02 ธ.ค. 2568·2 นาที
วิสัยทัศน์ AI ดั้งเดิมของ Larry Page เบื้องหลังเกมยาวของ Google
สำรวจว่าแนวคิดแรกเริ่มของ Larry Page เกี่ยวกับ AI และความรู้มีอิทธิพลต่อกลยุทธ์ระยะยาวของ Google อย่างไร—ตั้งแต่คุณภาพการค้นหาไปจนถึง moonshot และการเดิมพันด้าน AI
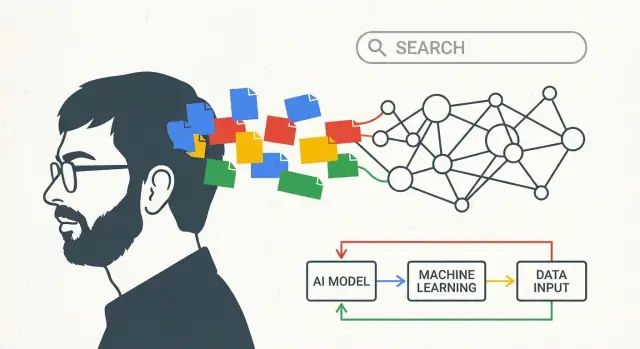
ความหมายของ “วิสัยทัศน์ AI ของ Larry Page” ในโพสต์นี้
นี่ไม่ใช่บทความที่ฮีตเรื่องจุดเปลี่ยนครั้งเดียว แต่เป็นเรื่องการคิดระยะยาว: บริษัทเลือกทิศทางตั้งแต่ต้น ลงทุนต่อเนื่องผ่านการเปลี่ยนเทคโนโลยีหลายครั้ง และค่อย ๆ เปลี่ยนไอเดียใหญ่ให้กลายเป็นผลิตภัณฑ์ที่ใช้กันทุกวัน
เมื่อโพสต์นี้พูดถึง “วิสัยทัศน์ AI ของ Larry Page” ไม่ได้หมายความว่า “Google ทำนายแชตบอทสมัยนี้” แต่มันหมายถึงสิ่งที่เรียบง่ายกว่าและทนทานกว่า: การสร้างระบบที่เรียนรู้จากประสบการณ์
คำจำกัดความแบบเข้าใจง่าย
ในโพสต์นี้ “วิสัยทัศน์ AI” หมายถึงความเชื่อที่เชื่อมโยงกันไม่กี่ข้อ:
- คอมพิวเตอร์ควรปรับปรุงสมรรถนะด้วยการเรียนรู้จากข้อมูล ไม่ใช่แค่ทำตามกฎที่เขียนขึ้นด้วยมือเท่านั้น
- ระบบที่ดีที่สุดพัฒนาได้ตามเวลาเพราะการใช้งานจริงสร้างฟีดแบ็ก (สิ่งที่ผู้คนคลิก สิ่งที่พวกเขาไม่สนใจ สิ่งที่พวกเขาพิมพ์ใหม่)
- เพื่อให้การเรียนรู้ใช้งานได้จริง คุณต้องมีโครงสร้างพื้นฐาน: คอมพิวติ้งรวดเร็ว พื้นที่จัดเก็บที่เชื่อถือได้ และวิธีรันการทดลองอย่างปลอดภัยในระดับมหาศาล
ด้วยคำอื่น ๆ “วิสัยทัศน์” วัดจากการสร้างเครื่องยนต์มากกว่ารุ่นเดียว: รวบรวมสัญญาณ เรียนรู้รูปแบบ ส่งการปรับปรุง ปฏิบัติซ้ำ
แนวเส้นที่จะติดตาม
เพื่อทำให้ไอเดียนี้ชัดเจน โพสต์ที่เหลือติดตามความก้าวหน้าง่าย ๆ ดังนี้:
- ค้นหา (Search): เริ่มจากปัญหาชัดเจน—ช่วยคนหาคำตอบที่ดี
- ข้อมูล + โครงสร้างพื้นฐาน: ใช้การใช้งานจริงเรียนรู้ว่า “ดี” เป็นอย่างไร และสร้างเครื่องจักรที่ประมวลผลมัน
- ผลิตภัณฑ์ AI-first: ทำให้ระบบที่เรียนรู้เป็นวิธีเริ่มต้น เพื่อให้เสียง รูปภาพ และอินเทอร์เฟซใหม่ ๆ ทำงานได้ดีโดยไม่ต้องเขียนทุกอย่างใหม่
เมื่อจบแล้ว “วิสัยทัศน์ AI ของ Larry Page” ควรจะรู้สึกไม่ใช่สโลแกน แต่เป็นกลยุทธ์: ลงทุนตั้งแต่ต้นในระบบการเรียนรู้ สร้างท่อส่งข้อมูลที่เลี้ยงมัน และอดทนให้ความก้าวหน้าทบต้นเป็นเวลาหลายปี
ปัญหาเริ่มต้นที่ Google พยายามแก้: การหา ‘คำตอบที่ดี’
เว็บในช่วงแรกมีปัญหาเรียบง่ายแต่ผลลัพธ์ยุ่งเหยิง: ข้อมูลเพิ่มขึ้นจนคนเดียวคัดกรองไม่ไหว และเครื่องมือค้นหาส่วนใหญ่เดาได้ว่าอะไรสำคัญ
ถ้าพิมพ์คำค้น เครื่องมือหลายตัวพึ่งสัญญาณเด่นชัด—คำปรากฏบ่อยแค่ไหน อยู่ในชื่อเรื่องไหม หรือเจ้าของเว็บยัดคำลงในข้อความล่องหนบ่อยแค่ไหน นั่นทำให้ผลลัพธ์ง่ายต่อการเล่นกลและยากจะเชื่อถือ เว็บเติบโตเร็วกว่าเครื่องมือที่จะจัดการมัน
PageRank อธิบายแบบคำแนะนำ
ข้อสังเกตสำคัญของ Larry Page และ Sergey Brin คือเว็บมีระบบลงคะแนนฝังอยู่แล้ว: ลิงก์
ลิงก์จากหน้าหนึ่งไปยังหน้าอื่นคล้ายการอ้างอิงในงานวิจัยหรือคำแนะนำจากเพื่อน แต่ไม่ใช่คำแนะนำทุกอันเท่ากัน ลิงก์จากหน้าที่หลายหน้ามองว่ามีค่า ควรถูกนับมากกว่าลิงก์จากหน้าไม่เป็นที่รู้จัก PageRank แปลงไอเดียนั้นเป็นคณิตศาสตร์: แทนที่จะจัดอันดับหน้าโดยดูจากสิ่งที่หน้าบอกเกี่ยวกับตัวมันเองเท่านั้น Google จัดอันดับโดยสิ่งที่เว็บส่วนที่เหลือ “พูด” ผ่านการเชื่อมโยง
สิ่งนี้ทำให้เกิดผลสองอย่างพร้อมกัน:
- ช่วยดันหน้าที่มีความน่าเชื่อถือขึ้นมา แม้จะไม่ได้ซ้ำคำค้นตรง ๆ
- ทำให้การจัดอันดับยากต่อการถูกเล่นกล เพราะความน่าเชื่อถือต้องหาได้จากเครือข่ายไซต์ทั้งหมด
ทำไมการวัดและการทำซ้ำจึงสำคัญตั้งแต่วันแรก
แค่ออกไอเดียการจัดอันดับฉลาดยังไม่พอ คุณภาพการค้นหาเป็นเป้าหมายที่เปลี่ยนอยู่เสมอ: หน้าใหม่ปรากฏ สแปมปรับตัว และความหมายของคำค้นอาจเปลี่ยน
ดังนั้นระบบต้องวัดได้และอัปเดตได้ Google พึ่งพาการทดสอบอย่างต่อเนื่อง—ลองเปลี่ยน วัดว่าผลลัพธ์ดีขึ้นไหม แล้วทำซ้ำ นิสัยการทำซ้ำนี้หล่อหลอมวิธีการระยะยาวของบริษัทในการสร้างระบบ "เรียนรู้": มองการค้นหาเป็นสิ่งที่ประเมินได้ต่อเนื่อง ไม่ใช่งานวิศวกรรมครั้งเดียว
ข้อมูลเป็นวงจรไหล: เรียนรู้จากการใช้งานจริง
การค้นหาที่ดีไม่ใช่แค่มีอัลกอริทึมฉลาด แต่มาจากคุณภาพและปริมาณสัญญาณที่อัลกอริทึมเรียนรู้
Google ยุคแรกได้เปรียบแบบฝังอยู่: เว็บเองเต็มไปด้วย "โหวต" ว่าสิ่งไหนสำคัญ ลิงก์ระหว่างหน้า (พื้นฐานของ PageRank) ทำหน้าที่เหมือนการอ้างอิง ข้อความจุดเชื่อม (anchor text) เพิ่มความหมาย นอกจากนี้รูปแบบภาษาในหน้าเว็บช่วยให้ระบบเข้าใจคำพ้อง การสะกด และวิธีที่หลากหลายที่ผู้คนถามคำถามเดียวกัน
วงจรฟีดแบ็กที่ทบต้น
เมื่อผู้คนเริ่มใช้เครื่องมือค้นหาในระดับใหญ่ การใช้งานสร้างสัญญาณเพิ่มเติม:
- คลิกแสดงผลว่าผลลัพธ์ใดดูเกี่ยวข้องกับผู้ใช้จริงสำหรับคำค้นนั้น
- “คลิกนาน” เทียบกับการกลับไปกลับมาเร็ว ๆ บ่งชี้ความพึงพอใจ
- การแก้ไขคำค้น (ค้นหาใหม่ด้วยคำอื่น) เผยความไม่ตรงกันระหว่างเจตนาและผลลัพธ์
นี่คือวงจรฟลายวีล: ผลลัพธ์ที่ดีขึ้นดึงการใช้งานมากขึ้น; การใช้งานมากขึ้นสร้างสัญญาณที่อุดมขึ้น; สัญญาณที่อุดมขึ้นปรับปรุงการจัดอันดับและความเข้าใจ; การปรับปรุงนั้นดึงผู้ใช้เพิ่มขึ้นเรื่อย ๆ เมื่อเวลาผ่านไป การค้นหาจะเหมือนระบบที่เรียนรู้และปรับตัวตามสิ่งที่ผู้คนพบว่ามีประโยชน์จริง ๆ
ทำไมความหลากหลายของข้อมูลจึงสำคัญ
ชนิดของข้อมูลต่าง ๆ เสริมกัน โครงสร้างลิงก์อาจเผยอำนาจความน่าเชื่อถือ ขณะที่พฤติกรรมการคลิกสะท้อนความชอบปัจจุบัน และข้อมูลภาษาช่วยแปลความหมายคำค้นที่ไม่ชัดเจน (“jaguar” หมายถึงสัตว์หรือรถ) เมื่อรวมกัน พวกมันทำให้ตอบได้ไม่ใช่แค่ "หน้าไหนมีคำเหล่านี้" แต่ "คำตอบที่ดีที่สุดสำหรับเจตนานี้คืออะไร"
หมายเหตุเรื่องความเป็นส่วนตัว
วงจรฟลายวีลนี้ยกคำถามความเป็นส่วนตัวที่ชัดเจน งานรายงานสาธารณะชี้ว่าผลิตภัณฑ์ผู้บริโภคขนาดใหญ่สร้างข้อมูลการโต้ตอบมหาศาล และบริษัทใช้สัญญาณรวมหรือสถิติเพื่อปรับปรุงคุณภาพ มีการระบุด้วยว่า Google ลงทุนในมาตรการความเป็นส่วนตัวและความปลอดภัยตลอดเวลา แม้รายละเอียดและประสิทธิผลจะเป็นเรื่องถกเถียง
ข้อสรุปง่าย ๆ: การเรียนรู้จากการใช้งานจริงมีพลัง—และความไว้วางใจขึ้นกับการจัดการการเรียนรู้นั้นอย่างรับผิดชอบ
การสร้าง “เครื่อง”: โครงสร้างพื้นฐานที่ทำให้ AI ใช้งานได้จริง
Google ไม่ได้ลงทุนในคอมพิวติ้งแบบกระจายเพราะเป็นเทรนด์ แต่เพราะเป็นทางเดียวที่จะตามจังหวะความยุ่งเหยิงของเว็บ ถ้าคุณอยากครอว์ลหน้าหลายพันล้าน อัปเดตการจัดอันดับบ่อย และตอบคำถามในไม่กี่วินาที คุณไม่สามารถพึ่งคอมพิวเตอร์เครื่องเดียวได้ คุณต้องมีเครื่องจำนวนพัน ๆ ตัวราคาถูกทำงานร่วมกัน พร้อมซอฟต์แวร์ที่มองความล้มเหลวเป็นเรื่องปกติ
ทำไมคอมพิวติ้งแบบกระจายสำคัญตั้งแต่ต้น
การค้นหาบังคับให้ Google สร้างระบบที่เก็บและประมวลผลข้อมูลจำนวนมหาศาลได้อย่างเชื่อถือได้ แนวทาง “หลายเครื่อง หนึ่งระบบ” นั้นกลายเป็นรากฐานของทุกสิ่งที่ตามมา: การทำดัชนี การวิเคราะห์ การทดลอง และในท้ายที่สุดการเรียนรู้ของเครื่อง
ข้อสรุปสำคัญคือ โครงสร้างพื้นฐานไม่ใช่เรื่องแยกจาก AI—มันกำหนดว่ารุ่นแบบใดเป็นไปได้
โครงสร้างพื้นฐานเปลี่ยน AI จากเดโมเป็นสินค้าอย่างไร
การฝึกโมเดลที่มีประโยชน์หมายถึงการโชว์ตัวอย่างจริงจำนวนมาก การให้บริการโมเดลหมายถึงการรันสำหรับผู้คนนับล้านทันทีโดยไม่มีการขัดข้อง ทั้งสองอย่างเป็น "ปัญหาเชิงสเกล":
- การฝึก ต้องการคอมพิวต์มหาศาลเพื่อประมวลผลข้อมูลซ้ำ ๆ
- การให้บริการ ต้องการระบบหน่วงต่ำเพื่อทำนายอย่างรวดเร็ว (มักเป็นมิลลิวินาที) แม้ในช่วงการจราจรหนาแน่น
เมื่อคุณสร้างพายไลน์สำหรับเก็บข้อมูล แจกจ่ายการคำนวณ ตรวจสอบประสิทธิภาพ และเปิดตัวการอัปเดตอย่างปลอดภัย ระบบที่อาศัยการเรียนรู้สามารถปรับปรุงต่อเนื่องได้ แทนที่จะมาเป็นการเขียนทับครั้งเดียวที่เสี่ยง
ตัวอย่างในชีวิตประจำวันของ “AI ที่ขับเคลื่อนด้วยท่อส่ง”
ฟีเจอร์คุ้นเคยบางอย่างแสดงให้เห็นว่าทำไมเครื่องจักรจึงสำคัญ:
- แก้คำสะกด: สังเกตรูปแบบอย่าง “restarant” → “restaurant” ต้องเรียนรู้จากการค้นหาและคลิกจำนวนมาก แล้วนำไปใช้ทันทีเมื่อมีการค้นหา
- เติมข้อความอัตโนมัติ: คาดเดาที่คุณกำลังจะพิมพ์ขึ้นอยู่กับพฤติกรรมรวมและการอนุมานเร็ว—มิฉะนั้นคำแนะนำจะหน่วงและรู้สึกผิด
- การแปลภาษา: คุณภาพการแปลดีขึ้นจากการฝึกบนชุดข้อมูลขนาดใหญ่แล้วส่งโมเดลที่ทำงานได้รวดเร็วสำหรับผู้ใช้ทั่วโลก
ข้อได้เปรียบระยะยาวของ Google ไม่ใช่แค่อัลกอริทึมฉลาด แต่เป็นการสร้างเครื่องยนต์เชิงปฏิบัติการที่ทำให้อัลกอริทึมเรียนรู้ ส่งมอบ และปรับปรุงในระดับอินเทอร์เน็ต
จากกฎสู่การเรียนรู้: การค้นหาค่อย ๆ เป็น ‘เหมือน AI’ มากขึ้นอย่างไร
ไปสู่โปรดักชันเร็วขึ้น
จากแชทสู่การปรับใช้และโฮสติ้ง เพื่อให้ทีมเรียนรู้จากการใช้งานจริงเร็วขึ้น
Google ยุคแรกดู “ฉลาด” แต่ปัญญานั้นถูกออกแบบ: การวิเคราะห์ลิงก์ (PageRank) สัญญาณการจัดอันดับที่จูนด้วยมือ และกฎเฮียริสติกมากมาย เมื่อเวลาผ่านไป จุดศูนย์ถ่วงย้ายจากกฎที่เขียนเองโดยมนุษย์ไปสู่ระบบที่ เรียนรู้ รูปแบบจากข้อมูล—โดยเฉพาะเกี่ยวกับความหมายที่ผู้คนต้องการ ไม่ใช่แค่สิ่งที่พวกเขาพิมพ์
ML เปลี่ยนความรู้สึกของการค้นหาอย่างไร
การเรียนรู้ของเครื่องค่อย ๆ ปรับปรุงสามสิ่งที่ผู้ใช้ทั่วไปสังเกตได้:
- คุณภาพการจัดอันดับ: แทนที่จะให้น้ำหนักสัญญาณด้วยสูตรคงที่ โมเดลเรียนรู้ว่าการรวมสัญญาณแบบไหนมักจะทำให้ผู้ใช้พอใจ (วัดจากพฤติกรรมรวมที่ไม่ระบุตัวตนและความคิดเห็นจากผู้ประเมินคุณภาพ)
- การเข้าใจเจตนา: คำค้นเช่น “jaguar speed” หรือ “apple support” บังคับให้โมเดลอนุมานความหมาย บริบท และความกำกวม ระบบที่เรียนรู้เก่งขึ้นในการแมปถ้อยคำสู่แนวคิดและเป้าหมายที่เป็นไปได้
- สแปมและความน่าเชื่อถือ: เมื่อฟาร์มคอนเทนต์และ SEO เชิงกลยุทธ์ขยายตัว ML ช่วยตรวจจับรูปแบบลิงก์ผิดปกติ เนื้อหาบาง ๆ และกลยุทธ์อื่น ๆ สนับสนุนการผลักดันสู่ผลลัพธ์คุณภาพสูง
ไทม์ไลน์เหตุการณ์สำคัญแบบเข้าใจง่าย
- 1998: PageRank และเอกสารต้นฉบับของ Google วางรากฐานเรื่องความเกี่ยวข้องผ่านลิงก์
- ต้นทศวรรษ 2000: การแก้คำสะกดเชิงสถิติและคำแนะนำคำค้นพัฒนา “คุณหมายถึง” และการปรับคำค้น
- 2011: Panda มุ่งเป้าเนื้อหาคุณภาพต่ำ; สัญญาณคุณภาพเป็นระบบมากขึ้น
- 2012: Penguin ลงโทษการจัดการลิงก์ ทำให้การต่อต้านสแปมข้ามพ้นกฎด้วยมือ
- 2015: RankBrain (ส่วนการจัดอันดับที่ใช้การเรียนรู้) ช่วยคำค้นที่ไม่คุ้นเคยหรือกำกวม
- 2018–2019: neural matching และ BERT นำความเข้าใจภาษาที่แข็งแกร่งกว่า โดยเฉพาะสำหรับคำค้นยาวและคำบุพบท
- 2021+: ยุค MUM และความพยายามเรื่อง “เนื้อหาที่เป็นประโยชน์” ผลักดันสัญญาณความตั้งใจและประโยชน์เชิงลึกขึ้น
แหล่งที่ควรอ้างอิง
เพื่อความน่าเชื่อถือ ควรอ้างผลงานวิจัยหลักและคำอธิบายผลิตภัณฑ์สาธารณะ:
- งานวิจัย: Brin & Page (PageRank, 1998), BERT (Devlin et al., 2018)
- ประกาศการค้นหาอย่างเป็นทางการ: บทความในบล็อก Google Search เกี่ยวกับ RankBrain, BERT, MUM, อัปเดต Panda/Penguin
- การพูด/สัมภาษณ์/งานอีเวนต์: สัมภาษณ์ Amit Singhal เกี่ยวกับวิวัฒนาการการจัดอันดับ; พรีเซนเทชันของ Sundar Pichai (Google I/O); งาน “Search On” สำหรับเหตุการณ์สำคัญสมัยใหม่
วัฒนธรรมการวิจัย: เปลี่ยนความพยายามไกลเป็นระบบที่ใช้งานได้
เกมยาวของ Google ไม่ได้มีแค่ไอเดียใหญ่—มันขึ้นกับวัฒนธรรมการวิจัยที่เปลี่ยนงานในเชิงวิชาการให้กลายเป็นสิ่งที่ผู้คนนับล้านใช้จริง นั่นหมายถึงให้รางวัลกับความอยากรู้อยากเห็น แต่ก็ต้องสร้างเส้นทางจากต้นแบบสู่ผลิตภัณฑ์ที่เชื่อถือได้
จาก “เผยแพร่” สู่ “ส่งออก” (publish → ship)
หลายบริษัทมองงานวิจัยเป็นเกาะแยก Google ผลักดันวงจรที่กระชับกว่า: นักวิจัยสำรวจแนวทางทะเยอทะยาน เผยแพร่ผล และร่วมมือกับทีมผลิตภัณฑ์ที่คำนึงถึงความหน่วง เชื่อถือได้ และความไว้วางใจของผู้ใช้ เมื่อวงจรนั้นทำงาน เอกสารวิจัยไม่ใช่จุดสิ้นสุด แต่เป็นจุดเริ่มต้นของระบบที่เร็วขึ้นและดีกว่า
มองเห็นได้ง่ายจากการที่ไอเดียโมเดลปรากฏในฟีเจอร์ "เล็ก ๆ": การแก้สะกดดีขึ้น การจัดอันดับฉลาดขึ้น คำแนะนำดีขึ้น หรือการแปลที่ฟังดูไม่แปลตามตัว แต่ละก้าวอาจดูเป็นการเปลี่ยนแปลงเล็ก ๆ แต่รวมกันแล้วเปลี่ยนความรู้สึกของ “การค้นหา” ได้
ความพยายามที่เป็นสัญลักษณ์
ความพยายามหลายอย่างกลายเป็นสัญลักษณ์ของท่อจากงานวิจัยสู่สินค้า Google Brain ช่วยผลักดัน deep learning ภายในบริษัทโดยพิสูจน์ว่าทำได้ดีกว่าวิธีเก่าเมื่อมีข้อมูลและคอมพิวต์เพียงพอ ต่อมา TensorFlow ทำให้ทีมฝึกและนำโมเดลขึ้นใช้อย่างสม่ำเสมอ—ส่วนที่ไม่หวือหวาแต่สำคัญมากต่อการสเกล ML ข้ามผลิตภัณฑ์
งานวิจัยเรื่องการแปลเชิงประสาท การรู้จำเสียง และระบบวิชันก็ย้ายจากห้องแลปสู่ประสบการณ์ประจำวัน หลังการทำซ้ำหลายครั้งที่ปรับปรุงคุณภาพและลดต้นทุน
ทำไมความอดทนจึงสำคัญ
ผลตอบแทนไม่ค่อยเกิดขึ้นทันที เวอร์ชันแรกอาจแพง ไม่แม่นยำ หรือยากจะรวมเข้า ระบบได้เปรียบจากการอยู่กับไอเดียนานพอที่จะสร้างโครงสร้างพื้นฐาน เก็บฟีดแบ็ก และปรับโมเดลจนเชื่อถือได้
ความอดทน—ให้ทุน “เดิมพันระยะยาว” ยอมรับทางอ้อม และทำซ้ำเป็นปี ๆ—ช่วยแปลงแนวคิด AI ที่ทะเยอทะยานเป็นระบบที่มีประโยชน์ซึ่งผู้คนไว้วางใจในระดับของ Google
อินพุตใหม่: เสียง รูปภาพ และวิดีโอ บังคับให้โมเดลฉลาดขึ้น
การค้นหาด้วยข้อความตอบแทนด้วยทริคการจัดอันดับ แต่เมื่อ Google เริ่มรับ เสียง ภาพ และ วิดีโอ แนวทางเดิมติดขัด อินพุตเหล่านี้ยาก: สำเนียง เสียงรบกวน รูปภาพเบลอ ภาพวิดีโอสั่น สแลง และบริบทที่ไม่ได้เขียนลงที่ไหนสักแห่ง เพื่อทำให้ใช้งานได้ Google ต้องการระบบที่เรียนรู้รูปแบบจากข้อมูล แทนการพึ่งกฎที่เขียนด้วยมือ
เสียง: แปลงเสียงให้เป็นเจตนา
กับการค้นหาด้วยเสียงและการพิมพ์ด้วยเสียงบน Android เป้าหมายไม่ใช่แค่ "ถอดคำพูด" แต่เป็นการเข้าใจสิ่งที่คนหมายถึง—อย่างรวดเร็ว บนอุปกรณ์ หรือผ่านการเชื่อมต่อไม่เสถียร
การรู้จำเสียงผลักดัน Google สู่การเรียนรู้ของเครื่องขนาดใหญ่ เพราะประสิทธิภาพดีขึ้นเมื่อโมเดลฝึกบนชุดข้อมูลเสียงขนาดใหญ่และหลากหลาย ความกดดันจากผลิตภัณฑ์นั้นทำให้ต้องลงทุนด้านคอมพิวต์ เครื่องมือเฉพาะทาง (พายไลน์ข้อมูล เซ็ตประเมินผล ระบบปรับใช้) และการจ้างคนที่ทำให้โมเดลเป็นผลิตภัณฑ์ที่มีชีวิต ไม่ใช่เดโมวิจัยครั้งเดียว
รูปภาพ: ความหมายไม่ใช่เมตาดาต้า
รูปภาพไม่มีคีย์เวิร์ด ผู้ใช้คาดหวังให้ Google Photos หาภาพ “สุนัข” “ชายหาด” หรือ “ทริปปารีสของฉัน” แม้ไม่เคยแท็กอะไรเลย
ความคาดหวังนี้บังคับให้ต้องมีความเข้าใจรูปภาพที่แข็งแรงขึ้น: การตรวจจับวัตถุ การจัดกลุ่มใบหน้า และการค้นหาความคล้ายคลึง อีกครั้งกฎไม่ครอบคลุมความหลากหลายของชีวิตจริง ดังนั้นระบบที่เรียนรู้จึงเป็นทางปฏิบัติเพื่อความแม่นยำที่ดีขึ้น ต้องการข้อมูลที่ติดป้ายมากขึ้น โครงสร้างฝึกที่ดีกว่า และวงจรการทดลองที่เร็วขึ้น
วิดีโอและคำแนะนำ: การสเกลเผยจุดอ่อน
วิดีโอเพิ่มความท้าทายสองเท่า: เป็นภาพต่อเนื่องตามเวลา บวก เสียง ช่วยให้ผู้ใช้ค้นหาใน YouTube—การค้นหา คำบรรยาย “ถัดไป” และตัวกรองความปลอดภัย—ต้องการโมเดลที่ทั่วไปข้ามหัวข้อและภาษา
ระบบคำแนะนำแสดงความจำเป็นของ ML ชัดเจนยิ่งขึ้น เมื่อผู้คนนับพันล้านคลิก ดู ข้าม และกลับมา ระบบต้องปรับตัวต่อเนื่อง วงจรฟีดแบ็กแบบนั้นให้รางวัลการลงทุนในฝึกแบบสเกล เมตริก และบุคลากรเพื่อให้โมเดลปรับปรุงโดยไม่ทำลายความไว้วางใจ
การเปลี่ยนสู่ AI-first: ทำให้ AI เป็นค่าเริ่มต้น ไม่ใช่ฟีเจอร์
เปลี่ยนงานวิจัยเป็นสินค้า
ตั้งค่าเวิร์กโฟลว์การสร้างที่ทีมสามารถกลับมา วัดผล และปรับปรุงได้เรื่อย ๆ
“AI-first” อธิบายง่ายที่สุดคือการตัดสินใจด้านผลิตภัณฑ์: แทนที่จะใส่ AI เป็นเครื่องมือพิเศษข้าง ๆ คุณทำให้มันเป็นส่วนหนึ่งของเครื่องยนต์ข้างในทุกสิ่งที่ผู้ใช้ใช้อยู่แล้ว
Google อธิบายทิศทางนี้สาธารณะราว 2016–2017 โดยบอกว่ากำลังเปลี่ยนจาก “mobile-first” เป็น “AI-first” ความคิดไม่ใช่ว่าทุกฟีเจอร์จะฉลาดทันที แต่เป็นว่าทางเริ่มต้นที่ผลิตภัณฑ์จะพัฒนาเพิ่มขึ้นจะเป็นระบบการเรียนรู้—การจัดอันดับ คำแนะนำ การรู้จำเสียง การแปล และการตรวจจับสแปม—มากกว่ากฎที่จูนด้วยมือ
AI อยู่ในวงจรหลัก
ในทางปฏิบัติ แนวทาง AI-first ปรากฏเมื่อ "วงจรหลัก" ของผลิตภัณฑ์เปลี่ยนอย่างเงียบ ๆ:
- ผลลัพธ์การค้นหาดีขึ้นเพราะระบบเรียนรู้รูปแบบในคำค้นและการคลิก ไม่ใช่ทีมเขียนกฎ if-then นับพัน
- รูปภาพถูกจัดตามเนื้อหาไม่ใช่ชื่อไฟล์และโฟลเดอร์
- Gmail จับอีเมลไม่พึงประสงค์ได้มากขึ้นโดยเรียนรู้พฤติกรรมที่เปลี่ยนไป แทนที่จะจับคู่คำหลักที่รู้จักเท่านั้น
ผู้ใช้อาจไม่เห็นปุ่มที่เขียนว่า “AI” พวกเขาแค่สังเกตผลลัพธ์ผิดพลาดน้อยลง ความฝืดน้อยลง และคำตอบที่เร็วขึ้น
ผู้ช่วยยกระดับมาตรฐานภาษาธรรมชาติ
ผู้ช่วยเสียงและอินเทอร์เฟซสนทนาปรับความคาดหวัง เมื่อผู้คนพูดว่า “เตือนให้โทรหาแม่เมื่อฉันถึงบ้าน” พวกเขาคาดหวังให้ซอฟต์แวร์เข้าใจเจตนา บริบท และภาษาทุกวันที่ไม่เป็นระบบ
นั่นผลักดันผลิตภัณฑ์ให้มองการเข้าใจภาษาธรรมชาติเป็นความสามารถพื้นฐาน—ทั้งเสียง การพิมพ์ และแม้แต่การชี้กล้องไปที่สิ่งของแล้วถามว่ามันคืออะไร การเปลี่ยนจึงเกี่ยวกับการตอบนิสัยผู้ใช้ใหม่มากกว่าความทะเยอทะยานวิจัย
สำคัญว่า “AI-first” ควรถูกอ่านเป็นทิศทาง—ที่ได้รับการสนับสนุนด้วยคำสาธารณะและการเคลื่อนไหวของผลิตภัณฑ์—ไม่ใช่คำอ้างว่า AI แทนที่วิธีอื่น ๆ ทั้งหมดในพริบตา
Alphabet และเกมยาว: พื้นที่สำหรับเดิมพันนอกการค้นหา
การก่อตั้ง Alphabet ใน 2015 ไม่ใช่แค่การเปลี่ยนชื่อ แต่เป็นการตัดสินใจเชิงปฏิบัติ: แยกแกนที่โตและสร้างรายได้ (Google) ออกจากความพยายามที่มีความเสี่ยงสูงกว่าและระยะยาวกว่า (เรียกว่า “Other Bets”) โครงสร้างนี้สำคัญถ้าคุณคิดว่าวิสัยทัศน์ AI ของ Larry Page เป็นโครงการหลายทศวรรษ ไม่ใช่รอบผลิตภัณฑ์เดียว
ทำไมต้องแยก “แกน” ออกจาก “เดิมพัน”
Google Search, Ads, YouTube และ Android ต้องการการดำเนินงานอย่างต่อเนื่อง: ความเชื่อถือได้ การควบคุมต้นทุน และการทำซ้ำที่มั่นคง Moonshot—รถขับเคลื่อนด้วยตัวเอง วิทยาศาสตร์ชีวิต โครงการเชื่อมต่อ—ต้องการสิ่งต่างไป: ความทนต่อความไม่แน่นอน พื้นที่ทดลองราคาแพง และสิทธิ์ที่จะผิด
ภายใต้ Alphabet แกนหลักจัดการด้วยเป้าหมายการแสดงผลชัดเจน ขณะที่เดิมพันสามารถประเมินตามจุดสกัดการเรียนรู้: “เราพิสูจน์สมมติฐานทางเทคนิคสำคัญหรือไม่?” “โมเดลดีพอเมื่อมีข้อมูลจริงไหม?” “ปัญหานี้แก้ได้ในระดับความปลอดภัยที่ยอมรับได้หรือไม่?”
ตรรกะของ moonshot: การทดลองเป็นกลยุทธ์
แนวคิดเกมยาวนี้ไม่ได้สมมติว่าทุกโปรเจกต์จะสำเร็จ แต่มันสมมติว่าการทดลองต่อเนื่องคือทางค้นพบสิ่งที่จะสำคัญในอนาคต โรงงาน moonshot อย่าง X เป็นตัวอย่างที่ดี: ทีมลองสมมติฐานกล้าหาญ ติดเครื่องมือวัดผล และตัดไอเดียที่พิสูจน์อ่อนแออย่างรวดเร็ว วินัยนี้สำคัญต่อ AI ที่ความก้าวหน้ามักขึ้นกับการทำซ้ำ—ข้อมูลดีขึ้น การตั้งค่าการฝึกดีขึ้น การประเมินดีขึ้น—ไม่ใช่แค่จุดเปลี่ยนเดียว
ข้อที่ควรรับไว้ (โดยไม่สัญญา)
Alphabet ไม่ใช่การรับประกันชัยชนะในอนาคต แต่เป็นวิธีปกป้องจังหวะการทำงานสองแบบ:
- รักษาแกนธุรกิจให้มุ่งมั่นและรับผิดชอบ
- สร้างที่อยู่อาศัยชัดเจนสำหรับงานวิจัยและเดิมพันที่ความแปรปรวนสูง
สำหรับทีม บทเรียนคือเชิงโครงสร้าง: ถ้าคุณต้องการผลลัพธ์ AI ระยะยาว ให้ออกแบบเพื่อสิ่งนั้น แยกงานส่งมอบระยะสั้นจากงานสำรวจ ลงทุนในการทดลองเป็นยานเรียนรู้ และวัดความคืบหน้าเป็นข้อมูลเชิงยืนยัน ไม่ใช่แค่วาทกรรม
จุดยาก: คุณภาพ ความปลอดภัย และความไว้วางใจในระดับใหญ่
ทำให้อินฟราสตรัคเจอร์ใช้งานได้จริง
ตั้งค่าแอป React, Go และ PostgreSQL ที่รองรับเมตริกจริงและการทำซ้ำ
เมื่อระบบ AI ให้บริการพันล้านคำค้น อัตราความผิดพลาดเล็กน้อยกลายเป็นข่าวประจำวันที่ซ้ำ ๆ โมเดลที่ "ส่วนใหญ่ถูก" ยังอาจทำให้ผู้คนนับล้านเข้าใจผิด—โดยเฉพาะในเรื่องสุขภาพ การเงิน การเลือกตั้ง หรือข่าวสด ในระดับ Google คุณภาพไม่ใช่ความหรูหรา แต่เป็นความรับผิดชอบที่ทบต้น
การแลกเปลี่ยนหลัก
อคติและการเป็นตัวแทน. โมเดลเรียนรู้รูปแบบจากข้อมูล รวมถึงอคติทางสังคมและประวัติศาสตร์ การจัดอันดับที่ดูเป็น "กลาง" ยังคงขยายมุมมองที่โดดเด่นหรือบริการภาษากลุ่มน้อยได้ไม่ดี
ความผิดพลาดและความเชื่อมั่นเกินไป. AI มักล้มเหลวในทางที่ฟังดูน่าเชื่อถือ ความผิดพลาดที่เป็นอันตรายที่สุดไม่ใช่บั๊กชัด ๆ แต่เป็นคำตอบที่ฟังดูสมเหตุสมผลและผู้ใช้เชื่อ
ความปลอดภัยเทียบกับประโยชน์. ตัวกรองเข้มงวดลดอันตรายแต่ก็อาจขัดขวางคำค้นที่ชอบธรรม ตัวกรองอ่อนช่วยเพิ่มการครอบคลุมแต่เสี่ยงให้สแกม การทำร้ายตัวเอง หรือข้อมูลผิด
ความรับผิดชอบ. เมื่อระบบอัตโนมัติมากขึ้น การตอบคำถามพื้นฐานยากขึ้น: ใครอนุมัติพฤติกรรมนี้? ทดสอบอย่างไร? ผู้ใช้จะอุทธรณ์หรือแก้ไขอย่างไร?
ทำไมการสเกลจึงเพิ่มความจำเป็นของการป้องกัน
การสเกลเพิ่มความสามารถ แต่ยัง:
- ขยายจำนวนกรณีขอบ (ภาษา วัฒนธรรม บริบทอ่อนไหว)
- เพิ่มแรงจูงใจให้เกิดการล่วงละเมิด (สแปม การโจมตี prompt injection, SEO เชิงสับไหว)
- ทำให้ความล้มเหลวยากจะย้อนกลับเมื่อรวมเข้าในผลิตภัณฑ์
ดังนั้นรั้วกันต้องสเกลด้วย: ชุดประเมินผล red-teaming การบังคับใช้นโยบาย การติดตามแหล่งที่มา และอินเทอร์เฟซผู้ใช้ที่บ่งชี้ความไม่แน่นอน
เช็คลิสต์ปฏิบัติสำหรับประเมินคำกล่าวอ้าง AI
ใช้เพื่อประเมินฟีเจอร์ “ขับเคลื่อนด้วย AI” ใด ๆ:
- โหมดล้มเหลวคืออะไร? พวกเขาโชว์จุดที่ระบบพังไหม ไม่ใช่แค่เดโม
- วัดอย่างไร? มองหาตัวชี้วัดจริง (ความแม่นยำ อัตราความเป็นพิษ อัตราการสร้างข้อมูลเท็จ) ไม่ใช่คำว่า “ดีขึ้น” อย่างคลุมเครือ
- ฝึกด้วยข้อมูลอะไร? อย่างน้อยบอกหมวดกว้าง ความสด และนโยบายการยกเว้น
- มีรั้วกันอย่างไร? กฎความปลอดภัย เส้นทางตรวจโดยมนุษย์ และการติดตามการล่วงละเมิด
- ผู้ใช้ตรวจสอบได้ไหม? อ้างอิง แหล่งที่มา หรือคำอธิบายที่ให้ตรวจสอบข้อเรียกร้องได้
- แก้ไขอย่างไร? มีวิธีรายงาน อัปเดตเร็ว และตรวจสอบได้หรือไม่
ความไว้วางใจได้มาจากกระบวนการที่ทำซ้ำได้—ไม่ใช่โมเดลจุดเปลี่ยนเดียว
บทเรียนสำหรับทีม: คิดแบบยาวหน่วยเกี่ยวกับ AI
รูปแบบที่ถ่ายโอนได้มากที่สุดเบื้องหลังเส้นทางยาวของ Google ง่าย ๆ: เป้าหมายชัด → ข้อมูล → โครงสร้างพื้นฐาน → การทำซ้ำ คุณไม่จำเป็นต้องมีสเกลของ Google เพื่อใช้วงจรนี้—ต้องมีวินัยเรื่องสิ่งที่คุณกำลังเพิ่มประสิทธิภาพและวิธีเรียนรู้จากการใช้งานจริงโดยไม่หลอกตัวเอง
รูปแบบหลักที่คุณคัดลอกได้
เริ่มจากคำสัญญาที่วัดได้กับผู้ใช้ (ความเร็ว ความผิดพลาดน้อยลง การจับคู่ที่ดีขึ้น) ติดตั้งเครื่องมือวัดเพื่อสังเกตผลลัพธ์ สร้าง “เครื่อง” ขั้นต่ำที่ให้คุณเก็บ ป้ายชื่อ และส่งการปรับปรุงอย่างปลอดภัย แล้วทำซ้ำเป็นก้าวเล็ก ๆ บ่อยครั้ง—มองทุกรีลีสเป็นโอกาสเรียนรู้
ถ้าคอขวดของคุณคือการไปจาก “ไอเดีย” สู่ “ผลิตภัณฑ์ที่ติดตั้งเครื่องมือวัด” ให้เร็วพอ เวิร์กโฟลว์การสร้างสมัยใหม่ช่วยได้ ตัวอย่างเช่น Koder.ai เป็นแพลตฟอร์ม vibe-coding ที่ทีมสามารถสร้างเว็บ แบ็กเอนด์ หรือแอปมือถือจากอินเทอร์เฟซแชท—มีประโยชน์สำหรับปั่น MVP ที่รวมวงจรฟีดแบ็ก (ปุ่มขึ้น/ลง รายงานปัญหา แบบสำรวจสั้น) โดยไม่ต้องรอเป็นสัปดาห์ ฟีเจอร์ต่าง ๆ เช่นโหมดวางแผน รวมสแนปช็อต/ย้อนคืน ก็สอดคล้องกับหลักการ “ทดลองอย่างปลอดภัย วัดผล ทำซ้ำ”
6 ข้อสรุปที่ผู้นำสามารถนำไปใช้ได้ (ไม่ต้องเป็น Google)
- เลือกดาวเหนือที่มองเห็นได้สำหรับผู้ใช้. “ปรับปรุงประสบการณ์การค้นหา” ชัดกว่าคำว่า “นำ AI มาใช้” กำหนดความสำเร็จเป็นสิ่งที่ผู้คนรู้สึกได้
- ออกแบบผลิตภัณฑ์ให้สร้างข้อมูลเพื่อการเรียนรู้. ใส่วงจรฟีดแบ็ก (ปุ่มชอบ/ไม่ชอบ แก้ไข “สิ่งนี้ช่วยไหม?”) ที่จับเจตนา ไม่ใช่แค่คลิก
- ลงทุนตั้งแต่ต้นในท่อส่ง มากกว่ารุ่น. การตรวจสอบคุณภาพข้อมูล แดชบอร์ดประเมินผล และเวิร์กโฟลว์การปรับใช้ ดีกว่าต้นแบบครั้งเดียว
- มองการประเมินเป็นฟีเจอร์ผลิตภัณฑ์. สร้างสกอร์การ์ดที่ทำซ้ำได้ (คุณภาพ ความหน่วง ต้นทุน ความปลอดภัย) เพื่อให้การทำซ้ำไม่ใช่การเดา
- ปล่อยเป็นชิ้นเล็ก ๆ. เริ่มจากกรณีใช้งานแคบ ปล่อยให้กลุ่มเล็ก วัดผล แล้วขยาย ความต่อเนื่องชนะการเปิดตัวใหญ่ครั้งเดียว
- ทำให้เดิมพันระยะยาวอยู่รอดได้. กันปริมาณความจุไว้ส่วนน้อยสำหรับการทดลอง แต่ต้องมีเกณฑ์การเรียนรู้ชัดเจนเพื่อความจริงใจ
บทความที่เกี่ยวข้อง
ถ้าคุณต้องการขั้นตอนถัดไปที่ใช้งานได้ ให้ใส่สิ่งเหล่านี้ในรายการอ่านของทีม:
- blog/ai-strategy-basics
- blog/data-flywheels-for-product-teams
- blog/evaluating-ml-models-without-a-phd
- blog/ai-governance-lightweight