18 ธ.ค. 2568·2 นาที
โหมดวางแผนสกีมา Postgres: แนวทางทีละขั้นตอน
โหมดวางแผนสกีมา Postgres ช่วยให้คุณกำหนดเอนทิตี ข้อจำกัด ดัชนี และมิเกรชันก่อนสร้างโค้ด เพื่อลดการเขียนซ้ำภายหลัง
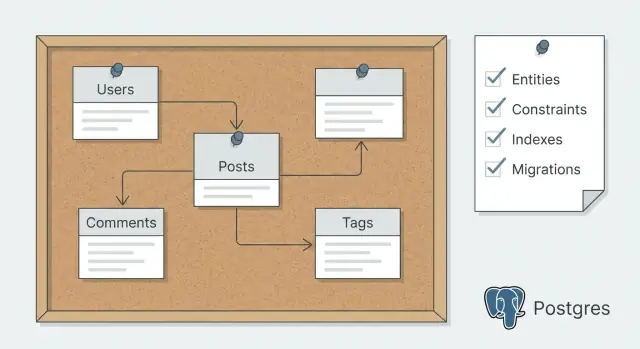
โหมดวางแผนสกีมา Postgres ช่วยให้คุณกำหนดเอนทิตี ข้อจำกัด ดัชนี และมิเกรชันก่อนสร้างโค้ด เพื่อลดการเขียนซ้ำภายหลัง
ถ้าคุณสร้าง endpoints และโมเดลก่อนที่รูปแบบฐานข้อมูลจะชัดเจน มักจะจบลงด้วยการเขียนฟีเจอร์เดิมซ้ำสองครั้ง แอปทำงานสำหรับเดโม แล้วข้อมูลจริงและกรณีขอบจริงก็เข้ามาและทุกอย่างเริ่มเปราะบาง
การเขียนซ้ำส่วนใหญ่เกิดจากสามปัญหาที่คาดเดาได้:
แต่ละปัญหาจะบังคับให้เกิดการเปลี่ยนแปลงที่ส่งผลไปยังโค้ด เทส และไคลเอนต์แอป
การวางแผนสกีมา Postgres หมายถึงการตัดสินใจสัญญาข้อมูลก่อน แล้วสร้างโค้ดที่สอดคล้องกับมัน ในทางปฏิบัติ นั่นคือการเขียนลงว่าเอนทิตี ความสัมพันธ์ และคำค้นหลักที่สำคัญ แล้วเลือกข้อจำกัด ดัชนี และแนวทางมิเกรชันก่อนที่เครื่องมือใดจะสเคฟโฟลด์ตารางและ CRUD
เรื่องนี้สำคัญยิ่งขึ้นเมื่อคุณใช้แพลตฟอร์มสร้างโค้ดเร็วอย่าง Koder.ai ซึ่งสามารถสร้างโค้ดได้มากอย่างรวดเร็ว การสร้างที่เร็วดี แต่เชื่อถือได้มากกว่าหากสกีมาแน่นอน โมเดลและ endpoints ที่สร้างออกมาต้องแก้ไขน้อยลงในภายหลัง
นี่คือสิ่งที่มักจะผิดพลาดเมื่อคุณข้ามการวางแผน:
แผนสกีมาที่ดีคือเรียบง่าย: คำอธิบายเป็นภาษาธรรมดาของเอนทิตี ร่างตารางและคอลัมน์ ข้อจำกัดและดัชนีสำคัญ และกลยุทธ์มิเกรชันที่ทำให้คุณเปลี่ยนแปลงได้อย่างปลอดภัยเมื่อผลิตภัณฑ์เติบโต
การวางแผนสกีมาจะได้ผลดีที่สุดเมื่อคุณเริ่มจากสิ่งที่แอปต้องจดจำและสิ่งที่ผู้คนต้องทำกับข้อมูลนั้น เขียนเป้าหมายเป็น 2–3 ประโยค ถ้าคุณอธิบายไม่ง่าย คุณอาจสร้างตารางเพิ่มที่ไม่จำเป็น
ถัดไป มุ่งความสนใจไปที่การกระทำที่สร้างหรือเปลี่ยนข้อมูล การกระทำเหล่านี้คือต้นทางของแถวจริง ๆ และเปิดเผยสิ่งที่ต้องตรวจสอบ คิดเป็นคำกริยา ไม่ใช่คำนาม
ตัวอย่าง แอปจองอาจต้องสร้างการจอง เลื่อนการจอง ยกเลิก คืนเงิน และส่งข้อความหาลูกค้า คำกริยาเหล่านี้จะบอกได้อย่างรวดเร็วว่าสิ่งใดต้องเก็บ (ช่องเวลา การเปลี่ยนสถานะ จำนวนเงิน) ก่อนที่คุณจะตั้งชื่อตาราง
จับเส้นทางการอ่านด้วย เพราะการอ่านขับเคลื่อนโครงสร้างและการจัดทำดัชนีภายหลัง ลิสต์หน้าจอหรือรายงานที่ผู้คนจะใช้จริงและวิธีที่เขาตัดข้อมูล: “การจองของฉัน” เรียงตามวันที่และกรองตามสถานะ, การค้นหาในแอดมินตามชื่อลูกค้าหรือหมายเลขการจอง, รายได้รายวันตามสถานที่, และมุมมองตรวจสอบว่าใครเปลี่ยนอะไรและเมื่อไร
สุดท้าย ให้บันทึกความต้องการที่ไม่ใช่ฟังก์ชันซึ่งเปลี่ยนการเลือกสกีมา เช่น ประวัติการตรวจสอบ, soft deletes, การแยก multi-tenant, หรือกฎความเป็นส่วนตัว (เช่น จำกัดผู้ที่เห็นรายละเอียดการติดต่อ)
ถ้าคุณวางแผนจะสร้างโค้ดหลังจากนี้ หมายเหตุดังกล่าวจะกลายเป็นพรอมต์ที่ชัดเจน พวกมันบอกชัดว่าอะไรจำเป็น อะไรเปลี่ยนได้ และอะไรต้องค้นหาได้ หากคุณใช้ Koder.ai การเขียนสิ่งนี้ก่อนสร้างทำให้โหมดวางแผนมีประสิทธิภาพมากขึ้นเพราะแพลตฟอร์มทำงานจากข้อกำหนดจริงแทนการเดา
ก่อนแตะตาราง ให้เขียนคำอธิบายง่าย ๆ ว่าแอปของคุณเก็บอะไร เริ่มจากการลิสต์คำนามที่คุณพูดซ้ำ: user, project, message, invoice, subscription, file, comment แต่ละคำนามคือเอนทิตีที่เป็นไปได้
แล้วเพิ่มหนึ่งประโยคต่อเอนทิตีที่ตอบว่า: มันคืออะไร และทำไมต้องมี ตัวอย่าง: “Project คือพื้นที่ทำงานที่ผู้ใช้สร้างเพื่อจัดกลุ่มงานและเชิญผู้อื่น” นี่ช่วยหลีกเลี่ยงตารางกำกวมเช่น data, items, หรือ misc
การเป็นเจ้าของเป็นการตัดสินใจสำคัญถัดไป และมันกระทบเกือบทุกคำค้นที่คุณเขียน สำหรับแต่ละเอนทิตี ให้ตัดสินใจ:
ตอนนี้ตัดสินใจว่าจะระบุระเบียนอย่างไร UUIDs ดีเมื่อระเบียนถูกสร้างจากหลายที่ (เว็บ มือถือ งานแบ็กกราวด์) หรือเมื่อคุณไม่ต้องการ ID ที่คาดเดาได้ Bigint เล็กกว่าและเร็วกว่านิดหน่อย ถ้าต้องการตัวระบุที่คนอ่านเข้าใจ ให้เก็บแยกต่างหาก (เช่น project_code ที่สั้นและเฉพาะภายในบัญชี) แทนบังคับให้เป็น primary key
สุดท้าย เขียนความสัมพันธ์ด้วยคำก่อนจะวาดไดอะแกรม: user มีหลาย project, project มีหลาย message, และ user สามารถเป็นสมาชิกหลาย project กำกับแต่ละลิงก์ว่าเป็น required หรือ optional เช่น “message ต้องเป็นของ project” เทียบกับ “invoice อาจเป็นของ project” ประโยคเหล่านี้จะเป็นแหล่งความจริงสำหรับการสร้างโค้ดต่อไป
เมื่อเอนทิตีอ่านชัดเป็นภาษาธรรมดา ให้แปลงแต่ละอันเป็นตารางพร้อมคอลัมน์ที่ตรงกับข้อมูลจริงที่ต้องเก็บ
เริ่มจากชื่อและชนิดที่คุณสามารถยึดได้ เลือกรูปแบบที่สอดคล้อง: ชื่อคอลัมน์เป็น snake_case, ใช้ชนิดเดียวกันสำหรับแนวคิดเดียวกัน, และ primary key ที่คาดเดาได้ สำหรับ timestamps ให้ใช้ timestamptz เพื่อไม่ให้โซนเวลาทำให้คุณแปลกใจ สำหรับเงิน ให้ใช้ numeric(12,2) (หรือเก็บเป็นเซนต์เป็น integer) แทน float
สำหรับฟิลด์สถานะ ให้ใช้ Postgres enum หรือคอลัมน์ text พร้อม CHECK constraint เพื่อควบคุมค่าที่อนุญาต
ตัดสินใจว่าสิ่งใดเป็น required vs optional โดยแปลงกฎเป็น NOT NULL ถ้าค่าต้องมีเพื่อให้แถวมีความหมาย ให้บังคับ NOT NULL ถ้าจริง ๆ แล้วไม่รู้หรือไม่สามารถใช้ได้ ให้อนุญาต null
ชุดคอลัมน์เริ่มต้นที่เป็นประโยชน์ในการวางแผน:
id (uuid หรือ bigint, เลือกแนวทางเดียวและยึดตามมัน)created_at และ updated_atdeleted_at ก็ต่อเมื่อคุณต้องการ soft deletes จริง ๆ และการคืนค่าจำเป็นcreated_by เมื่อคุณต้องการร่องรอยการตรวจสอบว่าใครทำอะไรความสัมพันธ์ many-to-many ควรกลายเป็นตารางเชื่อม เสมอ ตัวอย่าง ถ้าหลายผู้ใช้สามารถร่วมงานในแอป ให้สร้าง app_members โดยมี app_id และ user_id แล้วบังคับความเฉพาะบนคู่เพื่อไม่ให้เกิดค่าซ้ำ
คิดถึงประวัติล่วงหน้า หากคุณรู้ว่าจะต้องการ versioning ให้วางแผนตารางไม่เปลี่ยนแปลงเช่น app_snapshots ที่แต่ละแถวเป็นเวอร์ชันที่บันทึกและเชื่อมกับ apps โดย app_id และมี created_at
Constraints คือราวป้องกันของสกีมา ตัดสินใจว่ากฎใดต้องเป็นจริงไม่ว่าบริการ สคริปต์ หรือเครื่องมือแอดมินใดจะเข้าถึงฐานข้อมูล
เริ่มจากตัวตนและความสัมพันธ์ ทุกตารางต้องมี primary key และคอลัมน์ “belongs to” ทุกตัวควรเป็น foreign key จริง ๆ ไม่ใช่แค่ integer ที่หวังว่าจะตรงกัน
แล้วเพิ่มความเฉพาะ (uniqueness) ในที่ที่การซ้ำจะก่อให้เกิดปัญหาจริง เช่น บัญชีสองบัญชีมีอีเมลเดียวกัน หรือสองไลน์ไอเท็มมี (order_id, product_id) เหมือนกัน
ข้อจำกัดที่มีค่าสูงที่ควรวางแผนตั้งแต่ต้น:
amount >= 0, status IN ('draft','paid','canceled'), หรือ rating BETWEEN 1 AND 5พฤติกรรม cascade คือที่ที่การวางแผนออมคุณได้ในภายหลัง ถามว่าผู้คนคาดหวังอะไร ถ้าลูกค้าถูกลบ คำสั่งซื้อของพวกเขามักไม่ควรหาย นั่นชี้ไปที่ restrict deletes และเก็บประวัติ สำหรับข้อมูลที่ขึ้นกับพาเรนต์เช่น order line items การ cascade จาก order ไปยัง items อาจสมเหตุสมผลเพราะ items ไม่มีความหมายโดยไม่มี parent
เมื่อคุณสร้างโมเดลและ endpoints ภายหลัง ข้อจำกัดเหล่านี้จะกลายเป็นข้อกำหนดที่ชัดเจน: ข้อผิดพลาดใดต้องจัดการ ฟิลด์ใดบังคับ และกรณีขอบใดที่เป็นไปไม่ได้โดยการออกแบบ
ดัชนีควรถามคำถามเดียว: อะไรต้องเร็วสำหรับผู้ใช้จริง
เริ่มจากหน้าจอและ API ที่คุณคาดว่าจะส่งออกมาแรก ๆ หน้ารายการที่กรองตามสถานะและเรียงตามล่าสุดต้องการสิ่งต่างจากหน้ารายละเอียดที่โหลดระเบียนที่เกี่ยวข้อง
เขียน 5–10 แบบคำค้นก่อนเลือกดัชนี ตัวอย่าง: “แสดงใบแจ้งหนี้ของฉันใน 30 วันที่ผ่านมา กรองตามชำระ/ยังไม่ชำระ เรียงตาม created_at” หรือ “เปิดโปรเจกต์และลิสต์งานตาม due_date” จะทำให้การเลือกดัชนียึดกับการใช้งานจริง
ชุดดัชนีเริ่มต้นที่ดีมักรวมถึงคอลัมน์ foreign key ที่ใช้ join, คอลัมน์กรองทั่วไป (เช่น status, user_id, created_at) และหนึ่งหรือสองดัชนีคอมโพสิตสำหรับคำค้นหลายตัวที่คงที่ เช่น (account_id, created_at) เมื่อคุณกรองเสมอด้วย account_id แล้วเรียงตามเวลา
ลำดับคอลัมน์ในดัชนีคอมโพสิตสำคัญ ให้คอลัมน์ที่คุณกรองบ่อยและมีความเลือกสูงสุดอยู่หน้า หากคุณกรองด้วย tenant_id ในทุกคำขอ มันมักจะอยู่หน้าของหลาย ๆ ดัชนี
หลีกเลี่ยงการจัดดัชนีทุกอย่าง “กันไว้ก่อน” แต่ละดัชนีเพิ่มงานตอน INSERT และ UPDATE และนั่นอาจทำร้ายมากกว่าคำค้นไม่กี่คำที่ช้าบ้าง
วางแผนการค้นหาข้อความแยกต่างหาก ถ้าคุณต้องการแค่การจับคำง่าย ๆ ILIKE อาจพอในตอนแรก หากการค้นหาเป็นแกนหลัก ให้วางแผนสำหรับ full-text search (tsvector) ตั้งแต่แรกเพื่อไม่ต้องออกแบบใหม่ทีหลัง
สกีมาไม่ได้ “เสร็จ” เมื่อคุณสร้างตารางแรก มันเปลี่ยนทุกครั้งที่คุณเพิ่มฟีเจอร์ แก้ไขข้อผิดพลาด หรือต้องเรียนรู้เพิ่มเติม ถ้าคุณตัดสินใจแนวทางมิเกรชันตั้งแต่ต้น คุณจะหลีกเลี่ยงการเขียนซ้ำที่เจ็บปวดหลังการสร้างโค้ด
ยึดกฎง่าย ๆ: เปลี่ยนฐานข้อมูลทีละขั้นแบบเล็ก ๆ ฟีเจอร์ละขั้น มิเกรชันแต่ละอันควรตรวจทานได้ง่ายและปลอดภัยในการรันในทุกสภาพแวดล้อม
การแตกหักส่วนใหญ่เกิดจากการเปลี่ยนชื่อหรือลบคอลัมน์ หรือเปลี่ยนชนิด แทนที่จะทำทุกอย่างในครั้งเดียว ให้วางแผนเส้นทางปลอดภัย:
วิธีนี้ต้องทำหลายขั้น แต่เร็วกว่าจริงเพราะลดการหยุดชะงักและแพตช์ฉุกเฉิน
Seed data เป็นส่วนหนึ่งของมิเกรชันด้วย ตัดสินใจว่าตารางอ้างอิงใดเป็น “มีอยู่เสมอ” (roles, statuses, countries, plan types) และทำให้มันคาดเดาได้ ใส่ inserts และ updates สำหรับตารางเหล่านี้ในมิเกรชันเฉพาะเพื่อให้ทุกนักพัฒนาและการปรับใช้ได้ผลลัพธ์เหมือนกัน
ตั้งความคาดหวังตั้งแต่ต้น:
การย้อนกลับไม่ใช่แค่ "down migration" เสมอไป บางครั้งวิธีย้อนกลับที่ดีที่สุดคือการคืนค่าจากแบ็กอัพ หากคุณใช้ Koder.ai ก็ควรกำหนดด้วยว่าจะพึ่งพาสแนปชอตและการย้อนกลับเมื่อใดสำหรับการกู้คืนอย่างรวดเร็ว โดยเฉพาะก่อนการเปลี่ยนที่เสี่ยง
ลองนึกถึงแอป SaaS เล็ก ๆ ที่คนเข้าร่วมทีม สร้างโปรเจกต์ และติดตามงาน
เริ่มด้วยการลิสต์เอนทิตีและเฉพาะฟิลด์ที่ต้องการในวันแรก:
ความสัมพันธ์ตรงไปตรงมา: ทีมมีหลายโปรเจกต์, โปรเจกต์มีงานหลายงาน, และผู้ใช้เข้าร่วมทีมผ่าน team_members งานเป็นของโปรเจกต์และอาจถูกมอบหมายให้ผู้ใช้
ตอนนี้เพิ่มข้อจำกัดบางอย่างที่ป้องกันบั๊กที่มักพบเกินไป:
ดัชนีควรตรงกับหน้าจอจริง ตัวอย่าง ถ้าลิสต์งานกรองตาม project และ state และเรียงตามล่าสุด ให้วางดัชนีอย่าง tasks (project_id, state, created_at DESC) หาก “งานของฉัน” เป็นมุมมองสำคัญ ดัชนีอย่าง tasks (assignee_user_id, state, due_date) จะช่วยได้
สำหรับมิเกรชัน ให้เก็บชุดแรกไว้ปลอดภัยและเรียบง่าย: สร้างตาราง primary keys foreign keys และ unique constraints หลัก การเปลี่ยนตามหลังที่ดีคือสิ่งที่คุณเพิ่มเมื่อการใช้งานพิสูจน์แล้ว เช่น แนะนำ soft delete (deleted_at) บน tasks และปรับดัชนี "งานที่ใช้งาน" ให้ละแถวที่ถูกลบ
การเขียนซ้ำส่วนใหญ่เกิดเพราะสกีมาแรกขาดกฎและรายละเอียดการใช้งานจริง การวางแผนที่ดีไม่ใช่ไดอะแกรมที่สมบูรณ์แบบ แต่เป็นการจับกับดักตั้งแต่ต้น
ความผิดพลาดทั่วไปคือเก็บกฎสำคัญไว้แค่ในโค้ดแอป หากค่าต้องเป็นเอกลักษณ์ มีอยู่ หรืออยู่ในช่วงที่กำหนด ฐานข้อมูลควรบังคับ มิฉะนั้นงานแบ็กกราวด์ endpoint ใหม่ หรือการนำเข้าด้วยมืออาจข้ามตรรกะของคุณ
อีกข้อผิดพลาดคือคิดว่าดัชนีเป็นปัญหาทีหลัง การเพิ่มดัชนีหลังเปิดใช้งานมักกลายเป็นการเดา และคุณอาจจบด้วยการจัดดัชนีผิดจุด ในขณะที่คำค้นช้าจริง ๆ อาจเป็น join หรือตัวกรองบนฟิลด์สถานะ
ตาราง many-to-many ก็เป็นแหล่งบั๊กเงียบ หากตารางเชื่อมไม่ป้องกันการซ้ำ คุณอาจเก็บความสัมพันธ์เดียวกันสองครั้งและเสียเวลาDebug ว่า “ทำไมผู้ใช้คนนี้มีสองบทบาท?”
นอกจากนี้ง่ายที่จะสร้างตารางก่อนแล้วจึงรู้ว่าคุณต้องการ audit logs, soft deletes, หรือ event history การเพิ่มสิ่งเหล่านี้จะกระทบ endpoints และรายงาน
สุดท้าย คอลัมน์ JSON น่าดึงดูดสำหรับข้อมูล “ยืดหยุ่น” แต่จะลดการตรวจสอบและทำให้การทำดัชนียากขึ้น JSON เหมาะสำหรับ payload ที่เปลี่ยนแปลงจริง ๆ มิใช่ฟิลด์ธุรกิจหลัก
ก่อนสร้างโค้ด ให้รันรายการแก้ไขด่วนนี้:
หยุดตรงนี้และตรวจสอบให้แน่ใจว่าแผนสมบูรณ์พอที่จะแปลงเป็นโค้ดโดยไม่ต้องไล่ตามสิ่งที่ไม่คาดคิด เป้าหมายไม่ใช่ความสมบูรณ์แบบ แต่คือการจับช่องว่างที่จะทำให้ต้องเขียนซ้ำภายหลัง: ความสัมพันธ์ที่ขาด กฎไม่ชัด และดัชนีที่ไม่ตรงกับการใช้งานจริง
ใช้เช็คลิสต์นี้เป็นการตรวจสอบก่อนบินอย่างรวดเร็ว:
amount >= 0 หรือสถานะที่อนุญาต)การทดสอบความสมเหตุสมผลอย่างรวดเร็ว: สมมติว่าวันพรุ่งนี้มีเพื่อนร่วมทีมเข้ามา พวกเขาสามารถสร้าง endpoints แรกได้โดยไม่ต้องถามว่า “อันนี้เป็น null ได้ไหม?” หรือ “เกิดอะไรขึ้นเมื่อลบ?” ทุกชั่วโมงหรือเปล่า?
เมื่อแผนอ่านชัดและฟลว์หลักสมเหตุสมผลบนกระดาษ ให้แปลงเป็นสิ่งที่ปฏิบัติได้: สกีมาจริงพร้อมมิเกรชัน
เริ่มด้วยมิเกรชันเริ่มต้นที่สร้างตาราง ประเภท (ถ้าคุณใช้ enums) และข้อจำกัดที่ต้องมี เก็บรอบแรกให้เล็กแต่ถูกต้อง โหลด seed data เล็กน้อยและรันคำค้นที่แอปต้องการจริง ๆ หากฟลว์ใดรู้สึกไม่สะดวก ให้แก้สกีมาในขณะที่ประวัติมิเกรชันยังสั้น
สร้างโมเดลและ endpoints หลังจากที่คุณทดสอบการกระทำแบบ end-to-end สองสามอย่างกับสกีมา (create, update, list, delete และอีกหนึ่ง action ทางธุรกิจจริง) การสร้างโค้ดเร็วกว่ามากเมื่อตาราง คีย์ และการตั้งชื่อคงที่พอที่คุณจะไม่เปลี่ยนชื่อทุกวัน
วงจรปฏิบัติที่ช่วยลดการเขียนซ้ำ:
ตัดสินใจก่อนว่าคุณตรวจสอบอะไรในฐานข้อมูล vs ชั้น API ใส่กฎถาวรในฐานข้อมูล (foreign keys, unique constraints, check constraints) เก็บกฎชั่วคราวไว้ที่ API (feature flags, ข้อจำกัดชั่วคราว และตรรกะแข็งข้ามตารางที่เปลี่ยนบ่อย)
หากคุณใช้ Koder.ai วิธีที่สมเหตุสมผลคือเห็นพ้องกันเรื่องเอนทิตีและมิเกรชันในโหมดวางแผนก่อน แล้วค่อยสร้าง backend Go + PostgreSQL เมื่อการเปลี่ยนเกิดปัญหา สแนปชอตและการย้อนกลับสามารถช่วยให้คุณกลับสู่เวอร์ชันที่รู้จักได้อย่างรวดเร็วขณะปรับแผนสกีมา
วางแผนสกีมาก่อน มันกำหนดสัญญาข้อมูลที่มั่นคง (ตาราง คีย์ ข้อจำกัด) ทำให้โมเดลและ endpoints ที่สร้างออกมาไม่ต้องเปลี่ยนชื่อหรือเขียนซ้ำบ่อย ๆ
ในการปฏิบัติ: เขียนเอนทิตี ความสัมพันธ์ และคำค้นหลัก แล้วล็อกข้อจำกัด ดัชนี และมิเกรชันก่อนจะสร้างโค้ด
เขียน 2–3 ประโยคอธิบายสิ่งที่แอปต้องจดจำและสิ่งที่ผู้ใช้ต้องทำได้
จากนั้นจงลิสต์:
สิ่งนี้จะให้ความชัดเจนเพียงพอที่จะออกแบบตารางโดยไม่สร้างสิ่งเกินความจำเป็น
เริ่มจากการลิสต์คำนามที่คุณพูดซ้ำบ่อย ๆ (user, project, invoice, task) สำหรับแต่ละคำให้เพิ่มประโยคหนึ่งประโยคว่า: มันคืออะไรและทำไมต้องมี
ถ้าคุณอธิบายไม่ชัด คุณมีแนวโน้มจะได้ตารางกำกวมอย่าง items หรือ misc และจะเสียใจทีหลัง
ตั้งค่ายุทธศาสตร์ ID แบบเดียวกันทั้งสกีมา
UUIDs: เหมาะเมื่อระเบียนถูกสร้างจากหลายที่ (เว็บ/มือถือ/งานแบ็กกราวด์) หรือไม่ต้องการ ID ที่คาดเดาได้bigint: เล็กกว่า เร็วกว่าเล็กน้อย และเรียบง่ายเมื่อทุกอย่างถูกสร้างจากเซิร์ฟเวอร์หากต้องการ identifier ที่เป็นมิตรกับคน ให้เพิ่มคอลัมน์แยกที่มีค่าเฉพาะ (เช่น project_code) แทนใช้เป็น primary key
ตัดสินใจเป็นรายความสัมพันธ์ตามสิ่งที่ผู้ใช้คาดหวังและสิ่งที่ต้องเก็บรักษา
ค่าเริ่มต้นทั่วไป:
RESTRICT/NO ACTION เมื่อการลบพาเรนต์จะลบข้อมูลสำคัญ (เช่น customers → orders)CASCADE เมื่อแถวลูกไม่มีความหมายโดยไม่มีพาเรนต์ (เช่น order → line items)ตัดสินใจข้อนี้ตั้งแต่ต้นเพราะมันส่งผลต่อพฤติกรรม API และกรณีขอบ
ใส่กฎถาวรไว้ในฐานข้อมูลเพื่อบังคับให้ผู้เขียนทุกทาง (API, สคริปต์, การนำเข้า, เครื่องมือแอดมิน) ต้องปฏิบัติตาม
ให้ความสำคัญกับ:
เริ่มจากรูปแบบคำค้นจริง ไม่ใช่การเดา
เขียน 5–10 แบบคำค้นเป็นภาษาเรียบง่าย (กรอง + เรียง) แล้วสร้างดัชนีตามนั้น:
status, user_id, created_atสร้างตารางเชื่อมด้วย foreign key สองตัวและบังคับความเฉพาะด้วย UNIQUE แบบคอมโพสิต
ตัวอย่างแบบแผน:
team_members(team_id, user_id, role, joined_at)UNIQUE (team_id, user_id) เพื่อป้องกันการซ้ำวิธีนี้ป้องกันบั๊กเงียบ ๆ เช่น “ทำไมผู้ใช้คนนี้ปรากฏสองครั้ง?” และทำให้คำค้นสะอาด
ค่าเริ่มต้นที่ดี:
timestamptz สำหรับ timestamps (หลีกเลี่ยงปัญหาโซนเวลา)numeric(12,2) หรือเก็บเป็นสตางค์เป็น integer สำหรับเงิน (หลีกเลี่ยง float)CHECK constraintsรักษาความสอดคล้องของชนิดข้อมูลข้ามตาราง (ใช้ชนิดเดียวกันสำหรับแนวคิดเดียวกัน) เพื่อให้ joins และการตรวจสอบเป็นไปอย่างคาดเดาได้
ใช้มิเกรชันเล็ก ๆ ที่ตรวจทานได้และหลีกเลี่ยงการเปลี่ยนแปลงที่ทำลายในขั้นเดียว
เส้นทางที่ปลอดภัย:
นอกจากนี้ตัดสินใจก่อนว่าคุณจะจัดการ seed/reference data อย่างไรเพื่อให้ทุกสภาพแวดล้อมเหมือนกัน
PRIMARY KEY ในทุกตารางFOREIGN KEY สำหรับทุกคอลัมน์ที่ “belongs to”UNIQUE ในที่ที่การซ้ำเป็นอันตรายจริง (อีเมล, (team_id, user_id) ในตาราง join)CHECK สำหรับกฎง่าย ๆ (จำนวนไม่เป็นลบ, สถานะที่อนุญาต)NOT NULL สำหรับฟิลด์ที่จำเป็นต่อความหมายของแถว(account_id, created_at)หลีกเลี่ยงการจัดดัชนีทุกอย่าง เพราะดัชนีแต่ละอันทำให้ INSERT/UPDATE ช้าลง