04 พ.ค. 2568·2 นาที
ทฤษฎีฐานข้อมูลของ Jeffrey Ullman เบื้องหลังคิวรีที่เร็วและสเกลได้
แนวคิดหลักของ Jeffrey Ullman ขับเคลื่อนฐานข้อมูลสมัยใหม่: พีชคณิตเชิงสัมพันธ์ กฎการปรับแต่ง JOIN และการวางแผนแบบคอมไพเลอร์ ที่ช่วยให้ระบบสเกลได้
แนวคิดหลักของ Jeffrey Ullman ขับเคลื่อนฐานข้อมูลสมัยใหม่: พีชคณิตเชิงสัมพันธ์ กฎการปรับแต่ง JOIN และการวางแผนแบบคอมไพเลอร์ ที่ช่วยให้ระบบสเกลได้
คนส่วนใหญ่ที่เขียน SQL สร้างแดชบอร์ด หรือจูนคิวรีช้า ๆ ได้รับประโยชน์จากงานของ Jeffrey Ullman แม้จะไม่เคยได้ยินชื่อเขาก็ตาม Ullman เป็นนักวิทยาการคอมพิวเตอร์และผู้สอน งานวิจัยและตำราของเขาช่วยกำหนดวิธีที่ฐานข้อมูลอธิบายข้อมูล คิดเกี่ยวกับคิวรี และรันคิวรีเหล่านั้นอย่างมีประสิทธิภาพ
เมื่อเอนจินฐานข้อมูลแปลง SQL ของคุณเป็นสิ่งที่รันได้เร็ว มันอาศัยแนวคิดที่ต้องทั้งแม่นยำและยืดหยุ่น Ullman ช่วยทำให้ ความหมาย ของคิวรีเป็นทางการ (เพื่อให้ระบบสามารถเขียนใหม่ได้อย่างปลอดภัย) และเขาช่วยเชื่อมความคิดด้านฐานข้อมูลกับความคิดของคอมไพเลอร์ (เพื่อให้คิวรีถูกพาร์ซ จัดระเบียบ และแปลงเป็นขั้นตอนที่รันได้)
อิทธิพลนี้เงียบเพราะมันไม่ใช่ปุ่มในเครื่องมือ BI หรือฟีเจอร์ที่เห็นในคอนโซลคลาวด์ แต่มันแสดงออกเป็น:
JOIN ใหม่บทความนี้ใช้แนวคิดหลักของ Ullman เป็นทัวร์แนะนำภายในของฐานข้อมูลที่สำคัญสำหรับการใช้งานจริง: พีชคณิตเชิงสัมพันธ์อยู่ใต้ SQL อย่างไร วิธีการเขียนคิวรีใหม่ให้รักษาความหมายไว้ ทำไมตัวปรับแต่งแบบอิงต้นทุนตัดสินใจแบบที่เป็นอยู่ และอัลกอริทึม JOIN มักจะเป็นตัวกำหนดว่าจ็อบเสร็จในไม่กี่วินาทีหรือเป็นชั่วโมง
เราจะยกแนวคิดคล้ายคอมไพเลอร์บางอย่างมาด้วย—การพาร์ซ การเขียนใหม่ และการวางแผน—เพราะเอนจินฐานข้อมูลทำงานเหมือนคอมไพเลอร์ขั้นสูงกว่าที่หลายคนคิด
สัญญาสั้น ๆ: เราจะคงความถูกต้องของการอธิบายไว้ แต่หลีกเลี่ยงการพิสูจน์ที่หนักด้วยคณิตศาสตร์ เป้าหมายคือให้โมเดลทางความคิดที่ใช้งานได้ทันทีเมื่อต้องเจอปัญหาประสิทธิภาพ การขยาย หรือพฤติกรรมคิวรีที่งงงวย
ถ้าคุณเคยเขียน SQL แล้วคาดหวังว่ามันจะ "มีความหมายเดียว" คุณกำลังพึ่งพาแนวคิดที่ Jeffrey Ullman ช่วยทำให้เป็นที่นิยมและเป็นทางการ: แบบจำลองข้อมูลที่สะอาด และวิธีการที่แม่นยำในการบรรยายสิ่งที่คิวรีต้องการ
แก่นของแบบจำลองเชิงสัมพันธ์คือการมองข้อมูลเป็น ตาราง (relation) แต่ละตารางมี แถว (tuple) และ คอลัมน์ (attribute) ฟังดูชัดเจน แต่ส่วนสำคัญคือวินัยที่มันสร้างขึ้น:
กรอบนี้ทำให้สามารถคิดเรื่องความถูกต้องและประสิทธิภาพโดยไม่ต้องคาดเดา เมื่อคุณรู้ว่าตารางแทนอะไรและแถวถูกระบุอย่างไร คุณสามารถทำนายได้ว่า JOIN จะทำอะไร ความหมายของค่าซ้ำ และทำไมตัวกรองบางอย่างถึงเปลี่ยนผล
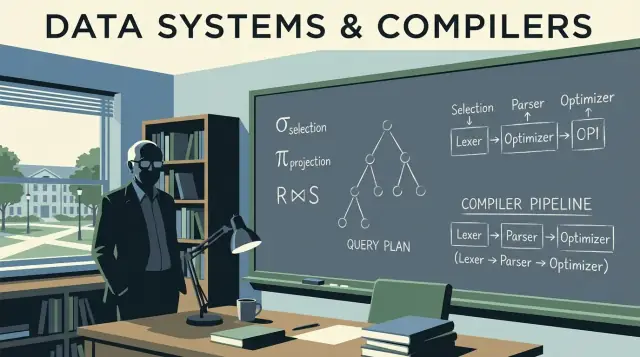
การสอนของ Ullman มักใช้ พีชคณิตเชิงสัมพันธ์ เป็นเครื่องคิดคำนวณคิวรี: ชุดของการดำเนินการเล็ก ๆ (select, project, join, union, difference) ที่รวมกันเพื่อแสดงสิ่งที่คุณต้องการ
เหตุผลที่สำคัญสำหรับการใช้กับ SQL: ฐานข้อมูลแปลง SQL เป็นรูปแบบเชิงพีชคณิตแล้ว เขียนใหม่ ให้เป็นรูปแบบเทียบเท่าอื่น ๆ คิวรีสองอันที่ดูต่างกันอาจเท่ากันเชิงพีชคณิต—นั่นคือเหตุผลที่ optimizer สามารถสลับลำดับ JOIN ดันตัวกรองลงไปก่อน หรือเอางานที่ทำซ้ำออกโดยยังคงความหมายไว้
SQL ส่วนใหญ่เป็นแบบ "อยากได้" แต่เอนจินมักจะปรับแต่งโดยใช้พีชคณิตเชิง "ทำอย่างไร"
ไดอาเล็กต์ SQL แตกต่างกัน (Postgres vs Snowflake vs MySQL) แต่พื้นฐานไม่เปลี่ยน การเข้าใจคีย์ ความสัมพันธ์ และความเท่าเทียมเชิงพีชคณิตช่วยให้คุณเห็นว่าเมื่อใดที่คิวรีผิดเชิงตรรกะ เมื่อใดที่มันแค่ช้า และการเปลี่ยนแปลงใดคงความหมายข้ามแพลตฟอร์มได้
พีชคณิตเชิงสัมพันธ์คือ "คณิตศาสตร์ใต้ผิว" ของ SQL: ชุดตัวดำเนินการเล็ก ๆ ที่อธิบายผลลัพธ์ที่คุณต้องการ งานของ Jeffrey Ullman ช่วยทำให้มุมมองนี้ชัดเจนและสอนง่าย—และยังคงเป็นโมเดลความคิดที่ตัว optimizer ส่วนใหญ่ใช้
คิวรีฐานข้อมูลสามารถแสดงเป็นท่อของบล็อกพื้นฐานไม่กี่อย่าง:\n\n- Select (σ): กรองแถว (แนวคิดเดียวกับ WHERE)\n- Project (π): เก็บเฉพาะคอลัมน์ที่ต้องการ (เช่น SELECT col1, col2)\n- Join (⋈): รวมตารางตามเงื่อนไข (JOIN ... ON ...)\n- Union (∪): รวมผลลัพธ์ที่มีรูปแบบเดียวกัน (UNION)\n- Difference (−): แถวใน A แต่ไม่อยู่ใน B (เหมือน EXCEPT)
เพราะชุดนี้เล็ก จึงง่ายขึ้นในการวินิจฉัยความถูกต้อง: ถ้าสองนิพจน์พีชคณิตเท่ากัน มันจะคืนตารางเดียวกันสำหรับสถานะฐานข้อมูลที่ถูกต้องทุกแบบ
เอาตัวอย่างคิวรีที่คุ้นเคย:
SELECT c.name
FROM customers c
JOIN orders o ON o.customer_id = c.id
WHERE o.total > 100;
เชิงแนวคิด นี่คือ:
เริ่มด้วย join ระหว่าง customers และ orders: customers ⋈ orders
select เฉพาะ orders ที่มากกว่า 100: σ(o.total > 100)(...)
project คอลัมน์ที่ต้องการ: π(c.name)(...)
นี่ไม่ใช่สัญกรณ์ภายในที่เอนจินทุกตัวใช้เป๊ะ ๆ แต่เป็นแนวคิดที่ถูกต้อง: SQL กลายเป็นต้นไม้ของตัวดำเนินการ
ต้นไม้หลายแบบสามารถมีความหมายเดียวกันได้ ตัวอย่างเช่น ตัวกรองมักดันลงไปก่อน (apply σ ก่อนการ join ขนาดใหญ่) และการโปรเจกต์สามารถตัดคอลัมน์ที่ไม่ใช้เร็วขึ้น (apply π ก่อน) กฎความเท่าเทียมเหล่านี้ทำให้ฐานข้อมูลเขียนคิวรีของคุณเป็นแผนที่ถูกกว่าทางคำนวณ โดยไม่เปลี่ยนความหมาย เมื่อต้องมองคิวรีเป็นพีชคณิต การ"ปรับแต่ง"จะไม่ใช่เวทมนตร์ แต่เป็นการปรับรูปแบบตามกฎที่ปลอดภัย
เมื่อคุณเขียน SQL ฐานข้อมูลไม่ได้รันมัน "ตามที่พิมพ์" แต่จะแปลงคำสั่งของคุณเป็น query plan: การแทนโครงสร้างของงานที่จะทำ
โมเดลความคิดที่ดีคือต้นไม้ของตัวดำเนินการ ใบไม้เป็นการอ่านจากตารางหรือตารางดัชนี โหนดภายในเปลี่ยนและรวมแถว ตัวดำเนินการทั่วไปได้แก่ scan, filter (selection), project (เลือกคอลัมน์), join, group/aggregate, และ sort
ฐานข้อมูลมักแยกการวางแผนเป็นสองชั้น:
อิทธิพลของ Ullman ปรากฏในการเน้นการ"แปลงที่รักษาความหมาย": ปรับโครงสร้างแผนเชิงตรรกะในหลายรูปแบบโดยไม่เปลี่ยนคำตอบ แล้วจึงเลือกกลยุทธ์เชิงกายภาพที่มีประสิทธิภาพ
ก่อนจะเลือกวิธีรันสุดท้าย optimizer จะใช้กฎเชิงพีชคณิตเพื่อ"ทำความสะอาด" แผนการ เขียนใหม่เหล่านี้ไม่เปลี่ยนผล แต่ลดงานที่ไม่จำเป็น
ตัวอย่างทั่วไป:\n\n- Selection pushdown: นำตัวกรองไปทำก่อนเพื่อให้แถวที่ไหลเข้าสู่ขั้นตอนต่อไปน้อยลง\n- Projection pruning: เก็บเฉพาะคอลัมน์ที่ต้องการเพื่อลด I/O และหน่วยความจำ\n- Join reordering: ต่อ JOIN ผลลัพธ์ที่เล็กกว่าก่อนเมื่อปลอดภัย แทนที่จะตามลำดับใน SQL
สมมติคุณต้องการคำสั่งซื้อของผู้ใช้ในประเทศหนึ่ง:
SELECT o.order_id, o.total
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE u.country = 'CA';
การตีความแบบพื้น ๆ อาจทำการ JOIN ผู้ใช้ทั้งหมด กับ คำสั่งทั้งหมด แล้วค่อยกรองประเทศ CA ต่อมา แต่การเขียนใหม่ที่รักษาความหมายจะดันเงื่อนไขลงไปก่อนเพื่อให้ JOIN แตะแถวจำนวนน้อยลง:\n\n- กรอง users ให้เหลือ country = 'CA'\n- แล้ว JOIN ผู้ใช้ที่กรองกับ orders\n- แล้ว project เฉพาะ order_id และ total
ในเชิงแผน optimizer พยายามเปลี่ยนจาก:
Join(Users, Orders) → Filter(country='CA') → Project(order_id,total)
เป็นบางอย่างใกล้เคียง:
Filter(country='CA') on Users → Join(with Orders) → Project(order_id,total)
คำตอบเหมือนเดิม งานน้อยลง
การเขียนใหม่แบบนี้มักถูกมองข้ามเพราะคุณไม่ต้องพิมพ์มัน—แต่เป็นเหตุผลสำคัญที่ SQL เดียวกันอาจรันเร็วบนฐานข้อมูลหนึ่งและช้าอีกฐานหนึ่ง
เมื่อคุณรันคิวรี ฐานข้อมูลจะพิจารณาหลายวิธีที่ถูกต้องในการได้คำตอบเดียวกัน แล้วเลือกวิธีที่คาดว่าจะถูกที่สุด กระบวนการตัดสินใจนี้เรียกว่า cost-based optimization—และเป็นที่ที่ทฤษฎีแบบ Ullman ปรากฏชัดในประสิทธิภาพที่ใช้จริงทุกวัน
โมเดลต้นทุนคือระบบให้คะแนนที่ optimizer ใช้เปรียบเทียบแผนทางเลือก เครื่องยนต์ส่วนใหญ่ประเมินต้นทุนโดยดูทรัพยากรหลักไม่กี่อย่าง:\n\n- จำนวนแถวที่ประมวลผล\n- I/O (การอ่านเพจจากดิสก์/SSD และผลของแคช)\n- CPU (การกรอง การแฮช การเรียง การรวม)\n- หน่วยความจำ (ว่าโอเปอเรชันพอดีใน RAM หรือเทลงดิสก์)
โมเดลไม่ต้องแม่นยำสมบูรณ์แบบ แต่ต้องถูกในทิศทางที่ดีพอให้เลือกแผนที่ดีได้บ่อยพอ
ก่อนจะให้คะแนนแผน optimizer ถามที่ทุกขั้นตอนว่า: แถวกี่แถวจะถูกผลิตออกมา? นั่นคือ cardinality estimation
ถ้าคุณกรอง WHERE country = 'CA' เอนจินจะประมาณสัดส่วนของตารางที่ตรงกับเงื่อนไข ถ้าคุณ JOIN customers กับ orders มันจะประมาณจำนวนคู่ที่ตรงตามคีย์การ JOIN การเดาเหล่านี้จะกำหนดว่ามันจะเลือก index scan แทน full scan หรือ hash join แทน nested loop หรือไม่
การทายของ optimizer มาจาก สถิติ: จำนวน แทนการกระจายค่า อัตรา null และความสัมพันธ์ระหว่างคอลัมน์ เมื่อสถิติล้าสมัยหรือขาดหาย เอนจินอาจทายจำนวนแถวผิดพลาดเป็นลำดับของขนาด แผนที่ดูถูกกลายเป็นแพงจริง ๆ อาการคลาสสิกคือการช้าลงแบบทันทีหลังข้อมูลเพิ่มขึ้น แผนเปลี่ยนแบบสุ่ม หรือ JOIN ที่เทลงดิสก์โดยไม่คาดคิด
การทายที่ดีกว่ามักต้องใช้เวลามากขึ้น: สถิติละเอียดขึ้น การสุ่มตัวอย่าง หรือการสำรวจแผนตัวเลือกมากขึ้น แต่การวางแผนเองก็มีค่าเวลา โดยเฉพาะกับคิวรีซับซ้อน
ดังนั้น optimizer ต้องหาจุดสมดุลระหว่าง:\n\n- วางแผนเร็วพอ สำหรับงานแบบ interactive\n- วางแผนฉลาดพอ เพื่อหลีกเลี่ยงการเลือกที่หายนะ
การเข้าใจสมดุลนี้ช่วยให้คุณตีความผลลัพธ์ของ EXPLAIN: optimizer ไม่ได้พยายามฉลาดจนสุด แต่มองหาความถูกต้องที่คาดการณ์ได้ภายใต้ข้อมูลจำกัด
Ullman ช่วยทำให้ไอเดียหนึ่งชัดเจน: SQL ไม่ค่อยถูก "รัน" เท่ากับถูก แปล เป็นแผนการดำเนินงาน จุดนี้ชัดเจนที่สุดเมื่อต้องจัดการ JOIN คิวรีสองอันที่คืนแถวเดียวกันอาจต่างกันมากในเวลาเรียกใช้ ขึ้นกับว่าเอนจินเลือกอัลกอริทึม JOIN ใดและลำดับที่ JOIN ตาราง
Nested loop join: สำหรับแต่ละแถวด้านซ้าย หาแถวที่ตรงกันด้านขวา ง่ายแต่เร็วเมื่อต้นทางซ้ายเล็กและด้านขวามีดัชนีที่ใช้ค้นหาได้
Hash join: สร้างตารางแฮชจากอินพุตหนึ่ง (มักเป็นด้านที่เล็กกว่า) แล้ว probe ด้วยอีกรายการ เหมาะกับอินพุตใหญ่ที่ไม่เรียงและเงื่อนไขเท่ากัน แต่ต้องการหน่วยความจำ หากเทลงดิสก์จะสูญเสียข้อได้เปรียบ
Merge join: เดินทั้งสองอินพุตในลำดับที่เรียงแล้ว เหมาะเมื่อทั้งสองฝั่งเรียงลำดับอยู่แล้ว (หรือเรียงได้ถูกและถูก) เช่น เมื่อตัวดัชนีส่งแถวตามคีย์ JOIN
เมื่อตารางสามตารางขึ้นไป จำนวนลำดับการ JOIN ที่เป็นไปได้จะเพิ่มขึ้นอย่างรวดเร็ว การ JOIN สองตารางใหญ่ก่อนอาจสร้างผลกลางขนาดมหึมาและทำให้ทุกอย่างช้าลง ลำดับที่ดีกว่ามักเริ่มจากตัวกรองที่คัดเลือกมากที่สุด เพื่อให้ผลกลางยังคงเล็ก
ดัชนีไม่ได้แค่เร่งการค้นหา—มันทำให้บางกลยุทธ์ JOIN เป็นไปได้ ดัชนีบนคีย์ JOIN สามารถเปลี่ยน nested loop ที่แพงเป็นการ seek ต่อแถวที่เร็ว ในทางกลับกัน การไม่มีดัชนีจะบังคับให้เอนจินใช้ hash join หรือการเรียงขนาดใหญ่สำหรับ merge join
ฐานข้อมูลไม่ได้แค่ "รัน SQL" แต่ คอมไพล์ มัน อิทธิพลของ Ullman ครอบคลุมทั้งทฤษฎีฐานข้อมูลและความคิดแบบคอมไพเลอร์ และความเชื่อมโยงนี้อธิบายว่าทำไมเอนจินคิวรีจึงทำงานเหมือนสายการทำงานของภาษาการโปรแกรม: แปล เขียนใหม่ และเพิ่มประสิทธิภาพก่อนจะทำงานจริง
เมื่อคุณส่งคิวรี ขั้นตอนแรกคล้ายกับ front end ของคอมไพเลอร์ เอนจินจะแยกคำสงวนและตัวระบุ ตรวจไวยากร และสร้าง parse tree (มักย่อเป็น abstract syntax tree) นี่คือที่ตรวจจับข้อผิดพลาดพื้นฐาน เช่น เครื่องหมายคั่นหาย ชื่อคอลัมน์กำกวม หรือเกณฑ์การกรุ๊ปไม่ถูกต้อง
โมเดลความคิดที่ช่วยได้: SQL เป็นภาษาหนึ่งที่โปรแกรมอธิบายความสัมพันธ์ของข้อมูลแทนที่จะเป็นลูป
คอมไพเลอร์แปลงไวยากรณ์เป็นตัวแทนกลาง (IR) ฐานข้อมูลก็ทำแบบเดียวกัน: แปลงไวยากรณ์ SQL เป็น ตัวดำเนินการเชิงตรรกะ เช่น
GROUP BY)รูปแบบเชิงตรรกะนี้ใกล้กับพีชคณิตเชิงสัมพันธ์มากกว่าโค้ด SQL ตรง ๆ ทำให้เข้าใจความหมายและความเท่าเทียมได้ง่ายขึ้น
การเพิ่มประสิทธิภาพของคอมไพเลอร์รักษาผลลัพธ์โปรแกรมไว้แต่ลดค่าใช้จ่ายการรัน เช่นเดียวกับ optimizer ของฐานข้อมูลที่ใช้ชุดกฎเช่น:
นี่คือเวอร์ชันฐานข้อมูลของ "dead code elimination": ไม่ใช่เทคนิคเดียวกัน แต่ปรัชญาเดียวกันคือรักษาเซมานติกส์และลดต้นทุน
ถ้าคิวรีของคุณช้า อยาจ้องแต่ SQL เท่านั้น ให้ดู query plan เหมือนตรวจสอบเอาต์พุตคอมไพล์ มันบอกคุณว่าเอนจินเลือกอะไรจริง ๆ: ลำดับ JOIN การใช้ดัชนี และจุดที่ใช้เวลาเยอะ
ข้อสรุปเชิงปฏิบัติ: เรียนรู้การอ่าน EXPLAIN เหมือนรายการคำสั่ง assembly ของประสิทธิภาพ มันเปลี่ยนการจูนจากเดาเป็นการดีบักด้วยหลักฐาน
ประสิทธิภาพคิวรีดี ๆ มักเริ่มก่อนคุณพิมพ์ SQL Ullman เรื่องทฤษฎีสกีมา (โดยเฉพาะ normalization) เกี่ยวกับการจัดโครงสร้างข้อมูลให้ฐานข้อมูลรักษาความถูกต้อง คาดการณ์ได้ และมีประสิทธิภาพเมื่อเติบโต
Normalization มุ่งหวัง:\n\n- ลดความผิดพลาดในการอัพเดต (เช่น ต้องอัพเดตที่อยู่ลูกค้าห้าที่และลืมที่หนึ่ง)\n- ปรับปรุงความสอดคล้อง โดยให้แต่ละข้อเท็จจริงอยู่ที่เดียว\n- ทำให้ข้อจำกัดบอกได้ชัด (คีย์ foreign key) เพื่อให้เอนจินจัดการแทนการพึ่งโค้ดแอป
ชัยชนะด้านความถูกต้องเหล่านี้แปลเป็นประสิทธิภาพต่อมา: ฟิลด์ที่ทำซ้ำลดลง ดัชนีเล็กลง และการอัพเดตที่ถูกลง
ไม่ต้องจำหลักฐานเพื่อใช้แนวคิด:\n\n- 1NF: เก็บค่าเป็นอะตอม (ไม่เก็บเป็นรายการคั่นด้วย comma) ซึ่งทำให้การกรองและการทำดัชนีตรงไปตรงมาขึ้น\n- 2NF: ถ้าตารางมีคีย์ประกอบ คอลัมน์ที่ไม่ใช่คีย์ควรขึ้นกับคีย์ทั้งชุด ไม่ใช่แค่บางส่วน\n- 3NF: คอลัมน์ที่ไม่ใช่คีย์ควรขึ้นกับคีย์เท่านั้น ไม่ขึ้นกับคอลัมน์อื่นที่ไม่ใช่คีย์\n- BCNF: เวอร์ชันเข้มงวดของ 3NF เมื่อทุกตัวกำหนดเป็น candidate key
Denormalization น่าสมเหตุสมผลเมื่อ:\n\n- ตารางเน้นการวิเคราะห์หนัก (fact tables กว้างสำหรับรายงาน)\n- JOIN กลายเป็นคอขวดและคุณยอมรับการซ้ำได้ในขอบเขตที่ควบคุมได้\n- ปรับเพื่อความเร็วการอ่านโดยมีกฎการรีเฟรชที่ชัดเจน (เช่น สร้างใหม่ทุกคืน)
กุญแจคือ denormalize อย่างมีเหตุผล และมีขั้นตอนรักษาความสอดคล้องของข้อมูลที่ชัดเจน
การออกแบบสกีมากำหนดว่าตัว optimizer ทำอะไรได้ คีย์และ foreign key ชัดเจนช่วยให้กลยุทธ์ JOIN ดีขึ้น การเขียนแปลงปลอดภัยมากขึ้น และการประมาณจำนวนแถวแม่นยำขึ้น ขณะเดียวกัน ข้อมูลซ้ำเกินไปอาจทำให้ดัชนีบวมและการเขียนช้าลง คอลัมน์ที่เก็บค่าหลายค่าอาจปิดกั้นพรีดิแคตที่มีประสิทธิภาพ เมื่อข้อมูลโตขึ้น การตัดสินใจการโมเดลข้อมูลเหล่านี้มักสำคัญกว่าการจูนแบบจุดเล็ก ๆ
Jeffrey Ullman ช่วยทำให้วิธีที่ระบบจัดหมายความของคิวรีและวิธีแปลงคิวรีเป็นรูปแบบที่เร็วขึ้นมีความเป็นทางการและเชื่อถือได้ พื้นฐานนี้จะทำงานทุกครั้งที่เอนจินทำการเขียนใหม่ของคิวรี จัดลำดับ JOIN ใหม่ หรือตัดสินใจแผนการรันที่ต่างออกไป โดยยังรับประกันผลลัพธ์ชุดเดียวกัน
พีชคณิตเชิงสัมพันธ์เป็นชุดตัวดำเนินการเล็ก ๆ (select, project, join, union, difference) ที่อธิบายผลลัพธ์ของคิวรีอย่างแม่นยำ เอนจินทั่วไปจะแปลง SQL เป็นต้นไม้ของตัวดำเนินการในลักษณะคล้ายพีชคณิต เพื่อให้สามารถใช้กฎความเท่าเทียมกัน (เช่น การดันตัวกรองลงไปก่อน) ก่อนจะเลือกกลยุทธ์การประมวลผล
การเขียนคิวรีที่ยังให้ความหมายเดิมแต่ปรับรูปแบบได้สำคัญเพราะตัวปรับแต่งต้องมั่นใจว่าแผนที่ถูกเปลี่ยนแล้วจะให้ผลลัพธ์ เหมือนเดิม กฎความเท่าเทียมช่วยให้ optimizer สามารถ:
WHERE ไปก่อน JOINการเปลี่ยนเหล่านี้ลดงานลงอย่างมากโดยไม่เปลี่ยนความหมาย
แผนเชิงตรรกะบรรยาย สิ่งที่ ต้องคำนวณ (เช่น filter, join, aggregate) โดยไม่สนใจรายละเอียดการเก็บข้อมูล แผนเชิงกายภาพเลือก วิธีทำงาน จริง ๆ (เช่น index scan vs full scan, hash join vs nested loop, การขนาน) ความแตกต่างด้านประสิทธิภาพส่วนใหญ่เกิดจากการเลือกกายภาพซึ่งเกิดขึ้นหลังจากการเขียนแผนเชิงตรรกะ
การเพิ่มประสิทธิภาพแบบอิงต้นทุนคือการประเมินแผนที่ถูกต้องหลายแบบแล้วเลือกแผนที่คาดว่าจะมีต้นทุนน้อยที่สุด ต้นทุนโดยทั่วไปถูกขับเคลื่อนด้วยปัจจัยใช้งานจริงเช่น จำนวนแถวที่ประมวลผล, I/O, CPU, และหน่วยความจำ (รวมถึงว่าการทำแฮชหรือการเรียงต้องเทลงดิสก์หรือไม่)
การประมาณจำนวนแถว (cardinality estimation) คือการทายของ optimizer ว่าแต่ละขั้นตอนจะส่งออกกี่แถว การทายเหล่านี้กำหนดการตัดสินใจ เช่น ลำดับ JOIN, ประเภท JOIN, และว่าการสแกนนั้นคุ้มค่าหรือไม่ เมื่อการทายผิด—มักเพราะสถิติเก่า/ขาด—จะเกิดผลคือช้าลงอย่างมาก แผนที่ดูถูกอาจกลายเป็นแพงจริง ๆ
Nested loop join: เหมาะเมื่อด้านซ้ายมีขนาดเล็กและด้านขวาสามารถค้นหาได้อย่างมีประสิทธิภาพ (มักผ่านดัชนี)Hash join: ดีสำหรับการ JOIN ขนาดใหญ่บนข้อมูลที่ไม่เรียงลำดับและมีเงื่อนไขความเท่ากัน แต่ต้องการหน่วยความจำเพียงพอเพื่อหลีกเลี่ยงการเทลงดิสก์Merge join: เหมาะเมื่อทั้งสองข้างเรียงลำดับแล้ว (หรือเรียงได้ถูกและถูก) เช่น ดัชนีที่คืนแถวตามคีย์ JOINมุ่งไปที่สัญญาณที่สำคัญ:
มองแผนเหมือนเป็นโค้ดที่คอมไพล์แล้ว: มันบอกสิ่งที่เอนจินตัดสินใจทำจริง ๆ
การทำให้เป็นปกติ (normalization) ลดการทำซ้ำของข้อมูลและความผิดพลาดในการอัพเดต ทำให้ตารางและดัชนีมีขนาดเล็กลงและ JOIN น่าเชื่อถือขึ้น การทำ denormalize เหมาะเมื่อเป็นตารางวิเคราะห์หนัก ๆ หรือ pattern ที่อ่านบ่อยและยอมรับความซ้ำได้โดยมีนโยบายปรับปรุงที่ชัดเจน
การสเกลมักหมายถึงการเปลี่ยนกลยุทธ์กายภาพโดยยังรักษาความหมายของคิวรีไว้ เครื่องมือที่ใช้บ่อยได้แก่:
Caching ช่วยการอ่านซ้ำได้ แต่ไม่สามารถแก้ปัญหางานที่ต้องแตะข้อมูลมากเกินไปหรือสร้างผลกลางขนาดใหญ่ได้