26 พ.ย. 2568·1 นาที
ทำไมฐานข้อมูลกราฟโดดเด่นเรื่องความสัมพันธ์—แต่ไม่ใช่ทุกอย่าง
ฐานข้อมูลกราฟโดดเด่นเมื่อการเชื่อมโยงเป็นตัวขับคำตอบ เรียนรู้กรณีที่เหมาะสม ข้อแลกเปลี่ยน และเมื่อใดที่ฐานข้อมูลเชิงสัมพันธ์หรือเอกสารเหมาะกว่า
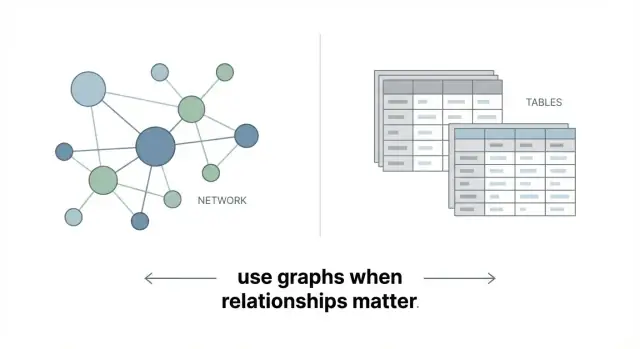
ฐานข้อมูลกราฟโดดเด่นเมื่อการเชื่อมโยงเป็นตัวขับคำตอบ เรียนรู้กรณีที่เหมาะสม ข้อแลกเปลี่ยน และเมื่อใดที่ฐานข้อมูลเชิงสัมพันธ์หรือเอกสารเหมาะกว่า
ฐานข้อมูลกราฟเก็บข้อมูลเป็นเครือข่ายแทนที่จะเป็นชุดตาราง แนวคิดสำคัญง่าย ๆ คือ:
นั่นแหละ: ฐานข้อมูลกราฟถูกออกแบบมาเพื่อแทนข้อมูลที่เชื่อมต่อกันโดยตรง
ในฐานข้อมูลกราฟ ความสัมพันธ์ไม่ใช่เรื่องรอง—มันถูกเก็บเป็นวัตถุที่ถามได้จริง ความสัมพันธ์สามารถมีคุณสมบัติของตัวมันเอง (เช่น ความสัมพันธ์ PURCHASED อาจเก็บวันที่ ช่องทาง และส่วนลด) และคุณสามารถเดินจากโหนดหนึ่งไปยังอีกโหนดได้อย่างมีประสิทธิภาพ
เรื่องนี้สำคัญเพราะคำถามทางธุรกิจหลายอย่างโดยธรรมชาติเกี่ยวกับเส้นทางและการเชื่อมต่อ: “ใครเชื่อมกับใคร?”, “สิ่งนี้ห่างกันกี่ก้าว?”, หรือ “ลิงก์ร่วมระหว่างสองสิ่งนี้คืออะไร?”
ฐานข้อมูลเชิงสัมพันธ์ทำได้ยอดเยี่ยมกับเรคอร์ดที่มีโครงสร้าง: ลูกค้า, คำสั่งซื้อ, ใบแจ้งหนี้ ความสัมพันธ์ก็มีในนั้นเช่นกัน แต่โดยปกติจะแสดงแบบทางอ้อมผ่าน foreign keys และการเชื่อมหลายขั้นมักหมายถึงการเขียน JOIN ข้ามหลายตาราง
กราฟเก็บการเชื่อมต่อไว้ใกล้กับข้อมูล ดังนั้นการสำรวจความสัมพันธ์หลายขั้นจึงมักง่ายกว่าในการออกแบบและสืบค้น
ฐานข้อมูลกราฟยอดเยี่ยมเมื่อ ความสัมพันธ์เป็นสิ่งสำคัญ—คำแนะนำ, วงการทุจริต, แผนผังพึ่งพา, กราฟความรู้ แต่ไม่ได้หมายความว่าจะดีกว่าเสมอไปสำหรับรายงานง่าย ๆ ยอดรวม หรืองานที่เป็นตารางมาก ๆ เป้าหมายไม่ใช่การแทนที่ทุกฐานข้อมูล แต่คือการใช้กราฟเมื่อการเชื่อมต่อสร้างมูลค่า
คำถามทางธุรกิจส่วนใหญ่ไม่ได้เกี่ยวกับเรคอร์ดเดี่ยว ๆ เท่านั้น—แต่เกี่ยวกับการเชื่อมต่อของสิ่งต่าง ๆ
ลูกค้าไม่ใช่แค่แถวข้อมูล; เขาเชื่อมโยงกับคำสั่งซื้อ, อุปกรณ์, ที่อยู่, ตั๋วสนับสนุน, การแนะนำ และบางครั้งกับลูกค้ารายอื่นด้วย ธุรกรรมก็ไม่ได้เป็นแค่เหตุการณ์เดียว; มันเชื่อมกับผู้ขาย, วิธีการชำระเงิน, ตำแหน่ง, ช่วงเวลา, และชุดกิจกรรมที่เกี่ยวข้อง เมื่อคำถามคือ “ใคร/อะไรเชื่อมกับอะไร และอย่างไร?” ข้อมูลความสัมพันธ์จะเป็นตัวเอก
ฐานข้อมูลกราฟถูกออกแบบมาสำหรับการสืบผ่าน: คุณเริ่มที่โหนดหนึ่งแล้ว “เดิน” เครือข่ายโดยตามเส้นเชื่อม
แทนที่จะ JOIN ตารางซ้ำ ๆ คุณบอกเส้นทางที่คุณสนใจ: Customer → Device → Login → IP Address → Other Customers กรอบแบบก้าวต่อก้าวนี้สอดคล้องกับวิธีที่คนสอบสวนการทุจริต ติดตามการพึ่งพา หรืออธิบายคำแนะนำ
ความต่างที่แท้จริงปรากฏเมื่อคุณต้องการหลายก้าว (สอง สาม ห้าก้าว) และคุณไม่รู้ล่วงหน้าว่าการเชื่อมที่น่าสนใจจะปรากฏที่ไหน
ในโมเดลเชิงสัมพันธ์ คำถามหลายก้าวมักกลายเป็นการต่อโซ่ JOIN ยาวพร้อมตรรกะพิเศษเพื่อหลีกเลี่ยงการซ้ำและควบคุมความยาวเส้นทาง ในกราฟ “หาทุกเส้นทางสูงสุด N ก้าว” เป็นรูปแบบปกติที่อ่านได้ง่าย—โดยเฉพาะในโมเดล property graph ที่ใช้กันแพร่หลาย
เส้นเชื่อมไม่ใช่แค่เส้น; มันสามารถบรรทุกข้อมูลได้:
คุณสมบัติเหล่านี้ช่วยให้คุณถามคำถามได้ชัดเจนขึ้น: “เชื่อมภายใน 30 วันที่ผ่านมา”, “ความผูกพันที่แข็งแกร่งสุด”, หรือ “เส้นทางที่มีธุรกรรมความเสี่ยงสูง” — โดยไม่ต้องยัดทุกอย่างลงในตารางค้นหาแยกต่างหาก
ฐานข้อมูลกราฟโดดเด่นเมื่อคำถามของคุณอาศัยการเชื่อมต่อ: “ใครเชื่อมกับใคร ผ่านอะไร และห่างกันกี่ก้าว?” หากมูลค่าของข้อมูลคุณอยู่ที่ความสัมพันธ์ (ไม่ใช่แค่แถวของแอตทริบิวต์) โมเดลกราฟจะทำให้การออกแบบข้อมูลและการสืบค้นเป็นธรรมชาติมากขึ้น
ทุกอย่างที่มีรูปแบบเป็นเครือข่าย—เพื่อน, ผู้ติดตาม, เพื่อนร่วมงาน, ทีม, การแนะนำ—สามารถแม็ปเป็นโหนดและความสัมพันธ์ คำถามทั่วไปเช่น “การเชื่อมต่อร่วมกัน”, “เส้นทางสั้นที่สุดไปหาคนนี้”, หรือ “ใครเชื่อมสองกลุ่มนี้?” มักจะกลายเป็นคำถามที่ยากหรือช้าเมื่อบังคับใส่ในตาราง JOIN หลายอัน
เครื่องมือแนะนำมักพึ่งพาการเชื่อมต่อหลายขั้น: user → item → category → รายการที่คล้ายกัน → ผู้ใช้คนอื่น ๆ ฐานข้อมูลกราฟเหมาะกับคำถามเช่น “คนที่ชอบ X ก็ชอบ Y ด้วยไหม”, “รายการที่มักถูกดูคู่กัน”, และ “หาสินค้าที่เชื่อมโดยคุณสมบัติหรือพฤติกรรมร่วม” โดยเฉพาะเมื่อสัญญาณหลากหลายและคุณเพิ่มความสัมพันธ์ชนิดใหม่บ่อย ๆ
กราฟการตรวจจับการทุจริตทำงานได้ดีเพราะพฤติกรรมที่น่าสงสัยมักไม่เป็นเหตุการณ์โดดเดี่ยว บัญชี, อุปกรณ์, ธุรกรรม, หมายเลขโทรศัพท์, อีเมล และที่อยู่ก่อตัวเป็นใยของตัวบ่งชี้ร่วม กราฟทำให้ง่ายขึ้นที่จะจับวง, รูปแบบซ้ำ, และลิงก์ทางอ้อม (เช่น สองบัญชี “ไม่เกี่ยวข้อง” แต่ใช้เดียวกันผ่านโซ่กิจกรรม)
สำหรับบริการ, โฮสต์, API, การเรียก และความเป็นเจ้าของ คำถามหลักคือการพึ่งพา: “อะไรจะพังถ้านี่เปลี่ยน?” กราฟรองรับการวิเคราะห์ผลกระทบ, สำรวจสาเหตุราก, และคำถาม “รัศมีการกระจายผลกระทบ” เมื่อระบบเชื่อมโยงกัน
กราฟความรู้เชื่อมเอนทิตี้ (คน, บริษัท, สินค้า, เอกสาร) กับข้อเท็จจริงและการอ้างอิง ช่วยในการค้นหา, การรวมเอนทิตี้, และการติดตามว่า “ทำไม” ข้อเท็จจริงถูกยืนยัน (provenance) ข้ามแหล่งที่เชื่อมโยงหลายแห่ง
ฐานข้อมูลกราฟเหมาะเมื่อตั้งคำถามจริง ๆ ว่าใครเชื่อมกับใคร ผ่านเส้นทางใด และมีรูปแบบซ้ำแบบไหน แทนที่จะ JOIN ตารางซ้ำ คุณถามคำถามความสัมพันธ์โดยตรงและคิวรียังคงอ่านได้เมื่อเครือข่ายเติบโตขึ้น
คำถามทั่วไป:
นี่ใช้ได้กับฝ่ายสนับสนุนลูกค้า (“ทำไมเราถึงแนะนำสิ่งนี้?”), ฝ่ายปฏิบัติตามข้อกำหนด (“แสดงโซ่ของกรรมสิทธิ์”), และการสอบสวน (“สิ่งนี้แพร่กระจายอย่างไร?”)
กราฟช่วยให้คุณเห็นกลุ่มตามการเชื่อมต่อ:
คุณสามารถใช้เพื่อแบ่งกลุ่มผู้ใช้, หาทีมทุจริต, หรือเข้าใจว่าสินค้าถูกซื้อร่วมกันอย่างไร กุญแจคือ “กลุ่ม” ถูกกำหนดโดยการเชื่อมต่อ ไม่ใช่คอลัมน์เดี่ยว
บางครั้งคำถามไม่ใช่แค่ “ใครเชื่อม” แต่เป็น “ใครสำคัญที่สุด” ในเว็บ:
โหนดศูนย์กลางบ่อยครั้งชี้ไปยังผู้มีอิทธิพล โครงสร้างพื้นฐานสำคัญ หรือคอขวดที่ควรติดตาม
กราฟเหมาะกับการค้นหารูปร่างที่ซ้ำได้:
ใน Cypher (ภาษาสืบค้นกราฟยอดนิยม) รูปแบบสามเหลี่ยมอาจดูแบบนี้:
MATCH (a)-[:KNOWS]->(b)-[:KNOWS]->(c)-[:KNOWS]->(a)
RETURN a,b,c
แม้คุณจะไม่เขียน Cypher ด้วยตัวเอง นี่แสดงว่าทำไมกราฟเข้าถึงได้ง่าย: คิวรีสะท้อนภาพในหัวคุณ
ฐานข้อมูลเชิงสัมพันธ์ดีในสิ่งที่มันสร้างมา: ธุรกรรมและเรคอร์ดที่มีโครงสร้าง หากข้อมูลของคุณเข้ากันได้ดีกับตาราง (ลูกค้า, คำสั่งซื้อ, ใบแจ้งหนี้) และคุณดึงข้อมูลโดย ID, ตัวกรอง, และการรวบยอดเป็นหลัก ระบบเชิงสัมพันธ์มักเป็นทางเลือกที่เรียบง่ายและปลอดภัยกว่า
JOIN ใช้ได้เมื่อเป็นครั้งคราวและตื้น ปัญหาเกิดเมื่องานสำคัญของคุณต้องการ JOIN หลายชั้น บ่อยครั้ง ข้ามหลายตาราง
ตัวอย่าง:
ใน SQL สิ่งเหล่านี้อาจกลายเป็นคิวรียาวพร้อม self-join ซ้ำ ๆ และตรรกะซับซ้อน ทำให้ยากต่อการจูนเมื่อความลึกของความสัมพันธ์เพิ่มขึ้น
ฐานข้อมูลกราฟเก็บความสัมพันธ์อย่างชัดเจน ดังนั้นการสืบผ่านหลายขั้นจึงเป็นการดำเนินการที่เป็นธรรมชาติ แทนที่จะประกอบตารางเมื่อตอนรันคิวรี คุณเดินผ่านโหนดและขอบที่เชื่อมต่อ
นั่นมักหมายถึง:
ถ้าทีมของคุณมักถาม คำถามหลายก้าว—“เชื่อมกับ”, “ผ่าน”, “ในเครือข่ายเดียวกัน”, “ภายใน N ก้าว”—ก็ควรพิจารณาฐานข้อมูลกราฟ
ถ้งานหลักของคุณคือ ธุรกรรมปริมาณสูง, สคีมาที่เข้มงวด, รายงาน และ JOIN ที่ตรงไปตรงมา SQL มักเป็นค่าเริ่มต้นที่ดีกว่า หลายระบบจริงใช้ทั้งสองอย่าง; ดูข้อความเกี่ยวกับโครงสร้างสถาปัตยกรรมการใช้กราฟควบคู่กับฐานข้อมูลอื่น ๆ (เช่น หมายเหตุเส้นทางภายใน)
ฐานข้อมูลกราฟเก็บข้อมูลเป็น โหนด (เอนทิตี้) และ ความสัมพันธ์ (การเชื่อมต่อ) โดยทั้งสองสามารถมี คุณสมบัติ ได้ ระบบถูกออกแบบมาสำหรับคำถามเช่น “A เชื่อมต่อกับ B อย่างไร?” หรือ “ใครอยู่ห่างกัน N ก้าว?” มากกว่าการรายงานแบบตารางเป็นหลัก
เพราะความสัมพันธ์ถูกเก็บเป็นวัตถุที่ถามได้จริง (ไม่ใช่แค่ค่า foreign-key) คุณสามารถเดินตามหลายขั้น (multiple hops) ได้อย่างมีประสิทธิภาพและแนบคุณสมบัติให้กับความสัมพันธ์เอง (เช่น date, amount, risk_score) ซึ่งทำให้การถามคำถามที่เน้นการเชื่อมโยงง่ายขึ้นทั้งในการออกแบบและการสืบค้น
ฐานข้อมูลเชิงสัมพันธ์มักเก็บความสัมพันธ์แบบทางอ้อม (foreign keys) และมักต้องใช้ JOIN หลายครั้งสำหรับคำถามที่มีหลายขั้น ในขณะที่ฐานข้อมูลกราฟเก็บการเชื่อมต่อไว้ใกล้ข้อมูล ทำให้การสืบค้นที่มีความลึกเปลี่ยนผ่านเป็นแบบแสดงเส้นทางได้โดยตรงและอ่านง่ายกว่า
ใช้ฐานข้อมูลกราฟเมื่อคำถามหลักของคุณเกี่ยวกับ เส้นทาง, ย่านเครือข่าย และรูปแบบ เช่น:
คำถามที่มักเหมาะกับกราฟ ได้แก่:
มักไม่ใช่เครื่องมือที่เหมาะเมื่อโหลดงานของคุณเป็น:
ในกรณีเหล่านี้ ระบบเชิงสัมพันธ์หรือระบบวิเคราะห์มักจะเรียบง่ายและถูกกว่า
ให้ขอบความสัมพันธ์เป็น edge เมื่อมันเชื่อมสองเอนทิตี้และอาจมีคุณสมบัติของตัวมันเอง (เวลา, บทบาท, น้ำหนัก) ทำเป็น node เมื่อมันเป็นเหตุการณ์หรือเอนทิตี้ที่มีหลายแอตทริบิวต์และเชื่อมโยงไปยังหลายฝ่าย (เช่น Order หรือ เหตุการณ์ Login ที่มีรายละเอียดและเชื่อมหลายเอนทิตี้)
ข้อแลกเปลี่ยนที่ควรรู้คือ:
แนวปฏิบัติที่ดีคือใช้กราฟเมื่อความสัมพันธ์เป็นผลิตภัณฑ์ แล้วเก็บระบบเดิมไว้สำหรับการรายงานและการวิเคราะห์แบบตาราง
Property graph ให้ทั้งโหนดและความสัมพันธ์มีคุณสมบัติ (key–value) เหมาะกับการออกแบบข้อมูลรอบแอปพลิเคชัน ในขณะที่ RDF แทนความรู้ด้วย ทริปเปิล (subject–predicate–object) เหมาะกับพจนานุกรมร่วมและการเชื่อมข้อมูลข้ามระบบซึ่งอาจทำให้รายละเอียดความสัมพันธ์ถูกเลื่อนไปเป็นโหนด/ทริปเปิลเพิ่มเติม
เลือกตามว่าคุณต้องการคุณสมบัติความสัมพันธ์แบบแอป (property graph) หรือการนิยามความหมายร่วมกันแบบสากล (RDF/SPARQL)
เก็บระบบหลักไว้ที่ SQL (หรือที่เก็บข้อมูลหลัก) แล้วฉายมุมมองความสัมพันธ์ไปยังกราฟเพื่อฟีเจอร์ที่ชัดเจน เช่น คำแนะนำ, การตรวจจับความเสี่ยง, การรวมตัวตน ซิงค์ด้วยแบบแบตช์หรือสตรีม แล้ววัดผลก่อนขยายใช้งาน