04 เม.ย. 2568·4 นาที
วิธีสร้างเว็บแอปเพื่อติดตามความน่าเชื่อถือของเครื่องมือภายใน
เรียนรู้การออกแบบและสร้างเว็บแอปเพื่อติดตามความน่าเชื่อถือของเครื่องมือภายในด้วย SLIs/SLOs, เวิร์กโฟลว์เหตุการณ์, แดชบอร์ด, การแจ้งเตือน และการรายงาน
เรียนรู้การออกแบบและสร้างเว็บแอปเพื่อติดตามความน่าเชื่อถือของเครื่องมือภายในด้วย SLIs/SLOs, เวิร์กโฟลว์เหตุการณ์, แดชบอร์ด, การแจ้งเตือน และการรายงาน
ก่อนจะเลือกเมตริกหรือสร้างแดชบอร์ด ให้ตัดสินใจก่อนว่าแอปความน่าเชื่อถือรับผิดชอบอะไร—และไม่รับผิดชอบอะไร ขอบเขตที่ชัดเจนป้องกันไม่ให้เครื่องมือกลายเป็น “พอร์ตัลปฏิบัติการรวม” ที่ไม่มีใครเชื่อถือ
เริ่มจากการลงรายการเครื่องมือภายในที่แอปจะครอบคลุม (เช่น ระบบตั๋ว, เงินเดือน, การบูรณาการ CRM, ท่อข้อมูล) และทีมที่เป็นเจ้าของหรือพึ่งพาเครื่องมือเหล่านั้น ระบุขอบเขตอย่างชัดเจน: “เว็บไซต์ที่ลูกค้าเห็น” อาจอยู่นอกขอบเขต ขณะที่ “คอนโซลผู้ดูแลภายใน” อยู่ในขอบเขต
องค์กรต่างกันใช้คำนี้ต่างกัน เขียนคำจำกัดความแบบใช้งานได้เป็นภาษาง่ายๆ—โดยปกติจะเป็นผสมของ:
ถ้าทีมยังเห็นต่าง แอปจะจบลงด้วยการเปรียบเทียบสิ่งไม่เท่ากัน
เลือก 1–3 ผลลัพธ์หลัก เช่น:
ผลลัพธ์เหล่านี้จะชี้นำสิ่งที่คุณวัดและวิธีการนำเสนอ
ลงรายการผู้ที่จะใช้แอปและการตัดสินใจที่พวกเขาทำ: วิศวกรที่สืบค้นเหตุการณ์, ฝ่ายสนับสนุนที่ยกระดับปัญหา, ผู้จัดการที่ทบทวนแนวโน้ม, และผู้มีส่วนได้ส่วนเสียที่ต้องการอัปเดตสถานะ สิ่งนี้จะกำหนดคำศัพท์ สิทธิ์ และระดับรายละเอียดที่แต่ละมุมมองควรแสดง
การติดตามความน่าเชื่อถือได้ผลเฉพาะเมื่อทุกคนเห็นตรงกันว่า “ดี” คืออะไร เริ่มจากแยกคำสามคำที่ฟังคล้ายกันออกจากกัน
SLI (Service Level Indicator) คือการวัด: “ร้อยละของคำขอที่สำเร็จเท่าไหร่?” หรือ “หน้าโหลดใช้เวลานานเท่าไร?”
SLO (Service Level Objective) คือเป้าหมายสำหรับการวัดนั้น: “99.9% ของคำขอสำเร็จใน 30 วัน”
SLA (Service Level Agreement) คือคำมั่นสัญญาที่มีผลตามมา มักเป็นภายนอกและมีเครดิตหรือบทลงโทษ สำหรับเครื่องมือภายใน คุณมักตั้ง SLOs เพื่อจัดความคาดหวังโดยไม่ต้องผูกเป็นสัญญา
ทำให้เปรียบเทียบได้ระหว่างเครื่องมือและอธิบายง่าย เกณฑ์ปฏิบัติได้คือ:
หลีกเลี่ยงการเพิ่มเมตริกมากเกินไปจนกว่าคุณจะตอบได้ว่า: “เมตริกนี้จะขับเคลื่อนการตัดสินใจอะไร?”
ใช้หน้าต่างแบบ rolling เพื่อให้ scorecard อัปเดตต่อเนื่อง:
แอปของคุณควรเปลี่ยนเมตริกเป็นการกระทำ กำหนดระดับความรุนแรง (เช่น Sev1–Sev3) และทริกเกอร์ชัดเจน เช่น:
คำนิยามเหล่านี้ทำให้การแจ้งเตือน ไทม์ไลน์เหตุการณ์ และการติดตามงบข้อผิดพลาดสอดคล้องกันข้ามทีม
แอปติดตามความน่าเชื่อถือเชื่อได้เท่าที่ข้อมูลเบื้องหลังเชื่อถือได้ ก่อนสร้างท่อ ingestion ให้ทำแผนที่สัญญาณทุกอย่างที่คุณจะใช้เป็น “ความจริง” และจดว่าคำถามใดที่สัญญาณแต่ละตัวตอบได้ (ความพร้อมใช้งาน, ความหน่วง, ข้อผิดพลาด, ผลกระทบจากการ deploy, การตอบสนองเหตุการณ์)
หลายทีมครอบคลุมพื้นฐานได้ด้วยการผสมผสาน:
ระบุระบบที่เป็น authoritative ให้ชัดเจน ตัวอย่างเช่น “uptime SLI” ของคุณอาจมาจาก synthetic probes เท่านั้น ไม่ใช่จาก logs ของเซิร์ฟเวอร์
ตั้งความถี่การอัปเดตตามกรณีการใช้งาน: แดชบอร์ดอาจรีเฟรชทุก 1–5 นาที ขณะที่ scorecard คำนวณชั่วโมงละครั้งหรือรายวัน
สร้าง ID ที่สม่ำเสมอสำหรับ tools/services, environments (prod/stage), และ owners ตกลงกฎการตั้งชื่อแต่เนิ่นๆ เพื่อไม่ให้ “Payments-API”, “payments_api”, และ “payments” กลายเป็นเอนทิตีคนละตัว
วางแผนว่าจะเก็บอะไรนานแค่ไหน (เช่น raw events 30–90 วัน, daily aggregates 12–24 เดือน) หลีกเลี่ยงการนำ payload ที่เป็นข้อมูลอ่อนไหวเข้ามา; เก็บเฉพาะ metadata ที่จำเป็นสำหรับการวิเคราะห์ความน่าเชื่อถือ (timestamps, status codes, buckets latency, incident tags)
สคีมาของคุณควรทำให้สองสิ่งง่าย: ตอบคำถามวันต่อวัน (“เครื่องมือนี้สุขภาพดีไหม?”) และสร้างสภาพเหตุการณ์ในอดีตเมื่อเกิดเหตุ (“อาการเริ่มเมื่อไหร่ ใครเปลี่ยนอะไร อะไรแจ้งเตือน?”) เริ่มจากชุดเอนทิตีหลักขนาดเล็กและทำให้ความสัมพันธ์ชัดเจน
แนวทางปฏิบัติพื้นฐานคือ:
โครงสร้างนี้รองรับแดชบอร์ด (“tool → สถานะปัจจุบัน → เหตุการณ์ล่าสุด”) และการเจาะลึก (“incident → events → checks และ metrics ที่เกี่ยวข้อง”)
เพิ่มฟิลด์ audit ที่จำเป็นสำหรับความรับผิดชอบและประวัติ:
created_by, created_at, updated_atstatus พร้อมการติดตามการเปลี่ยนสถานะ (ในตาราง Event หรือประวัติเฉพาะ)สุดท้าย ให้มี tags ยืดหยุ่นสำหรับการกรองและรายงาน (เช่น ทีม, ความสำคัญ, ระบบ, ความสอดคล้อง) ตารางเชื่อม tool_tags (tool_id, key, value) ช่วยให้การติดแท็กสอดคล้องและทำให้การคำนวณคะแนนรวมง่ายขึ้นในภายหลัง
ตัวติดตามความน่าเชื่อถือควร “น่าเบื่อ” ในความหมายที่ดี: รันง่าย เปลี่ยนแปลงง่าย และดูแลได้ง่าย สแต็กที่ “ถูกต้อง” มักเป็นสแต็กที่ทีมของคุณดูแลได้โดยไม่ต้องฮีโร่
เลือกเว็บเฟรมเวิร์กหลักที่ทีมรู้จัก—Node/Express, Django, หรือ Rails ต่างก็เป็นตัวเลือกที่ดี ให้ความสำคัญกับ:
ถ้าคุณกำลังรวมกับระบบภายใน (SSO, ตั๋ว, แชท) ให้เลือกระบบนิเวศที่การผนวกรวมทำได้ง่ายที่สุด
ถ้าต้องการเร่งการทำต้นแบบ แพลตฟอร์มโค้ดแบบ vibe-coding อย่าง Koder.ai อาจเป็นจุดเริ่มต้นที่ใช้งานได้จริง: คุณอธิบายเอนทิตี (tools, checks, SLOs, incidents), เวิร์กโฟลว์ (alert → incident → postmortem) และแดชบอร์ดในแชท แล้วสร้าง scaffold แอปเว็บที่ทำงานได้อย่างรวดเร็ว เนื่องจาก Koder.ai มักเน้น React ฝั่งหน้าและ Go + PostgreSQL ฝั่งหลัง จึงสอดคล้องกับสแต็กเริ่มต้นที่หลายทีมชอบ—และคุณสามารถส่งออกซอร์สโค้ดเมื่อย้ายไปพายไลน์ด้วยตนเองได้
สำหรับแอปภายใน ส่วนใหญ่ PostgreSQL เป็นค่าดีฟอลต์ที่เหมาะสม: รองรับการรายงานเชิงสัมพันธ์, คิวรีตามเวลา, และการตรวจสอบบัญชีได้ดี
เพิ่มส่วนประกอบอื่นเมื่อช่วยแก้ปัญหาจริง:
ตัดสินใจระหว่าง:
ไม่ว่าเลือกแบบไหน ให้แยก dev/staging/prod และทำ CI/CD อัตโนมัติ เพื่อการเปลี่ยนแปลงไม่ไปเปลี่ยนตัวเลขความน่าเชื่อถืออย่างเงียบ ๆ หากใช้แพลตฟอร์ม (รวมถึง Koder.ai) ให้มองหาฟีเจอร์แยกสภาพแวดล้อม การปรับใช้ และการ rollback ที่รวดเร็วเพื่อให้คุณวนปรับได้อย่างปลอดภัยโดยไม่ทำลายตัวติดตาม
เอกสารการกำหนดค่าไว้ที่เดียว: environment variables, secrets, feature flags มีคู่มือสั้น ๆ การรันในเครื่อง และ runbook ขั้นต่ำ (ต้องทำอย่างไรถ้า ingestion หยุด, คิวค้าง, หรือฐานข้อมูลถึงขีดจำกัด) หน้าสั้น ๆ ใน /docs มักเพียงพอ
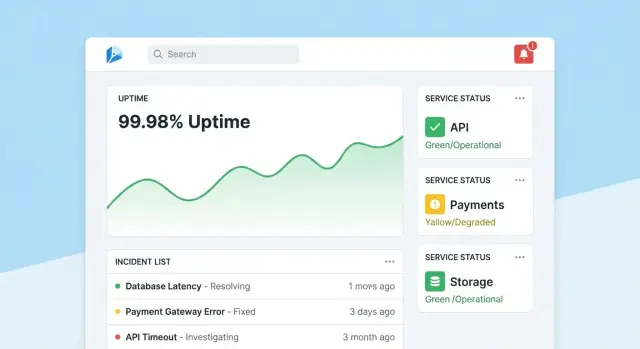
แอปติดตามความน่าเชื่อถือสำเร็จเมื่อผู้ใช้ตอบคำถามสองข้อในไม่กี่วินาที: “เราปลอดภัยไหม?” และ “ฉันต้องทำอะไรต่อ?” ออกแบบหน้าจอรอบๆ การตัดสินใจเหล่านั้น โดยมีการนำทางชัดเจนจากภาพรวม → เครื่องมือเฉพาะ → เหตุการณ์เฉพาะ
ให้หน้าแรกเป็นศูนย์บัญชาการแบบกะทัดรัด นำด้วยสรุปสุขภาพโดยรวม (เช่น จำนวนเครื่องมือที่ผ่าน SLOs, เหตุการณ์ที่ยังเปิด, ความเสี่ยงปัจจุบันที่ใหญ่ที่สุด) แล้วแสดงเหตุการณ์และการแจ้งเตือนล่าสุดพร้อมป้ายสถานะ
ทำให้มุมมองเริ่มต้นสงบ: ไฮไลต์เฉพาะสิ่งที่ต้องการความสนใจ ให้แต่ละไทล์สามารถเจาะลึกไปยังเครื่องมือหรือเหตุการณ์ที่ได้รับผลกระทบได้ทันที
แต่ละหน้าควอตอบว่า “เครื่องมือนี้น่าเชื่อถือพอไหม?” และ “ทำไม/ทำไมไม่?” รวมถึง:
ออกแบบกราฟให้คนทั่วไปเข้าใจ: แสดงหน่วย, มาร์กเส้นเกณฑ์ SLO, และคำอธิบายสั้น ๆ (tooltip) แทนการควบคุมเชิงเทคนิคที่หนาแน่น
หน้ากิจกรรมเป็นบันทึกที่ดำเนินการได้ ให้มีไทม์ไลน์ (อีเวนต์ที่บันทึกโดยอัตโนมัติ เช่น แจ้งเตือน, การรับทราบ, การบรรเทา), อัปเดตจากคน, ผู้ใช้ที่ได้รับผลกระทบ, และการดำเนินการที่ทำ
ทำให้อัปเดตง่าย: กล่องข้อความเดียว, สถานะที่กำหนดไว้ล่วงหน้า (Investigating/Identified/Monitoring/Resolved), และหมายเหตุภายในเมื่อจำเป็น เมื่อปิดเหตุการณ์ ให้มีปุ่ม “เริ่ม postmortem” ที่เติมข้อมูลจากไทม์ไลน์ให้บางส่วน
ผู้ดูแลต้องการหน้าจอเรียบง่ายสำหรับจัดการ tools, checks, SLO targets, และ owners ปรับเพื่อความถูกต้อง: ค่าเริ่มต้นที่สมเหตุสมผล, การตรวจสอบความถูกต้อง, และคำเตือนเมื่อการเปลี่ยนแปลงมีผลต่อการรายงาน แสดง “แก้ไขล่าสุด” ให้เห็นได้ชัดเพื่อให้คนเชื่อถือตัวเลข
ข้อมูลความน่าเชื่อถือจะยังคงมีประโยชน์เมื่อผู้คนเชื่อถือได้ นั่นหมายถึงการผูกทุกการเปลี่ยนแปลงกับตัวตน จำกัดผู้ที่แก้ไขสำคัญได้ และเก็บประวัติที่ชัดเจนให้กลับไปตรวจสอบได้ในภายหลัง
สำหรับเครื่องมือภายใน ให้ตั้งค่า SSO (SAML) หรือ OAuth/OIDC ผ่านผู้ให้บริการ IdP ของคุณ (Okta, Azure AD, Google Workspace) เพื่อลดการจัดการรหัสผ่านและทำให้ onboarding/offboarding เป็นอัตโนมัติ
รายละเอียดเชิงปฏิบัติ:
เริ่มจากบทบาทง่าย ๆ แล้วเพิ่มกฎละเอียดเมื่อต้องการ:
ปกป้องการกระทำที่เปลี่ยนผลลัพธ์ความน่าเชื่อถือหรือเรื่องเล่าการรายงาน:
บันทึกการแก้ไข SLOs, checks, และฟิลด์เหตุการณ์ทุกครั้งพร้อม:
ทำให้ log ค้นหาได้และมองเห็นจากหน้ารายละเอียดที่เกี่ยวข้อง (เช่น หน้ากิจกรรมแสดงประวัติการเปลี่ยนทั้งหมด) สิ่งนี้ช่วยให้การทบทวนมีข้อเท็จจริงและลดการถกเถียงใน postmortem
การมอนิเตอร์เป็น “ชั้นเซนเซอร์” ของแอป: เปลี่ยนพฤติกรรมจริงเป็นข้อมูลที่เชื่อถือได้ สำหรับเครื่องมือภายใน synthetic checks มักเป็นเส้นทางที่เร็วที่สุดเพราะคุณควบคุมความหมายของคำว่า “สุขภาพ” ได้
เริ่มจากชุดเช็คประเภทเล็ก ๆ ที่ครอบคลุมแอปภายในโดยทั่วไป:
ทำให้เช็คมีความแน่นอน ถ้าการตรวจสอบอาจล้มเหลวเพราะเนื้อหาที่เปลี่ยนได้ คุณจะสร้างเสียงรบกวนและลดความเชื่อมั่น
สำหรับแต่ละการรันเช็ค เก็บ:
เก็บข้อมูลเป็น เหตุการณ์แบบ time-series (แถวต่อการรันเช็ค) หรือ การสรุปเป็นช่วงเวลา (เช่น rollups ต่อนาทีที่มีการนับและ p95 latency) ข้อมูลเหตุการณ์ดิบดีต่อการดีบัก; rollups ดีสำหรับแดชบอร์ดเร็ว หลายทีมเก็บทั้งสองแบบ: เก็บ raw events 7–30 วัน และเก็บ rollups ระยะยาว
ผลลัพธ์เช็คที่ขาดหายไม่ควรถูกตีความเป็น “down” โดยอัตโนมัติ ให้มีสถานะ unknown สำหรับกรณีเช่น:
สิ่งนี้ป้องกันการบันทึก downtime เกินจริงและทำให้ช่องว่างการมอนิเตอร์เป็นปัญหาที่มองเห็นได้
ใช้ worker แบบแบ็กกราวด์ (กำหนดงานแบบ cron, คิว) เพื่อรันเช็คเป็นช่วงเวลาคงที่ (เช่น ทุก 30–60 วินาทีสำหรับเครื่องมือสำคัญ) ใส่ timeouts, การลองใหม่พร้อม backoff, และจำกัด concurrent เพื่อไม่ให้ checker โหลดระบบภายในเกินไป จงบันทึกผลการรันทุกรายการ—แม้จะล้มเหลว—เพื่อให้แดชบอร์ด uptime แสดงทั้งสถานะปัจจุบันและประวัติที่เชื่อถือได้
การแจ้งเตือนคือจุดที่การติดตามความน่าเชื่อถือกลายเป็นการกระทำ เป้าหมายคือ: แจ้งคนที่เหมาะสม ด้วยบริบทที่เหมาะสม ในเวลาที่เหมาะสม—โดยไม่รบกวนทุกคน
เริ่มจากกฎแจ้งเตือนที่เชื่อมตรงกับ SLIs/SLOs มีสองแบบที่ใช้งานได้จริง:
สำหรับแต่ละกฎ ให้เก็บ “เหตุผล” ไว้พร้อมกับ “อะไรที่เกิดขึ้น”: SLO ไหนได้รับผล, หน้าต่างการประเมิน, และความรุนแรงที่ตั้งใจไว้
ส่งการแจ้งเตือนผ่านช่องทางที่ทีมใช้จริง (อีเมล, Slack, Microsoft Teams) ข้อความแต่ละฉบับควรรวม:
หลีกเลี่ยงการเทเมตริกดิบ ให้คำแนะนำสั้น ๆ ว่า “ขั้นตอนต่อไป” เช่น “ตรวจ deploy ล่าสุด” หรือ “เปิด logs”
นำไปใช้:
แม้เป็นเครื่องมือภายใน ผู้คนก็ต้องการการควบคุม เพิ่มการเลื่อนขั้นแบบแมนนวล (ปุ่มในหน้าการแจ้งเตือน/เหตุการณ์) และผสานกับเครื่องมือ on-call หากมี (เช่น PagerDuty/Opsgenie) หรืออย่างน้อยให้มีรายการหมุนเวียนที่กำหนดค่าได้เก็บไว้ในแอป
การจัดการเหตุการณ์เปลี่ยน “เราเห็นแจ้งเตือน” เป็นการตอบสนองที่แชร์ได้ สร้างฟีเจอร์นี้ในแอปเพื่อให้คนย้ายจากสัญญาณไปสู่การประสานงานโดยไม่ต้องกระโดดข้ามเครื่องมือ
ให้สร้างเหตุการณ์ได้โดยตรงจากการแจ้งเตือน หน้าเครื่องมือ หรือกราฟ uptime เติมฟิลด์สำคัญล่วงหน้า (service, environment, แหล่งที่มา, เวลาแรกที่เห็น) และมอบหมาย ID เหตุการณ์ที่ไม่ซ้ำ
ชุดฟิลด์เริ่มต้นที่ดีควรเบา: ความรุนแรง, ผลกระทบต่อผู้ใช้ (ทีมภายในที่ได้รับผล), เจ้าของปัจจุบัน, และลิงก์ไปยังการแจ้งเตือนที่ทริกเกอร์
ใช้วงชีวิตง่ายๆ ที่ตรงกับการทำงานจริงของทีม:
แต่ละการเปลี่ยนสถานะควรบันทึกว่าใครทำเมื่อไหร่ เพิ่มไทม์ไลน์อัปเดต (ข้อความสั้นพร้อม timestamp), รองรับไฟล์แนบ และลิงก์ไปยัง runbooks และตั๋ว (เช่น runbook ของ payments-retries หรือ ตั๋ว INC-1234) นี่จะเป็นเธรดเดียวสำหรับ “เกิดอะไรขึ้นและเราทำอะไรบ้าง”
ทำให้การเริ่ม postmortem เร็วและรูปแบบสอดคล้องกัน มีเทมเพลตที่รวม:
ผูกงานติดตามกลับไปยังเหตุการณ์ ติดตามความคืบหน้า และแสดงงานที่ค้างชำระบนแดชบอร์ดทีม หากรองรับการทบทวนเพื่อเรียนรู้ ให้มีโหมด “blameless” ที่มุ่งเป้าไปที่การเปลี่ยนแปลงระบบและกระบวนการมากกว่าความผิดพลาดของบุคคล
การรายงานคือจุดที่การติดตามความน่าเชื่อถือกลายเป็นการตัดสินใจ แดชบอร์ดช่วยผู้ปฏิบัติ สกอร์การ์ดช่วยผู้นำเข้าใจว่าเครื่องมือภายในดีขึ้นไหม พื้นที่ไหนควรลงทุน และ “ดี” คืออะไร
สร้างมุมมองที่สม่ำเสมอและทำซ้ำได้ต่อเครื่องมือ (และต่อทีมถ้าต้องการ) ที่ตอบคำถามอย่างรวดเร็ว:
เมื่อทำได้ ให้เพิ่มบริบทสั้น ๆ เช่น “SLO พลาดเพราะ 2 การ deploy” หรือ “downtime ส่วนใหญ่จาก dependency X” โดยไม่ต้องเปลี่ยนเป็นรีวิวเหตุการณ์เต็มรูปแบบ
ผู้นำมักไม่ต้องการ “ทุกอย่าง” เพิ่มตัวกรองสำหรับ ทีม, ความสำคัญของเครื่องมือ (เช่น Tier 0–3), และ หน้าต่างเวลา ให้แน่ใจว่าเครื่องมือเดียวกันสามารถปรากฏในการสรุปหลายแบบ (ทีมแพลตฟอร์มเป็นเจ้าของ แต่ทีมการเงินพึ่งพา)
ให้สรุประายสัปดาห์และรายเดือนที่แชร์นอกแอปได้:
รักษาเรื่องราวให้สอดคล้อง (“เปลี่ยนแปลงอะไรตั้งแต่ช่วงก่อนหน้า?” “ที่ไหนเราเกินงบ?”) หากต้องการคำอธิบายสำหรับผู้มีส่วนได้ส่วนเสีย ให้ลิงก์ไปยังคำแนะนำสั้น ๆ เกี่ยวกับ SLI/SLO (แสดงเป็นเอกสารอธิบาย ไม่ใช่ลิงก์)
ตัวติดตามความน่าเชื่อถือมักกลายเป็นแหล่งความจริง จัดการมันเหมือนระบบ production: ตั้งค่าเป็นค่าเริ่มต้นให้ปลอดภัย ทนต่อข้อมูลไม่ดี และกู้คืนได้ง่ายเมื่อเกิดปัญหา
ล็อกทุก endpoint แม้เป็น “ภายในเท่านั้น”
เก็บ credential ไว้นอกโค้ดและอย่าให้ปรากฏใน log
เก็บ secrets ใน secret manager และหมุนเวียน them ให้บ่อย ให้เว็บแอปสิทธิ์ฐานข้อมูลแบบ least-privilege: แยกบทบาทอ่าน/เขียน, จำกัดการเข้าถึงเฉพาะตารางที่จำเป็น, และใช้ credential ที่มีอายุสั้นเมื่อเป็นไปได้ เข้ารหัสข้อมูลระหว่างทาง (TLS) ระหว่างเบราว์เซอร์↔แอป และแอป↔ฐานข้อมูล
เมตริกมีประโยชน์เมื่อเหตุการณ์พื้นฐานเชื่อถือได้
เพิ่มการตรวจฝั่งเซิร์ฟเวอร์สำหรับ timestamps (timezone/clock skew), ฟิลด์ที่จำเป็น, และ idempotency keys เพื่อ deduplicate การลองใหม่ ติดตามข้อผิดพลาดการนำเข้าใน dead-letter queue หรือตาราง “quarantine” เพื่อไม่ให้เหตุการณ์ไม่ดีทำลายแดชบอร์ด
อัตโนมัติการ migration ฐานข้อมูลและทดสอบ rollback กำหนดเวลาแบ็กอัพ ทดสอบการคืนค่าเป็นประจำ และเอกสารแผนกู้คืนขั้นต่ำ (ใคร, ทำอะไร, ใช้เวลานานเท่าไร)
สุดท้าย ทำให้ตัวติดตามเองมีความน่าเชื่อถือ: เพิ่ม health checks, มอนิเตอร์สถานะคิวและความหน่วงฐานข้อมูลพื้นฐาน, และแจ้งเตือนเมื่อ ingestion ลดลงเป็นศูนย์โดยเงียบ ๆ
แอปติดตามความน่าเชื่อถือสำเร็จเมื่อผู้คนเชื่อถือและใช้งานจริง ถือการออกครั้งแรกเป็นวงเรียนรู้ ไม่ใช่การเปิดตัวครั้งใหญ่
เลือก 2–3 เครื่องมือภายในที่ใช้งานกว้างและมีเจ้าของชัดเจน ติดตั้งชุดเช็คน้อย ๆ (เช่น: availability หน้าแรก, การล็อกอินสำเร็จ, endpoint API สำคัญ) และเผยแพรแดชบอร์ดหนึ่งหน้าที่ตอบ: “มันใช้งานได้ไหม? ถ้าไม่ มีอะไรเปลี่ยนและใครเป็นเจ้าของ?”
เก็บพายลอตให้เห็นได้แต่จำกัด: หนึ่งทีมหรือกลุ่มผู้ใช้ power users เล็ก ๆ ก็พอสำหรับตรวจสอบฟลูว์
ใน 1–2 สัปดาห์แรก รวบรวม feedback เชิงรุกเกี่ยวกับ:
เปลี่ยน feedback เป็น backlog ที่ชัดเจน ปุ่ม “รายงานปัญหาในเมตริกนี้” บนแต่ละกราฟมักช่วยให้เห็น insight เร็วที่สุด
เพิ่มคุณค่าเป็นชั้น: เชื่อมกับเครื่องมือแชทสำหรับการแจ้งเตือน, แล้วเชื่อมกับระบบเหตุการณ์สำหรับการสร้างตั๋วอัตโนมัติ, แล้ว CI/CD สำหรับมาร์ก deploy แต่ละการผนวกรวมควรลดงานแมนนวลหรือย่นเวลาในการวินิจฉัย—มิฉะนั้นจะกลายเป็นความซับซ้อน
ถ้าคุณทำต้นแบบอย่างรวดเร็ว ให้พิจารณาใช้ Koder.ai ในโหมดวางแผนเพื่อแม็ปขอบเขตเริ่มต้น (เอนทิตี, บทบาท, เวิร์กโฟลว์) ก่อนสร้างจริง มันเป็นวิธีง่าย ๆ ในการทำ MVP ให้เข้มงวด—และเพราะคุณสามารถ snapshot และ rollback ได้ คุณจะวนปรับแดชบอร์ดและ ingestion อย่างปลอดภัยเมื่อทีมปรับคำนิยาม
ก่อนขยายไปยังทีมอื่น กำหนดตัวชี้วัดความสำเร็จ เช่น ผู้ใช้แดชบอร์ดที่ใช้งานรายสัปดาห์, เวลาลดลงในการตรวจพบ, การแจ้งเตือนซ้ำลดลง, หรือการทบทวน SLO เป็นประจำ เผยแพรโรดแมปสั้น ๆ และขยายทีละเครื่องมือพร้อมเจ้าของชัดเจนและการอบรม
เริ่มจากการกำหนด ขอบเขต (ระบุว่าเครื่องมือและสภาพแวดล้อมใดรวมอยู่) และคำนิยามการทำงานของคำว่า "ความน่าเชื่อถือ" (เช่น ความพร้อมใช้งาน, ความหน่วงเวลา, ข้อผิดพลาด) จากนั้นเลือกผลลัพธ์ 1–3 ข้อที่อยากปรับปรุง (เช่น ตรวจพบปัญหาเร็วขึ้น, รายงานชัดขึ้น) แล้วออกแบบหน้าจอแรกตามการตัดสินใจหลักที่ผู้ใช้ต้องทำ: “เราปลอดภัยไหม?” และ “ขั้นตอนต่อไปคืออะไร?”
SLI คือสิ่งที่วัด (เช่น % การร้องขอที่สำเร็จ, p95 latency)
SLO คือเป้าหมายของการวัดนั้น (เช่น 99.9% ใน 30 วัน)
SLA คือสัญญาอย่างเป็นทางการที่มีผลทางกฎหมาย/การเงิน (มักอยู่ภายนอก)
สำหรับเครื่องมือภายใน โดยทั่วไปตั้ง SLOs เพื่อจัดความคาดหวังโดยไม่ต้องใช้ภาพรวมแบบ SLA
ใช้ชุดเมตริกพื้นฐานที่เล็กและเปรียบเทียบได้ระหว่างเครื่องมือ:
ใช้หน้าต่างแบบ rolling เพื่อให้คะแนนอัปเดตอย่างต่อเนื่อง:
กำหนดทริกเกอร์ความรุนแรงชัดเจนผูกกับผลกระทบต่อผู้ใช้และระยะเวลา เช่น:
แผนผังแหล่งข้อมูลที่เป็น “แหล่งความจริง” สำหรับแต่ละคำถาม ตัวอย่างแหล่งข้อมูลที่ควรใช้:
ใช้ pull เมื่อต้องการดึงข้อมูลจากระบบที่สามารถโพลได้ตามเวลา (เช่น API ของ monitoring, ticketing)
ใช้ push (webhooks/events) สำหรับเหตุการณ์ปริมาณมากหรือใกล้เรียลไทม์ (เช่น deploys, alerts, อัปเดตเหตุการณ์)
แนวทางที่พบบ่อยคือแดชบอร์ดรีเฟรชทุก 1–5 นาที ในขณะที่ scorecards คำนวณชั่วโมงละครั้งหรือรายวัน
โครงสร้างข้อมูลทั่วไปมี:
บันทึกการแก้ไขที่มีผลสูงทุกครั้งด้วยข้อมูล ใคร, เมื่อไหร่, อะไรเปลี่ยน (ก่อน/หลัง), และ มาจากที่ไหน (UI/API/automation) ผสานกับการเข้าถึงแบบ role-based:
จัดการผลการตรวจสอบที่ขาดหายเป็นสถานะ unknown แยกต่างหาก ไม่ควรถือเป็น downtime ทันที สถานการณ์ที่อาจเกิด unknown เช่น: