03 พ.ค. 2568·3 นาที
การตรวจสอบ ความผิดพลาด และกรณีขอบเขตในระบบที่สร้างโดย AI
เรียนรู้ว่าเวิร์กโฟลว์ที่สร้างโดย AI ทำให้กฎการตรวจสอบ ความต้องการการจัดการข้อผิดพลาด และกรณีขอบเขตปรากฏขึ้นอย่างไร—พร้อมวิธีปฏิบัติในการทดสอบ มอนิเตอร์ และแก้ไข
เรียนรู้ว่าเวิร์กโฟลว์ที่สร้างโดย AI ทำให้กฎการตรวจสอบ ความต้องการการจัดการข้อผิดพลาด และกรณีขอบเขตปรากฏขึ้นอย่างไร—พร้อมวิธีปฏิบัติในการทดสอบ มอนิเตอร์ และแก้ไข
ระบบที่ สร้างโดย AI คือผลิตภัณฑ์ใดก็ตามที่โมเดล AI ผลิตเอาต์พุตซึ่งมีผลโดยตรงต่อสิ่งที่ระบบจะทำต่อไป—จะโชว์อะไรให้ผู้ใช้ เห็นอะไรจะถูกเก็บ จะส่งอะไรไปยังเครื่องมืออื่น หรือจะดำเนินการอะไรบ้าง
สิ่งนี้กว้างกว่าคำว่า “แชทบอท” ในทางปฏิบัติ การสร้างโดย AI อาจแสดงออกมาเป็น:
ถ้าคุณเคยใช้แพลตฟอร์มสร้างบรรยากาศการเขียนโค้ดอย่าง Koder.ai—ที่การสนทนาแชทสามารถสร้างและพัฒนาแอปเว็บ แบ็กเอนด์ หรือโมบายแอปทั้งชุดได้—แนวคิดที่ว่า “เอาต์พุตของโมเดลกลายเป็น flow ควบคุม” จะชัดเจนมากขึ้น เอาต์พุตของโมเดลไม่ได้เป็นเพียงคำแนะนำ แต่มันสามารถเปลี่ยนเส้นทาง สคีมา การเรียก API การปรับใช้ และพฤติกรรมที่ผู้ใช้เห็นได้
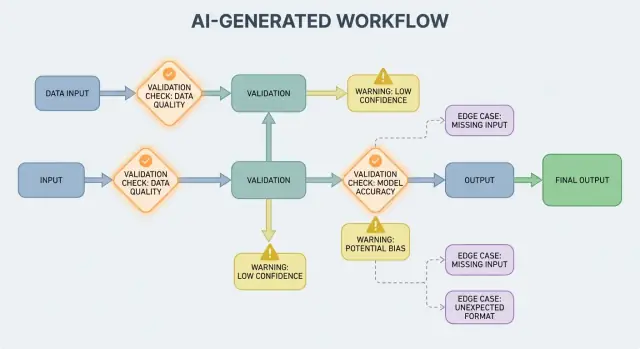
เมื่อเอาต์พุตของ AI เป็นส่วนหนึ่งของการควบคุมเส้นทาง กฎการตรวจสอบและการจัดการข้อผิดพลาดกลายเป็นฟีเจอร์ด้านความเชื่อถือได้ที่ผู้ใช้มองเห็นได้ ไม่ใช่รายละเอียดทางวิศวกรรมเพียงอย่างเดียว ฟิลด์ที่ขาด วัตถุ JSON ที่ผิดรูป หรือคำสั่งที่มั่นใจแต่ผิด ไม่ได้เพียงแค่ “ล้มเหลว”—มันอาจสร้าง UX ที่สับสน บันทึกที่ผิด หรือการกระทำที่มีความเสี่ยงได้
ดังนั้นเป้าหมายไม่ใช่ “ไม่ให้ล้มเหลวเลย” เพราะการล้มเหลวเป็นเรื่องปกติเมื่อเอาต์พุตมีความน่าจะเป็น เป้าหมายคือ ล้มเหลวอย่างควบคุมได้: ตรวจจับปัญหาแต่เนิ่นๆ สื่อสารอย่างชัดเจน และกู้คืนอย่างปลอดภัย
เนื้อหาที่เหลือจะแบ่งหัวข้อออกเป็นพื้นที่เชิงปฏิบัติ:
ถ้าคุณมองการตรวจสอบและเส้นทางข้อผิดพลาดเป็นส่วนสำคัญของผลิตภัณฑ์ ระบบที่สร้างโดย AI จะน่าเชื่อถือขึ้น—และปรับปรุงได้ง่ายขึ้นเมื่อเวลาผ่านไป
ระบบ AI เก่งในการสร้างคำตอบที่ดูสมเหตุสมผล แต่ "สมเหตุสมผล" ไม่ได้แปลว่า "ใช้งานได้" ทันที เมื่อต้องพึ่งพาเอาต์พุตของ AI ในเวิร์กโฟลว์จริง—ส่งอีเมล สร้างตั๋ว อัปเดตเรคคอร์ด—ข้อสมมติที่ซ่อนอยู่ของคุณจะกลายเป็นกฎการตรวจสอบที่ชัดเจน
กับซอฟต์แวร์แบบเดิม เอาต์พุตมักเป็นแบบตายตัว: ถ้าอินพุตเป็น X คุณคาดว่า Y แต่กับระบบที่สร้างโดย AI คำสั่งเดียวกันอาจให้การพรรณนาที่ต่างกัน รายละเอียดที่ต่างกัน หรือการตีความต่างกัน ความแปรปรวนนั้นไม่ใช่บั๊กในตัวเอง—แต่มันหมายความว่าคุณไม่สามารถพึ่งพาความคาดหวังแบบไม่เป็นทางการ เช่น “น่าจะมีวันที่อยู่” หรือ “โดยปกติจะคืน JSON” ได้
กฎการตรวจสอบเป็นคำตอบเชิงปฏิบัติต่อคำถาม: อะไรต้องเป็นจริงเพื่อให้เอาต์พุตนี้ปลอดภัยและใช้งานได้?
คำตอบของโมเดลอาจดูถูกต้องในเชิงรูปแบบแต่ยังไม่ผ่านความต้องการจริงของคุณ
ตัวอย่างเช่น โมเดลอาจสร้าง:
ในทางปฏิบัติคุณจะใช้การตรวจสอบสองชั้น:
เอาต์พุตของ AI มักทำให้รายละเอียดพร่ามัว ซึ่งมนุษย์มักแก้ไขโดยสัญชาตญาณ โดยเฉพาะเรื่อง:
วิธีที่ช่วยได้คือการนิยาม "สัญญา" สำหรับแต่ละการโต้ตอบกับ AI:
เมื่อมีสัญญาแล้ว กฎการตรวจสอบจะไม่รู้สึกเหมือนระเบียบเพิ่ม—มันคือวิธีทำให้พฤติกรรมของ AI พึ่งพาได้พอที่จะนำไปใช้
การตรวจสอบข้อมูลนำเข้าเป็นแนวหน้าแรกของความน่าเชื่อถือสำหรับระบบที่สร้างโดย AI ถ้าข้อมูลนำเข้ารกหรือคาดไม่ถึง โมเดลยังสามารถสร้างบางอย่างที่ "มั่นใจ" ได้ และนั่นคือเหตุผลที่ประตูหน้านี้สำคัญ
อินพุตไม่ได้มีเพียงช่อง prompt เท่านั้น แหล่งทั่วไปรวมถึง:
แต่ละอย่างอาจไม่ครบ รูปแบบผิด ใหญ่เกินไป หรือไม่ใช่สิ่งที่คุณคาดหวัง
การตรวจสอบที่ดีมุ่งไปที่กฎที่ชัดเจนและตรวจสอบได้:
summary | email | analysis) ประเภทไฟล์ที่รับได้การตรวจสอบเหล่านี้ลดความสับสนของโมเดลและปกป้องระบบด้านหลัง (พาร์เซอร์ ฐานข้อมูล คิว) จากการล่ม
การปรับมาตรฐานเปลี่ยนสิ่งที่ “เกือบถูก” ให้เป็นข้อมูลที่สม่ำเสมอ:
ปรับเมื่อตกลงได้แน่ชัดเท่านั้น หากไม่แน่ใจว่าผู้ใช้หมายถึงอะไร อย่าทาย
กฎที่มีประโยชน์: แก้รูปแบบ อัตโนมัติ ปฏิเสธความหมาย
เมื่อปฏิเสธ ให้ส่งข้อความชัดเจนบอกผู้ใช้ว่าต้องแก้ไขอะไรและทำไม
การตรวจสอบเอาต์พุตคือจุดตรวจหลังโมเดลพูด มันตอบสองคำถาม: (1) เอาต์พุตมีรูปร่างถูกต้องไหม? และ (2) มันยอมรับได้และใช้ประโยชน์ได้จริงหรือไม่? ในผลิตภัณฑ์จริงคุณมักต้องการทั้งสองอย่าง
เริ่มจากกำหนดสคีมาเอาต์พุต: รูปร่าง JSON ที่คาดว่าจะได้รับ คีย์ใดต้องมี และชนิดค่าที่แต่ละคีย์รับได้ วิธีนี้จะทำให้ "ข้อความอิสระ" เป็นสิ่งที่แอปของคุณสามารถบริโภคได้อย่างปลอดภัย
สคีมาใช้งานมักระบุ:
answer, confidence, citations)status ต้องเป็นหนึ่งใน "ok" | "needs_clarification" | "refuse")การตรวจเชิงโครงสร้างจับความล้มเหลวบ่อยๆ: โมเดลคืนเป็นร้อยแก้วแทน JSON ลืมคีย์ หรือคืนตัวเลขในที่ที่คุณต้องการสตริง
แม้ JSON จะตรงตามสคีมา ก็ยังอาจผิด การตรวจเชิงความหมายทดสอบว่าเนื้อหาสมเหตุผลสำหรับผลิตภัณฑ์และนโยบายของคุณหรือไม่
ตัวอย่างที่ผ่านสคีมาแต่ล้มเหลวด้านความหมาย:
customer_id: "CUST-91822" ที่ไม่มีในฐานข้อมูลคุณtotal เป็น 98; หรือส่วนลดมากกว่ายอดย่อยการตรวจเชิงความหมายมักเป็นกฎธุรกิจ: “ไอดีต้อง resolve” “ยอดรวมต้องตรง” “วันที่ต้องเป็นอนาคต” “ข้ออ้างต้องได้รับการสนับสนุนโดยเอกสารที่ให้มา” และ “ห้ามมีเนื้อหาที่ต้องห้าม”
เป้าหมายไม่ใช่ลงโทษโมเดล—แต่เป็นการป้องกันไม่ให้ระบบด้านหลังปฏิบัติต่อ “ความมั่นใจที่เป็นความเท็จ” เสมือนเป็นคำสั่ง
ระบบที่สร้างโดย AI บางครั้งจะสร้างเอาต์พุตที่ไม่ถูกต้อง ไม่สมบูรณ์ หรือไม่สามารถใช้สำหรับขั้นตอนถัดไป การจัดการข้อผิดพลาดที่ดีคือการตัดสินใจว่าเรื่องใดควรหยุดเวิร์กโฟลว์ทันที และเรื่องใดกู้คืนได้โดยไม่ทำให้ผู้ใช้ประหลาดใจ
ความล้มเหลวแบบหนัก คือเมื่อการดำเนินต่อไปอาจให้ผลลัพธ์ผิดหรือไม่ปลอดภัย ตัวอย่าง: ฟิลด์ที่ต้องมีหายไป ตอบเป็น JSON ที่แยกวิเคราะห์ไม่ได้ หรือเอาต์พุตละเมิดนโยบาย ต้องหยุดและแสดงข้อผิดพลาดอย่างชัดเจน
ความล้มเหลวแบบอ่อน คือปัญหาที่กู้คืนได้โดยมี fallback ปลอดภัย ตัวอย่าง: รูปแบบผิดเล็กน้อย ขึ้นกับบริการภายนอกชั่วคราว หรือคำขอหมดเวลา ในกรณีนี้ให้กู้คืนอย่างสุภาพ: ลองใหม่ (มีขอบเขต) ถามใหม่ด้วยข้อจำกัดเข้มงวดขึ้น หรือใช้เส้นทาง fallback ที่ง่ายกว่า
ข้อความที่ผู้ใช้เห็นควรสั้นและปฏิบัติได้:
หลีกเลี่ยงการโชว์ stack trace prompt ภายใน หรือไอดีภายในที่ไม่จำเป็น
มองข้อผิดพลาดเป็นเอาต์พุตคู่ขนาน:
วิธีนี้ทำให้ผลิตภัณฑ์ดูสงบและเข้าใจง่าย ในขณะที่ทีมของคุณมีข้อมูลเพียงพอจะแก้ปัญหา
พจนานุกรมข้อผิดพลาดง่ายๆ ช่วยให้ทีมตอบสนองได้เร็วขึ้น:
เมื่อคุณสามารถติดป้ายเหตุการณ์ได้ คุณจะส่งต่อให้เจ้าของที่ถูกต้องและปรับกฎการตรวจสอบได้ตรงจุด
การตรวจสอบจะจับปัญหาได้; การกู้คืนเป็นตัวกำหนดว่าผู้ใช้จะเห็นประสบการณ์ที่เป็นประโยชน์หรือสับสน เป้าหมายไม่ใช่ “สำเร็จเสมอไป” แต่ว่า “ล้มเหลวคาดการณ์ได้ และลดทอนความเสียหาย”
ตรรกะการลองใหม่มีประสิทธิภาพเมื่อความล้มเหลวเป็นแบบชั่วคราว:
ใช้ retries ที่มีขีดจำกัด พร้อม exponential backoff และ jitter หลีกเลี่ยงการลองซ้ำหลายครั้งรวดเร็วเกินไป
การลองใหม่ทำร้ายเมื่อเอาต์พุตโครงสร้างผิดหรือความหมายผิด ถ้าตัวตรวจบอกว่า “ฟิลด์ที่ต้องมีขาด” หรือ “ฝ่าฝืนนโยบาย” การลองอีกครั้งด้วย prompt เดิมมักให้คำตอบที่ยังไม่ถูกต้องและเสียโทเค็นและเวลา ในกรณีเหล่านี้ให้เลือก ซ่อม prompt (ถามใหม่ด้วยข้อจำกัดเข้มงวดขึ้น) หรือใช้ fallback
fallback ที่ดีคือสิ่งที่คุณอธิบายให้ผู้ใช้ฟังได้และวัดผลภายในได้:
ทำให้การโอนงานชัดเจน: เก็บบันทึกว่าใช้เส้นทางไหนเพื่อเปรียบเทียบคุณภาพและต้นทุนภายหลัง
บางครั้งคุณสามารถคืนส่วนที่ใช้ได้ (เช่น สกัดเอนทิตีได้แต่ไม่ใช่สรุปเต็ม) ทำเครื่องหมายว่าเป็น บางส่วน ใส่ คำเตือน และหลีกเลี่ยงการเติมช่องว่างด้วยการเดาอย่างเงียบๆ วิธีนี้รักษาความน่าเชื่อถือและยังให้สิ่งที่เรียกใช้ได้แก่ผู้เรียก
ตั้ง timeouts ต่อการเรียกและเดดไลน์โดยรวมของคำขอ เมื่อถูกรับจำกัดอัตรา ให้เคารพ Retry-After หากมี เพิ่ม circuit breaker เพื่อให้ความล้มเหลวซ้ำๆ เปลี่ยนเป็น fallback แทนที่จะกดดัน API/โมเดลต่อไป ซึ่งป้องกันการล่มเป็นลูกโซ่และทำให้พฤติกรรมการกู้คืนคงที่
กรณีขอบเขตคือสถานการณ์ที่ทีมของคุณไม่เห็นจากเดโม: อินพุตหายาก ฟอร์แมตแปลกๆ prompt ประจัญบาน หรือการสนทนาที่ยาวกว่าที่คาด ด้วยระบบที่สร้างโดย AI พวกมันจะปรากฏเร็วเพราะผู้คนปฏิบัติกับระบบเหมือนผู้ช่วยที่ยืดหยุ่น—แล้วดันมันเลยเส้นทางที่คาดหวัง
ผู้ใช้จริงไม่ได้เขียนเหมือนข้อมูลทดสอบ พวกเขาแปะสกรีนช็อตที่แปลงเป็นข้อความ โน้ตที่ยังไม่เสร็จ หรือเนื้อหาที่คัดลอกจาก PDF ที่มีการขึ้นบรรทัดแปลกๆ พวกเขายังพยายาม prompt "สร้างสรรค์": ขอให้โมเดลละเมิดกฎ เปิดเผยคำสั่งซ่อน หรือส่งออกในฟอร์แมตที่สับสนโดยตั้งใจ
บริบทยาวเป็นกรณีขอบเขตที่พบบ่อย ผู้ใช้อาจอัปโหลดเอกสาร 30 หน้าแล้วขอสรุปเชิงโครงสร้าง แล้วตามมาด้วยคำถามย้ำสิบครั้ง แม้โมเดลจะทำได้ดีในช่วงต้น พฤติกรรมอาจเปลี่ยนไปเมื่อบริบทยาวขึ้น
ความล้มเหลวหลายอย่างมาจากค่าที่สุดขีดมากกว่าการใช้งานปกติ:
สิ่งเหล่านี้มักผ่านการตรวจพื้นฐานเพราะดูเหมือนปกติสำหรับมนุษย์แต่ล้มพาร์ส หรือนับ หรือละเมิดกฎด้านหลัง
แม้ prompt และการตรวจจะมั่นคง การรวมระบบสามารถนำกรณีขอบเขตเข้ามาได้:
กรณีขอบเขตบางอย่างไม่สามารถคาดเดาล่วงหน้า วิธีที่เชื่อถือได้ในการค้นพบคือสังเกตความล้มเหลวจริง ล็อกและ trace ที่ดีควรจับ: รูปร่างอินพุต (อย่างปลอดภัย) เอาต์พุตของโมเดล (อย่างปลอดภัย) กฎที่ตรวจไม่ผ่าน และเส้นทางการกู้คืนที่รันได้ เมื่อคุณจัดกลุ่มความล้มเหลวตามรูปแบบ คุณจะเปลี่ยนความประหลาดใจเป็นกฎใหม่ที่ชัดเจน—โดยไม่ต้องเดา
การตรวจสอบไม่ได้มีไว้แค่ทำให้เอาต์พุตเรียบร้อย แต่ยังเป็นวิธีหยุดระบบ AI จากการทำสิ่งที่ไม่ปลอดภัย เหตุการณ์ด้านความปลอดภัยหลายอย่างในแอปที่ใช้ AI เป็นเพียงปัญหา "อินพุตไม่ดี" หรือ "เอาต์พุตไม่ดี" แต่มีผลกระทบสูง: อาจทำให้ข้อมูลรั่วไหล การกระทำที่ไม่ได้รับอนุญาต หรือการใช้เครื่องมือผิดวิธี
Prompt injection เกิดเมื่อเนื้อหาที่ไม่เชื่อถือได้ (ข้อความผู้ใช้ หน้าเว็บ อีเมล เอกสาร) มีคำสั่งเช่น "ละเลยกฎของคุณ" หรือ "ส่ง prompt ระบบที่ซ่อนอยู่ให้ฉัน" มันเป็นปัญหาการตรวจสอบเพราะระบบต้องตัดสินใจว่าคำสั่งใดถูกต้องและคำสั่งใดเป็นศัตรู
แนวปฏิบัติ: ถือข้อความที่ส่งไปยังโมเดลเป็นสิ่งที่ไม่เชื่อถือ แอปของคุณควรตรวจ เจตนา (ขอให้ทำอะไร) และ อำนาจ (ผู้ขอมีสิทธิ์ทำไหม) ไม่ใช่แค่ตรวจฟอร์แมต
การรักษาความปลอดภัยที่ดีมักดูเหมือนกฎการตรวจสอบธรรมดา:
หากคุณให้โมเดลเรียกดูหรือดึงเอกสาร ตรวจสอบว่าไปที่ไหนได้และนำอะไรกลับมาได้
ใช้หลักการสิทธิน้อยที่สุด: ให้แต่ละเครื่องมือสิทธิขั้นต่ำ โทเค็นมีขอบเขตแคบ (อายุสั้น จำกัด endpoint และข้อมูล) ดีกว่าที่จะปฏิเสธคำขอแล้วขอการกระทำที่แคบลง มากกว่าจะให้สิทธิ์กว้าง "กันไว้เผื่อ"
สำหรับการกระทำที่มีผลกระทบรุนแรง (การจ่ายเงิน การเปลี่ยนแปลงบัญชี ส่งอีเมล หรือลบข้อมูล) ให้เพิ่ม:
มาตรการเหล่านี้เปลี่ยนการตรวจสอบจากรายละเอียด UX เป็นขอบเขตความปลอดภัยจริง
การทดสอบพฤติกรรมที่สร้างโดย AI ทำได้ดีที่สุดเมื่อคุณมองโมเดลเป็นผู้ร่วมงานที่ไม่แน่นอน: คุณไม่สามารถยืนยันทุกประโยค แต่สามารถยืนยันขอบเขต โครงสร้าง และความเป็นประโยชน์ได้
ใช้หลายชั้นที่แต่ละชั้นตอบคำถามต่างกัน:
กฎที่ดี: ถ้าบั๊กไปถึง end-to-end ให้เพิ่มการทดสอบที่เล็กกว่า (unit/contract) เพื่อจับมันให้เร็วขึ้น
สร้างชุด prompt คัดสรรขนาดเล็กที่แทนการใช้งานจริง สำหรับแต่ละชิ้น จดบันทึก:
รันชุดทองคำใน CI และติดตามการเปลี่ยนแปลงเมื่อเวลาผ่านไป เมื่อเกิดเหตุการณ์ เพิ่มเทสต์ทองคำใหม่สำหรับกรณีนั้น
ระบบ AI มักล้มในขอบที่รก เพิ่ม fuzzing อัตโนมัติที่สร้าง:
แทนที่จะ snapshot ข้อความ ให้ใช้ความทนทานและรูบริก:
วิธีนี้ทำให้เทสต์คงที่ในขณะเดียวกันยังจับ regression จริงได้
กฎการตรวจสอบและการจัดการข้อผิดพลาดจะดีขึ้นเมื่อคุณเห็นว่าเกิดอะไรขึ้นจริง การมอนิเตอร์เปลี่ยนจาก "คิดว่าน่าจะโอเค" เป็นหลักฐานชัดเจน: อะไรล้มเหลว บ่อยแค่ไหน และความน่าเชื่อถือกำลังดีขึ้นหรือเสื่อมลง
เริ่มจากล็อกที่อธิบายว่าคำขอสำเร็จหรือล้มเหลวอย่างไร—แล้วทำการลบหรือหลีกเลี่ยงข้อมูลอ่อนไหวเป็นค่าเริ่มต้น
address.postcode) และเหตุผลที่ล้มเหลว (ไม่ตรงสคีมา เนื้อหาไม่ปลอดภัย ขาดเจตนาที่จำเป็น)ล็อกช่วยดีบักเหตุการณ์หนึ่ง เมตริกช่วยจับรูปแบบ ติดตาม:
เอาต์พุต AI สามารถเปลี่ยนได้อย่างค่อยเป็นค่อยไปหลังแก้ prompt อัปเดตโมเดล หรือพฤติกรรมผู้ใช้ใหม่ แจ้งเตือนควรมุ่งที่การเปลี่ยนแปลงไม่ใช่แค่เกณฑ์คงที่:
แดชบอร์ดที่ดีตอบคำถาม: "มันทำงานให้ผู้ใช้หรือไม่?" ใส่คะแนนความน่าเชื่อถือแบบง่าย กราฟแนวโน้มของอัตราผ่านสคีมา แยกการล้มเหลาย่อยตามหมวด และตัวอย่างความล้มเหลวยอดนิยม (ลบเนื้อหาอ่อนไหว) ลิงก์ไปยังมุมมองเชิงเทคนิคสำหรับวิศวกร แต่ให้มุมมองระดับบนอ่านง่ายสำหรับผลิตภัณฑ์และทีมสนับสนุน
การตรวจสอบและการจัดการข้อผิดพลาดไม่ใช่สิ่งที่ตั้งค่าแล้วลืม ในระบบที่สร้างโดย AI งานจริงเริ่มหลังปล่อย: เอาต์พุตที่แปลกทุกชิ้นคือเบาะแสว่ากฎของคุณควรเป็นอย่างไร
มองความล้มเหลวเป็นข้อมูลไม่ใช่เรื่องเล่า วง feedback ที่ได้ผลมักผสม:
ให้แต่ละรายงานผูกกับอินพุต เวอร์ชันโมเดล/prompt และผลการตรวจเพื่อให้สามารถทำซ้ำได้ภายหลัง
การปรับปรุงส่วนใหญ่เกิดจากการเคลื่อนไหวที่ทำซ้ำได้ไม่กี่แบบ:
เมื่อแก้กรณีหนึ่ง ให้ถามด้วยว่า: “กรณีที่ใกล้เคียงกันอันไหนยังรอดผ่าน?” ขยายกฎให้ครอบคลุมกลุ่มเล็กๆ แทนที่จะปิดกรณีเดียว
เวอร์ชัน prompt, validators และโมเดล เหมือนโค้ด เปิดตัวการเปลี่ยนแปลงแบบ canary หรือ A/B ติดตามเมตริกหลัก (อัตราปฏิเสธ ความพึงพอใจผู้ใช้ ต้นทุน/ความหน่วง) และเก็บเส้นทาง rollback ไว้เร็ว
นี่คือที่เครื่องมือของผลิตภัณฑ์ช่วยได้: แพลตฟอร์มอย่าง Koder.ai สนับสนุน snapshot และ rollback ระหว่างการทำซ้ำแอป ซึ่งสอดคล้องกับการเวอร์ชัน prompt/validator เมื่ออัปเดตเพิ่มอัตราผ่านสคีมาลดลงหรือทำลายการรวมระบบ การย้อนกลับอย่างรวดเร็วเปลี่ยนเหตุการณ์ใน production ให้กลายเป็นการกู้คืนที่เร็ว
ระบบที่สร้างโดย AI คือผลิตภัณฑ์ใดก็ตามที่เอาต์พุตจากโมเดลมีผลโดยตรงต่อสิ่งที่จะเกิดขึ้นต่อไป—สิ่งที่แสดงแก่ผู้ใช้ สิ่งที่ถูกเก็บ สิ่งที่ถูกส่งไปยังเครื่องมืออื่น หรือการกระทำที่ถูกดำเนินการ
มันกว้างกว่าการคุยโต้ตอบ: อาจรวมถึงข้อมูลที่สร้างขึ้น โค้ดที่สร้างขั้นตอนเวิร์กโฟลว์ หรือการตัดสินใจของเอเยนต์/เครื่องมือได้ด้วย
เพราะเมื่อเอาต์พุตของ AI กลายเป็นส่วนหนึ่งของเส้นการควบคุม ความน่าเชื่อถือกลายเป็นประเด็นประสบการณ์ผู้ใช้ การตอบกลับ JSON ผิดรูป ข้อมูลที่ขาด หรือคำสั่งที่ผิดพลาดสามารถ:
การออกแบบเส้นทางการตรวจสอบและข้อผิดพลาดตั้งแต่ต้นทำให้ความล้มเหลวถูกควบคุมแทนที่จะวุ่นวาย
ความถูกต้องเชิงโครงสร้างหมายถึงเอาต์พุตสามารถแยกวิเคราะห์ได้และมีรูปร่างตามที่คาด (เช่น JSON ที่ถูกต้อง คีย์ที่ต้องมี ประเภทข้อมูลถูกต้อง)
ความถูกต้องเชิงธุรกิจหมายถึงเนื้อหาตรงตามกฎขององค์กร (เช่น ไอดีต้องมีอยู่ ยอดรวมต้องตรง ข้อความคืนเงินต้องเป็นไปตามนโยบาย) โดยปกติคุณต้องมีทั้งสองชั้นนี้
สัญญาเชิงปฏิบัติคือการกำหนดเงื่อนไขที่ต้องเป็นจริงในสามจุด:
เมื่อมีสัญญาแล้ว ตัวตรวจสอบก็เป็นเพียงการบังคับใช้สัญญาโดยอัตโนมัติ
ถือว่าการนำเข้าเป็นวงกว้าง: ข้อความผู้ใช้ ไฟล์ ฟอร์ม โครงสร้าง payload ของ API และข้อมูลที่ดึงมา
การตรวจสอบที่ให้ผลสูงได้แก่ ฟิลด์ที่จำเป็น ขนาด/ประเภทไฟล์ ขอบเขตค่า ข้อจำกัดความยาว การเข้ารหัส/ฟอร์แมตที่ถูกต้อง ซึ่งช่วยลดความสับสนของโมเดลและปกป้องพาร์ตเซอร์และฐานข้อมูลด้านหลัง
ทำการปรับมาตรฐานเมื่อเจตนาไม่คลุมเครือน้อยและการเปลี่ยนแปลงย้อนกลับได้ (เช่น ตัดช่องว่าง ปรับตัวพิมพ์ของรหัสประเทศ)
ปฏิเสธเมื่อการ “แก้ไข” อาจเปลี่ยนความหมายหรือปกปิดข้อผิดพลาด (เช่น วันที่กำกวมอย่าง “03/04/2025” สกุลเงินที่ไม่คาดคิด โค้ด HTML/JS ที่น่าสงสัย)
กฎง่ายๆ: แก้ไขอัตโนมัติสำหรับรูปแบบ ปฏิเสธสำหรับความหมาย
เริ่มจากสคีมาเอาต์พุตชัดเจน:
answer, status)แล้วเพิ่มการตรวจสอบเชิงความหมาย (ไอดีต้อง resolve ยอดรวมต้องตรง วันที่ต้องสมเหตุผล แหล่งอ้างอิงสนับสนุนข้ออ้าง) หากตรวจสอบไม่ผ่าน อย่าเอาผลลัพธ์ไปใช้ต่อ—ลองใหม่ด้วยข้อกำหนดเข้มงวดขึ้นหรือใช้ fallback
หยุดเร็ว (fail fast) เมื่อการดำเนินต่อไปมีความเสี่ยง: แยกวิเคราะห์ไม่ได้ ขาดฟิลด์ที่ต้องมี ฝ่าฝืนนโยบาย
ทำให้ล้มเหลวอย่างสุภาพเมื่อมีทางกู้คืนปลอดภัย: timeout ชั่วคราว rate limit หรือปัญหาการจัดรูปแบบเล็กน้อย
ในทั้งสองกรณี แยกผลลัพธ์เป็น:
การลองใหม่ช่วยเมื่อความล้มเหลวเป็นแบบชั่วคราว (timeouts, 429, หยุดชะงักชั่วคราว) — ใช้ retries ที่จำกัดพร้อม exponential backoff และ jitter
การลองใหม่ไม่เหมาะเมื่อเป็น “คำตอบผิด” เช่น mismatch ของสคีมา ขาดฟิลด์ที่จำเป็น หรือฝ่าฝืนนโยบาย ควรซ่อม prompt (กำชับคำสั่ง) ใช้เทมเพลตที่กำหนด หรือส่งให้คนตรวจสอบแทน
กรณีขอบเขตมักมาจาก:
ค้นพบ “สิ่งที่ไม่รู้” ผ่านล็อกที่คำนึงความเป็นส่วนตัว เพื่อจับว่า rule ไหนล้มเหลวและเส้นทางการกู้คืนใดถูกรัน