดหยุ่นนี้ช่วยเร่งการทำงานของผลิตภัณฑ์ แต่จะโยกความรับผิดชอบไปที่แอปและทีมของคุณ: คุณจะต้องมีข้อปฏิบัติที่ชัดเจน กฎการตรวจสอบแบบเลือกได้ และการออกแบบคิวรีที่รอบคอบเพื่อหลีกเลี่ยงข้อมูลที่ยุ่งเหยิงและไม่สอดคล้อง
ต่อไปเราจะดูว่าทำไมโมเดลบางอย่างจึงเปลี่ยนบ่อย วิธีที่สคีมาที่ยืดหยุ่นลดแรงเสียดทานอย่างไร เอกสารแมปกับคิวรีแอปอย่างไร และข้อแลกเปลี่ยนที่ควรพิจารณาก่อนเลือกเก็บข้อมูลเป็นเอกสารแทนเชิงสัมพันธ์—หรือใช้แนวทางผสม
แบบข้อมูลไม่ค่อยคงที่เพราะผลิตภัณฑ์ไม่คงที่ สิ่งที่เริ่มต้นว่า “แค่เก็บโปรไฟล์ผู้ใช้” มักกลายเป็นการตั้งค่าความชอบ การแจ้งเตือน เมตาดาต้าการเรียกเก็บเงิน ข้อมูลอุปกรณ์ ธงยินยอม และรายละเอียดอีกหลายอย่างที่ไม่มีในเวอร์ชันแรก
การเปลี่ยนแปลงส่วนใหญ่เกิดจากการเรียนรู้ ทีมเพิ่มฟิลด์เมื่อพวกเขา:\n
การเปลี่ยนเหล่านี้มักเป็นการเพิ่มทีละเล็กทีละน้อยและบ่อย—การเพิ่มเล็ก ๆ ที่ยากจะจัดตารางเป็น "มิเกรชันครั้งใหญ่"
ฐานข้อมูลจริงมีประวัติ ระเบียนเก่าจะคงรูปร่างที่ถูกเขียนไว้ ในขณะที่ระเบียนใหม่จะใช้รูปร่างล่าสุด คุณอาจมีลูกค้าที่สร้างก่อน marketing_opt_in มีคำสั่งซื้อก่อนที่ delivery_instructions จะถูกสนับสนุน หรือเหตุการณ์ที่บันทึกก่อนฟิลด์ source ใหม่จะถูกนิยาม
ดังนั้นคุณไม่ได้ "เปลี่ยนแบบข้อมูลเดียว"—คุณกำลังรองรับหลายเวอร์ชันพร้อมกัน บางครั้งเป็นเดือน
เมื่อหลายทีมปล่อยงานพร้อมกัน แบบข้อมูลกลายเป็นพื้นที่ผิวร่วม ทีมจ่ายเงินอาจเพิ่มสัญญาณป้องกันการฉ้อโกง ขณะที่ทีมเติบโตอาจเพิ่มข้อมูลติดตาม ที่เก็บในไมโครเซอร์วิสแต่ละตัวอาจเก็บแนวคิด "ลูกค้า" ที่มีความต้องการต่างกัน และความต้องการเหล่านั้นพัฒนาไปอย่างอิสระ
ถ้าไม่มีการประสานงาน "สคีมาที่สมบูรณ์แบบเดียว" จะกลายเป็นคอขวด
ระบบภายนอกมักส่ง payload ที่รู้บ้างไม่รู้บ้าง มีการซ้อนหรือไม่สอดคล้อง: อีเวนต์ webhook เมตาดาต้าพาร์ทเนอร์ แบบฟอร์ม เทเลเมทรีจากอุปกรณ์ แม้เมื่อคุณทำ normalization ชิ้นสำคัญ คุณมักอยากเก็บโครงสร้างดั้งเดิมเพื่อการตรวจสอบ การดีบัก หรือการใช้งานในอนาคต
แรงผลักดันเหล่านี้ผลักทีมให้ใช้การเก็บที่ทนต่อการเปลี่ยนแปลงได้ดี—โดยเฉพาะเมื่อต้องการความเร็วในการส่งงาน
เมื่อผลิตภัณฑ์ยังหาทิศทาง แบบข้อมูลแทบจะไม่ "เสร็จ" ฟิลด์ใหม่ปรากฏ ฟิลด์เก่ากลายเป็นทางเลือก และลูกค้าที่ต่างกันอาจต้องการข้อมูลต่างกันเล็กน้อย ฐานข้อมูลเอกสารได้รับความนิยมในช่วงเวลาเหล่านี้เพราะช่วยให้คุณพัฒนาแบบข้อมูลโดยไม่ต้องเปลี่ยนทุกการเปลี่ยนเป็นโครงการมิเกรชันฐานข้อมูล
ด้วยเอกสาร JSON การเพิ่มพร็อพเพอร์ตีใหม่อาจง่ายเพียงเขียนในระเบียนใหม่ เอกสารเดิมไม่จำเป็นต้องถูกแตะจนกว่าคุณจะตัดสินใจ backfill นั่นหมายความว่าการทดลองเล็ก ๆ—เช่น เก็บการตั้งค่าความชอบใหม่—ไม่จำเป็นต้องประสานการเปลี่ยนสคีมา หน้าต่างการปล่อย และงาน backfill เพียงแค่เริ่มเรียนรู้ได้เลย
บางครั้งคุณมีตัวแปรจริง ๆ: บัญชี "ฟรี" มีการตั้งค่าน้อยกว่า บัญชี "องค์กร" มีฟิลด์เพิ่มขึ้น หรือประเภทผลิตภัณฑ์หนึ่งต้องการแอตทริบิวต์พิเศษ ในฐานข้อมูลเอกสาร มักรับได้ที่เอกสารในคอลเลกชันเดียวมีรูปร่างต่างกัน ตราบใดที่แอปของคุณรู้วิธีตีความ
แทนที่จะบังคับทุกอย่างเข้าโครงสร้างแน่นเดียว คุณสามารถรักษา:\n
id, userId, createdAt)\n- ฟิลด์ที่เป็นตัวแปรแสดงเฉพาะเมื่อเกี่ยวข้องสคีมาที่ยืดหยุ่นไม่ได้หมายความว่า "ไม่มีข้อบังคับ" รูปแบบที่พบบ่อยคือถือว่าฟิลด์ที่ขาดคือ "ให้ใช้ค่าเริ่มต้น" แอปของคุณสามารถใช้ค่าเริ่มต้นที่สมเหตุสมผลเมื่ออ่าน (หรือกำหนดเมื่อเขียน) เพื่อให้เอกสารเก่ายังทำงานได้ถูกต้อง
ฟีเจอร์แฟลกมักเพิ่มฟิลด์ชั่วคราวและการปล่อยแบบเป็นส่วน ๆ สคีมาที่ยืดหยุ่นทำให้ปล่อยการเปลี่ยนให้กลุ่มผู้ใช้เล็ก ๆ ง่ายขึ้น เก็บสถานะพิเศษเฉพาะผู้ใช้ที่ถูกแฟลก และทำซ้ำได้เร็ว—โดยไม่ต้องติดขัดกับงานสคีมาก่อนที่จะทดสอบไอเดีย
ทีมผลิตภัณฑ์หลายทีมคิดเป็น "สิ่งที่ผู้ใช้เห็นบนจอ" หน้าโปรไฟล์ รายละเอียดคำสั่งซื้อ แดชบอร์ดโครงการ—แต่ละอย่างมักแมปไปที่วัตถุแอปเดียวที่มีรูปร่างคาดเดาได้ ฐานข้อมูลเอกสารสนับสนุนแนวคิดนั้นโดยให้คุณเก็บวัตถุนั้นเป็นเอกสาร JSON เดียว โดยมีการแปลงระหว่างโค้ดแอปและที่เก็บข้อมูลน้อยลง
กับตารางสัมพันธ์ ฟีเจอร์เดียวมักถูกแยกข้ามหลายตาราง คีย์ต่างประเทศ และตรรกะ join โครงสร้างนี้ทรงพลัง แต่เมื่อแอปเก็บข้อมูลเป็นอ็อบเจ็กต์ซ้อนอยู่แล้ว มันอาจรู้สึกเป็นพิธีมากเกินไป
ในฐานข้อมูลเอกสาร คุณมักจะ persist อ็อบเจ็กต์เกือบเหมือนต้นฉบับ:\n
user ที่ตรงกับคลาส/ไทป์ User ของคุณ\n- เอกสาร project ที่ตรงกับสเตตของ Project\n
การแปลงที่น้อยลงมักหมายถึงบักการแมปที่น้อยลงและการทำซ้ำที่เร็วขึ้นเมื่อฟิลด์เปลี่ยนข้อมูลแอปจริงไม่ค่อยแบน ที่อยู่ การตั้งค่า การแจ้งเตือน ตัวกรองที่บันทึก ธง UI—ทั้งหมดนี้มักซ้อนกัน การเก็บอ็อบเจ็กต์ซ้อนภายในเอกสารพาเรนต์ช่วยให้ค่าที่เกี่ยวข้องอยู่ใกล้กัน ซึ่งช่วยสำหรับคิวรีแบบ "หนึ่งระเบียน = หนึ่งหน้าจอ": ดึงเอกสารหนึ่งฉบับ แล้วเรนเดอร์หนึ่งวิว ลดความจำเป็นในการ join และความประหลาดใจด้านประสิทธิภาพ
เมื่อแต่ละทีมฟีเจอร์เป็นเจ้าของรูปร่างเอกสารของตน ความรับผิดชอบชัดเจนขึ้น: ทีมที่ส่งฟีเจอร์ก็ควบคุมการพัฒนาสคีมาของมัน นั่นมักทำงานได้ดีในสถาปัตยกรรมไมโครเซอร์วิสหรือโมดูลาร์ ที่การเปลี่ยนแปลงอิสระเป็นเรื่องปกติไม่ใช่ข้อยกเว้น
ฐานข้อมูลเอกสารมักเหมาะสำหรับทีมที่ปล่อยบ่อยเพราะการเพิ่มข้อมูลเล็ก ๆ ไม่จำเป็นต้องเป็นการเปลี่ยนฐานข้อมูลที่ประสานกันทั้งหมด
ถ้าผู้จัดการผลิตภัณฑ์ขอ "เพิ่มอีกแอตทริบิวต์หนึ่ง" (เช่น preferredLanguage หรือ marketingConsentSource) โมเดลเอกสารมักให้คุณเริ่มเขียนฟิลด์นั้นได้ทันที คุณไม่จำเป็นต้องจัดตารางมิเกรชัน ล็อกตาราง หรือเจรจาหน้าต่างปล่อยข้ามบริการหลายตัวเสมอไป
นั่นลดจำนวนงานที่อาจบล็อกสปรินท์: ฐานข้อมูลยังใช้งานได้ในขณะที่แอปพัฒนา
การเพิ่มฟิลด์ทางเลือกในเอกสารคล้าย JSON มักเข้ากันได้ย้อนหลัง:\n
ระบบจริงไม่ค่อยอัปเกรดไคลเอนต์ทั้งหมดพร้อมกัน คุณอาจมี:\n
รูปแบบการปรับใช้ที่ปฏิบัติได้ดูเหมือนนี้:\n
เหตุผลหนึ่งที่ทีมชอบฐานข้อมูลเอกสารคือคุณสามารถออกแบบข้อมูลตามวิธีที่แอปของคุณ อ่าน มันมากที่สุด แทนที่จะกระจายแนวคิดข้ามหลายตารางแล้วมาต่อกันทีหลัง คุณสามารถเก็บอ็อบเจ็กต์ "ทั้งชุด" (มักเป็นเอกสาร JSON) ในที่เดียว
การ denormalize หมายถึงการคัดลอกหรือฝังฟิลด์ที่เกี่ยวข้องเพื่อให้คิวรีทั่วไปตอบได้จากการอ่านเอกสารเดียว
ตัวอย่างเช่น เอกสารคำสั่งซื้ออาจรวมฟิลด์สแนปชอตลูกค้า (ชื่อ อีเมล ณ เวลาซื้อ) และอาเรย์ของรายการสินค้า การออกแบบนี้ทำให้ "แสดง 10 คำสั่งซื้อล่าสุดของฉัน" รวดเร็วและง่าย เพราะ UI ไม่ต้องดึงข้อมูลหลายครั้งเพื่อเรนเดอร์หน้า
เมื่อข้อมูลสำหรับหน้าจอหรือการตอบ API อยู่ในเอกสารเดียว คุณมักจะได้:\n
การฝังมักเป็นประโยชน์เมื่อ:\n
การอ้างอิงมักดีกว่าเมื่อ:\n
ไม่มีรูปร่างเอกสารที่ "ดีที่สุด" สากล โมเดลที่ปรับให้เหมาะกับคิวรีหนึ่งอาจทำให้อีกคิวรีช้าลง (หรือแพงขึ้นเมื่ออัปเดต) วิธีที่น่าเชื่อถือที่สุดคือเริ่มจากคิวรีจริงของคุณ—สิ่งที่แอปต้องดึงจริง ๆ—แล้วออกแบบเอกสารรอบๆ เส้นทางการอ่านเหล่านั้น และกลับมาทบทวนโมเดลเมื่อการใช้งานพัฒนา
สคีมาขณะอ่านหมายความว่าคุณไม่จำเป็นต้องนิยามทุกฟิลด์และรูปร่างตารางก่อนที่จะเก็บข้อมูล แอปของคุณ (หรือคิวรีวิเคราะห์) จะตีความโครงสร้างของแต่ละเอกสารเมื่ออ่าน แท้จริงนั้นช่วยให้คุณปล่อยฟีเจอร์ที่เพิ่ม preferredPronouns หรือ shipping.instructions ใหม่โดยไม่ต้องประสานมิเกรชันฐานข้อมูลก่อน
ทีมส่วนใหญ่ยังคงมี "รูปร่างที่คาดหวัง" อยู่ในหัว—แค่บังคับใช้น้อยลงและเลือกสรรมากขึ้น เอกสารลูกค้าฉบับหนึ่งอาจมี phone อีกฉบับไม่มี คำสั่งซื้อเก่าอาจเก็บ discountCode เป็นสตริง ในขณะที่คำสั่งซื้อใหม่เก็บเป็นอ็อบเจ็กต์ discount ที่ละเอียดกว่า
ความยืดหยุ่นไม่หมายความถึงความโกลาหล แนวทางที่ใช้ได้:\n
id, createdAt, หรือ status และจำกัดชนิดข้อมูลในฟิลด์ที่ความเสี่ยงสูง\n- การตรวจสอบที่ระดับแอป: ตรวจสอบอินพุตเมื่อเขียน (ชั้น API) และปฏิเสธหรือปรับปกติค่าที่ไม่คาดคิด\n- งาน “สุขอนามัยข้อมูล” พื้นหลัง: สแกนหาค่าผิดปกติเป็นระยะและแก้หรือปักธงไว้ความสม่ำเสมอเล็กน้อยให้ผลมาก:\n
camelCase, timestamps ใน ISO-8601)\n- ชุดฟิลด์ที่จำเป็นเล็ก ๆ ข้ามเอกสาร\n- การเวอร์ชันเอกสาร (เช่น schemaVersion: 3) เพื่อให้ผู้อ่านจัดการรูปร่างเก่าและใหม่ได้อย่างปลอดภัยเมื่อแบบเริ่มคงที่—โดยปกติหลังจากที่คุณเรียนรู้ว่าฟิลด์ใดเป็นแกนหลัก—ให้แนะนำการตรวจสอบที่เข้มงวดขึ้นรอบฟิลด์เหล่านั้นและความสัมพันธ์ที่สำคัญ เก็บฟิลด์ทางเลือกหรือฟิลด์ทดลองให้ยืดหยุ่น เพื่อให้ฐานข้อมูลยังรองรับการทำซ้ำเร็วโดยไม่ต้องมิเกรทบ่อย
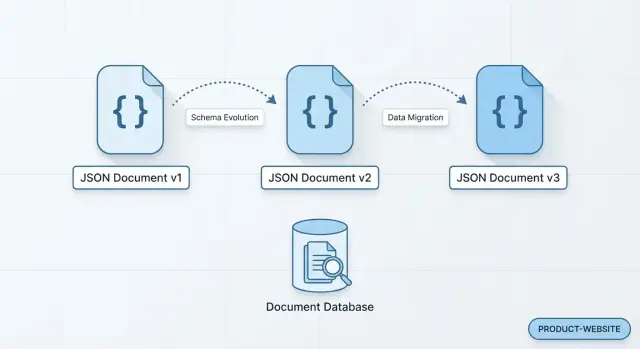
เมื่อผลิตภัณฑ์ของคุณเปลี่ยนสัปดาห์ต่อสัปดาห์ ไม่ใช่แค่รูปร่างข้อมูลปัจจุบันที่สำคัญ คุณยังต้องมีเรื่องราวที่เชื่อถือได้ว่ามันมาถึงอย่างไร ฐานข้อมูลเอกสารเหมาะกับการเก็บประวัติการเปลี่ยนเพราะเก็บระเบียนที่มีตัวเองครบซึ่งสามารถพัฒนาได้โดยไม่บังคับให้เขียนประวัติทั้งหมดใหม่
แนวทางหนึ่งคือเก็บการเปลี่ยนเป็นสตรีมเหตุการณ์: แต่ละเหตุการณ์เป็นเอกสารใหม่ที่คุณ append แทนการอัปเดตแถวเก่าเป็นต้น เช่น UserEmailChanged, PlanUpgraded, หรือ AddressAdded\n
เพราะแต่ละเหตุการณ์เป็นเอกสาร JSON คุณสามารถจับบริบทแบบเต็มในช่วงเวลานั้น—ใครทำ อะไรเป็นเหตุ และเมตาดาต้าที่คุณต้องการในภายหลัง
นิยามเหตุการณ์มักไม่คงที่ คุณอาจเพิ่ม source="mobile", experimentVariant, หรืออ็อบเจ็กต์ซ้อนใหม่อย่าง paymentRiskSignals กับการเก็บแบบเอกสาร เหตุการณ์เก่าเพียงละเว้นฟิลด์ใหม่และเหตุการณ์ใหม่รวมฟิลด์เหล่านั้นเข้าไป ผู้บริโภค (เซอร์วิส งาน) สามารถตั้งค่าเริ่มต้นเมื่อไม่มีฟิลด์ แทนการ backfill หลายล้านระเบียนย้อนหลังเพียงเพื่อเพิ่มแอตทริบิวต์เดียว
เพื่อให้ผู้บริโภคคาดเดาได้ ทีมหลายทีมใส่ schemaVersion (หรือ eventVersion) ในแต่ละเอกสาร นั่นช่วยให้การเปิดตัวแบบค่อยเป็นค่อยไป:\n
ประวัติที่ทนทานของ "สิ่งที่เกิดขึ้น" มีประโยชน์มากกว่าการตรวจสอบ ทีมวิเคราะห์สามารถสร้างสถานะใหม่ในช่วงเวลาใดก็ได้ และวิศวกรสนับสนุนสามารถสืบหาสาเหตุโดยการเล่นเหตุการณ์ซ้ำหรือดู payload ที่นำไปสู่บั๊ก ในเดือนต่อ ๆ มา นั่นช่วยให้การวิเคราะห์สาเหตุรากฐานเร็วและรายงานเชื่อถือได้มากขึ้น
ฐานข้อมูลเอกสารทำให้การเปลี่ยนง่ายขึ้น แต่ไม่ได้ตัดงานออก—มันย้ายงานออกไป ก่อนตัดสินใจ ควรชัดเจนว่าคุณแลกอะไรเพื่อแลกกับความยืดหยุ่นนั้น
ฐานข้อมูลเอกสารหลายตัวรองรับธุรกรรม แต่ธุรกรรมข้ามเอกสารอาจถูกจำกัด ช้าลง หรือแพงกว่าฐานข้อมูลเชิงสัมพันธ์—โดยเฉพาะที่สเกลสูง หากงานหลักของคุณต้องการการอัปเดตแบบ "ทั้งหมดหรือไม่มีเลย" ข้ามหลายระเบียน (เช่น อัปเดตคำสั่งซื้อ สินค้าคงคลัง และรายการบัญชีพร้อมกัน) ให้ตรวจสอบว่าฐานข้อมูลจัดการอย่างไรและมีค่าใช้จ่ายด้านประสิทธิภาพหรือความซับซ้อนเท่าใด
เพราะฟิลด์เป็นทางเลือก ทีมอาจเผลอสร้างหลาย "เวอร์ชัน" ของแนวคิดเดียวกันใน production (เช่น address.zip vs address.postalCode) ซึ่งทำลายฟีเจอร์ลงมาข้างล่างและทำให้บั๊กยากตรวจจับ
การลดความเสี่ยงปฏิบัติได้คือกำหนดสัญญาร่วมสำหรับประเภทเอกสารสำคัญ (แม้น้ำหนักเบา) และเพิ่มกฎการตรวจสอบแบบเลือกได้ในจุดที่สำคัญ เช่น สถานะการชำระเงิน ราคา หรือสิทธิ์
ถ้าเอกสารพัฒนาอย่างอิสระ คิวรีการวิเคราะห์อาจยุ่ง: นักวิเคราะห์ต้องเขียนตรรกะสำหรับชื่อฟิลด์หลายแบบและค่าที่ขาด หากทีมต้องพึ่งพาการรายงานหนัก ๆ คุณอาจต้องมีแผนเช่น:\n
การฝังข้อมูลที่เกี่ยวข้อง (เช่น สแนปชอตลูกค้าในคำสั่งซื้อ) เร่งการอ่าน แต่ก็ทำให้ข้อมูลซ้ำ เมื่อชิ้นข้อมูลที่แชร์เปลี่ยน คุณต้องตัดสินใจ: อัปเดตทุกที่ เก็บประวัติไว้ หรือยอมให้ไม่สอดคล้องชั่วคราว การตัดสินใจนี้ควรตั้งใจ ไม่เช่นนั้นคุณเสี่ยงต่อการลื่นไหลของข้อมูล
ฐานข้อมูลเอกสารเหมาะเมื่อการเปลี่ยนแปลงบ่อย แต่ให้รางวัลทีมที่ทำงานออกแบบ โมเดลการตั้งชื่อ และการตรวจสอบเป็นงานต่อเนื่อง ไม่ใช่การตั้งค่าหนเดียวจบ
ฐานข้อมูลเอกสารเก็บข้อมูลเป็นเอกสาร JSON ทำให้เหมาะเมื่อฟิลด์เป็นทางเลือก เปลี่ยนบ่อย หรือแตกต่างตามลูกค้า อุปกรณ์ หรือสายผลิตภัณฑ์ แทนที่จะบังคับทุกเรคคอร์ดให้เข้ารูปแบบตารางเดียว คุณสามารถพัฒนาแบบข้อมูลทีละน้อยในขณะที่ทีมยังเคลื่อนไหวได้
ข้อมูลสินค้าหาใช่คงที่: ขนาด วัสดุ ธงการปฏิบัติตาม ข้อเสนอพิเศษ คำอธิบายภูมิภาค และฟิลด์เฉพาะตลาดมักปรากฏขึ้นเรื่อย ๆ ด้วยข้อมูลซ้อนในเอกสาร JSON "product" สามารถเก็บฟิลด์หลัก (SKU, price) พร้อมอนุญาตแอตทริบิวต์เฉพาะหมวดหมู่โดยไม่ต้องออกแบบสคีมาใหม่เป็นสัปดาห์
โปรไฟล์เริ่มเล็กแล้วเติบโต: การตั้งค่าการแจ้งเตือน ความยินยอมทางการตลาด คำตอบ onboarding แฟลกฟีเจอร์ และสัญญาณการปรับแต่ง ในฐานข้อมูลเอกสาร ผู้ใช้แต่ละคนอาจมีชุดฟิลด์ต่างกันโดยไม่ทำลายการอ่านที่มีอยู่ ความยืดหยุ่นนี้ช่วยพัฒนารวดเร็วเมื่อการทดลองเพิ่ม/ลบฟิลด์บ่อย
เนื้อหาใน CMS สมัยใหม่ไม่ใช่แค่ "หน้า" แต่มิกซ์ของบล็อกและคอมโพเนนต์—ฮีโร่ FAQ แกลเลอรีสินค้า embeds—แต่ละอันมีโครงสร้างของตัวเอง การเก็บเพจเป็นเอกสาร JSON ให้บรรณาธิการและนักพัฒนาสามารถเพิ่มชนิดคอมโพเนนต์ใหม่โดยไม่ต้องมิเกรทเพจประวัติทั้งหมดทันที
เทเลเมทรีมักแตกต่างตามเวอร์ชันเฟิร์มแวร์ แพ็กเกจเซ็นเซอร์ หรือผู้ผลิต ฐานข้อมูลเอกสารจัดการโมเดลข้อมูลที่พัฒนาได้ดี: เหตุการณ์แต่ละอันรวมเฉพาะสิ่งที่อุปกรณ์รู้ ในขณะที่สคีมาขณะอ่านช่วยให้เครื่องมือวิเคราะห์ตีความฟิลด์เมื่อปรากฏ
ถ้าคุณกำลังตัดสินใจระหว่าง NoSQL กับ SQL นี่คือสถานการณ์ที่ฐานข้อมูลเอกสารมักช่วยให้การทำซ้ำเร็วขึ้นและมีแรงเสียดทานน้อยลง
เมื่อแบบข้อมูลยังคงนิ่งไม่ลง "ดีพอและเปลี่ยนง่าย" ดีกว่า "สมบูรณ์แบบบนกระดาษ" นิสัยปฏิบัติที่ช่วยให้คุณรักษาโมเมนตัมโดยไม่ทำให้ฐานข้อมูลเป็นลิ้นชักขยะ
เริ่มแต่ละฟีเจอร์ด้วยการเขียนคิวรีที่คาดว่าจะเกิดขึ้นจริงใน production: หน้าจอที่เรนเดอร์ การตอบ API ที่ส่ง และการอัปเดตที่ทำบ่อยที่สุด
ถ้าการกระทำของผู้ใช้ต้องการ "order + items + shipping address" บ่อย ๆ ให้โมเดลเอกสารที่ให้การอ่านนั้นโดยไม่ต้องดึงเพิ่ม ถ้าอีกการกระทำต้องการ "all orders by status" ให้แน่ใจว่าคุณสามารถคิวรีหรือทำดัชนีสำหรับเส้นทางนั้นได้
การฝัง (nesting) ดีเมื่อ:\n
คุณสามารถผสม: ฝังสแนปชอตเพื่อความเร็วในการอ่าน และเก็บการอ้างอิงถึงแหล่งความจริงสำหรับการอัปเดต
แม้จะยืดหยุ่น ให้เพิ่มกฎน้ำหนักเบาสำหรับฟิลด์ที่คุณพึ่งพา (ชนิด ข้อบังคับ ID สถานะที่อนุญาต) ใส่ schemaVersion (หรือ docVersion) เพื่อให้แอปจัดการเอกสารเก่าได้อย่างสุภาพและมิเกรตทีละน้อยเมื่อเวลาผ่านไป
มองมิเกรชันเป็นการบำรุงรักษารายงวด ไม่ใช่เหตุการณ์ครั้งเดียว เมื่อโมเดลโตขึ้น ให้จัดตาราง backfill และ cleanup เล็ก ๆ (ฟิลด์ที่ไม่ได้ใช้ เปลี่ยนชื่อคีย์ สแนปชอตที่ denormalize) และวัดผลก่อน/หลัง เช็กลิสต์ง่าย ๆ และสคริปต์มิเกรชันน้ำหนักเบาช่วยได้มาก
การเลือกฐานข้อมูลเอกสารหรือเชิงสัมพันธ์ไม่ใช่เรื่อง "อันไหนดีกว่า" แต่เป็นเรื่องประเภทการเปลี่ยนที่ผลิตภัณฑ์ของคุณประสบบ่อยที่สุด
ฐานข้อมูลเอกสารเหมาะเมื่อรูปร่างข้อมูลเปลี่ยนบ่อย ระเบียนต่าง ๆ อาจมีฟิลด์ต่างกัน หรือทีมต้องปล่อยฟีเจอร์โดยไม่ต้องประสานมิเกรชาทุกสปรินท์
มันยังเหมาะเมื่อแอปของคุณทำงานกับ "อ็อบเจ็กต์ทั้งชิ้น" เช่น คำสั่งซื้อ (ข้อมูลลูกค้า + รายการ + หมายเหตุการส่ง) หรือโปรไฟล์ผู้ใช้ (การตั้งค่า + ความชอบ + ข้อมูลอุปกรณ์) ที่เก็บรวมกันเป็นเอกสาร JSON
ฐานข้อมูลเชิงสัมพันธ์โดดเด่นเมื่อคุณต้องการ:\n
ถ้างานของทีมเป็นการปรับแต่งคิวรีข้ามตารางและการวิเคราะห์ SQL มักเป็นทางเลือกที่ง่ายกว่าในระยะยาว
หลายทีมใช้ทั้งสอง: relational สำหรับ "ระบบบันทึกหลัก" (billing, inventory, entitlements) และ document สำหรับมุมมองที่พัฒนาเร็วหรืออ่านเร็ว (profiles, metadata คอนเทนต์, แคตาล็อกสินค้า) ในไมโครเซอร์วิสแต่ละตัวสามารถเลือกสตอเรจที่เหมาะกับขอบเขตของมัน
นอกจากนี้ ไฮบริดสามารถอยู่ภายในฐานข้อมูลเชิงสัมพันธ์ได้ เช่น PostgreSQL สามารถเก็บฟิลด์กึ่งมีโครงสร้างด้วย JSON/JSONB ควบคู่กับคอลัมน์ที่มีชนิดชัดเจน—มีประโยชน์เมื่อต้องการความสอดคล้องเชิงธุรกรรมและที่เก็บคุณสมบัติที่เปลี่ยนได้
ถ้าสคีมาของคุณเปลี่ยนเป็นประจำ คอขวดมักอยู่ที่วงจร end-to-end: อัปเดตโมเดล API UI มิเกรชัน (ถ้ามี) และการปล่อยอย่างปลอดภัย Koder.ai ถูกออกแบบมาสำหรับการทำซ้ำแบบนั้น คุณสามารถอธิบายฟีเจอร์และรูปร่างข้อมูลในแชท สร้างงานเว็บ/แบ็กเอนด์/โมบายที่ทำงานได้ แล้วปรับปรุงเมื่อข้อกำหนดเปลี่ยน
ในทางปฏิบัติ ทีมมักเริ่มด้วยคอร์เชิงสัมพันธ์ (สแตกแบ็กเอนด์ของ Koder.ai คือ Go กับ PostgreSQL) และใช้รูปแบบแบบเอกสารเมื่อเหมาะสม (เช่น JSONB สำหรับแอตทริบิวต์ยืดหยุ่นหรือ payload เหตุการณ์) ฟีเจอร์ snapshots และ rollback ของ Koder.ai ก็ช่วยเมื่อรูปร่างทดลองต้องถูกย้อนกลับอย่างรวดเร็ว
รันการประเมินสั้น ๆ ก่อนผูกมัด:\n
ฐานข้อมูลแบบเอกสารเก็บแต่ละระเบียนเป็นเอกสารที่มีตัวเองครบ (มักเป็นรูปแบบคล้าย JSON รวมถึงอ็อบเจ็กต์ซ้อนและอาเรย์) แทนที่จะกระจายวัตถุธุรกิจหนึ่งชิ้นข้ามหลายตาราง คุณจะอ่านและเขียนวัตถุทั้งหมดในหนึ่งการดำเนินการได้บ่อยครั้ง โดยปกติภายในคอลเลกชัน เช่น users, orders.
ในผลิตภัณฑ์ที่เคลื่อนไหวเร็ว แอตทริบิวต์ใหม่ ๆ มักปรากฏขึ้นอย่างต่อเนื่อง (การตั้งค่าความชอบ เมตาดาต้าการเรียกเก็บเงิน ธงยินยอม ฟิลด์สำหรับการทดลอง) สคีมาที่ยืดหยุ่นให้คุณเริ่มเขียนฟิลด์ใหม่ได้ทันที ทำให้เอกสารเก่าอยู่เหมือนเดิม และสามารถ backfill ภายหลังได้—ดังนั้นการเปลี่ยนเล็ก ๆ จะไม่กลายเป็นโครงการมิเกรชันขนาดใหญ่
ไม่จำเป็นต้องไม่มีสคีมาเลย ทีมส่วนใหญ่ยังคงมี “รูปร่างที่คาดหวัง” แต่การบังคับใช้อาจย้ายไปที่:
แบบนี้ช่วยรักษาความยืดหยุ่นในขณะเดียวกันก็ลดเอกสารที่ไม่สอดคล้องกัน
ปฏิบัติตามแนวทางที่ฟิลด์ใหม่เป็นการเพิ่มและไม่บังคับ:
วิธีนี้รองรับเวอร์ชันข้อมูลผสมใน production โดยไม่ต้องปิดระบบเพื่อมิเกรชัน
ออกแบบจากการอ่านที่เกิดขึ้นบ่อย: ถ้าหน้าจอหรือ API ต้องการ “order + items + shipping address” ให้เก็บข้อมูลเหล่านั้นร่วมกันในเอกสารเดียวเมื่อเป็นไปได้ ซึ่งจะลด round trip และหลีกเลี่ยงการประกอบผลลัพธ์ด้วย join จำนวนมาก ทำให้ความหน่วงในการอ่านลดลงในเส้นทางที่เน้นอ่าน
ใช้การฝัง (embedding) เมื่อข้อมูลลูกมักถูกอ่านพร้อมกับพาเรนต์และมีขนาดจำกัด (เช่น สูงสุด 20 รายการ) ใช้การอ้างอิงเมื่อข้อมูลที่เกี่ยวข้องมีขนาดใหญ่/ไม่จำกัด ถูกแชร์ระหว่างพาเรนต์หลายตัว หรือเปลี่ยนบ่อย
คุณสามารถผสมทั้งสอง: ฝัง snapshot เพื่อความเร็วในการอ่าน และเก็บการอ้างอิงไปยังแหล่งความจริงเพื่อการอัปเดต
ช่วยให้การปรับใช้และการทำซ้ำเร็วขึ้นโดยทำให้การเพิ่มฟิลด์เป็นแบบที่เข้ากันได้ย้อนหลังได้มากขึ้น:
ประโยชน์ชัดเจนเมื่อมีหลายบริการหรือแอปมือถือที่เวอร์ชันเก่ายังใช้งานอยู่
ใส่เกราะป้องกันเบา ๆ เช่น:
id, createdAt, status)แนวทางทั่วไปคือเก็บเหตุการณ์แบบ append-only (แต่ละการเปลี่ยนเป็นเอกสารใหม่) และใส่เวอร์ชัน (eventVersion/schemaVersion) ในแต่ละเอกสาร ฟิลด์ใหม่สามารถถูกเพิ่มในเหตุการณ์อนาคตโดยไม่ต้องเขียนประวัติซ้ำ ผู้บริโภคสามารถอ่านหลายเวอร์ชันระหว่างการเปิดตัวแบบค่อยเป็นค่อยไป
ข้อแลกเปลี่ยนสำคัญได้แก่:
หลายทีมใช้วิธีผสม: relational สำหรับระบบหลักที่ต้องความถูกต้องเข้มงวด และ document สำหรับมุมมองที่พัฒนาเร็วหรือปรับแต่งสำหรับการอ่าน
camelCase, timestamps แบบ ISO-8601)schemaVersion/docVersionขั้นตอนเหล่านี้ช่วยป้องกันการลื่นไหลของข้อมูล เช่น address.zip vs address.postalCode