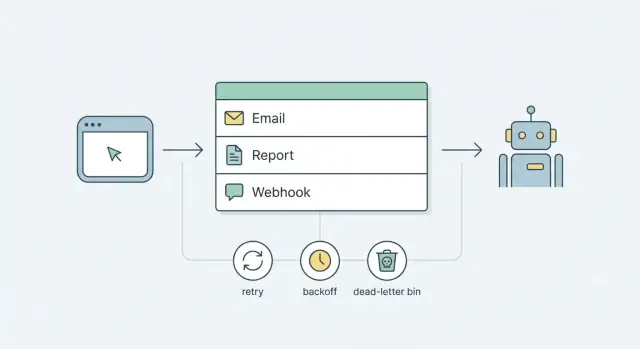
Arka plan işlerine neden ihtiyacınız var (ve neden hızla karmaşıklaşır)
Bir kullanıcı isteği içinde bir veya iki saniyeden uzun sürebilecek işler çalıştırılmamalıdır. E-posta gönderme, rapor oluşturma ve webhook teslimatı ağlara, üçüncü taraf servislere veya yavaş sorgulara bağlıdır. Bazen dururlar, başarısız olurlar veya beklenenden daha uzun sürerler.
Bu işleri kullanıcı beklerken yaparsanız, insanlar hemen fark eder. Sayfalar takılır, "Kaydet" butonları döner ve istekler zaman aşımına uğrar. Yeniden denemeler yanlış yerde de tetiklenebilir: kullanıcı sayfayı yeniler, load balancer yeniden dener veya frontend yeniden gönderir ve sonunda aynı e-postadan, tekrarlayan webhook çağrısından veya birbirleriyle yarışan iki rapor çalışmasından oluşan çoğaltmalar elde edersiniz.
Arka plan işler, istekleri küçük ve öngörülebilir tutarak bunu çözer: eylemi kabul edin, yapılacak işi kaydedin, hızlıca yanıt verin. İş, isteğin dışında, sizin kontrol ettiğiniz kurallarla çalışır.
Zor kısım güvenilirliktir. İş isteğin yolundan çıktığında hâlâ şu sorulara cevap vermeniz gerekir:
- E-posta sağlayıcısı 3 dakika boyunca kapalıysa ne olur?
- Bir webhook endpoint 500 döndürürse veya zaman aşımına uğrarsa?
- İş iki kez çalışırsa ne olur?
- Kullanıcı şikayet etmeden önce takılı işleri nasıl fark edersiniz?
Birçok ekip bu sorulara "ağır altyapı" ekleyerek yanıt verir: bir message broker, ayrı worker filoları, panolar, uyarılar ve playbooklar. Bu araçlar gerçekten gerektiğinde faydalıdır, ancak yeni hareketli parçalar ve yeni arıza modları da getirirler.
Daha iyi bir başlangıç hedefi daha basittir: zaten sahip olduğunuz parçaları kullanarak güvenilir işler. Çoğu ürün için bu, veritabanı destekli bir kuyruk artı küçük bir worker sürecidir. Açık bir yeniden deneme ve geri çekilme stratejisi ile sürekli başarısız olan işler için bir dead-letter deseni ekleyin. Böylece ilk günden karmaşık bir platforma bağlı kalmadan öngörülebilir davranış elde edersiniz.
Hızlı prototipler yaparken bile (örneğin Koder.ai gibi araçlarla) bu ayrım önemlidir. Kullanıcılar şimdi hızlı bir yanıt almalı ve sisteminiz yavaş, başarısızlığa meyilli işleri güvenli şekilde arka planda tamamlamalı.
Kuyruk basitçe ne demektir
Kuyruk, işlerin beklediği bir bekleme hattıdır. Yavaş veya güvenilmez görevleri bir kullanıcı isteği sırasında yapmak yerine (e-posta gönderme, rapor oluşturma, webhook çağırma), küçük bir kayıt kuyruğa koyup hızlıca dönersiniz. Daha sonra ayrı bir süreç bu kaydı alıp işi yapar.
Sıkça göreceğiniz birkaç terim:
- İş (Job): "kullanıcı 123'e karşılama e-postası gönder" gibi bir iş birimi.
- Worker: işleri çekip çalıştıran kod.
- Deneme (Attempt): bir işi çalıştırma girişimi.
- Zamanlama (Schedule): işin ne zaman çalışacağı (şimdi veya sonra).
- Kuyruk: işlerin worker alana kadar beklediği yer.
En basit akış şöyle görünür:
-
Enqueue: uygulamanız bir iş kaydı kaydeder (tip, payload, çalışma zamanı).
-
Claim: bir worker sıradaki uygun işi bulur ve sadece bir worker'ın çalıştırması için onu "kilitler".
-
Run: worker görevi gerçekleştirir (gönder, oluştur, teslim et).
-
Finish: işi tamamlandı olarak işaretle, veya bir hata kaydet ve bir sonraki çalışma zamanını ayarla.
İş hacminiz mütevazıysa ve zaten bir veritabanınız varsa, veritabanı destekli kuyruk genellikle yeterlidir. Anlaşılması kolaydır, hata ayıklaması basittir ve e-posta işleme ile webhook teslim güvenilirliği gibi yaygın ihtiyaçlara uyar.
Streaming platformları, çok yüksek throughput, çok sayıda bağımsız tüketici veya büyük olay geçmişlerini birçok sistemde yeniden oynatma ihtiyacı olduğunda anlamlı hale gelir. Onlarca servisi saatte milyonlarca olayla çalıştırıyorsanız Kafka gibi araçlar yardımcı olur. O zamana kadar bir veritabanı tablosu artı worker döngüsü birçok gerçek dünya kuyruğunu karşılar.
Her iş için takip etmeniz gereken asgari veriler
Bir veritabanı kuyruğu, her iş kaydının üç soruyu hızlıca yanıtlaması sayesinde düzenli kalır: ne yapılacak, bir sonraki deneme ne zaman ve son sefer ne oldu. Bunu doğru yapın, operasyon sıkıcı olur (hedef budur).
Payload içinde ne saklanmalı (ve ne saklanmamalı)
İşi yapmak için gereken en küçük girdiyi saklayın, tüm render edilmiş çıktıyı değil. İyi payload'lar ID'ler ve birkaç parametreden oluşur, örneğin { "user_id": 42, "template": "welcome" }.
Büyük blob'ları saklamaktan kaçının (tam HTML e-postalar, büyük rapor verileri, devasa webhook gövdeleri). Bu veritabanınızı hızlı büyütür ve hata ayıklamayı zorlaştırır. Eğer iş büyük bir belgeye ihtiyaç duyuyorsa, bunun yerine bir referans saklayın: report_id, export_id veya bir dosya anahtarı. Worker çalışırken tam veriyi alabilir.
Kendini amorti eden alanlar
Minimum olarak şu alanlara yer açın:
- job_type + payload:
job_type handler'ı seçer (send_email, generate_report, deliver_webhook). payload ID'ler ve seçenekler gibi küçük girdileri tutar.
- status: açıkça tutun (örneğin:
queued, running, succeeded, failed, dead).
- deneme takibi:
attempt_count ve max_attempts böylece açıkça işe yaramadığında yeniden denemeyi durdurabilirsiniz.
- zaman alanları:
created_at ve next_run_at (ne zaman uygun olacağı). Daha iyi görünürlük isterseniz started_at ve finished_at ekleyin.
- idempotency + son hata: çift etkileri önlemek için bir
idempotency_key ve neden başarısız olduğunu loglarda aramadan görmeniz için last_error.
Idempotency kulağa karmaşık gelebilir, ama fikir basit: aynı iş iki kez çalışırsa ikinci çalıştırma tehlikeli bir şey yapmamalıdır. Örneğin webhook teslim işi webhook:order:123:event:paid gibi bir idempotency anahtarı kullanabilir, böylece bir yeniden deneme zaman aşımı ile çakışsa aynı olayı iki kez teslim etmezsiniz.
Ayrıca başlangıçta birkaç basit sayı yakalayın. Büyük bir pano gerekmez, sadece şu sorgulara yanıt veren veriler: kaç iş kuyruğa girdi, kaçı başarısız, en eski kuyruğa alınmış işin yaşı.
Adım adım: bugün kurabileceğiniz basit bir veritabanı kuyruğu
Zaten bir veritabanınız varsa yeni altyapı eklemeden arka plan kuyruğuna başlayabilirsiniz. İşler satırlardır ve worker, uygun satırları alıp işi yapan bir süreçtir.
1) Bir jobs tablosu oluşturun
Tabloyu küçük ve sıkıcı tutun. Daha sonra işleri çalıştırmak, yeniden denemek ve hata ayıklamak için yeterli alanı istiyorsunuz.
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued',
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
Postgres üzerinde inşa ediyorsanız (Go backendlerde yaygın), jsonb iş verisini { "user_id":123,"template":"welcome" } gibi saklamak için pratiktir.
2) Güvenli şekilde enqueue edin (özellikle kullanıcı eylemleri için)
Bir kullanıcı eylemi bir işi tetiklemeli ise (e-posta gönderme, webhook ateşleme), mümkünse işi ana değişiklikle aynı veritabanı işlemi içinde yazın. Bu, ana yazma işleminden hemen sonra çökme olursa "kullanıcı var ama iş eksik" durumunu önler.
Örnek: bir kullanıcı kaydolduğunda, kullanıcı satırını ve send_welcome_email işini tek bir transaction içinde ekleyin.
3) Ölçeklenebilir bir worker döngüsü çalıştırın
Worker aynı döngüyü tekrarlar: bir uygun iş bul, onu talep et (claim) böylece başkası alamaz, işle, sonra bitir veya yeniden deneme zamanını ayarla.
Pratikte bu şu adımları içerir:
status='queued' ve next_run_at <= now() olan bir iş seçin.- Atomik olarak talep edin (Postgres'te
SELECT ... FOR UPDATE SKIP LOCKED sık kullanılan bir yaklaşımdır).
status='running', locked_at=now(), locked_by='worker-1' olarak güncelleyin.- İşi işleyin.
- Bitmiş olarak işaretleyin (
done/succeeded) veya last_error kaydedip bir sonraki denemeyi planlayın.
Birden çok worker aynı anda çalışabilir. Talep adımı çift seçimi önler.
4) Worker kapanışını işleri bozmadan yönetin
Kapanışta yeni işler almayı durdurun, mevcut işi bitirin, sonra çıkın. Eğer bir süreç işin ortasında ölürse, basit bir kural uygulayın: zaman aşımını geçen running durumundaki işleri periyodik bir "reaper" yeniden kuyruğa alabilir.
Koder.ai üzerinde inşa ediyorsanız, e-posta, rapor ve webhooklar için bu veritabanı-kuyruk deseni sağlam bir varsayılandır.
Kaosu önleyen yeniden denemeler ve geri çekilme
İstek–iş ayırımını dağıtın
İstekleri hızlı tutup yavaş işleri workerlara taşıyan bir React + Go uygulaması oluşturun.
Yeniden denemeler, gerçek dünya karmaşık olduğunda kuyruğun sakin kalmasını sağlar. Net kurallar olmadan yeniden denemeler gürültülü bir döngüye dönüşür: kullanıcılara spam gönderir, API'lara yük bindirir ve gerçek hatayı gizler.
Önce neyin yeniden denenmesi gerektiğine, neyin hızlıca başarısız sayılacağına karar verin.
Geçici sorunları yeniden deneyin: ağ zaman aşımı, 502/503 hataları, rate limitler veya kısa süreli veritabanı bağlantı kopmaları.
Başarısız olacağı belli olan durumlarda hızlıca başarısız olun: eksik e-posta adresi, payload yüzünden 400 dönen webhook, silinmiş hesap için rapor talebi.
Geri çekilme, denemeler arasındaki beklemedir. Lineer geri çekilme (5s, 10s, 15s) basittir ama yine trafik dalgalarına neden olabilir. Üstel geri çekilme (5s, 10s, 20s, 40s) yükü yayar ve webhooklar ile üçüncü taraf sağlayıcılar için genelde daha güvenlidir. Binlerce işin aynı saniyede yeniden denememesini sağlamak için jitter (küçük rastgele gecikme) ekleyin.
Üretimde iyi davranan kurallar:
- Sadece açıkça geçici hatalarda yeniden deneyin (zaman aşımı, 429, 5xx).
- Üstel geri çekilme + jitter kullanın.
- Denemeleri sınırlandırın, sonra işi başarısız olarak işaretleyin.
- Her deneme için bir zaman aşımı koyun ki workerlar takılmasın.
- Her işi idempotent yapın ki yeniden denemeler çoğaltma yaratmasın.
Maksimum deneme sayısı hasarı sınırlamaktır. Birçok ekip için 5 ila 8 deneme yeterlidir. Ondan sonra yeniden denemeyi durdurup işi gözden geçirmek üzere park etmek (dead-letter) daha iyidir.
Zaman aşımı "zombi" işleri engeller. E-postalar için deneme başına 10–20 saniye uygundur. Webhooklar genellikle daha kısa bir limit ister (5–10 saniye), çünkü alıcı kapalı olabilir ve siz devam etmek istersiniz. Rapor üretimi dakikalar alabilir ama yine de bir kesme olmalı.
Koder.ai ile inşa ediyorsanız should_retry, next_run_at ve bir idempotency anahtarını birinci sınıf alanlar olarak ele alın. Bu küçük detaylar sorun çıktığında sistemi sessiz tutar.
Dead-letter işleme ve basit operasyonlar
Dead-letter durumu, denemelerin artık güvenli veya faydalı olmadığı durumlarda işlerin gittiği yerdir. Bu, sessiz hatayı görünür, aranabilir ve müdahale edilebilir hale getirir.
Dead-letter işinde ne saklanmalı
Neler olduğunu anlamak ve işi tekrar oynatmak için yeterli bilgiyi saklayın, ancak gizli bilgileri dikkatli yönetin.
Saklayın:
- İş girdileri (payload) tam olarak, iş türü ve sürümü
- Son hata mesajı ve kısa bir stack trace (veya yoksa bir hata kodu)
- Deneme sayısı, ilk çalışma zamanı, son çalışma zamanı ve (eğer planlandıysa) sonraki çalışma zamanı
- Worker kimliği (servis adı, host) ve loglar için correlation ID
- Dead-letter nedeni (zaman aşımı, doğrulama hatası, vendor'dan gelen 4xx vb.)
Payload içinde token veya kişisel veri varsa, depolamadan önce kırpın veya şifreleyin.
Basit triage iş akışı
Bir iş dead-letter olduğunda hızlı bir karar verin: yeniden dene, düzelt veya görmezden gel.
Yeniden deneme, dış servis kesintileri ve zaman aşımı için uygundur. Düzeltme, hatalı veri (eksik e-posta, yanlış webhook URL) veya kod hatası içindir. Görmezden gelme nadir olmalı, ama iş artık alakalı değilse (örneğin müşteri hesabını silmişse) geçerli olabilir—bunu yaparsanız bir neden kaydedin ki iş yok olmayıp bilinçli olarak atılmış olsun.
Manuel yeniden kuyruğa alma en güvenlisidir; yeni bir iş oluşturur ve eski dead-letter kaydını değişmez bırakır. Dead-letter işi kim yeniden kuyruğa aldı, ne zaman ve neden işaretleyin, sonra yeni bir kopyayla yeniden enqueue yapın.
Uyarı için şu sinyalleri izleyin: dead-letter sayısının hızla artması, aynı hatanın birçok işte tekrarlanması ve uzun süredir kuyruğa alınmış ancak alınmayan işler.
Koder.ai kullanıyorsanız, kötü bir sürüm anında hataları hızla geri almak için snapshot ve rollback yardımcı olabilir.
Son olarak, vendor kesintileri için güvenlik vanaları ekleyin. Sağlayıcı başına gönderimleri sınırlayın ve bir circuit breaker kullanın: bir webhook endpoint ciddi şekilde hata veriyorsa, onların (ve sizin) sunucularını delip geçmemek için kısa bir pencere için yeni denemeleri durdurun.
E-posta, rapor ve webhooklar için desenler
Korkmadan deneme yapın
Değişikliklerden önce snapshot alarak bir sürüm hata yaptıysa geri alın.
Bir kuyruk, her iş tipinin açık kuralları olduğunda en iyi sonucu verir: başarı ne demek, ne yeniden denenmeli ve ne asla iki kere olmamalı.
E-postalar. Çoğu e-posta hatası geçicidir: sağlayıcı zaman aşımı, rate limit veya kısa kesinti. Bunları yeniden denenecek olarak ele alın, geri çekilme ile. En büyük risk çift gönderimlerdir; bu yüzden e-posta işleriniz idempotent olmalı. user_id + template + event_id gibi kararlı bir dedupe anahtarı saklayın ve bu anahtar zaten gönderilmişse göndermeyi reddedin.
Ayrıca template adı ve sürümünü (veya render edilmiş konu/gövdenin hash'ini) saklamak faydalıdır. İşleri yeniden çalıştırmanız gerekirse aynı içeriği mi göndereceğinize yoksa en son şablondan mı yeniden oluşturacağınıza karar verebilirsiniz. Sağlayıcı bir message ID döndürürse bunu destek için saklayın.
Raporlar. Rapor hataları farklıdır. Dakikalar sürebilirler, sayfalama limitlerine takılabilir veya her şeyi bir kerede yaparsanız bellek tükenebilir. İşleri küçük parçalara bölün. Yaygın bir desen: bir "rapor talebi" işi birçok "sayfa" veya "parça" işine ayırır, her biri veri dilimini işler.
Kullanıcıyı bekletmek yerine sonucu sonradan indirilecek şekilde saklayın. Bu, report_run_id ile anahtarlanmış bir veritabanı tablosu veya dosya referansı ve metadata (status, row count, created_at) olabilir. UI'nın "işleniyor" vs "hazır" gösterebilmesi için ilerleme alanları ekleyin.
Webhooklar. Webhooklar teslimat güvenilirliği ile ilgilidir, hızla değil. Her isteği imzalayın (ör. paylaşılan bir secret ile HMAC) ve replay'ı önlemek için zaman damgası ekleyin. Sadece alıcının daha sonra başarılı olabileceği durumlarda yeniden deneyin.
Basit kurallar:
- Zaman aşımı ve 5xx cevaplarda geri çekilme + maksimum deneme sayısıyla yeniden deneyin.
- Çoğu 4xx cevabını kalıcı hata kabul edip yeniden denemeyi durdurun.
- Hata ayıklama için son durum kodunu ve kısa bir cevap gövdesini kaydedin.
- Alıcıların çoğaltmaları güvenle yok sayabilmesi için idempotency anahtarı kullanın.
- Payload boyutunu sınırlayın ve aslında ne gönderdiğinizi loglayın.
Sıralama ve öncelik. Çoğu iş için sıkı sıralama gerekmez. Sıralama gerekli olduğunda genelde anahtar bazındadır (kullanıcı, fatura, webhook hedefi). Bir group_key ekleyin ve aynı anahtar için aynı anda sadece bir iş çalıştırın.
Öncelik için acil işleri yavaş işlerden ayırın. Büyük bir rapor kuyruğu şifre sıfırlama e-postalarını geciktirmemeli.
Örnek: bir satın alma sonrası (1) sipariş onayı e-postası, (2) partner webhook ve (3) rapor güncelleme işi kuyruğa alınır. E-posta hızlıca yeniden denemeye sahiptir, webhook daha uzun geri çekilme ile yeniden denenir, rapor ise düşük öncelikte daha sonra çalışır.
Gerçekçi bir örnek: kayıt akışı, webhook ve gece raporu
Bir kullanıcı uygulamanıza kaydolur. Üç şey olmalı ama hiçbiri kayıt sayfasını yavaşlatmamalı: karşılama e-postası gönder, CRM'e webhook ile bildir ve kullanıcıyı gece raporuna dahil et.
Kayıt sırasında kuyruğa alınanlar
Kullanıcı kaydını oluşturduktan hemen sonra veritabanı kuyruğunuza üç iş satırı yazın. Her satır bir tip, bir payload (ör. user_id), bir status, bir deneme sayısı ve next_run_at zaman damgası içerir.
Tipik yaşam döngüsü:
queued: oluşturuldu ve worker bekliyorrunning: bir worker tarafından talep edildisucceeded: tamamlandı, daha fazla iş yokfailed: başarısız oldu, daha sonra yeniden denenmek üzere veya deneme hakkı doldudead: deneme hakkı doldu, insan müdahalesi gerekli
Karşılama e-postası işi welcome_email:user:123 gibi bir idempotency anahtarı içerir. Göndermeden önce worker tamamlanmış idempotency anahtarları tablosuna bakar (veya unique constraint ile zorlar). İş iki kez çalışırsa ikinci çalışma anahtarı görüp gönderimi atlar. Çift karşılama e-postası olmaz.
Bir başarısızlık ve nasıl toparlanır
CRM webhook endpoint'i kapalıysa webhook işi zaman aşımı ile başarısız olur. Worker geri çekilme kullanarak yeniden deneme planlar (örneğin: 1 dakika, 5 dakika, 30 dakika, 2 saat) ve küçük jitter ekler böylece birçok iş aynı saniyede yeniden denemez.
Maksimum denemeden sonra iş dead olur. Kullanıcı yine de kayıt oldu, karşılama e-postası gitti ve gece raporu işi normal şekilde çalışabilir. Sadece CRM bildirimi takıldı ve görünür durumda.
Ertesi sabah destek veya ilgili kişi şu adımları yapabilir:
- Dead-jobları türüne göre filtrele (
webhook.crm gibi)
- Son hata mesajını okuyup payload'ın doğru görünüp görünmediğini doğrula
- CRM'in tekrar çalıştığını doğrula
- İşi yeniden kuyruğa al (dead -> queued, deneme sayısını sıfırla) veya o hedefi geçici olarak devre dışı bırak
Koder.ai gibi bir platformda uygulama geliştiriyorsanız, aynı desen geçerlidir: kullanıcı akışını hızlı tutun, yan etkileri işlere itin ve hataların incelenip tekrar çalıştırılmasını kolaylaştırın.
Kuyrukları güvensiz yapan yaygın hatalar
İş tiplerini temiz modelleyin
E-posta, webhook ve raporlar için ayrı iş tipleri oluşturun; her handler için açık kurallar belirleyin.
Bir kuyruğu bozan en hızlı yol onu isteğe bağlı gibi görmektir. Ekipler genellikle "bu sefer isteğin içinde e-postayı gönderelim" diye başlar çünkü daha basit hissedilir. Sonra bu yayılır: şifre sıfırlama, makbuzlar, webhooklar, rapor dışa aktarımlar. Kısa sürede uygulama yavaşlar, zaman aşımı artar ve üçüncü tarafın bir arızası sizin kesintiniz haline gelir.
Diğer bir yaygın tuzak idempotency'yi atlamaktır. Bir iş iki kez çalışabiliyorsa iki sonuç üretmemelidir. İdempotency olmadan yeniden denemeler çift e-posta, tekrar eden webhook olayları veya daha kötü sonuçlar doğurur.
Üçüncü sorun görünürlük eksikliğidir. Sadece destek taleplerinden hataları öğreniyorsanız, kuyruk zaten kullanıcıları etkiliyor demektir. İş sayısını durumuna göre gösteren ve last_error ile aranabilen basit bir iç görünüm bile zaman kazandırır.
Güvenilirliği öldürenler
Basit kuyruqlarda erken ortaya çıkan bazı sorunlar:
- Hata sonrası hemen yeniden deneme. Sağlayıcı kapalıysa hızlı yeniden denemeler kendi trafiğinizi yaratır.
- Yavaş işleri acil işlerle karıştırmak. 10 dakikalık bir rapor "e-postanı doğrula" mesajını engelleyebilir.
- Hataları sonsuza dek geçici saymak. Hiçbir zaman başarılı olmayacak işler döngüye girer ve gerçek problemleri gizler.
- Payload sürümlerine sahip çıkmamak. İş şekli değişirse eski işler başarısız olmaya başlar.
- Rate limitleri göz ardı etmek. Kuyruklar sizi throttle eden sağlayıcıları boşaltabilir.
Geri çekilme kendi yaptığınız kesintileri önler. 1 dakika, 5 dakika, 30 dakika, 2 saat gibi basit bir takvim bile hataları daha güvenli hale getirir. Ayrıca maksimum deneme limiti koyun ki bozuk bir iş durup görünür olsun.
Koder.ai üzerinde geliştiriyorsanız, bu temel özellikleri özelliğin kendisiyle birlikte dağıtmak, haftalar sonra temizlik projesi yapmak yerine daha iyidir.
Hızlı kontrol listesi ve sonraki adımlar
Daha fazla araç eklemeden önce temellerin sağlam olduğundan emin olun. Bir veritabanı destekli kuyruk, her işin kolayca talep edilebildiği, yeniden denenebildiği ve incelenebildiği durumlarda iyi çalışır.
Kısa güvenilirlik kontrol listesi:
- Her işte: id, type, payload, status, attempts, max_attempts, run_at/next_run_at ve last_error olsun.
- Workerlar işleri güvenli şekilde talep etsin (bir worker bir işi alır) ve çökmeler sonrası toparlansın (kilit zaman aşımı + reaper).
- Her iş için açık bir zaman aşımı olsun ki takılan işler tekrar denenebilir hale gelsin.
- Yeniden denemeler sınırlandırılsın ve gecikme artsın (backoff) ki thundering herd oluşmasın.
- Bir dead-letter durumu (veya tablosu) olsun ve işleri yeniden çalıştırma veya elenme için net bir yol.
Sonraki adım: ilk üç iş tipinizi seçin ve kurallarını yazın. Örneğin: şifre sıfırlama e-postası (hızlı yeniden denemeler, kısa max), gece raporu (az deneme, uzun zaman aşımı), webhook teslimatı (daha çok deneme, uzun geri çekilme, kalıcı 4xx’te dur).
Veritabanı kuyruğu ne zaman yetersiz olur bilmiyorsanız şu sinyalleri izleyin: çok sayıda worker nedeniyle satır düzeyi çatışmaları, farklı iş tipleri arasında sıkı sıralama ihtiyacı, büyük fan-out (bir olay binlerce iş tetikliyorsa), veya farklı ekiplerin farklı workerları sahiplenmesi gerektiğinde.
Hızlı bir prototip istiyorsanız akışı Koder.ai içinde Planning Mode ile taslaklayabilir, jobs tablosu ve worker döngüsünü üretebilir ve snapshot/rollback ile dağıtımdan önce yineleyebilirsiniz.