ความหมายของการวิวัฒนาการ API สำหรับแบ็กเอนด์ที่สร้างด้วย AI
การวิวัฒนาการของ API คือกระบวนการที่เปลี่ยน API หลังจากที่มีลูกค้าใช้งานจริงแล้ว ซึ่งอาจหมายถึงการเพิ่มฟิลด์ ปรับกฎการตรวจสอบค่า ปรับปรุงประสิทธิภาพ หรือเพิ่ม endpoints ใหม่ สิ่งนี้มีความสำคัญเมื่อมีลูกค้าใช้งานในสภาพแวดล้อม production เพราะแม้การเปลี่ยนแปลง "เล็กน้อย" ก็สามารถทำให้แอปมือถือ สคริปต์การรวมระบบ หรือกระบวนการของพันธมิตรเกิดข้อผิดพลาดได้
ความเข้ากันได้ย้อนหลัง อธิบายแบบง่าย ๆ
การเปลี่ยนแปลงถือว่า เข้ากันได้ย้อนหลัง ถ้าลูกค้าที่มีอยู่ยังคงทำงานได้ โดยไม่ต้องอัปเดตเลย
ตัวอย่างเช่น สมมติว่า API ของคุณคืนค่า:
{ "id": "123", "status": "processing" }
การเพิ่มฟิลด์ตอบกลับใหม่ที่เป็นทางเลือกมักจะยังคงเข้ากันได้ย้อนหลัง:
{ "id": "123", "status": "processing", "estimatedSeconds": 12 }
ไคลเอนต์เก่าที่ละเลยฟิลด์ที่ไม่รู้จะยังคงทำงานได้ แต่การเปลี่ยนชื่อ status เป็น state การเปลี่ยนชนิดของฟิลด์ (string → number) หรือการเปลี่ยนฟิลด์ที่เป็นทางเลือกให้กลายเป็นบังคับเป็นการเปลี่ยนแปลงที่มักทำให้ระบบพัง
ความหมายของ “แบ็กเอนด์ที่สร้างด้วย AI” ในที่นี้
แบ็กเอนด์ที่สร้างด้วย AI ไม่ใช่แค่โค้ดตัวอย่างเท่านั้น ในทางปฏิบัติจะประกอบด้วย:
- โค้ด API ที่สร้างขึ้น (handlers, controllers, serializers)
- การตั้งค่า (routing, กฎการพิสูจน์ตัวตน, rate limits)
- กาวเชื่อมต่อโครงสร้างพื้นฐาน (migrations, เทมเพลตการปรับใช้, การตั้งค่าสภาพแวดล้อม)
เพราะ AI สามารถสร้างส่วนต่างๆ ของระบบได้อย่างรวดเร็ว API อาจเกิด "drift" ได้เว้นแต่คุณจะจัดการการเปลี่ยนแปลงอย่างตั้งใจ
สิ่งนี้จะเห็นชัดเมื่อสร้างแอปทั้งแอปจาก workflow แบบแชท เช่น Koder.ai (แพลตฟอร์ม vibe-coding) ที่สามารถสร้างเว็บ เซิร์ฟเวอร์ และแอปมือถือจากแชทเพียงเล็กน้อย—มักจะใช้ React บนเว็บ, Go + PostgreSQL ที่แบ็กเอนด์ และ Flutter สำหรับมือถือ ความเร็วนี้ดี แต่ทำให้วินัยด้านสัญญา (และ diff/การทดสอบอัตโนมัติ) สำคัญขึ้นมาก เพื่อไม่ให้การสร้างใหม่โดยไม่ได้ตั้งใจเปลี่ยนสิ่งที่ลูกค้าพึ่งพา
อะไรที่อัตโนมัติได้กับอะไรที่ต้องตรวจสอบโดยมนุษย์
AI สามารถอัตโนมัติหลายอย่างได้: สร้าง OpenAPI specs อัปเดตโค้ด boilerplate แนะนำค่าเริ่มต้นที่ปลอดภัย และร่างขั้นตอนการย้ายข้อมูล แต่การตรวจสอบโดยมนุษย์ยังจำเป็นสำหรับการตัดสินใจที่มีผลต่อสัญญาของลูกค้า—การอนุญาตให้เปลี่ยนแปลงใดบ้าง ฟิลด์ใดมั่นคง และจะจัดการ edge cases และกฎธุรกิจอย่างไร เป้าหมายคือความเร็วที่มาพร้อมกับพฤติกรรมที่คาดเดาได้ ไม่ใช่ความเร็วแลกกับความประหลาดใจ
ทำไมความเข้ากันได้ย้อนหลังจึงเป็นสิ่งสำคัญอันดับต้น ๆ
API มักไม่มีเพียง "ลูกค้า" เดียว แม้ผลิตภัณฑ์ขนาดเล็กอาจมีผู้บริโภคหลายรายที่พึ่งพา endpoints เดียวกันให้ทำงานแบบเดิม:
- เว็บแอปที่ปล่อยอย่างต่อเนื่อง
- แอปมือถือที่อัปเดตผ่านสโตร์ช้ากว่า
- การรวมระบบของพันธมิตร (มักเป็นทีมหรือบริษัทอื่น)
- บริการภายในและระบบอัตโนมัติ (บิลลิ่ง, วิเคราะห์, เครื่องมือสนับสนุน)
เมื่อ API เสียหาย ต้นทุนไม่ได้มีแค่เวลาของนักพัฒนา ผู้ใช้มือถืออาจติดเวอร์ชันเก่านานเป็นสัปดาห์ ดังนั้นการเปลี่ยนแปลงที่ทำให้ระบบพังสามารถกลายเป็นช่วงเวลาที่ยาวนานของข้อผิดพลาดและตั๋วซัพพอร์ต พันธมิตรอาจประสบ downtime ขาดข้อมูล หรือหยุดกระบวนการที่สำคัญ—ซึ่งอาจมีผลทางสัญญาหรือชื่อเสียง บริการภายในอาจล้มเหลวอย่างเงียบ ๆ และสร้างงานค้างมากมาย (เช่น เหตุการณ์หายไปหรือบันทึกไม่สมบูรณ์)
แบ็กเอนด์ที่สร้างด้วย AI เพิ่มความพิเศษ: โค้ดสามารถเปลี่ยนเร็วและบ่อยครั้ง บางครั้งเป็น diff ขนาดใหญ่ เพราะการสร้างถูกปรับให้ผลิตโค้ดที่ทำงานได้ ไม่ใช่เพื่อรักษาพฤติกรรมข้ามเวลา ความเร็วนี้มีค่า แต่ก็เพิ่มความเสี่ยงของการเปลี่ยนแปลงที่ทำให้ระบบพังโดยไม่ตั้งใจ (การเปลี่ยนชื่อฟิลด์ ค่าเริ่มต้นต่างไป การตรวจสอบเข้มงวดขึ้น ข้อกำหนดการพิสูจน์ตัวตนใหม่)
ด้วยเหตุนี้ ความเข้ากันได้ย้อนหลังต้องเป็นการตัดสินใจด้านผลิตภัณฑ์อย่างตั้งใจ ไม่ใช่นิสัยที่พยายามทำให้ดีที่สุด วิธีปฏิบัติที่ได้ผลคือการกำหนดกระบวนการเปลี่ยนแปลงที่คาดเดาได้ โดยถือว่า API เป็นอินเทอร์เฟซผลิตภัณฑ์: คุณสามารถเพิ่มความสามารถได้ แต่ไม่ควรทำให้ลูกค้าที่มีอยู่ประหลาดใจ
โมเดลคิดที่มีประโยชน์คือต้องถือสัญญา API (เช่น OpenAPI spec) เป็น "แหล่งความจริง" ว่าลูกค้าสามารถพึ่งพาอะไรได้ การสร้างเป็นรายละเอียดการใช้งาน: คุณสามารถสร้างแบ็กเอนด์ใหม่ได้ แต่สัญญา—และคำมั่นที่ให้—ต้องคงที่เว้นแต่คุณจะตั้งใจจะเพิ่มเวอร์ชันและสื่อสารการเปลี่ยนแปลง
สัญญา API เป็นแหล่งความจริง
เมื่อระบบ AI สามารถสร้างหรือแก้ไขโค้ดแบ็กเอนด์อย่างรวดเร็ว สมอเชื่อถือเดียวคือ สัญญา API: คำอธิบายที่เขียนไว้ว่าไคลเอนต์เรียกอะไร ต้องส่งอะไร และคาดหวังอะไรตอบกลับ
“สัญญา” หมายถึงอะไรในทางปฏิบัติ
สัญญาคือสเป็กที่อ่านโดยเครื่อง เช่น:
- OpenAPI สำหรับ REST endpoints (paths, parameters, auth, รูปร่างการตอบกลับ)
- JSON Schema สำหรับตรวจสอบ request/response payloads (มักฝังใน OpenAPI)
- GraphQL schema สำหรับชนิดข้อมูล คำสืบค้น มิวเทชัน และการเลิกใช้งาน
สัญญานี้คือสิ่งที่คุณสัญญากับผู้บริโภคภายนอก—แม้ว่าการใช้งานภายในจะเปลี่ยนไป
Contract-first vs. code-first (และที่ที่ตัวสร้างโค้ดเข้าไป)
ใน workflow แบบ contract-first คุณออกแบบหรืออัปเดต OpenAPI/GraphQL schema ก่อน แล้วจึงสร้าง server stubs และเติมตรรกะ นี่ปลอดภัยกว่าสำหรับความเข้ากันได้เพราะการเปลี่ยนแปลงเป็นเรื่องตั้งใจและตรวจสอบได้
ใน workflow แบบ code-first สัญญาถูกผลิตจาก annotation ในโค้ดหรือการสืบค้นเวลารัน แบ็กเอนด์ที่สร้างด้วย AI มักเอนเอียงไปทาง code-first เป็นค่าเริ่มต้น ซึ่งใช้ได้—ตราบใดที่สัญญาที่สร้างขึ้นถูกถือเป็นสิ่งที่ต้องตรวจสอบ ไม่ใช่ของถูกละเลย
แนวทางผสมที่ปฏิบัติได้: ให้ AI เสนอการเปลี่ยนแปลงโค้ด แต่กำหนดให้มันอัปเดต (หรือสร้างใหม่) สัญญาด้วย และใช้ diff ของสัญญาเป็นสัญญาณการเปลี่ยนแปลงหลัก
เก็บสัญญาไว้ภายใต้ระบบควบคุมเวอร์ชัน
เก็บสเป็ก API ในรีโปเดียวกับแบ็กเอนด์และตรวจสอบผ่าน pull request กฎง่าย ๆ: อย่า merge ถ้าไม่ได้เข้าใจการเปลี่ยนแปลงสัญญาและอนุมัติ วิธีนี้ทำให้การแก้ไขที่ไม่เข้ากันมองเห็นได้ตั้งแต่ต้น ก่อนจะถึง production
สร้างทั้งเซิร์ฟเวอร์และไคลเอนต์จากแหล่งเดียวกัน
เพื่อลดการ drift ให้สร้าง server stubs และ client SDKs จากสัญญาเดียวกัน เมื่อสัญญาอัปเดต ทั้งสองฝ่ายจะอัปเดตพร้อมกัน—ทำให้ยากขึ้นที่แบ็กเอนด์ที่สร้างด้วย AI จะ "คิดค้น" พฤติกรรมที่ไคลเอนต์ไม่ได้สร้างมาให้รองรับ
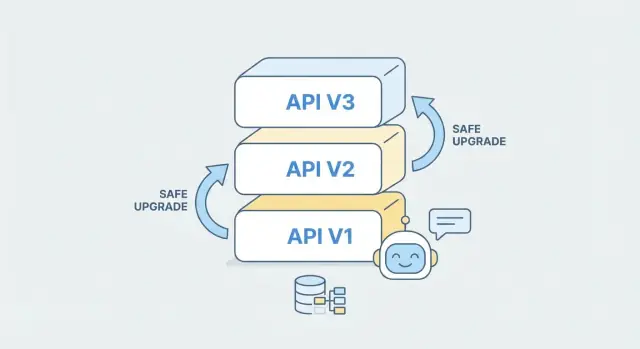
กลยุทธ์การจัดเวอร์ชันที่ใช้งานได้จริง
การเวอร์ชัน API ไม่ใช่การคาดการณ์การเปลี่ยนแปลงทั้งหมดในอนาคต—แต่เป็นการให้ทางเลือกที่ชัดเจนแก่ไคลเอนต์เพื่อให้พวกเขายังคงทำงานได้ในขณะที่คุณปรับปรุงแบ็กเอนด์ ในทางปฏิบัติ กลยุทธ์ที่ "ดีที่สุด" คือวิธีที่ผู้บริโภคของคุณเข้าใจทันทีและทีมของคุณใช้ได้สม่ำเสมอ
กลยุทธ์ทั่วไป (และความรู้สึกสำหรับลูกค้า)
URL versioning ใส่เวอร์ชันใน path เช่น /v1/orders และ /v2/orders มองเห็นได้ในทุกคำขอ แก้ปัญหาได้ง่าย และทำงานดีกับ caching และ routing
Header versioning เก็บ URL ให้สะอาดและย้ายเวอร์ชันไปไว้ใน header (เช่น Accept: application/vnd.myapi.v2+json) อาจดูเรียบร้อย แต่ตรวจสอบได้ยากกว่า
Query parameter versioning ใช้เช่น /orders?version=2 เข้าใจง่าย แต่บางครั้ง client หรือ proxy อาจตัด/เปลี่ยน query string ทำให้สับสนได้
คำแนะนำปริยาย
สำหรับทีมส่วนใหญ่—โดยเฉพาะเมื่อคุณต้องการให้ลูกค้าเข้าใจง่าย—แนะนำให้ใช้ URL versioning นี่เป็นวิธีที่ไม่น่าประหลาดใจที่สุด ง่ายต่อการเอกสาร และทำให้เห็นชัดว่า SDK, แอปมือถือ หรือการรวมของพันธมิตรเรียกเวอร์ชันไหน
วิธีที่แบ็กเอนด์ที่สร้างด้วย AI สามารถช่วยได้
เมื่อใช้ AI สร้างหรือขยายแบ็กเอนด์ ให้ถือแต่ละเวอร์ชันเป็นหน่วย "สัญญา+การใช้งาน" แยกกัน คุณสามารถสเกฟโฟลด์ /v2 จาก OpenAPI spec ที่อัปเดตในขณะที่ยังรักษา /v1 ไว้ นำไปสู่ความเสี่ยงน้อยลง: ลูกค้าที่มีอยู่ยังคงทำงาน ขณะที่ลูกค้าใหม่อาจย้ายมาที่ v2 โดยตั้งใจ
เอกสารและการสื่อสารการเปลี่ยนแปลง
การเวอร์ชันจะได้ผลก็ต่อเมื่อเอกสารตามทัน รักษา เอกสาร API แบบเวอร์ชัน ให้เป็นปัจจุบัน เก็บตัวอย่างให้สอดคล้องตามเวอร์ชัน และเผยแพร่ changelog ที่ระบุชัดว่ามีอะไรเปลี่ยน แนะนำการย้าย และตัวอย่างคำขอ/การตอบแบบเปรียบเทียบ
การเปลี่ยนแปลงที่เข้ากันได้กับที่ทำให้ระบบพัง: เช็คลิสต์ใช้งานได้จริง
เมื่อแบ็กเอนด์ที่สร้างด้วย AI อัปเดต วิธีที่ปลอดภัยที่สุดในการคิดเรื่องความเข้ากันได้คือ: “ไคลเอนต์เดิมยังทำงานได้ไหมโดยไม่ต้องเปลี่ยนแปลง?” ใช้เช็คลิสต์ด้านล่างเพื่อจำแนกการเปลี่ยนแปลงก่อนปล่อย
ที่มักจะเข้ากันได้ (การเพิ่มเติม)
การเปลี่ยนแปลงเหล่านี้มักไม่ทำให้ไคลเอนต์เก่าหยุดทำงานเพราะไม่ทำให้สิ่งที่ไคลเอนต์ส่งหรือคาดหวังถูกยกเลิก:
- ฟิลด์ตอบกลับใหม่ที่เป็นทางเลือก (เช่น
middleName หรือ metadata) ไคลเอนต์ที่ไม่ต้องการฟิลด์ไม่ควรหยุดทำงาน
- Endpoints ใหม่ หรือเมทอดใหม่บน path ต่างกัน
- ฟิลด์คำขอใหม่ที่เป็นทางเลือก ที่เซิร์ฟเวอร์สามารถละเลยหรือใช้ค่าเริ่มต้น
- ขยายค่า enum ในการตอบกลับ (ไคลเอนต์ควรรับมือค่าที่ไม่รู้จักอย่างระมัดระวัง)
ที่มักจะทำให้ระบบพัง (มีความเสี่ยง)
ถือการเปลี่ยนแปลงเหล่านี้เป็น breaking เว้นแต่มีหลักฐานชัดเจน:
- การลบฟิลด์หรือตัด endpoints หรือหยุดรองรับฟิลด์คำขอที่ลูกค้าส่งอยู่
- การเปลี่ยนชื่อฟิลด์ (แม้ความหมายไม่เปลี่ยน) หลายไคลเอนต์แมปตามชื่อ
- การเปลี่ยนชนิดข้อมูล (string → number, object → array,
nullable → non-nullable)
- การเปลี่ยนพฤติกรรม: ค่าเริ่มต้นต่างไป การเปลี่ยนการจัดเรียง semantics ของ pagination หรือกฎการตรวจสอบที่เปลี่ยนไป
- การเข้มงวดข้อจำกัด: ฟิลด์ที่เคยเป็นทางเลือกกลายเป็นบังคับ ย่อความยาวสูงสุด เปลี่ยนรูปแบบที่ยอมรับได้
“ผู้อ่านที่ทนทาน” เป็นเกณฑ์มาตรฐานของคุณ
สนับสนุนให้ไคลเอนต์เป็น ผู้อ่านที่ทนทาน: ละเลยฟิลด์ที่ไม่รู้จัก และจัดการค่าผิดปกติของ enum อย่างยืดหยุ่น วิธีนี้ทำให้แบ็กเอนด์สามารถวิวัฒน์โดยเพิ่มฟิลด์โดยไม่บังคับให้อัปเดตไคลเอนต์
วิธีที่ตัวสร้างโค้ด AI ควรบังคับกฎ
ตัวสร้างโค้ดสามารถป้องกันการเปลี่ยนแปลงที่ทำให้ระบบพังโดยนโยบาย:
- บล็อกการ merge หาก diff ของ OpenAPI รวมการ ลบฟิลด์, การเปลี่ยนชื่อ, หรือการเปลี่ยนชนิด โดยไม่เพิ่มเวอร์ชัน
- กำหนดให้การเปลี่ยนแปลงที่ทำให้ระบบพังต้องถูกนำเสนอเป็น ฟิลด์/endpoint ใหม่ ก่อน พร้อมประกาศเลิกใช้งานของของเก่า
- แจ้งเตือนเมื่อเพิ่ม enum ในการตอบกลับหรือเปลี่ยนค่าเริ่มต้น เพื่อกระตุ้นการตรวจสอบความเข้ากันได้
การย้ายฐานข้อมูลและสคีมาโดยไม่ทำให้ลูกค้าพัง
การเปลี่ยนสคีมาอย่างปลอดภัยมากขึ้น
จำลองการย้ายสคีมาโดยใช้ขั้นตอน expand-migrate-contract และรักษาลูกค้าเก่าให้ทำงานได้ระหว่างการเปิดตัว
การเปลี่ยนแปลง API คือสิ่งที่ลูกค้าเห็น: รูปร่างคำขอ/การตอบ ฟิลด์ ชื่อ และพฤติกรรมข้อผิดพลาด การเปลี่ยนแปลงฐานข้อมูลคือสิ่งที่แบ็กเอนด์เก็บ: ตาราง คอลัมน์ ดัชนี ข้อจำกัด และรูปแบบข้อมูล ทั้งสองเกี่ยวข้องแต่ไม่เหมือนกัน
ข้อผิดพลาดทั่วไปคือถือว่าการย้ายสคีมาเป็นเรื่องภายในเท่านั้น ในแบ็กเอนด์ที่สร้างด้วย AI ชั้น API มักถูกสร้างจากสคีมา (หรือผูกแน่นกับมัน) ดังนั้นการเปลี่ยนสคีมาอาจกลายเป็นการเปลี่ยน API โดยเงียบ ๆ ซึ่งทำให้ไคลเอนต์เก่าพังแม้คุณไม่ได้ตั้งใจแตะ API
รูปแบบการย้ายที่ปลอดภัย (expand → migrate → contract)
ใช้แนวทางหลายขั้นตอนเพื่อให้เส้นทางโค้ดเก่าและใหม่ทำงานได้ระหว่างการอัปเกรดแบบเลื่อน:
- เพิ่ม: เพิ่มคอลัมน์/ตารางใหม่โดยไม่ลบหรือเปลี่ยนชื่อของเดิม
- backfill: เติมข้อมูลในช่องใหม่สำหรับแถวที่มีอยู่ (ทำเป็นแบทช์ถ้าจำเป็น)
- dual-write: ให้แบ็กเอนด์เขียนทั้งที่เก่าและใหม่
- สลับการอ่าน: เริ่มอ่านจากแหล่งใหม่ในขณะที่ยัง dual-write
- ล้างข้อมูลเก่า: เมื่อไคลเอนต์ทั้งหมดอัปเดตและโค้ดเก่าหายไป จึงค่อยลบของเดิม
รูปแบบนี้หลีกเลี่ยงการปล่อยครั้งใหญ่และให้ตัวเลือกการย้อนกลับ
ค่าเริ่มต้น null และฟิลด์ที่ "ขาดหาย"
ไคลเอนต์เก่ามักสมมติว่าฟิลด์เป็นทางเลือกหรือมีความหมายคงที่ เมื่อเพิ่มคอลัมน์ใหม่ที่ไม่เป็น null ให้เลือกระหว่าง:
- ค่าเริ่มต้นฝั่งเซิร์ฟเวอร์ เพื่อรักษาพฤติกรรมเดิม หรือ
- อนุญาต NULL ชั่วคราวและจัดการมันที่ชั้น API
ระวัง: ค่าเริ่มต้นใน DB ไม่จำเป็นช่วยได้ถ้า serializer ของ API ยังคงส่ง null หรือเปลี่ยนกฎการตรวจสอบ
การย้ายโดย AI: ช่วยได้แต่ไม่อัตโนมัติ
เครื่องมือ AI สามารถร่างสคริปต์การย้ายและแนะนำ backfills แต่ยังต้องตรวจสอบโดยมนุษย์: ยืนยันข้อจำกัด ตรวจสอบประสิทธิภาพ (ล็อก อินเด็กซ์) และรันการย้ายกับข้อมูลในสเตจเพื่อให้แน่ใจว่าไคลเอนต์เก่ายังคงทำงานได้
Feature flags และการเปิดตัวแบบค่อยเป็นค่อยไปเพื่อการอัปเดตที่ปลอดภัยขึ้น
Feature flag ให้คุณเปลี่ยนพฤติกรรมโดยไม่ต้องเปลี่ยนรูปร่าง endpoint นั่นมีประโยชน์โดยเฉพาะกับแบ็กเอนด์ที่สร้างด้วย AI ที่ตรรกะภายในอาจถูกสร้างใหม่หรือปรับปรุงบ่อยครั้ง แต่ลูกค้ายังคงพึ่งพาความสม่ำเสมอของคำขอและการตอบ
แทนการปล่อยเป็น "สวิตช์ใหญ่" ให้ส่งเส้นทางโค้ดใหม่ในสถานะปิด แล้วเปิดอย่างค่อยเป็นค่อยไป หากเกิดปัญหาคุณสามารถปิดทันทีโดยไม่ต้องรีดีพลอยฉุกเฉิน
การเปิดตัวแบบค่อยเป็นค่อยไปทำงานอย่างไร
แผนการเปิดตัวที่ใช้ได้จริงมักรวมสามเทคนิค:
- Canary release: เปิดพฤติกรรมใหม่ให้กับสัดส่วนเล็ก ๆ ของทราฟฟิกหรือผู้เช่า
- การเปิดแบบตามเปอร์เซ็นต์: เพิ่มสัดส่วนจาก 1% → 10% → 50% → 100% คอยดูอัตราข้อผิดพลาดและผลกระทบต่อไคลเอนต์
- แผนย้อนกลับเร็ว: กำหนดเมตริกที่จะเป็นสัญญาณย้อนกลับ (เช่น อัตรา 5xx, ความล้มเหลวในการตรวจสอบค่า, ตั๋วซัพพอร์ต) และทำให้การย้อนกลับเป็นไปได้ภายในไม่กี่นาที
สำหรับ API กุญแจคือ รักษาการตอบกลับให้คงที่ในขณะที่ทดลองภายใน คุณสามารถสลับการใช้งาน (model ใหม่, routing logic ใหม่, แผนการ query ใหม่) ในขณะที่ยังคงคืนรหัสสถานะ ชื่อฟิลด์ และรูปแบบข้อผิดพลาดที่สัญญารับประกันไว้ ถ้าต้องเพิ่มข้อมูลใหม่ ให้เลือกฟิลด์เพิ่มเติมที่ไคลเอนต์จะละเลยได้
ตัวอย่างง่าย: เปิดใช้การตรวจสอบค่าที่เข้มงวดขึ้นแบบค่อยเป็นค่อยไป
สมมติ POST /orders ตอนนี้ยอมรับ phone ได้หลายรูปแบบ คุณต้องการบังคับให้เป็นรูปแบบ E.164 แต่การเข้มงวดนี้อาจทำให้ลูกค้าเก่าพัง
แนวทางที่ปลอดภัย:
- ส่ง validator ที่เข้มงวดไว้หลัง flag (เช่น
strict_phone_validation)
- เริ่มในโหมด "รายงานเท่านั้น": รับคำขอแต่ล็อกสิ่งที่จะล้มเหลว การตอบยังคงไม่เปลี่ยน
- Canary เปิดการบังคับใช้ ให้กับผู้ใช้ภายในหรือ 1% ของทราฟฟิก
- เพิ่มสัดส่วน ขึ้นขณะมอนิเตอร์: การเพิ่มขึ้นของข้อผิดพลาดการตรวจสอบ ค่า retry ของไคลเอนต์ และการลดลงของการใช้งาน
- ย้อนกลับทันที หากความล้มเหลวเกินเกณฑ์
แพทเทิร์นนี้ให้คุณปรับปรุงคุณภาพข้อมูลโดยไม่เปลี่ยน API ที่เข้ากันได้ย้อนหลังให้กลายเป็นการเปลี่ยนแปลงที่ทำให้ระบบพังโดยไม่ได้ตั้งใจ
การเลิกใช้งานและการปิดเวอร์ชัน: วิธีเกษียณเวอร์ชันเก่า
เปลี่ยนสเป็กเป็น endpoints
สร้าง endpoints, models และการตรวจสอบค่า แล้วปรับเปลี่ยนการเปลี่ยนแปลงโดยไม่เสียการควบคุมสัญญา
การเลิกใช้งานคือการ "ออกจากอย่างสุภาพ" ของพฤติกรรม API เก่า: คุณหยุดแนะนำ ให้เตือนลูกค้าแต่เนิ่น ๆ และให้เส้นทางที่คาดเดาได้ในการย้าย ส่วนการปิด (sunsetting) คือขั้นตอนสุดท้าย: เวอร์ชันเก่าถูกปิดในวันที่ประกาศ สำหรับแบ็กเอนด์ที่สร้างด้วย AI—ที่ endpoints และสคีมาอาจวิวัฒน์เร็ว—กระบวนการเกษียณที่เข้มงวดช่วยให้การอัปเดตปลอดภัยและรักษาไว้ซึ่งความไว้วางใจ
นิยามว่า "major" หมายถึงอะไร (Semantic Versioning)
ใช้ semantic versioning ที่ระดับสัญญา API ไม่ใช่แค่ในรีโป
- MAJOR: การเปลี่ยนแปลงที่ทำให้ระบบพัง (ลบฟิลด์/endpoints, เปลี่ยนความหมายของฟิลด์, เข้มงวดการตรวจสอบ, เปลี่ยนข้อกำหนดการพิสูจน์ตัวตน, เปลี่ยนพฤติกรรมเริ่มต้นที่ลูกค้าพึ่งพา)
- MINOR: การเพิ่มที่เข้ากันได้ย้อนหลัง (ฟิลด์ทางเลือกใหม่, endpoints ใหม่, ค่า enum เพิ่มเมื่อไคลเอนต์ละเลยค่าที่ไม่รู้จัก, พารามิเตอร์กรองใหม่)
- PATCH: แก้บั๊กและปรับปรุงที่ไม่เปลี่ยนสัญญาหรือพฤติกรรมที่สังเกตได้
ใส่นิยามนี้ในเอกสารของคุณแล้วใช้มันอย่างสม่ำเสมอ ป้องกัน "major เงียบ" ที่การช่วยด้วย AI อาจดูเล็กแต่ทำให้ลูกค้าจริงๆ พัง
ตารางเวลาเลิกใช้งานที่ปฏิบัติได้
เลือกนโยบายปริยายและยึดตามมันเพื่อให้ผู้ใช้วางแผนได้ ตัวอย่างทั่วไป:
- ประกาศเลิกใช้งาน: ประกาศทันทีเมื่อปล่อยเวอร์ชันใหม่
- หน้าต่างเลิกใช้งาน: รักษาเวอร์ชันเก่าให้ทำงาน 90–180 วัน (นานขึ้นสำหรับลูกค้าองค์กร)
- วันที่ปิดบริการ: ประกาศวันที่ตัดสินใจตั้งแต่วันแรก
ถ้าไม่แน่ใจ ให้เลือกหน้าต่างที่ยาวขึ้นเล็กน้อย; ต้นทุนการเก็บเวอร์ชันไว้นิดหน่อยมักต่ำกว่าต้นทุนการย้ายฉุกเฉินของลูกค้า
สัญญาณการเลิกใช้งาน (ทำให้ยากที่จะพลาด)
พึ่งหลายช่องทาง เพราะไม่ใช่ทุกคนจะอ่าน release notes
- Headers ของการตอบกลับ: เช่น
Deprecation: true และ Sunset: Wed, 31 Jul 2026 00:00:00 GMT พร้อม Link ไปยังเอกสารการย้าย
- บันทึกในเอกสาร: แบนเนอร์ชัดเจนในเอกสารเวอร์ชันเก่าที่ระบุวันที่ปิดและเช็คลิสต์การย้าย (ข้อความไปยัง /docs/api/v2/migration)
- คำเตือนใน SDKs: คำเตือนใน SDK อย่างเบา (บันทึก runtime + annotation การเลิกใช้งานระดับคอมไพล์ถ้าเป็นไปได้)
รวมประกาศเลิกใช้งานใน changelogs และอัปเดตสถานะเพื่อให้ทีมจัดซื้อและปฏิบัติการเห็น
การลบ: ปิดบริการด้วยวันที่แน่นอน (และสถานะสิ้นสุดที่ปลอดภัย)
รักษาเวอร์ชันเก่าจนถึงวันที่ปิด จากนั้นปิดอย่างจงใจ—ไม่ใช่แบบค่อยๆ ทำให้พังโดยบังเอิญ
เมื่อปิด:
- คืนข้อผิดพลาดชัดเจนสำหรับเวอร์ชันที่เลิกใช้ (เช่น
410 Gone) พร้อมข้อความชี้ไปยังเวอร์ชันใหม่และหน้าแนะนำการย้าย
- เก็บหน้าคำอธิบายที่อ่านง่ายไว้สักระยะ (เช่น /docs/deprecations/v1)
สำคัญที่สุด ให้ถือการปิดบริการเป็นการเปลี่ยนแปลงที่มีกองเจ้าของ มอนิเตอร์ และแผนย้อนกลับ วินัยนี้ทำให้การวิวัฒน์บ่อยครั้งเป็นไปได้โดยไม่ทำให้ลูกค้าประหลาดใจ
การทดสอบเพื่อป้องกันการเปลี่ยนแปลงที่ทำให้ระบบพังโดยไม่ตั้งใจ
โค้ดที่สร้างด้วย AI อาจเปลี่ยนเร็ว—และบางครั้งในจุดที่ไม่คาดคิด วิธีที่ปลอดภัยที่สุดในการรักษาการทำงานของลูกค้าคือทดสอบ สัญญา (สิ่งที่คุณสัญญาภายนอก) ไม่ใช่แค่การใช้งานภายใน
การทดสอบสัญญา: เปรียบเทียบสเป็กกับสเป็ก
แนวทางพื้นฐานคือการทดสอบสัญญาที่เปรียบเทียบ OpenAPI spec ก่อนหน้ากับสเป็กที่สร้างใหม่ ถือเป็นการตรวจสอบ "ก่อน vs หลัง":
- ตรวจจับ endpoint ที่ถูกลบ การเปลี่ยนชื่อฟิลด์ กฎการตรวจสอบที่เข้มงวดขึ้น หรือต้องการการพิสูจน์ตัวตนที่เปลี่ยน
- แจ้งเตือนการเปลี่ยนแปลงรหัสการตอบกลับ (เช่น 200 → 204 หรือพฤติกรรม 404 ที่เปลี่ยน)
- จับการเปลี่ยนแปลงเล็กน้อย เช่น ฟิลด์ที่เป็นทางเลือกกลายเป็นบังคับ
หลายทีมทำ OpenAPI diff ใน CI อัตโนมัติเพื่อไม่ให้การเปลี่ยนแปลงที่สร้างขึ้นถูกปรับใช้โดยไม่ตรวจสอบ นี่มีประโยชน์อย่างยิ่งเมื่อ prompts, เทมเพลต หรือเวอร์ชันโมเดลเปลี่ยน
การทดสอบสัญญาที่ไคลเอนต์เป็นผู้นำ (อธิบายง่าย ๆ)
การทดสอบแบบ consumer-driven contract เปลี่ยนมุมมอง: แทนที่ทีมแบ็กเอนด์จะเดาว่าลูกค้าใช้ API อย่างไร แต่แต่ละไคลเอนต์แชร์ชุดความคาดหวังเล็ก ๆ (คำขอที่ส่งและการตอบที่พึ่งพา) แบ็กเอนด์ต้องพิสูจน์ว่ายังคงตอบสนองความคาดหวังเหล่านั้นก่อนปล่อย
วิธีนี้ดีเมื่อคุณมีผู้บริโภคหลายคน (เว็บ แอป มือถือ พันธมิตร) และต้องการอัปเดตโดยไม่ต้องประสานการปรับใช้ทุกตัว
การทดสอบ regression สำหรับรูปร่างการตอบและข้อผิดพลาด
เพิ่มการทดสอบ regression ที่ล็อกลง:
- รูปร่าง JSON ของการตอบ (ชื่อฟิลด์ ชนิด การซ้อน)
- ค่าเริ่มต้นและความสามารถเป็น null (ขาดหาย vs null)
- semantics ของ pagination และการจัดเรียง
- รูปแบบข้อผิดพลาด: รหัสข้อผิดพลาด โครงสร้างข้อความ และฟิลด์ข้อผิดพลาดการตรวจสอบ
ถ้าคุณเผยแพร่สคีมาข้อผิดพลาด ให้ทดสอบมันโดยตรง—ไคลเอนต์มักจะแยกวิเคราะห์ข้อผิดพลาดมากกว่าที่เราคาด
ประตู CI ก่อนการเปิดตัว
รวม OpenAPI diff, consumer contracts และการทดสอบรูปร่าง/ข้อผิดพลาดเป็นประตู CI หากการเปลี่ยนแปลงที่สร้างขึ้นล้มเหลว การแก้ไขมักคือการปรับ prompt, กฎการสร้าง หรือชั้นความเข้ากันได้—ก่อนที่ ผู้ใช้จะสังเกตเห็น
การจัดการข้อผิดพลาดและความเสถียรของพฤติกรรมข้ามเวอร์ชัน
เมื่อไคลเอนต์รวมกับ API ของคุณ พวกเขามักไม่ "อ่าน" ข้อความข้อผิดพลาดโดยตรง—แต่โต้ตอบกับรูปแบบและรหัสข้อผิดพลาด การพิมพ์ผิดในข้อความที่อ่านได้มนุษย์อาจน่ารำคาญ แต่รหัสสถานะที่เปลี่ยน ฟิลด์ที่หายไป หรือตัวระบุข้อผิดพลาดที่เปลี่ยนชื่อสามารถทำให้ checkout ล้มเหลว การซิงก์ล้มเหลว หรือเกิดลูป retry แบบไม่สิ้นสุด
ข้อผิดพลาดที่สม่ำเสมอ: ให้ความสำคัญกับการอ่านด้วยเครื่อง
ตั้งเป้าคงรูปแบบข้อผิดพลาด (error envelope) และชุดตัวระบุที่ไคลเอนต์พึ่งพา เช่น ถ้าคุณส่ง { code, message, details, request_id } อย่าลบหรือเปลี่ยนชื่อฟิลด์เหล่านี้ในเวอร์ชันใหม่ คุณสามารถปรับปรุงถ้อยคำใน message ได้ แต่รักษาความหมายของ code ให้นิ่งและมีเอกสาร
ถ้าคุณมีรูปแบบหลายแบบในสภาพแวดล้อม ให้ต้านทานการ "ทำความสะอาด" ในที่เดียว แนะนำให้เพิ่มรูปแบบใหม่หลังเส้นแบ่งเวอร์ชันหรือกลไกต่อรอง (เช่น header Accept) ในขณะที่ยังรองรับแบบเก่า
การเพิ่มรหัสข้อผิดพลาดใหม่โดยไม่ทำลายไคลเอนต์เก่า
รหัสข้อผิดพลาดใหม่บางครั้งจำเป็น แต่ควรเพิ่มโดยไม่ทำให้การรวมระบบเก่าประหลาดใจ
แนวทางปลอดภัย:
- รักษารหัสเดิมให้ใช้ได้: ถ้าไคลเอนต์จัดการ
VALIDATION_ERROR อยู่แล้ว อย่าแทนที่ด้วย INVALID_FIELD ทันที
- แนะนำรหัสใหม่เป็นกรณีที่เฉพาะเจาะจงขึ้น: คืน
code ใหม่ แต่รวมคำใบ้ที่เข้ากันได้ย้อนหลังกว่าใน details (หรือแม็ปกับรหัสทั่วไปเดิมสำหรับเวอร์ชันเก่า)
- อธิบายกฎ fallback: บอกให้ไคลเอนต์ปฏิบัติต่อรหัสที่ไม่รู้จักเป็นคลาสทั่วไปตาม HTTP status (400/401/403/404/409/429/500) และยังแสดง
message
สำคัญอย่างยิ่ง: อย่าเปลี่ยน ความหมาย ของรหัสที่มีอยู่ หาก NOT_FOUND เคยหมายถึง "ทรัพยากรไม่มีอยู่" อย่าใช้มันแทน "ปฏิเสธการเข้าถึง" (ซึ่งควรจะเป็น 403)
ความเสถียรของพฤติกรรม: ค่าเริ่มต้นต้องไม่เปลี่ยนเงียบๆ
ความเข้ากันได้ย้อนหลังยังหมายถึง "คำขอเดียวกัน ผลลัพธ์เดียวกัน" การเปลี่ยนค่าเริ่มต้นเล็ก ๆ อาจทำให้ไคลเอนต์ที่ไม่ตั้งค่าพารามิเตอร์เกิดปัญหา
Pagination: อย่าเปลี่ยน limit, page_size, หรือพฤติกรรม cursor โดยไม่เวอร์ชัน หากเปลี่ยนจาก page-based เป็น cursor-based ถือเป็น breaking เว้นแต่จะรักษาเส้นทางเดิมไว้
การจัดเรียง: ค่าเริ่มต้นของการจัดเรียงควรคงที่ การเปลี่ยนจาก created_at desc เป็น relevance desc อาจเปลี่ยนลำดับและทำให้ UI หรือการซิงก์แบบ incremental ผิดพลาด
การกรอง: หลีกเลี่ยงการเปลี่ยนตัวกรองที่แฝงอยู่ (เช่น จู่ ๆ ก็ไม่รวมรายการ "inactive" โดยค่าเริ่มต้น) หากต้องการพฤติกรรมใหม่ ให้เพิ่ม flag ชัดเจน เช่น include_inactive=true หรือ status=all
กับดักทั่วไป: เขตเวลา รูปแบบตัวเลข และบูลีน
ปัญหาบางอย่างไม่เกี่ยวกับ endpoints แต่เกี่ยวกับการตีความ
- เขตเวลา: ระบุเสมอว่า timestamps เป็น UTC หรือมี offset และรักษาความสอดคล้อง การเปลี่ยนจากเวลาโลคอลเป็น UTC โดยไม่เตือนอาจทำให้เกิดเหตุการณ์ซ้ำหรือหาย
- รูปแบบตัวเลข: ตัวเลขใน JSON ชัดเจน แต่สตริงที่ "เหมือนตัวเลข" (ค่าเงิน ทศนิยม) อาจต่างกัน อย่าเปลี่ยน
"9.99" เป็น 9.99 (หรือกลับกัน) แบบกะทันหัน
- ค่าเริ่มต้นบูลีน: ค่าเริ่มต้นเช่น
include_deleted=false หรือ send_email=true อย่าให้พลิก ถ้าต้องเปลี่ยนค่าเริ่มต้น ให้ให้ไคลเอนต์เลือกผ่านพารามิเตอร์ใหม่
สำหรับแบ็กเอนด์ที่สร้างด้วย AI โดยเฉพาะ ให้ล็อกพฤติกรรมเหล่านี้ด้วยสัญญาและการทดสอบอย่างชัดเจน: โมเดลอาจ "ปรับปรุง" การตอบกลับเว้นแต่คุณจะบังคับความเสถียรเป็นข้อบังคับ
การสังเกตการณ์: มอนิเตอร์ความเข้ากันได้ในโลกจริง
ทำการเปลี่ยนแปลงอย่างตั้งใจ
ใช้โหมดวางแผนเพื่อกำหนดเวอร์ชัน ฟิลด์ และการเลิกใช้งานก่อนจะสร้างโค้ด
ความเข้ากันได้ย้อนหลังไม่ใช่สิ่งที่ตรวจสอบครั้งเดียวแล้วลืม ด้วยแบ็กเอนด์ที่สร้างด้วย AI พฤติกรรมอาจเปลี่ยนเร็วกว่าระบบมือทำ ดังนั้นคุณต้องมีวงจรป้อนกลับที่แสดงว่า ใครใช้เวอร์ชันไหน และการอัปเดตกำลังทำร้ายลูกค้าหรือไม่
ติดตามเมตริกตามเวอร์ชัน API (และตาม endpoint)
เริ่มจากติดแท็กทุกคำขอด้วย เวอร์ชัน API (เช่น path /v1/..., header X-Api-Version, หรือ schema version ที่ต่อรองได้) แล้วเก็บเมตริกแยกตามเวอร์ชัน:
- การใช้งาน: คำขอต่อวินาทีตามเวอร์ชันและ route
- ความหน่วง: p50/p95 ตามเวอร์ชัน (การเปลี่ยนที่เข้ากันได้อาจช้าจนรับไม่ได้)
- อัตราข้อผิดพลาด: 4xx vs 5xx ตามเวอร์ชัน (การพุ่งขึ้นมักบอกการพังที่ซ่อนอยู่)
จะทำให้คุณสังเกตเห็นเช่น /v1/orders เหลือ 5% ของทราฟฟิกแต่มี 70% ของข้อผิดพลาดหลัง rollout
ตรวจจับไคลเอนต์ที่ยังใช้ฟิลด์หรือ endpoints เก่า
ติดตั้ง instrumentation ใน gateway หรือแอปพลิเคชันเพื่อล็อกสิ่งที่ไคลเอนต์ส่งและ route ที่เรียก:
- คำขอ hitting endpoints ที่ถูกเลิกใช้ (เช่น
/v1/legacy-search)
- payload ที่มีฟิลด์ที่ถูกเลิกใช้
- คำขอที่ขาดฟิลด์ใหม่ที่ไคลเอนต์บางตัวอาจถือว่ามี
ถ้าคุณควบคุม SDKs ให้เพิ่ม header ระบุไอดีไคลเอนต์ + เวอร์ชัน SDK เบา ๆ เพื่อดูการรวมระบบที่ล้าสมัย
ใช้ logs และ tracing เพื่อตรวจหาการเปลี่ยนแปลง
เมื่อข้อผิดพลาดพุ่งขึ้น คุณต้องตอบว่า: "การปรับใช้ตัวใดเปลี่ยนพฤติกรรม?" เชื่อมโยงการพุ่งขึ้นกับ:
- รายละเอียดการปล่อย (commit hash/build id)
- logs แบบมีโครงสร้างที่รวมเวอร์ชัน route และความล้มเหลวในการตรวจสอบ
- distributed traces ที่แสดงจุดที่ความหน่วงหรือข้อยกเว้นเกิดขึ้น (gateway → handler → DB)
ย้อนกลับให้เหมาะกับการปรับใช้ที่สร้างโดยอัตโนมัติ
รักษาการย้อนกลับให้เรียบง่าย: ต้องสามารถปรับใช้ artifact ที่สร้างก่อนหน้า (container/image) และสลับทราฟฟิกกลับผ่าน router หลีกเลี่ยงการย้อนกลับที่ต้องกลับข้อมูล; ถ้ามีการเปลี่ยนสคีมา ให้ใช้การย้ายแบบ additive เพื่อให้เวอร์ชันเก่ายังคงทำงานในขณะที่ย้อนกลับ API layer
ถ้าแพลตฟอร์มของคุณรองรับ snapshots ของสภาพแวดล้อมและย้อนกลับได้เร็ว ให้ใช้พวกมัน ตัวอย่างเช่น Koder.ai รวม snapshots และ rollback ใน workflow ซึ่งเข้าคู่กับการย้ายข้อมูลแบบ "expand → migrate → contract" และการเปิดตัว API แบบค่อยเป็นค่อยไป
Workflow ที่ทำซ้ำได้สำหรับการวิวัฒนาการของ API ที่สร้างด้วย AI
แบ็กเอนด์ที่สร้างด้วย AI อาจเปลี่ยนเร็ว—endpoints ใหม่ปรากฏ โมเดลเปลี่ยน และการตรวจสอบเข้มงวดขึ้น วิธีที่ปลอดภัยที่สุดในการรักษาเสถียรภาพลูกค้าคือปฏิบัติการเปลี่ยนแปลง API เหมือนกระบวนการปล่อยขนาดเล็กที่ทำซ้ำได้ ไม่ใช่ "แก้ครั้งเดียว"
Workflow (เสนอ → เลิกใช้งาน)
- เสนอการเปลี่ยนแปลง
เขียนเหตุผล พฤติกรรมที่ตั้งใจ และผลกระทบต่อสัญญาอย่างชัดเจน (ฟิลด์ ชนิด บังคับ/ทางเลือก รหัสข้อผิดพลาด)
- จัดประเภท
ทำเครื่องหมายเป็น เข้ากันได้ (ปลอดภัย) หรือ breaking (ต้องการการเปลี่ยนของไคลเอนต์) ถ้าไม่แน่ใจ ให้ถือเป็น breaking และออกแบบเส้นทางความเข้ากันได้
- ออกแบบแผนความเข้ากันได้
ตัดสินใจว่าจะสนับสนุนไคลเอนต์เก่าอย่างไร: alias, dual-write/dual-read, ค่าเริ่มต้น, tolerant parsing, หรือเวอร์ชันใหม่
- นำไปใช้ภายใต้การป้องกัน
เพิ่มการเปลี่ยนแปลงด้วย feature flags หรือการตั้งค่าเพื่อเปิดแบบค่อยเป็นค่อยไปและย้อนกลับได้เร็ว
- ทดสอบสัญญา
รันการตรวจสอบสัญญาอัตโนมัติ (เช่นกฎ OpenAPI diff) พร้อมการทดสอบ goldens ของ "ไคลเอนต์ที่รู้จัก" เพื่อจับ drift ของพฤติกรรม
- ปล่อยพร้อมเอกสาร
ทุกการปล่อยควรรวม: เอกสารอ้างอิงใน /docs, หมายเหตุการย้ายสั้นเมื่อเกี่ยวข้อง และรายการใน changelog ระบุว่ามีอะไรเปลี่ยนและเข้ากันได้หรือไม่
- เลิกใช้งานและลบตามตาราง
ประกาศการเลิกใช้งานพร้อมวันที่ เพิ่ม header/warnings ของการตอบกลับ วัดการใช้งานที่เหลือ แล้วลบหลังจากหน้าต่าง sunset
ตัวอย่างย่อ: เปลี่ยนชื่อฟิลด์โดยไม่ทำให้ลูกค้าพัง
ถ้าต้องการเปลี่ยนชื่อ last_name เป็น family_name:
- การจัดการคำขอ: ยอมรับทั้งสองฟิลด์; ถ้าทั้งสองมี ให้เลือก
family_name
- การตอบ: คืนทั้งสองฟิลด์ในช่วงการเปลี่ยน (หรือคืน
family_name และเก็บ last_name เป็น alias)
- การเก็บข้อมูล: แม็ปทั้งสองไปยังคอลัมน์ภายในเดียวกัน
- เอกสาร + changelog: ระบุชื่อใหม่ ติดป้าย
last_name ว่าเลิกใช้งาน และกำหนดวันที่จะลบ
ถ้าบริการของคุณมีการสนับสนุนตามแผนหรือการสนับสนุนเวอร์ชันระยะยาว ให้ระบุสิ่งนั้นอย่างชัดเจนบน /pricing