13 พ.ย. 2568·2 นาที
วิวัฒนาการของ NoSQL: เหตุใดจึงเกิดขึ้นเพื่อตอบปัญหาการสเกลและความยืดหยุ่น
เรียนรู้ว่าเหตุใด NoSQL จึงเกิดขึ้น: สภาพแวดล้อมเว็บสเกล ความต้องการข้อมูลยืดหยุ่น และข้อจำกัดของระบบเชิงสัมพันธ์—พร้อมโมเดลหลักและการแลกเปลี่ยน
ปัญหาอะไรที่ NoSQL พยายามจะแก้ไข?
NoSQL ปรากฏขึ้นเมื่อทีมจำนวนมากพบว่าความต้องการของแอปพลิเคชันไม่สอดคล้องกับสิ่งที่ฐานข้อมูลเชิงสัมพันธ์ (ฐานข้อมูล SQL) ถูกออกแบบมาให้ทำได้ดี SQL ไม่ได้ "ล้มเหลว" แต่ที่ระดับเว็บขนาดใหญ่ ทีมบางส่วนเริ่มให้ความสำคัญกับเป้าหมายที่ต่างออกไป
แรงกดดันสองอย่าง: การสเกลและการเปลี่ยนแปลง
ก่อนอื่น การสเกล แอปที่ได้รับความนิยมเริ่มมีการระเบิดของทราฟฟิก เขียนข้อมูลบ่อย และปริมาณข้อมูลจากผู้ใช้มหาศาล สำหรับเวิร์กโหลดเหล่านี้ การ "ซื้อเซิร์ฟเวอร์ที่ใหญ่กว่า" กลายเป็นเรื่องแพง ช้าในการดำเนินการ และถูกจำกัดโดยขนาดเครื่องที่คุณสามารถใช้งานได้จริง
ประการที่สอง การเปลี่ยนแปลง ฟีเจอร์ผลิตภัณฑ์พัฒนาอย่างรวดเร็ว และข้อมูลเบื้องหลังไม่จำเป็นต้องพอดีกับชุดตารางที่ตายตัว การเพิ่มแอตทริบิวต์ใหม่ในโปรไฟล์ผู้ใช้ เก็บประเภทอีเวนต์หลายแบบ หรือรับ JSON กึ่งโครงสร้างจากหลายแหล่งมักหมายถึงการย้ายสกีมาบ่อยครั้งและการประสานระหว่างทีม
ทำไมฐานข้อมูลเชิงสัมพันธ์ถึงลำบากในบางกรณี
ฐานข้อมูลเชิงสัมพันธ์ดีมากในการบังคับรูปแบบและอนุญาตการค้นหาซับซ้อนข้ามตารางที่ทำ normalization แต่เวิร์กโหลดระดับสูงบางอย่างทำให้คุณสมบัติเหล่านั้นยากที่จะใช้ประโยชน์:
- การเขียนพร้อมกันจำนวนมากข้ามหลายตารางอาจสร้างการแย่งกัน (contention)
- คำค้นหาที่อาศัยการ join หนักอาจมีค่าใช้จ่ายสูงเมื่อข้อมูลเติบโตอย่างรวดเร็ว
- การสเกลออกข้ามหลายเครื่องเป็นไปได้ แต่การบริหารรักษาความสอดคล้องอย่างเข้มงวดในทุกที่อาจซับซ้อน
ผลลัพธ์: ทีมบางกลุ่มมองหาระบบที่ยอมแลกบางการรับประกันและความสามารถเพื่อแลกกับการสเกลที่ง่ายขึ้นและการทำซ้ำที่เร็วขึ้น
NoSQL: กลุ่มแนวทาง ไม่ใช่ของสิ่งเดียว
NoSQL ไม่ใช่ฐานข้อมูลหรือการออกแบบเดียว มันคือคำรวมสำหรับระบบที่เน้นการผสมของ:
- การสเกลแนวนอน (เพิ่มเครื่อง)
- รูปแบบข้อมูลที่ยืดหยุ่น
- รูปแบบการเข้าถึงที่ปรับแต่งสำหรับความต้องการแอปพลิเคชันเฉพาะ
การปรับความคาดหวังใหม่
NoSQL ไม่เคยถูกออกแบบมาเป็นตัวแทนสากลของ SQL มันคือชุดการแลกเปลี่ยน: คุณอาจได้การสเกลหรือความยืดหยุ่นของสกีมา แต่คุณอาจต้องยอมรับการรับประกันความสอดคล้องที่อ่อนกว่า ตัวเลือกการค้นหาแบบ ad-hoc น้อยลง หรือความรับผิดชอบมากขึ้นในการออกแบบข้อมูลระดับแอป
ทำไมการสเกลแบบดั้งเดิมเริ่มทำงานได้ยากขึ้น
เป็นเวลาหลายปี คำตอบมาตรฐานต่อฐานข้อมูลช้า คือ: ซื้อเครื่องที่ใหญ่ขึ้น เพิ่ม CPU เพิ่ม RAM ใช้ดิสก์เร็วขึ้น และรักษาสกีมาและโมเดลการปฏิบัติการเดิม การสเกลแบบ "ขึ้น" นี้ใช้ได้—จนกระทั่งมันไม่เป็นไปได้อีกต่อไป
การสเกลแนวตั้งเจอขีดจำกัดที่ชัด
เครื่องระดับสูงมีราคาสูงอย่างรวดเร็ว และความคุ้มค่าของราคา/ประสิทธิภาพจะเริ่มไม่เป็นมิตร การอัปเกรดมักต้องผ่านการอนุมัติงบประมาณครั้งใหญ่และหน้าต่างการบำรุงรักษาที่ไม่บ่อยนัก แม้คุณจะสามารถจ่ายค่าเครื่องที่ใหญ่ขึ้นได้ แต่เซิร์ฟเวอร์เดียวก็ยังมีเพดาน: บัสหน่วยความจำหนึ่งชุด ระบบเก็บข้อมูลหนึ่งชุด และโหนดหลักที่รับภาระการเขียนทั้งหมด
การเติบโตเปลี่ยนรูปร่างของเวิร์กโหลด
เมื่อผลิตภัณฑ์เติบโต ฐานข้อมูลเผชิญแรงอ่าน/เขียนอย่างต่อเนื่องแทนพีคเป็นครั้งคราว ทราฟฟิกกลายเป็น 24/7 อย่างแท้จริง และฟีเจอร์บางอย่างสร้างรูปแบบการเข้าถึงที่ไม่สม่ำเสมอ จำนวนแถวหรือพาร์ติชันที่ถูกเข้าถึงหนักเพียงเล็กน้อยสามารถครอบงำทราฟฟิก สร้างตารางร้อน (hot tables) หรือคีย์ร้อน (hot keys) ที่ดึงทุกอย่างให้ช้าลง
คอขวดเชิงปฏิบัติการกลายเป็นเรื่องปกติ:
- ดัชนีบานเมื่อฟีเจอร์ใหม่ต้องการดัชนีรองมากขึ้น
- การแย่งกันจากการเขียนพร้อมกันจำนวนมากที่เข้าตารางเดียวกัน
- การรอการล็อกที่ทำให้ความหน่วงไม่คาดเดาได้ภายใต้ภาระ
- ความหน่วงในการทำสำเนาและการสลับล้มเหลวที่ช้าลงเมื่อชุดข้อมูลเติบโต
เครื่องใหญ่ไม่แก้ปัญหา availability ระดับโลก
หลายแอปต้องให้บริการข้ามภูมิภาค ไม่ใช่แค่เร็วในดาต้าเซ็นเตอร์เดียว ฐานข้อมูลหลักในที่เดียวเพิ่มความหน่วงให้ผู้ใช้ที่อยู่ไกล และทำให้การเกิดข้อขัดข้องกลายเป็นโศกนาฏกรรม คำถามเปลี่ยนจาก "จะซื้อเครื่องยี่ห้อใหญ่ขึ้นอย่างไร?" เป็น "จะรันฐานข้อมูลบนหลายเครื่องและหลายที่ตั้งอย่างไร?"
ความต้องการรูปแบบข้อมูลที่ยืดหยุ่น
ฐานข้อมูลเชิงสัมพันธ์เด่นเมื่อรูปร่างข้อมูลคงที่ แต่ผลิตภัณฑ์สมัยใหม่จำนวนมากไม่หยุดนิ่ง สกีมาตารางถูกออกแบบเข้มงวด: ทุกแถวมีชุดคอลัมน์ ประเภท และข้อจำกัดเดียวกัน ความคาดเดาได้นั้นมีค่า—จนกระทั่งคุณต้องทำซ้ำเร็ว
สกีมาที่เข้มงวดและต้นทุนจริงของการเปลี่ยนแปลง
ในทางปฏิบัติ การเปลี่ยนสกีมาบ่อยครั้งมีต้นทุนสูง การเปลี่ยนแปลงที่ดูเหมือนเล็กน้อยอาจต้องย้ายข้อมูล เติมข้อมูลย้อนหลัง อัปเดตดัชนี วางแผนการปรับใช้ที่ประสานกัน และวางแผนความเข้ากันได้เพื่อไม่ให้เส้นทางโค้ดเก่าเสียหาย บนตารางขนาดใหญ่ แม้แต่การเพิ่มคอลัมน์หรือเปลี่ยนประเภทก็อาจเป็นงานที่กินเวลาพร้อมความเสี่ยงเชิงปฏิบัติการ
แรงเสียดทานนี้ผลักดันททีมให้เลื่อนการเปลี่ยนแปลง สะสมวิธีแก้ไขชั่วคราว หรือเก็บ blob แบบยุ่งในฟิลด์ข้อความ—ซึ่งไม่มีใครเป็นทางออกที่ดีสำหรับการทำซ้ำอย่างรวดเร็ว
ข้อมูลกึ่งโครงสร้างเข้ากับการพัฒนาผลิตภัณฑ์
ข้อมูลแอปจำนวนมากเป็นกึ่งโครงสร้างตามธรรมชาติ: อ็อบเจกต์ซ้อน ฟิลด์ที่เป็นทางเลือก และแอตทริบิวต์ที่เปลี่ยนแปลงตามเวลา
ตัวอย่างเช่น "โปรไฟล์ผู้ใช้" อาจเริ่มจากชื่อและอีเมล แล้วเติบโตไปเป็นการตั้งค่าความชอบ บัญชีที่ลิงก์ ที่อยู่จัดส่ง การตั้งค่าการแจ้งเตือน และแฟลกทดลอง แต่ละผู้ใช้อาจไม่มีทุกฟิลด์ และฟิลด์ใหม่เพิ่มขึ้นอย่างค่อยเป็นค่อยไป รูปแบบเอกสารสามารถเก็บรูปร่างที่ซ้อนและไม่สม่ำเสมอโดยตรงโดยไม่บังคับให้เรคอร์ดทุกชิ้นเข้ากับเทมเพลตเดียวกัน
ทำซ้ำได้เร็วขึ้น ลดการ join ที่น่าอึดอัด
ความยืดหยุ่นยังลดความจำเป็นในการ join ซับซ้อนสำหรับรูปร่างข้อมูลบางอย่าง เมื่อต้องการหน้าจอเดียวที่ต้องการวัตถุประกอบ (คำสั่งพร้อมไอเท็ม ข้อมูลการจัดส่ง และประวัติสถานะ) การออกแบบเชิงสัมพันธ์อาจต้องการหลายตารางและการ join—รวมถึงชั้น ORM ที่พยายามซ่อนความซับซ้อนแต่มักเพิ่มแรงเสียดทาน
ตัวเลือก NoSQL ช่วยให้การจำลองข้อมูลใกล้กับวิธีการอ่านและเขียนของแอป ช่วยให้ทีมปล่อยฟีเจอร์ได้เร็วขึ้น
การเปลี่ยนไปสู่เว็บสเกลที่เปลี่ยนข้อกำหนดของฐานข้อมูล
เว็บแอปไม่ได้แค่ใหญ่ขึ้น—แต่เปลี่ยนรูปร่าง แทนที่จะให้บริการผู้ใช้ภายในจำนวนน้อยในช่วงชั่วโมงทำงาน ผลิตภัณฑ์เริ่มให้บริการผู้ใช้ทั่วโลกเป็นล้านคนตลอดเวลา พร้อมพีคกะทันหันจากการเปิดตัว ข่าว หรือการแชร์ทางสังคม
ความคาดหวังแบบ always-on ยกมาตรฐาน: การหยุดทำงานกลายเป็นข่าว ไม่ใช่แค่ความไม่สะดวก ในเวลาเดียวกัน ทีมถูกขอให้ปล่อยฟีเจอร์เร็วขึ้น—บ่อยครั้งก่อนจะรู้ว่าสกีมาข้อมูล "สุดท้าย" ควรเป็นอย่างไร
การกระจายตัวกลายเป็นเส้นทางสู่การเติบโต
เพื่อทันตาม พึ่งพาเครื่องเดียวที่ใหญ่ขึ้นไม่เพียงพอ ยิ่งคุณจัดการทราฟฟิกมากขึ้นเท่าไร คุณยิ่งต้องการความจุที่สามารถเพิ่มได้ทีละขั้น—เพิ่มโนดอีกตัว กระจายภาระ แยกความล้มเหลว
นี่ผลักสถาปัตยกรรมไปสู่ฟลีทของเครื่องมากกว่า "กล่องหลัก" เดียว และเปลี่ยนความคาดหวังของทีมต่อฐานข้อมูล: ไม่ใช่แค่ความถูกต้อง แต่เป็นประสิทธิภาพที่คาดเดาได้ภายใต้ความพร้อมใช้งานสูงและพฤติกรรมที่ยืดหยุ่นเมื่อส่วนของระบบไม่ทำงาน
รูปแบบที่ทีมนำไปใช้ก่อนที่ฐานข้อมูลจะตามทัน
ก่อนที่ "NoSQL" จะเป็นหมวดหมู่กระแสหลัก ทีมหลายทีมก็เริ่มปรับระบบให้เข้ากับความเป็นจริงของเว็บสเกล:
- เลเยอร์แคช (มักเป็นหน่วยความจำ) เพื่อลดการอ่านซ้ำ
- การ denormalize เพื่อลดการ join ที่แพงและลดรอบการขอ
- มุมมองคำนวณล่วงหน้า และ rollup ที่ materialized สำหรับฟีด ไทม์ไลน์ และแดชบอร์ด
เทคนิคเหล่านี้ใช้ได้ แต่ถ่ายโอนความซับซ้อนไปยังโค้ดแอป: การยกเลิกแคช การรักษาข้อมูลที่ทำสำเนาให้สอดคล้อง และการสร้างพาไปป์ไลน์สำหรับเรคอร์ดที่ "พร้อมให้บริการ"
สิ่งนี้ผลักดันให้ฐานข้อมูลต้องพัฒนา
เมื่อรูปแบบเหล่านี้กลายเป็นมาตรฐาน ฐานข้อมูลต้องรองรับการกระจายข้อมูลข้ามเครื่อง ทนต่อความล้มเหลวบางส่วน จัดการปริมาณการเขียนสูง และแทนรูปร่างข้อมูลที่เปลี่ยนแปลงได้อย่างชัดเจน NoSQL ปรากฏขึ้นบางส่วนเพื่อทำให้กลยุทธ์เว็บสเกลทั่วไปเป็นความสามารถหลักแทนที่จะเป็นวิธีแก้ปัญหาชั่วคราว
การแลกเปลี่ยนในการกระจายและทฤษฎี CAP
สร้างต้นแบบกลยุทธ์ข้อมูลของคุณ
สร้างต้นแบบแนวทาง SQL กับ NoSQL อย่างรวดเร็วด้วยแอปแบบฟูลสแตกที่สร้างจากแชท
เมื่อข้อมูลอยู่ในเครื่องเดียว กฎจะดูเรียบง่าย: มีแหล่งความจริงเดียว และการอ่านหรือเขียนแต่ละครั้งสามารถตรวจสอบได้ทันที เมื่อคุณกระจายข้อมูลข้ามเซิร์ฟเวอร์ (มักข้ามภูมิภาค) ความเป็นจริงใหม่ปรากฏ: ข้อความอาจล่าช้า โนดอาจล้มเหลว และบางส่วนของระบบอาจหยุดสื่อสารชั่วคราว
การแลกเปลี่ยนแกนกลาง (อธิบายง่าย)
ฐานข้อมูลกระจายต้องตัดสินใจว่าจะทำอย่างไรเมื่อไม่สามารถประสานงานได้อย่างปลอดภัย ควรยังคงให้บริการคำขอเพื่อให้แอปยัง "พร้อม" แม้ว่าผลลัพธ์อาจล้าสมัยเล็กน้อยหรือควรปฏิเสธการดำเนินการบางอย่างจนกว่าจะยืนยันความเห็นพ้องของสำเนา ซึ่งอาจถูกมองว่าเป็นการหยุดทำงานสำหรับผู้ใช้
สถานการณ์เหล่านี้เกิดขึ้นระหว่างการล้มเหลวของเราเตอร์ เครือข่ายล้นเกิน การปรับปรุงแบบโรลิง กำหนดค่าไฟร์วอลล์ผิดพลาด และความล่าช้าในการทำสำเนาข้ามภูมิภาค
CAP ในกรอบเดียว: C, A และ P
ทฤษฎี CAP เป็นย่อความสำหรับคุณสมบัติสามอย่างที่คุณอยากได้พร้อมกัน:
- Consistency (C): ทุกการอ่านคืนค่าการเขียนล่าสุด (หรือข้อผิดพลาด). ในทางปฏิบัติ "ทุกคนเห็นคำตอบเดียวกันเดี๋ยวนั้น"
- Availability (A): ทุกคำขอได้รับการตอบ (ไม่จำเป็นต้องเป็นข้อมูลใหม่ที่สุด)
- Partition Tolerance (P): ระบบยังทำงานได้แม้เครือข่ายจะแยกเป็นกลุ่มแยกกัน
ประเด็นสำคัญไม่ใช่ "เลือกสองตลอดไป" แต่คือ: เมื่อเกิดพาร์ติชันของเครือข่าย คุณต้องเลือกระหว่างความสอดคล้องและความพร้อมใช้งาน ในระบบเว็บสเกล พาร์ติชันถือว่าเป็นเรื่องหลีกเลี่ยงไม่ได้—โดยเฉพาะในสภาพแวดล้อมหลายภูมิภาค
พาร์ติชันเชื่อมโยงกับการล่มจริง
ลองนึกว่าแอปของคุณรันวางในสองภูมิภาคเพื่อความยืดหยุ่น การตัดใยแก้วนำแสงหรือปัญหาเส้นทางทำให้การซิงก์หยุดชะงัก
- หากคุณให้ความสำคัญกับ availability ทั้งสองภูมิภาคยังรับเขียนและข้อมูลอาจเบี่ยงเบนชั่วคราว
- หากคุณให้ความสำคัญกับ consistency หนึ่งภูมิภาคอาจปฏิเสธการเขียน (หรือการอ่าน) จนกว่าจะยืนยันความเห็นพ้องได้
ระบบ NoSQL ต่างๆ (และแม้แต่การกำหนดค่าต่างกันของระบบเดียวกัน) ทำการแลกเปลี่ยนต่างกันขึ้นกับสิ่งที่สำคัญที่สุด: ประสบการณ์ผู้ใช้เมื่อเกิดความล้มเหลว ความถูกต้อง การปฏิบัติงานที่เรียบง่าย หรือพฤติกรรมการกู้คืน
การสเกลออก: แนวคิดหลักคือการชาร์ดและการทำสำเนา
การสเกลออก (การสเกลแนวนอน) หมายถึงการเพิ่มความจุโดยการเพิ่มเครื่อง (โนด) แทนการซื้อเครื่องที่ใหญ่ขึ้น สำหรับหลายทีม นี่คือการเปลี่ยนแปลงทางการเงินและการปฏิบัติการ: สามารถเพิ่มโหนดสาธารณะทีละน้อย คาดหวังความล้มเหลว และการเติบโตไม่ต้องอาศัยการโยกย้าย "กล่องใหญ่" ที่เสี่ยง
ชาร์ด (partitioning): กระจายงาน
เพื่อให้หลายโนดมีประโยชน์ ระบบ NoSQL พึ่งพาการชาร์ด (หรือเรียกว่า partitioning) แทนที่จะให้ฐานข้อมูลเดียวจัดการคำขอทั้งหมด ข้อมูลจะแบ่งเป็นพาร์ติชันและกระจายไปยังโนด
ตัวอย่างง่ายคือการแบ่งตามคีย์ (เช่น user_id):
- Node A เก็บผู้ใช้ 1–1,000,000
- Node B เก็บผู้ใช้ 1,000,001–2,000,000
การอ่านและเขียนกระจายตัว ลดจุดร้อน และทำให้ throughput เพิ่มเมื่อเพิ่มโนด พาร์ติชันคีย์จึงเป็นการตัดสินใจเชิงออกแบบ: เลือกคีย์ที่สอดคล้องกับรูปแบบการค้นหา มิฉะนั้นคุณอาจบีบทราฟฟิกไปยังชาร์ดเดียว
การทำสำเนา: availability และการสเกลการอ่าน
การทำสำเนาคือการเก็บสำเนาข้อมูลเดียวกันบนหลายโนด ซึ่งช่วยในด้าน:
- Availability: หากโนดหนึ่งล้มเหลว สำเนาอื่นสามารถให้บริการได้
- ความจุการอ่าน: การอ่านสามารถให้บริการจากสำเนาหลายแห่ง
การทำสำเนายังช่วยให้กระจายข้อมูลข้ามแร็คหรือภูมิภาคเพื่อความทนทานต่อการล่มเฉพาะจุด
ต้นทุนแฝง: การบาลานซ์และการปฏิบัติการ
การชาร์ดและการทำสำเนาเพิ่มงานปฏิบัติการอย่างต่อเนื่อง เมื่อข้อมูลเติบโตหรือโนดเปลี่ยน ระบบต้อง rebalance—ย้ายพาร์ติชันขณะออนไลน์ หากจัดการไม่ดี การบาลานซ์อาจทำให้เกิดพีคความหน่วง โหลดไม่สม่ำเสมอ หรือชั่วคราวขาดความจุ
นี่คือการแลกเปลี่ยนหลัก: การสเกลที่ถูกกว่าโดยการเพิ่มโนด แลกกับการกระจาย การมอนิเตอร์ และการจัดการความล้มเหลวที่ซับซ้อนขึ้น
แบบของความสอดคล้อง: จากเข้มงวดถึงในท้ายที่สุด
เมื่อข้อมูลถูกกระจาย ฐานข้อมูลต้องกำหนดว่า "ถูกต้อง" หมายถึงอะไรเมื่อมีการอัปเดตพร้อมกัน เครือข่ายช้า หรือโนดไม่สามารถสื่อสารกัน
ความสอดคล้องแบบเข้มงวด
ด้วยความสอดคล้องแข็งแรง เมื่อการเขียนได้รับการยืนยัน ผู้อ่านทุกคนควรเห็นมันทันที นี่สอดคล้องกับประสบการณ์ "แหล่งความจริงเดียว" ที่หลายคนเชื่อมโยงกับฐานข้อมูลเชิงสัมพันธ์
ความท้าทายคือการประสานงาน: รับประกันข้ามโนดต้องมีการส่งข้อความหลายครั้ง รอคำตอบเพียงพอ และจัดการความล้มเหลวระหว่างทาง ยิ่งโนดไกลหรือมีการใช้งานหนัก ยิ่งเพิ่มความหน่วง—บางครั้งในทุกการเขียน
ความสอดคล้องในท้ายที่สุด
Eventual consistency ผ่อนปรนการรับประกันนั้น: หลังการเขียน โนดต่างกันอาจคืนคำตอบต่างกันชั่วคราว แต่ระบบจะลู่เข้าสู่สถานะเดียวกันเมื่อเวลาผ่านไป
ตัวอย่าง:
- เคาน์เตอร์ "ไลก์" อาจแสดง 101 บนสำเนาหนึ่ง ในขณะที่สำเนาอื่นยังแสดง 100 สักครู่หนึ่ง
- โพสต์ใหม่อาจปรากฏในฟีดของผู้ใช้บางคนก่อนคนอื่น โดยเฉพาะข้ามภูมิภาค
สำหรับประสบการณ์ผู้ใช้หลายอย่าง ความไม่ตรงกันชั่วคราวนั้นยอมรับได้หากระบบยังคงเร็วและพร้อมใช้งาน
ความขัดแย้งและวิธีแก้
ถ้าสำเนาสองตัวรับอัปเดตพร้อมกัน ฐานข้อมูลต้องมีนโยบายการรวม
วิธีที่พบบ่อยได้แก่:
- Timestamp (last-write-wins): เก็บอัปเดตที่มี timestamp ใหม่สุด ง่ายแต่เสี่ยงสูญเสียข้อมูลถ้านาฬิกาเพี้ยนหรือ "ใหม่สุด" ไม่ใช่สิ่งที่ต้องการเชิงความหมาย
- เวอร์ชันแบบเวกเตอร์ (แนวคิด): ติดตามว่าสำเนาใดเห็นอัปเดตใด ตรวจจับการเขียนพร้อมกัน แล้วรวมหรือแสดงความขัดแย้งให้แก้ไข
ที่ไหนที่ความสอดคล้องแข็งแรงยังสำคัญ
ความสอดคล้องแข็งแรงมักคุ้มค่าในงานการย้ายเงิน ขีดจำกัดสินค้าคงคลัง ชื่อผู้ใช้ที่ต้องเป็นเอกลักษณ์ สิทธิ์การเข้าถึง และเวิร์กโฟลว์ที่ "สองความจริงชั่วคราว" อาจก่อให้เกิดความเสียหายจริง
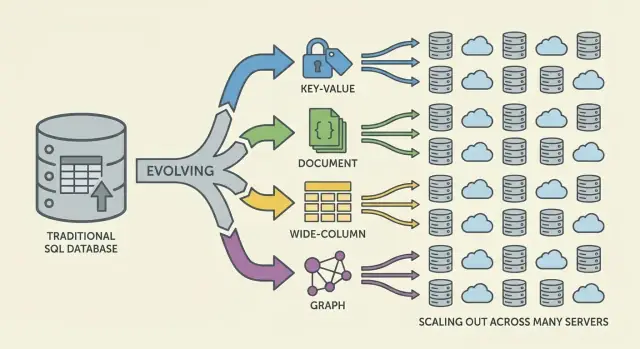
ตระกูลหลักของฐานข้อมูล NoSQL (และสิ่งที่แต่ละแบบมุ่งเน้น)
แชร์เดโมที่รันได้
เปิดตัวเดโมภายในที่ทำงานได้พร้อมโฮสติ้ง แล้วแชร์เพื่อรับข้อเสนอแนะ
NoSQL คือชุดโมเดลที่แลกเปลี่ยนต่างกันในเรื่องการสเกล ความหน่วง และรูปร่างข้อมูล การเข้าใจ "ตระกูล" ช่วยคาดเดาว่าอะไรจะเร็ว อะไรจะปวดหัว และทำไม
Key-value stores: ความเร็วจากความเรียบง่าย
ฐานข้อมูล key-value เก็บค่าไว้หลังคีย์เฉพาะ เหมือน hashmap ขนาดใหญ่ที่กระจายได้ เพราะรูปแบบการเข้าถึงมักเป็น "get โดยคีย์" / "set โดยคีย์" พวกมันจึงเร็วมากและสเกลแนวนอนได้ดี
เหมาะเมื่อคุณรู้คีย์สำหรับดึงอยู่แล้ว (เซสชัน แคช ฟีเจอร์แฟล็ก) แต่จำกัดสำหรับการค้นหา ad-hoc: การกรองข้ามหลายฟิลด์มักไม่ใช่วัตถุประสงค์ของระบบ
Document databases: เรคอร์ดยืดหยุ่น รูปร่างคล้าย JSON
ฐานข้อมูลเอกสารเก็บเอกสารเหมือน JSON (มักอยู่ในคอลเลกชัน) แต่ละเอกสารอาจมีโครงสร้างต่างกัน ซึ่งรองรับความยืดหยุ่นของสกีมาเมื่อผลิตภัณฑ์เติบโต
พวกมันปรับแต่งการอ่าน/เขียนเอกสารทั้งชิ้นและการค้นหาตามฟิลด์ภายในเอกสาร—โดยไม่บังคับตารางที่เข้มงวด การแลกเปลี่ยนคือการจำลองความสัมพันธ์อาจซับซ้อน และการ join (หากรองรับ) อาจจำกัดกว่าฐานข้อมูลเชิงสัมพันธ์
Wide-column stores: ผ่านข้อมูลเขียนจำนวนมากที่สเกลมหาศาล
ฐานข้อมูลแบบ wide-column (ได้รับแรงบันดาลใจจาก Bigtable) จัดเรียงข้อมูลตามคีย์แถว โดยมีคอลัมน์มากมายที่อาจต่างกันต่อแถว พวกมันโดดเด่นด้านอัตราการเขียนมหาศาลและการเก็บแบบกระจาย ทำให้เหมาะกับ time-series อีเวนต์ และโลจ
พวกมันมักตอบแทนการออกแบบที่ระมัดระวังตามรูปแบบการเข้าถึง: คุณค้นหามีประสิทธิภาพตามคีย์หลักและกฎการจัดกลุ่ม ไม่ใช่ตัวกรองแบบสุ่ม
Graph databases: การคิวรีที่เน้นความสัมพันธ์เป็นหลัก
ฐานข้อมูลกราฟให้ความสำคัญกับความสัมพันธ์เป็นอันดับแรก แทนที่จะ join ซ้ำๆ ระบบจะเดินตามขอบระหว่างโหนด ทำให้คำถามประเภท "สิ่งเหล่านี้เชื่อมโยงกันอย่างไร" เป็นเรื่องธรรมชาติและเร็ว (วงจรการฉ้อโกง คำแนะนำ แผนผังการพึ่งพา)
ไกด์ด่วน: แต่ละโมเดลเหมาะกับอะไร
- Key-value: ดึงเร็วที่สุดตาม ID; แคช เซสชัน เคาน์เตอร์
- Document: ข้อมูลผลิตภัณฑ์ที่พัฒนาได้; โปรไฟล์ แคตตาล็อก เนื้อหา
- Wide-column: การเก็บอีเวนต์ขนาดใหญ่; เทเลเมทรี บันทึก time-series
- Graph: การค้นหาความสัมพันธ์ลึก; กราฟสังคม การวางเส้นทาง การวิเคราะห์การฉ้อโกง
การเปลี่ยนแปลงในการออกแบบข้อมูล: Join น้อยลง การออกแบบมีเจตนามากขึ้น
ฐานข้อมูลเชิงสัมพันธ์ส่งเสริม normalization: แยกข้อมูลเป็นตารางหลายตารางและประกอบใหม่ด้วย join ในเวลาคิวรี หลายระบบ NoSQL ผลักให้คุณออกแบบรอบรูปแบบการเข้าถึงที่สำคัญที่สุด—บางครั้งแลกด้วยการซ้ำของข้อมูล—เพื่อให้ความหน่วงคาดเดาได้ข้ามโนด
ทำไมการ denormalize จึงเป็นเรื่องปกติ
ในฐานข้อมูลกระจาย การ join อาจต้องดึงข้อมูลจากพาร์ติชันหรือเครื่องหลายเครื่อง เพิ่มการเดินทางของเครือข่าย การประสานงาน และความหน่วงที่ไม่คาดคิด การ denormalize (เก็บข้อมูลที่เกี่ยวข้องด้วยกัน) ลดรอบการขอและทำให้การอ่านมักจะเป็น "ท้องถิ่น"
ผลลัพธ์เชิงปฏิบัติ: คุณอาจเก็บชื่อผู้ใช้ซ้ำในเรคอร์ด orders ถึงแม้มันจะอยู่ในตาราง customers เพราะ "ดู 20 คำสั่งล่าสุด" เป็นการค้นหาหลัก
ข้อจำกัดของการค้นหา: join น้อยลง การออกแบบในแอปเพิ่มขึ้น
ฐานข้อมูล NoSQL หลายตัวรองรับ join จำกัด (หรือไม่มี) ดังนั้นแอปต้องรับผิดชอบมากขึ้น:
- ดึงเอกสาร/แถวตามคีย์แล้วเรนเดอร์ตรง
- อ่านชุดข้อมูลสองชุดแยกกันแล้วรวมในโค้ด
- คำนวณมุมมองล่วงหน้า (counts, summaries) เพื่อตัดการสแกนที่แพง
นี่คือเหตุผลที่การออกแบบ NoSQL มักเริ่มจาก: "หน้าจอไหนที่เราต้องโหลด?" และ "คำค้นหาหลักที่ต้องให้เร็วคืออะไร?"
ดัชนีรอง—และต้นทุนแอบแฝงของมัน
ดัชนีรองสามารถเปิดการค้นหาใหม่ๆ ("ค้นหาผู้ใช้ตามอีเมล") แต่ไม่ได้มาฟรี ในระบบกระจาย การเขียนแต่ละครั้งอาจอัปเดตโครงสร้างดัชนีหลายตัว นำไปสู่:
- การเพิ่มการเขียน: หนึ่งการเขียนเชิงตรรกะกลายเป็นหลายการเขียนเชิงกายภาพ
- พื้นที่เก็บเพิ่มขึ้น: รายการดัชนีอาจใหญ่เท่าข้อมูล
- ความซับซ้อนเชิงปฏิบัติการ: ดัชนีอาจล่าช้าหรือจำเป็นต้องจูนอย่างระมัดระวัง
ตัวอย่างการออกแบบที่เพิ่มประสิทธิภาพ
- ฝังมากกว่าการอ้างอิง: เก็บไอเท็มคำสั่งภายในเอกสารคำสั่งเพื่ออ่านคำสั่งได้ในการร้องขอเดียว
- แบ่งบัคเก็ตข้อมูล time-series: เก็บอีเวนต์ต่ออุปกรณ์ต่อวันเพื่อหลีกเลี่ยงพาร์ติชันที่ไม่จำกัด
- วัตถุอ่านที่ materialize: รักษาเรคอร์ด "user_profile_summary" เพื่อให้หน้าโปรไฟล์แสดงได้โดยไม่ต้องสแกนโพสต์ ไลก์ และคนติดตาม
ประโยชน์และการแลกเปลี่ยนที่ทีมยอมรับ
ควบคุมทั้งหมดด้วยตัวเอง
สร้างแอปแล้วส่งออกซอร์สโค้ดเพื่อแก้ไขต่อในแบบของคุณ
NoSQL ไม่ได้ถูกนำมาใช้เพราะมัน "ดีกว่า" ในทุกด้าน แต่นำมาใช้เพราะทีมยอมแลกบางความสะดวกของฐานข้อมูลเชิงสัมพันธ์เพื่อแลกกับความเร็ว การสเกล และความยืดหยุ่นภายใต้แรงกดดันเว็บสเกล
สิ่งที่ทีมได้
สเกลออกโดยออกแบบ. ระบบ NoSQL หลายระบบทำให้การเพิ่มเครื่องเป็นไปได้จริงโดยไม่ต้องอัปเกรดเครื่องเดี่ยวอย่างต่อเนื่อง ชาร์ดและการทำสำเนาเป็นความสามารถหลัก ไม่ใช่ของแทรก
สกีมายืดหยุ่น. ระบบเอกสารและคีย์-แวลู ช่วยให้แอปพัฒนาโดยไม่ต้องส่งทุกการเปลี่ยนแปลงฟิลด์ผ่านนิยามตารางที่เข้มงวด ลดแรงเสียดทานเมื่อความต้องการเปลี่ยนสัปดาห์ต่อสัปดาห์
รูปแบบความพร้อมสูง. การทำสำเนาข้ามโนดและภูมิภาคช่วยให้บริการยังคงรันได้ระหว่างความล้มเหลวของฮาร์ดแวร์หรือบำรุงรักษา
สิ่งที่ทีมต้องจ่าย
การทำสำเนาข้อมูลและ denormalization. การหลีกเลี่ยง join มักหมายถึงการทำสำเนาข้อมูล ซึ่งดีต่อประสิทธิภาพการอ่านแต่เพิ่มพื้นที่เก็บและความซับซ้อนเมื่อต้องอัปเดตทุกที่
ความประหลาดใจเรื่องความสอดคล้อง. Eventual consistency อาจยอมรับได้—จนกว่าจะไม่เป็น หากการออกแบบแอปไม่รองรับหรือแก้ความขัดแย้ง ผู้ใช้จะเห็นข้อมูลล้าสมัยหรือกรณีขอบที่สับสน
การวิเคราะห์ที่ยากขึ้น (บางครั้ง). บางที่จัดเก็บ NoSQL เหมาะกับการอ่าน/เขียนเชิงปฏิบัติการ แต่ทำให้การค้นหา ad-hoc รายงาน หรือการรวมเชิงซับซ้อนยุ่งยากกว่าระบบที่เน้น SQL
ทำไมการปฏิบัติการและเครื่องมือจึงสำคัญ
การนำ NoSQL มาใช้ในช่วงแรกมักย้ายความพยายามจากฟีเจอร์ฐานข้อมูลไปสู่วินัยวิศวกรรม: มอนิเตอร์การทำสำเนา จัดการพาร์ติชัน รัน compaction วางแผนแบ็กอัพ/กู้คืน และทดสอบโหลด ทีมที่มีวุฒิภาวะการปฏิบัติการสูงได้ประโยชน์มากที่สุด
วิธีประเมินการแลกเปลี่ยน
เลือกตามความเป็นจริงของเวิร์กโหลด: ความหน่วงที่ต้องการ throughput ในช่วงพีค รูปแบบการค้นหาหลัก ความทนต่อการอ่านที่ล้าสมัย และข้อกำหนดการกู้คืน (RPO/RTO) ตัวเลือก NoSQL ที่ "ถูกต้อง" มักเป็นตัวที่สอดคล้องกับวิธีที่แอปของคุณล้มเหลว สเกล และถูกคิวรี มากกว่าตัวที่มีรายการฟีเจอร์น่าประทับใจที่สุด
จะตัดสินใจว่า NoSQL เหมาะกับวันนี้หรือไม่อย่างไร
การเลือก NoSQL ไม่ควรเริ่มจากแบรนด์ฐานข้อมูลหรือคำฮิต แต่น่าจะเริ่มจากสิ่งที่แอปต้องทำ วิธีที่มันจะเติบโต และ "ถูกต้อง" หมายถึงอะไรสำหรับผู้ใช้ของคุณ
เริ่มจากข้อกำหนดและรูปแบบการเข้าถึง
ก่อนเลือกร้านข้อมูล ให้จด:
- 5–10 คำค้นหาหรือการดำเนินการหลักที่ต้องรองรับ (อ่าน เขียน ค้นหา การรวม)
- ทราฟฟิกที่คาดหวังตอนนี้เทียบกับ 12–24 เดือนข้างหน้า
- ความทนต่อการอ่านที่ล้าสมัย (มิลลิวินาที วินาที ไม่เคย)
- ความคาดหวังเมื่อเกิดความล้มเหลว (เกิดอะไรขึ้นถ้าโนดหรือภูมิภาคล่ม?)
ถ้าคุณอธิบายรูปแบบการเข้าถึงไม่ชัด การเลือกใดๆ จะเป็นการเดา—โดยเฉพาะกับ NoSQL ที่การออกแบบมักถูกกำหนดโดยวิธีการอ่านและเขียน
เช็คลิสต์ตัดสินใจแบบง่าย (SQL vs NoSQL vs ไฮบริด)
ใช้ตัวกรองด่วนนี้:
- เลือก SQL ถ้าคุณต้องการความสอดคล้องแข็งแรงโดยดีฟอลต์ คำค้นหา ad-hoc ซับซ้อน และความสัมพันธ์จำนวนมากที่ได้ประโยชน์จากการ join
- เลือก NoSQL ถ้าคุณต้องการการสเกลแนวนอนสำหรับรูปแบบการเข้าถึงเฉพาะ ออกแบบข้อมูลไปรอบๆ รูปแบบเหล่านั้นได้ และยอมรับความสอดคล้องผ่อนปรนในบางเวิร์กโฟลว์
- เลือกไฮบริด ถ้าส่วนต่างๆ ของแอปมีความต้องการต่างกัน (พบได้บ่อยในผลิตภัณฑ์จริง)
สัญญาณปฏิบัติ: หาก "ความจริงหลัก" (คำสั่ง การชำระเงิน สต็อก) ต้องถูกต้องตลอดเวลา เก็บไว้ใน SQL หรือสโตร์ที่มีความสอดคล้องแข็งแรง หากคุณให้บริการเนื้อหาปริมาณสูง เซสชัน แคช ฟีด หรือข้อมูลผู้ใช้ที่ยืดหยุ่น NoSQL อาจเหมาะ
พิจารณา polyglot persistence อย่างมีจุดมุ่งหมาย
หลายทีมประสบความสำเร็จด้วยหลายสโตร์: ตัวอย่าง SQL สำหรับธุรกรรม, ฐานข้อมูลเอกสารสำหรับโปรไฟล์/เนื้อหา, และ key-value สำหรับเซสชัน จุดมุ่งหมายไม่ใช่ความซับซ้อนเพื่อมันเอง แต่คือการจับคู่แต่ละเวิร์กโหลดกับเครื่องมือที่จัดการได้ดี
นี่คือที่ที่เวิร์กโฟลว์ของนักพัฒนามีความสำคัญ หากคุณกำลังทดลองสถาปัตยกรรม (SQL vs NoSQL vs ไฮบริด) สามารถสปินต้นแบบที่ทำงานได้เร็ว—API แบบจำลองข้อมูล และ UI—จะช่วยลดความเสี่ยง แพลตฟอร์มเช่น Koder.ai ช่วยทีมทำสิ่งนี้โดยสร้างแอปฟูลสแตกจากแชท โดยมักจะมี frontend React และ backend Go + PostgreSQL แล้วให้คุณส่งออกซอร์สโค้ด แม้คุณอาจจะเพิ่ม NoSQL สำหรับบางเวิร์กโหลดในภายหลัง การมีระบบ SQL ที่แข็งแรงเป็น "ระบบของบันทึก" พร้อมการทำโปรโตไทป์อย่างรวดเร็ว snapshot และการย้อนกลับ ช่วยให้การทดลองปลอดภัยและเร็วขึ้น
ยืนยันด้วยการทดสอบ ไม่ใช่ความเห็นส่วนตัว
ไม่ว่าเลือกอะไร พิสูจน์มัน:
- ทำ load tests ด้วยคำค้นหาจริงและขนาดข้อมูลสมจริง
- ทำ failure drills (ฆ่าโนด จำลองปัญหาเครือข่าย ทดสอบการกู้คืน)
- สร้าง แผนการวิวัฒนาการสกีมา: วิธีเพิ่มฟิลด์ ย้ายเรคอร์ด และรักษาความเข้ากันได้ของเวอร์ชันเก่า/ใหม่ระหว่างการไล่ปล่อย
ถ้าคุณไม่สามารถทดสอบสถานการณ์เหล่านี้ การตัดสินใจฐานข้อมูลของคุณจะยังเป็นทฤษฎี—และโปรดักชันจะกลายเป็นสนามทดสอบของคุณ
คำถามที่พบบ่อย
What was NoSQL originally trying to solve?
NoSQL แก้ปัญหาสองแรงกดดันหลัก:
- สเกล: ปริมาณเขียนสูง การระเบิดของทราฟฟิก และชุดข้อมูลที่ใหญ่เกินกว่าที่จะพึ่งพา "เครื่องที่ใหญ่กว่า" เพียงเครื่องเดียว
- การเปลี่ยนแปลง: ความต้องการของผลิตภัณฑ์เปลี่ยนเร็ว ทำให้การปรับสกีมาในระบบเชิงสัมพันธ์มีต้นทุนสูงและเสี่ยง
มันไม่ได้หมายความว่า SQL "แย่" แต่หมายถึงเวิร์กโหลดบางอย่างให้ความสำคัญกับการแลกเปลี่ยนคนละชุดกัน
Why did scaling a single relational database server start to break down?
การ "สเกลขึ้น" แบบดั้งเดิมมีข้อจำกัดในทางปฏิบัติ:
- ฮาร์ดแวร์ระดับสูงมีราคาเร็วและการอัปเกรดก่อให้เกิดการหยุดชะงัก
- เครื่องเดียวกลายเป็นคอขวดสำหรับการเขียน พื้นที่จัดเก็บ และการเปลี่ยนผ่าน
- ผู้ใช้ทั่วโลกจะเจอความหน่วงเมื่อตัวฐานข้อมูลหลักอยู่ในภูมิภาคเดียว
ระบบ NoSQL มักเลือกแนวทาง สเกลออก โดยเพิ่มโนดแทนการซื้อเครื่องใหญ่ขึ้นเรื่อยๆ
Why did rigid schemas become a problem for modern applications?
สกีมาเชิงสัมพันธ์เข้มงวดโดยตั้งใจ ซึ่งดีต่อความเสถียรแต่เจ็บปวดเมื่อเปลี่ยนแปลงเร็ว ในตารางขนาดใหญ่ การเปลี่ยนแปลง "เล็กน้อย" อาจต้อง:
- การโยกย้ายข้อมูลและ backfill
- การอัปเดดดัชนี
- การประสานการปล่อยซอฟต์แวร์ระหว่างทีม
- ความเสี่ยงการหยุดทำงานหรือหน้าต่างการบำรุงรักษาที่ยาวนาน
รูปแบบแบบเอกสารมักลดแรงเสียดทานนี้ด้วยการยอมรับฟิลด์ที่เป็นทางเลือกและเปลี่ยนรูปร่างได้
Is NoSQL only about horizontal scaling (scaling out)?
ไม่จำเป็นเสมอไป ฐานข้อมูล SQL หลายตัวสามารถสเกลออกได้ แต่การทำเช่นนั้นมักซับซ้อนในเชิงปฏิบัติการ (กลยุทธ์ชาร์ด การ join ข้ามชาร์ด ธุรกรรมแบบกระจาย)
ระบบ NoSQL มักทำให้การกระจายข้อมูล (partitioning + replication) เป็นความสามารถหลักที่ออกแบบมาให้ใช้งานได้ง่ายสำหรับรูปแบบการเข้าถึงที่คาดเดาได้เมื่อขนาดใหญ่
Why do NoSQL designs often use denormalization and fewer joins?
การทำ denormalization เก็บข้อมูลในรูปแบบที่อ่านได้โดยตรง มักทำให้จำเป็นต้องทำสำเนาฟิลด์เพื่อหลีกเลี่ยงการ join ข้ามพาร์ติชัน
ตัวอย่าง: เก็บชื่อลูกค้าในเรคอร์ด orders เพื่อให้การดึง "20 คำสั่งล่าสุด" เป็นการอ่านเดียวที่เร็ว
การแลกเปลี่ยนคือความซับซ้อนเมื่อต้องอัปเดต: คุณต้องรักษาความสอดคล้องของข้อมูลที่ซ้ำผ่านตรรกะแอปหรือพาไปป์ไลน์
What does the CAP theorem mean in practical terms for NoSQL?
ในระบบกระจาย ฐานข้อมูลต้องตัดสินใจว่าทำอย่างไรเมื่อเกิดการแบ่งพาร์ติชันของเครือข่าย:
- เน้นความพร้อมใช้งาน: ยังคงให้บริการ อาจส่งข้อมูลที่ล้าสมัยชั่วคราว
- เน้นความสอดคล้อง: ปฏิเสธหรือลดการทำงานจนกว่าจะยืนยันความเห็นพ้องของสำเนาได้
CAP เตือนว่าเมื่อเกิดพาร์ติชัน คุณไม่สามารถรับประกันทั้งความสอดคล้องที่สมบูรณ์และความพร้อมใช้งานเต็มรูปแบบพร้อมกันได้
What’s the difference between strong consistency and eventual consistency?
ความสอดคล้องแข็งแรง (Strong consistency) หมายความว่าหลังการเขียนถูกยืนยัน ผู้อ่านทุกคนจะเห็นค่าเดียวกันทันที; มักต้องประสานหลายโนด
ความสอดคล้องในท้ายที่สุด (Eventual consistency) หมายความว่าโนดต่างกันอาจให้คำตอบต่างกันชั่วคราว แต่ระบบจะลู่เข้าสู่สถานะเดียวกันเมื่อเวลาผ่านไป
ความแข็งแรงเหมาะกับงานที่ไม่ยอมให้มีความไม่สอดคล้อง เช่น การย้ายเงิน ขีดจำกัดสินค้าคงคลัง หรือสิทธิ์การเข้าถึง
How do NoSQL databases handle conflicting writes?
ความขัดแย้งเกิดเมื่อสำเนาต่างกันรับอัปเดตพร้อมกัน ยุทธศาสตร์ที่พบบ่อย:
- Last-write-wins (timestamps): เลือกอัปเดตที่มีเวลาใหม่สุด; ง่าย แต่เสี่ยงสูญเสียข้อมูลถ้าเวลาไม่สอดคล้องหรือ "ใหม่กว่า" ไม่ได้หมายถึงถูกต้องเชิงความหมาย
- วิธีการเวอร์ชัน (เช่น เวกเตอร์): ติดตามว่าแต่ละสำเนาเห็นอัปเดตใดบ้าง เพื่อตรวจจับความขัดแย้งและรวมหรือแสดงผลขึ้นมาให้แก้ไข
การเลือกวิธีขึ้นกับว่าการสูญเสียอัปเดตชั่วคราวรับได้หรือไม่สำหรับข้อมูลประเภทนั้น
How do I choose between key-value, document, wide-column, and graph databases?
แนวทางการเลือกแบบย่อ:
- Key-value: การค้นหาตามคีย์เร็วที่สุด (sessions, caching, feature flags)
- Document: เรคอร์ดแบบ JSON ยืดหยุ่น (โปรไฟล์, แคตตาล็อก, เนื้อหา)
- Wide-column: การเขียนปริมาณมากระดับมหาศาล (อีเวนต์, บันทึก, time-series)
- Graph: การข้ามความสัมพันธ์ (คำแนะนำ, วงจรการฉ้อโกง, แผนผังการพึ่งพา)
เลือกตามรูปแบบการเข้าถึงหลักของคุณ ไม่ใช่ตามความนิยมทั่วไป
How can I tell if NoSQL is the right choice for my system today?
เริ่มจากข้อกำหนดแล้วพิสูจน์ด้วยการทดสอบ:
- จด 5–10 การดำเนินการหลัก ที่ต้องรองรับและการเติบโตที่คาดหวัง
- กำหนดความทนต่อการอ่านที่ล้าสมัยและพฤติกรรมเมื่อเกิดความล้มเหลว (การสูญเสียโนด/ภูมิภาค)
- ทำ load tests ด้วยขนาดข้อมูลสมจริง
- ฝึก failure drills (ปิดโนด จำลองพาร์ติชัน ทดสอบการกู้คืน)
ระบบจริงหลายแห่งเป็น : SQL สำหรับความจริงหลัก (การชำระเงิน สต็อก) และ NoSQL สำหรับข้อมูลปริมาณสูงหรือยืดหยุ่น (ฟีด, เซสชัน, โปรไฟล์)