05 มิ.ย. 2568·4 นาที
วิธีสร้างเว็บแอปเพื่อติดตามคะแนนสุขภาพการยอมรับใช้งานลูกค้า
เรียนรู้วิธีสร้างเว็บแอปที่ติดตามการใช้งานสินค้า คำนวณคะแนนสุขภาพการยอมรับใช้งาน และแจ้งเตือนทีมเมื่อมีความเสี่ยง—รวมแดชบอร์ด โมเดลข้อมูล และคำแนะนำ
กำหนดเป้าหมายและสัญญาณการยอมรับใช้งาน (Adoption Signals)
ก่อนสร้างคะแนนสุขภาพการใช้งานลูกค้า ให้ตัดสินใจว่าคะแนนนั้นจะ ช่วยธุรกิจทำอะไร คะแนนที่ออกแบบมาเพื่อส่งการแจ้งเตือนความเสี่ยงการยกเลิกจะแตกต่างจากคะแนนที่ต้องการชี้นำการเริ่มใช้งาน การฝึกอบรมลูกค้า หรือการปรับปรุงผลิตภัณฑ์
กำหนดความหมายของ “การยอมรับใช้งาน” สำหรับผลิตภัณฑ์คุณ
การยอมรับใช้งานไม่ใช่แค่ “ล็อกอินล่าสุด” จดพฤติกรรมไม่กี่อย่างที่บ่งชี้ว่าลูกค้าได้รับคุณค่า:
- Activation: ช่วงเวลาครั้งแรกที่ผู้ใช้บรรลุผลลัพธ์ที่มีความหมาย (เช่น “เชิญเพื่อนร่วมทีม”, “เชื่อมต่อแหล่งข้อมูล”, “เผยแพร่รายงาน”)
- Core actions: พฤติกรรมที่ทำซ้ำได้และมีสัญญาณชัดว่ามักเกิดกับบัญชีที่ประสบความสำเร็จ (เช่น การส่งออกสัปดาห์ละครั้ง, การรันออโตเมชัน, แดชบอร์ดที่มีผู้ใช้หลายคนดู)
- Retention: การใช้งานอย่างต่อเนื่องในความถี่ที่เหมาะสมกับผลิตภัณฑ์ของคุณ (รายวัน รายสัปดาห์ รายเดือน) โดยควรมีผู้ใช้มากกว่าหนึ่งคนในบัญชี
สิ่งเหล่านี้จะเป็นสัญญาณการยอมรับใช้งานเริ่มต้นสำหรับการวิเคราะห์การใช้งานฟีเจอร์และการวิเคราะห์โคฮอร์ตภายหลัง
ระบุการตัดสินใจที่แอปของคุณควรสนับสนุน
ชัดเจนเกี่ยวกับสิ่งที่จะเกิดขึ้นเมื่อคะแนนเปลี่ยนแปลง:
- ใครจะได้รับการแจ้งเมื่อบัญชีตกต่ำกว่าค่าที่กำหนด?\n- ควรเริ่ม playbook อะไร (ติดต่อ, ฝึกอบรม, ตรวจสอบการสนับสนุน)?\n- ข้อมูลเชิงลึกใดที่ควรนำมาประกอบการติดตามการยอมรับใช้งาน (จุดที่มี摩擦, ฟีเจอร์ที่ใช้น้อย, เวลาไปถึงคุณค่า)?
ถ้าคุณตั้งชื่อการตัดสินใจไม่ได ้ อย่าติดตามเมตริกนั้นตอนนี้
ระบุผู้ใช้ บทบาท และช่วงเวลา
ชัดเจนว่าใครจะใช้แดชบอร์ดความสำเร็จลูกค้า:
- ผู้จัดการ CS ต้องการการจัดลำดับความสำคัญและบริบทของบัญชี
- ทีมผลิตภัณฑ์ ต้องการรูปแบบ โคฮอร์ต และการเคลื่อนไหวในระดับฟีเจอร์
- การสนับสนุน ต้องการกิจกรรมล่าสุดที่เกี่ยวข้องกับตั๋วและเหตุการณ์
- ผู้นำทีม ต้องการรายงานสรุปที่เข้าใจง่ายและแนวโน้ม
เลือกระยะเวลามาตรฐาน—7/30/90 วันที่ผ่านมา—และพิจารณา stage ของ lifecycle (ทดลองใช้งาน, กำลังเริ่มต้น, สถานะคงที่, ต่ออายุ) นี่ช่วยหลีกเลี่ยงการเปรียบเทียบบัญชีใหม่กับบัญชีที่โตแล้ว
กำหนดเกณฑ์ความสำเร็จ
กำหนด “เสร็จ” สำหรับโมเดลคะแนนของคุณ:
- ความแม่นยำ: ทำนายความเสี่ยงและสัญญาณการขยายได้ดีกว่าวิธีปัจจุบันหรือไม่
- ความสามารถในการอธิบาย: ตัวแทน CSM อธิบาย ทำไม คะแนนสูง/ต่ำในหนึ่งนาทีได้หรือไม่
- ความง่ายในการใช้: ประหยัดเวลาและขับเคลื่อนการกระทำที่ต่อเนื่องหรือไม่
เป้าหมายเหล่านี้กำหนดทุกอย่างถัดไป: การติดตามเหตุการณ์ ตรรกะการให้คะแนน และเวิร์กโฟลว์ที่คุณสร้างรอบคะแนน
เลือกเมตริกสำหรับคะแนนสุขภาพของคุณ
การเลือกเมตริกคือจุดที่คะแนนจะกลายเป็นสัญญาณที่มีประโยชน์หรือเป็นตัวเลขที่มีเสียงรบกวน พยายามเลือกตัวชี้วัดจำนวนน้อยที่สะท้อนการยอมรับใช้งานจริง — ไม่ใช่แค่อัตรากิจกรรม
เริ่มจากสัญญาณการยอมรับใช้งานของผลิตภัณฑ์
เลือกเมตริกที่แสดงว่าผู้ใช้ได้รับคุณค่าอย่างสม่ำเสมอ:
- การล็อกอิน / ผู้ใช้ที่ใช้งาน เช่น weekly active users (WAU) และแนวโน้มใน 4–8 สัปดาห์ที่ผ่านมา
- Active days: จำนวนวันที่แตกต่างกันที่บัญชีใช้งานในสัปดาห์/เดือน (ช่วยหลีกเลี่ยงการเข้าใช้งานครั้งเดียวยาวๆ ที่ทำให้เข้าใจผิด)
- ความลึกของฟีเจอร์: การใช้งานฟีเจอร์ที่ให้คุณค่า (การกระทำที่สัมพันธ์กับความสำเร็จ) ไม่ใช่ทุกครั้งที่กดปุ่ม
- การเชื่อมต่ออินทิเกรชัน: โดยเฉพาะถ้าการเชื่อมต่อเพิ่มค่า switching cost หรือเปิดกระบวนงานสำคัญ
- การใช้ที่นั่ง (seat utilization): เปอร์เซ็นต์ที่นั่งที่ซื้อที่ถูกเชิญ ใช้งาน และมีการใช้งานจริง
เก็บรายการให้กระชับ ถ้าคุณอธิบายได้ว่าทำไมเมตริกสำคัญในหนึ่งประโยค นั่นคือเมตริกหลัก
เพิ่มบริบทธุรกิจ (เพื่อไม่ให้คะแนนไม่เป็นธรรม)
การตีความการยอมรับใช้งานต้องมีบริบท ทีม 3 คนจะมีพฤติกรรมต่างจากการเปิดตัว 500 ที่นั่ง
สัญญาณบริบททั่วไป:
- ระดับแผน และสิทธิ์การใช้งานฟีเจอร์
- ขนาดสัญญา / ช่วง ARR
- ช่วง lifecycle: ทดลองใช้งาน เทียบกับชำระเงินใหม่ หรือใกล้ต่ออายุ
สิ่งเหล่านี้ไม่จำเป็นต้อง “เพิ่มคะแนน” แต่ช่วยตั้งความคาดหวังและเกณฑ์ที่สมจริงตามเซ็กเมนต์
ตัดสินใจตัวชี้วัดแบบนำหน้า vs. ตามหลัง
คะแนนที่มีประโยชน์ผสม:
- ตัวชี้วัดนำหน้า (predict future success): การเพิ่มขึ้นของ active days, การเสร็จสิ้น onboarding, การเชื่อมต่ออินทิเกรชันครั้งแรก
- ตัวชี้วัดตามหลัง (confirm outcomes): การต่ออายุ สัญญาณการขยาย การเก็บรักษาระยะยาว
หลีกเลี่ยงการให้ค่าน้ำหนักมากเกินไปกับเมตริกตามหลัง เพราะมันบอกสิ่งที่เกิดขึ้นไปแล้ว
ทางเลือก: ป้อนข้อมูลเชิงคุณภาพ (ใช้อย่างระมัดระวัง)
ถ้ามี NPS/CSAT, ปริมาณตั๋ว support, และ บันทึก CSM สามารถเพิ่มความละเอียดได้ ใช้สิ่งเหล่านี้เป็นตัวปรับหรือตัวปักธง ไม่ใช่ฐานหลัก เพราะข้อมูลเชิงคุณภาพมักหายากและมีความอคติ
สร้างพจนานุกรมข้อมูลเรียบง่าย
ก่อนสร้างชาร์ต ให้ตกลงชื่อและคำนิยาม ตารางพจนานุกรมข้อมูลเบาๆ ควรมี:
- ชื่อเมตริก (เช่น
active_days_28d) - คำนิยามชัดเจน (อะไรนับ อะไรไม่เข้า)
- หน้าต่างเวลาและความถี่การรีเฟรช
- ระบบต้นทาง (เหตุการณ์จากผลิตภัณฑ์, CRM, support)
นี่ช่วยป้องกันความสับสน “เมตริกเดียวกัน ความหมายต่างกัน” เมื่อคุณสร้างแดชบอร์ดและการแจ้งเตือน
ออกแบบโมเดลคะแนนที่อธิบายได้
คะแนนการยอมรับใช้งานจะใช้ได้ต่อเมื่อทีมเชื่อถือได้ ตั้งเป้าโมเดลที่อธิบายให้ CSM ฟังในหนึ่งนาที และอธิบายให้ลูกค้าในห้านาที
เริ่มจากเรียบง่าย: weighted points (ก่อนใช้ ML)
เริ่มด้วยโมเดลกฎที่โปร่งใส เลือกสัญญาณการยอมรับน้อย ๆ (เช่น ผู้ใช้ที่ใช้งาน, การใช้ฟีเจอร์สำคัญ, อินทิเกรชันที่เปิด) และกำหนดน้ำหนักที่สะท้อนช่วง “aha” ของผลิตภัณฑ์
ตัวอย่างการให้น้ำหนัก:
- Weekly active users per seat: 0–40 คะแนน
- ความถี่การใช้ฟีเจอร์สำคัญ: 0–35 คะแนน
- ความกว้างของฟีเจอร์ที่ใช้: 0–15 คะแนน
- เวลาตั้งแต่กิจกรรมที่มีความหมายล่าสุด: 0–10 คะแนน
เก็บน้ำหนักให้อธิบายได้ง่าย คุณสามารถปรับได้ภายหลัง—อย่ารอให้โมเดลสมบูรณ์แบบ
ทำ normalization เพื่อลดความเอนเอียง
การนับดิบลงโทษบัญชีเล็กและทำให้บัญชีใหญ่ดูเรียบ หากจำเป็นให้ normalize เมตริก:
- ต่อที่นั่ง (usage / licensed seats)
- ตามอายุบัญชี (บัญชีใหม่ vs บัญชีโตแล้ว)
- ตามระดับแผน (feature availability)
นี่ช่วยให้คะแนนสะท้อนพฤติกรรม ไม่ใช่แค่ขนาด
กำหนด green/yellow/red พร้อมเหตุผลชัดเจน
ตั้งเกณฑ์ (เช่น Green ≥ 75, Yellow 50–74, Red < 50) และบันทึกเหตุผลของแต่ละ cutoff เชื่อมเกณฑ์กับผลลัพธ์ที่คาดหวัง (ความเสี่ยงต่อการต่ออายุ, การเสร็จ onboarding, ความพร้อมขยาย)
เก็บบันทึกเกณฑ์ไว้ในเอกสารภายในหรือ /blog/health-score-playbook
ทำให้มันอธิบายได้: ตัวช่วยและแนวโน้ม
ทุกคะแนนควรแสดง:
- Top 3 contributors (สิ่งที่ช่วย/ทำให้คะแนนลด)
- การเปลี่ยนแปลงเมื่อเวลาผ่านไป (7/30 วันที่ผ่านมา)
- สรุปเป็นภาษาธรรมดา (“การใช้ Feature X ลดลง 35% สัปดาห์ต่อสัปดาห์”)
วางแผนการปรับปรุง: versioning ของโมเดล
ปฏิบัติต่อการให้คะแนนเหมือนผลิตภัณฑ์ กำหนดเวอร์ชัน (เช่น v1, v2) และติดตามผล: การแจ้งเตือนความเสี่ยงแม่นยำขึ้นหรือไม่? CSM ทำงานเร็วขึ้นหรือไม่? เก็บเวอร์ชันของโมเดลกับการคำนวณแต่ละครั้งเพื่อเทียบผลเมื่อเวลาผ่านไป
ติดตามเหตุการณ์ของผลิตภัณฑ์และแหล่งข้อมูล
คะแนนสุขภาพเชื่อถือได้มากเท่ากับข้อมูลกิจกรรมที่อยู่เบื้องหลัง ก่อนเขียนตรรกะการให้คะแนน ให้แน่ใจว่าสัญญาณถูกจับอย่างสม่ำเสมอในระบบต่าง ๆ
เลือกแหล่งเหตุการณ์ของคุณ
โปรแกรมการยอมรับใช้งานส่วนใหญ่ดึงจากผสมของ:
- Frontend events (page views, clicks, การโต้ตอบฟีเจอร์)
- Backend actions (API calls, งานที่เสร็จ, การสร้างเรคคอร์ด)
- Billing (แผน, การต่ออายุ, สถานะการชำระเงิน, จำนวนที่นั่ง)
- Support and success tools (ตั๋ว, CSAT, ไมล์สโตนการ onboarding)
กฎปฏิบัติ: ติดตามการกระทำสำคัญทางฝั่งเซิร์ฟเวอร์ (ยากต่อการปลอม แทบไม่ถูกผลกระทบจาก ad blocker) และใช้ frontend events สำหรับการมีส่วนร่วม UI และการค้นพบ
กำหนดสคีม่าเหตุการณ์ที่ชัดเจน
เก็บสัญญาที่สม่ำเสมอเพื่อให้ง่ายต่อการ join, query และอธิบายต่อผู้มีส่วนได้ส่วนเสีย โครงร่างพื้นฐาน:
event_nameuser_idaccount_idtimestamp(UTC)properties(feature, plan, device, workspace_id, ฯลฯ)
ใช้คำศัพท์ควบคุมสำหรับ event_name (เช่น project_created, report_exported) และบันทึกไว้ใน tracking plan ง่ายๆ
ตัดสินใจเรื่อง SDK vs server-side (หรือทั้งสองอย่าง)
- SDK tracking เร็วในการส่งขึ้นระบบและดีสำหรับเหตุการณ์ UI
- Server-side tracking เหมาะกับการกระทำที่เป็น system-of-record
หลายทีมใช้ทั้งสอง แต่ต้องแน่ใจว่าไม่ double-count การกระทำเดียวกันในโลกจริง
จัดการ identity ให้ถูกต้อง
คะแนนมักจะรวมระดับ account ดังนั้นคุณต้องมีการจับคู่ user→account ที่เชื่อถือได้ วางแผนสำหรับ:
- ผู้ใช้ที่เป็นสมาชิกหลายบัญชี
- การรวมบัญชี (การได้มาหรือการรวม workspace)
- ID แบบไม่ระบุชื่อสำหรับพฤติกรรมก่อนเข้าสู่ระบบ (แล้วรวมอย่างปลอดภัยหลังสมัคร)
ฝังการตรวจสอบคุณภาพข้อมูล
ขั้นต่ำสุด ควรเฝ้าดูเหตุการณ์หาย ซ้ำจำนวนมาก และความสอดคล้องของ timezone (เก็บ UTC; แปลงเพื่อแสดง) แจ้งเตือนความผิดปกติเบื้องต้นเพื่อไม่ให้การแจ้งเตือนความเสี่ยงทำงานเพราะ tracking พัง
ออกแบบโมเดลข้อมูลและการจัดเก็บ
แอปคะแนนสุขภาพการยอมรับใช้งานลูกค้าจะรุ่งหรือตกอยู่ที่การออกแบบว่า “ใครทำอะไร และเมื่อไร” เป้าหมายคือให้คำถามทั่วไปตอบได้เร็ว: บัญชีนี้เป็นอย่างไรในสัปดาห์นี้? ฟีเจอร์ไหนกำลังขึ้นหรือลง? การออกแบบข้อมูลที่ดีทำให้การให้คะแนน แดชบอร์ด และการแจ้งเตือนง่าย
เอนทิตีหลักที่ควรโมเดล
เริ่มจากชุดเล็ก ๆ ของตาราง “source of truth”:
- Accounts: account_id, plan, segment, lifecycle stage, CSM owner
- Users: user_id, account_id, role/persona, created_at, status
- Subscriptions (หรือ contracts): account_id, start/end, seats, MRR, renewal date
- Features: feature_id, name, category (activation, collaboration, admin, ฯลฯ)
- Events: event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores: account_id, score_date (or computed_at), overall_score, component scores, explanation fields
รักษาความสอดคล้องโดยใช้ stable IDs (account_id, user_id) ทุกที่
แยกการเก็บข้อมูล: relational + analytics
ใช้ relational database (เช่น Postgres) สำหรับ accounts/users/subscriptions/scores—สิ่งที่อัปเดตและ join บ่อย
เก็บเหตุการณ์ความหนาแน่นสูงใน warehouse/analytics (เช่น BigQuery/Snowflake/ClickHouse) เพื่อให้แดชบอร์ดและการวิเคราะห์โคฮอร์ตตอบสนองได้โดยไม่โหลดฐานข้อมูลธุรกรรม
เก็บค่ารวบยอดเพื่อความเร็ว
แทนการคำนวณทุกอย่างจากเหตุการณ์ดิบ ให้รักษา:
- สรุปรายวันของบัญชี (หนึ่งแถวต่อบัญชีต่อวัน): ผู้ใช้ที่ใช้งาน, จำนวนเหตุการณ์สำคัญ, กิจกรรมล่าสุด, ไมล์สโตนการยอมรับ
- ตัวนับฟีเจอร์: per account/day/feature การใช้งาน, ผู้ใช้เฉพาะ, เวลาที่ใช้ (ถ้ามี)
ตารางเหล่านี้ขับเคลื่อนกราฟแนวโน้ม ข้อมูล "อะไรเปลี่ยน" และส่วนประกอบของคะแนนสุขภาพ
การเก็บรักษา partitioning และประสิทธิภาพการสืบค้น
สำหรับตารางเหตุการณ์ขนาดใหญ่ วางแผน retention (เช่น raw 13 เดือน, เก็บรวบยอดนานกว่า) และ partition by date จัดกลุ่ม/index โดย account_id และ timestamp/date เพื่อเร่งคำถาม “บัญชีตามเวลา”
ในตารางเชิงสัมพันธ์ ให้ใส่ index ฟิลเตอร์และ join ที่พบบ่อย: account_id, (account_id, date) บนสรุปรายวัน และ foreign keys เพื่อรักษาความสะอาดของข้อมูล
วางสถาปัตยกรรมเว็บแอป
Make it team-ready
Put your CS dashboard on a custom domain for easier internal access.
สถาปัตยกรรมควรช่วยให้ส่ง v1 ที่ไว แล้วเติบโตโดยไม่ต้องเขียนใหม่ เริ่มด้วยการตัดสินใจว่าจำเป็นต้องมีชิ้นส่วนเท่าไร
Monolith vs services (เก็บ v1 ให้เรียบง่าย)
สำหรับทีมส่วนใหญ่ โมดูลาร์มอนอลิธคือเส้นทางที่เร็วที่สุด: โค้ดเบสเดียวที่มีเขตแดนชัดเจน (ingestion, scoring, API, UI) deploy หนึ่งชุด และลดปัญหาการปฏิบัติการ
ย้ายเป็น services ก็ต่อเมื่อมีเหตุผลชัด—เช่น ความต้องการสเกลแยกต่างหาก การแยกข้อมูลอย่างเข้มงวด หรือทีมต่างกันดูแลส่วนต่าง ๆ มิฉะนั้น premature services จะเพิ่มจุดล้มเหลวและชะลอการวนซ้ำ
กำหนดคอมโพเนนต์หลัก
อย่างน้อย วางหน้าที่เหล่านี้ (แม้อยู่ในแอปเดียวตอนเริ่ม):
- Ingestion: รับเหตุการณ์ผลิตภัณฑ์ (SDK, Segment, webhook, batch imports)
- Aggregation: เปลี่ยนเหตุการณ์ดิบเป็นข้อเท็จจริงการใช้งานรายวัน/รายสัปดาห์ต่อบัญชี/ผู้ใช้
- Scoring: คำนวณคะแนนสุขภาพการยอมรับใช้งานและคำอธิบายประกอบ
- API: ให้คะแนน แนวโน้ม และข้อมูล "ทำไม" ไปยัง UI และการผสาน
- UI: แดชบอร์ด customer success พร้อมมุมมองบัญชี โคฮอร์ต และการ drill-down
ถ้าต้องการต้นแบบเร็ว ๆ วิธี vibe-coding อาจช่วยให้ได้แดชบอร์ดทำงานโดยไม่ต้องลงทุนมาก ตัวอย่างเช่น Koder.ai สามารถสร้าง UI React และ backend Go จากคำอธิบายสั้น ๆ ของเอนทิตี (accounts, events, scores), endpoints และหน้าจอ—มีประโยชน์สำหรับยืน v1 ให้ทีม CS ทดลอง
Scheduled jobs vs. streaming
การให้คะแนนแบบ batch (เช่น รายชั่วโมง/รายวัน) มักเพียงพอสำหรับการติดตามการยอมรับใช้งานและง่ายต่อการปฏิบัติการ การสตรีมเหมาะเมื่อคุณต้องการการแจ้งเตือนเกือบเรียลไทม์ (เช่น การลดใช้งานกะทันหัน) หรือต้องรองรับปริมาณเหตุการณ์สูง
แนวปฏิบัติปานกลาง: ingest เหตุการณ์ต่อเนื่อง, aggregate/score ตามตารางเวลา, และสงวน streaming สำหรับสัญญาณด่วน
สภาพแวดล้อม ความลับ และความต้องการนอกหน้าที่
ตั้งค่า dev/stage/prod แต่เนิ่น ๆ โดยมีบัญชีตัวอย่างใน stage เพื่อยืนยันแดชบอร์ด ใช้ระบบจัดการความลับและหมุน credentials
บันทึกข้อกำหนดล่วงหน้า: ปริมาณเหตุการณ์คาดการณ์, ความสดของคะแนน (SLA), targets latency ของ API, ความพร้อมใช้งาน, การเก็บรักษาข้อมูล และข้อจำกัดความเป็นส่วนตัว (การจัดการ PII และการควบคุมการเข้าถึง) นี่ช่วยป้องกันไม่ให้ตัดสินใจเชิงสถาปัตยกรรมล่าช้าภายใต้ความกดดัน
สร้าง data pipeline และงานให้คะแนน
คะแนนสุขภาพของคุณจะเชื่อถือได้เท่ากับ pipeline ที่สร้างมัน ปฏิบัติต่อการให้คะแนนเหมือนระบบโปรดักชัน: ทำซ้ำได้ สังเกตได้ และอธิบายได้เมื่อใครสักคนถามว่า “ทำไมบัญชีนี้ลดวันนี้?”
ไพพ์ไลน์เรียบง่าย: raw → validated → aggregates
เริ่มด้วย flow ที่คัดกรองข้อมูลจนเหลือสิ่งที่สามารถให้คะแนนได้ปลอดภัย:
- Raw events: การ ingest แบบ append-only จากแอป โมบาย อินทิเกรชัน และการส่งออก billing/CRM
- Validated events: เหตุการณ์ที่ผ่านการตรวจ schema (ฟิลด์จำเป็น ประเภทถูกต้อง), การตรวจ identity (user → account mapping), และการ deduplication
- Daily aggregates: rollups ตามบัญชี (และปกติเป็น workspace/team) เช่น ผู้ใช้ที่ใช้งาน จำนวนเหตุการณ์สำคัญ เวลาไปถึงคุณค่า และ deltas แนวโน้ม
โครงสร้างนี้ทำให้งานให้คะแนนเร็วและเสถียร เพราะทำงานบนตารางที่สะอาดและกะทัดรัด แทนที่จะเป็นพันล้านแถวดิบ
ตารางเวลาในการคำนวณซ้ำและ backfills
ตัดสินใจว่าคะแนนต้องสดแค่ไหน:
- Hourly ให้คะแนนเหมาะกับการเคลื่อนไหวที่ต้องการการตอบสนองเร็ว
- Daily มักพอสำหรับ SMB/self-serve และช่วยลดต้นทุน
สร้าง scheduler ที่รองรับ backfills (เช่น ประมวลผลใหม่ 30/90 วันที่ผ่านมา) เมื่อแก้ tracking เปลี่ยน weighting หรือเพิ่มสัญญาณ Backfill ควรเป็นฟีเจอร์หลัก ไม่ใช่สคริปต์ฉุกเฉิน
Idempotency: หลีกเลี่ยงการนับซ้ำ
งานให้คะแนนจะถูก retry, imports จะรันใหม่, webhooks จะถูกส่งซ้ำ ออกแบบให้รองรับสิ่งนั้น
ใช้ idempotency key สำหรับเหตุการณ์ (event_id หรือ hash คงที่ของ timestamp + user_id + event_name + properties) และบังคับความเป็นเอกลักษณ์ที่ validated layer สำหรับ aggregates ให้ upsert ตาม (account_id, date) เพื่อให้การคำนวณซ้ำแทนที่ผลก่อนหน้า แทนที่จะเพิ่ม
การมอนิเตอร์และการตรวจจับความผิดปกติ
เพิ่มมอนิเตอร์เชิงปฏิบัติการสำหรับ:
- Job success/failure และจำนวน retry
- Data lag (ข้อมูลล่าสุดใน aggregates ล้าจาก “ตอนนี้” เท่าไร)
- Volume anomalies (การลด/สเปกเหตุการณ์อย่างกะทันหัน, ผู้ใช้ที่ใช้งาน, การกระทำสำคัญ)
เกณฑ์ง่าย ๆ (เช่น “เหตุการณ์ลดลง 40% เทียบกับค่าเฉลี่ย 7 วัน”) จะป้องกันการล้มเหลวเงียบที่ทำให้แดชบอร์ด CS สับสน
บันทึกตรวจสอบ (audit trails) สำหรับทุกคะแนน
เก็บ audit record ต่อบัญชีต่อการรันการให้คะแนน: เมตริกอินพุต ฟีเจอร์ที่สกัด (เช่น week-over-week change) เวอร์ชันโมเดล และคะแนนสุดท้าย เมื่อ CSM คลิก “ทำไม?” คุณควรแสดงได้อย่างชัดเจนว่าอะไรเปลี่ยนและเมื่อใด—โดยไม่ต้องย้อนรอยจาก logs
สร้าง API ที่ปลอดภัยสำหรับคะแนนและข้อมูลเชิงลึก
Ship a health score v1
Turn your health score ideas into a working dashboard using chat instead of scaffolding.
เว็บแอปของคุณขึ้นอยู่กับ API มันคือสัญญาระหว่างงานให้คะแนน UI และเครื่องมือปลายทาง (แพลตฟอร์ม CS, BI, การส่งออกข้อมูล) ตั้งเป้า API ที่เร็ว คาดการณ์ได้ และปลอดภัยโดยค่าเริ่มต้น
Endpoint หลักเพื่อรองรับเวิร์กโฟลว์จริง
ออกแบบ endpoint รอบการใช้งานจริงของ Customer Success:
- Account health:
GET /api/accounts/{id}/healthคืนค่าสุดท้ายของคะแนน สถานะ (เช่น Green/Yellow/Red) และ timestamp ที่คำนวณล่าสุด - Trends:
GET /api/accounts/{id}/health/trends?from=&to=สำหรับคะแนนตามเวลาและ deltas เมตริกหลัก - Drivers (“why”):
GET /api/accounts/{id}/health/driversแสดงปัจจัยบวก/ลบสูงสุด (เช่น “weekly active seats down 35%”) - Cohorts:
GET /api/cohorts/health?definition=สำหรับการวิเคราะห์โคฮอร์ตและการเปรียบเทียบกลุ่มเพื่อน - Exports:
POST /api/exports/healthเพื่อสร้าง CSV/Parquet ตามสคีมาที่สอดคล้อง
การกรอง pagination และ caching
ทำให้ endpoints รายการง่ายต่อการแบ่ง:
- Filters:
plan,segment,csm_owner,lifecycle_stage, และdate_rangeคือสิ่งจำเป็น - Pagination: ใช้ cursor-based pagination (
cursor,limit) เพื่อความเสถียรเมื่อข้อมูลเปลี่ยน - Caching: แคชคำถามหนัก (cohort rollups, trend series) และคืนค่า
ETag/If-None-Matchเพื่อลดการโหลดซ้ำ ทำให้ cache keys ตระหนักถึง filters และ permissions
ความปลอดภัยด้วยการควบคุมการเข้าถึงตามบทบาท
ปกป้องข้อมูลในระดับบัญชี ดำเนินการ RBAC (เช่น Admin, CSM, Read-only) และบังคับใช้ฝั่งเซิร์ฟเวอร์ในทุก endpoint CSM ควรเห็นเฉพาะบัญชีที่ตนดูแล; บทบาททางการเงินอาจเห็นสรุประดับแผนแต่ไม่เห็นรายละเอียดระดับผู้ใช้
คืนค่าความสามารถในการอธิบายเสมอ
ควบคู่กับตัวเลข คะแนนสุขภาพการใช้งานลูกค้า ให้คืนฟิลด์ “ทำไม”: top drivers, เมตริกที่ได้รับผลกระทบ, และ baseline ที่เปรียบเทียบ (ช่วงก่อนหน้า, cohort median) นี่เปลี่ยน การติดตามการยอมรับใช้งาน ให้เป็นการกระทำ ไม่ใช่แค่รายงาน และทำให้แดชบอร์ดน่าเชื่อถือ
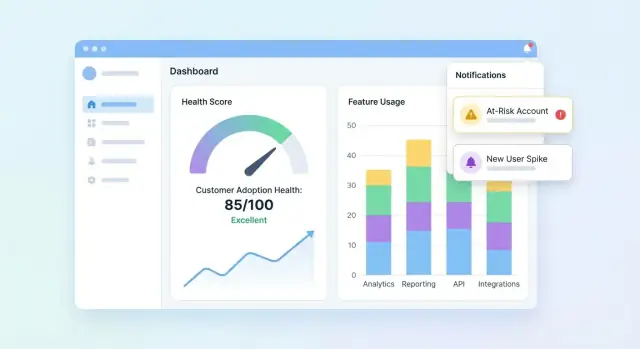
ออกแบบแดชบอร์ดและมุมมองบัญชี
UI ของคุณควรตอบสามคำถามอย่างรวดเร็ว: ใครบ้างที่แข็งแรง? ใครบ้างที่กำลังถอย? ทำไม? เริ่มจากแดชบอร์ดสรุปพอร์ตโฟลิโอ แล้วให้ผู้ใช้กดลงลึกไปยังบัญชีเพื่อเข้าใจเรื่องราวเบื้องหลังคะแนน
สิ่งจำเป็นบนแดชบอร์ดพอร์ตโฟลิโอ
ใส่ไทล์และชาร์ตที่กระชับให้ทีม CS สแกนได้ในไม่กี่วินาที:
- การกระจายคะแนน (ฮิสโตแกรมหรือบัคเก็ต เช่น Healthy / Watch / At-risk)
- รายการที่เสี่ยง พร้อมฟิลด์ที่ต้องใช้จริง (บัญชี, เจ้าของ, คะแนน, กิจกรรมล่าสุด, ตัวขับเคลื่อนหลัก)
- แนวโน้มคะแนนตามเวลา (line chart) พร้อมตัวกรองตามเซ็กเมนต์
ทำให้รายการที่เสี่ยงคลิกได้เพื่อเปิดบัญชีและดูการเปลี่ยนแปลงทันที
มุมมองบัญชี: อธิบายคะแนน
หน้าบัญชีควรอ่านเหมือนไทม์ไลน์ของการยอมรับใช้งาน:
- ไทม์ไลน์ ของเหตุการณ์สำคัญ (ขั้นตอน onboarding เสร็จ, การเชื่อมต่ออินทิเกรชัน, การเปลี่ยนแปลง admin, การใช้ฟีเจอร์ครั้งแรก)
- เมตริกหลัก (ผู้ใช้ที่ใช้งาน, การกระทำฟีเจอร์สำคัญ, เวลาตั้งแต่กิจกรรมที่มีความหมายล่าสุด)
- สรุปการยอมรับฟีเจอร์ แสดงว่าฟีเจอร์ใดถูกนำไปใช้ ถูกมองข้าม หรือลดลง
เพิ่ม panel “ทำไมคะแนนนี้?”: คลิกคะแนนเพื่อดูสัญญาณที่มีส่วนช่วย (บวกและลบ) พร้อมคำอธิบายภาษาธรรมดา
มุมมองโคฮอร์ตและเซ็กเมนต์
ให้ตัวกรองโคฮอร์ตที่ตรงกับการจัดการบัญชีของทีม: โคฮอร์ต onboarding, ระดับแผน, และ อุตสาหกรรม จับคู่แต่ละโคฮอร์ตกับเส้นแนวโน้มและตารางเล็ก ๆ ของ movers เพื่อให้ทีมเปรียบเทียบผลลัพธ์และสังเกตรูปแบบ
ภาพที่เข้าถึงได้และไว้วางใจได้
ใช้ป้ายบอกสถานะที่อ่านง่าย หลีกเลี่ยงไอคอนกำกวม และเสนอ ตัวบ่งชี้สถานะที่ปลอดภัยสำหรับสี (เช่น ป้ายข้อความ + รูปร่าง) ทำให้ชาร์ตเป็นเครื่องมือในการตัดสินใจ: ใส่คำอธิบายเหตุการณ์, แสดงช่วงวันที่ และทำให้พฤติกรรม drill-down สอดคล้องทั่วหน้า
เพิ่มการแจ้งเตือน งาน และเวิร์กโฟลว์
คะแนนสุขภาพมีประโยชน์ก็ต่อเมื่อมันผลักดันให้เกิดการกระทำ การแจ้งเตือนและเวิร์กโฟลว์แปลง “ข้อมูลที่น่าสนใจ” เป็นการติดต่อทันเวลา แก้ไข onboarding หรือการกระตุ้นผลิตภัณฑ์ โดยไม่ต้องให้ทีมจ้องแดชบอร์ดทั้งวัน
กำหนดกฎการแจ้งเตือนที่สอดคล้องกับความเสี่ยงจริง
เริ่มจากชุดเล็ก ๆ ของทริกเกอร์ที่มีสัญญาณชัด:
- การลดคะแนน (เช่น ลดลง 15 คะแนนสัปดาห์ต่อสัปดาห์)
- สถานะ Red (ข้ามเกณฑ์วิกฤต)
- การลดการใช้งานแบบฉับพลัน (การใช้ฟีเจอร์สำคัญต่ำกว่าพื้นฐาน)
- ขั้นตอน onboarding ล้มเหลว (รายการตรวจสอบค้าง, อินทิเกรชันไม่เสร็จ)
ทำให้ทุกกฎชัดเจนและอธิบายได้ แทนที่จะเตือนว่า “สุขภาพแย่” ให้แจ้งว่า “ไม่มีการใช้งานใน Feature X เป็นเวลา 7 วัน + onboarding ยังไม่เสร็จ”
เลือกช่องทางและให้ปรับได้
ทีมต่างกันทำงานต่างกัน ดังนั้นสร้างการรองรับช่องทางและการตั้งค่า:
- อีเมล สำหรับเจ้าของบัญชีและผู้จัดการ
- Slack สำหรับการมองเห็นทีมและการตอบสนองเร็ว
- งานในแอป ภายในแดชบอร์ด customer success เพื่อไม่ให้งานหาย
ให้แต่ละทีมตั้งค่า: ใครได้รับการแจ้ง, เปิดกฎใดบ้าง, และ threshold ใดถือว่า “ด่วน”
ลดเสียงรบกวนด้วยกรอบควบคุม
ความเหนื่อยล้าจากการแจ้งเตือนฆ่าการติดตามการยอมรับใช้งาน ใส่การควบคุมเช่น:
- หน้าต่าง cooldown (ไม่แจ้งซ้ำสำหรับบัญชีเดียวกันภายใน N ชั่วโมง/วัน)
- เกณฑ์ข้อมูลขั้นต่ำ (ข้ามการแจ้งถ้าบัญชีมีข้อมูลน้อยเกินไป)
- การรวม/สรุป สำหรับสัญญาณไม่เร่งด่วน (สรุปรายวัน/รายสัปดาห์)
เพิ่มบริบทและขั้นตอนถัดไป
แต่ละการแจ้งเตือนควรตอบ: อะไรเปลี่ยน แสดงความสำคัญอย่างไร และต้องทำอะไรต่อ รวมตัวขับเคลื่อนคะแนนล่าสุด ไทม์ไลน์สั้น ๆ (เช่น 14 วันที่ผ่านมา) และงานแนะนำเช่น “นัดสาย onboarding” หรือ “ส่งคู่มือการเชื่อมต่อ” ลิงก์ไปมุมมองบัญชี (เช่น /accounts/{id})
ติดตามผลลัพธ์เพื่อปิดวงจร
ปฏิบัติต่อการแจ้งเตือนเป็นงานที่มีสถานะ: acknowledged, contacted, recovered, churned การรายงานผลช่วยปรับกฎ ปรับปรุง playbook และพิสูจน์ได้ว่าคะแนนสุขภาพนำไปสู่การลด churn ที่วัดได้
รับรองคุณภาพข้อมูล ความเป็นส่วนตัว และการกำกับดูแล
Generate the app skeleton
Describe your entities and screens, and let Koder.ai generate the React UI and Go backend.
ถ้าคะแนนสุขภาพสร้างจากข้อมูลที่ไม่เชื่อถือ ทีมจะเลิกเชื่อและเลิกใช้มัน จงปฏิบัติต่อคุณภาพข้อมูล ความเป็นส่วนตัว และ governance เป็นฟีเจอร์ของผลิตภัณฑ์ ไม่ใช่เรื่องรอง
ใส่การตรวจสอบข้อมูลอัตโนมัติ
เริ่มด้วยการตรวจสอบเบา ๆ ในทุกจุดส่งผ่าน (ingest → warehouse → scoring output) การทดสอบสัญญาณสูงไม่กี่รายการจับปัญหาส่วนใหญ่ได้เร็ว:
- Schema checks: คอลัมน์ที่คาดหวังมีอยู่ ประเภทไม่เปลี่ยนแปลง enums ถูกต้อง
- Range checks: ค่าที่เป็นไปไม่ได้ (session ติดลบ, timestamp ในอนาคต) ล้มเหลวเร็ว
- Null checks: ฟิลด์จำเป็น (
account_id,event_name,occurred_at) ต้องไม่ว่าง
เมื่อทดสอบล้มเหลว ให้บล็อกงานให้คะแนน (หรือตั้งผลลัพธ์เป็น “stale”) เพื่อไม่ให้ pipeline พังเงียบแล้วสร้างการแจ้งเตือนความเสี่ยงผิดๆ
จัดการกรณีขอบเขตทั่วไปอย่างชัดเจน
การให้คะแนนล้มเหลวในสถานการณ์ “แปลกแต่ปกติ” กำหนดกฎสำหรับ:
- บัญชีใหม่ที่มีข้อมูลน้อย: แสดง “ข้อมูลไม่เพียงพอ” หรือใช้ baseline ramp-up แทนคะแนนต่ำ
- การใช้งานตามฤดูกาล: เปรียบเทียบกับช่วงก่อนหน้าของบัญชีหรือเกณฑ์โคฮอร์ตแทนเกณฑ์สากล
- การล้มของระบบและช่องว่างการติดตาม: ทำเครื่องหมายช่วงเวลาที่ได้รับผลกระทบและป้องกันไม่ให้ลงโทษลูกค้าสำหรับ downtime ของคุณ
เพิ่มการควบคุมการเข้าถึงและความเป็นส่วนตัว
จำกัด PII โดยค่าเริ่มต้น: เก็บเท่าที่จำเป็นสำหรับการติดตามการยอมรับใช้งาน ใช้ RBAC ในเว็บแอป บันทึกว่าใครดู/ส่งออกข้อมูล และปิดบังการส่งออกเมื่อฟิลด์ไม่จำเป็น (เช่น ซ่อนอีเมลใน CSV)
สร้าง runbooks และนิสัยการกำกับดูแล
เขียน runbook สั้น ๆ สำหรับการตอบเหตุการณ์: วิธีหยุดการให้คะแนน ช่วงเวลา backfill ข้อมูล และรันงานใหม่ ทบทวนเมตริก CS และน้ำหนักคะแนนเป็นประจำ—รายเดือนหรือรายไตรมาส เพื่อป้องกันการ drift เมื่อผลิตภัณฑ์ของคุณเปลี่ยน สำหรับการจัดกระบวนการ ให้เชื่อม internal checklist ของคุณจาก /blog/health-score-governance
ยืนยัน ทดลอง และขยายคะแนนสุขภาพ
การยืนยันคือจุดที่คะแนนหยุดเป็นแค่ “ชาร์ตสวย” และเริ่มเชื่อถือพอที่จะขับเคลื่อนการกระทำ ปฏิบัติต่อเวอร์ชันแรกเป็นสมมติฐาน ไม่ใช่คำตอบสุดท้าย
รันพายล็อตและปรับเทียบกับการตัดสินของมนุษย์
เริ่มด้วยกลุ่มบัญชีพายล็อต (เช่น 20–50 บัญชีในแต่ละเซ็กเมนต์) สำหรับแต่ละบัญชีเทียบคะแนนและเหตุผลกับการประเมินของ CSM
มองหารูปแบบ:
- คะแนนที่สูง/ต่ำกว่าการตัดสินของ CSM อย่างสม่ำเสมอ (calibration)
- “False alarms” (ความเสี่ยงสูงแต่บัญชียังดี) เทียบกับ “misses” (คะแนนดีแต่บัญชี churn)
- เหตุผลที่ไม่ตรงกับความจริง (ช่องว่างในการอธิบาย)
วัดว่ามันมีประโยชน์จริงไหม
ความแม่นยำสำคัญ แต่ความมีประโยชน์คือสิ่งที่ให้ผลตอบแทน ติดตามผลลัพธ์การปฏิบัติงานเช่น:
- เวลาในการตรวจพบความเสี่ยง (ตรวจพบปัญหาเร็วแค่ไหน)
- อัตราความสำเร็จในการติดต่อ (เปอร์เซ็นต์ของบัญชีเสี่ยงที่ดีขึ้นหลังจากการแทรกแซง)
- ตัวชี้วัดการลด churn (การเคลื่อนไหวความน่าจะเป็นต่อการต่ออายุ, สัญญาณการขยาย, การเปลี่ยนแปลงภาระงาน support)
ทดสอบการเปลี่ยนแปลงอย่างปลอดภัยด้วย versioning
เมื่อปรับ threshold น้ำหนักหรือเพิ่มสัญญาณ ให้จัดเป็นเวอร์ชันใหม่ A/B test เวอร์ชันกับโคฮอร์ตหรือเซ็กเมนต์ที่เทียบเคียงได้ และเก็บประวัติไว้เพื่ออธิบายว่าทำไมคะแนนเปลี่ยน
เก็บข้อเสนอแนะภายใน UI
เพิ่มคอนโทรลเบา ๆ เช่น “คะแนนรู้สึกผิด” พร้อมเหตุผล (เช่น “การเสร็จ onboarding ล่าสุดไม่ถูกสะท้อน”, “การใช้งานแบบมีฤดูกาล”, “mapping บัญชีผิด”) นำข้อเสนอแนะนี้ไปยัง backlog และติด tag กับบัญชีและเวอร์ชันของคะแนนเพื่อการดีบักเร็วขึ้น
ขยายด้วย roadmap
เมื่อพายล็อตเสถียร วางแผนการขยาย: การเชื่อมต่อเชิงลึกกว่า (CRM, billing, support), การแบ่งเซ็กเมนต์ (ตามแผน อุตสาหกรรม lifecycle), อัตโนมัติ (งานและ playbook), และการตั้งค่า self-serve ให้ทีมปรับมุมมองโดยไม่ต้องพึ่งวิศวกร
เมื่อขยาย ให้รักษาวงจร build/iterate ให้สั้น ทีมมักใช้ Koder.ai เพื่อสร้างหน้าแดชบอร์ดใหม่ ปรับรูปแบบ API หรือเพิ่มฟีเจอร์เวิร์กโฟลว์ (เช่น งาน การส่งออก และ releases ที่พร้อม rollback) โดยตรงจากแชท—มีประโยชน์เมื่อต้องเวอร์ชันโมเดลคะแนนและต้องส่ง UI + backend พร้อมกันโดยไม่ชะลอวง feedback ของ CS
คำถามที่พบบ่อย
What should a customer adoption health score do for the business?
Start by defining what the score is for:
- Churn risk alerts (identify accounts slipping)
- Onboarding guidance (prioritize setup steps)
- Product improvement (spot friction and underused features)
If you can’t name a decision that changes when the score changes, don’t include that metric yet.
How do I define “adoption” for my product?
Write down the few behaviors that prove customers are getting value:
- Activation: the first meaningful outcome (e.g., invite a teammate, connect a data source)
- Core actions: repeatable actions correlated with successful accounts
- Retention cadence: continued usage weekly/monthly (ideally by multiple users)
Avoid defining adoption as “logged in recently” unless login directly equals value in your product.
Which metrics should I include in a health score?
Start with a small set of high-signal indicators:
- Weekly active users (WAU) and trend
- Active days (distinct days active, not just one long session)
- Key feature usage frequency (your “value features”)
- Integrations connected (when they unlock workflows or increase stickiness)
- Seat utilization (invited, activated, and active seats)
Only keep metrics you can justify in one sentence.
How do I keep the score fair across small and large accounts?
Normalize and segment so the same behavior is judged fairly:
- Normalize by seats (usage per licensed seat)
- Adjust expectations by account age (new vs. mature)
- Segment thresholds by plan tier/entitlements and ARR band
This prevents raw counts from punishing small accounts and flattering large ones.
What’s the difference between leading and lagging indicators in health scoring?
Leading indicators help you act early; lagging indicators confirm outcomes.
- Leading: increasing active days, onboarding completion, first integration connected
- Lagging: renewal, expansion, long-term retention
Use lagging indicators mainly for validation and calibration—don’t let them dominate the score if your goal is early warning.
How can I build an explainable scoring model without machine learning?
Use a transparent, weighted-points model first. Example components:
- WAU per seat (0–40)
- Key feature frequency (0–35)
- Breadth of features used (0–15)
- Time since last meaningful activity (0–10)
Then define clear status bands (e.g., Green ≥ 75, Yellow 50–74, Red < 50) and document why those cutoffs exist.
What product events should I instrument to power the score?
At a minimum, ensure each event includes:
event_name,user_id,account_id,timestamp(UTC)- Optional
properties(feature, plan, workspace_id, etc.)
Track critical actions when possible, keep in a controlled vocabulary, and avoid double-counting if you also instrument via an SDK.
How should I model and store data for a health score web app?
Model around a few core entities and split storage by workload:
- Relational DB (e.g., Postgres): accounts, users, subscriptions, scores
- Warehouse/analytics store: high-volume raw events
- Aggregates: daily account summaries and per-feature counters for fast trends
Partition large event tables by date, and index/cluster by account_id to speed up “account over time” queries.
How do I build scoring jobs that are reliable and debuggable?
Treat scoring as a production pipeline:
- Raw → validated → daily aggregates → score
- Make jobs idempotent (dedupe events; upsert aggregates by
(account_id, date)) - Support backfills for the last 30/90 days when tracking or weights change
- Store an audit record per run (inputs, derived metrics, model version, final score)
This makes “Why did the score drop?” answerable without digging through logs.
What API endpoints and alert rules should I build first?
Start with a few workflow-driven endpoints:
GET /api/accounts/{id}/health(latest score + status)GET /api/accounts/{id}/health/trends?from=&to=(time series + deltas)GET /api/accounts/{id}/health/drivers(top positive/negative contributors)
Enforce RBAC server-side, add cursor pagination for lists, and reduce noise in alerts with cooldown windows and minimum-data thresholds. Link alerts to the account view (e.g., ).