13 พ.ค. 2568·4 นาที
สร้างเว็บแอปเพื่อติดตามการใช้งานผลิตภัณฑ์ตามระดับบัญชี
เรียนรู้วิธีออกแบบข้อมูล เหตุการณ์ และแดชบอร์ดเพื่อติดตามการยอมรับผลิตภัณฑ์ตามระดับบัญชี และลงมือจากข้อมูลเชิงลึกด้วยการแจ้งเตือนและการทำงานอัตโนมัติ
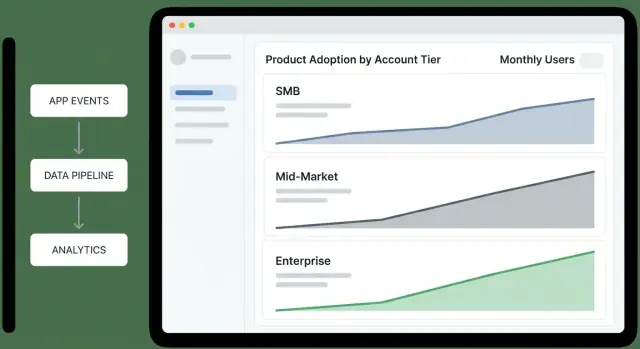
เรียนรู้วิธีออกแบบข้อมูล เหตุการณ์ และแดชบอร์ดเพื่อติดตามการยอมรับผลิตภัณฑ์ตามระดับบัญชี และลงมือจากข้อมูลเชิงลึกด้วยการแจ้งเตือนและการทำงานอัตโนมัติ
ก่อนจะสร้างแดชบอร์ดหรือใส่ instrumentation ให้ชัดว่าฟีเจอร์นี้มีไว้เพื่ออะไร ใครจะใช้ และระดับบัญชีถูกนิยามอย่างไร โครงการ “ติดตามการยอมรับ” ส่วนใหญ่ล้มเหลวเพราะเริ่มจากข้อมูลแล้วจบด้วยความเห็นไม่ตรงกัน
กฎปฏิบัติ: ถ้าสองทีมอธิบายคำว่า “การยอมรับ” ไม่เหมือนกันในประโยคเดียว พวกเขาจะไม่เชื่อแดชบอร์ดในภายหลัง
ตั้งชื่อผู้ชมหลักและสิ่งที่แต่ละคนต้องทำต่อไปหลังจากดูข้อมูล:
ทดสอบความเข้าใจ: ผู้ชมแต่ละกลุ่มควรตอบ “แล้วไง?” ได้ในไม่กี่วินาที
การยอมรับไม่ใช่เมตริกเดียว เขียนคำนิยามที่ทีมยอมรับ—โดยปกติเป็นลำดับของขั้นตอน:
ยึดโยงกับมูลค่าของลูกค้า: สัญญาณการกระทำใดที่บอกว่าพวกเขาได้ผลลัพธ์ ไม่ใช่แค่สำรวจ
ระบุระดับบัญชีของคุณและทำให้การกำหนดเป็นแบบตามกฎที่แน่นอน ระดับทั่วไปรวม SMB / Mid-Market / Enterprise, Free / Trial / Paid, หรือ Bronze / Silver / Gold
บันทึกกฎในภาษาธรรมดา (และในโค้ดต่อมา):
จดการตัดสินใจที่แอปต้องช่วยให้เกิดได้ เช่น:
ใช้สิ่งเหล่านี้เป็นเกณฑ์ยอมรับ:
ระดับบัญชีมีพฤติกรรมต่างกัน เมตริกการยอมรับเดียวจะลงโทษลูกค้าขนาดเล็กหรือซ่อนความเสี่ยงในบัญชีใหญ่ เริ่มจากนิยามความสำเร็จต่อระดับแล้วเลือกเมตริกที่สะท้อนความเป็นจริงนั้น
เลือกผลลัพธ์หลักหนึ่งตัวที่แสดงมูลค่าจริง:
north star ควรนับได้ แบ่งตามระดับ และยากต่อการเล่นเกม
เขียน funnel การยอมรับเป็นขั้นตอนพร้อมกฎชัดเจน—เพื่อให้คำตอบในแดชบอร์ดไม่ขึ้นกับการตีความ
ตัวอย่างขั้นตอน:
ความแตกต่างตามระดับสำคัญ: คำว่า “Activated” ใน enterprise อาจต้องการการกระทำของแอดมิน และ การกระทำของผู้ใช้ปลายทาง
ใช้ leading indicators เพื่อตรวจจับโมเมนตัมตั้งแต่ต้น:
ใช้ lagging indicators เพื่อยืนยันการยอมรับที่ยั่งยืน:
เป้าควรสะท้อนเวลาที่คาดว่าจะถึงมูลค่าและความซับซ้อนขององค์กร ตัวอย่าง: SMB อาจตั้งเป้าเปิดใช้งานภายใน 7 วัน; Enterprise อาจตั้งเป้า integrate ภายใน 30–60 วัน
จดเป้าหมายเพื่อให้การแจ้งเตือนและบอร์ดคะแนนมีความสอดคล้องระหว่างทีม
โมเดลข้อมูลชัดเจนจะป้องกัน “คณิตศาสตร์ปริศนา” ในภายหลัง คุณต้องตอบคำถามพื้นฐานว่า ใครใช้ฟีเจอร์อะไร ในบัญชีใด ภายใต้ระดับใด ในเวลานั้น โดยไม่ต้องต่อผูกตรรกะแบบ ad-hoc ในแต่ละแดชบอร์ด
เริ่มจากชุดเล็กๆ ที่สะท้อนการซื้อและการใช้งานของลูกค้า:
account_id), ชื่อ, สถานะ, และฟิลด์วงจรชีวิต (created_at, churned_at)user_id, โดเมนอีเมล (ช่วยจับคู่), created_at, last_seen_atworkspace_id และ foreign key ไปยัง account_idระบุชัดเจนว่า analytics ของคุณเก็บในระดับใด:
ค่าเริ่มต้นที่ใช้งานได้จริงคือเก็บเหตุการณ์ระดับ user (แนบ account_id) แล้วค่อยรวมเป็นเมตริกระดับบัญชี หลีกเลี่ยงเหตุการณ์ระดับบัญชีถ้าไม่มีผู้ใช้ (เช่น การนำเข้าจากระบบ)
เหตุการณ์บอกว่า อะไรเกิดขึ้น; snapshots บอกว่า อะไรเป็นจริงในขณะนั้น
อย่าเขียนทับ “current tier” และสูญเสียบริบท สร้างตาราง account_tier_history:
account_id, tier_idvalid_from, valid_to (nullable สำหรับปัจจุบัน)source (billing, sales override)สิ่งนี้ช่วยให้คุณคำนวณการยอมรับ ขณะที่บัญชีเป็น Team แม้มันจะอัปเกรดทีหลัง
เขียนคำนิยามครั้งเดียวและปฏิบัติเหมือนข้อกำหนดผลิตภัณฑ์: นิยามว่าอะไรถือเป็น “ผู้ใช้ที่ใช้งาน” วิธีการอ้างเหตุการณ์ไปยังบัญชี และจัดการการเปลี่ยนระดับกลางเดือนอย่างไร สิ่งนี้ป้องกันไม่ให้สองแดชบอร์ดแสดงความจริงต่างกัน
การวิเคราะห์การยอมรับจะดีเพียงใดขึ้นกับเหตุการณ์ที่คุณเก็บ เริ่มจากแมปชุดเล็กของการกระทำ “เส้นทางสำคัญ” ที่บ่งชี้ความคืบหน้าสำหรับแต่ละระดับบัญชี แล้วติดตั้งให้สม่ำเสมอทั้งเว็บ โมบาย และ backend
โฟกัสที่เหตุการณ์ที่บ่งชี้ขั้นตอนสำคัญ — ไม่ใช่ทุกคลิก ชุดเริ่มต้นใช้ได้จริง:
signup_completed (สร้างบัญชี)user_invited และ invite_accepted (การเติบโตของทีม)first_value_received (ช่วงเวลา “aha” ของคุณ; นิยามให้ชัด)key_feature_used (การกระทำที่ให้มูลค่าสำหรับฟีเจอร์; อาจมีหลายเหตุการณ์ต่อฟีเจอร์)integration_connected (ถ้า integrations ช่วยให้ลูกค้ายึดติด)เหตุการณ์ทุกตัวควรมีบริบทพอให้แบ่งตามระดับและบทบาท:
account_id (จำเป็น)user_id (จำเป็นเมื่อมีบุคคลเกี่ยวข้อง)tier (จับค่าในเวลาของเหตุการณ์)plan (billing plan/SKU ถ้ามี)role (เช่น owner/admin/member)workspace_id, feature_name, source (web/mobile/api), timestampใช้รูปแบบที่คาดเดาได้เพื่อให้แดชบอร์ดไม่กลายเป็นพจนานุกรม:
snake_case กริยา และถ้าใช้แล้วเป็นอดีตก็อาจใช้รูปแบบอดีตกาล (report_exported, dashboard_shared)account_id แทน acctId)invoice_sent) หรือเหตุการณ์เดียวพร้อม feature_name; เลือกวิธีเดียวแล้วยึดติดรองรับทั้งกิจกรรมแบบไม่ระบุตัวตนและยืนยันตัวตน:
anonymous_id เมื่อเข้าชมครั้งแรก แล้วเชื่อมกับ user_id เมื่อเข้าสู่ระบบworkspace_id เสมอและแม็ปไปยัง account_id ทางฝั่งเซิร์ฟเวอร์เพื่อหลีกเลี่ยงบั๊กจากไคลเอ็นต์ติดตั้งการกระทำของระบบบน backend เพื่อให้เมตริกสำคัญไม่พึ่งเบราว์เซอร์หรือบล็อกเกอร์โฆษณา ตัวอย่าง: subscription_started, payment_failed, seat_limit_reached, audit_log_exported
เหตุการณ์ฝั่งเซิร์ฟเวอร์เหมาะเป็นตัวทริกเกอร์สำหรับการแจ้งเตือนและเวิร์กโฟลว์
นี่คือที่ที่การติดตามกลายเป็นระบบ: เหตุการณ์มาจากแอป ถูกทำความสะอาด เก็บอย่างปลอดภัย และแปลงเป็นเมตริกที่ทีมของคุณใช้ได้จริง
ทีมส่วนใหญ่ใช้ผสมกัน:
ไม่ว่าเลือกทางไหน ให้ถือการรับเข้าเป็นสัญญา: ถ้าอ่านเหตุการณ์ไม่ได้ ควรกักไว้ไม่ใช่รับเข้าซ่อนๆ
ที่เวลาการรับเข้า ให้มาตรฐานฟิลด์สำคัญเพื่อให้การรายงานลงไปล่างน่าเชื่อถือ:
account_id, user_id, และถ้าจำเป็น workspace_idevent_name, tier, plan, feature_key) และใส่ค่า default เมื่อต้องการเท่านั้นตัดสินใจว่าจะเก็บ raw events ที่ไหนตามต้นทุนและรูปแบบการสืบค้น:
สร้างงานสรุปรายวัน/ชั่วโมงที่ผลิตตารางเช่น:
ทำให้ rollups เป็นแบบ deterministic เพื่อให้สามารถรันซ้ำเมื่อมีการเปลี่ยนแปลงการกำหนดระดับหรือ backfill
กำหนด retention ชัดเจนสำหรับ:
คะแนนการยอมรับช่วยทีมที่งานยุ่งมีตัวเลขเดียวในการติดตาม แต่ต้องเรียบง่ายและอธิบายได้ ตั้งเป้า 0–100 ที่สะท้อนพฤติกรรมที่มีความหมายและแบ่งสาเหตุการเปลี่ยนแปลงได้
เริ่มจากรายการถ่วงน้ำหนักที่อธิบายได้ จำกัดสูงสุด 100 คะแนน รักษาน้ำหนักให้คงที่อย่างน้อยหนึ่งไตรมาสเพื่อให้แนวโน้มเปรียบเทียบได้
ตัวอย่างการให้ค่าน้ำหนัก (ปรับตามผลิตภัณฑ์):
แต่ละพฤติกรรมควรแม็ปกับกฎเหตุการณ์ชัดเจน (เช่น “ใช้ core feature” = core_action ใน 3 วันแยกต่างหาก) เมื่อคะแนนเปลี่ยน ให้เก็บปัจจัยที่มีส่วนร่วมเพื่อแสดงว่า: “+15 เพราะเชิญ 2 ผู้ใช้” หรือ “-10 เพราะ core usage ลดลงต่ำกว่า 3 วัน”
คำนวณคะแนนต่อบัญชี (snapshot รายวันหรือรายสัปดาห์) แล้วรวมตามระดับโดยใช้ การกระจาย ไม่ใช่แค่อัตราเฉลี่ย:
ติดตาม การเปลี่ยนแปลงรายสัปดาห์ และ การเปลี่ยนแปลง 30 วัน ต่อระดับ แต่หลีกเลี่ยงการผสมขนาดของระดับ:
วิธีนี้ทำให้ระดับเล็กอ่านค่าได้โดยไม่ให้ระดับใหญ่ครอบงำเรื่องราว
แดชบอร์ดภาพรวมระดับบัญชีควรให้ผู้บริหารตอบคำถามหนึ่งข้อภายในหนึ่งนาที: “ระดับใดดีขึ้น ระดับใดถดถอย และเพราะเหตุใด?” ถือมันเป็นหน้าจอตัดสินใจ ไม่ใช่สมุดรวบรวมรายงาน
Funnel ตามระดับ (Awareness → Activation → Habit): “บัญชีติดขัดที่ขั้นตอนไหนตามระดับ?” รักษาขั้นตอนให้สอดคล้องกับผลิตภัณฑ์ (เช่น “เชิญผู้ใช้” → “ทำการกระทำหลักครั้งแรก” → “รายสัปดาห์ใช้งาน”)
อัตราการเปิดใช้งานตามระดับ: “บัญชีใหม่หรือบัญชีที่กลับมาเปิดใช้งานถึงค่าครั้งแรกหรือไม่?” แนบตัวประกอบ (denominator) เพื่อให้ผู้นำแยกสัญญาณจากสถิติเล็กๆ
Retention ตามระดับ (เช่น 7/28/90 วัน): “บัญชียังใช้งานหลังชนะครั้งแรกหรือไม่?” แสดงเส้นเดียวต่อระดับ หลีกเลี่ยงการแบ่งย่อยมากเกินไปบนภาพรวม
ความลึกของการใช้งาน (feature breadth): “พวกเขาใช้หลายพื้นที่ของผลิตภัณฑ์หรือยังคงตื้น?” แถบแบบสแต็กต่อระดับทำงานได้ดี: % ใช้ 1 พื้นที่, 2–3 พื้นที่, 4+ พื้นที่
เพิ่มการเปรียบเทียบสองแบบทุกที่:
ใช้ delta แบบคงที่ (การเปลี่ยนแปลงเป็นจุดเปอร์เซ็นต์) เพื่อให้ผู้บริหารสแกนได้เร็ว
จำกัดตัวกรอง ให้เป็น global และคงค่า:
ถ้าตัวกรองจะเปลี่ยนคำนิยามเมตริก อย่าให้ในภาพรวม—ผลักไปยัง drill-down views
รวมแผงเล็กๆ สำหรับแต่ละระดับ: “สิ่งใดสัมพันธ์กับการยอมรับที่สูงขึ้นในช่วงนี้?” ตัวอย่าง:
ทำให้อธิบายได้: เลือกข้อความแบบ “บัญชีที่ตั้งค่า X ใน 3 วันแรกรักษาได้ดีขึ้น 18pp” แทนผลลัพธ์จากโมเดลที่ไม่ชัดเจน
วาง การ์ด KPI ตามระดับ ด้านบน (activation, retention, depth), กราฟแนวโน้มหนึ่งหน้าจอตรงกลาง, และ ตัวขับเคลื่อน + การดำเนินการถัดไป ด้านล่าง ทุกวิดเจ็ตต้องตอบคำถามเดียว—มิฉะนั้นไม่ควรอยู่ในสรุปสำหรับผู้บริหาร
แดชบอร์ดระดับช่วยจัดลำดับความสำคัญ แต่การทำงานจริงเกิดขึ้นเมื่อคุณคลิกเข้าไปดู ทำไม ระดับเปลี่ยนและ ใคร ต้องการการดูแล ออกแบบ drill-down ให้เป็นเส้นทางนำ: ระดับ → เซ็กเมนต์ → บัญชี → ผู้ใช้
เริ่มด้วยตารางภาพรวมระดับ แล้วให้ผู้ใช้ตัดให้แคบลงเป็นเซ็กเมนต์ที่มีความหมายโดยไม่ต้องสร้างรายงานเอง ตัวกรองทั่วไป:
แต่ละหน้าเซ็กเมนต์ควรตอบ: “บัญชีใดที่ขับคะแนนระดับนี้ขึ้นหรือลง?” รวมรายการอันดับบัญชีพร้อมการเปลี่ยนแปลงคะแนนและฟีเจอร์ที่มีส่วนสำคัญ
โปรไฟล์บัญชีควรรู้สึกเหมือนแฟ้มคดี:
ทำให้สแกนได้ง่าย: แสดงการเปลี่ยนแปลง (“+12 สัปดาห์นี้”) และใส่หมายเหตุเหตุการณ์ที่ทำให้เกิดสไปก์
จากหน้าบัญชี แสดงรายชื่อผู้ใช้ตามกิจกรรมล่าสุดและบทบาท การคลิกผู้ใช้จะแสดงการใช้ฟีเจอร์และบริบท last-seen
เพิ่มมุมมองโคฮอร์ตเพื่ออธิบายรูปแบบ: เดือนที่สมัคร โปรแกรม onboarding และ ระดับตอนสมัคร ช่วยให้ CS เปรียบเทียบของเหมือนกันแทนการผสมบัญชีใหม่กับบัญชีเก่า
รวมมุมมอง “ใครใช้ฟีเจอร์อะไร” ต่อระดับ: อัตราการยอมรับ ความถี่ และฟีเจอร์ที่กำลังขึ้น/ลง พร้อมรายการบัญชีที่ใช้/ไม่ใช้แต่ละฟีเจอร์
สำหรับ CS และ Sales ให้เพิ่มตัวเลือก export/share: ส่งออก CSV, บันทึกมุมมอง, และลิงก์ภายในที่แชร์ได้ เช่น /accounts/{id} ที่เปิดด้วยตัวกรองที่ตั้งไว้
แดชบอร์ดดีสำหรับเข้าใจการยอมรับ แต่ทีมจะลงมือเมื่อได้รับการกระตุ้นในเวลาที่เหมาะสม การแจ้งเตือนควรผูกกับระดับบัญชีเพื่อไม่ให้ CS และ Sales ถูกสแปมด้วยสัญญาณคุณค่าน้อย — หรือพลาดปัญหาในบัญชีมูลค่าสูง
เริ่มจากชุดเล็กๆ ของสัญญาณว่า “มีบางอย่างผิดปกติ”:
ทำให้สัญญาณเหล่านี้รับรู้ตามระดับ เช่น Enterprise อาจแจ้งเมื่อมีการลดลง 15% week-over-week ใน workflow หลัก ขณะที่ SMB อาจต้องลด 40% เพื่อหลีกเลี่ยงเสียงรบกวนจากการใช้งานเป็นครั้งคราว
การแจ้งเตือนการขยายควรเน้นบัญชีที่โตขึ้นเป็นมูลค่า:
เกณฑ์ต่างกันตามระดับ: ผู้ใช้ power คนเดียวอาจสำคัญสำหรับ SMB ในขณะที่ Enterprise ต้องการการยอมรับข้ามทีม
ส่งการแจ้งเตือนไปยังที่ที่งานเกิดขึ้น:
ให้เพย์โหลดที่ลงมือได้: ชื่อบัญชี ระดับ สิ่งที่เปลี่ยน ช่วงเปรียบเทียบ และลิงก์ไปยังมุมมองลงลึก เช่น /accounts/{account_id}
การแจ้งเตือนทุกอันต้องมีผู้รับผิดชอบและ playbook สั้นๆ: ใครตอบ ข้อเช็ค 2–3 ข้อแรก (ความสดของข้อมูล การปล่อยล่าสุด การเปลี่ยนแปลงสิทธิ์ผู้ดูแล) และการติดต่อหรือคำแนะนำในแอปที่แนะนำ
บันทึก playbook ข้างๆ นิยามเมตริกเพื่อให้การตอบสนองคงเส้นคงวาและการแจ้งเตือนยังน่าเชื่อถือ
ถ้าเมตริกการยอมรับขับการตัดสินใจตามระดับ (CS outreach, การตั้งราคา, แผนงาน) ข้อมูลที่ป้อนต้องมีกลไกดูแล เพียงชุดเล็กของการตรวจสอบและนิสัยการกำกับจะป้องกัน "การลดลงปริศนา" ในแดชบอร์ดและรักษาความสอดคล้องของผู้มีส่วนได้ส่วนเสีย
ตรวจสอบเหตุการณ์ให้เร็วที่สุด (SDK ฝั่งไคลเอ็นต์, API gateway, หรือ ingestion worker) ปฏิเสธหรือกักเหตุการณ์ที่ไม่น่าเชื่อถือ
ตรวจสอบเช่น:
account_id หรือ user_id (หรือค่าไม่พบในตารางบัญชี)tier ที่ไม่อยู่ใน enum ที่อนุญาตเก็บตาราง quarantine เพื่อดูเหตุการณ์ไม่ดีโดยไม่ปนเปื้อนข้อมูลวิเคราะห์
การติดตามการยอมรับต้องการความตรงเวลา เหตุการณ์มาช้าทำให้การใช้งานรายสัปดาห์และ rollup ระดับบัญชีผิดรูป ตรวจสอบ:
ส่งมอนิเตอร์ไปยังช่อง on-call ไม่ใช่ทุกคน
การ retry เกิดขึ้น (เครือข่ายมือถือ webhook redelivery batch replay) ทำให้ ingestion รองรับ idempotency โดยใช้ idempotency_key หรือ event_id ที่คงที่ และ dedupe ในช่วงเวลาหนึ่ง
การรวมควรรันซ้ำได้โดยไม่ถูกนับซ้ำ
สร้างพจนานุกรมที่นิยามเมตริกแต่ละตัว (อินพุต ฟิลเตอร์ ช่วงเวลา กฎการอ้างระดับ) และถือเป็นแหล่งเดียวของความจริง เชื่อมแดชบอร์ดและเอกสารกับพจนานุกรมนั้น
เพิ่ม audit logs สำหรับการเปลี่ยนแปลงนิยามเมตริกและกฎการให้คะแนน—ใครเปลี่ยนอะไร เมื่อไร และทำไม—เพื่ออธิบายความเปลี่ยนแปลงของแนวโน้มได้เร็ว
การวิเคราะห์การยอมรับมีประโยชน์ต่อเมื่อผู้ใช้เชื่อมั่น วิธีปลอดภัยคือออกแบบการติดตามให้ตอบคำถามการยอมรับโดยเก็บข้อมูลที่ละเอียดอ่อนน้อยที่สุด และทำให้ "ใครเห็นอะไร" เป็นฟีเจอร์สำคัญ
เริ่มด้วยตัวระบุที่พอสำหรับ insight: account_id, user_id (หรือตัวระบุ pseudonymous), timestamp, feature และชุดคุณสมบัติพฤติกรรมเล็กๆ (plan, tier, platform) หลีกเลี่ยงการจับชื่อ ที่อยู่อีเมล ข้อความฟรี หรือข้อมูลที่อาจมีความลับ
ถ้าต้องวิเคราะห์ระดับผู้ใช้ ให้เก็บตัวระบุผู้ใช้แยกจาก PII และเชื่อมต่อเมื่อต้องการเท่านั้น พิจารณา IP และตัวระบุอุปกรณ์เป็นข้อมูลอ่อนไหว ถ้าไม่จำเป็นสำหรับการให้คะแนน อย่าเก็บ
กำหนดบทบาทการเข้าถึงชัดเจน:
ตั้งค่าเริ่มต้นเป็นมุมมองสรุป รวมมุมมองระดับผู้ใช้เป็นสิทธิ์พิเศษ และซ่อนฟิลด์ที่อ่อนไหว (อีเมล ชื่อเต็ม id ภายนอก) เว้นแต่บทบาทต้องการจริงๆ
รองรับคำขอลบโดยสามารถลบประวัติเหตุการณ์ของผู้ใช้ (หรือลดรูปแบบเป็นนิรนาม) และลบข้อมูลบัญชีเมื่อสัญญาสิ้นสุด
ใช้กฎการเก็บรักษา (เช่น เก็บ raw events N วัน เก็บ aggregates นานกว่า) และบันทึกความยินยอมและความรับผิดชอบในการประมวลผลข้อมูลที่เกี่ยวข้อง
วิธีที่เร็วที่สุดในการเห็นคุณค่าคือเลือกสถาปัตยกรรมที่ตรงกับที่ข้อมูลของคุณอยู่แล้ว คุณสามารถพัฒนาได้ภายหลัง—สิ่งที่สำคัญคือให้ข้อมูลเชิงระดับบัญชีที่เชื่อถือได้เข้าถึงผู้คนได้เร็ว
Warehouse-first analytics: เหตุการณ์ไหลเข้า warehouse (เช่น BigQuery/Snowflake/Postgres) แล้วคำนวณเมตริกการยอมรับและให้บริการกับเว็บแอป เหมาะถ้าคุณใช้ SQL มีนักวิเคราะห์ หรืออยากมีแหล่งความจริงเดียวแบ่งปันกับรายงานอื่น
App-first analytics: เว็บแอปของคุณเขียนเหตุการณ์ไปยังฐานข้อมูลของแอปและคำนวณเมตริกภายในแอป สามารถเร็วกว่าสำหรับผลิตภัณฑ์ขนาดเล็ก แต่เติบโตยากเมื่อปริมาณเหตุการณ์สูงและต้องการ reprocessing ประวัติ
ค่าเริ่มต้นที่ใช้งานได้สำหรับทีม SaaS ส่วนใหญ่คือ warehouse-first พร้อมฐานข้อมูลปฏิบัติการขนาดเล็กสำหรับการกำหนดค่า (tiers, นิยามเมตริก, กฎการแจ้งเตือน)
ส่งมอบเวอร์ชันแรกด้วย:
3–5 เมตริก (เช่น บัญชีที่ใช้งาน, การใช้ฟีเจอร์หลัก, คะแนนการยอมรับ, retention รายสัปดาห์, เวลาไปถึงค่าแรก)
หน้าภาพรวมระดับหนึ่งหน้า: คะแนนการยอมรับตามระดับ + แนวโน้ม
หน้าบัญชีหนึ่งหน้า: ระดับปัจจุบัน กิจกรรมล่าสุด ฟีเจอร์ที่ใช้มากสุด และคำอธิบายสั้นๆ ว่า “ทำไมคะแนนเป็นแบบนี้”
เพิ่มช่องทางรับฟีดแบ็กเร็ว: ให้ Sales/CS ติดธง “ดูผิด” จากแดชบอร์ดโดยตรง เวอร์ชันนิยามเมตริกเพื่อแก้สูตรโดยไม่แก้ประวัติอย่างเงียบๆ เปิดตัวเป็นกลุ่ม (ทีมหนึ่ง → ทั้งองค์กร) และเก็บ changelog ของการอัปเดตเมตริกในแอป (เช่น /docs/metrics) เพื่อให้ผู้มีส่วนได้ส่วนเสียรู้ว่าเขากำลังดูอะไร
ถ้าคุณต้องการย้ายจาก “สเปค” ไปยังแอปภายในที่ใช้งานได้เร็ว แนวทาง vibe-coding อาจช่วยได้—โดยเฉพาะในเฟส MVP ที่คุณกำลังยืนยันคำนิยาม ไม่ใช่ปรับโครงสร้างพื้นฐานให้สมบูรณ์
กับ Koder.ai ทีมสามารถต้นแบบเว็บแอปการวิเคราะห์การยอมรับผ่านอินเทอร์เฟซแชทพร้อมการสร้างโค้ดที่แก้ไขได้จริง เหมาะกับโปรเจกต์แบบนี้เพราะขอบเขตครอบคลุม (React UI, เลเยอร์ API, โมเดลข้อมูล Postgres, และงานสรุปรายตาราง) และมักวิวัฒนาการเร็วเมื่อผู้มีส่วนได้ส่วนเสียบรรจบกัน
เวิร์กโฟลว์ตัวอย่าง:
เพราะ Koder.ai รองรับการปรับใช้/โฮสต์ โดเมนที่กำหนดเอง และการส่งออกรหัส มันจึงเป็นทางเลือกที่ใช้งานได้จริงเพื่อให้ได้ MVP ภายในองค์กรที่น่าเชื่อถือ ในขณะที่ยังคงตัวเลือกสถาปัตยกรรมระยะยาวเปิดไว้
เริ่มจากคำนิยามร่วมกันของการยอมรับในรูปแบบลำดับการใช้งาน:
จากนั้นทำให้คำนิยามนี้ รับรู้ตามระดับบัญชี (เช่น SMB เปิดใช้งานภายใน 7 วัน ขณะที่ Enterprise อาจต้องการการกระทำของผู้ดูแลระบบร่วมกับการกระทำของผู้ใช้ปลายทาง)
เพราะแต่ละระดับพฤติกรรมต่างกัน ตัวชี้วัดเดียวอาจ:
การแบ่งตามระดับช่วยให้ตั้งเป้าหมายที่เป็นจริง เลือก north star ที่เหมาะสมต่อแต่ละระดับ และตั้งการแจ้งเตือนที่ตรงกับบัญชีมูลค่าสูง
ใช้ชุดกฎที่เป็นเชิงกำหนดและจดไว้:
valid_from / valid_toวิธีนี้จะป้องกันไม่ให้แดชบอร์ดเปลี่ยนความหมายเมื่อบัญชีอัปเกรดหรือดาวน์เกรด
เลือกระบบผลลัพธ์หลักหนึ่งตัวต่อแต่ละระดับที่สะท้อนมูลค่าจริง:
ทำให้มันนับได้ ยากต่อการเล่นเกม และเชื่อมโยงชัดเจนกับผลลัพธ์ของลูกค้า — ไม่ใช่แค่คลิก
กำหนดขั้นตอนชัดเจนและกฎการมีสิทธิ์เพื่อป้องกันการตีความคลาดเคลื่อน ตัวอย่าง:
ติดตามชุดเหตุการณ์เส้นทางหลักเล็กๆ ก่อน ไม่ใช่ทุกคลิก ตัวเริ่มต้นที่ใช้งานได้:
signup_completeduser_invited, invite_acceptedfirst_value_received (กำหนด “aha” ให้ชัดเจน)ใส่คุณสมบัติที่ทำให้การแบ่งกลุ่มและการอ้างต้นมีความน่าเชื่อถือ:
ใช้ทั้งสองแบบ:
Snapshots มักเก็บผู้ใช้ที่ใช้งาน รายการฟีเจอร์หลัก ค่าส่วนประกอบของคะแนนการยอมรับ และระดับบัญชีของวันนั้น — เพื่อให้การเปลี่ยนแปลงระดับบัญชีไม่เขียนทับการรายงานในอดีต
ทำให้มันเรียบง่าย อธิบายได้ และคงที่:
core_action ใน 3 วันแยกต่างหากใน 14 วัน)สรุปผลตามระดับโดยใช้การกระจาย (median, percentiles, % ที่เกินเกณฑ์) ไม่ใช่แค่ค่าเฉลี่ย
ทำให้การแจ้งเตือนมีความจำเพาะตามระดับและลงมือได้:
ส่งการแจ้งเตือนไปยังช่องที่งานเกิดขึ้น (Slack/email สำหรับกรณีฉุกเฉิน, สรุปเป็นประจำสำหรับความเร่งด่วนน้อย) และแนบข้อมูลที่ทำให้ลงมือได้: ชื่อบัญชี, ระดับ, สิ่งที่เปลี่ยน, หน้าลงลึกเช่น /accounts/{account_id}
ปรับข้อกำหนดตามระดับ (เช่น Enterprise อาจต้องการการกระทำของแอดมินและผู้ใช้ปลายทาง)
key_feature_used (หรือเหตุการณ์แยกตามฟีเจอร์)integration_connectedให้ความสำคัญกับเหตุการณ์ที่แสดงความคืบหน้าไปสู่ผลลัพธ์ มากกว่าการโต้ตอบ UI ทุกอย่าง
account_id (จำเป็น)user_id (จำเป็นเมื่อเกี่ยวข้องกับบุคคล)tier (จับค่าในเวลาที่เหตุการณ์เกิด)plan / SKU (ถ้าจำเป็น)role (owner/admin/member)workspace_id, feature_name, source, timestampรักษาการตั้งชื่อให้สอดคล้อง (snake_case) เพื่อไม่ให้การสืบค้นกลายเป็นโปรเจกต์แปลภาษา