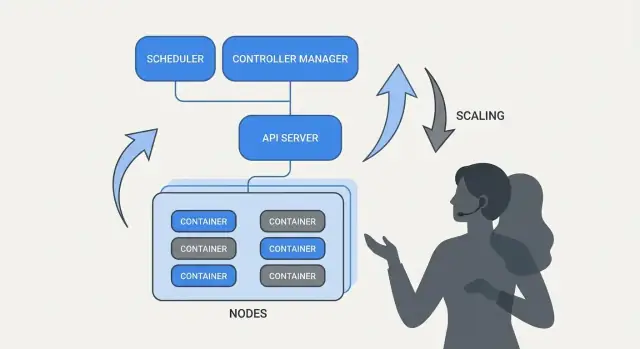
Neden Kubernetes Günlük Operasyonları Değiştirdi
Kubernetes sadece yeni bir araç getirmedi—onlarca (veya yüzlerce) servis çalıştırırken "günlük operasyon"un nasıl göründüğünü değiştirdi. Orkestrasyondan önce ekipler genellikle aynı tekrar eden sorulara cevap bulmak için betikler, manuel runbook'lar ve birikmiş bilgiye güvenirlerdi: Bu servis nerede çalışmalı? Değişikliği nasıl güvenli şekilde dağıtırız? Bir node gece 2'de öldüğünde ne olur?
"Orkestrasyon" gerçekte neyi çözer
Özünde orkestrasyon, niyetiniz ("bu servisi şöyle çalıştır") ile makinelerin arızalanması, trafiğin kayması ve kesintisiz dağıtımlar gibi dağınık gerçeklik arasındaki koordinasyon katmanıdır. Her sunucuyu özel bir kar tanesi olarak görmek yerine, orkestrasyon hesaplamayı bir havuz olarak ele alır ve iş yüklerini taşınabilir, planlanabilir birimler olarak görür.
Kubernetes, ekiplerin istediklerini tanımladığı ve sistemin sürekli olarak gerçeği bu tanıma uydurmaya çalıştığı bir modeli popülerleştirdi. Bu değişim önemlidir çünkü operasyonları kahramanlıklardan ziyade tekrarlanabilir süreçlere dönüştürür.
Ekiplerin hemen hissettiği üç sonuç
Kubernetes, çoğu servis ekibinin ihtiyaç duyduğu operasyonel sonuçları standartlaştırdı:
- Dağıtım: ne çalıştırılması gerektiğini, nasıl güncelleneceğini ve sağlıklı olduğunu doğrulamanın tutarlı bir yolu.
- Ölçeklendirme: servisi yeniden tasarlamadan veya makineleri elle sağlarken çoktan çoğa pratik bir yol.
- Servis operasyonları: servislerin birbirini bulması, trafiği yönlendirme ve örnekler değişirken çalışmaya devam etmesi için istikrarlı yollar.
Kapsam ve kaynaklara dair not
Bu yazı Kubernetes ile ilişkili fikirler ve kalıplara (ve Brendan Burns gibi liderlerin etkisine) odaklanır; kişisel bir biyografi değildir. "Nasıl başladı" veya "neden böyle tasarlandı" gibi iddialar halka açık kaynaklara—konferans konuşmaları, tasarım belgeleri ve upstream dokümantasyon—dayandırılmalıdır, böylece anlatı efsaneye dönüşmez.
Brendan Burns ve Kubernetes'in Köken Hikayesi (Yüksek Düzey)
Brendan Burns, Joe Beda ve Craig McLuckie ile birlikte Kubernetes'in üç orijinal kurucusundan biri olarak geniş çapta tanınır. Google içindeki erken Kubernetes çalışmalarında Burns, teknik yönü şekillendirmeye ve projeyi kullanıcılara anlatma biçimine katkıda bulundu—özellikle "yazılımı nasıl işletirsiniz" sorusunun vurgulanmasında, sadece "konteynerleri nasıl çalıştırırsınız" değil. (Kaynaklar: Kubernetes: Up & Running, O’Reilly; Kubernetes proje deposu AUTHORS/maintainers listeleri)
Açık kaynak işbirliği tasarımı şekillendirdi
Kubernetes, bitmiş bir dahili sistem olarak "sadece yayımlanmadı"; kamuya açık şekilde, büyüyen katkıda bulunanlar, kullanım durumları ve kısıtlamalarla birlikte inşa edildi. Bu açıklık projeyi farklı ortamlarda ayakta kalabilecek arayüzlere itti:
- gizli uygulama detayları yerine net, versiyonlanmış API'ler
- bulut sağlayıcılar ve on-prem kurulumlar arasında taşınabilir davranışlar
- çekirdeğin nispeten küçük kalmasını sağlar sırta destek veren genişletme noktaları
Bu işbirlikçi baskı, Kubernetes'in neyi optimize ettiğini etkiledi: birçok ekibin üzerinde uzlaşabileceği paylaşılan ilkelere ve tekrarlanabilir kalıplara yöneldi, araçlarda anlaşmasalar bile.
Burada "standartlaştırma" gerçekte ne anlama geliyor
Kubernetes'in "dağıtım ve operasyonu standartlaştırdığı" söylenirken genellikle her sistemi aynı yaptığı kastedilmez. Kastedilen, ekipler arasında tekrarlanabilecek ortak bir sözlük ve iş akışları sunmasıdır:
- "deployment", "service", "ingress", "job", "namespace" gibi ortak terimler
- ne istediğinizi beyan etme ve sistemin buna doğru çalışması için sürekli bir model
- değişiklikleri kademeli olarak dağıtma, ölçeklendirme ve hatalardan kurtarma için öngörülebilir yollar
Bu ortak model, dokümantasyonun, araçların ve ekip uygulamalarının bir şirketten diğerine taşınmasını kolaylaştırdı.
Kubernetes proje vs. ekosistem ayrımı
Kubernetes (açık kaynak proje) ile Kubernetes ekosistemini ayırmak faydalıdır.
Proje, platformu uygulayan çekirdek API ve kontrol düzlemi bileşenleridir. Ekosistem ise etrafında büyüyen dağıtımlar, yönetilen hizmetler, eklentiler ve CNCF projeleridir. İnsanların güvenip kullandığı birçok gerçek dünya "Kubernetes özelliği" (gözlemlenebilirlik yığınları, politika motorları, GitOps araçları) çekirdek projede değil, bu ekosistemde yaşar.
Temel Fikir: Deklaratif İstenen Durum
Deklaratif yapılandırma, sistemleri tanımlama biçiminde basit bir kaymadır: yapılacak adımları listelemek yerine istediğiniz son durumu belirtirsiniz.
Kubernetes terimleriyle, platforma "bir konteyner başlat, sonra bir port aç, sonra çökerse yeniden başlat" demek yerine "bu uygulamadan üç kopya çalışmalı, bu porttan erişilebilir, bu container imajını kullanmalı" diye belirtirsiniz. Kubernetes, gerçeği bu tanımla eşleştirmekle sorumludur.
İstenen durum vs. emredici betikler
Emredici operasyonlar bir runbook gibidir: geçen sefer işe yarayan komutların dizisi, bir şey değiştiğinde tekrar yürütülür.
İstenen durum ise daha çok bir sözleşme gibidir. Nihaî sonucu bir yapılandırma dosyasında kaydedersiniz ve sistem sürekli olarak bu sonuca doğru çalışır. Bir şey saparsa—bir örnek ölür, bir node kaybolur, manuel bir değişiklik girerse—platform uyumsuzluğu fark eder ve düzeltir.
Önce/sonra: runbook komutları vs. YAML
Önce (emredici runbook düşüncesi):
- bir sunucuya SSH at
- yeni container imajını çek
- eski süreci durdur
- yeni süreci başlat
- bir load balancer kuralını güncelle
- trafik yükselirse, diğer sunucularda tekrar et
Bu yaklaşım işe yarar, ama kolayca "kar tanesi" sunuculara ve sadece birkaç kişinin güvendiği uzun bir kontrol listesine dönüşebilir.
Sonra (deklaratif istenen durum):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
Dosyayı (örneğin image veya replicas'ı güncellemek) değiştirirsiniz, uygulayınca Kubernetes'in controller'ları çalışıp çalışanın gerçeği beyana uydurmaya çalışır.
Neden bu iş yükünü ve sürüklenmeyi azaltır
Deklaratif istenen durum, "bu 17 adımı yap"ı "bunu böyle tut"a çevirerek operasyonel emeği azaltır. Ayrıca yapılandırma sürüklenmesini azaltır çünkü gerçek kaynak açıklıdır ve genellikle versiyon kontrolünde tutulur—sürprizler daha kolay görülebilir, denetlenebilir ve tutarlı şekilde geri alınabilir.
Controller'lar ve Uzlaştırma: Şeyi Doğru Tutan Sistem
Kubernetes "kendi kendine yönetiyormuş" hissi verir çünkü basit bir kalıp etrafında inşa edilmiştir: ne istediğinizi tanımlarsınız ve sistem sürekli olarak gerçeği bu tanıma yaklaştırmaya çalışır. Bu kalıbın motoru controller'dır.
Controller nedir (sade ifadeyle)
Controller, kümenin mevcut durumunu izleyen ve bunu YAML'da (veya API çağrısında) beyan ettiğiniz istenen durumla karşılaştıran bir döngüdür. Bir fark gördüğünde, bu farkı azaltmak için harekete geçer.
Bir kerelik bir betik değildir ve bir insanın tıklamasını beklemez. Tekrar tekrar çalışır—gözlemle, karar ver, harekete geç—böylece her an değişime yanıt verebilir.
Uzlaştırma: Kubernetes’in “şeyi doğru tutma”sı nasıl çalışır
Bu tekrar eden karşılaştırma ve düzeltme davranışına uzlaştırma (reconciliation) denir. Bu, "kendini iyileştirme" vaadinin arkasındaki mekanizmadır. Sistem arızaları sihirle engellemez; sapmayı fark edip düzeltir.
Sapma sıradan nedenlerle oluşabilir:
- bir süreç çöker
- bir node kaybolur
- biri bir şeyi yukarı/aşağı ölçeklendirir
- bir dağıtım güncellenir
Uzlaştırma, Kubernetes'in bu olayları niyetinizi yeniden kontrol etmek ve onu geri yüklemek için sinyal olarak ele alması anlamına gelir.
İnsanların gerçekten umursadığı sonuçlar
Controller'lar tanıdık operasyonel sonuçlara dönüşür:
- Başarısız pod’ları değiştir: bir pod ölürse, controller hala onu istediğinizi görür ve yeni bir tane planlar.
- Replika sayılarını sabit tut: 5 replika istediniz ama sadece 4 çalışıyorsa, Kubernetes eksik olanı oluşturmaya çalışır.
- Rollout ilerlemesini sürdür: güncellemeler sırasında controller'lar yeni versiyona doğru sistemi taşırken istenen kullanılabilirliği korumaya çalışır.
Önemli olan, semptomların peşinden manuel olarak koşmamanızdır. Hedefi beyan edersiniz ve kontrol döngüleri sürekli olarak "bunu böyle tutma" işini yapar.
Bu yaklaşımın bir özellikten fazlasına ölçeklenmesi
Bu yaklaşım tek bir kaynak tipine bağlı değildir. Kubernetes aynı controller-ve-uzlaştırma fikrini birçok nesnede kullanır—Deployment, ReplicaSet, Job, Node, Endpoint ve daha fazlası. Bu tutarlılık, Kubernetes'in bir platform haline gelmesinin büyük bir nedenidir: kalıbı bir kez anladığınızda, yeni yetenekler ekledikçe sistemin nasıl davranacağını tahmin edebilirsiniz (aynı döngüyü takip eden özel kaynaklar dahil).
Planlama (Scheduling): Bir Manuel Görev Değil, Ürün Özelliği
Web uygulamasını başlatın
Servis sınırlarınız ve yayın hızınıza uygun bir React UI üretin.
Kubernetes sadece "konteynerleri çalıştır" yapsaydı bile, ekipler en zor kararı; hangi iş yükünün nerede çalışacağına karar vermekle baş başa kalırdı. Planlayıcı, Pod'ları kaynak ihtiyaçları ve tanımladığınız kurallar temelinde otomatik olarak doğru node'lara yerleştiren yerleşik sistemdir.
Bu önemlidir çünkü yerleşim kararları doğrudan çalışma süresini ve maliyeti etkiler. Kalabalık bir node'da sıkışmış bir web API'si yavaşlayabilir veya çöker. Bir batch işi gecikme hassasiyeti yüksek hizmetlerin yanına yerleştirilirse gürültülü-komşu sorunları yaratabilir. Kubernetes bunu bir spreadsheet ve SSH rutininin yerine tekrarlanabilir bir ürün yeteneğine dönüştürür.
Scheduler ne için optimize eder
Temel düzeyde scheduler, Pod'un isteklerini karşılayabilecek node'ları arar.
- CPU/ram istekleri: yerleştirme kararları için kapasite ayırır. 500m CPU ve 1Gi bellek isterseniz, Kubernetes sadece yeterli boşluğa sahip node'ları dikkate alır.
Bu tek alışkanlık—gerçekçi istekler belirlemek—kritik servislerin her şeyle rekabet etmeyi bırakması sayesinde rastgele kararsızlığı sıklıkla azaltır.
Ekiplerin gerçekte kullandığı yaygın kısıtlamalar
Kaynakların ötesinde, üretim kümelerinin çoğu birkaç pratik kurala dayanır:
- Affinity / anti-affinity: "bunları birlikte yerleştir" (önbellek yerelliği için) veya "bunları ayrı tut" (bir node arızasının tüm replikaları almasını önlemek için).
- Taints ve tolerations: belirli node'ları özel amaçlı (GPU node'ları, sistem node'ları, uyumluluk node'ları) olarak işaretleyin ve yalnızca onaylı iş yüklerinin oraya yerleşmesine izin verin.
Bunun kesintileri nasıl azalttığı
Planlama özellikleri ekiplerin operasyonel niyetini kodlamasına yardımcı olur:
- replikaları node'lara yayarak node arızalarına karşı dayanıklılık sağlamak
- "patlayan" işleri müşteri hizmetlerinden izole etmek
- pahalı node'ların (GPU gibi) yanlış iş yükleri tarafından tüketilmesini önlemek
Pratik çıkarım: planlama kurallarını ürün gereksinimleri gibi ele alın—bunları yazın, gözden geçirin ve tutarlı şekilde uygulayın—böylece güvenilirlik gece 2'de doğru node'u hatırlayan birine bağlı kalmaz.
Ölçeklendirme: Uygulamayı Yeniden Yazmadan Bir Örnektan Binlere
Kubernetes'in en pratik fikirlerinden biri, ölçeklendirmenin uygulama kodunu değiştirmeyi veya yeni bir dağıtım yaklaşımı icat etmeyi gerektirmemesi gerektiğidir. Eğer uygulama bir konteyner olarak çalışabiliyorsa, aynı iş yükü tanımı genellikle yüzlerce veya binlerce kopyaya büyüyebilir.
Ölçeklendirmenin iki katmanı vardır
Kubernetes ölçeklendirmeyi iki ilişkili karara ayırır:
- Kaç pod çalıştırılacağı (daha fazla throughput veya yedeklilik için daha fazla kopya).
- Kümenin ne kadar kapasiteye sahip olduğu (bu pod'ları yerleştirecek yeterli node—ve doğru boyutta nodelar).
Bu ayrım önemlidir: 200 pod isterken kümeye sadece 50 yer varsa, "ölçeklendirme" bekleyen işlerin kuyruğuna dönüşür.
Konsept olarak autoscaling (HPA, VPA, Cluster Autoscaler)
Kubernetes genellikle üç autoscaler kullanır, her biri farklı bir kaldıraç üzerine odaklanır:
- Horizontal Pod Autoscaler (HPA): CPU kullanımı, bellek veya özel uygulama metrikleri gibi sinyallere göre pod sayısını değiştirir.
- Vertical Pod Autoscaler (VPA): her pod'un kaynak isteklerini/limitlerini ayarlar, böylece her pod daha fazla (veya daha az) CPU/ram alır.
- Cluster Autoscaler: scheduler'ın istenen pod'ları yerleştirebilmesi için node ekler veya çıkarır.
Birlikte kullanıldığında, ölçeklendirmeyi "gecikmeyi sabit tut" veya "CPU yüzde X civarında tut" gibi politika haline getirir; manuel müdahale değil.
"İyi ölçeklendirme" neye bağlıdır
Ölçeklendirme sadece girdiler kadar iyidir:
- Metrikler: CPU kolaydır ama her zaman anlamlı değildir; istek hızı, kuyruk derinliği ve gecikme genellikle gerçek yükle daha iyi örtüşür.
- Kaynak istekleri/limitleri: bunlar scheduler'a bir pod'un neye ihtiyaç duyduğunu söyler. Yoksa yerleşim ve autoscaling kararları tahmine dönüşür.
- Yük desenleri: ani trafik dalgalanmaları, yavaş ısınmalar ve ağır arka plan işler ölçeklendirmenin tepki hızını değiştirir.
Yaygın tuzaklar
Tekrarlanan iki hata: yanlış metrikle ölçeklendirme (CPU düşükken istekler zaman aşımına girer) ve eksik kaynak istekleri (autoscaler kapasiteyi öngöremez, pod'lar çok sıkışır ve performans tutarsızlaşır).
Güvenli Dağıtımlar: Rollout'lar, Sağlık Kontrolleri ve Geri Alma
Kubernetes'in popülerleştirdiği büyük değişimlerden biri, "dağıtım"ı tek seferlik bir komut değil, sürekli yönetilen bir kontrol problemi olarak ele almaktır. Rollout'lar ve rollback'ler birinci sınıf davranışlardır: hangi sürümü istediğinizi beyan edersiniz ve Kubernetes değişimi adım adım uygularken gerçekten güvenli olup olmadığını sürekli kontrol eder.
Rollout'lar kontrollü bir geçiştir
Bir Deployment ile rollout, eski Pod'ların yeni olanlarla kademeli olarak değiştirilmesidir. Her şeyi durdurup yeniden başlatmak yerine, Kubernetes kapasiteyi koruyarak ve yeni versiyon gerçek trafikte doğrulanırken adım adım değişikliğe gider.
Yeni versiyon başarısız olmaya başlarsa, rollback acil bir prosedür değildir. Önceki bilinen iyi ReplicaSet'e geri dönebilir ve controller'ın eski durumu geri yüklemesine izin verebilirsiniz.
Probe'lar: "çalışıyor ama kötü" sürümleri önleme
Sağlık kontrolleri, rollout'ları umut temelli olmaktan ölçülebilir hale getirir.
- Readiness probe: bir Pod'un trafiği alıp alamayacağını belirler. Bir container çalışıyor olabilir ama hazır olmayabilir (önbellek ısınıyor, bağımlılıkları bekliyor). Readiness, kullanıcıları gerçekten cevap veremeyecek örneklere göndermeyi engeller.
- Liveness probe: bir container'ın takılıp takılmadığını veya sağlıksız olup yeniden başlatılması gerekip gerekmediğini tespit eder. Bu, sürecin canlı ama bozuk olduğu yavaş arıza modunu önler.
Doğru kullanıldığında probe'lar, Pod'lar başlatıldığı için iyi görünen ama gerçekte istekleri reddeden dağıtımları azaltır.
Dağıtım stratejileri: rolling, blue/green, canary
Kubernetes yerel olarak rolling update sağlar, ancak ekipler genellikle üstüne ekstra desenler ekler:
- Blue/green: iki tam ortamı tutun ve green doğrulandıktan sonra trafiği değiştirin.
- Canary: trafiğin küçük bir yüzdesini yeni sürüme gönderin, metrikleri izleyin ve sonra kademeli olarak genişletin.
Ölçülebilir (ve otomatikleştirilebilir) güvenlik
Güvenli dağıtımlar sinyallere dayanır: hata oranı, gecikme, doygunluk ve kullanıcı etkisi. Birçok ekip rollout kararlarını SLO'lar ve hata bütçeleri ile ilişkilendirir—bir canary çok fazla bütçe yakarsa, terfi durur.
Amaç, geri almanın gerçek göstergelere dayalı otomatik tetiklenmesi, böylece "geri alma"nın tahmin edilebilir bir sistem tepkisi olmasıdır—gece geç saatlerdeki kahramanlık anı değil.
Servis Operasyonları: Keşif, Yönlendirme ve Sabit Ağlama
Güvenlik ağıyla dağıtın
Uygulamanızı dağıtın ve anlık görüntüler ile geri alma seçenekleriyle yineleyin.
Bir konteyner platformu, uygulamanız hareket ettikten sonra diğer parçaların hâlâ uygulamanızı bulabilmesi halinde ancak "otomatik" hisseder. Gerçek üretim kümelerinde pod'lar sürekli oluşturulur, silinir, yeniden planlanır ve ölçeklenir. Her değişiklik IP adreslerini konfigürasyonlarda güncellemeyi gerektirseydi, operasyonlar sürekli bir meşguliyete dönüşür ve kesintiler olağan olurdu.
Servis keşfinin önemi
Servis keşfi, istemcilere değişen bir backend kümesine güvenilir bir şekilde ulaşma yolu vermektir. Kubernetes'te ana değişim, bireysel örneklere hedeflenmeyi bırakıp bir isimlendirilmiş servise hedeflenmektir ("10.2.3.4 çağır" yerine "checkout çağır"). Platform, bu isim için hangi pod'ların hizmet verdiğini halleder.
Service, selector ve endpoint'ler (düz Türkçe)
Bir Service, bir grup pod için sabit bir ön kapıdır. Küme içinde alttaki pod'lar değişse bile tutarlı bir isim ve sanal adrese sahiptir.
Bir selector, Kubernetes'in hangi pod'ların o ön kapının arkasında olduğunu belirlemesidir. Çoğunlukla app=checkout gibi etiketleri eşler.
Endpoints (veya EndpointSlices), seçiciyle şu anda eşleşen gerçek pod IP'lerinin canlı listesidir. Pod'lar ölçeklenip yeniden planlandığında bu liste otomatik olarak güncellenir—istemciler aynı Service adını kullanmaya devam eder.
Sabit adresler, load balancing ve trafik yönlendirme
Operasyonel olarak bu şunları sağlar:
- Sabit adresleme: uygulamalar pod IP'lerini takip etmek yerine bir Service DNS adına konuşur.
- Load balancing: trafik Service arkasındaki sağlıklı pod'lar arasında dağıtılır.
- Öngörülebilir yönlendirme: "trafik kimin alacağı" (etiketler/selector) ile "pod'ların nerede çalıştığı"nı ayırabilirsiniz.
Kümeye dışarıdan yönelen (north–south) trafik genellikle bir Ingress veya daha yeni Gateway yaklaşımı kullanılarak yönetilir. Her ikisi de hostname veya path'e göre istekleri yönlendirebileceğiniz kontrollü bir giriş noktası sağlar ve genellikle TLS terminasyonu gibi konuları merkezileştirir. Önemli fikir yine aynıdır: arka plan hizmetleri değişirken dış erişimi sabit tutmak.
Kendini İyileştirme: Üretimde Gerçekte Ne Anlama Gelir
Kubernetes'te "kendini iyileştirme" sihir değil. Bu, bir dizi otomatik tepkinin birleşimidir: yeniden başlat, yeniden planla ve değiştir. Platform, beyan ettiğiniz istenen durumu izler ve gerçeği buna doğru itmeye devam eder.
Yeniden başlat: bir container çöktüğünde
Bir süreç sonlanır veya bir container sağlıksız hale gelirse, Kubernetes onu aynı node üzerinde yeniden başlatabilir. Bu genellikle şunlarla tetiklenir:
- Liveness probe: "Bu container hâlâ işliyor mu?" Eğer hayırsa, yeniden başlat.
- Restart politikaları: yeniden başlatma kuralları.
Yaygın üretim akışı: tek bir container çöküyor → Kubernetes yeniden başlatıyor → Service sadece sağlıklı Pod'lara trafiği yönlendiriyor.
Yeniden planla ve değiştir: bir node arızalandığında
Bir node tamamen çökerse (donanım sorunu, kernel panic, ağ kaybı), Kubernetes node'u erişilemez olarak tespit eder ve işi başka yere taşır. Yüksek düzey:
- Node sağlıksız/ready değil olarak işaretlenir.
- Orada çalışan Pod'lar kayıp sayılır.
- Controller'lar istenen replika sayısını geri yüklemek için diğer sağlıklı node'larda yedek Pod'lar oluşturur.
Bu, küme düzeyinde "kendini iyileştirme"dir: sistem kapasiteyi insanlar SSH'lamayı beklemek yerine yerine koyar.
Gözlemlenebilirlik: gerçekten iyileştiğini nasıl anlarsınız
Kendini iyileştirme ancak doğrulayabilirseniz önemlidir. Ekipler genellikle şunları izler:
- Loglar (uygulama logları ve platform olayları) hangi şeylerin yeniden başladığını ve nedenini görmek için
- Metrikler olarak yeniden başlatma sayıları, başarısız probe'lar ve node hazır olma durumu
- Uyarılar iyileşmenin çalışmadığını gösterdiğinde (ör. tekrar eden CrashLoopBackOff, replika eksikliği, çok fazla eviction)
İyileşmeyi bozabilecek yanlış konfigürasyonlar
Kubernetes olsa bile, "iyileşme" koruyucuları yanlışsa başarısız olabilir:
- yanlış veya eksik liveness/readiness probe (yanlış pozitifler veya asla hazır olmayan Pod'lar)
- kaynak istek/limit eksikliği, öngörülemez yerleşim veya OOM kill'lere yol açar
- çok az replika (tek bir Pod süreklilik sağlayamaz)
- aşırı agresif probe zamanlamaları yeniden başlatma fırtınalarına neden olur
- node-local duruma bağımlı iş yükleri kalıcı bir depolama stratejisi olmadan
İyileştirme iyi kurulursa, kesintiler daha küçük ve daha kısa olur—ve daha da önemlisi ölçülebilir hale gelir.
Deklaratif bir spesifikasyondan oluşturun
Operasyon için hazır bir spesifikasyonu, hızlıca dağıtıp üzerine yineleyebileceğiniz gerçek bir uygulamaya dönüştürün.
Kubernetes sadece konteyner çalıştırabildiği için kazanmadı. Kazanmasının nedeni en yaygın operasyonel ihtiyaçlar için standart API'ler sunmasıydı—dağıtım, ölçeklendirme, ağ ve gözlemlenebilirlik gibi. Ekipler aynı "nesne" biçimi (Deployment, Service, Job gibi) üzerinde anlaşınca, araçlar organizasyonlar arasında paylaşılabilir, eğitim basitleşir ve dev-ops elden teslimleri kabile bilgisinden kurtulur.
Standart API'ler ekip iş akışlarını nasıl değiştirir
Tutarlı bir API, dağıtım pipeline'ınızın her uygulamanın tuhaflıklarını bilmesine gerek kalmaması demektir. Aynı Kubernetes kavramlarını kullanarak aynı eylemleri—oluştur, güncelle, geri al ve sağlık kontrol et—uygulayabilir.
Ayrıca hizalanmayı geliştirir: güvenlik ekipleri politika olarak koruyucuları ifade edebilir; SRE'ler ortak sağlık sinyalleri etrafında runbook'ları standardize edebilir; geliştiriciler paylaşılan bir sözlükle sürümleri düşünebilir.
Kubernetes'i genişletme: CRD'ler ve Operator'lar
Platform değişimi Custom Resource Definitions (CRD) ile belirginleşir. CRD, kümeye yeni bir nesne türü eklemenizi sağlar (ör. Database, Cache, Queue) ve bunu yerleşik kaynaklarla aynı API kalıplarıyla yönetmenize izin verir.
Bir Operator, bu özel nesneleri istenen durumla uzlaştıran bir controller ile eşleştirilir—yedekleme, failover veya sürüm yükseltmeleri gibi önceden manuel olan görevleri otomatikleştirir. Temel fayda sihir değil; Kubernetes'in her şeye uyguladığı aynı kontrol döngüsü yaklaşımını yeniden kullanmaktır.
GitOps, CI/CD ve politika kontrolleriyle uyum
Kubernetes API-odaklı olduğu için modern iş akışlarıyla temiz entegrasyon sağlar:
- GitOps: istenen durum Git'te yaşar; değişiklikler kod gibi gözden geçirilir.
- CI/CD: pipeline'lar manifestleri uygular, hazır olmayı bekler ve versiyonları terfi ettirir.
- Politika kontrolleri: admission controller'lar riskli konfigürasyonları üretime ulaşmadan engelleyebilir.
Eğer bu fikirler üzerine daha pratik dağıtım ve operasyon rehberleri arıyorsanız, /blog'a göz atın. Ücret ve yönetişim değerlendirmeleri için /pricing'i inceleyebilirsiniz.
Ekiplerin Bugün Uygulayabileceği Şeyler (Kubernetes Dışında Bile)
Kubernetes'in en büyük fikirleri—birçoğu Brendan Burns'in erken çerçevesiyle ilişkilendirilebilir—VM'lerde, serverless'de veya daha küçük bir konteyner kurulumunda bile iyi şekilde tercüme edilebilir.
Günlük operasyonları iyileştiren kalıplar
İstenen durumu yazın ve otomasyonun bunu uygulamasına izin verin. Terraform, Ansible veya bir CI pipeline'ı fark etmez; konfigürasyonu tek doğruluk kaynağı olarak ele alın. Sonuç daha az manuel dağıtım adımı ve çok daha az "benim makinemde çalıştı" sürprizidir.
Tek seferlik betikler yerine uzlaştırma kullanın. Bir kerelik çalışıp uman betikler yerine, anahtar özellikleri sürekli doğrulayan döngüler oluşturun (sürüm, konfig, örnek sayısı, sağlık). Bu, tekrarlanabilir operasyonlar ve arızalardan sonra öngörülebilir kurtarma sağlar.
Planlama ve ölçeklendirmeyi açık ürün özellikleri haline getirin. Ne zaman ve neden kapasite ekleyeceğinizi (CPU, kuyruk derinliği, gecikme SLO'ları) tanımlayın. Kubernetes autoscaling olmasa bile ekipler ölçek kurallarını standardize edebilir, böylece büyüme uygulamayı yeniden yazmayı veya birini uyandırmayı gerektirmez.
Dağıtımları standardize edin. Kademeli güncellemeler, sağlık kontrolleri ve hızlı geri alma prosedürleri değişiklik riskini azaltır. Bunu load balancer'lar, feature flag'ler ve gerçek sinyallerle kapalı dağıtım pipeline'larıyla uygulayabilirsiniz.
Güvenli bir benimseme kontrol listesi
- Bir servisin istenen durumunu tanımlayın: sürüm, konfig, bağımlılıklar ve minimum örnek sayısı
- sağlık uç noktaları ekleyin (liveness ve readiness eşdeğerleri) ve bunları load balancer veya dağıtım pipeline'ınıza bağlayın
- dağıtım adımlarını otomatikleştirin: deploy, doğrula, trafiği kaydır ve başarısızlığa geri al
- küçük bir "uzlaştırıcı" oluşturun: yanlış konfig, eksik örnekler gibi sürüklenmeyi düzenli olarak düzelten zamanlanmış kontroller
- açık sınırlarla (maks örnek, soğuma süreleri, onay kuralları) ölçek tetikleyicileri ekleyin
Bunun kendi başına çözmediği şeyler
Bu kalıplar kötü uygulama tasarımını, güvenli olmayan veri geçişlerini veya maliyet kontrolünü tek başına çözmez. Hâlâ versiyonlanmış API'lara, geçiş planlarına, bütçe/limitlere ve deploy'ları müşteri etkisiyle ilişkilendiren gözlemlenebilirliğe ihtiyacınız var.
Sonraki adımlar
Tek bir müşteri yüzlü servisi seçin ve kontrol listesini uçtan uca uygulayın, sonra genişletin.
Eğer yeni servisler inşa ediyorsanız ve "hızlıca dağıtılabilir bir şeye" ulaşmak istiyorsanız, Koder.ai size chat tabanlı bir spesifikasyondan tam bir web/backend/mobil uygulama üretebilir—genellikle frontend için React, backend için Go ve PostgreSQL, mobil için Flutter—ve ardından kaynak kodunu dışa aktararak burada tartışılan Kubernetes kalıplarını (deklaratif konfigürasyonlar, tekrarlanabilir rollout'lar ve rollback-dostu operasyonlar) uygulayabilirsiniz. Maliyet ve yönetişim değerlendirmeleri için /pricing'i inceleyin.