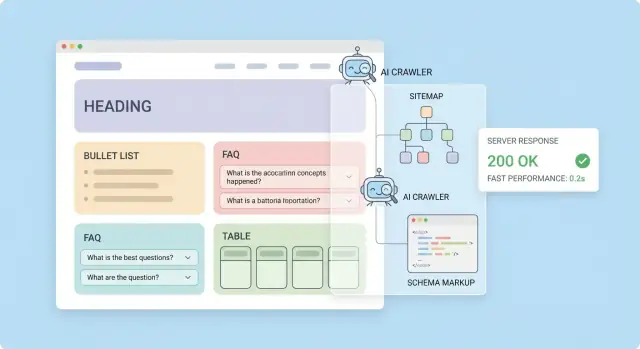
“AI-Uyumlu” Gerçekte Ne Anlama Gelir
“AI-uyumlu” sıklıkla bir pazarlama terimi olarak kullanılır; ama uygulamada bunun anlamı, sitenizin otomatik sistemler tarafından kolayca bulunabilir, okunabilir ve doğru şekilde yeniden kullanılabilir olmasıdır.
People tarafından söylenen AI tarayıcılar, genellikle özetler, cevaplar, eğitim veri setleri veya retrieval sistemleri gibi özellikleri desteklemek için web sayfalarını getiren arama motorları, AI ürünleri veya veri sağlayıcıları tarafından işletilen botlardır. LLM dizinleme genellikle sayfalarınızı aranabilir bir bilgi deposuna dönüştürmeyi (çoğunlukla meta verili “parçalara ayrılmış” metin) ifade eder; böylece bir AI asistan doğru parçayı getirip alıntılayabilir veya belirtebilir.
Gerçek hedefler
AI optimizasyonu “sıralama”dan çok şu dört sonuca yöneliktir:
- Keşif: tarayıcılar önemli URL’lerinize güvenilir şekilde erişebilmeli.
- Ayrıştırma: içeriğiniz tahmin yürütmeye gerek kalmadan okunabilir olmalı (temiz HTML, öngörülebilir yapı).
- Atıf/alıntı: kimin yazdığı, ne zaman güncellendiği ve hangi kaynakların desteklediği açık olmalı.
- Erişilebilirlik kalitesi: pasajlar kendi başına anlaşılır, spesifik ve bir soruya eşlemek için kolay olmalı.
Beklentileri ayarlayın (ve kontrol edebildikleriniz)
Hiç kimse belirli bir AI indeksine veya modele dahil olmayı garanti edemez. Farklı sağlayıcılar farklı şekilde tarar, farklı politikalara uyar ve farklı zamanlarda günceller.
Kontrol edebileceğiniz şey, içeriğinizi erişilmesi, çıkarılması ve kaynak gösterilebilmesi açısından basit hale getirmektir—böylece kullanılırsa doğru kullanılır.
Bu rehberin sonunda neleri uygulamış olacaksınız
- Robots ve meta yönergelerle net erişim kurallarına sahip taranabilir bir site
- Çoğaltmaları azaltmak için temiz URL ve canonical uygulamaları
- Ana sayfaları çabuk görünür kılan sitemapler ve dahili bağlantılar
- Makinelerin yorumlayabileceği şekilde “parçalara ayrılmış” içerik formatlama
- Her sayfanın ne hakkında olduğunu etiketleyecek yapılandırılmış veri
- LLM odaklı keşfi yönlendirecek basit bir
llms.txt dosyası
- Tarayıcı zaman aşımından kaçınmaya yardımcı performans ve sunucu yanıtları
- Atıfı destekleyen güven sinyalleri (yazarlar, tarihler, kaynaklar, sahiplik)
- Botların gerçekte ne gördüğünü doğrulamak için test rutinleri
Hızla yeni sayfalar ve akışlar oluşturuyorsanız, bu gereksinimlerle çatışmayan araçları seçmek faydalıdır. Örneğin Koder.ai kullanan ekipler (React ön yüzleri ve Go/PostgreSQL arka uçları oluşturan sohbet odaklı bir platform) genellikle SSR/SSG dostu şablonları, sabit yönleri ve tutarlı meta verileri erken aşamada yapılandırırlar—böylece “AI-uyumlu” olmak bir düzeltme değil varsayılan haline gelir.
LLM’lerin Kolayca Ayrıştırabileceği İçerik Yapısı
LLM’ler ve AI tarayıcılar bir sayfayı insan gibi yorumlamazlar. Metni çıkarır, fikirler arasındaki ilişkileri çıkarır ve sayfanızı tek, net bir amaçla eşlemeye çalışırlar. Yapınız ne kadar öngörülebilirse, yanlış varsayımlar o kadar azalır.
“İdeal” bir sayfa nasıl görünür
Sayfayı düz metinde hızlıca taranabilir hale getirin:
- Sayfanın ana vaadini karşılayan net bir H1
- Açıklayıcı başlıklara sahip kısa bölümler
- Ana anlatıyı bölen gereksiz yan çubuk gürültüsünden ve fazla “yüzen” çağrıdan kaçının
Kullanışlı bir desen: vaat → özet → açıklama → kanıt → sonraki adımlar.
Hızlı anlamak için bir TL;DR ekleyin
Üst kısma kısa bir özet (2–5 satır) yerleştirin. Bu, AI sistemlerinin sayfayı hızla sınıflandırmasına ve ana iddiaları yakalamasına yardımcı olur.
Örnek TL;DR:
TL;DR: Bu sayfa, AI tarayıcılarının ana konuyu, tanımları ve kilit çıkarımları güvenilir şekilde çıkarması için içeriğin nasıl yapılandırılacağını açıklar.
Sayfa başına birincil konu tutun
LLM dizinleme, her URL’nin tek bir niyete yanıt verdiği durumlarda en iyi çalışır. Farklı amaçları karıştırırsanız (ör. “fiyatlandırma”, “entegrasyon dokümanları” ve “şirket geçmişi”ni aynı sayfada bulundurmak), sayfa kategorize edilmesi zorlaşır ve yanlış sorgular için yüzeye çıkabilir.
İlgili ama farklı niyetleri kapsamanız gerekiyorsa, bunları ayrı sayfalara bölün ve iç bağlantılarla bağlayın (ör. /pricing, /docs/integrations).
Belirsiz terimleri tanımlayın ve bağlam ekleyin
Kitle bir terimi birden fazla şekilde yorumlayabiliyorsa, erken tanımlayın.
Örnek:
AI tarayıcı optimizasyonu: site içeriğini ve erişim kurallarını otomatik sistemlerin sayfaları güvenilir şekilde keşfedip, okuyup yorumlayabilmesi için hazırlama.
Varlık adlandırmasında tutarlılık sağlayın
Her ürün, özellik, plan ve ana kavram için tek bir ad seçin ve her yerde o adı kullanın. Tutarlılık çıkarımı iyileştirir (“Özellik X” her zaman aynı şeyi ifade eder) ve modeller özetlerken veya sayfaları karşlaştırırken varlık karışıklığını azaltır.
Başlıklar, Listeler ve Tablolar: Sayfaları Parçaya Uygun Hale Getirin
Çoğu AI dizinleme hattı sayfaları parçalara ayırır ve daha sonra en uygun parçaları depolayıp getirir. Sizin işiniz, bu parçaları belirgin, kendi başına anlaşılır ve alıntılanması kolay yapmak.
Net bir H1–H3 hiyerarşisi kullanın
Sayfa başına bir H1 (sayfanın vaadi), ardından aranabilecek ana bölümler için H2ler ve alt konular için H3ler kullanın.
Basit bir kural: H2’lerinizi sayfanın tam içeriğini tanımlayan bir içindekiler tablosuna dönüştürebiliyorsanız doğru yoldasınız. Bu yapı retrieval sistemlerinin uygun bağlamı parçaya eklemesine yardımcı olur.
Başlıkları kendi başına anlaşılır yazın
“Overview” veya “Daha fazla bilgi” gibi belirsiz etiketlerden kaçının. Bunun yerine, başlıklar kullanıcı niyetine yanıt vermeli:
- “Fiyatlandırma ve nelerin dahil olduğu”
- “Desteklenen dosya formatları ve boyut sınırları”
- “Kurulum ne kadar sürer (tipik zaman çizelgeleri)”
Bir parça bağlam dışına çıkarıldığında başlık çoğunlukla onun “başlığı” olur. Anlamlı yapın.
Kısa paragrafları, listeleri ve tabloları tercih edin
Okunabilirlik ve parçaların odaklı olması için 1–3 cümlelik kısa paragraflar kullanın.
Gereksinimler, adımlar ve özellik vurguları için madde listeleri iyi iş görür. Karşılaştırmalar için tablolar yapıyı korudukları için mükemmeldir.
| Plan | En uygun olan | Temel limit |
|---|
| Başlangıç | Denemek için | 1 proje |
| Ekip | İş birliği | 10 proje |
Doğrudan yanıtlar için SSS ekleyin
Kısa, net ve tamamlayıcı cevaplara sahip küçük bir SSS bölümü çıkarılabilirliği artırır:
S: CSV yüklemelerini destekliyor musunuz?
C: Evet—dosya başına 50 MB’a kadar CSV.
“Sonraki adımlar” ve “İlgili okumalar” ekleyin
Kilit sayfaları hem kullanıcıların hem de tarayıcıların niyet tabanlı yolları takip edebilmesi için gezinme bloklarıyla kapatın:
- Sonraki adımlar: /pricing, /signup
- İlgili okumalar: /blog/technical-seo-for-ai, /docs/sitemaps
Render: İçeriğin JavaScript Olmadan Var Olduğundan Emin Olun
AI tarayıcıları hepsi tam bir tarayıcı gibi davranmaz. Birçoğu ham HTML’yi hemen alıp okuyabilir, ancak JavaScript çalıştırma, API çağrılarını bekleme ve sayfayı hydration sonrası oluşturma işlerinde zorlanır (veya bunları atlayabilir). Eğer ana içerik yalnızca istemci tarafı render’dan sonra görünüyorsa, LLM dizinleme yapan sistemlerin sizi “görmezden gelme” riski vardır.
HTML tarama vs. JavaScript ile render edilen sayfalar
Geleneksel bir HTML sayfasında, tarayıcı belgeyi indirir ve başlıkları, paragrafları, bağlantıları ve meta verileri hemen çıkarabilir.
JS ağırlıklı bir sayfada ilk yanıt ince bir kabuk olabilir (birkaç div ve script). Anlamlı metin ancak scriptler çalışıp veriler yüklendiğinde görünür. Bu ikinci adımda kapsama düşer: bazı tarayıcılar script çalıştırmaz; bazıları ise zaman aşımı veya kısmi destekle çalıştırır.
Kritik içerik için sunucu tarafı render (veya hibrit) tercih edin
İndekslenmesini istediğiniz sayfalar—ürün açıklamaları, fiyatlandırma, SSS, dokümanlar—için şunları tercih edin:
- Sunucu Taraflı Render (SSR): içerik ilk HTML yanıtında yer alır
- Statik üreteç (SSG/ISR): önceden oluşturulmuş HTML, periyodik yenilemelerle
- Hibrit render: ana içeriği sunucu tarafında render edin, etkileşim için JS ekleyin
Amaç “JavaScript yok” değil; amaç önce anlamlı HTML, sonra JS.
Önemli metni “görünmez” UI’nin arkasına saklamayın
Sekmeler, akordiyonlar ve “daha fazlasını oku” kontrolleri DOM içinde ise sorun yoktur. Sorun, sekme içeriğinin yalnızca tıklamadan sonra getirilmesi veya istemci tarafı isteğiyle enjekte edilmesidir. Keşif için önemli olan içerikse, ilk HTML’de yer verin ve görünürlüğü kontrol etmek için CSS/ARIA kullanın.
Render boşluklarını tespit etmek için hızlı testler
Aşağıdaki iki kontrolü kullanın:
- View Source: sunucunun teslim ettiği HTML’i gösterir (birçok tarayıcının gördüğü)
- Inspect Element: JS sonrası DOM’u gösterir (gerçek tarayıcının ulaştığı)
Başlıklarınız, ana kopyanız, dahili bağlantılarınız veya SSS cevaplarınız yalnızca Inspect Element’te görünüyorsa, bu bir render riski olarak ele alınmalı ve o içerik sunucu tarafından render edilen çıktıya taşınmalıdır.
AI tarayıcılar ve geleneksel arama botları her ikisi de net, tutarlı erişim kurallarına ihtiyaç duyar. Önemli içeriği yanlışlıkla engellerseniz veya tarayıcıları özel veya “dağınık” alanlara izin verirseniz, tarama bütçeniz boşa harcanır ve indekslenen içerik kirlene bilir.
robots.txt: site genelinde trafik kontrolü
robots.txt geniş kurallar için kullanılır: hangi klasörlerin veya URL desenlerinin taranıp taranmaması gerektiği.
Pratik bir temel:
- Allow/Disallow:
/admin/, /account/, dahili arama sonuçları veya sonsuz kombinasyonlar üreten parametre içeren URL’leri engelleyin.
- Crawl-delay: yalnızca sunucunuz bot trafiğiyle mücadele ediyorsa ekleyin. Birçok büyük bot bunu göz ardı eder, bu yüzden ana hız kontrolü olarak buna güvenmeyin.
- Sitemap directive: tarayıcıları kanonik sitemap konumunuza yönlendirin ki keşif tahmin edilebilir olsun.
Örnek:
User-agent: *
Disallow: /admin/
Disallow: /account/
Disallow: /internal-search/
Sitemap: /sitemap.xml
Önemli: robots.txt ile engellemek taramayı engeller, ancak bir URL başka yerden referans gösteriliyorsa indekslerde görünmesini her zaman engellemez. İndeks kontrolü için sayfa düzeyinde yönergeler kullanın.
HTML sayfalarında meta name="robots" kullanın ve HTML olmayan dosyalar (PDF’ler, feed’ler, oluşturulmuş çıktılar) için X-Robots-Tag başlıklarını tercih edin.
Yaygın desenler:
- İnce veya yardımcı sayfalar (filtreler, sıralama varyantları, yazdırma görünümleri):
noindex,follow ki bağlantılar geçsin ama sayfa indekslenmesin.
- Gizli veya hassas alanlar: sadece
noindex’e güvenmeyin—kimlik doğrulama ile koruyun ve ayrıca taramayı engellemeyi düşünün.
- Çoğaltma versiyonları (ör. önizleme URL’leri):
noindex artı uygun canonicalizasyon.
Ortamlar için basit bir kural seti (prod vs. staging)
Kuralları her ortam için belgeleyin ve uygulayın:
- Prodüksiyon: varsayılan olarak taranabilir; yalnızca açıkça özel veya düşük değerli alanları engelleyin.
- Staging/preview: giriş gerektirsin; kazara indekslemeyi önlemek için global
noindex ekleyin (başlık tabanlı en kolay yöntem).
Erişim kontrolleriniz kullanıcı verilerini etkiliyorsa, kullanıcıya yönelik politika ile gerçek durumun eşleştiğinden emin olun (ilgili olduğunda /privacy ve /terms sayfalarını kontrol edin).
Canonical URL’ler, Çoğaltmalar ve Yönlendirme Hijyeni
SEO temelini tamamen kontrol altında tutun
Kaynağın sahibi olun ki robots kurallarını, canonicals ve durum kodlarını kendi istediğiniz gibi uygulayabilesiniz.
AI sistemlerinin ve arama tarayıcılarının sayfalarınızı güvenilir şekilde anlamasını istiyorsanız, “aynı içerik birden fazla URL” durumlarını azaltmalısınız. Çoğaltmalar tarama bütçesini boşa harcar, sinyalleri böler ve yanlış sürümün indekslenmesine veya referans verilmesine neden olabilir.
Temiz, stabil URL’ler oluşturun
Yıllarca geçerli kalacak URL’ler hedefleyin. Oturum kimlikleri, sıralama seçenekleri veya izleme kodları gibi gereksiz parametreleri indekslenebilir URL’lere dahil etmeyin (?utm_source=..., ?sort=price, ?ref= gibi). Eğer filtreler, sayfalama veya iç arama gibi işlevsellik için parametreler gerekiyorsa, “ana” versiyonun stabil, temiz bir URL’de de erişilebilir olduğundan emin olun.
Stabil URL’ler uzun vadeli atıfları iyileştirir: bir LLM bir referansı öğrendiğinde veya depoladığında, URL yapınız her yeniden tasarımda değişmiyorsa aynı sayfaya işaret etme olasılığı çok daha yüksektir.
Kopyaları çökertmek için canonical etiketleri kullanın
Çoğaltmaların beklendiği sayfalarda bir link rel="canonical" ekleyin:
- İçeriklerin çoğunu paylaşan ürün varyantları
- Filtrelenmiş kategori görünümleri
- İzleme parametreli versiyonlar
Canonical etiketleri tercih edilen, indekslenebilir URL’ye işaret etmeli (ve ideal olarak o canonical URL 200 döndürmelidir).
Yönlendirme hijyeni: basit ve öngörülebilir tutun
Bir sayfa kalıcı olarak taşındığında 301 yönlendirmesi kullanın. Yönlendirme zincirlerinden (A → B → C) ve döngülerden kaçının; bunlar tarayıcıları yavaşlatır ve kısmi indekslemelere yol açabilir. Eski URL’leri doğrudan nihai hedefe yönlendirin ve yönlendirmeleri HTTP/HTTPS ve www/non-www arasında tutarlı tutun.
hreflang’ı yalnızca gerçek eşdeğerler için kullanın
hreflang yalnızca gerçekten yerelleştirilmiş eşdeğerleriniz olduğunda uygulanmalı (sadece tercüme parçaları değil). Yanlış hreflang hangi sayfanın hangi kitle için alıntılanması gerektiği konusunda kafa karışıklığı yaratabilir.
Sitemapler ve Dahili Bağlantılar ile Güvenilir Keşif
Sitemapler ve dahili bağlantılar keşif için “teslimat sisteminiz”dir: tarayıcılara neyin olduğunu, neyin önemli olduğunu ve neyin görmezden gelinmesi gerektiğini söyler. AI tarayıcıları ve LLM dizinleme için hedef basit—en iyi, temiz URL’lerinizi bulmayı kolay ve kaçırmayı zor hale getirin.
Yalnızca doğru URL’leri listeleyen XML sitemapler oluşturun
Sitemapiniz sadece indekslenebilir, canonical URL’leri içermelidir. Bir sayfa robots.txt ile engellenmişse, noindex olarak işaretlenmişse, yönlendirme yapıyorsa veya canonical olmayan bir versiyon ise sitemap’te yer almamalıdır. Bu, tarama bütçesini odaklar ve bir LLM’in kopya veya güncelliğini yitirmiş bir versiyonu almasını azaltır.
URL formatlarında tutarlılık sağlayın (trailing slash, küçük harf, HTTPS) ki sitemap canonical kurallarınızı yansıtsın.
Büyük sitemapleri bölün ve bir sitemap index kullanın
Çok sayıda URL’niz varsa, sitemapleri birden fazla dosyaya bölün (yaygın limit: dosya başına 50.000 URL) ve her sitemap’i listeleyen bir sitemap index yayınlayın. İçerik türüne göre organize etmek bakım kolaylığı sağlar, ör.:
/sitemaps/pages.xml/sitemaps/blog.xml/sitemaps/docs.xml
Bu, bakımı kolaylaştırır ve hangi sayfaların keşfedildiğini izlemenize yardımcı olur.
lastmodu güven sinyali olarak kullanın, deploy zaman damgası olarak değil
lastmodu anlamlı şekilde değiştiğinde güncelleyin (içerik, fiyatlandırma, politika veya ana meta veriler değiştiğinde). Eğer her deploy’da tüm URL’ler güncellenirse, tarayıcılar bu alanı yoksaymayı öğrenir ve gerçekten önemli güncellemeler gecikebilir.
Dahili bağlantılar: sitenizi bir harita gibi gezilebilir yapın
Güçlü bir hub-and-spoke yapısı hem kullanıcılar hem de makineler için faydalıdır. En önemli “spoke” sayfalara bağlanan hub’lar (kategori, ürün veya konu sayfaları) oluşturun ve her spoke hub’a geri bağlansın. Menülerde değil, içerikte bağlamsal bağlantılar ekleyin.
Eğitim içerikleri yayıyorsanız, ana giriş noktalarınızı açık tutun—makaleler için /blog, daha derin referans materyali için /docs gibi.
Yapılandırılmış Veri: Sayfalarınızı Makinelerin Anlaması İçin Etiketleyin
Staging'i üretimden ayırın
Gerekli yerlerde global noindex dahil olmak üzere temiz üretim ve staging varsayımları kurun.
Yapılandırılmış veri, bir sayfanın ne olduğunu (makale, ürün, SSS, organizasyon) makinenin okunabilir biçimde etiketlemenin yoludur. Arama motorları ve bazı AI sistemleri hangi metnin başlık olduğunu, kimin yazdığını veya ana varlığın ne olduğunu tahmin etmek zorunda kalmaz—doğrudan ayrıştırabilirler.
Doğru Schema.org tipini seçin
İçeriğinize uygun Schema.org tiplerini kullanın:
- Article (blog yazıları, rehberler)
- FAQPage (soru/cevap bölümleri)
- HowTo (adım adım talimatlar)
- Product (fiyatlandırma sayfaları, ürün detay sayfaları)
- Organization (şirket kimliği)
Her sayfa için bir birincil tip seçin, sonra destekleyici özellikler ekleyin (örneğin bir Article bir Organization’ı yayıncı olarak referans gösterebilir).
İşaretlemeyi kullanıcıların gördüğüyle hizalayın
AI tarayıcıları ve arama motorları yapılandırılmış veriyi görünen sayfayla karşılaştırır. Eğer işaretleme sayfada olmayan bir SSS iddia ediyorsa ya da gösterilmeyen bir yazar adı listeleniyorsa, karışıklık yaratır ve işaretlemenin göz ardı edilmesine yol açabilir.
İçerik sayfalarında author, ayrıca gerçekse datePublished ve dateModified ekleyin. Bu, tazelik ve hesap verebilirliği (LLM’lerin güven değerlendirmesinde sık baktığı iki unsur) netleştirir.
Eğer resmi profilleriniz varsa, Organization schema’sına sameAs bağlantıları ekleyin (ör. şirketinizin doğrulanmış sosyal profilleri).
Örnek: Article JSON-LD
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Build a Website Ready for AI Crawlers and LLM Indexing",
"author": { "@type": "Person", "name": "Jane Doe" },
"datePublished": "2025-01-10",
"dateModified": "2025-02-02",
"publisher": {
"@type": "Organization",
"name": "Acme",
"sameAs": ["https://www.linkedin.com/company/acme"]
}
}
Son olarak, yaygın test araçlarıyla doğrulayın (Google’ın Rich Results Test, Schema Markup Validator). Hataları düzeltin ve uyarıları pragmatik olarak ele alın: seçtiğiniz tipe ve ana özelliklere (başlık, yazar, tarihler, ürün bilgisi) bağlı uyarıları önceliklendirin.
llms.txt: LLM Odaklı Keşif İçin Basit Bir Rehber
Bir llms.txt dosyası, dil modeli odaklı tarayıcılara (ve onları yapılandıran insanlara) sitenizin en önemli giriş noktalarını işaret eden küçük, insan tarafından okunabilir bir “kart”tır: dokümanlarınız, ana ürün sayfalarınız ve terminolojinizi açıklayan referans materyalleri.
Bu, tüm tarayıcılar için garantili davranışa sahip bir standart değildir ve sitemap, canonical ya da robots kontrollerinin yerine kullanılmamalıdır. Keşif için yardımcı bir kestirme olarak düşünün.
Nereye yerleştirmeli
Kök dizine koyun ki kolayca bulunabilsin:
Bu robots.txt ile aynı fikir: tahmin edilebilir konum, hızlı fetch.
Ne dahil edilmeli (ve kaçınılmalı)
Kısa ve kürate edilmiş tutun. İyi adaylar:
- Ana giriş noktaları: ürün genel bakışı, fiyatlandırma, başlarken rehberi
- Dokümantasyon merkezleri: docs ana sayfası, API referansı, SDK rehberleri, eğitimler
- Sözlük / terminoloji: alan terimlerinizi ve tercih ettiğiniz adlandırmaları tanımlayan sayfa
- Yeniden kullanım politikaları: lisanslama, atıf beklentileri, veri kullanımı notları
Ayrıca kısa stil notları eklemeyi düşünün (ör. “UI’da müşterilere ‘workspace’ diyoruz”). Uzun pazarlama metinleri, tam URL dökümleri veya canonical URL’lerle çelişebilecek içeriklerden kaçının.
Basit bir örnek:
# llms.txt
# Purpose: curated entry points for understanding and navigating this site.
## Key pages
- / (Homepage)
- /pricing
- /docs
- /docs/getting-started
- /docs/api
- /blog
## Terminology and style
- Prefer “workspace” over “account”.
- Product name is “Acme Cloud” (capitalized).
- API objects: “Project”, “User”, “Token”.
## Policies
- /terms
- /privacy
Sitemapler ve canonical’lar ile hizalı tutun
Tutarlılık hacminden daha önemlidir:
- Sadece keşfedilmesini ve alıntılanmasını istediğiniz URL’leri listeleyin.\n- Listelenen sayfaların 200 döndüğünden ve doğru canonicala sahip olduğundan emin olun.\n- Bir sayfa değiştirildiğinde yönlendirmeye güvenmek yerine bağlantıyı güncelleyin.\n- robots.txt ile engellenen URL’leri dahil etmeyin (karışık sinyaller oluşturur).
Hafif bakım süreci (çeyreklik)
Yönetilebilir bir rutin:
- Çeyreklik gözden geçirme (15 dakika):
llms.txt içindeki her bağlantıya tıklayın ve hâlâ en iyi giriş noktası olup olmadığını doğrulayın.
- Büyük sürümlerin ardından: navigasyonu yeniden yapılandırdığınızda doküman merkezlerini ekleyin/kaldırın.
- Mevcut kontrollerle ilişkilendirin: sitemap veya canonical’ları güncellediğinizde
llms.txtu da güncelleyin.
İyi yapıldığında, llms.txt küçük, doğru ve gerçekten faydalı kalır—herhangi bir tarayıcının nasıl davranacağını garanti etmeden.
Tarayıcılar (AI odaklı olanlar dahil) sabırsız kullanıcılar gibi davranır: siteniz yavaş veya kararsızsa daha az sayfa alırlar, daha az yeniden denerler ve indekslerini daha seyrek güncellerler. İyi performans ve güvenilir sunucu yanıtları, içeriğinizin keşfedilme, yeniden taranma ve güncel tutulma olasılığını artırır.
Hız ve kullanılabilirlik: tarayıcıların “hissettiği” şey
Sunucunuz sık sık zaman aşımına uğruyor veya hata veriyorsa, bir tarayıcı otomatik olarak geri çekilebilir. Bu, yeni sayfaların daha geç görünmesine ve güncellemelerin hızlı yansımamasına neden olabilir.
Sadece laboratuvar skorları değil, yoğun saatlerde de tutarlı kullanılabilirlik ve öngörülebilir yanıt süreleri hedefleyin.
TTFB’yi iyileştirin ve payload’u azaltın
Time to First Byte (TTFB) sunucu sağlığının güçlü bir göstergesidir. Yüksek etkili birkaç düzeltme:
- Genel sayfalar için CDN önbellekleme kullanın ve mümkünse origin cache’i etkinleştirin.
- HTML, CSS ve JavaScript için sıkıştırmayı (Brotli veya gzip) açın.
- HTML’i hafif tutun: büyük inline scriptler veya aşırı izleme etiketleri göndermekten kaçının.
- Görselleri yeniden boyutlandırın ve sıkıştırın, böylece sayfaların anlamlı içerik için büyük indirmelere ihtiyacı kalmasın.
Crawlers görüntüleri insanlar gibi “görmese” bile büyük dosyalar tarama süresini ve bant genişliğini boşa harcar.
Doğru HTTP durum kodlarını döndürün
Tarayıcılar hangi sayfaları saklayıp hangilerini atacaklarına durum kodlarına göre karar verir:
- 200 geçerli içerik sayfaları için.\n- 301 kalıcı taşınmalar için (yönlendirme zincirlerini kısa tutun).\n- 404 bir sayfa yoksa.\n- 410 bir sayfa kasıtlı olarak kaldırıldıysa ve daha hızlı düşmesi isteniyorsa.\n- 5xx hatalarını dikkatle yönetin: kök nedenleri çabucak düzeltin ve yalnızca doğru hata kodunu döndüren hafif bir yedek sayfa düşünün.
Ana içeriği oturum arkasına saklamayın
Eğer ana makale metni kimlik doğrulama gerektiriyorsa, birçok tarayıcı yalnızca kabuğu indeksler. Ana okuma erişimini herkese açık tutun veya temel içeriği içeren taranabilir bir önizleme sağlayın.
Meşru taramaları engellemeden hız sınırlama
Sitenizi kötüye kullanımdan koruyun fakat kaba engellemeden kaçının. Tercihler:
- Makul patlamalara izin veren token-bucket hız sınırlamaları\n- Bilinen tarayıcı IP aralıkları için beyaz liste (mümkünse)\n-
Retry-After başlığı ile birlikte net 429 yanıtları
Bu, sitenizi korurken sorumlu tarayıcıların işini yapmasına izin verir.
Güven Sinyalleri: Kaynaklar, Yazarlar ve Net Sahiplik
AI SEO değişikliklerinizi planlayın
Kod ve şablon üretmeden önce SSR, robots ve schema görevlerinizi planlayın.
“E‑E‑A‑T” büyük iddialar ya da gösterişli rozetler gerektirmez. AI tarayıcıları ve LLM’ler için bu çoğunlukla kimin bir şeyi yazdığının, gerçeklerin nereden geldiğinin ve kimin bunun sorumluluğunu taşıdığının açık olması demektir.
Kaynak göstermeyi açık (ve doğrulanabilir) yapın
Bir iddia sunduğunuzda, kaynağı iddiaya mümkün olduğunca yakın iliştirin. Birincil ve resmi referansları (yasalar, standart kurumları, satıcı dokümanları, hakemli makaleler) ikinci el özetlere tercih edin.
Örneğin, yapılandırılmış veri davranışından bahsediyorsanız Google dokümantasyonunu (“Google Search Central — Structured Data”) ve gerektiğinde schema tanımlarını (“Schema.org vocabulary”) referans gösterin. Robots yönergelerinden bahsediyorsanız ilgili standartları ve resmi tarayıcı dokümanlarını (ör. “RFC 9309: Robots Exclusion Protocol”) belirtin. Her bahiste dış bağlantı vermeseniz bile, okuyucunun ilgili belgeyi bulabileceği kadar ayrıntı verin.
Yazar atamasını ve editoryal sahipliği gösterin
Bir yazar satırı, kısa biyografi, yetkinlikler ve yazarın sorumlulukları ile atıf ekleyin. Ardından sahipliği açıkça belirtin:
- Footer’da net bir site sahibi (şirket/kurumsal varlık)
- Gerçek kanalları olan bir iletişim sayfası (sadece form değil)
- Misyonunuzu ve editoryal sürecinizi açıklayan bir Hakkımızda sayfası (bkz. /about)
İddiaları spesifik tutun—ve delilleri saklayın
“En iyi” ve “garantili” gibi ifadelerden kaçının. Bunun yerine neyi test ettiğinizi, neyin değiştiğini ve sınırların ne olduğunu açıklayın. Ana sayfaların üstünde veya altında güncelleme notları ekleyin (ör. “Güncellendi 2025‑12‑10: yönlendirmeler için canonical davranışı netleştirildi”). Bu, insanlar ve makineler tarafından yorumlanabilen bir bakım izi oluşturur.
Tutarlı bir sözlük sürdürün
Temel terimlerinizi bir kez tanımlayın, sonra site genelinde tutarlı kullanın (ör. “AI tarayıcı”, “LLM dizinleme”, “rendered HTML”). Hafif bir sözlük sayfası (örn. /glossary) belirsizliği azaltır ve içeriğinizin daha doğru özetlenmesini kolaylaştırır.
Test, İzleme ve Sürekli İyileştirme
AI-uyumlu bir site tek seferlik bir proje değildir. CMS güncellemesi, yeni bir yönlendirme ya da yeniden tasarım gibi küçük değişiklikler keşif ve indekslemeyi sessizce bozabilir. Basit bir test rutini, görünürlük veya trafik değişikliklerinde tahmin yürütmeyi önler.
Keşif problemlerini gösteren sinyalleri izleyin
Temelden başlayın: tarama hatalarını, indeks kapsamını ve en çok bağlantı alan sayfalarınızı takip edin. Eğer tarayıcılar ana URL’leri fetch edemiyorsa (zaman aşımı, 404, engellenen kaynaklar), LLM dizinleme hızla bozulma eğilimi gösterir.
Ayrıca izleyin:
- İndeks kapsamından aniden düşen sayfalar\n- Dahili bağlantı almayı bırakan önemli URL’ler\n- Beklenmedik şekilde artan “çoğaltılmış” veya “hariç tutulmuş” sayfalar
Yayınları bir güvenilirlik mühendisi gibi kontrol edin
Sürüm sonrası (küçük dahi olsa) şu değişiklikleri inceleyin:
- Yönlendirmeler: eski URL’ler kullanıcıları ve botları doğru yere gönderiyor mu?\n- Canonicals: şablonlar değişti mi ve canonical’lar yanlış yere mi işaret ediyor?\n- Sitemapler: hâlâ geçerli, güncel ve hatalı URL içermiyor mu?
15 dakikalık bir sürüm sonrası denetim, sorunları uzun vadeli görünürlük kaybına dönüşmeden önce yakalayabilir.
Sayfalarınızın nasıl özetlendiğini test edin
Birkaç yüksek değerli sayfayı seçin ve AI araçları veya dahili özetleme scriptleri ile nasıl özetlendiklerini test edin. Bakılacaklar:
- Eksik tanımlar ("bu nedir?" cümlesi net değil mi)
- Başlıklar sayfanın gerçek bölümleriyle uyuşmuyor mu
- Önemli detaylar uzun paragrafların içinde başlıksız gömülü kalmış mı
Özetler belirsizse, düzeltme genellikle editoryal olur: daha güçlü H2/H3 başlıkları, daha net ilk paragraflar ve daha açık terimler.
Periyodik bir “AI hazır olma” kontrol listesi oluşturun
Öğrendiklerinizi periyodik bir kontrol listesine dönüştürün ve bir sorumlu atayın (gerçek bir isim, “pazarlama” değil). Canlı ve uygulanabilir tutun—sonra en son sürümü dahili olarak herkesin erişebileceği bir yerde paylaşın ki tüm ekip aynı playbook’u kullansın. /blog/ai-seo-checklist gibi hafif bir referans yayınlayın ve site ile araçlar geliştikçe güncelleyin.
Hızla teslimat yapan bir ekipseniz (özellikle AI destekli geliştirme ile), “AI hazır olma” kontrollerini doğrudan build/yayın iş akışınıza eklemeyi düşünün: her zaman canonical etiketleri, tutarlı yazar/tarih alanları ve sunucu tarafından render edilen ana içerik üreten şablonlar. Koder.ai gibi platformlar burada yardımcı olabilir—bu varsayılanları yeni React sayfaları ve uygulama yüzeyleri boyunca tekrarlanabilir kılar ve planlama modu, snapshot ve geri alma ile değişikliklerin taranabilirliği etkilemesi durumunda geri almayı kolaylaştırır.
Küçük, istikrarlı iyileştirmeler bile birleşir: daha az tarama hatası, daha temiz indeksleme ve insanların ve makinelerin anlaması daha kolay içerik.